

Anomalieerkennung mittels Machine Learning in Python


Viele unserer Anwendungen wurden in den letzten Jahren durch die hohe Datenmenge vorangetrieben, die wir erheben und verarbeiten können. Nicht wenige sprechen davon, dass wir uns im Zeitalter der Daten befinden. Einer der wichtigsten Aspekte beim Bearbeiten einer so großen Datenmenge ist die Anomalieerkennung – darunter versteht man Prozesse, die es uns ermöglichen, Ausreißer zu identifizieren, also Daten, die außerhalb der Erwartungen liegen und ein Verhalten aufweisen, das nicht der Norm entspricht. In der wissenschaftlichen Forschung könnten anomale Datenpunkte eine Ursache für technische Probleme sein und sie müssen bei der Erstellung von Schlussfolgerungen verworfen werden. Sie könnten allerdings auch zu neuen Entdeckungen führen.
In diesem Blogbeitrag erfahren Sie, warum der Einsatz von Machine Learning für die Anomalieerkennung hilfreich ist, und Sie lernen die wichtigsten Techniken zur Erkennung von Anomalien mit Python kennen. Sie erfahren, wie man beliebte Methoden wie OneClassSVM und Isolation Forest implementiert, Sie sehen Beispiele für die Visualisierung dieser Ergebnisse und Sie werden verstehen, wie man sie auf reale Probleme anwendet.
Wo wird Anomalieerkennung eingesetzt?
Anomalieerkennung ist ebenfalls ein wichtiger Bestandteil der modernen Business Intelligence, da sie Erkenntnisse darüber liefert, was möglicherweise schiefgehen könnte, und auch potenzielle Probleme identifizieren kann. Nachfolgend finden Sie einige Beispiele für den Einsatz von Anomalieerkennung im modernen Geschäftsleben.
Sicherheitswarnungen
Es gibt einige Angriffe im Bereich der Cybersicherheit, die durch Anomalieerkennung aufgedeckt werden können. So kann beispielsweise ein Anstieg des Anfragevolumens auf einen DDoS-Angriff hinweisen, während verdächtiges Anmeldeverhalten (z. B. mehrere fehlgeschlagene Versuche) mitunter auf unbefugten Zugriff hindeutet. Die Erkennung verdächtigen Benutzer*innen-Verhaltens kann auf potenzielle Cybersicherheitsbedrohungen hinweisen und Unternehmen können entsprechend darauf reagieren, um Schaden zu verhindern oder zu minimieren.
Betrugserkennung
In Bezug auf Finanzorganisationen können beispielsweise Banken Anomalieerkennung nutzen, um verdächtige Kontoaktivitäten zu erkennen, die womöglich auf illegale Tätigkeiten wie Geldwäsche oder Identitätsdiebstahl hindeuten. Verdächtige Transaktionen können auch ein Zeichen für Kreditkartenbetrug sein.
Beobachtbarkeit
Eine der gängigen Praktiken bei Webdiensten besteht darin, Metriken zur Echtzeitleistung des Dienstes zu erheben, wenn ein abnormales Verhalten im System auftritt. So kann beispielsweise eine Spitze in der Speicherauslastung darauf hindeuten, dass etwas im System nicht richtig funktioniert – Techniker*innen müssen sich sofort darum kümmern, um eine Betriebsunterbrechung zu vermeiden.
Warum sollte man Machine Learning für Anomalieerkennung verwenden?
Während klassische statistische Methoden ebenfalls Ausreißer identifizieren können, hat Machine Learning im Bereich der Anomalieerkennung einen neuen Maßstab gesetzt. Dank Machine-Learning-Algorithmen können komplexere Daten (z. B. mit mehreren Parametern) gleichzeitig analysiert werden. Machine-Learning-Techniken bieten auch die Möglichkeit, kategoriale Daten zu analysieren, die mit herkömmlichen statistischen Methoden, die eher für numerische Daten geeignet sind, nicht so einfach auszuwerten sind.
Häufig können diese programmierten Algorithmen zur Anomalieerkennung als Anwendung eingesetzt werden (weiterführend hierzu unser Tutorial FastAPI für Machine Learning) und nach Bedarf oder in geplanten Intervallen ausgeführt werden, um Anomalien zu finden. Dies ermöglicht es, umgehend Maßnahmen im Unternehmen zu ergreifen und sie auch als Reporting-Tools für Business-Intelligence-Teams zu nutzen, um Strategien zu bewerten und anzupassen.
Technik- und Algorithmustypen im Bereich der Anomalieerkennung
Man kann zwischen zwei grundlegenden Typen der Anomalieerkennung differenzieren: Ausreißererkennung und Neuartigkeitenerkennung.
Ausreißererkennung
Die Erkennung von Ausreißern wird manchmal auch als unbeaufsichtigte Anomalieerkennung bezeichnet, da davon ausgegangen wird, dass es in den Trainingsdaten einige unerkannte (also nicht gekennzeichnete) Anomalien gibt. Der Ansatz darin besteht, unbeaufsichtigte Machine-Learning-Algorithmen zu verwenden, um diese herauszufiltern. Einige dieser Algorithmen sind etwa Einklassen-Support-Vektor-Maschinen (SVMs), Isolation Forest, Local Outlier Factor und Elliptic Envelope.
Neuartigkeitenerkennung
Andererseits wird die Erkennung von Neuartigkeiten manchmal auch als semi-beaufsichtigte Anomalieerkennung bezeichnet. Da wir davon ausgehen, dass alle Trainingsdaten nicht nur aus Anomalien bestehen, werden sie alle als normal gekennzeichnet. Das Ziel ist es, zu erkennen, ob es sich bei neuen Daten um eine Anomalie handelt, die manchmal auch als Neuartigkeit bezeichnet wird. Die Algorithmen, die bei der Ausreißererkennung eingesetzt werden, können auch für die Neuartigkeitenerkennung verwendet werden, vorausgesetzt, es gibt keine Anomalien in den Trainingsdaten.
Neben der erwähnten Erkennung von Ausreißern und Neuartigkeiten ist auch häufig die Anomalieerkennung in Zeitreihendaten erforderlich. Da sich der Ansatz und die Technik, die für Zeitreihendaten verwendet werden, jedoch oft von den oben genannten Algorithmen unterscheiden, werden wir diese zu einem späteren Zeitpunkt im Detail besprechen.
Code-Beispiel: Auffinden von Anomalien im Bienenstock-Datensatz
Im Rahmen dieses Blogbeitrags verwenden wir folgenden Bienenstock-Datensatz als Beispiel, um Anomalien in den Bienenstöcken zu erkennen. Dieser Datensatz enthält unterschiedliche Messungen des Bienenstocks (einschließlich der Temperatur und der relativen Luftfeuchtigkeit) zu verschiedenen Zeiten.
Hier stellen wir zwei ganz unterschiedliche Verfahren zur Entdeckung von Anomalien vor. Die verwendeten Methoden sind OneClassSVM (basiert auf der Support-Vektor-Maschinen-Technologie und dient dazu, Entscheidungsgrenzen festzulegen) sowie Isolation Forest (ein ensemblebasiertes Verfahren, das Random Forest ähnlich ist).
Beispiel: OneClassSVM
In diesem ersten Beispiel verwenden wir die Daten von Bienenstock 17 unter der Annahme, dass die Bienen ihren Stock in einem konstant angenehmen Zustand für die Kolonie halten. Wir werden überprüfen, ob das zutrifft und ob es Zeiten gibt, in denen der Stock Anomalien in Bezug auf Temperatur und relative Luftfeuchtigkeit aufweist. Wir verwenden OneClassSVM, um unsere Daten anzupassen und die Entscheidungsgrenzen in einem Streudiagramm zu betrachten.
Das „SVM“ in OneClassSVM steht für Support-Vektor-Maschine – ein beliebter Machine-Learning-Algorithmus zur Klassifizierung und Regression. Während Support-Vektor-Maschinen verwendet werden können, um Datenpunkte in hohen Dimensionen zu klassifizieren, ist es uns möglich, durch die Wahl eines Kernels und eines skalaren Parameters eine Entscheidungsgrenze zu definieren, welche die meisten Datenpunkte (normale Daten) einschließt, während eine kleine Anzahl von Anomalien außerhalb der Grenzen verbleibt. Dies stellt die Wahrscheinlichkeit (nu) der Entdeckung einer neuen Anomalie dar. Die Methode zur Anwendung von Support-Vektor-Maschinen für die Anomalieerkennung wird in einem Paper von Scholkopf et al. mit dem Titel Estimating the Support of a High-Dimensional Distribution behandelt.
1. Jupyter-Projekt einrichten
Wenn Sie ein neues Projekt in PyCharm (Professional 2024.2.2) einrichten, wählen Sie Jupyter unter Python aus.
Der Vorteil, ein Jupyter-Projekt (früher auch Scientific-Projekt) in PyCharm zu verwenden, ist, dass eine Dateistruktur für Sie generiert wird – einschließlich eines Ordners zum Speichern Ihrer Daten und eines Ordners für alle Jupyter Notebooks. So können Sie alle Ihre Experimente an einem Ort aufbewahren.
Ein weiterer großer Vorteil ist, dass wir Diagramme sehr einfach mithilfe von Matplotlib darstellen können. Das sehen Sie in den folgenden Schritten.
2. Abhängigkeiten installieren
Laden Sie requirements.txt aus dem entsprechenden GitHub-Repo herunter. Sobald Sie die Datei im Projektverzeichnis abgelegt und in PyCharm geöffnet haben, werden Sie aufgefordert, die fehlenden Bibliotheken zu installieren.
Klicken Sie auf Install requirements (Abhängigkeiten installieren), um alle notwendigen Elemente zu installieren. Für dieses Projekt verwenden wir Python 3.11.1.
3. Daten importieren und prüfen
Sie können den „Beehives“-Datensatz entweder bei Kaggle oder aus diesem GitHub-Repo herunterladen. Platzieren Sie alle drei CSV-Dateien im Ordner Data. Fügen Sie dann in main.py den folgenden Code ein:
import pandas as pd
df = pd.read_csv('data/Hive17.csv', sep=";")
df = df.dropna()
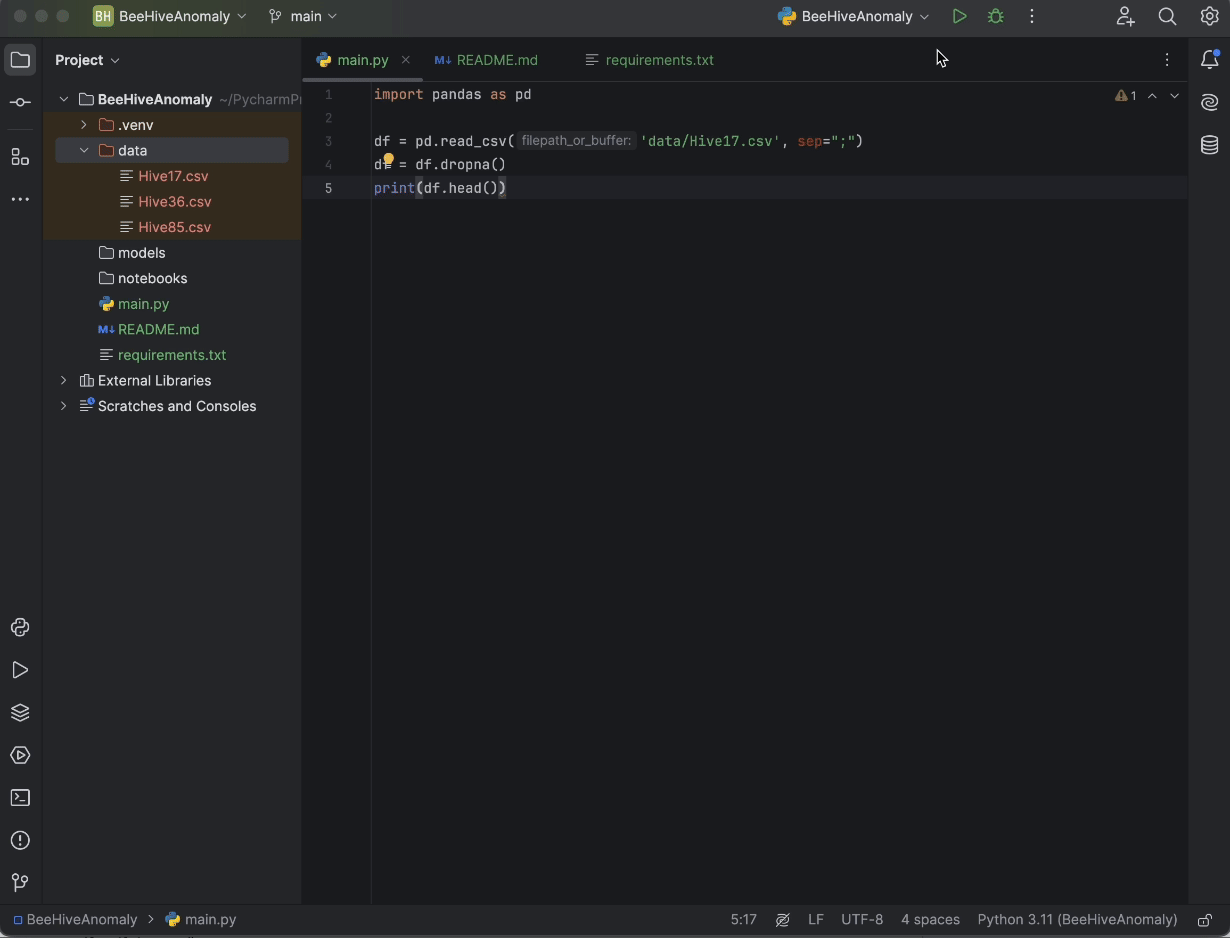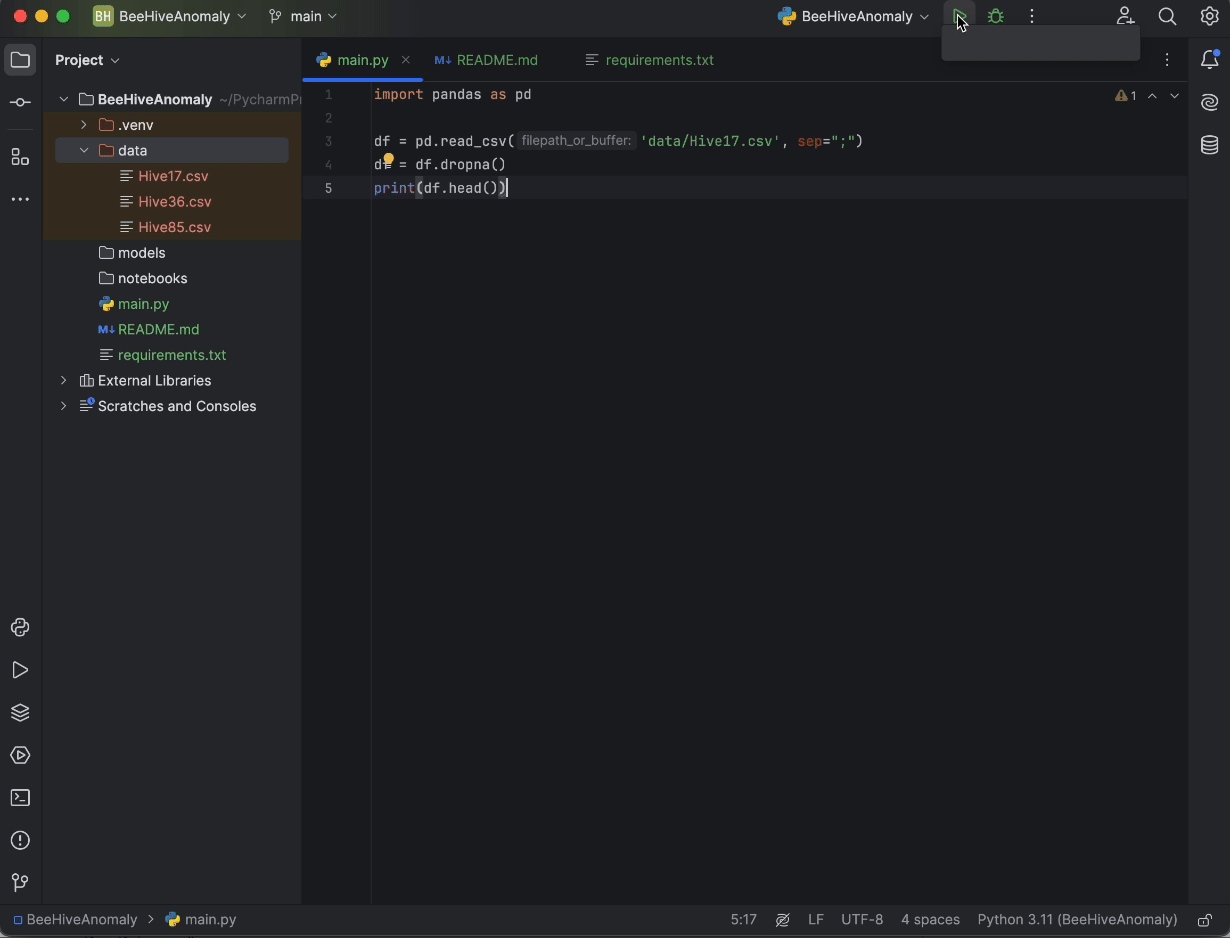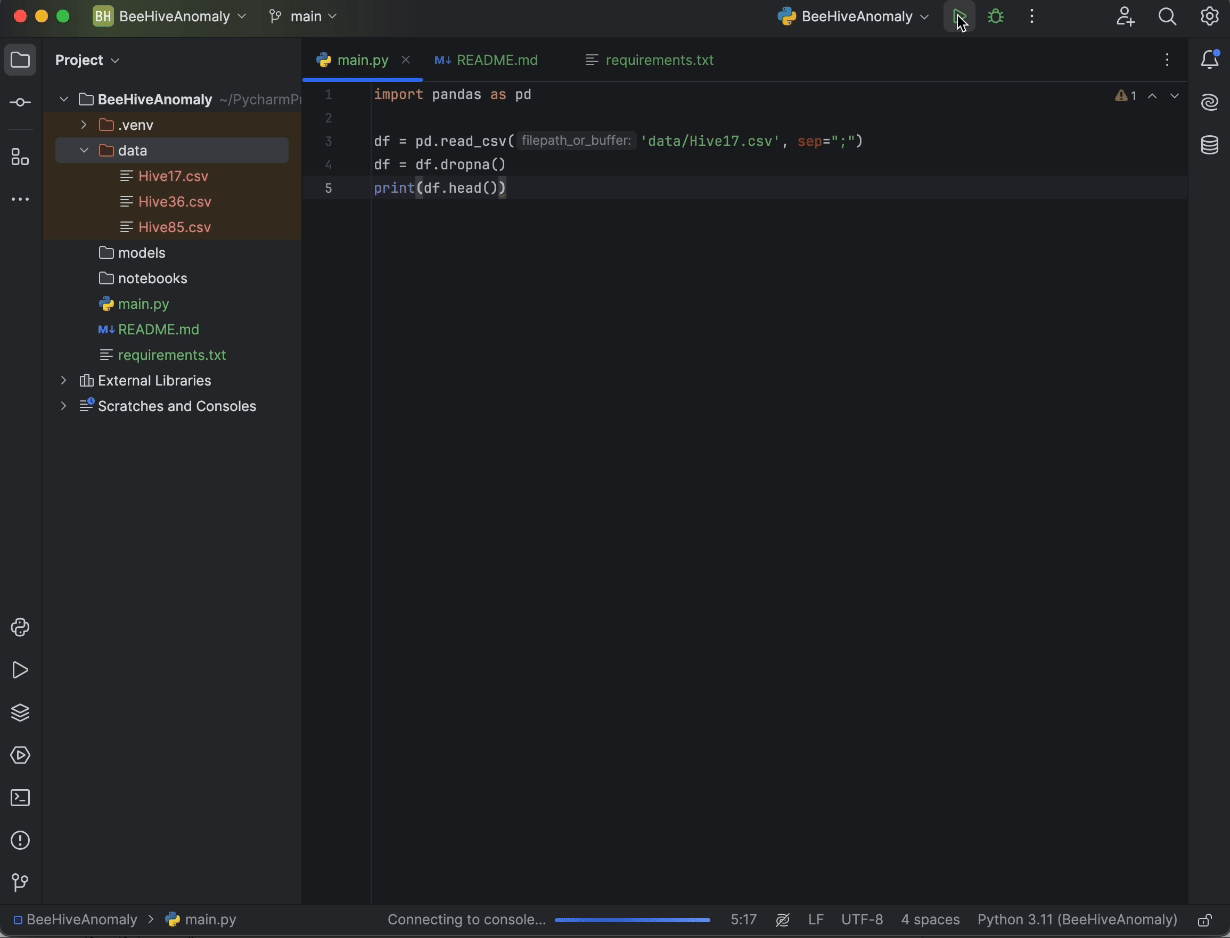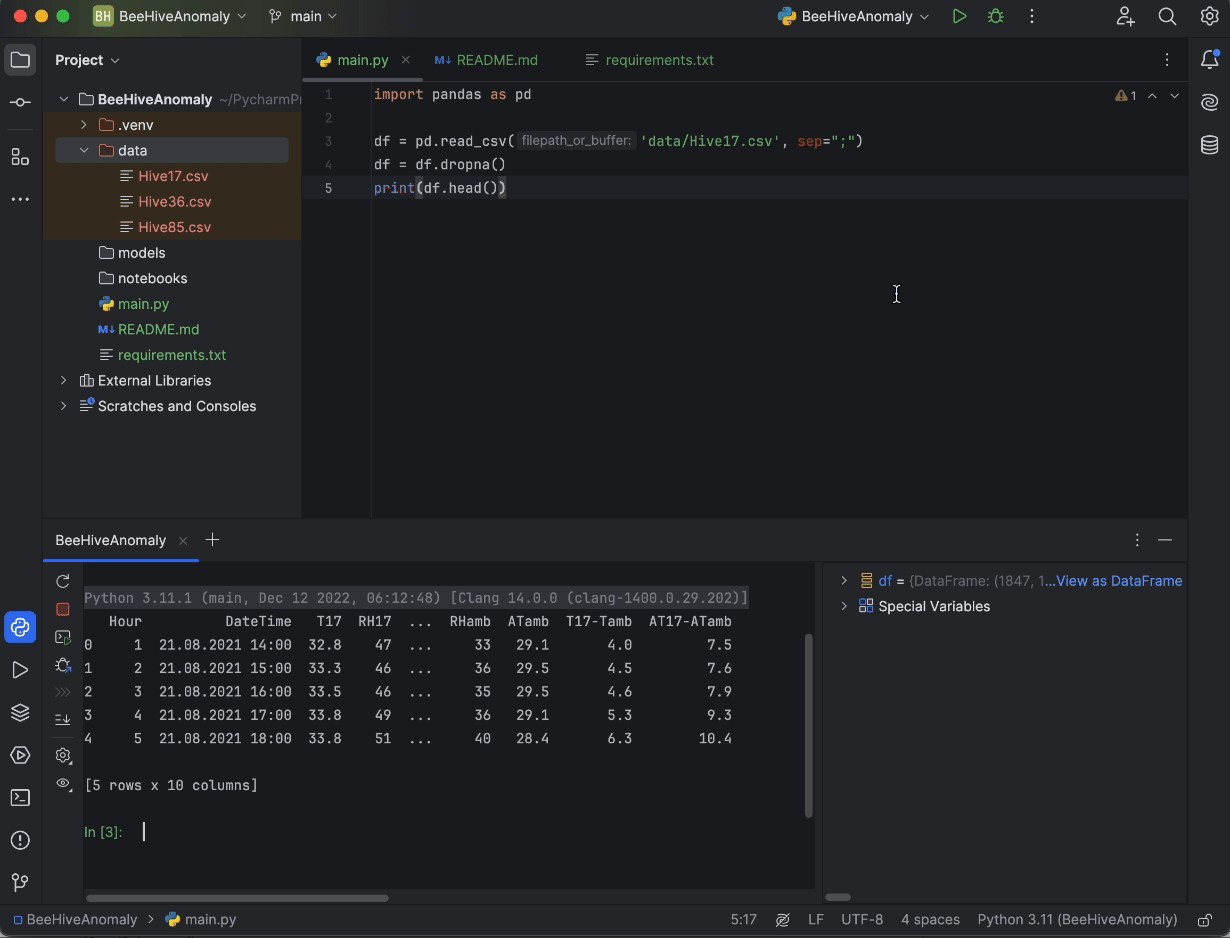
print(df.head())
Klicken Sie abschließend auf die Schaltfläche Run (Ausführen) in der oberen rechten Ecke des Bildschirms. Unser Code wird dann in der Python-Konsole ausgeführt, sodass wir einen Eindruck davon bekommen, wie unsere Daten aussehen.
4. Datenpunkte anpassen und in einem Diagramm untersuchen
Da wir OneClassSVM aus scikit-learn verwenden werden, importieren wir dies zusammen mit DecisionBoundaryDisplay und Matplotlib mithilfe des folgenden Codes:
from sklearn.svm import OneClassSVM from sklearn.inspection import DecisionBoundaryDisplay import matplotlib.pyplot as plt
Aus der Beschreibung der Daten wissen wir, dass die Spalte T17 für die Temperatur des Bienenstocks und RH17 für die relative Luftfeuchtigkeit desselben steht. Wir extrahieren den Wert dieser beiden Spalten als Eingabewert:
X = df[["T17", "RH17"]].values
Dann erstellen wir das Modell und passen es an. Beachten Sie, dass wir zunächst die Standardeinstellung ausprobieren:
estimator = OneClassSVM().fit(X)
Hiermit zeigen wir die Entscheidungsgrenze zusammen mit den Datenpunkten an:
disp = DecisionBoundaryDisplay.from_estimator(
estimator,
X,
response_method="decision_function",
plot_method="contour",
xlabel="Temperature", ylabel="Humidity",
levels=[0],
)
disp.ax_.scatter(X[:, 0], X[:, 1])
plt.show()
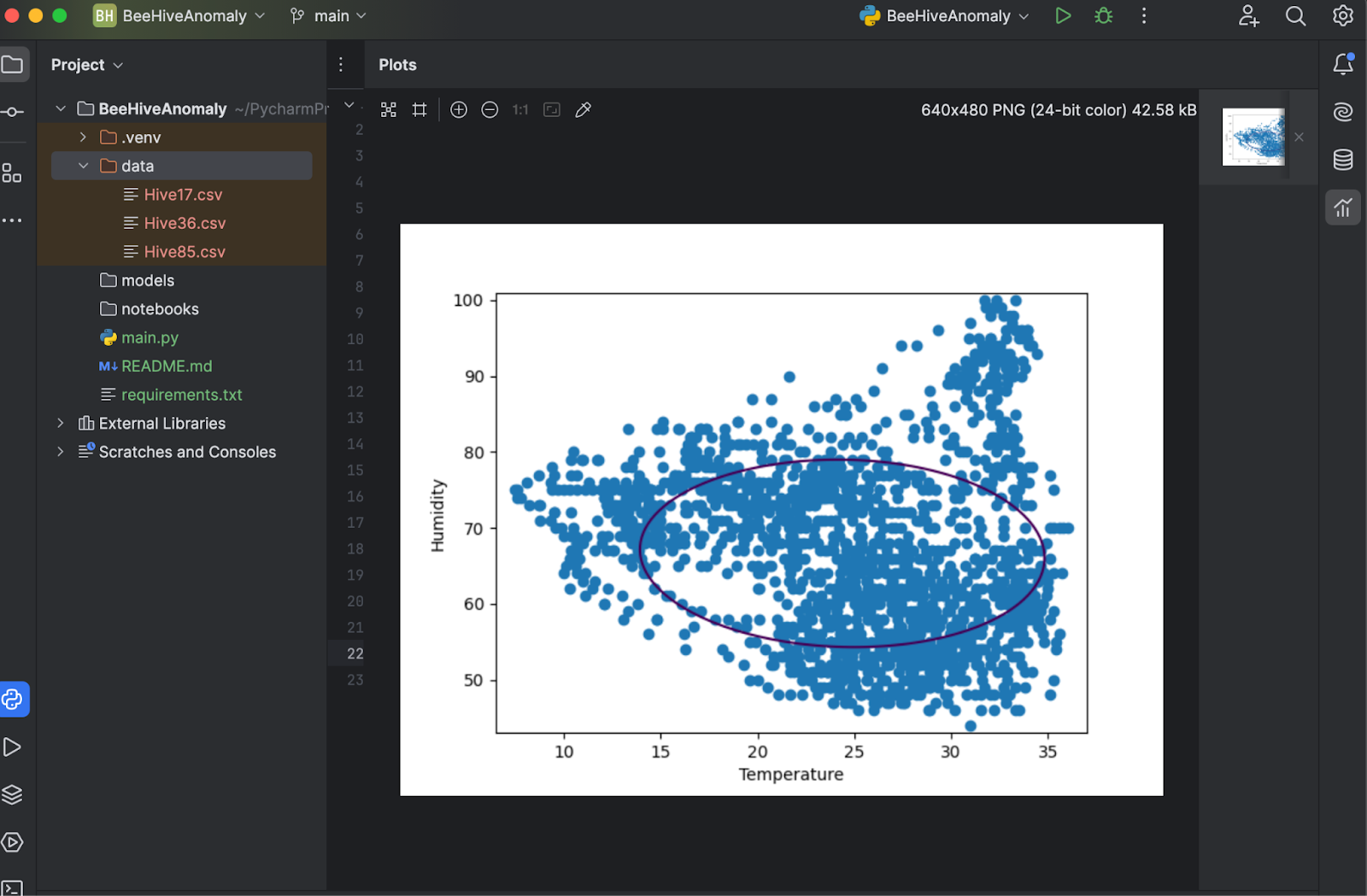
Speichern Sie nun die Änderungen und klicken Sie erneut auf Run (Ausführen). Sie werden sehen, dass das Diagramm in einem separaten Fenster zur Überprüfung angezeigt wird.
5. Feinabstimmung von Hyperparametern
Wie das obige Diagramm zeigt, passt die Entscheidungsgrenze nicht besonders gut zu den Datenpunkten. Die Datenpunkte bestehen aus einer Reihe unregelmäßiger Formen anstelle eines Ovals. Zur Feinabstimmung unseres Modells müssen wir dem OneClassSVM-Modell einen bestimmten Wert für „nu“ und „gamma“ zuweisen. Sie können es ruhig selbst ausprobieren – aber nach einigen Tests scheint es, dass „nu=0.1, gamma=0.05“ das beste Ergebnis liefert.
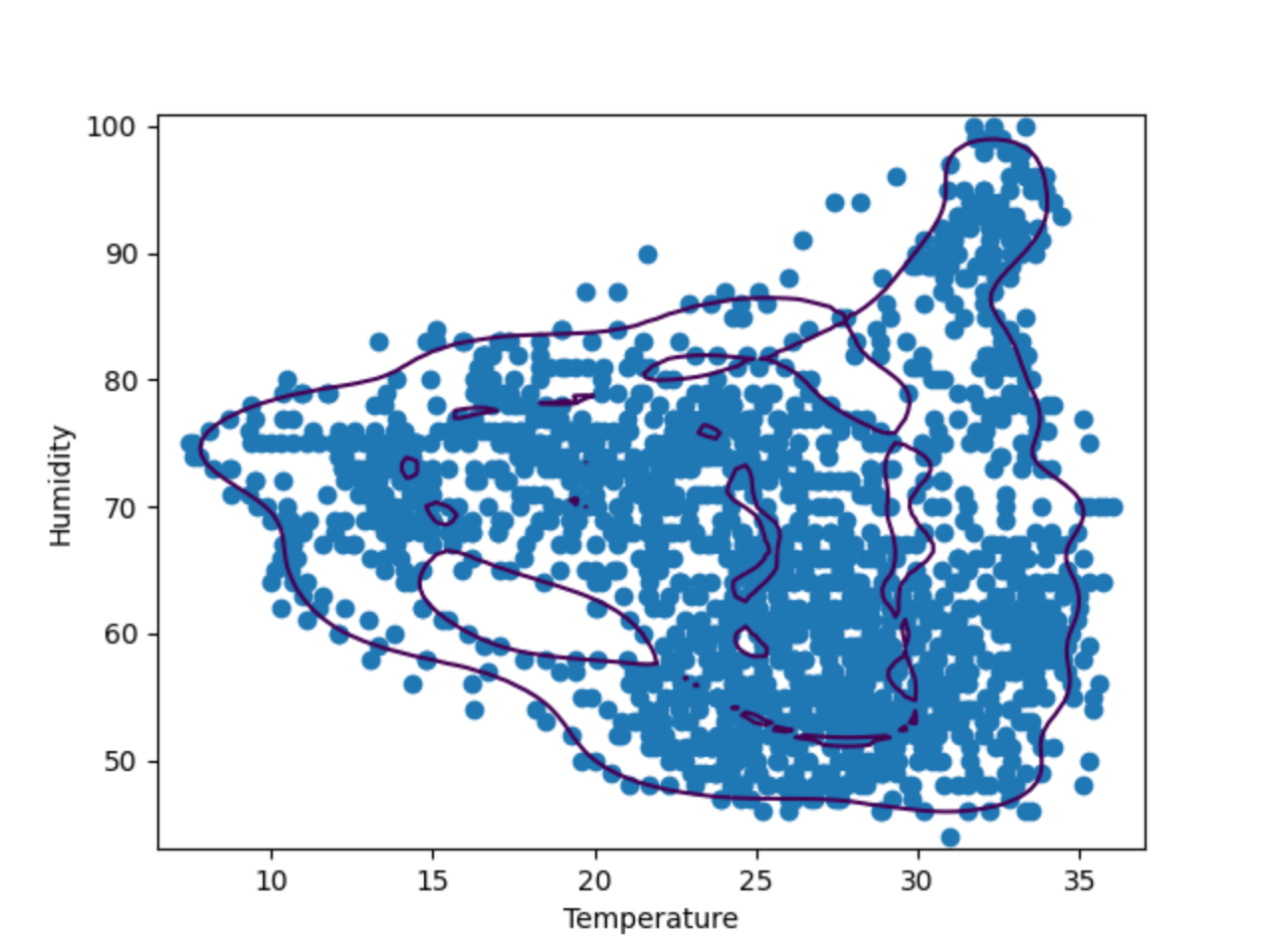
Beispiel: Isolation Forest
Isolation Forest ist eine ensemblebasierte Methode ähnlich der bekannteren„Random Forest“-Klassifikationsweise. Durch die zufällige Auswahl von Trennmerkmalen und entsprechenden Werten werden zahlreiche Entscheidungsbäume erstellt. Die Pfadlänge vom Baumstamm bis zur Abzweigung, welche die Entscheidung trifft, wird über alle Bäume hinweg gemittelt (daher auch der Begriff „forest“/Wald). Eine kurze durchschnittliche Pfadlänge weist auf Anomalien hin.
Vergleichen wir nun das Ergebnis von OneClassSVM mit IsolationForest. Dazu erstellen wir zwei Diagramme der Entscheidungsgrenzen, die von den beiden Algorithmen festgelegt werden. In den folgenden Schritten bauen wir auf dem obigen Skript auf und verwenden dabei dieselben Daten für Bienenstock 17.
1. IsolationForest importieren
IsolationForest kann aus den Ensemble-Kategorien in Scikit-learn importiert werden:
from sklearn.ensemble import IsolationForest
2. Refactoring und Hinzufügen einer neuen Schätzfunktion
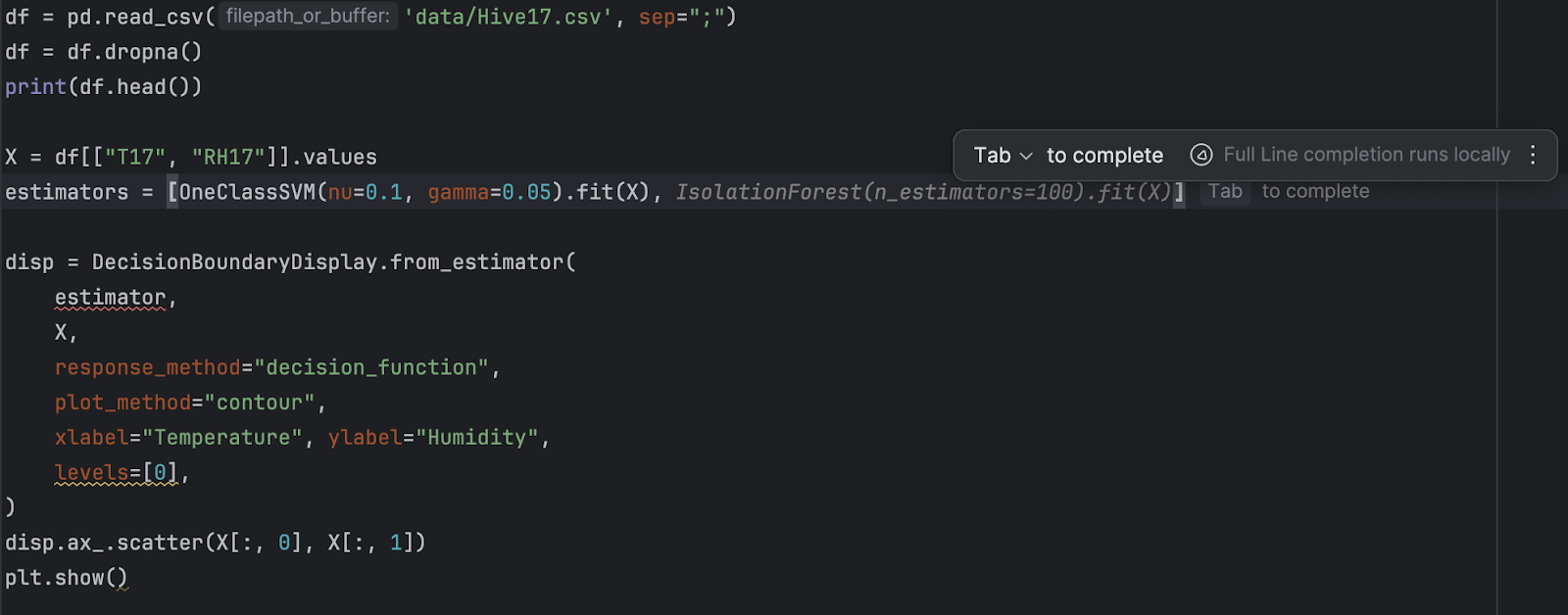
Da wir nun zwei verschiedene Schätzfunktionen haben, sollten wir sie in einer Liste zusammenfassen:
estimators = [
OneClassSVM(nu=0.1, gamma=0.05).fit(X),
IsolationForest(n_estimators=100).fit(X)
]
Danach verwenden wir eine for-Schleife, um alle Schätzfunktionen durchzugehen.
for estimator in estimators:
disp = DecisionBoundaryDisplay.from_estimator(
estimator,
X,
response_method="decision_function",
plot_method="contour",
xlabel="Temperature", ylabel="Humidity",
levels=[0],
)
disp.ax_.scatter(X[:, 0], X[:, 1])
plt.show()
Als letzten Schliff fügen wir jedem Diagramm einen Titel hinzu, um die Kontrolle zu erleichtern. Dazu ergänzen wir nach disp.ax_.scatter Folgendes:
disp.ax_.set_title(
f"Decision boundary using {estimator.__class__.__name__}"
)
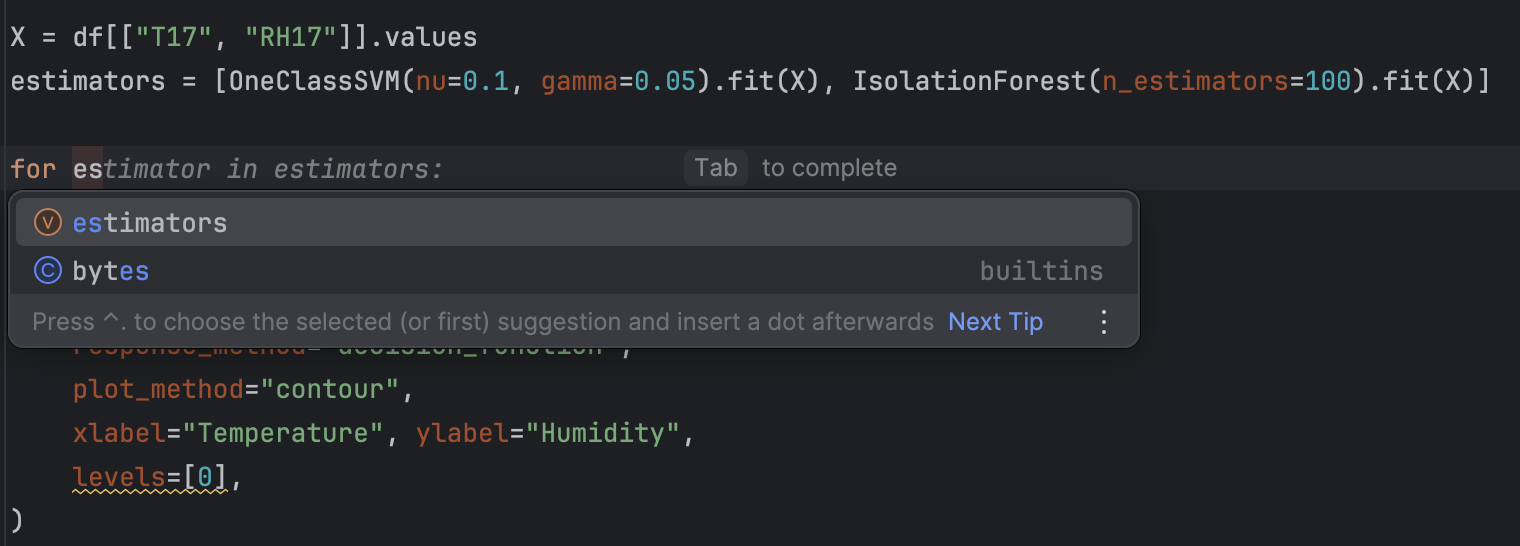
Sie werden feststellen, dass das Refactoring mit PyCharm dank der Auto-Completion-Vorschläge besonders einfach ist.
3. Code ausführen
Wie zuvor müssen Sie zum Ausführen des Codes lediglich auf die Schaltfläche Run (Ausführen) in der oberen rechten Ecke klicken. Nachdem der Code ausgeführt wurde, sollten wir zwei Diagramme erhalten.
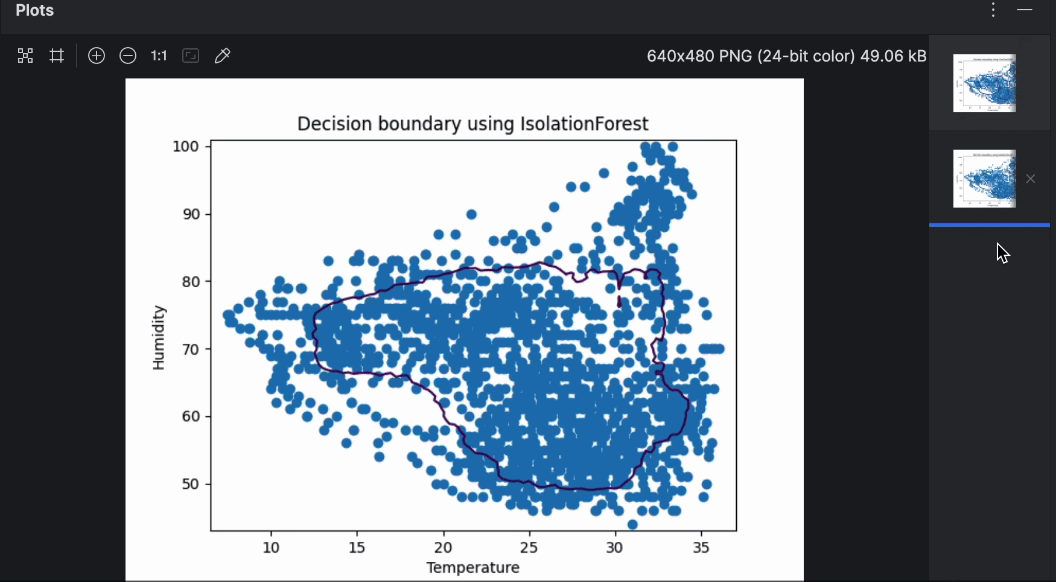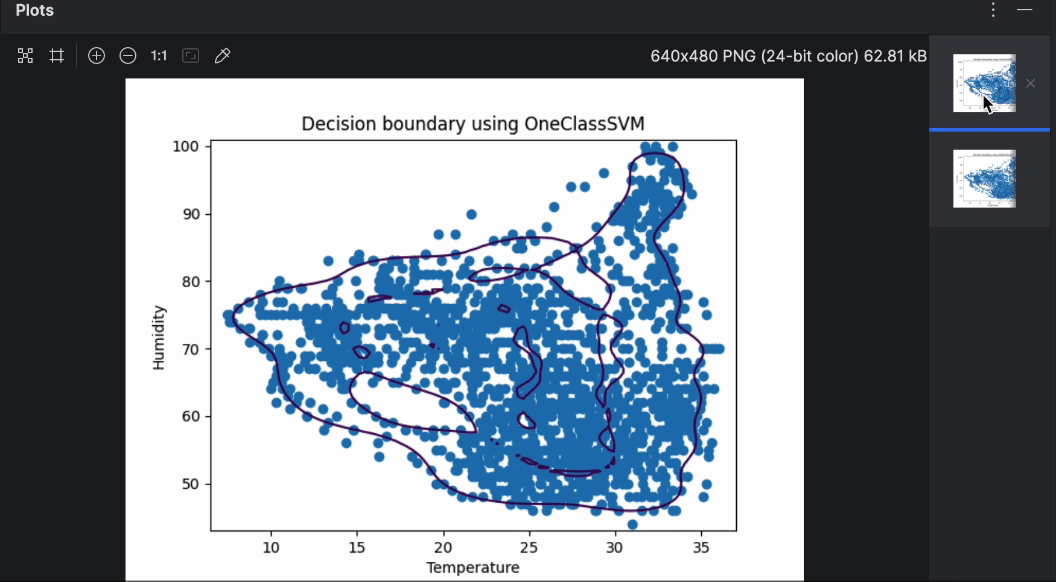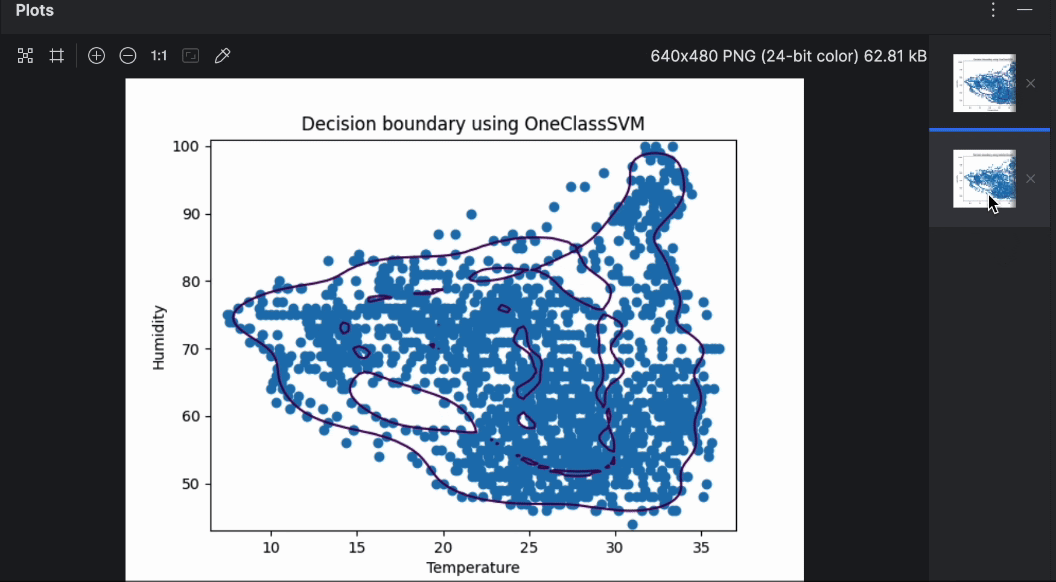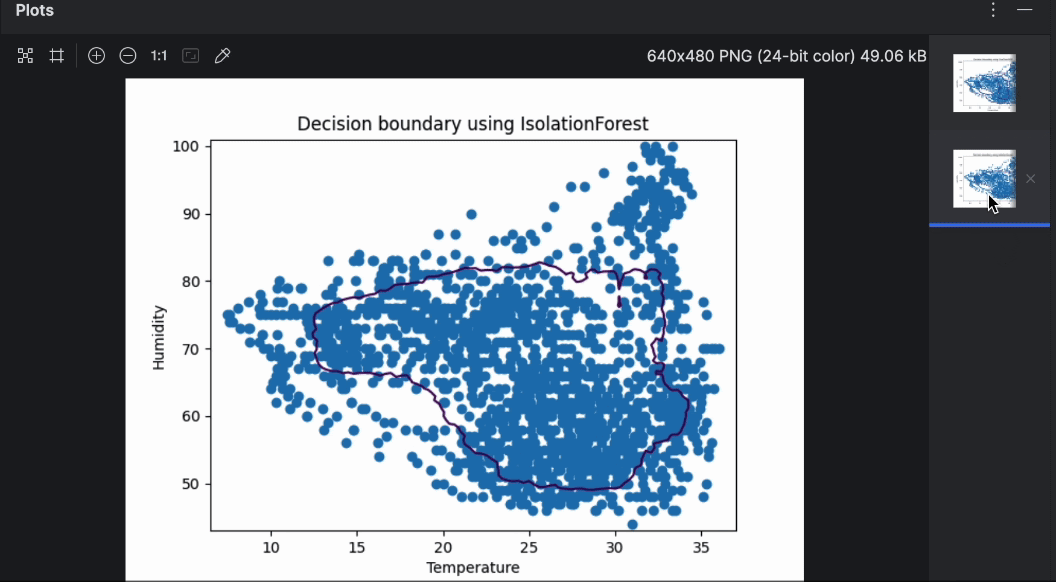
Mit der Vorschau auf der rechten Seite können Sie ganz einfach durch die beiden Diagramme blättern. Wie Sie sehen können, ist die Entscheidungsgrenze bei der Verwendung verschiedener Algorithmen recht unterschiedlich. Im Rahmen der Anomalieerkennung lohnt es sich, mit verschiedenen Algorithmen und Parametern zu experimentieren, um jene Option zu finden, die für den jeweiligen Anwendungsfall am besten geeignet ist.
Nächster Schritt: Anomalieerkennung in Zeitreihendaten
Falls es sich bei den Daten wie bei unseren Bienenstockdaten um eine Zeitreihe handelt, gibt es zusätzliche Methoden, um Anomalien herauszufiltern. Da Zeitreihen Trends und Perioden umfassen, kann alles, was von diesbezüglichen Mustern abweicht, als Anomalie betrachtet werden. Beliebte Methoden zur Anomalieerkennung in Zeitreihen sind STL-Zerlegung und LSTM-Vorhersage.
Erfahren Sie in diesem Blogbeitrag, wie Sie diese Methoden zur Erkennung von Anomalien in Zeitreihen verwenden können.
Zusammenfassung
Die Anomalieerkennung hat sich als wichtiger Aspekt der Business Intelligence erwiesen. Die Fähigkeit, Anomalien zu identifizieren und sofortige Maßnahmen zu ergreifen, ist in einigen Geschäftsbereichen unerlässlich. Der Einsatz eines geeigneten Machine-Learning-Modells zur automatischen Erkennung von Anomalien kann dazu beitragen, komplizierte und große Datenmengen in kurzer Zeit zu analysieren. In diesem Blogbeitrag haben wir Ihnen gezeigt, wie Sie mithilfe von statistischen Modellen wie OneClassSVM Anomalien erkennen können.
Um mehr über die Verwendung von PyCharm für Machine Learning zu erfahren, lesen Sie bitte „Start Studying Machine Learning With PyCharm“ (Einführung in Machine Learning mit PyCharm)und „How to Use Jupyter Notebooks in PyCharm“ (Jupyter Notebooks in PyCharm).
Anomalien mit PyCharm erkennen
Mit dem Jupyter-Projekt in PyCharm Professional lässt sich Ihr Projekt zur Anomalieerkennung mühelos mit zahlreichen Datendateien und Notebooks strukturieren. Sie können Graphen erstellen, um Anomalien zu untersuchen, und Diagramme sind in PyCharm äußerst benutzerfreundlich. Weitere Funktionen, wie etwa Auto-Completion-Vorschläge, gestalten das Navigieren durch die Scikit-learn-Modelle und die Matplotlib-Diagrammeinstellungen besonders angenehm.
Verbessern Sie Ihr Data-Science-Projekt mit PyCharm und sehen Sie sich die verfügbaren Data-Science-Features an, um Ihren Data-Science-Workflow zu optimieren.
Autorin des ursprünglichen Blogposts





