

How to Use Git with DataGrip

In the software world, there has been a solid habit of using version control to keep track and manage source code changes and collaboration. We have moved from centralized solutions like SourceSafe and TFS and now into using tools that distribute the management with Mercurial and Git. While both centralized and distributed technologies have pros and cons, we will be looking at why database professionals need to use version control and how to do it with the popular tool Git.

With DataGrip’s inheritance from IntelliJ IDEA, we have the ability to use Git to store, manage edits, and allow a team to collaborate on projects that benefit everyone. There is no reason why your database SQL scripts should not be under source control right next to your team’s application code. We will dig into VCS and give you some knowledge to keep that your database scripts and files backed up and up to date.
You can download DataGrip now to see how your team’s database work can benefit.
What is Version Control and Git?
If you are new to VCS or version control, just know that it is a way to track changes to one or more files and has the ability to track those changes with a version that can be referenced later when necessary. By having versioned (explicit or dated) changes, we can revert back to previous versions of the code if anything goes wrong. We can also have labels that track released versions of our database so that we can proceed to future development without losing our production code.
Having backups of production data and scripts is a key for a well-run database, but it’s hard to keep the database history while not having issues like forgotten files throughout your hard drive. You probably have a practice of overwriting your database’s backups with the latest data. The issue you will run into is losing good data that you may need in the future and also corrupting your database schema. The other technique database professionals use is to save a date stamped backup in a folder, but that just leads to a mess with lots of files to manage.
A database backup is just SQL code or other files that contain the data in a format the database engine can import, so why not handle it the same way you manage the rest of your code — in a source code system like Git? Setting this up is very simple, so let’s walk through it.
As with any version control system, Git was created to keep a historical look at source code and that includes database scripts and backups. As a distributed version control system, it is aimed at speed, data integrity, and support for non-linear workflows. You might be asking, “What makes it distributed?” The key to Git is that is tracks your changes locally and remotely. When you check your code into Git, it stores those snapshot changes locally on your file system in a local repository. That way you can make many changes or back out of changes that you need to without affecting anyone else who also works with or depends on the code. When you are sure you want to make your changes available for others, you can then “push” your changes to the remote repository. You can also “pull” other’s changes that have been pushed to the remote repository.
That is a very simple look at Git, but if you want more details please review the Git documentation and tutorials.
Installing Git
To work with Git or any other VCS system with DataGrip, we will need to install the plugin. To install the plugin go to File | Settings… and then select the Plugins option. Finally, click the Install JetBrains plugins… button.
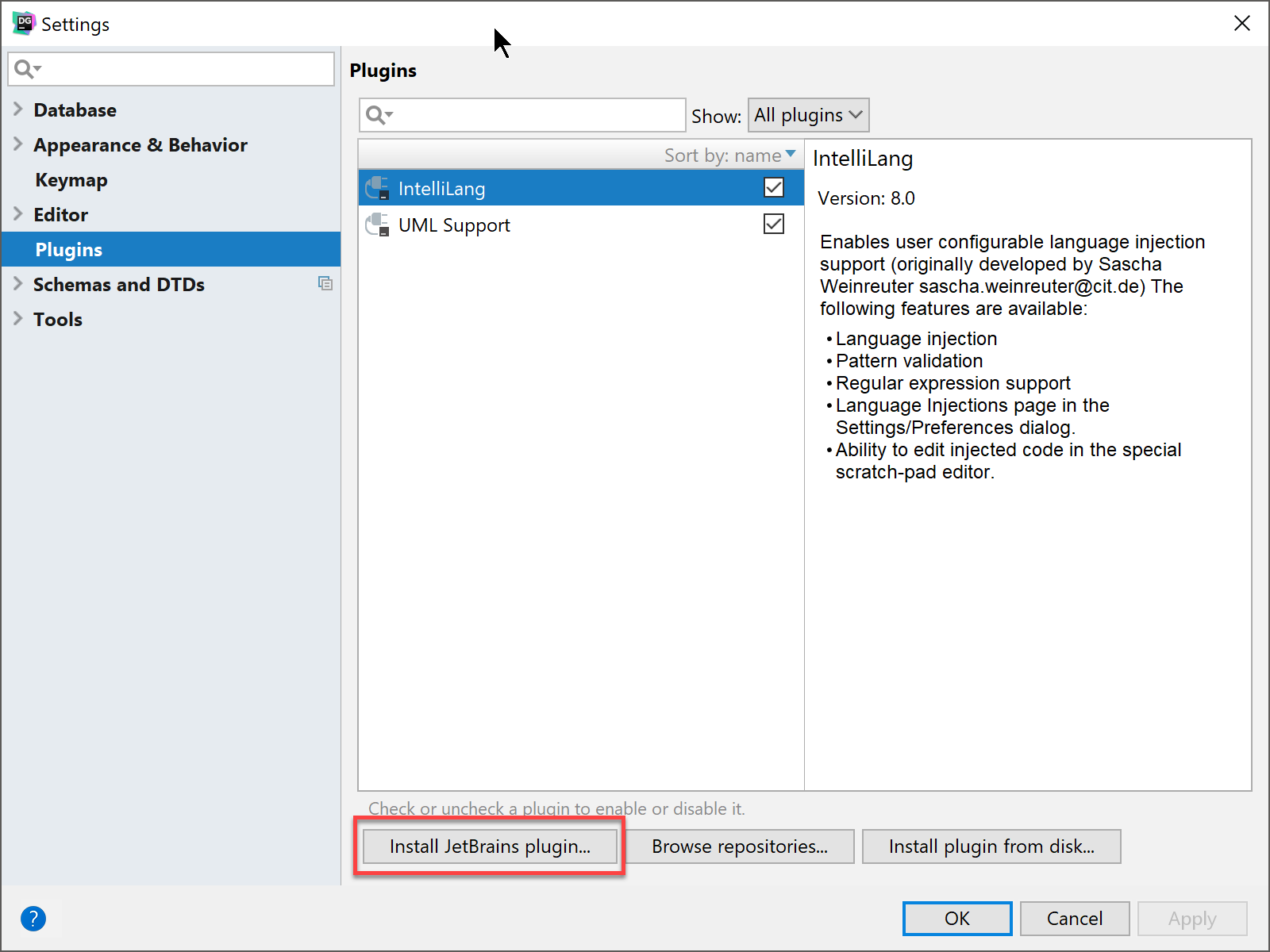
Search for git on the search box. You should get the Git Integration plugin showing first in the list, which will allow you to install the plugin and restart DataGrip.
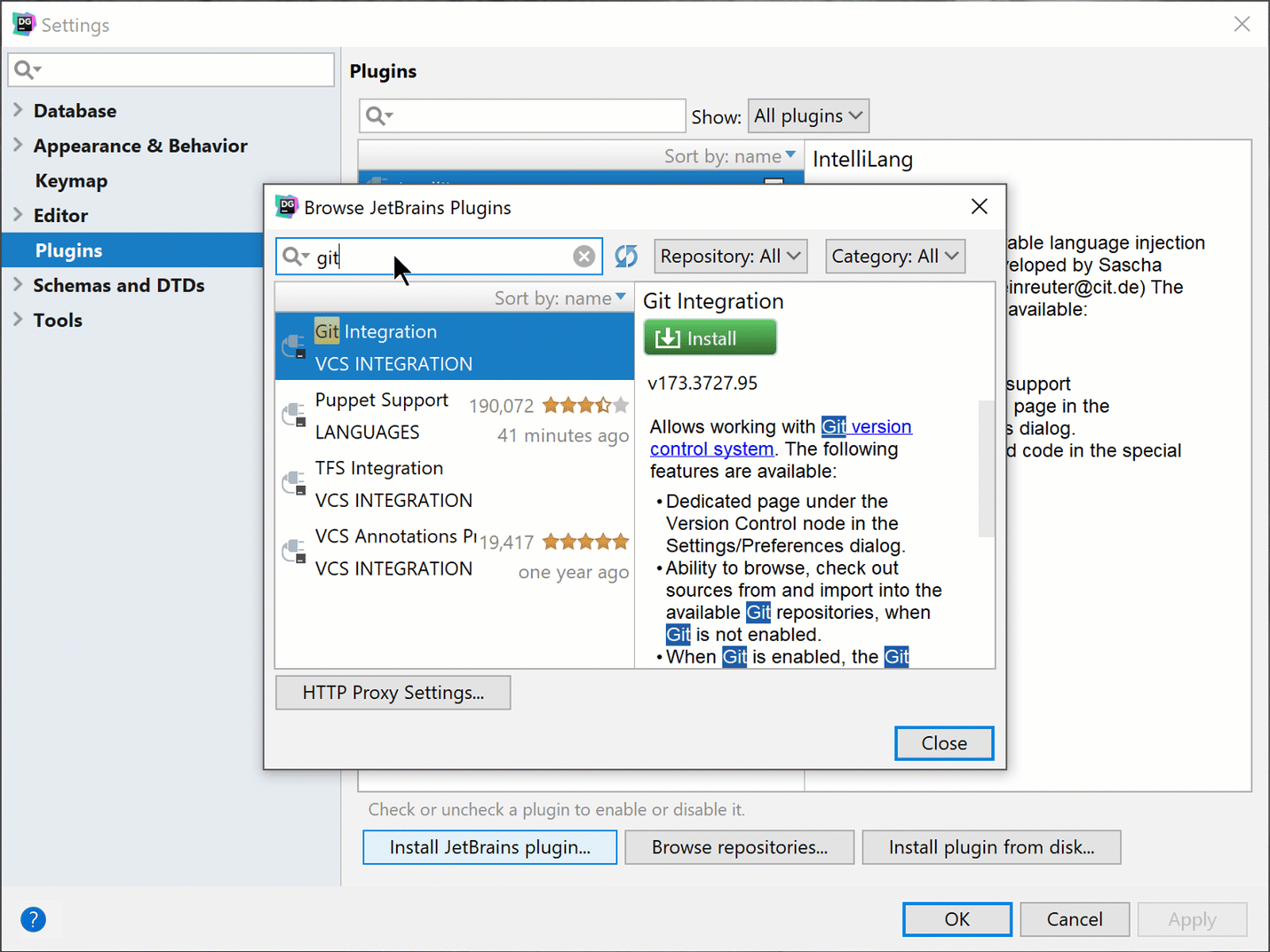
Working with Git in DataGrip
Cloning a Project from GitHub
With the Git plugin installed, you can now clone a remote repository to your local file system. Cloning is a command in Git that copies all the most updated file snapshots that exist on the remote server to the local you specify.
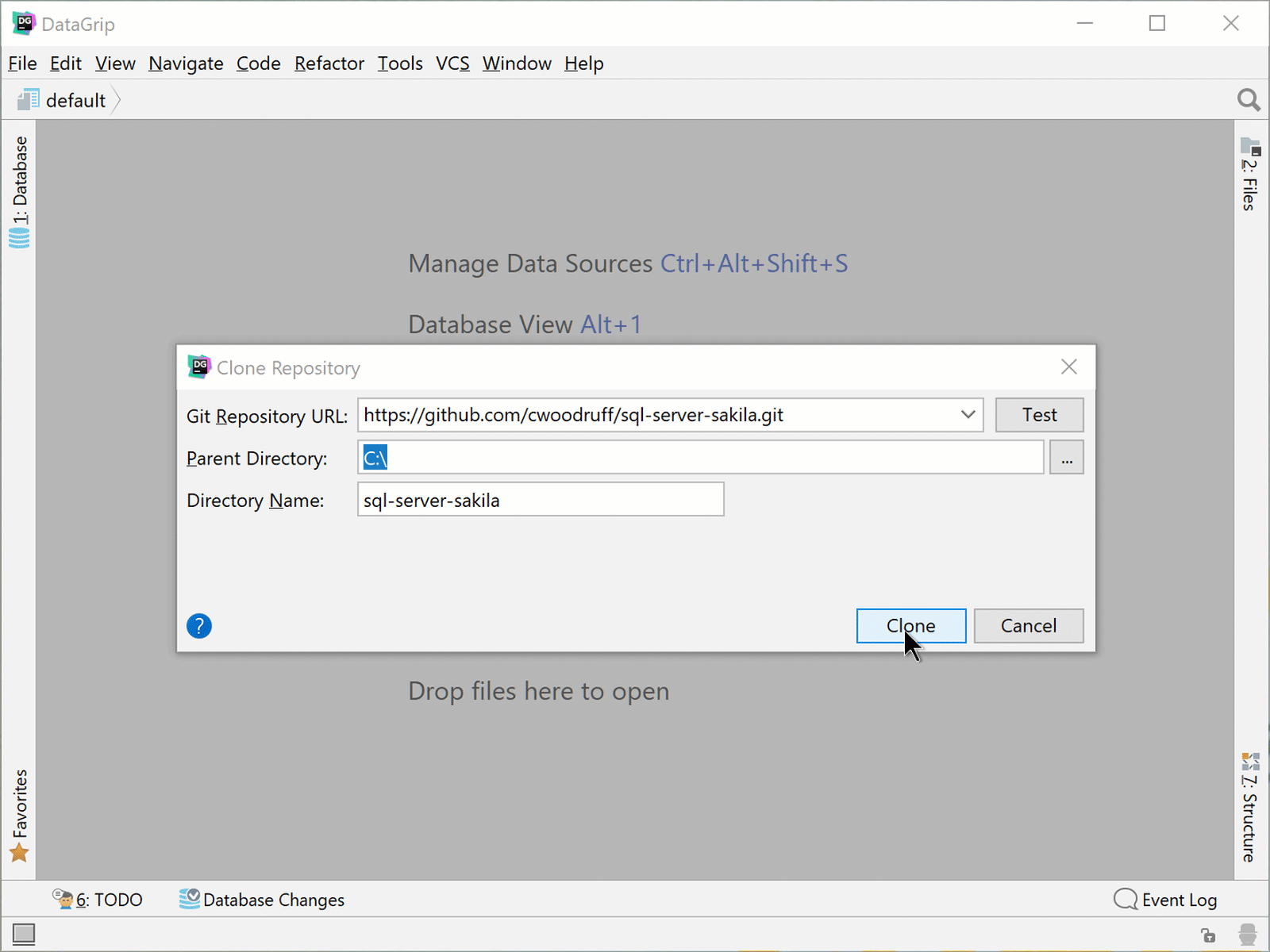
In DataGrip, go to VCS | Checkout from Version Control | Git and you will be presented with the Clone Repository dialog.
For this example, we will clone the following Git Repository URL from GitHub to a local folder of your choosing (Parent Directory).
https://github.com/cwoodruff/sql-server-sakila.git
GitHub is a Web-based Git version control repository hosting service. It is used for software code and other files such as database scripts we are showing with DataGrip. It offers all of the distributed version control and source code management functionality of Git. To learn more about GitHub and/or to sign up for a free account, go to GitHub.com.
After cloning, the files that were copied to your local filesystem will be present in DataGrip’s File Tool Window.
Modifying a Database Script and adding a new file to the project
For the purpose of showing how we save changes to files stored in our local Git repository and also how new files are added, we will modify the schema file that was cloned from the remote repository and also add a new *.sql script for a stored procedure that was added to the MSSQL database project.
Replace line 16 (“use sakila”) in the sql-server-sakila-schema.sql file with the following:
IF DB_ID (N'sakila')IS NOT NULL DROP DATABASE sakila; GO CREATE DATABASE sakila; GO USE sakila; GO
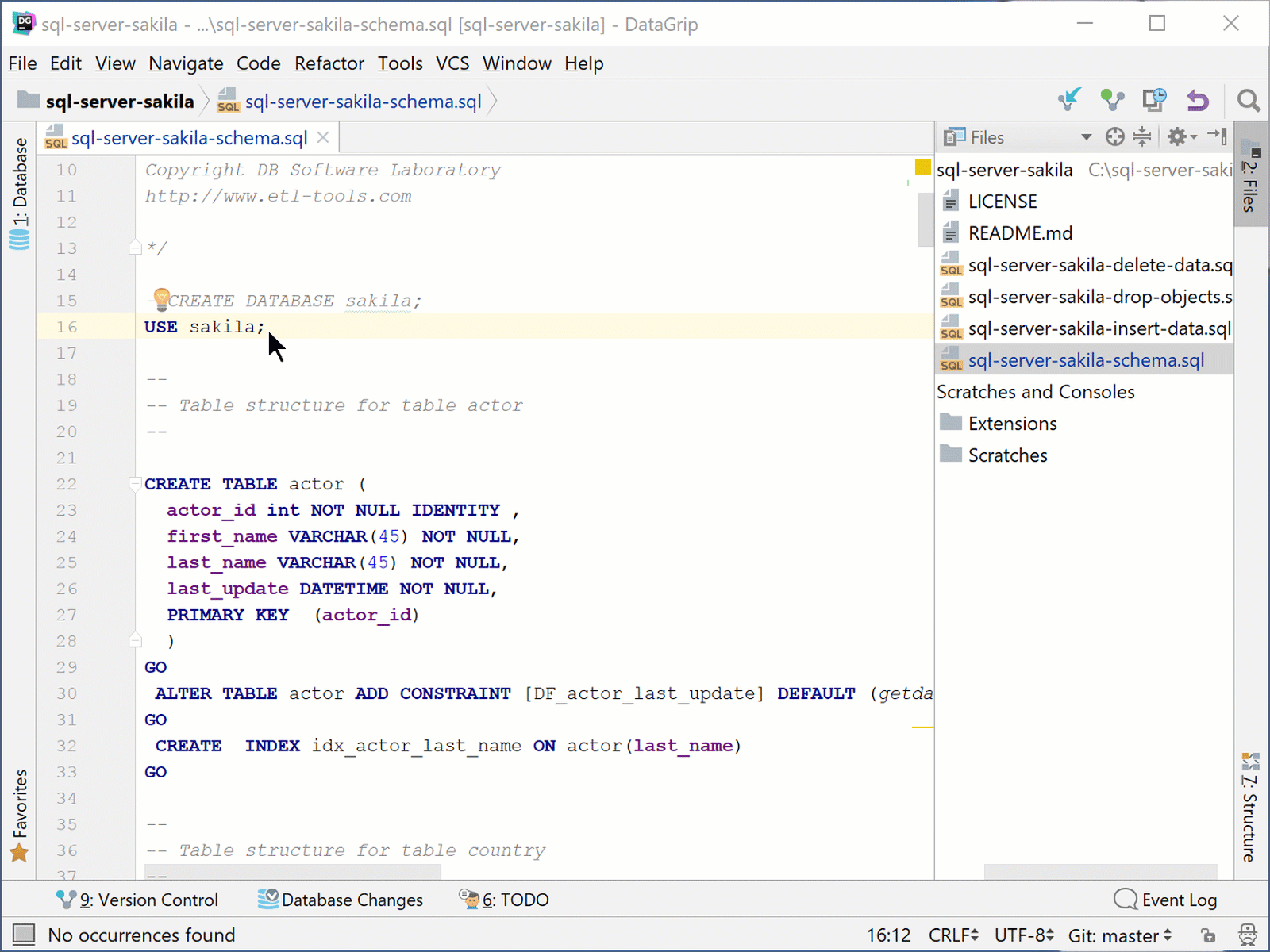
Next, add a new file called sql-server-sakila-spInsertActor.sql to the project with the following code:
USE sakila;
GO
CREATE PROCEDURE dbo.spInsertActor
@first_name VARCHAR(45),
@last_name VARCHAR(45)
AS
SET NOCOUNT ON;
INSERT INTO dbo.actor (first_name, last_name)
VALUES (@first_name, @last_name);
GO
You now have your 2 file changes that we will commit locally and push to the remote repository.
Committing code changes to Local Git
You will now commit the 2 changes (along with your .idea folder and files) to your local Git repository. Go to VCS | Commit… and open the Commit Changes dialog. You will need to select the Unversioned Files to have the new stored procedure and .idea folder committed.
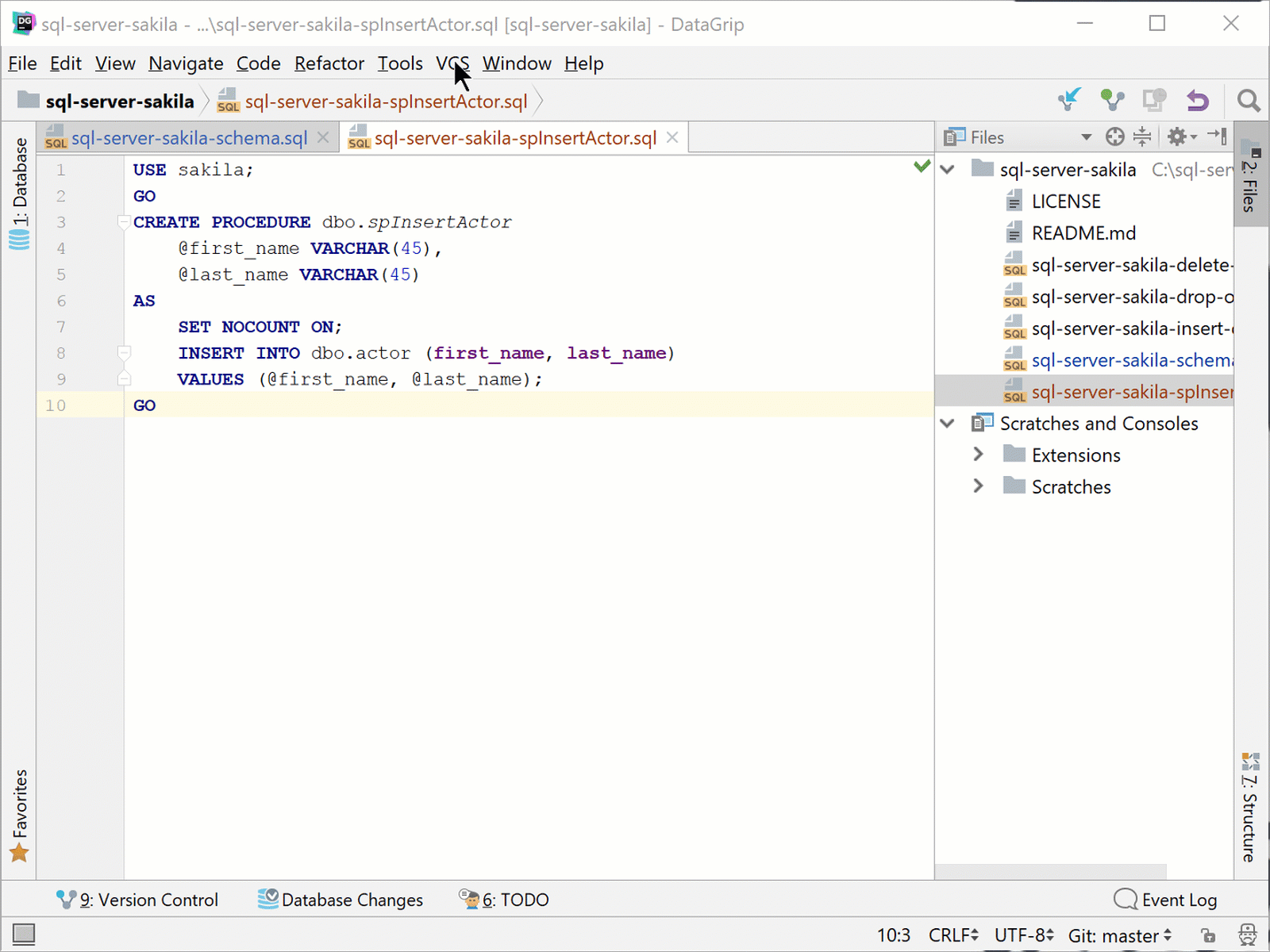
It is a good idea and required that you have a short concise commit message that gets logged with your commit. A good rule is just one sentence that clearly states what and why you did the commit. I will give a commit message of the following: “Added sproc spInsertActor, updated schema, and .idea folder and files”.
Press Commit and your files will be saved to your local repository and will be ready to be saved or pushed to the remote repository. If DataGrip finds any issues before committing due to the analysis it runs on the code, you will be prompted with a message and the commit will not be performed.
Pushing Commits to Remote Git on GitHub
Now that the commit has been processed and DataGrip did not prompt any errors or warnings, we can look at pushing the commit to the remote Git server. Push is the term that Git uses when the user saves all local commits remotely. In our example, the remote git server resides on GitHub.
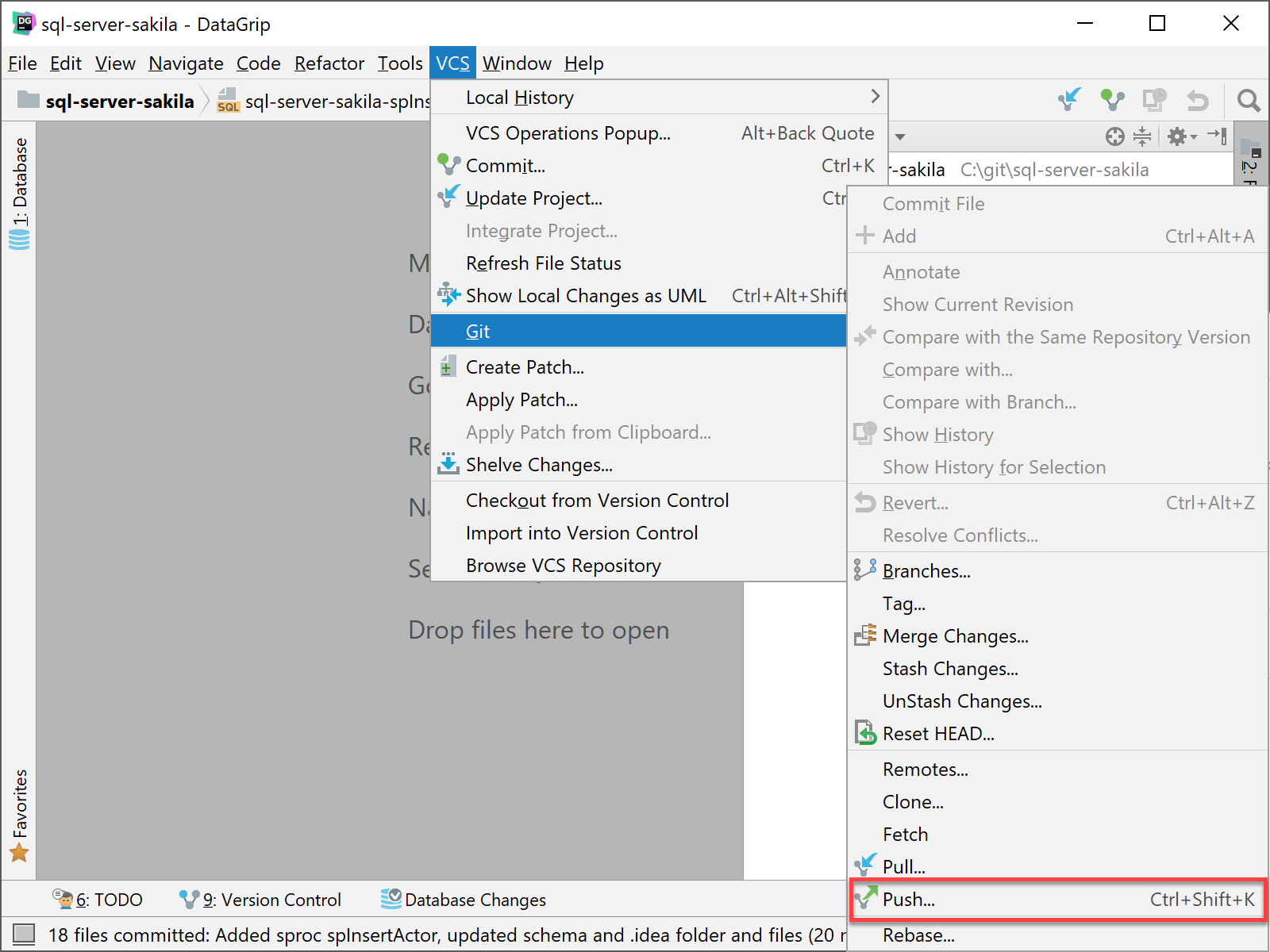
We will push our commit to GitHub by selecting VCS | Git | Push…
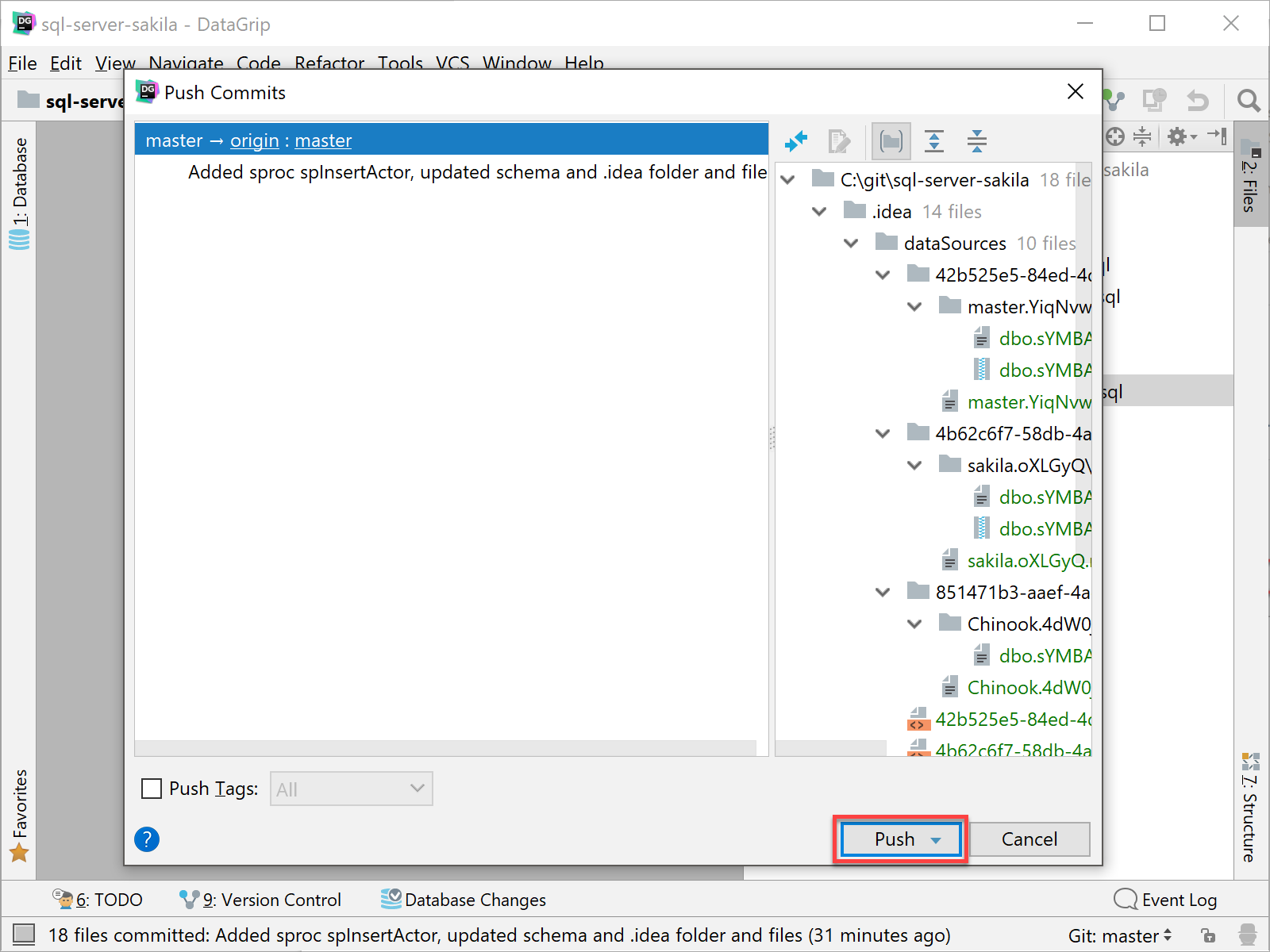
A Push Dialog will appear. The dialog will show the commits and commit details so you can review everything before doing the push to the remote Git servers at GitHub.
DataGrip may prompt you at this point for your GitHub.com credentials before allowing your commit(s) to be pushed. If you were pushing your commits to another remote Git server, you may be prompted for login information as needed.
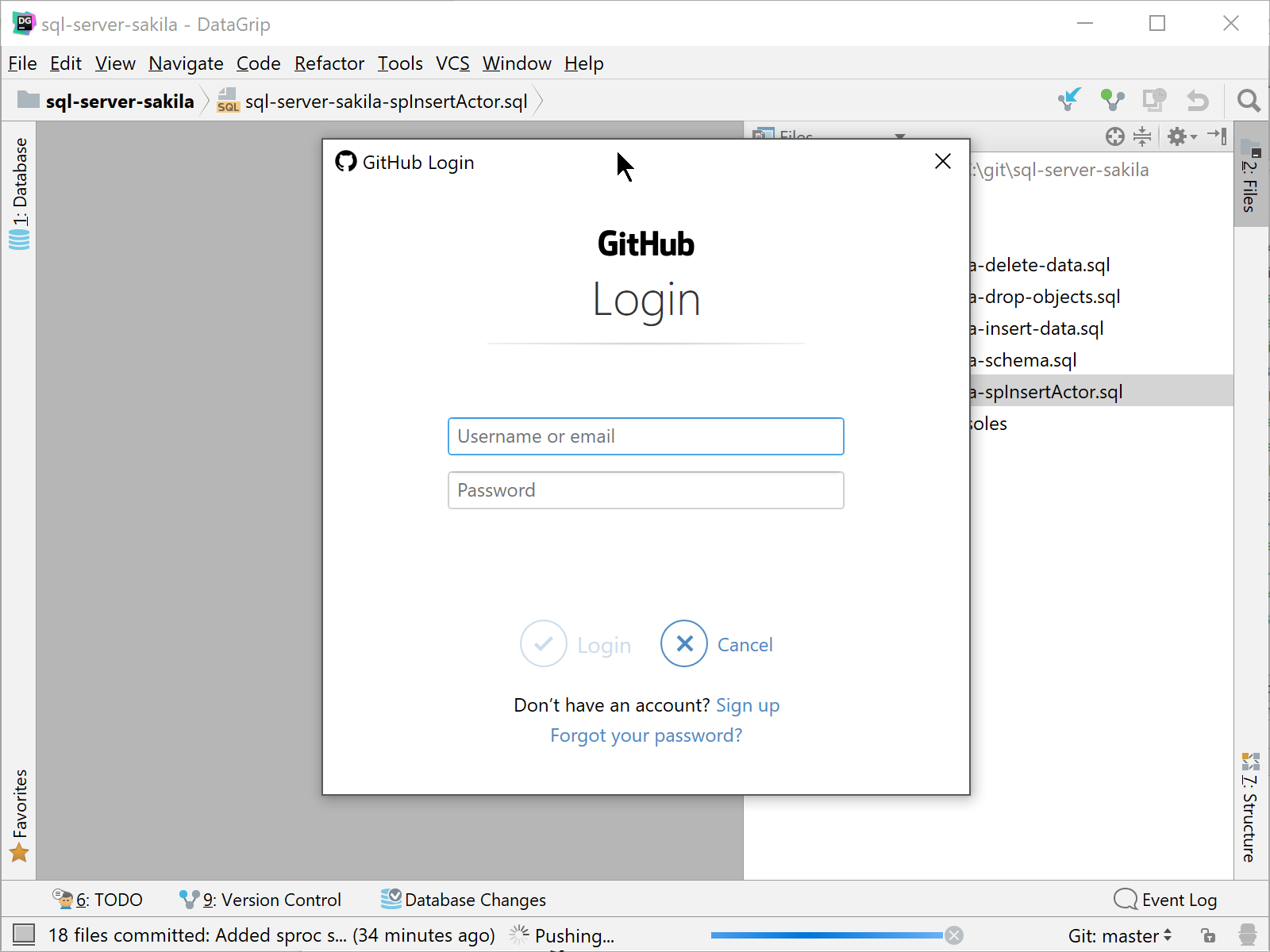
Pulling Changes from Others with Git
Since you can push your changes to the remote Git server to store those changes in the remote repository, it makes sense that there should be a way to get others’ commits from the remote repositories. That is the next feature of Git we will explore, the Pull.
Pulling from Git is very similar to pushing, but the flow and analysis works from the remote to the local. When the pull happens, Git and possibly DataGrip will analyze the code being brought back from the remote servers and detect any issues before saving those files to the local filesystem. A common complaint from Git might be pulling code when you have commits locally that have not been pushed to the remote repository.
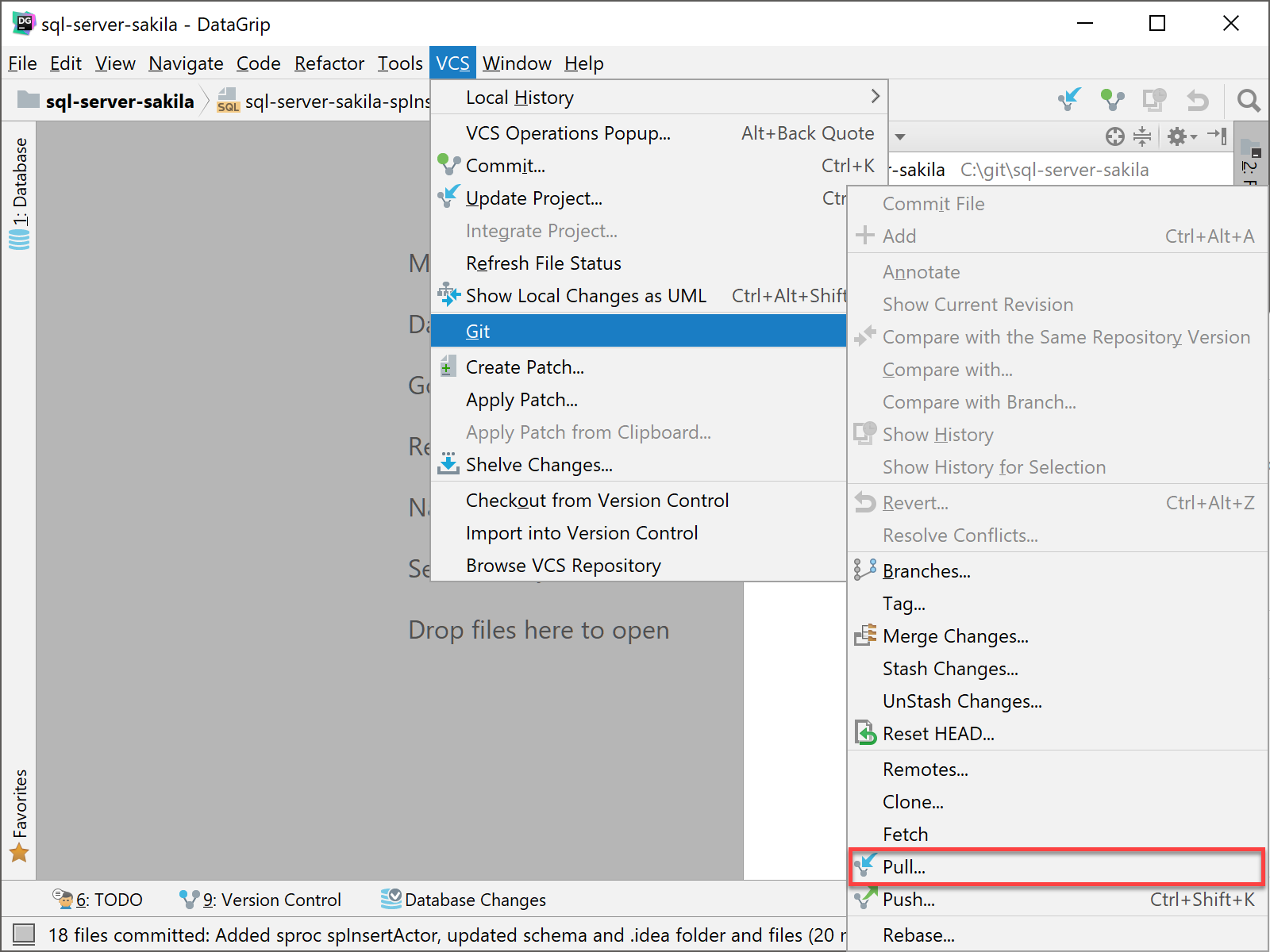
Your coworker has updated a file or files in the remote GitHub repository for the project you are working with currently. You need to get those changes to have a complete up-to-date database environment and also to make sure you have the current scripts for testing. To get all updates from others, including your coworker, you will go in DataGrip to VCS | Git | Pull.
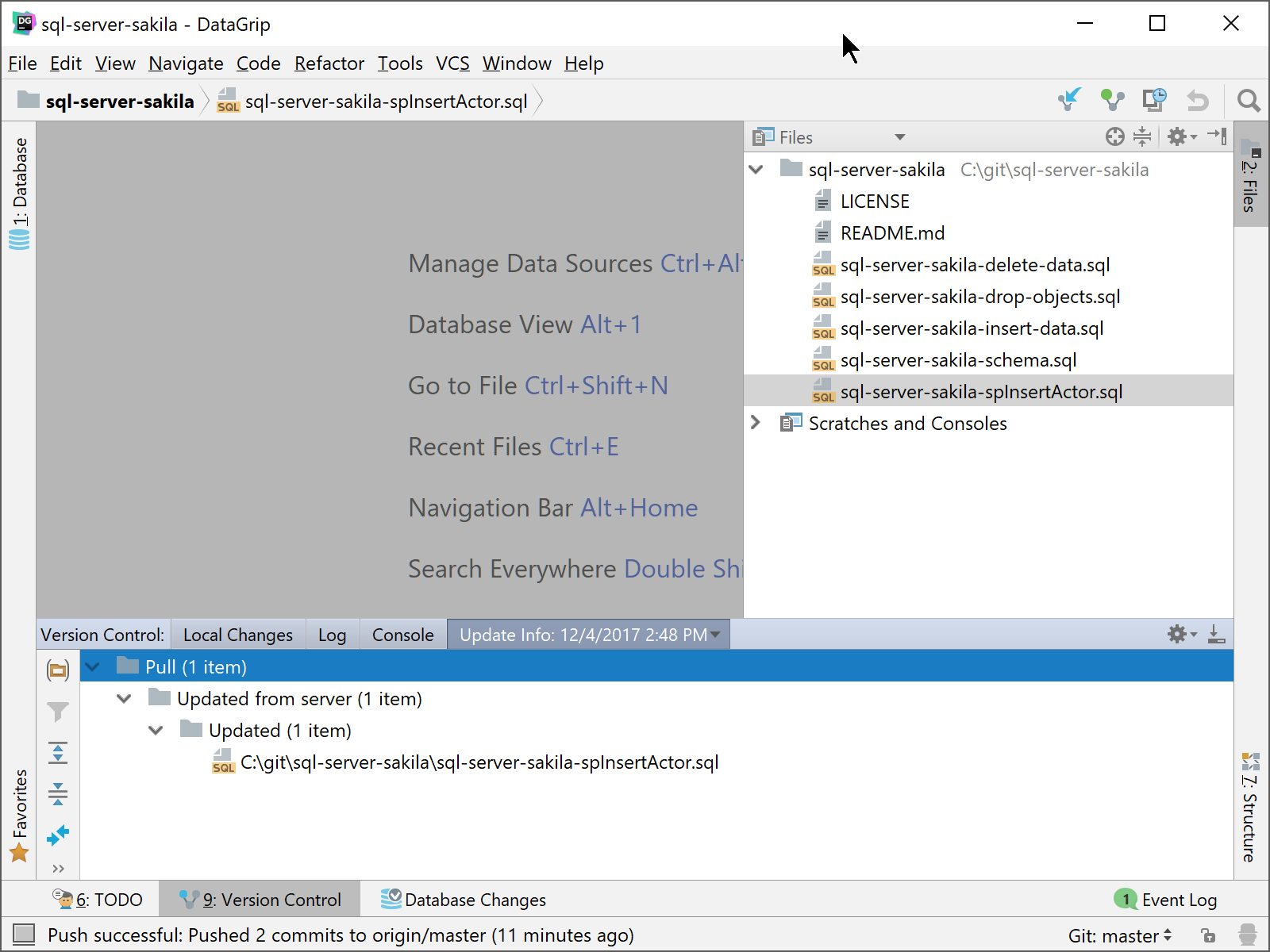
After the pull is performed and no errors have been found, you will get the results of your pull. Here is an example of what results you would get from having your sql-server-sakila-spInsertActor.sql file updated by your coworker and pushed to GitHub.
You can now work with the updated files and continue with your work.
Creating a Branch with Git
Now that you know how to commit, push and pull using Git, we will look at one final feature called Branching. A branch in Git is a local and remote snapshot of code files you can encapsulate your work. Maybe you are creating a new feature and you need to keep it isolated from other work you or others are doing. You can work and commit your updates to your branch and then push your commits to the remote repository as your branch can also exist there. When you are done with your branch and need to get the code into the main area of the repository, you will then perform a merge locally and push that merge to the remote side.
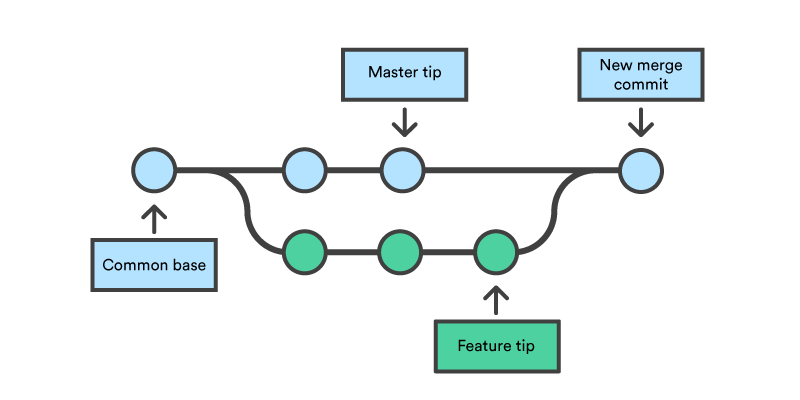
Let’s look at a diagram that shows the workflow of a git branch and merge. You will see the point where the branch is created from the master branch (Common base). The green points along the workflow show the commits that have occurred during the branch lifetime along with the blue commits that happened at the same time from others. In the end, we will have common merged code after a git merge has been performed (New merge commit).
In DataGrip, we can create a new branch by going to VCS | Git | Branches…
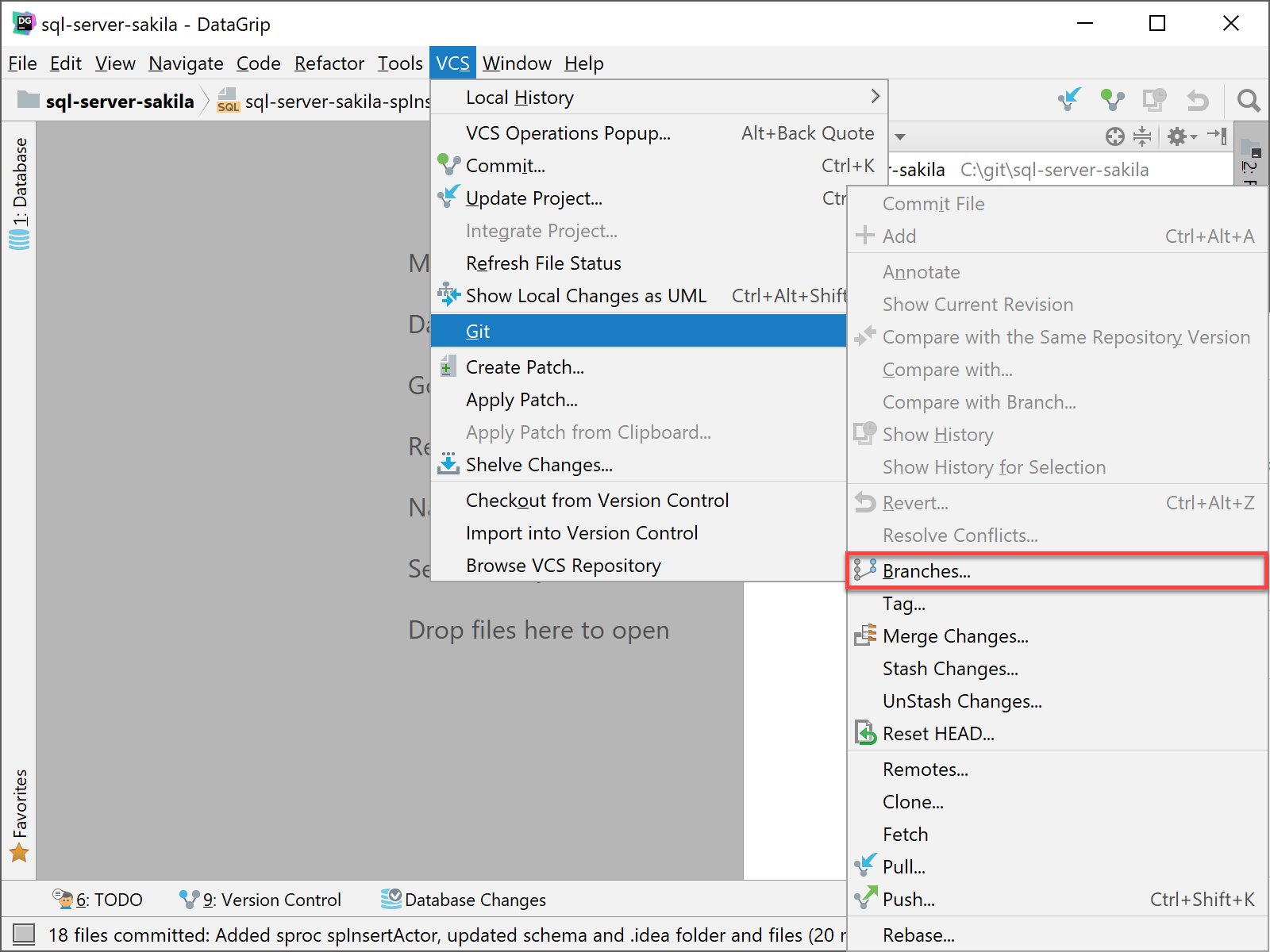
You will then get the Git Branches dialog that will allow you to create a new branch. You can also detect and access other local and remote branches, but that is beyond the scope of this tutorial.
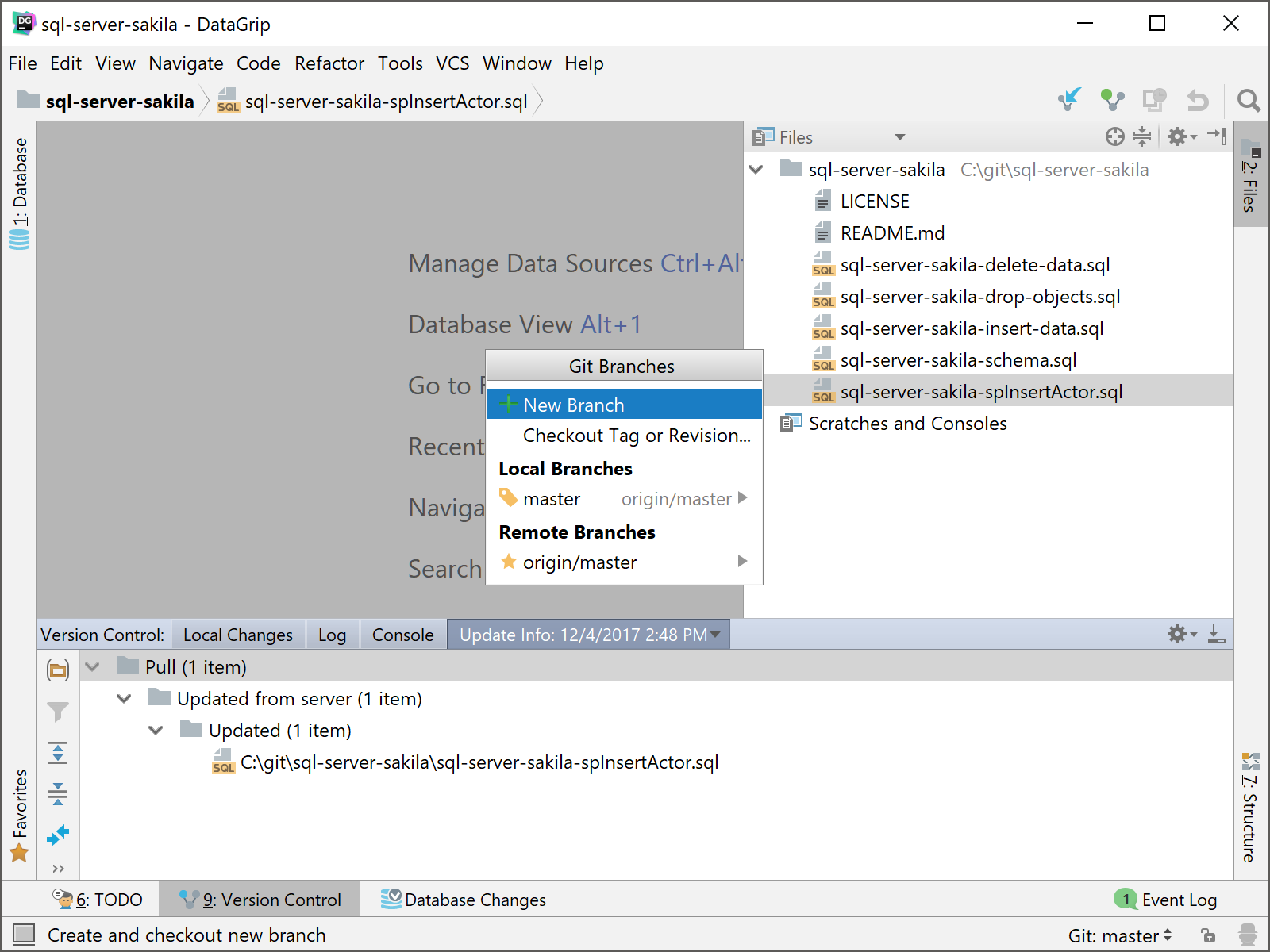
After you create your branch, you will see the name of the branch at the bottom right in DataGrip’s bottom status bar. This is where you can also create branches or see what other branches are available to you on your local filesystem. The great thing about Git is you can have more than one branch locally (just make sure not to confuse them). I created a new branch call Test as you can see below.
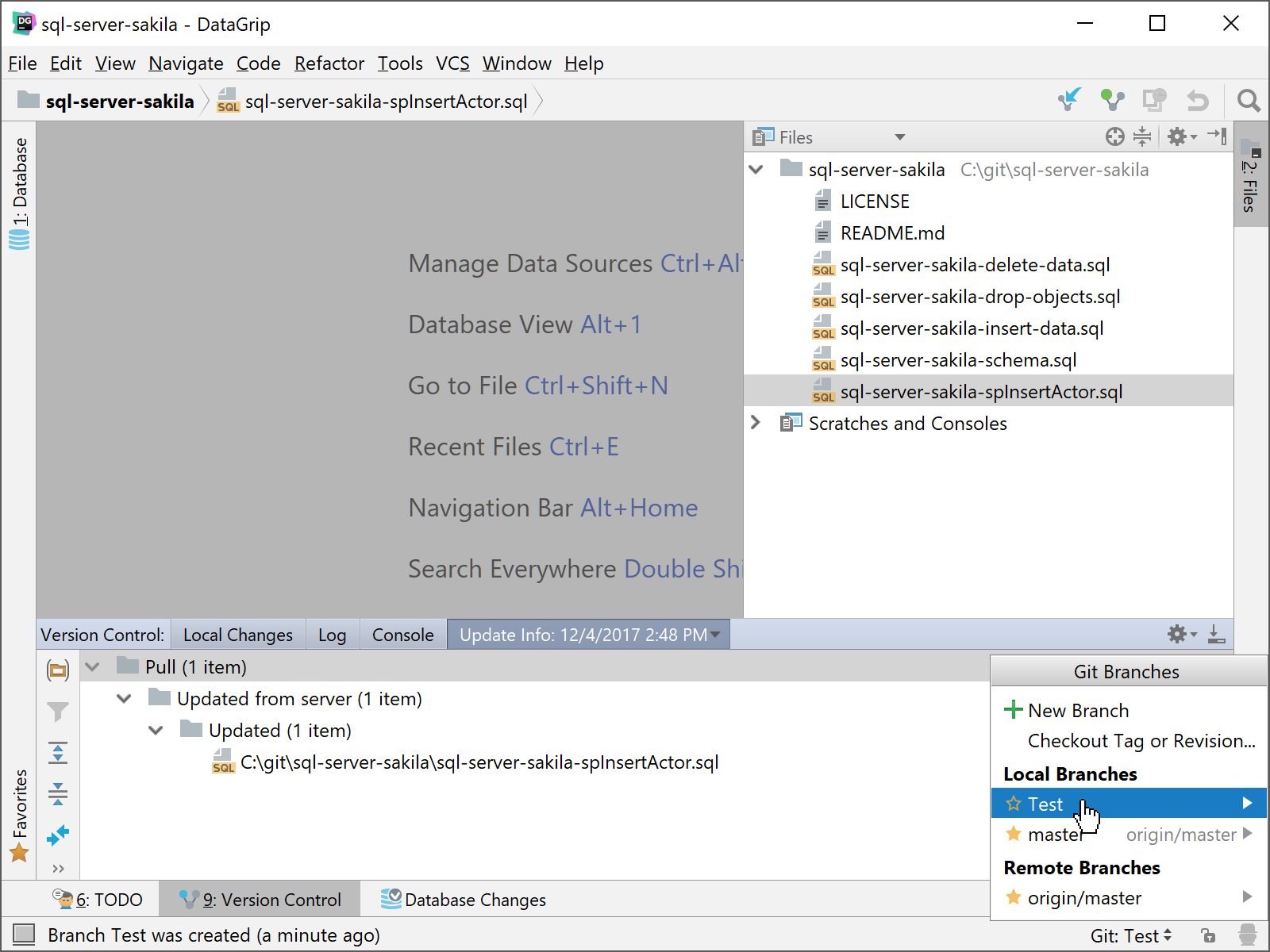
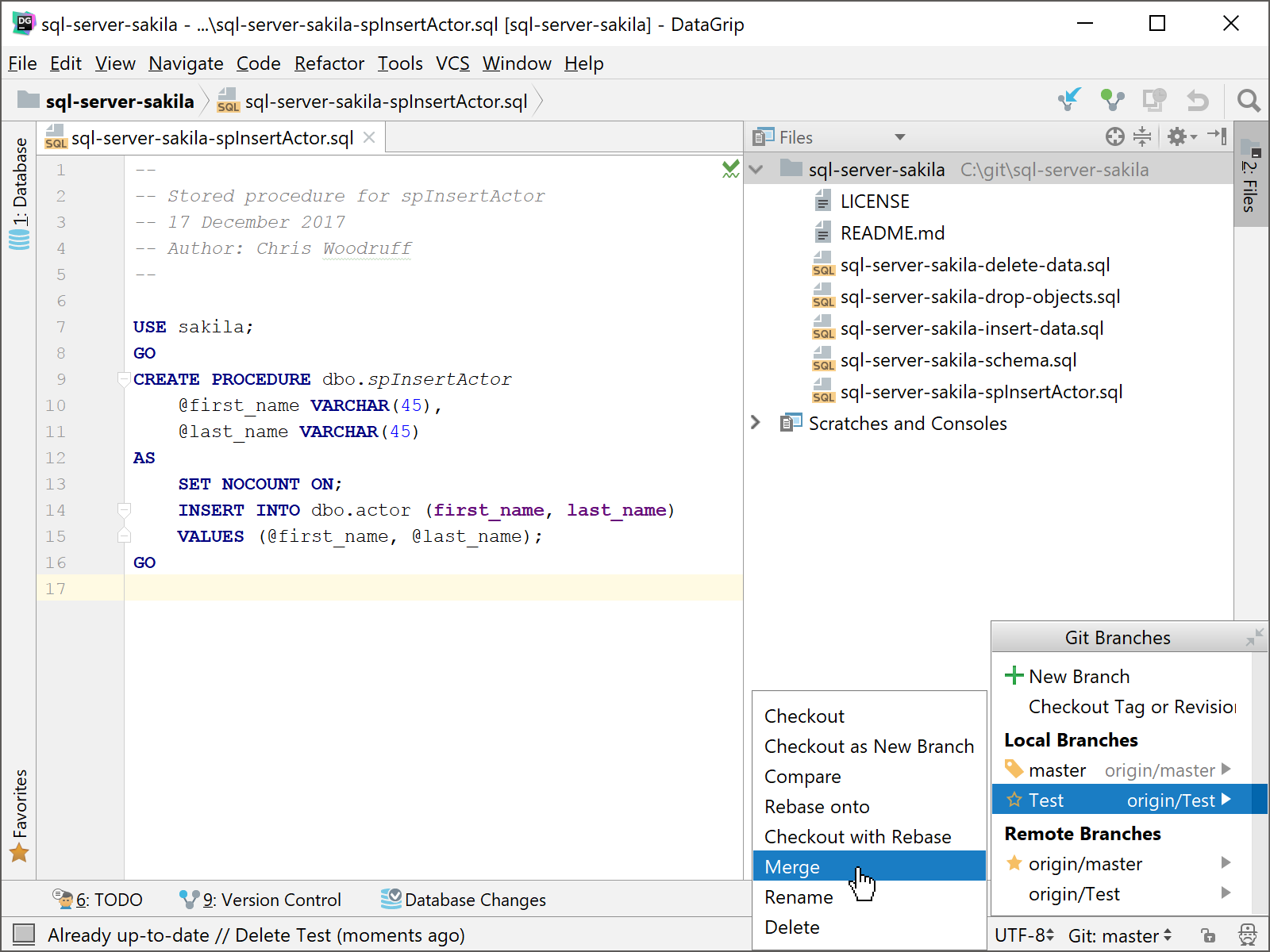
After you have committed and pushed your changes to the branch, tested that your changes meet your requirements and finally need to be merged back into the master branch, you will need to go to the branch you want the Test branch merged with. In this case, it is the Master branch.
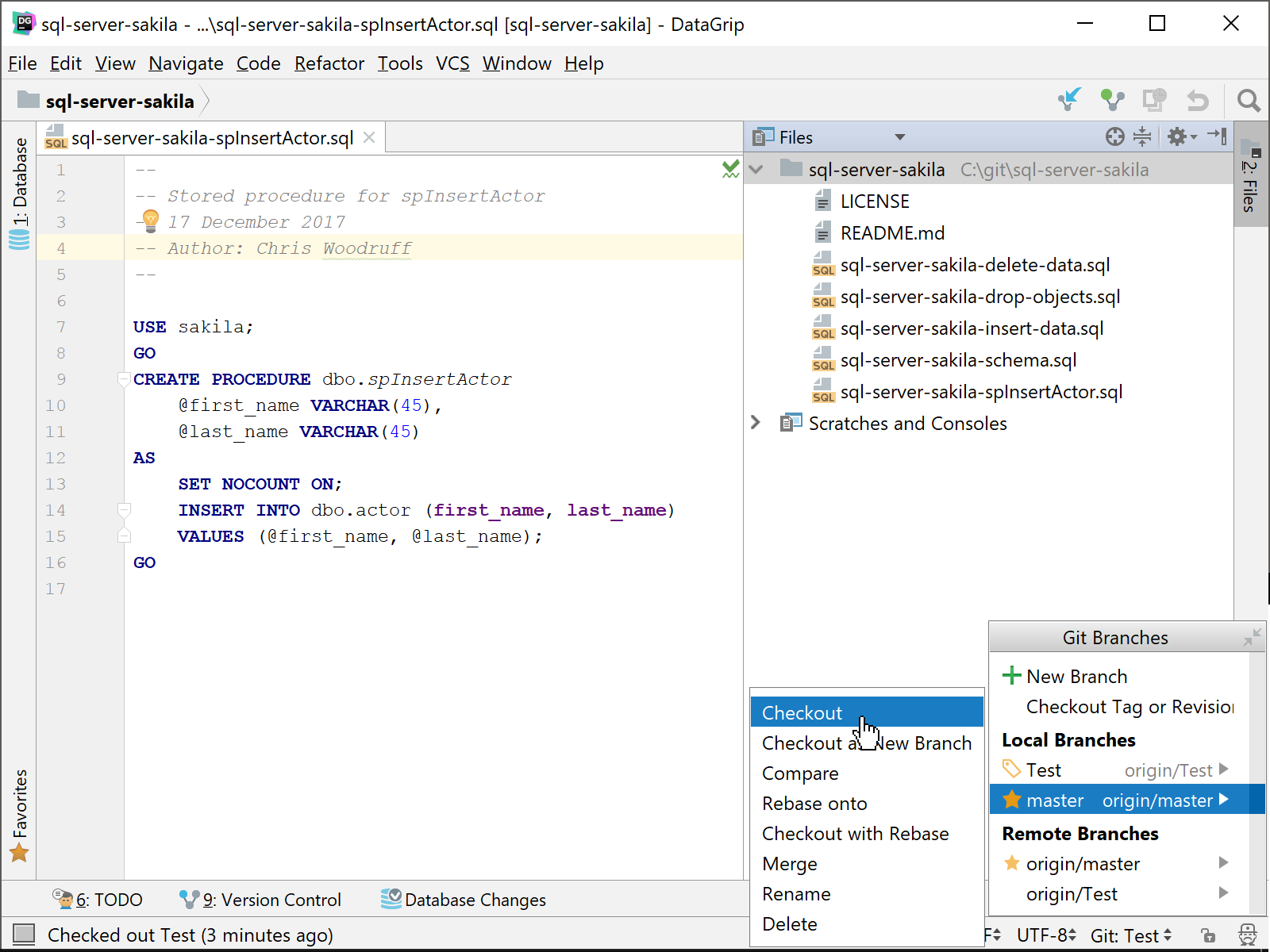
Once you check out the Master branch and make it the current branch, you will then need to merge the Test branch into it. The best way is to select the Master branch again and then Merge. This will merge the only other branch currently in your local repository which is the Test branch. DataGrip will prompt you if you want to delete the Test branch after you have merged it into the Master branch. It will be safe to allow DataGrip to delete the branch since we will not have any use for it after the merge.
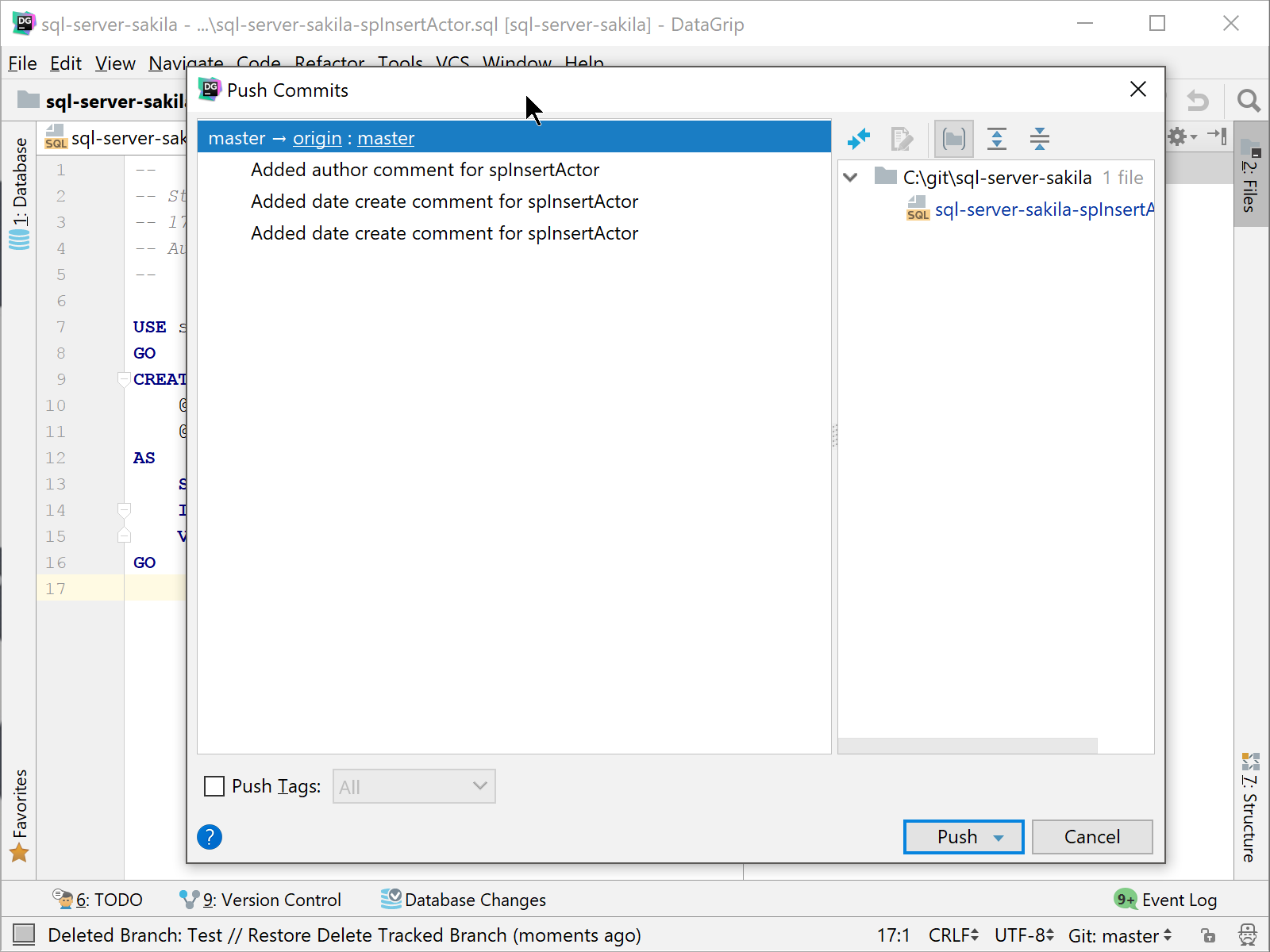
At this point, you need to push the changes that now are in the Master branch back to the remote repository. Perform a Push on the Master branch, and your work that started in the Test branch that was merged locally to the Master branch will now reside in the remote Master branch in GitHub.
Branching can be tricky, so please pay attention to what you are doing. It would be wise to create local and remote repositories (with GitHub hosting the remote) and experimenting with Git branches. To learn more about branching, go to the Git docs on Git Branching – Basic Branching and Merging.
Wrap Up
All code – no matter if it is C# files for an ASP.NET Core project, JavaScript files for a React/Redux application, or SQL scripts for a database – should be stored and tracked using a version control system. As you have learned in this tutorial, Git is a powerful distributed version control system that will allow not only you as a database professional to organize, track, and work with branches, but will also allow your entire team to do the same because of the remote Git repositories that go along with your local repositories.
Download the latest DataGrip and try it out! We’d love to hear your thoughts and feedback!
To learn more about Git with all the JetBrains IDEs, watch the YouTube series covering Git Questions.







