

Working with SQL and Databases in IntelliJ-based IDEs webinar follow-up

We hosted our very first webinar on Wednesday, July 14th. Thanks to all who joined us and especially those who asked questions. We hope it all was useful for you and your feedback on the webinar is very welcome!
https://www.youtube.com/watch?v=RlNEwBhckDA&feature=youtu.be
Here is the recording. Let me briefly describe what we talked about.
— Creating a simple query: Live templates, code completion, expand column list.
— Subqueries: Surround with, executing options, compare result-sets.
— Data editor: Bulk sumbit, multiple submit, foreign keys navigation, transpose view etc.
— Data extractors: Text extractors, SQL extractors, INSERTs batch editing, etc.
— Navigation and search: Finding objects in the database, text in the source code, data in the table, column in the result-set.
— User parameters.
— Questions and answers.
Introduction
DataGrip is a standalone IDE for SQL based on IntelliJ Platform. All of DataGrip’s features are also available in other IDEs from JetBrains like IntelliJ IDEA, PhpStorm, PyCharm, RubyMine, as well as the upcoming Rider and Gogland. DataGrip supports the most popular databases, and will add support for Amazon Redshift and Microsoft Azure this July.
Creating a simple query 🔗
Live templates let you insert frequently-used or custom code constructs into your scripts. You can create your own, too!

We highlighted several types of code completion, the most interesting being abbreviation completion and JOIN statement completion.
The IDE can complete your statement in a JOIN clause if the tables are connected with a foreign key.

Abbreviation completion lets you type abbreviations of database objects to use them in your code. For example fica for film_category, or gabi for getAuthorByID.

Expand column list lets you use the list of columns instead of wildcards.

Subqueries 🔗
To surround one query with another, or to make a common table expression, use the Surround With action by Cmd/Ctrl+Alt+T. Func(exp) means that the caret will be placed before the parentheses, not after.
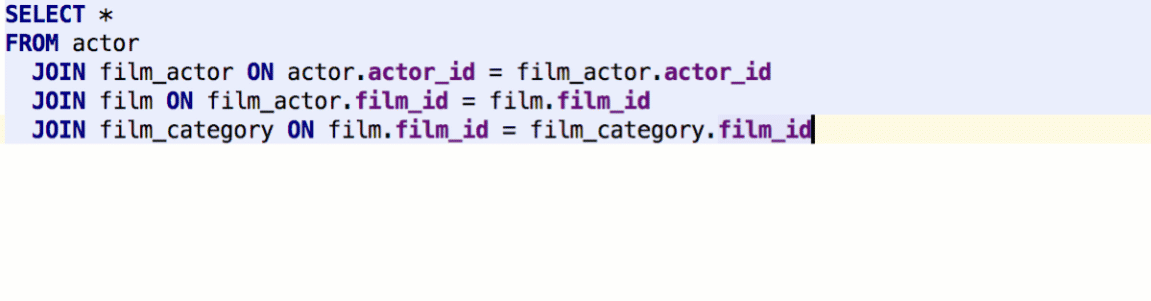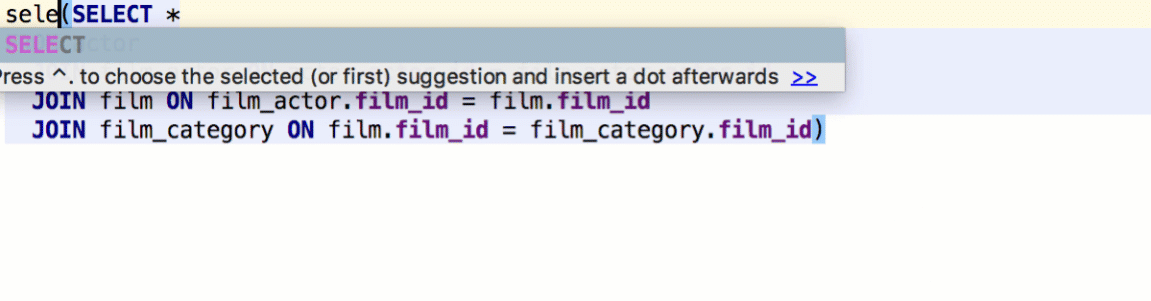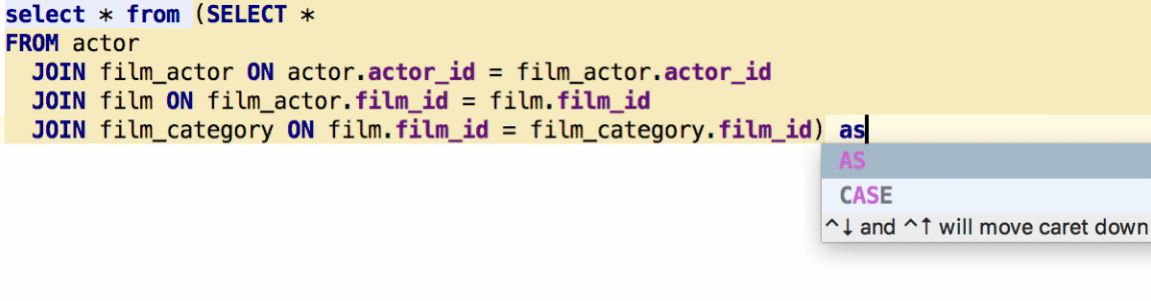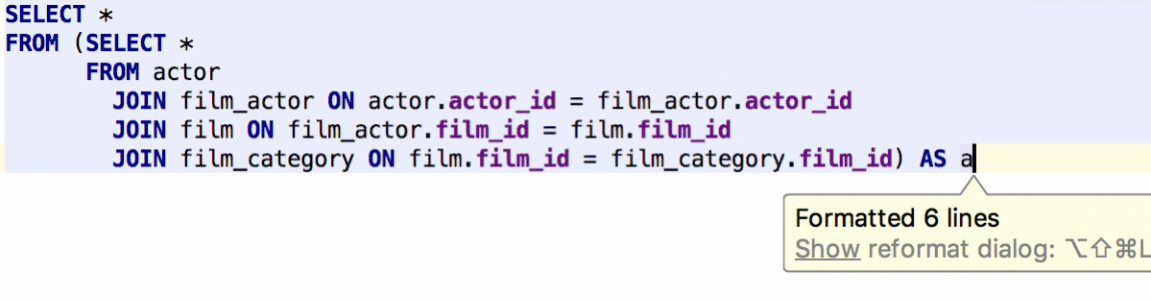
DataGrip lets you define what particular query you wish to execute after pressing Cmd/Ctrl+Enter: only a subquery, the whole statement where the caret is, or the whole script.
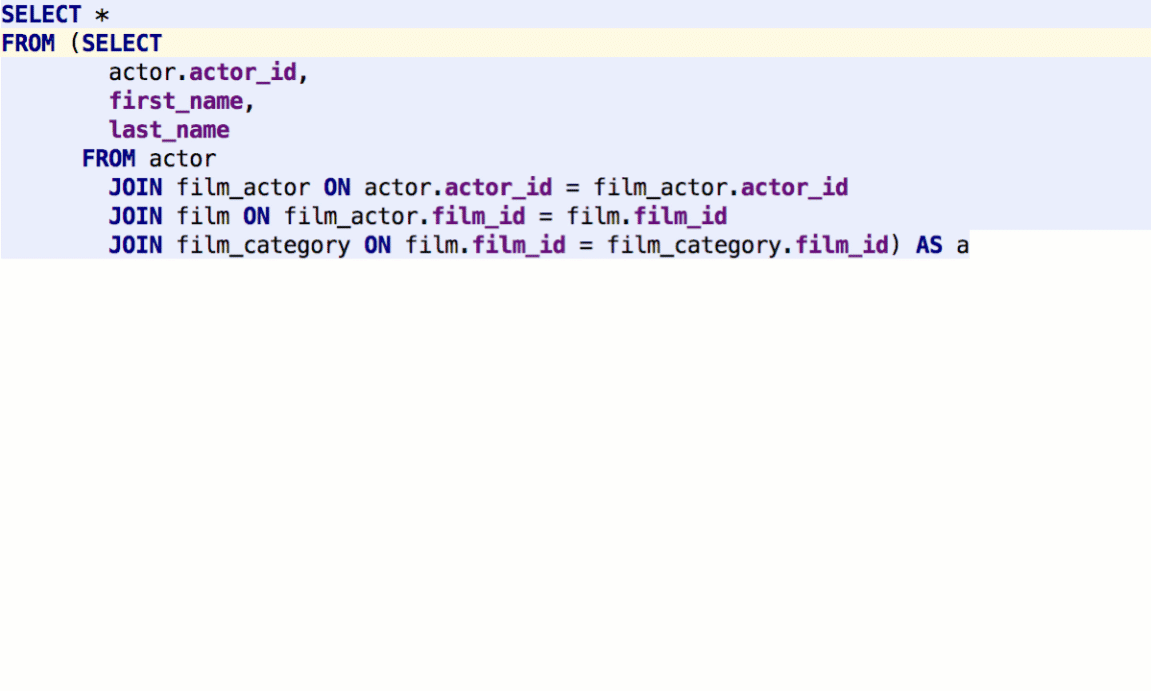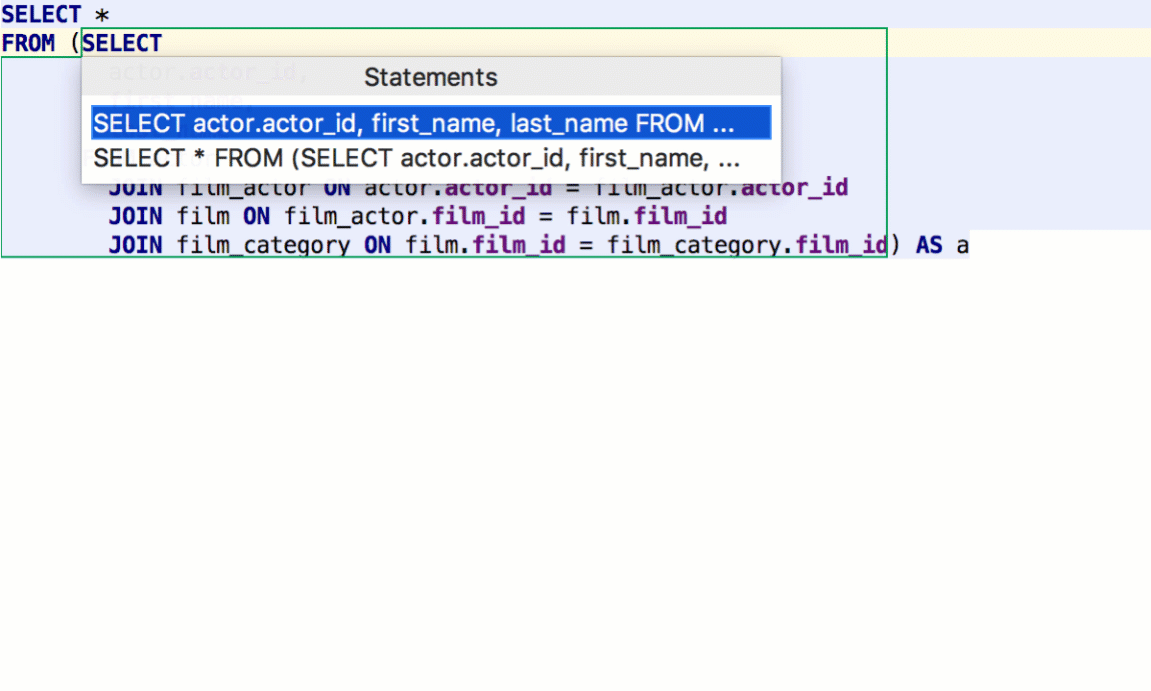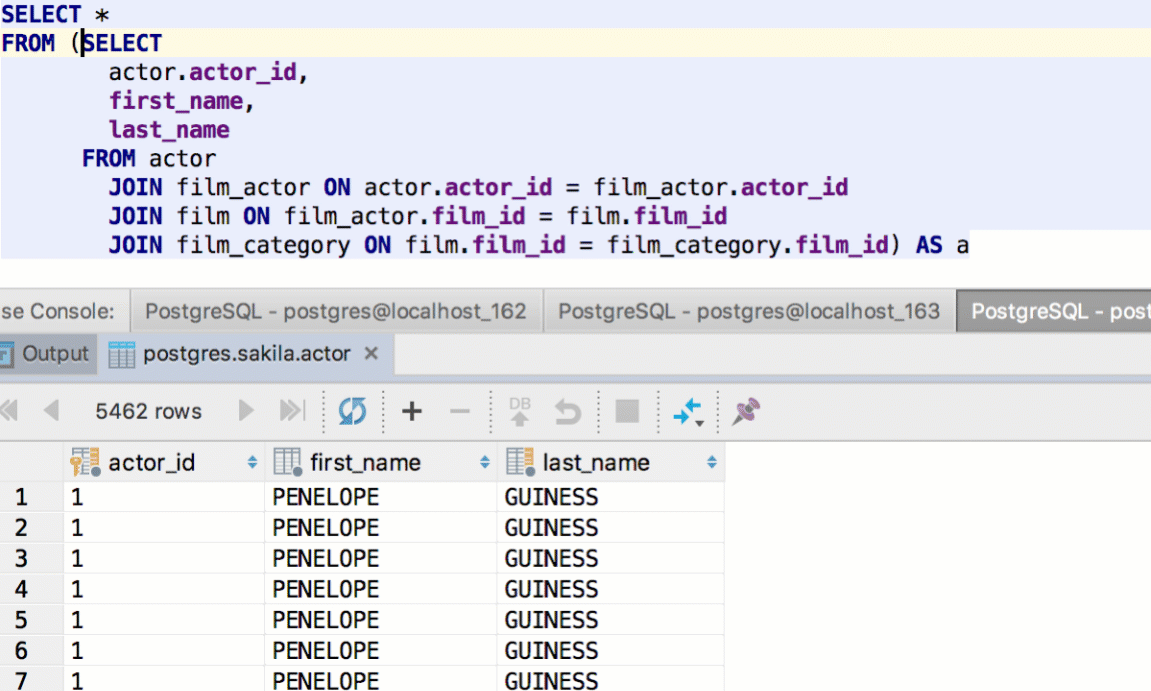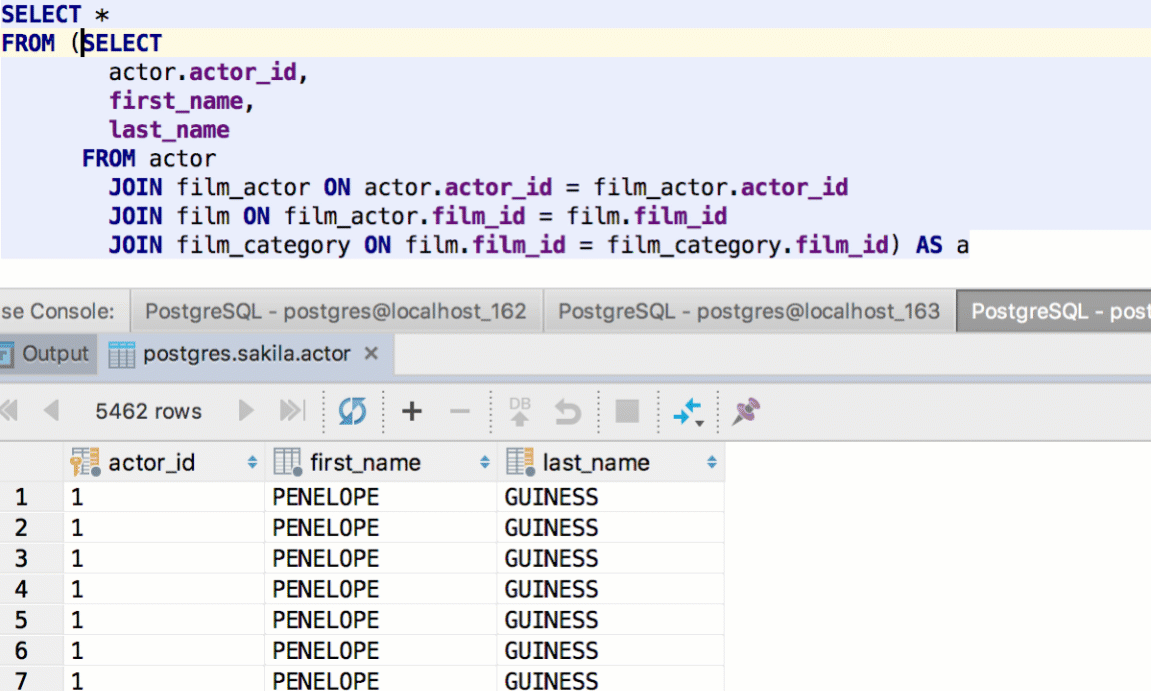
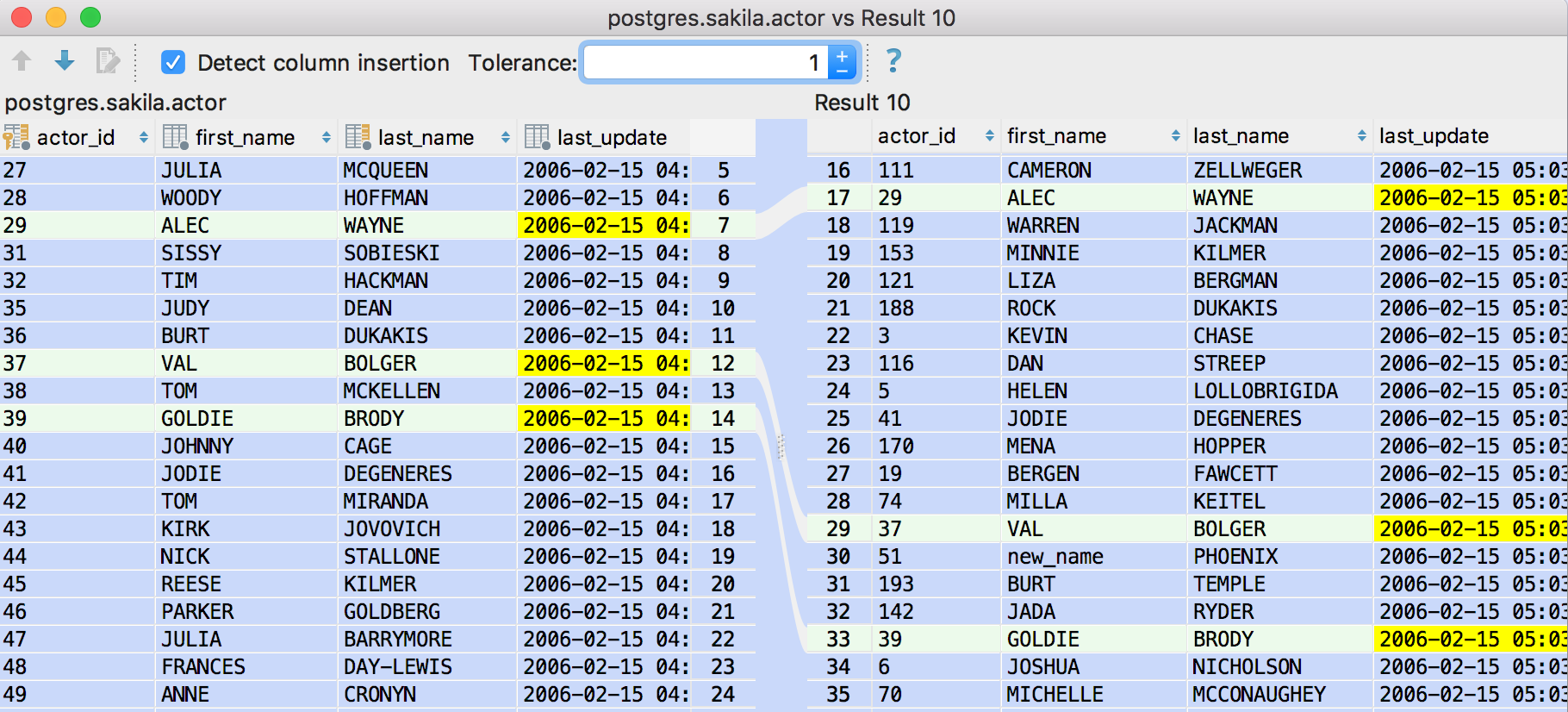
If you have two result-sets, they can be compared in Diff Viewer.
Data editor 🔗
The grid is editable: when you observe table data, you can apply any changes just like you would in Excel. All your changes are stored locally and can be submitted at once. Local changes are colored, so you can see which changes you are going to save, be it updating, inserting or deleting rows. Submit with Ctrl+Enter. Ctrl+Z is for reverting, but works in a tricky way — only the currently selected changes are canceled. If you wish to cancel all changes, select all cells with Ctrl+A before using Ctrl+Z.
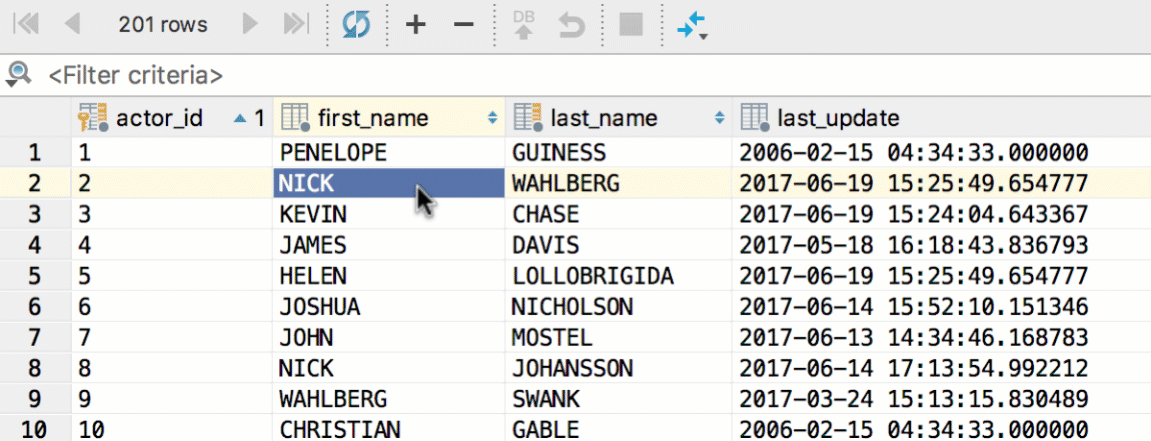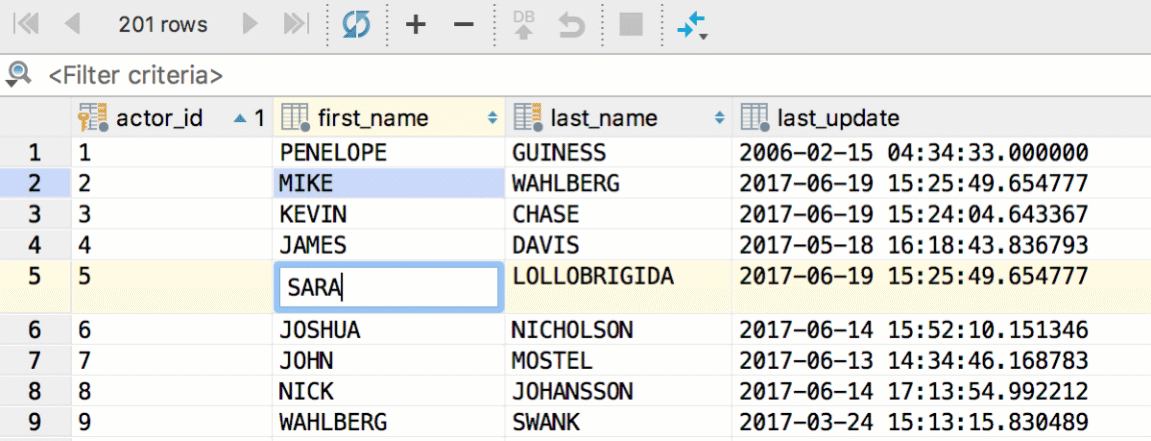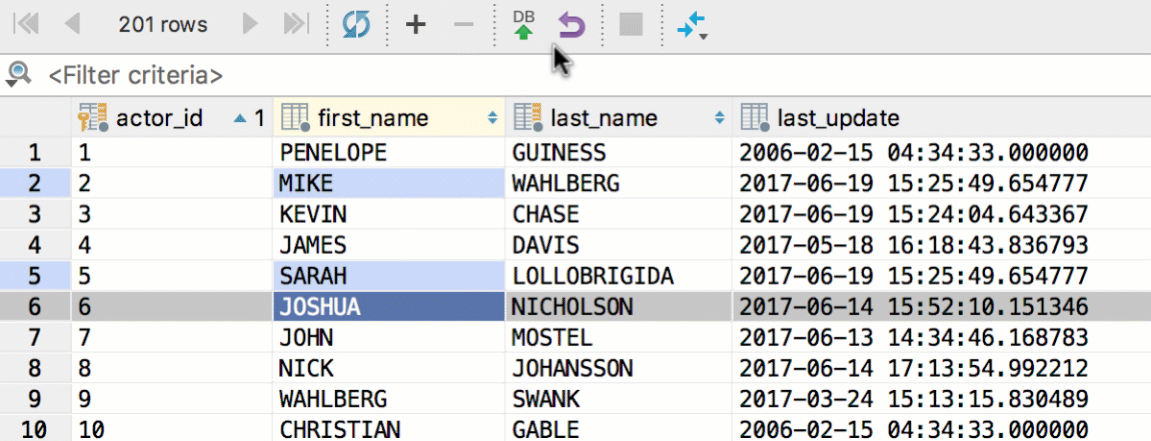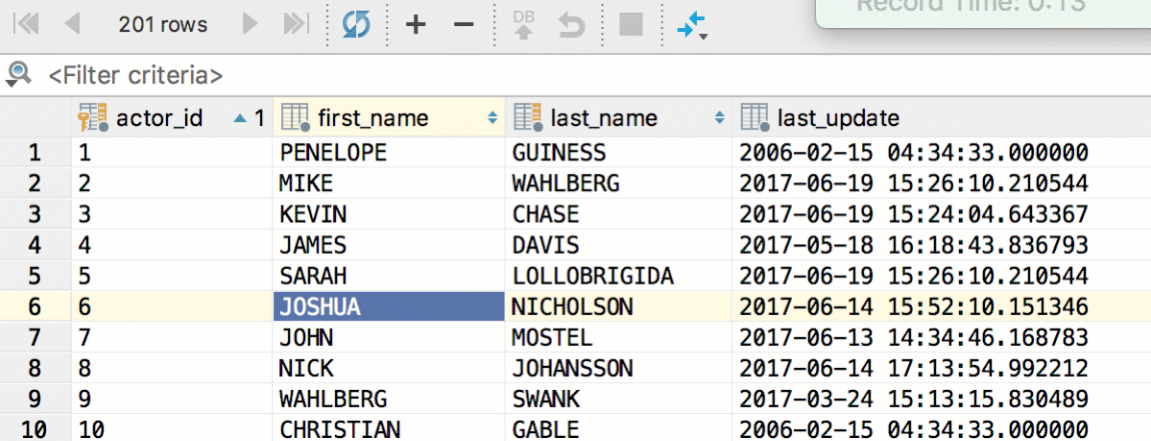
Several fields can be edited at once — just select them and begin typing. Of course, it works only if the columns you are editing are not unique and have the same type. Copy and paste works here as well.
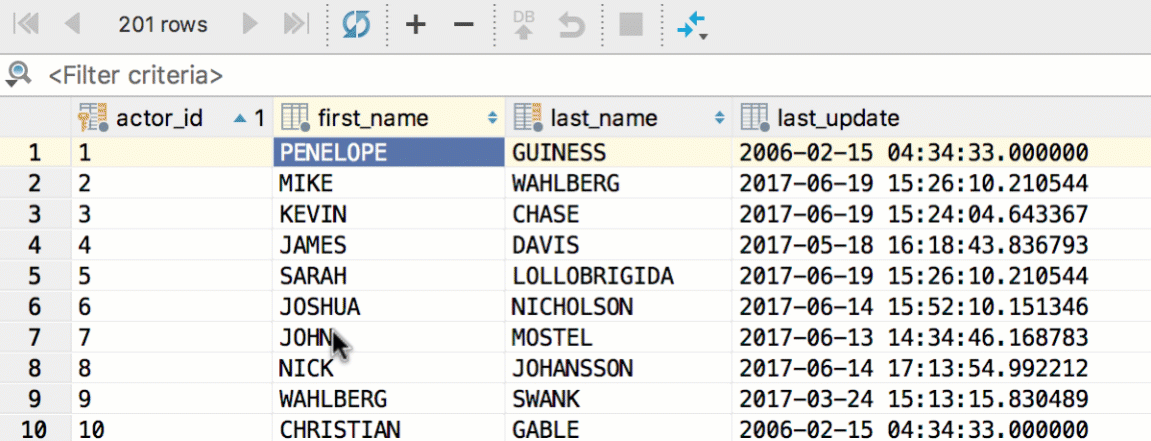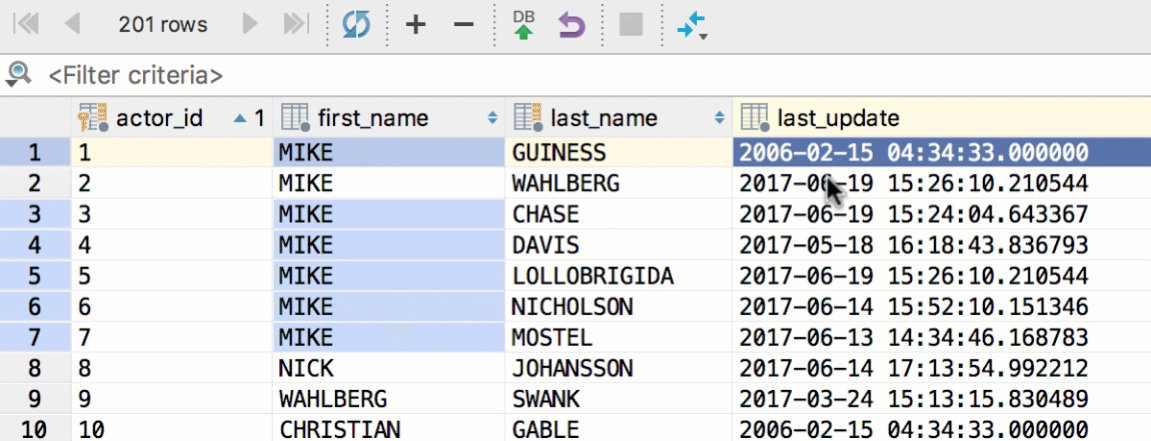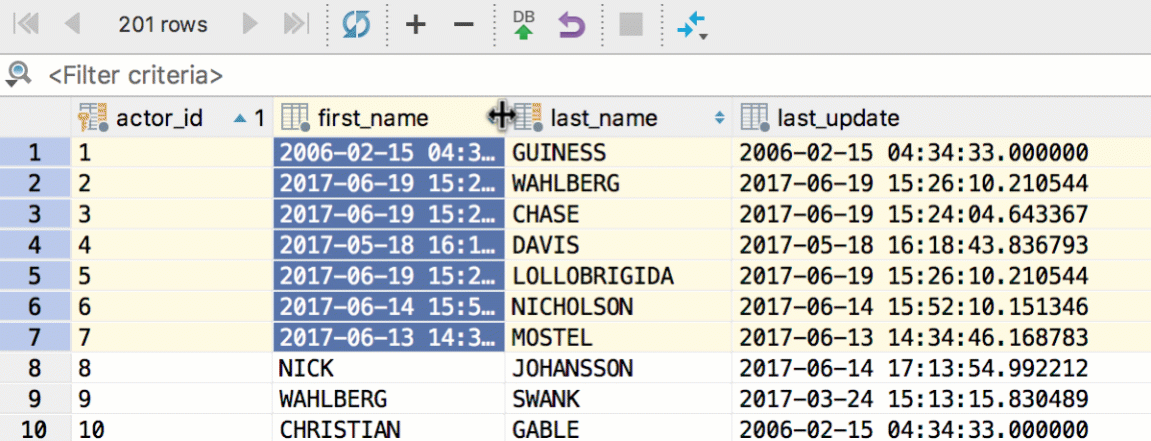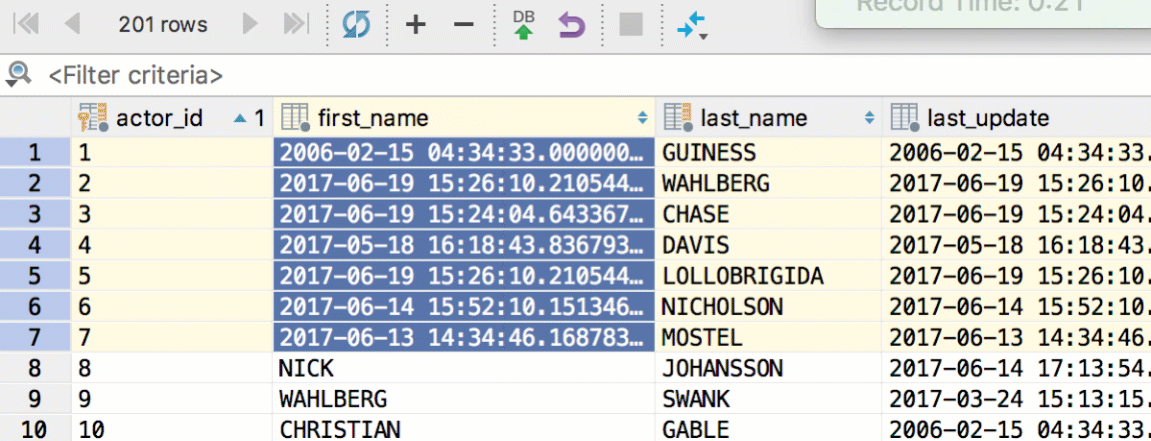
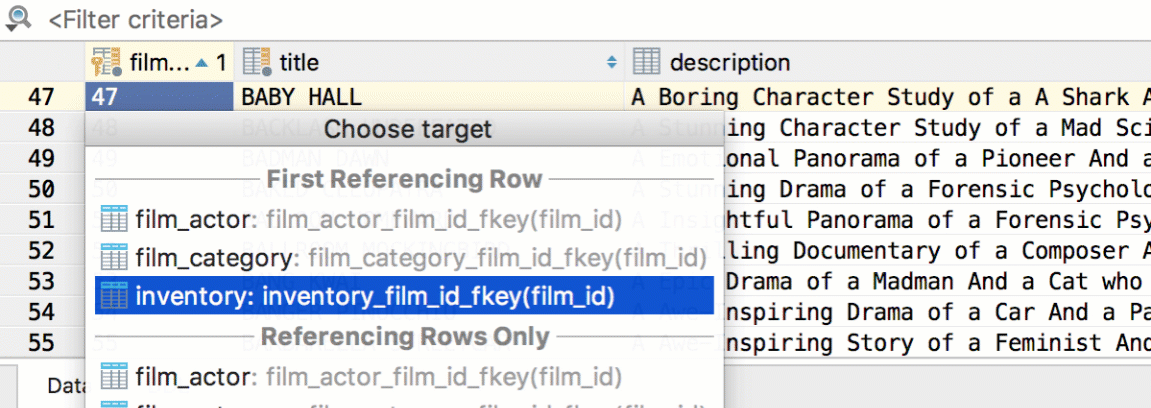
Use foreign keys navigation to see referencing data. For example, when you press Cmd+Down/F4 on the actor_id field with some particular value, you see the list of referencing tables. In our case it was only the film_actor table. Choose ‘referencing rows only’ and see the rows with actor_id = 6. Obviously, it’s just the list of films where the actor with id = 6 took part in. And again, pressing Cmd+Down/F4 on any row can bring you to this film’s row in the film table.
The Transpose view option lets you, surprisingly, transpose data! In other words, it flips your table: rows become columns and vice versa.

Data extractors 🔗
Any result-set or data can be extracted in many ways. The most obvious one is the CSV format. Just choose the extractor and then extract the data to the file or to the clipboard. Extracting to the clipboard is also mapped for the Copy action (Cmd/Ctrl+C), and this is what we use for the demonstration.
Paste your CSV data anywhere you want to. We used a scratch file – a temporary file which can be created at any moment just from the IDE.
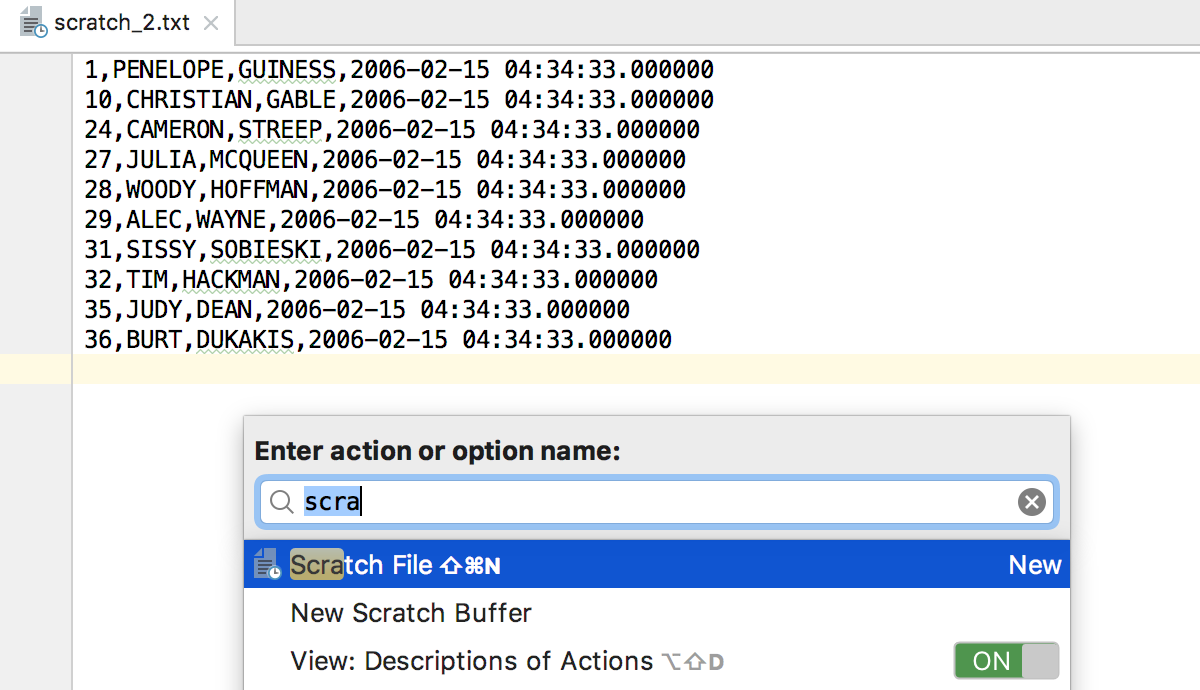
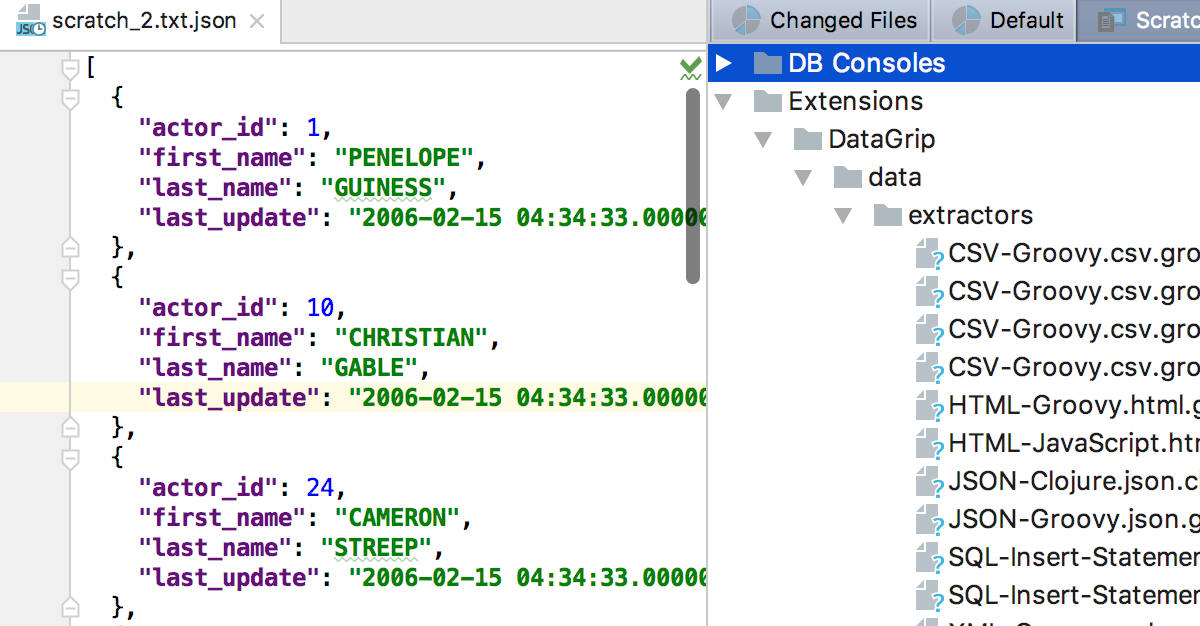
There are several text formats to export data in, including JSON, HTML, and XML. You can even create your own format with Groovy. Existing extractors can be found in Files (Cmd/Ctrl+2) → Scratches → Extensions → DataGrip → data → extractors.
Here are a couple of useful extractors: SQL Updates and SQL Inserts. You data will be presented as a batch of SQL statements. We showed a couple features which can help when you edit a batch of INSERT statements. First, ‘Edit as Table’ — select all statements you need to edit and choose this option from the context menu. Then, in a temporary table, edit the values you’re going to insert.
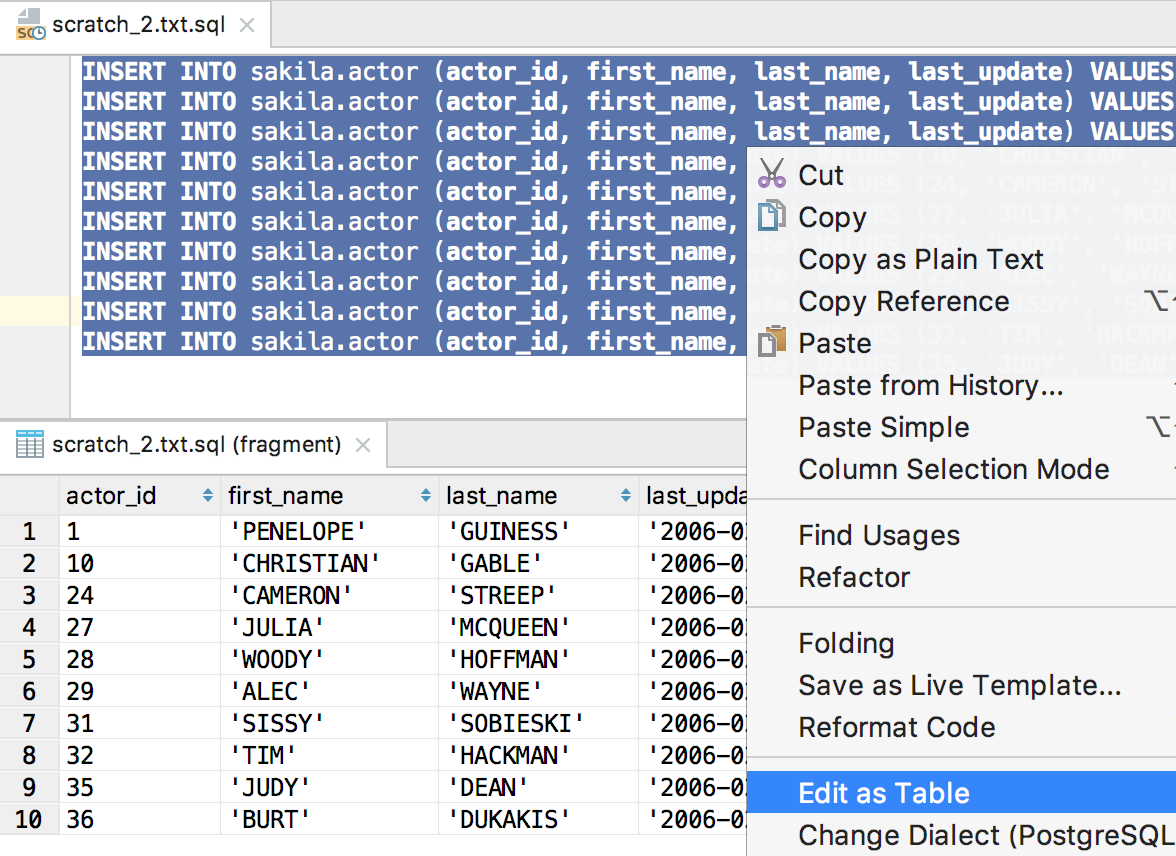
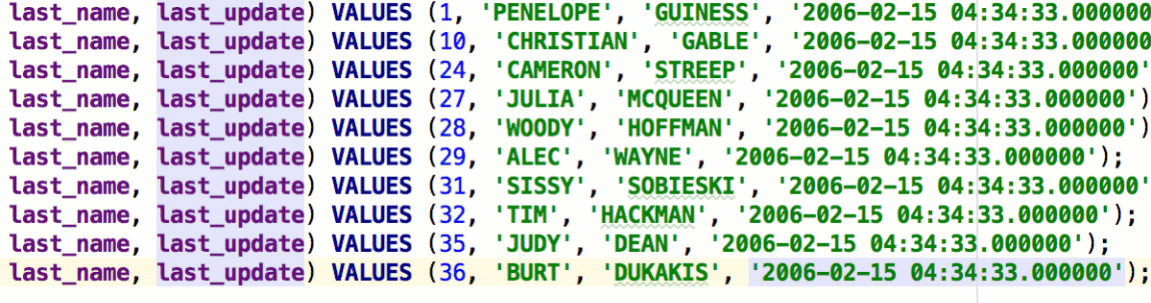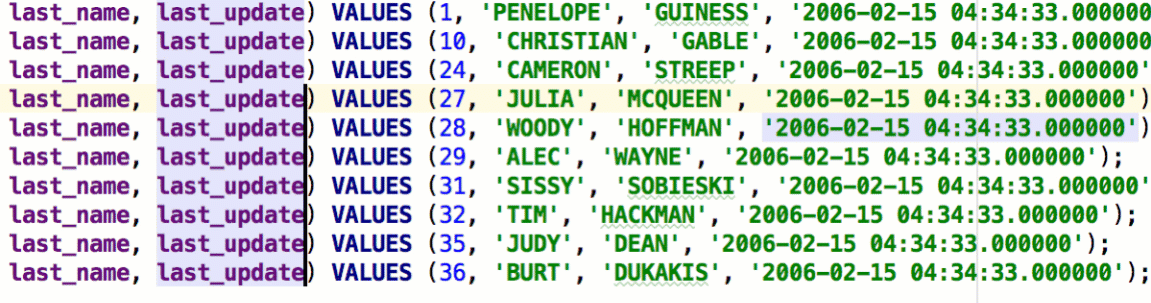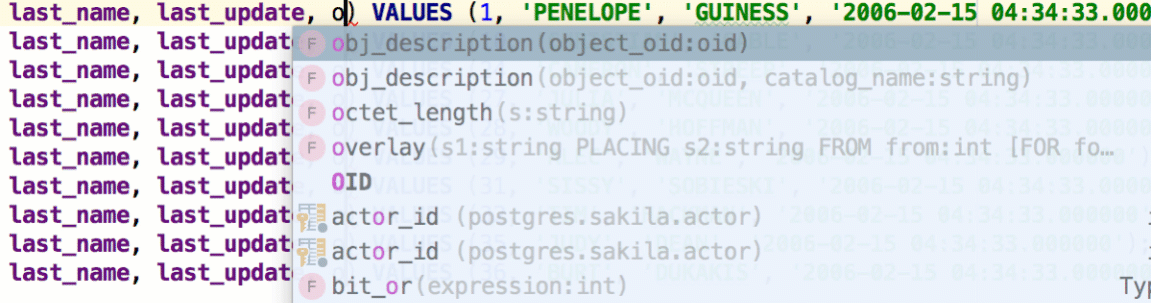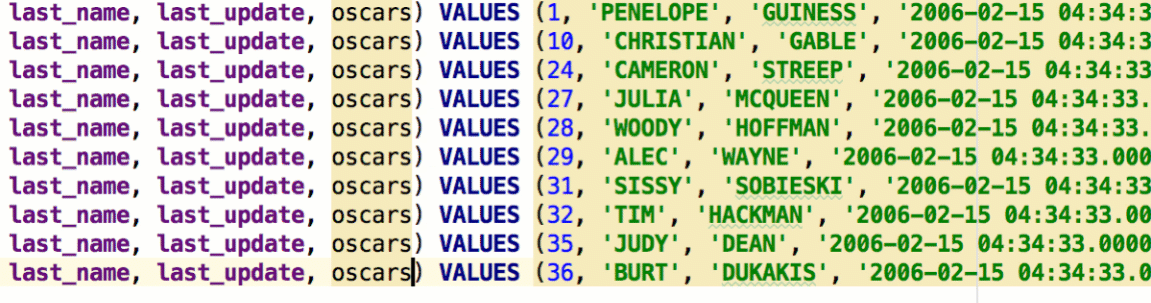
Another way to edit several statements at once is multiple cursors. The easiest way to place them is to press Alt/Ctrl twice, hold it and press the Up or Down arrow keys.
Navigation and search 🔗
You can navigate to the declaration of any resolved symbol with Cmd/Ctrl+Click, whether it is located in your SQL code or in the database.
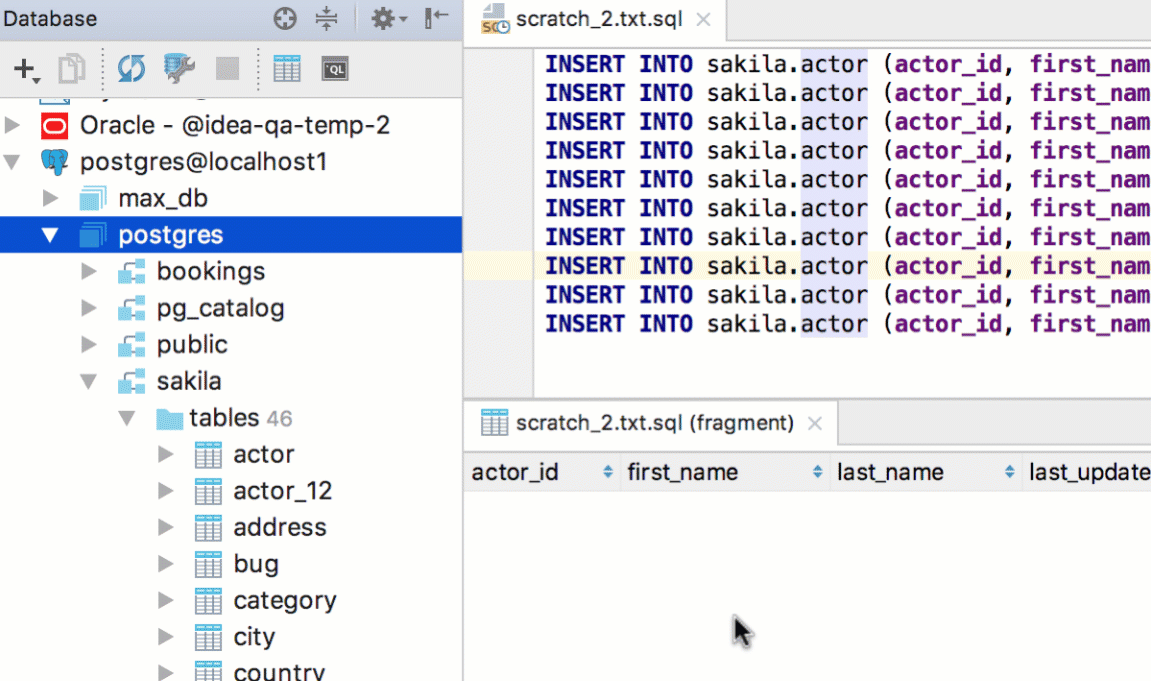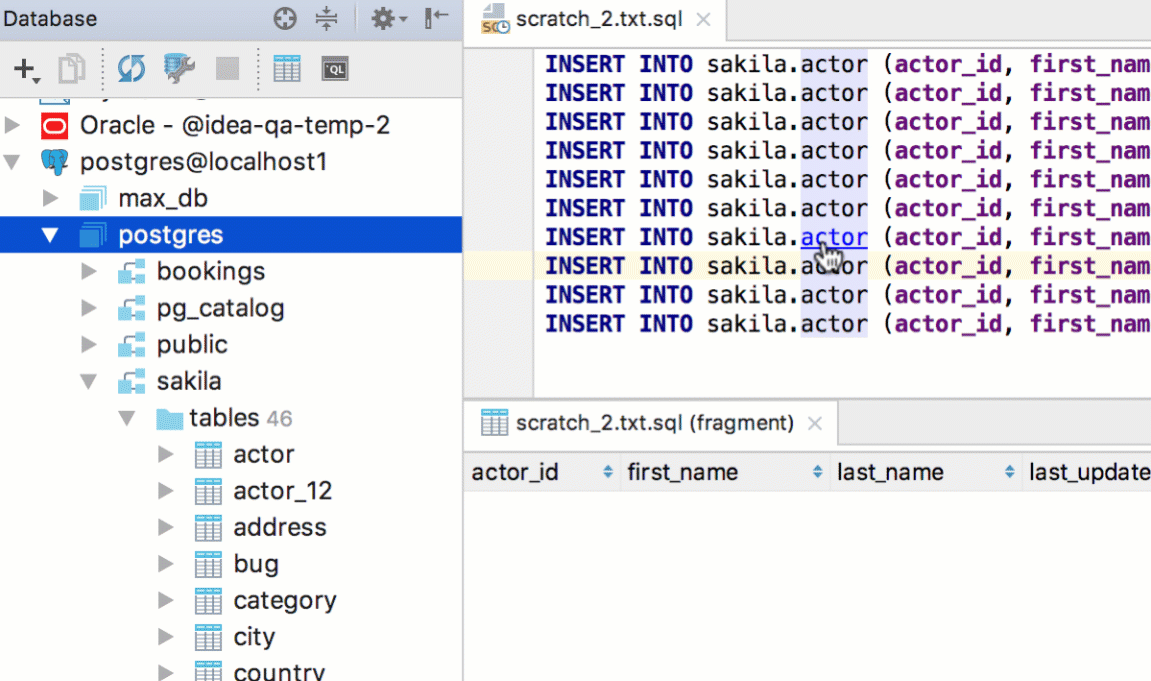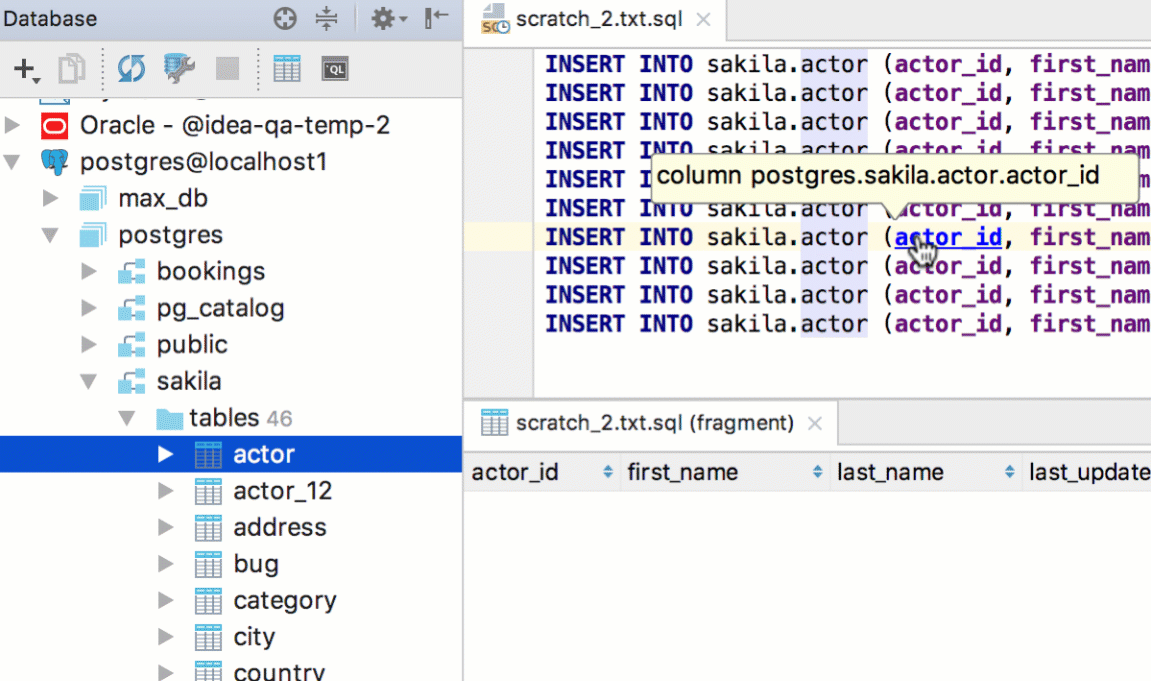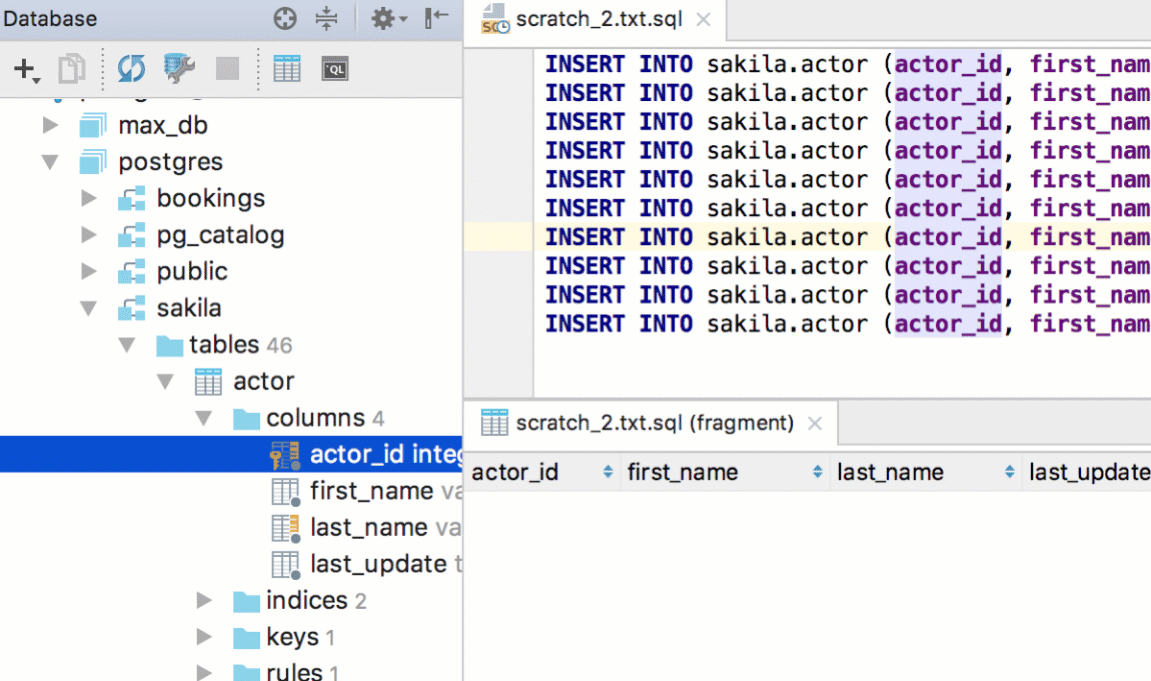
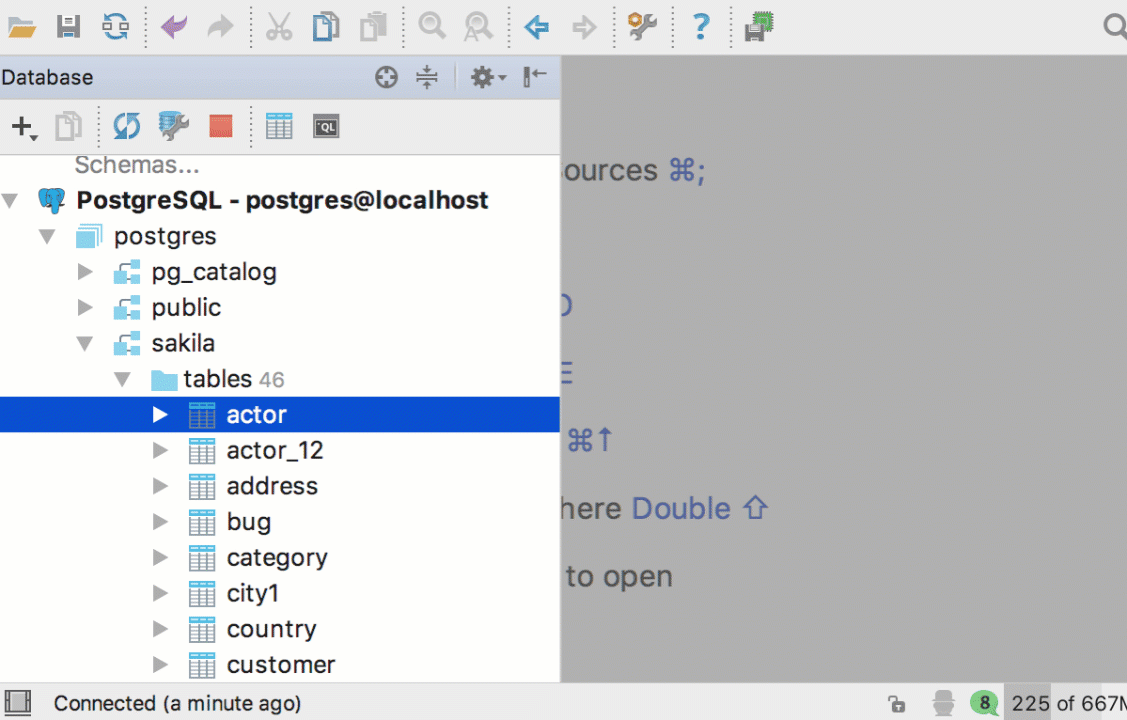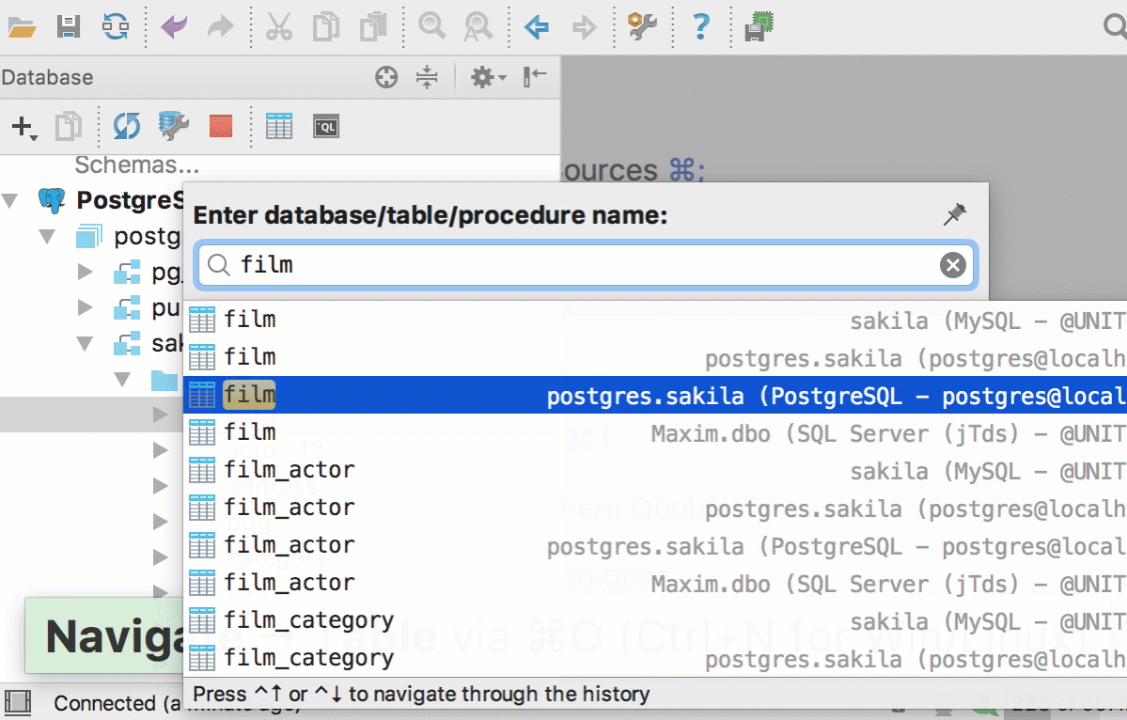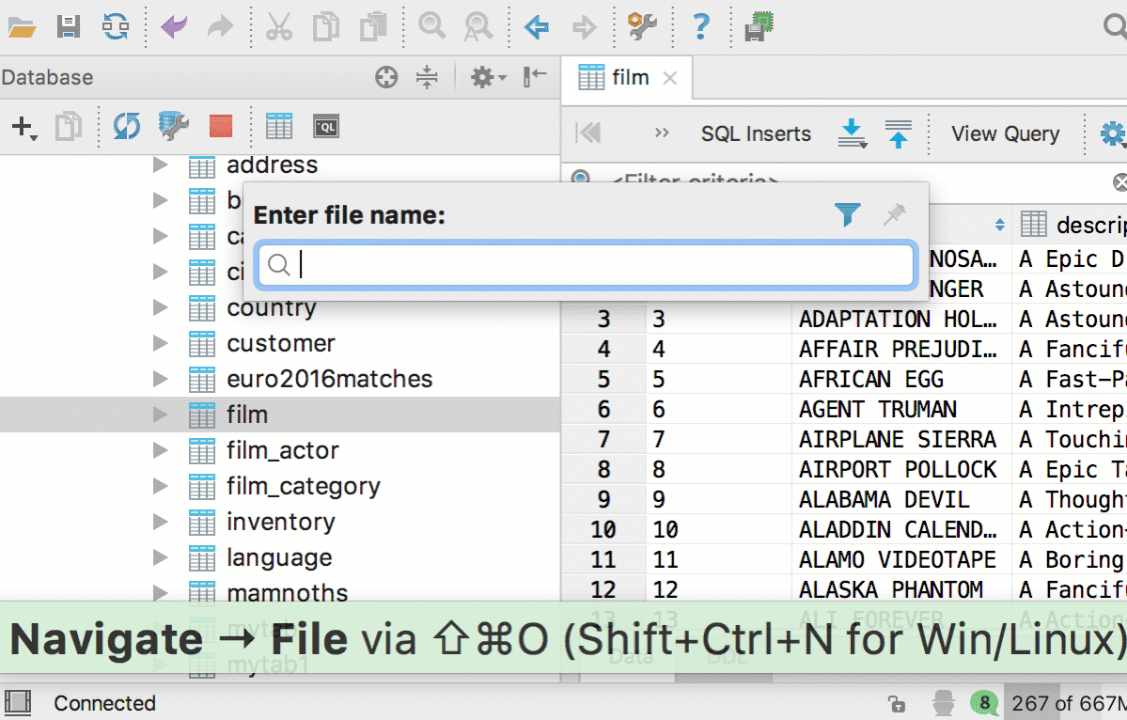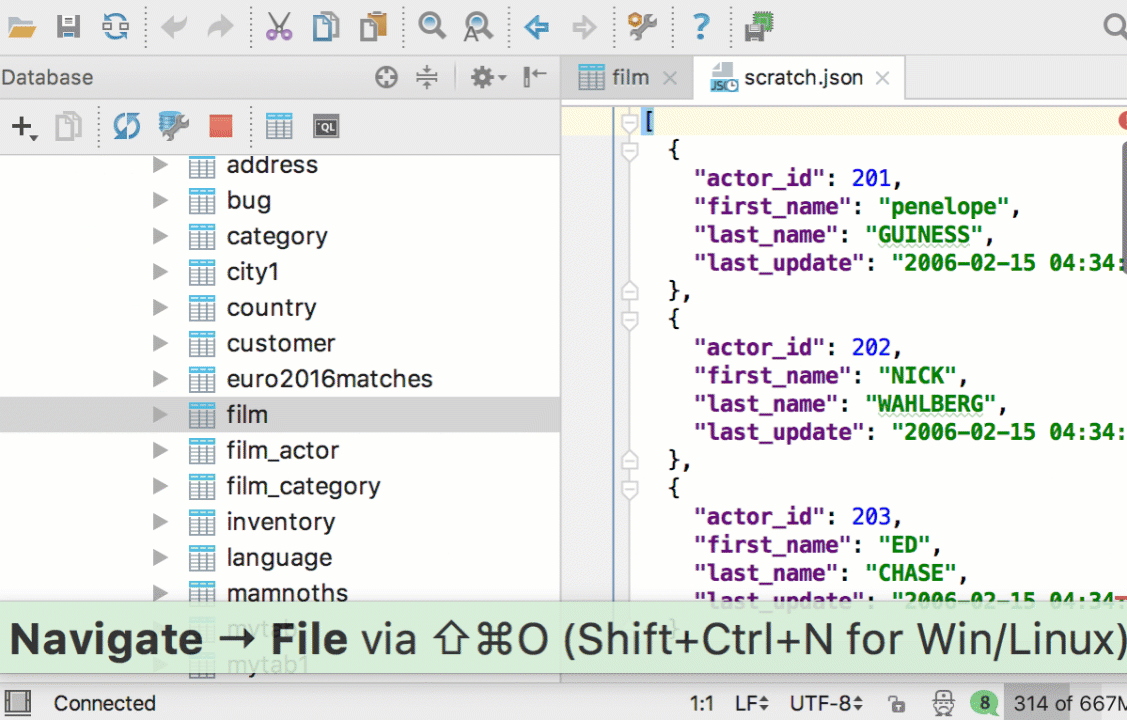
Navigate to a database object (like a table, procedure and so on) by pressing Cmd+O/Ctrl+N. If it is a table, a table editor will open. Cmd+Shift+O/Ctrl+Shift+N will bring you to any file.
Ctrl+F will find text in the editor, which is trivial. What’s not trivial is that Ctrl/Cmd+Space will invoke the code completion based on the words in the corresponding file!
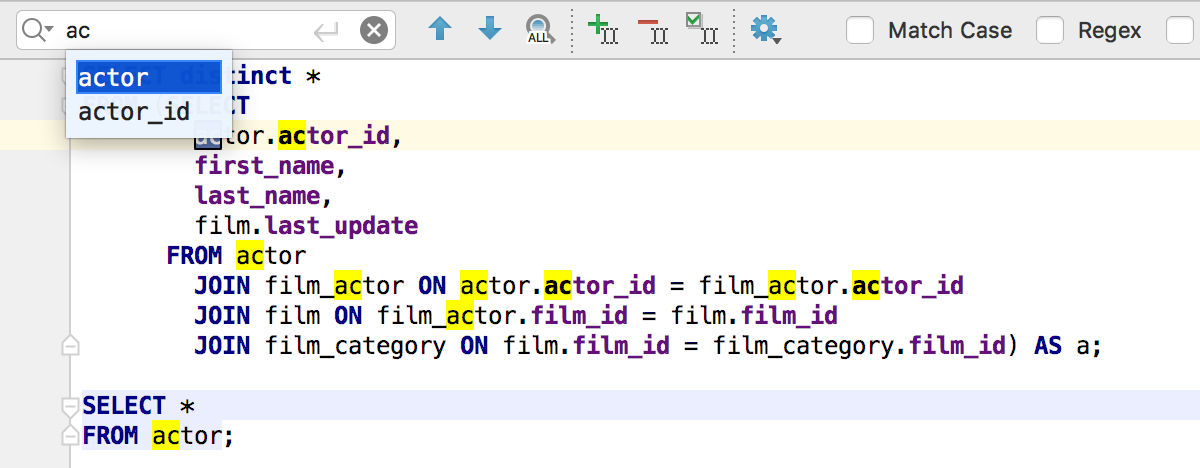
Ctrl+F in the data editor helps you quickly find data inside a table, without writing a statement. It’s especially helpful if you don’t know which exact column contains the data you’re looking for. You can see only rows with matches, if you prefer.
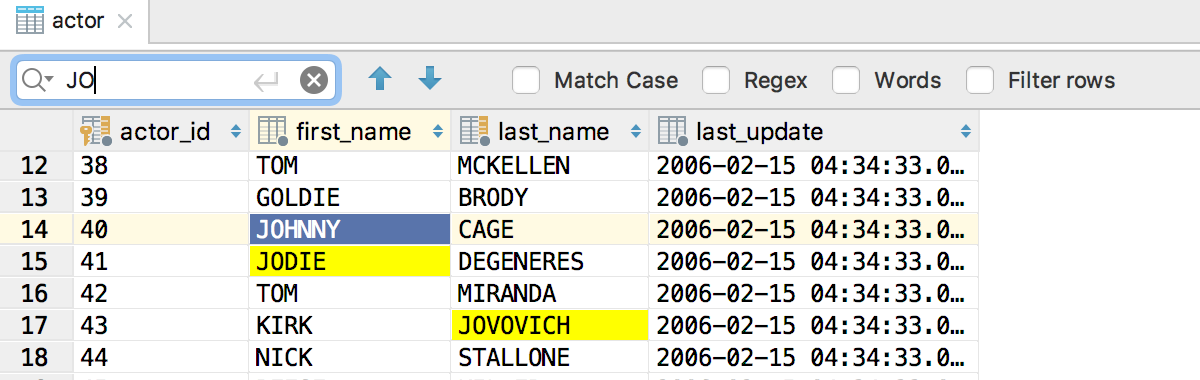
A small tip for searching for columns in any result-set or table: Open Structure view with Ctrl+F12 and start typing! Speed search saves you again and filters the columns based on what you’ve typed. Press Enter to navigate to a particular column.
User parameters 🔗
When you get an SQL query from another application, it can be parameterized. DataGrip supports running this kind of queries. The UI for editing parameter patterns is available in Settings/Preferences → Database → User Parameters. Regular expressions are highlighted and you can choose in what dialect these patterns are valid.
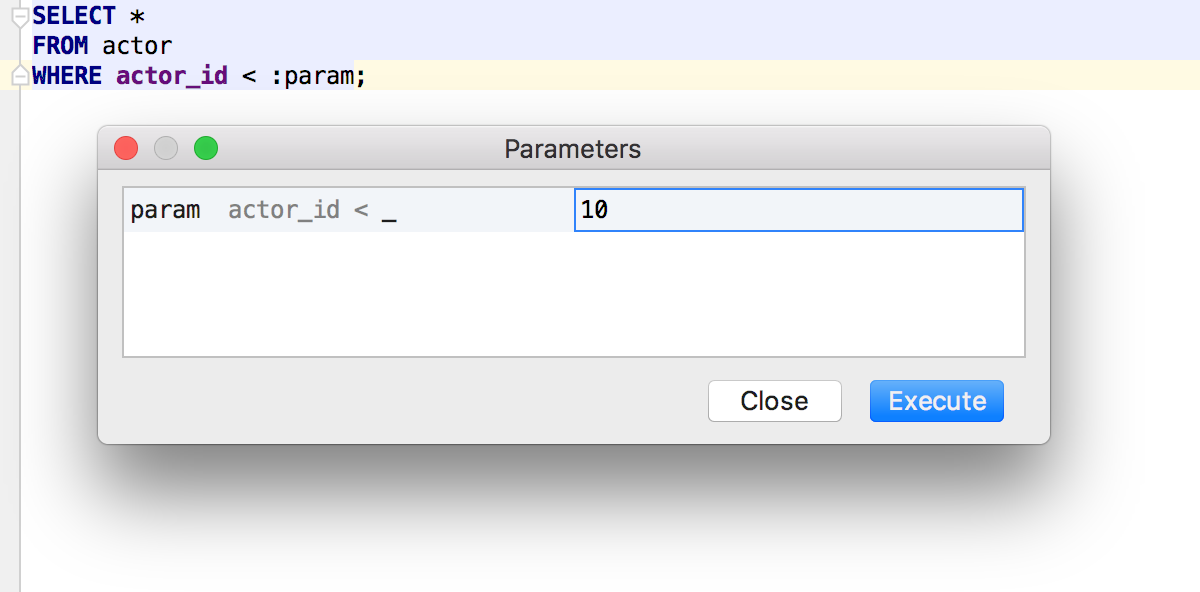
That wrapped up the main part of the webinar.
Questions and answers
(the most interesting ones)
30:03
Q: Do you plan to support Hive or Impala?
A: DataGrip can connect to any database which has a JDBC-driver. It means that you can connect to Hive or Impala, see tables and other objects, and run queries. Special features of these kind of database are not supported and their syntax is not correctly highlighted. There is an issue in our tracker about adding the possibility to define custom dialects in DataGrip.
31:02
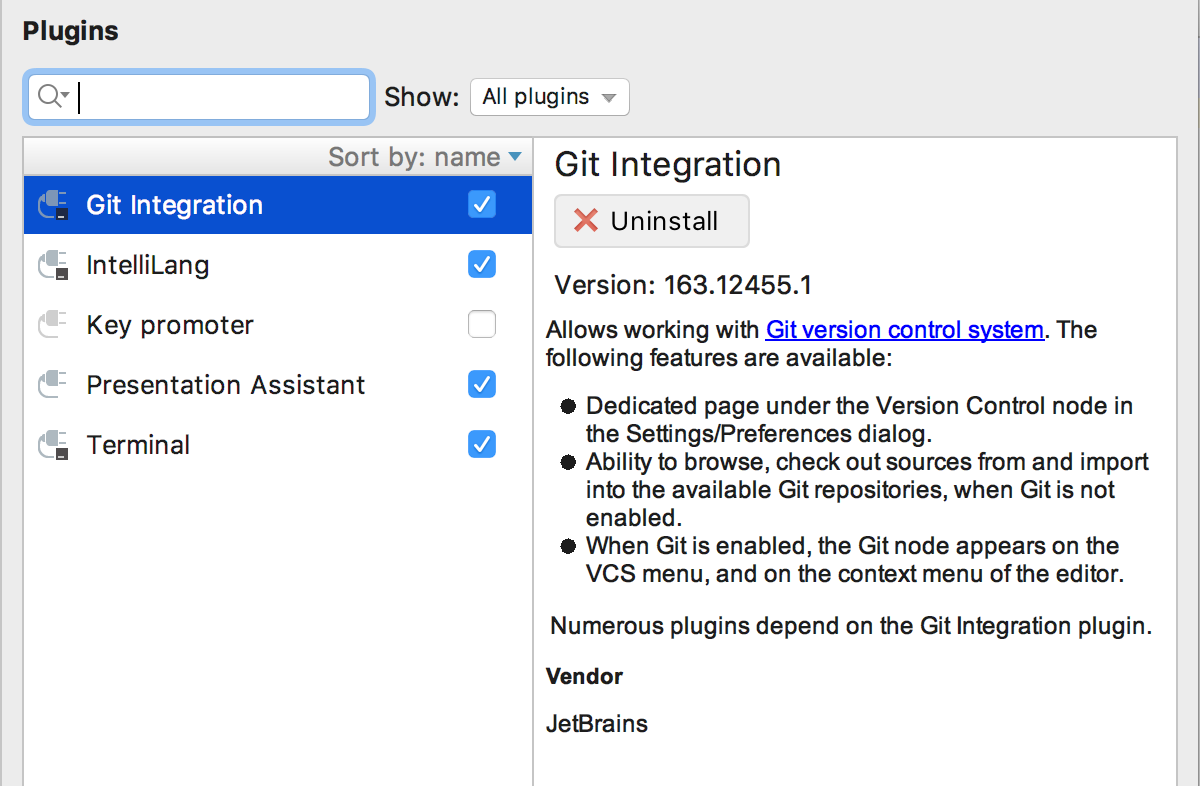
Q: What about version control systems?
A: DataGrip supports Version Control Systems like Git, SVN, Mercurial and some others. But this support doesn’t come out of the box: you need to install a JetBrains plugin for it. Go to Settings → Plugins → Browse repositories and search for the plugin you need. This plugin will bring first-class support for any VCS you need.
32:00
Q: Do you plan to add more management tools?
A: Not any time soon. We are focusing on developers for now, but we will consider adding administration support later.
32:57
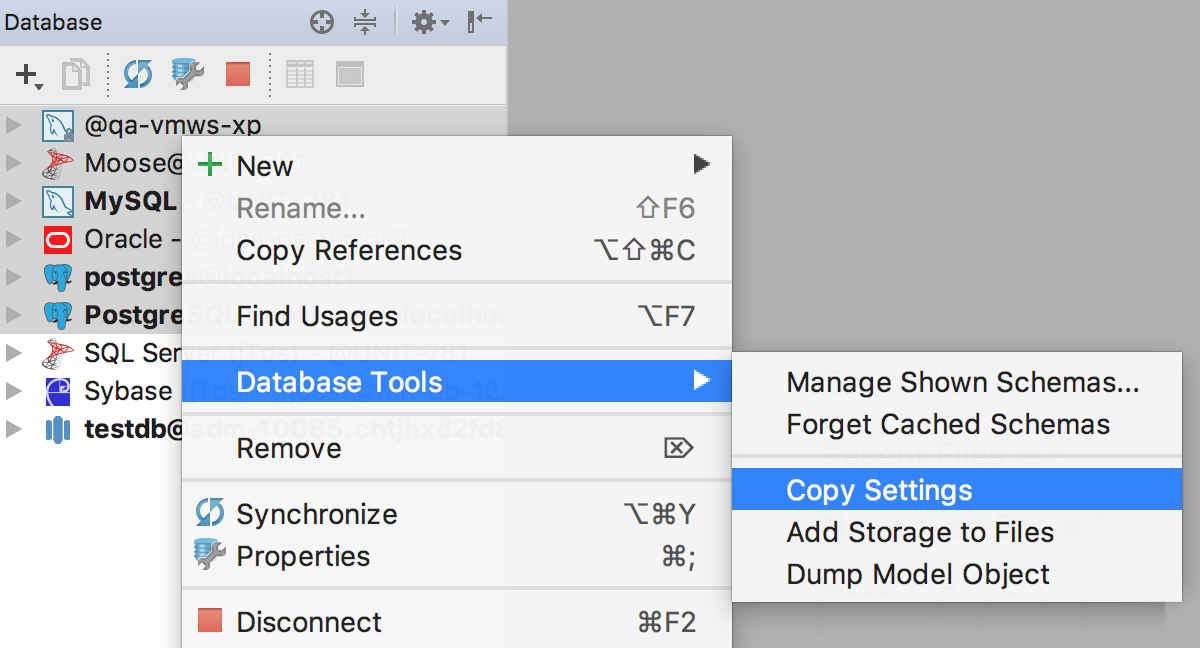
Q: Is there a way to share data sources from DataGrip to other IDEs?
A: Select the data sources you want to share and then go to context menu → Database Tools → Copy Settings.
Press + to add a new datasource and choose Import from Clipboard. During the webinar I said that this feature would be coming in the new version, but it’s also available in 2017.1.4 as long as datasource information is already copied to the clipboard.
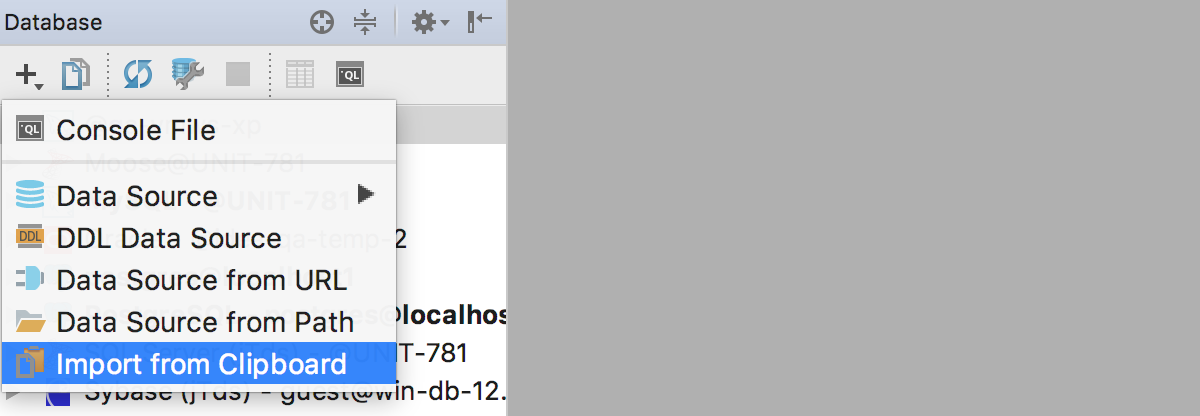
It didn’t work during the webinar only because I didn’t actually press Copy Settings.
47:15
Q: Is it possible to record DDL and DML actions?
A: We are thinking about logging all queries coming from DataGrip. The only thing we offer now is the Modify Table window, where all your changes to the table are reflected in the generated script.
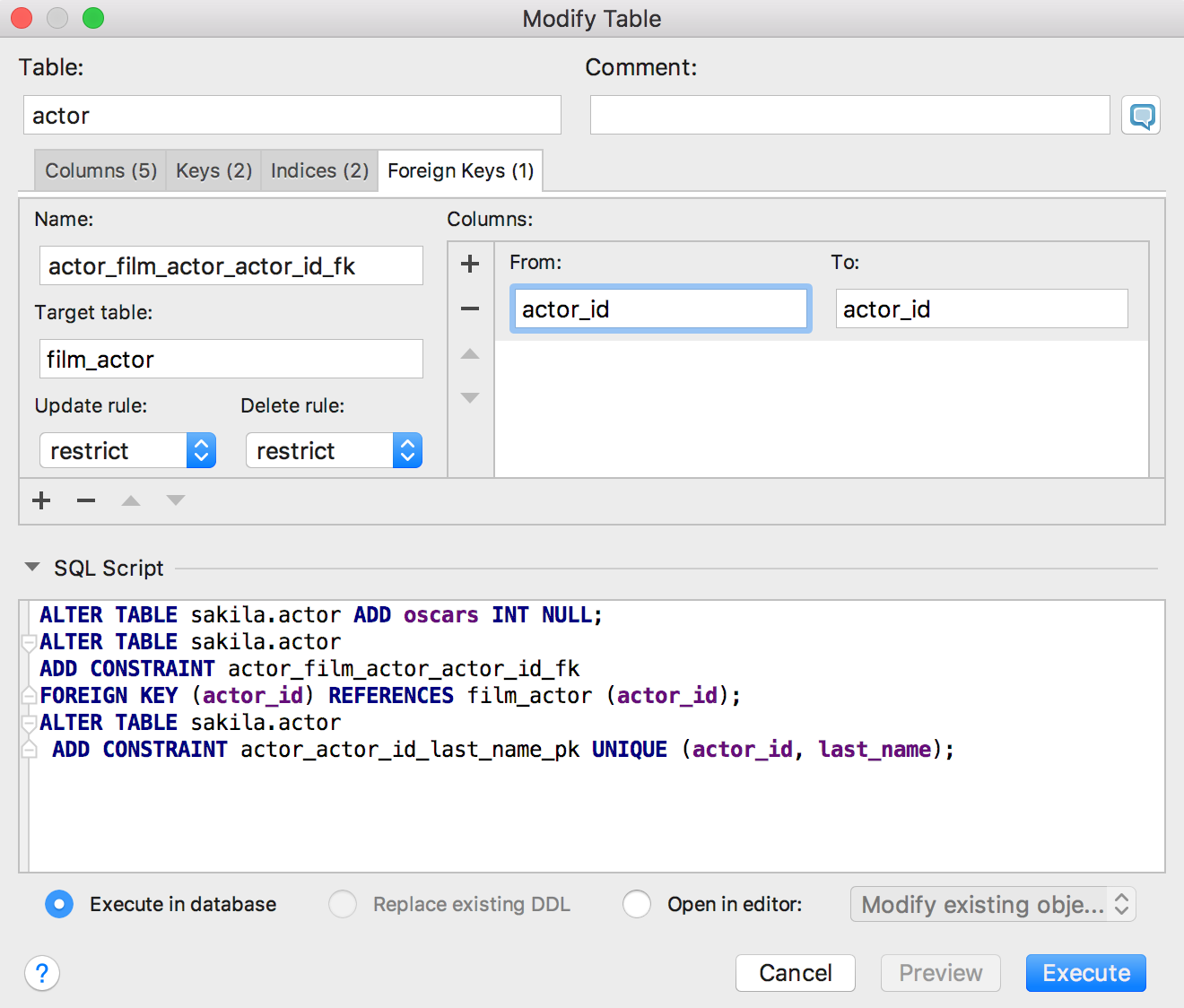
49:20
Q: Can users configure the CSV format and use the custom delimiter?
A: Sure, simply choose Configure CSV formats… from the extractors drop-down.
51:15
Q: Is there a way to load CSV files to the database?
A: There are several ways to do that. The most common is to choose ‘Import data from file’ from the context menu of your database or schema. Or, you can just drag and drop your CSV file to the appropriate place in your database.
58:05
Q: What about data visualization, like graphs or pie-charts?
A: Sorry, there is no data visualization in DataGrip.
58:55
Q: Can we compare result-sets from different data sources?
A: Yes, you can.
That’s it! Thank you for your time, and if you’d like to have a webinar on a particular topic, let us know!
Your DataGrip Team




