

Nextсloud Performance Hacks with EverSQL and DataGrip

Hi, I’m Pasha. In my everyday life, I’m a Developer Advocate for data engineering, but by night, I’m a geek. Like, a really geeky geek! I have used Linux since 2009 as my primary OS (BTW I use Arch). If possible, I always prefer to host everything I use. So if you decide to drop me an email at me@asm0dey.site, rest assured, I’ll receive it on my self-hosted mail server. While self-hosting certainly has its benefits, it does have some downsides, like poorer performance, that should be addressed.
This is the story of how I “fought” with self-hosted MySQL to get better database performance.
Nextcloud
Frankly, I don’t like Dropbox. For myself and a couple of friends, I self-host Nextcloud, an alternative to Dropbox. Nextcloud is much more powerful, featuring a vast assortment of supported plugins, which the Nextcloud people refer to as “applications”. It has an application for to-do lists, an application for creating polls, and an application for having Google-like Memories and whatnot. It’s written in PHP and (more importantly) uses MySQL as a database.
How many tables could there be in such an application? If I didn’t know any better, I’d say something like “two: users and files”. However, there are also some maintenance and versioning routines, so you probably also have to account for tasks, versions, preferences, and so on. Here’s what it looks like in reality:

No joke – there are a whopping 199 tables! They mostly don’t have references between them. I think this is a legacy of MyISAM, which didn’t support references at all. By the way, if you know the actual references, you can create them right inside DataGrip with the Create virtual reference action.
What are all those tables? For example, here is everything related to files:
After careful consideration, we understand why it works this way. File locks are needed should one file be changed from different locations.
Trash, for example, is also just pure metadata when you think about it – it has a different physical location from anything else in the store, and it should be possible to clean the trash entirely, partially, or maybe even recover it!
Here’s what the trash table looks like:
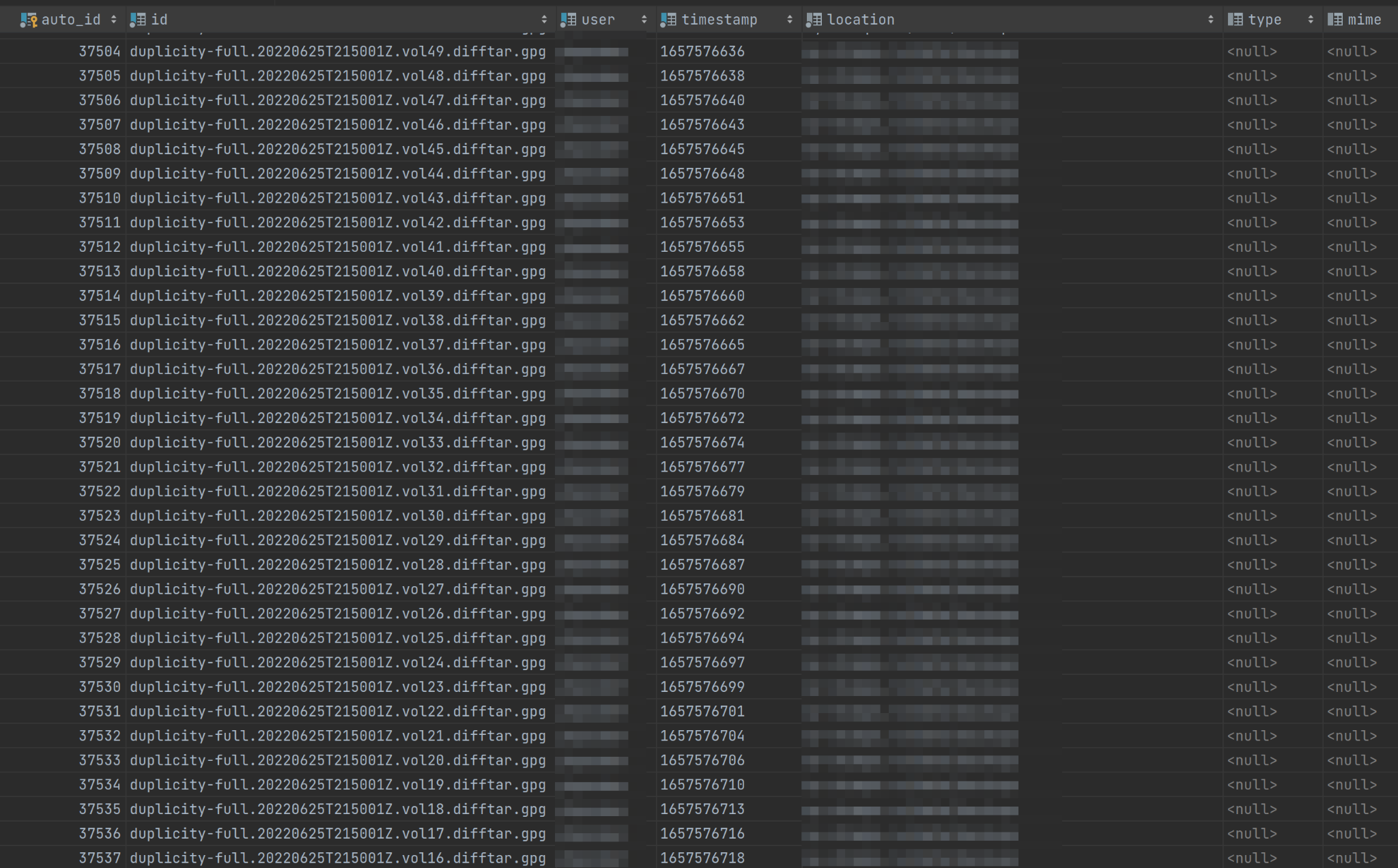
Hopefully, this image alone gives you an idea of how enormous the whole thing is. And since I’m hosting it myself, I’m solely responsible for its performance. This is usually a good thing because I can learn a lot and help a lot of people (after all, knowledge is what makes me a good Developer Advocate). But on the other hand, it means there’s a lot of pressure on me! What if the performance becomes so poor that the server starts failing the people who rely on it?
If you’re still unsure about the quality of Nextcloud itself, I just want to say that it’s an excellent piece of software! Many people and organizations use it successfully, myself included!
But three weeks ago, I had some bad luck when my instance of Nextcloud became terribly slow. I didn’t know what happened. I didn’t change anything. “Too much data” would be one possible explanation, but I only have 150 GB of data, so what could have gone wrong?
Debugging
The first step I took was connecting to the database of my Nextcloud. Of course, it’s not exposed to the internet, so I needed to use an SSH tunnel to do this, as shown here:
It’s so simple, and the configuration even supports parsing of the `~/.ssh/config` file! Then, I entered my login and password:
I realized the IDE is actually smarter than me: I constantly forget what arguments I should use with SSH to establish an SSH tunnel. I just had to click the “Test connection” link, and:
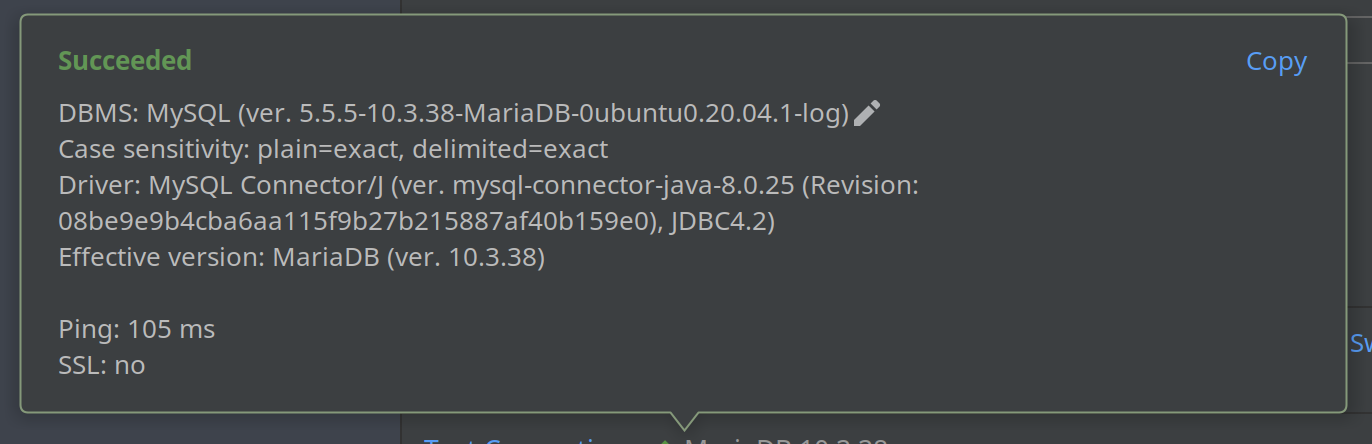
But you know what’s even more impressive? This small notification:

To be honest, I sometimes forget that I use MariaDB, not MySQL. And I didn’t even know that it has its own JDBC driver. You bet I want it!
As a second step, I tried to understand what was causing my instance of Nextcloud to run so slowly. It’s simple in MariaDB – even more straightforward than in Postgres (I’m much more familiar with it than with DBs that resemble MySQL):
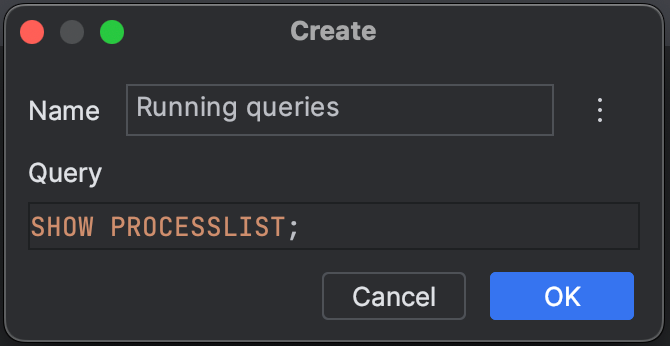
SHOW PROCESSLIST;
Since I would rather not have to memorize vendor-specific clauses, I created a virtual view in DataGrip:
What did I see in the output? Something like:
UPDATE `oc_authtoken` SET `last_activity` = 1680386487 WHERE (`id` = 16684) AND (`last_activity` < 1680386472);
I didn’t have any idea what it meant, and to be honest, I wasn’t sure how to optimize it. I wanted to start by checking indexes.
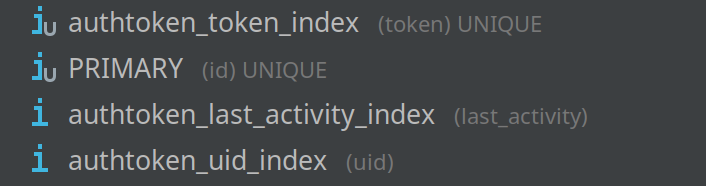
In my fevered imagination, having an index on the ID should make this query instantaneous. And yet, I was looking at this query for almost a minute!
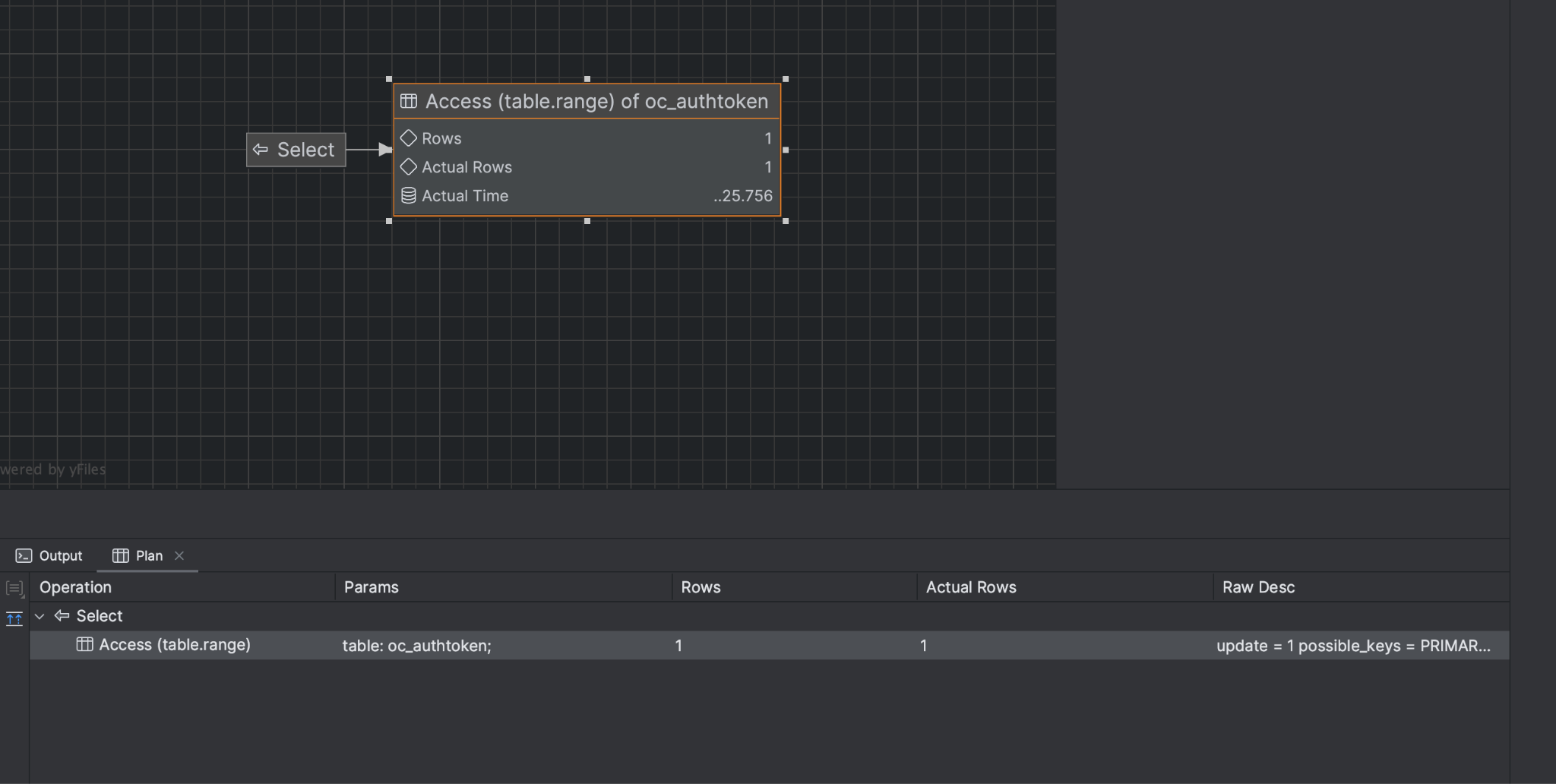
When I realized that this was happening with other queries, too, I started googling. But beyond the obvious “check indexes,” there was almost no information. I then started googling things like “MySQL query optimizer”. Of course, the first few results were about EXPLAIN and ANALYZE, but frankly, they’re alien to me in MySQL. Even the nice visual representation I could see in EXPLAIN didn’t help me much:
But then, a miracle was found. And its name was EverSQL.
EverSQL
EverSQL is a SaaS SQL optimizer for several databases, including MySQL and its flavors, as well as Postgres and its flavors. When I signed up, I got one credit for free. Credits are a virtual currency for “buying” single optimizations. What is required for optimization? Two things:
- The query you want to improve (in my case, it was that UPDATE statement).
- A database description in a special format: EverSQL generates a crazy SQL query that I won’t even paste here. The query produces a huge JSON with the full description of the database: tables, columns, constraints, and indexes. No actual data goes to EverSQL, so you can rest assured that your data is not being shared.
The story wouldn’t be any fun without a few failures, right? Well, I managed to screw up the second step 🤦🏽. I issued that huge SQL query on the wrong console and got a schema for a completely different database. Be careful, do not repeat my mistakes!
But I was brave and lucky, and when the team from EverSQL (the co-founders, no less) dropped me a line and asked if I had been able to solve my optimization question, I didn’t blindly delete the message (as sometimes I do with marketing emails). Instead, I told them my sad story, and they were kind enough to give me several credits in order to experiment with EverSQL. On the second try, I was careful and issued the correct query in the correct DB schema. They even gave me some advice on how to improve my query. I just needed to add a new index. I no longer have the original recommendation, but it was something like this:
CREATE OR REPLACE INDEX oc_authtoken_idx_id_last_activity
ON oc_authtoken (id, last_activity);
While it may seem obvious to those who know what’s going on, it’s still a mystery to me why this recommendation improves anything. However, the following chart tells you everything you need to know:
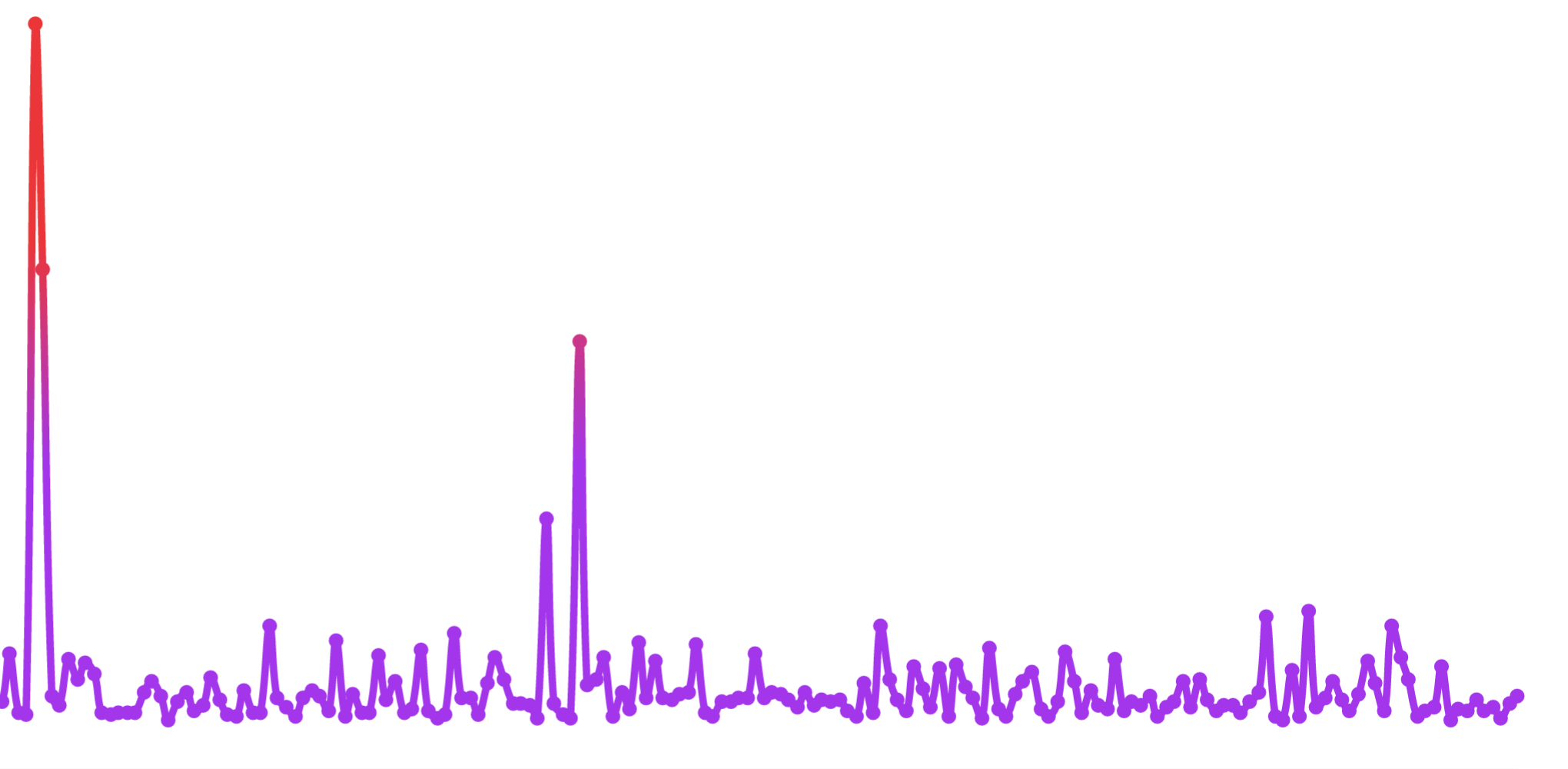
This is the average execution time. We can see that it hasn’t spiked all that much recently, but at one point it was around nine seconds. No amount of indexes could save me if the disk was very busy. It’s also worth noting that, if a lot of slow queries run simultaneously, they can negatively affect each other. So I needed a more systematic approach to improve my database performance.
For the usual code, we should run static analysis tools as frequently as possible to control certain code health metrics. The same goes for databases: We should monitor performance. I usually have some performance monitoring tools installed on my self-hosted applications, but not for MySQL. Well, I could check whether there was sufficient space on my spinning drive and enough memory. But that was definitely not enough.
This is where the second exciting feature of EverSQL came into play: sensors!
EverSQL sensors
A sensor is a small, non-intrusive daemon that monitors slow log, CPU, and additional external signals. Basically, the installation consisted of only two steps:
- Changing the MySQL settings to publish a slow log to a particular destination, as described here.
- Installing the sensor (that is just a Python file) to a specific location.
After that, the sensor sent all the slow queries to EverSQL’s servers so that they could analyze patterns and find bottlenecks. After a couple of weeks of reporting and some optimizations, the resulting dashboard looked like this:
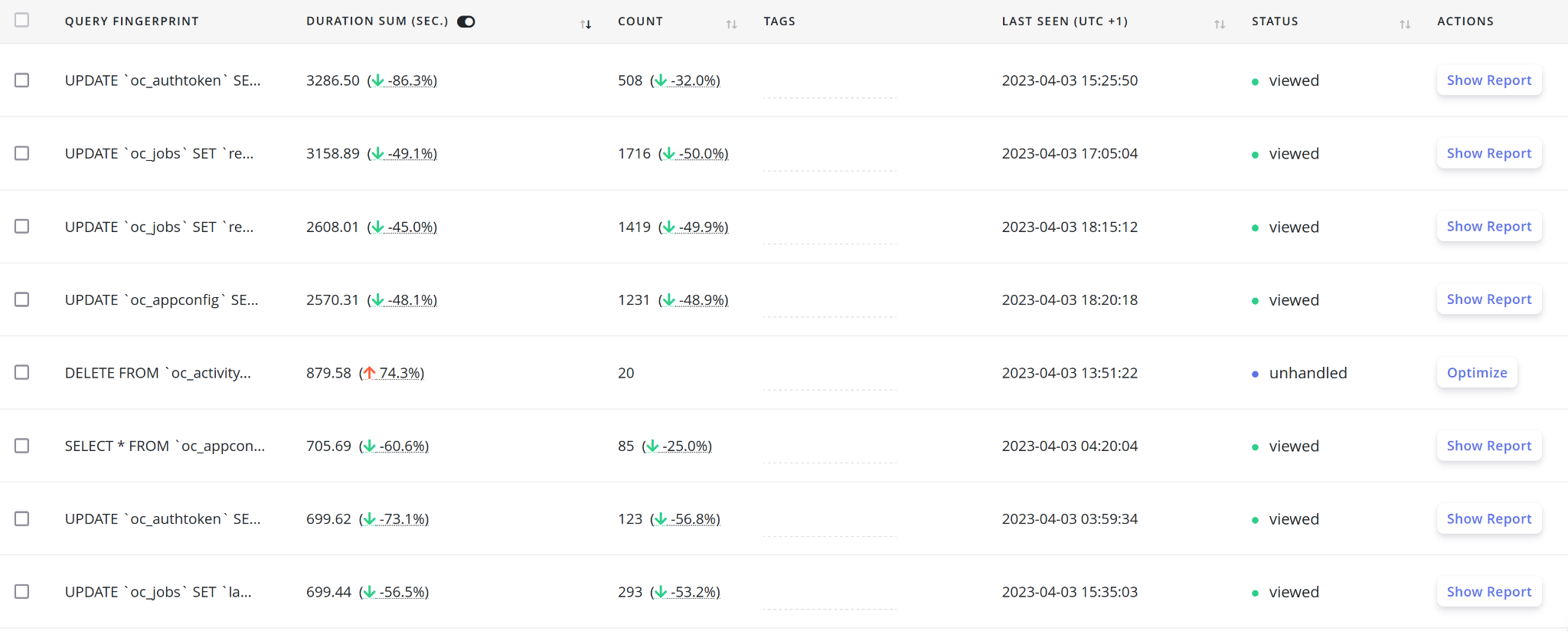
Do you see the improvement basically everywhere? Hopefully, it’s the result of adding approximately 8 indexes recommended by EverSQL. Some optimizations appeared later than others, so don’t waste all your credits on the first day!
Then, after about a week of work, something even more interesting appeared on the dashboard!
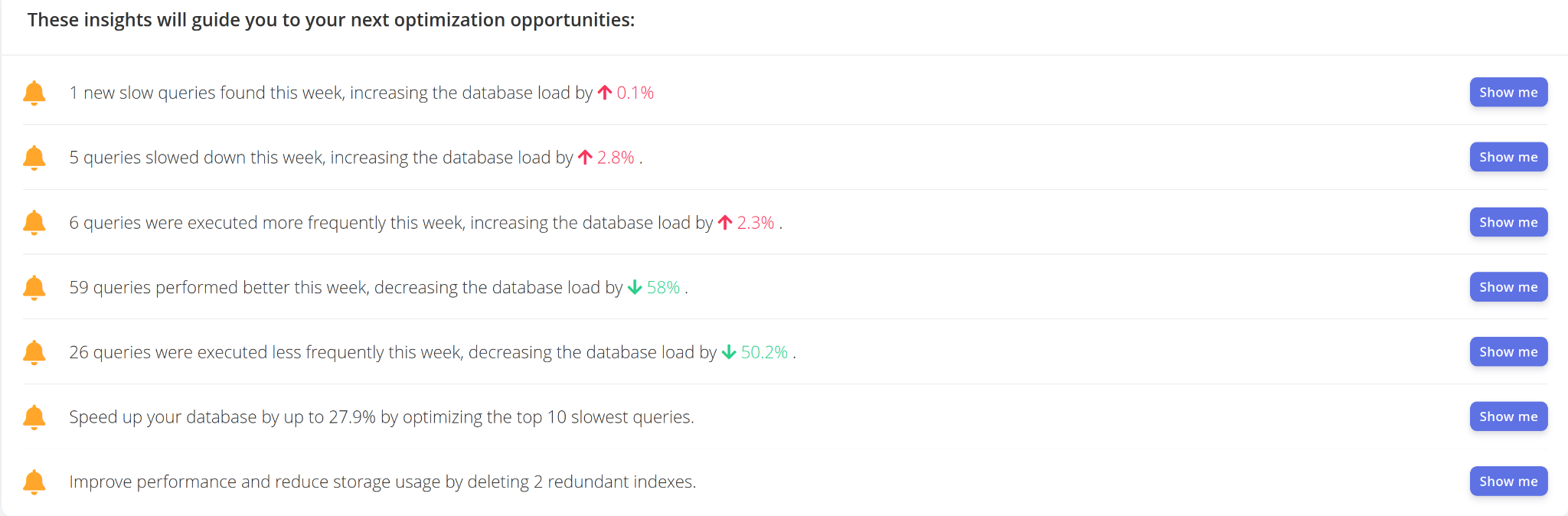
Every “Show me” button turned on a filter on the dashboard. Yes, it recommended not only adding indexes but also deleting some, like these:

I also had to click this checkbox in the settings:

That’s because I don’t actually manage the code of Nextcloud. Otherwise, I would have probably gotten even more recommendations on how to tune my queries to make the database perform even better.
But what if you’re writing the code and want it optimized? We’ve got a solution for you. There is an EverSQL plugin for our IDEs!
EverSQL plugin for JetBrains IDEs
The actual name of the plugin is “SQL Optimizer, Indexing Advisor, MySQL, PostgreSQL, by EverSQL”. It is compatible with the whole spectrum of our IDEs, which is a smart move, since people work with supported databases from almost every language.
Here is what it looks like in Marketplace:
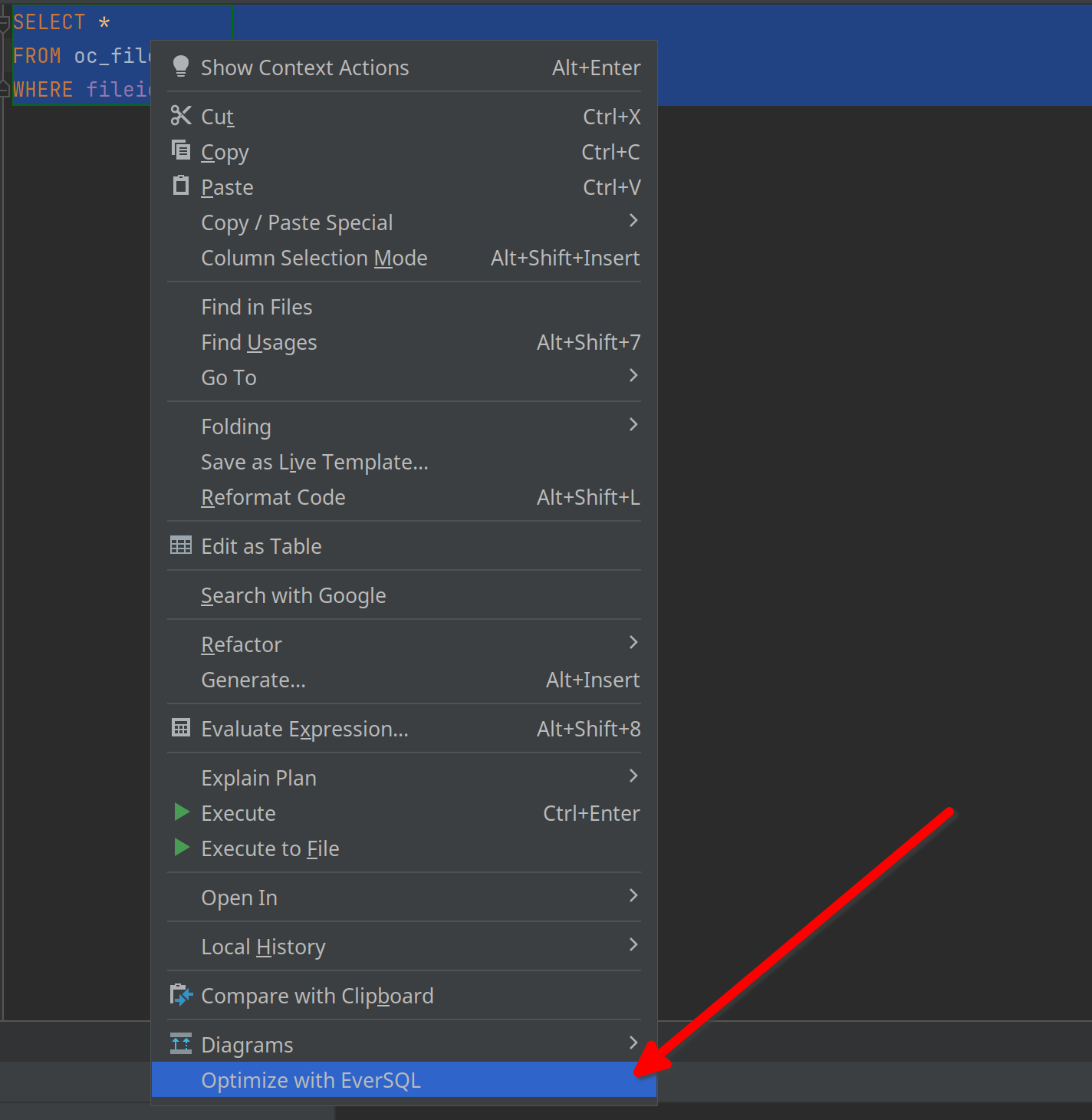
Its working principle is straightforward: Just type your query, select it, and in the context menu, choose “Optimize”.
After that, you will be taken to the same interface of EverSQL in your browser with a dialog like this:
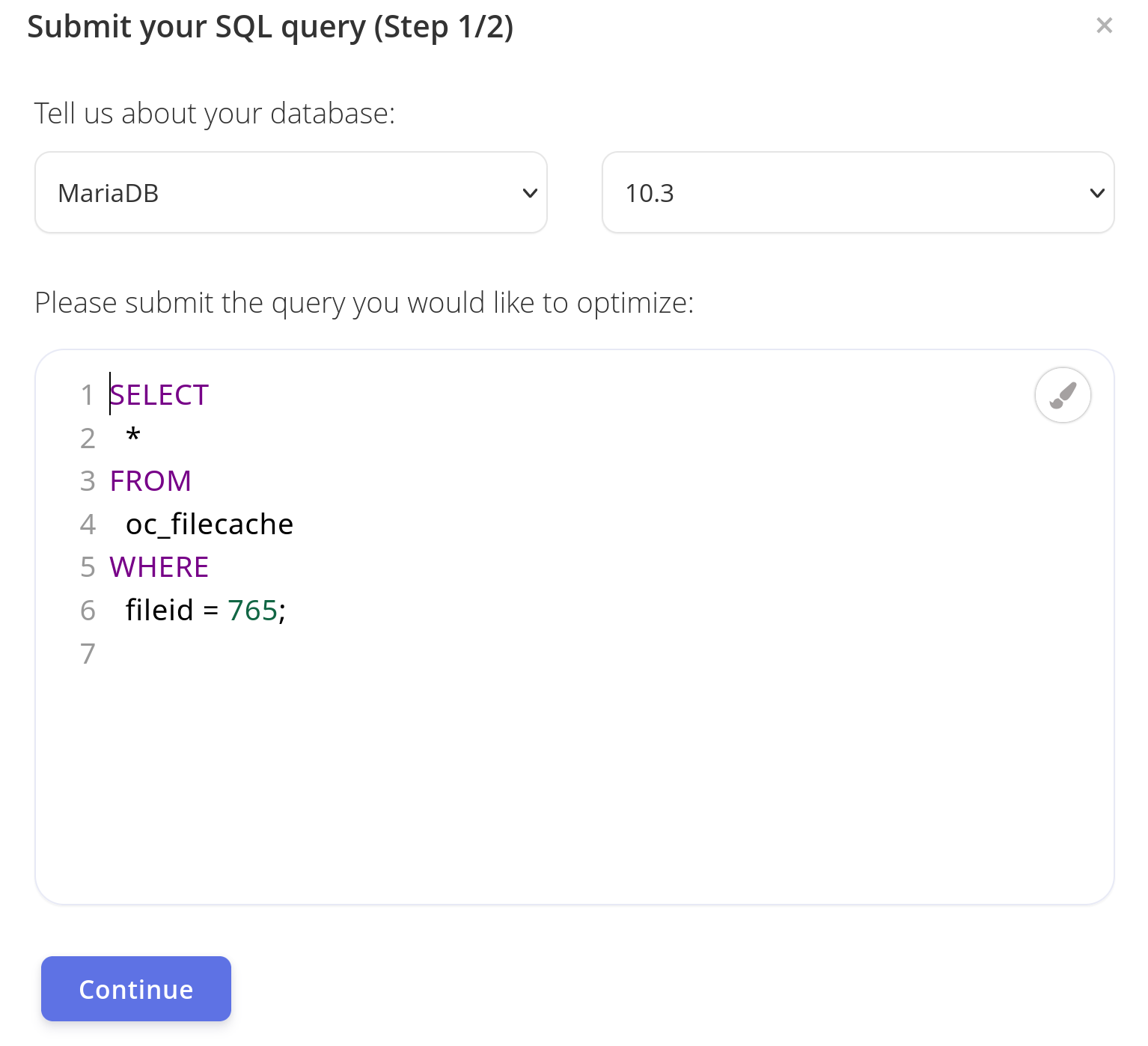
There, you’ll be able to see all the recommendations for optimization immediately.
In conclusion
One’s choice of tools is essential. For me, the choice is always apparent – if I can control something, I will. But sometimes having this control exposes gaps in my knowledge, and I have to use other tools to close those gaps.
DataGrip helps me be as effective as possible when working with databases.
Nextcloud allows me to take control over my data (and sync my photos to my server, not Google’s),
And EverSQL helps me where I’m just not good enough – in the optimization of my queries in my production. The tool is definitely worth trying.




