

Python による機械学習を使った異常検知手法


近年は多くのアプリケーションで大量のデータが活用されていますが、このようなデータは収集・処理可能なものです。 私たちがデータ時代に生きていると言う人もいるでしょう。 このような大量のデータを処理する際には、異常検知が欠かせません。これは、想定の範囲外であり、通常とは異なる挙動を示しているデータ(外れ値)を特定可能にするプロセスです。 科学研究の分野では、異常なデータポイントは技術的な問題の発生要因となるため、結論を導く際には破棄する必要がある場合があります。また、新たな発見につながるものになることもあります。
このブログ記事では、異常検知に機械学習を使用するのが有用である理由を確認し、Python を使って異常を検知する主な手法を探ります。 OneClassSVM や Isolation Forest などの一般的な手法を実践する方法を学び、これらの結果を可視化する方法の例を確認して実世界の問題に応用する方法を理解します。
異常検知が使用される分野
異常検知は問題となり得るものについてインサイトを提供し、潜在的な問題を特定しうる可能性があるため、現代のビジネスインテリジェンスで重要な役割を果たしています。 異常検知は現代のビジネスで以下のように使用されています。
セキュリティ警告
異常検知によって検出できる可能性のあるサイバーセキュリティ攻撃はいくつか存在します。たとえば、リクエスト量が急増した場合には DDoS 攻撃を示している可能性があり、不審なログイン行動(何度も試行に失敗するなど)が見られた場合には不正アクセスを示している可能性があります。 不審なユーザー行動が検出されるということは潜在的なサイバーセキュリティ脅威が発生していることを示している可能性があるため、企業は適宜に対応し、損害を防止したり最小限に抑えたりすることができます。
不正行為検出
銀行などの金融組織では、不審な口座取引を明確化する目的で異常検知が用いられる場合があります。このような取引は、マネーロンダリングや個人情報の盗難などの不正な活動を示している可能性があります。 不審な取引はクレジットカードの不正利用を示していることもあります。
可観測性
ウェブサービスでは、システムが異常動作を起こしている場合にサービスのパフォーマンスメトリクスをリアルタイムに収集するのが一般的です。 たとえば、メモリ使用率の急増はシステムの機能に不具合が発生していることを示している可能性があるため、エンジニアは直ちにその不具合に対処してサービスの中断を回避する必要があります。
異常検知に機械学習を使用する理由
従来の統計手法でも外れ値を発見することはできますが、異常検知に機械学習を利用すると、作業が大きく変わります。 機械学習アルゴリズムを使用すれば、比較的複雑なデータ(複数のパラメーターを持つデータなど)をすべてまとめて解析できるためです。 機械学習の手法では、どちらかと言えば数値データに適している従来の統計手法では容易に解析できないカテゴリデータを解析することも可能です。
このような異常検知アルゴリズムは往々にしてプログラム化されているため、アプリケーションとしてデプロイ(「機械学習のための FastAPI」チュートリアルを参照)し、リクエストベースか指定間隔で実行して異常を検知することができます。 つまり、社内で迅速な対応を促すのに役立つだけでなく、ビジネスインテリジェンスチームが戦略の見直しと調整を行うためのレポート作成ツールとしても使用できます。
異常検知手法の種類とアルゴリズム
一般的に、異常検知には主に外れ値検出と新規性検知の 2 種類があります。
外れ値検出
外れ値検出は、トレーニングデータに未検知の異常(ラベルが付いていない異常)があると仮定し、教師なし機械学習アルゴリズムを使用してその異常を識別するアプローチであるため、教師なし異常検知と呼ばれることもあります。 このようなアルゴリズムには、One-Class Support Vector Machines(SVM)、Isolation Forest、Local Outlier Factor、Elliptic Envelope などがあります。
新規性検知
一方、新規性検知は半教師あり異常検知と呼ばれることがあります。 すべてのトレーニングデータにはまったく異常が含まれないと仮定するため、すべて正常としてラベル付けされます。 その目標は、新しいデータが異常(新規性とも呼ばれる)であるかどうかを検出することです。 外れ値検出で使用されるアルゴリズムは、トレーニングデータに異常がない場合に限って新規性検知にも使用できます。
前述の外れ値検出と新規性検知以外に、時系列データの異常検知が必要になることもよくあります。 ただし、時系列データに使用されるアプローチと手法は前述のアルゴリズムとは異なっていることが多いため、これらについては後日詳しく説明します。
コード例: 養蜂箱データセットで異常を検出する
このブログ記事では、こちらの養蜂箱データセットを例に養蜂箱の異常を検出します。 このデータセットには、さまざまな時間での養蜂箱のさまざまな測定値(養蜂箱の温度や相対湿度など)が含まれています。
ここでは、まったく異なる 2 つの異常検出方法をご紹介します。 決定境界を引くために使用するサポートベクターマシンテクノロジーに基づく One-Class SVM と、Random Forest に類似したアンサンブル手法である Isolation Forest です。
例: One-Class SVM
この最初の例では、養蜂箱 17 番のデータを使用し、ミツバチが巣をコロニーにとって常に快適な環境に保つと仮定します。これにより、この仮定が真であるかどうかと、養蜂箱の温度と相対湿度レベルが異常な状態になることがあるかどうかを調べることができます。 One-Class SVM を使用してデータを適合させ、散布図上の意思決定境界を確認しましょう。
One-Class SVM の SVM はサポートベクターマシンの略であり、分類と回帰に使用される一般的な機械学習アルゴリズムです。 サポートベクターマシンは高次元のデータポイントを分類するために使用できますが、カーネルとスカラーパラメーターを選択して境界を定義することで、ほとんどのデータポイント(正常データ)を含む決定境界を作成し、少数の異常を境界の外側に維持して新しい異常を見つける確率(nu)を表すことができます。 異常検知にサポートベクターマシンを使用する手法については、Scholkopf et al による『Estimating the Support of a High-Dimensional Distribution』というタイトルの論文で説明されています。
1. Jupyter プロジェクトを開始する
PyCharm(Profefssional 2024.2.2)で新規プロジェクトを開始する際に、Python の下にある Jupyter を選択します。
PyCharm で Jupyter プロジェクト(旧称「科学計算プロジェクト」)を使用するメリットは、データを格納するフォルダーやすべての Jupyter ノートブックを保存するフォルダーなどのファイル構造が自動的に生成されるため、すべての実験を 1 か所にまとめられることです。
Matplotlib を使用することで、グラフを非常に簡単にレンダリングできるという大きなメリットもあります。 これは以下の手順でお見せします。
2. 依存関係をインストールする
関連する GitHub リポジトリからこちらの requirements.txt をダウンロードします。 これをプロジェクトディレクトリに配置して PyCharm で開くと、欠落したライブラリをインストールするように求められます。
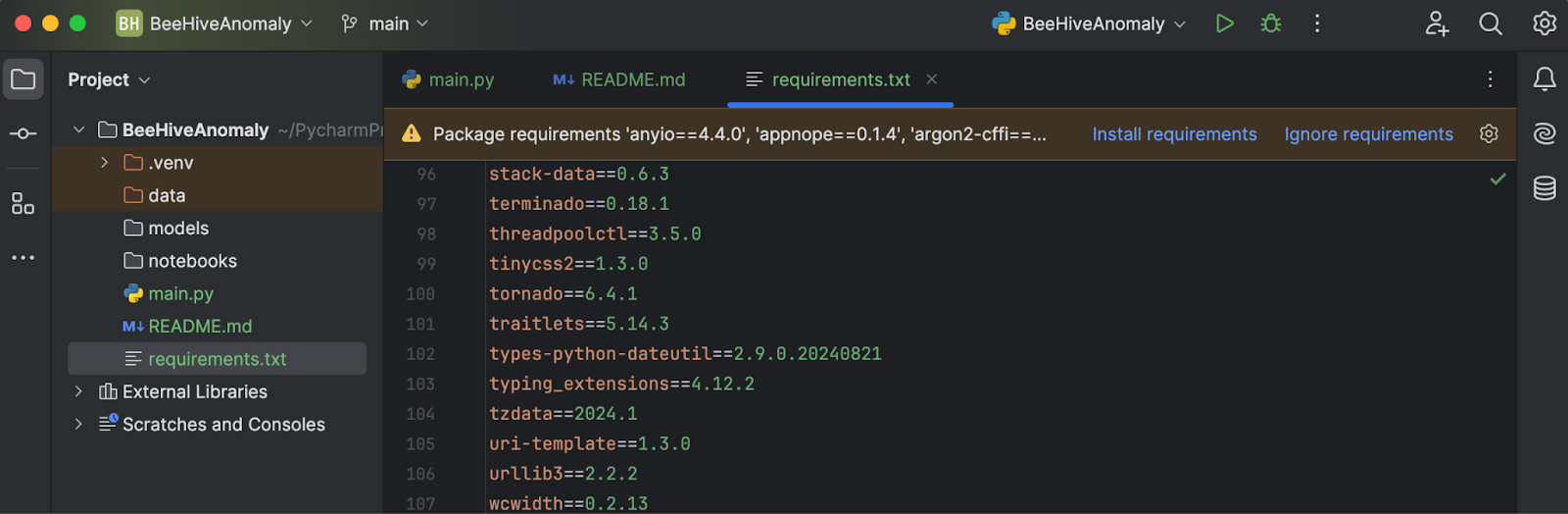
Install requirements(requirements のインストール)をクリックすると、すべての requirements がインストールされます。 このプロジェクトでは、Python 3.11.1 を使用しています。
3. データをインポートして検査する
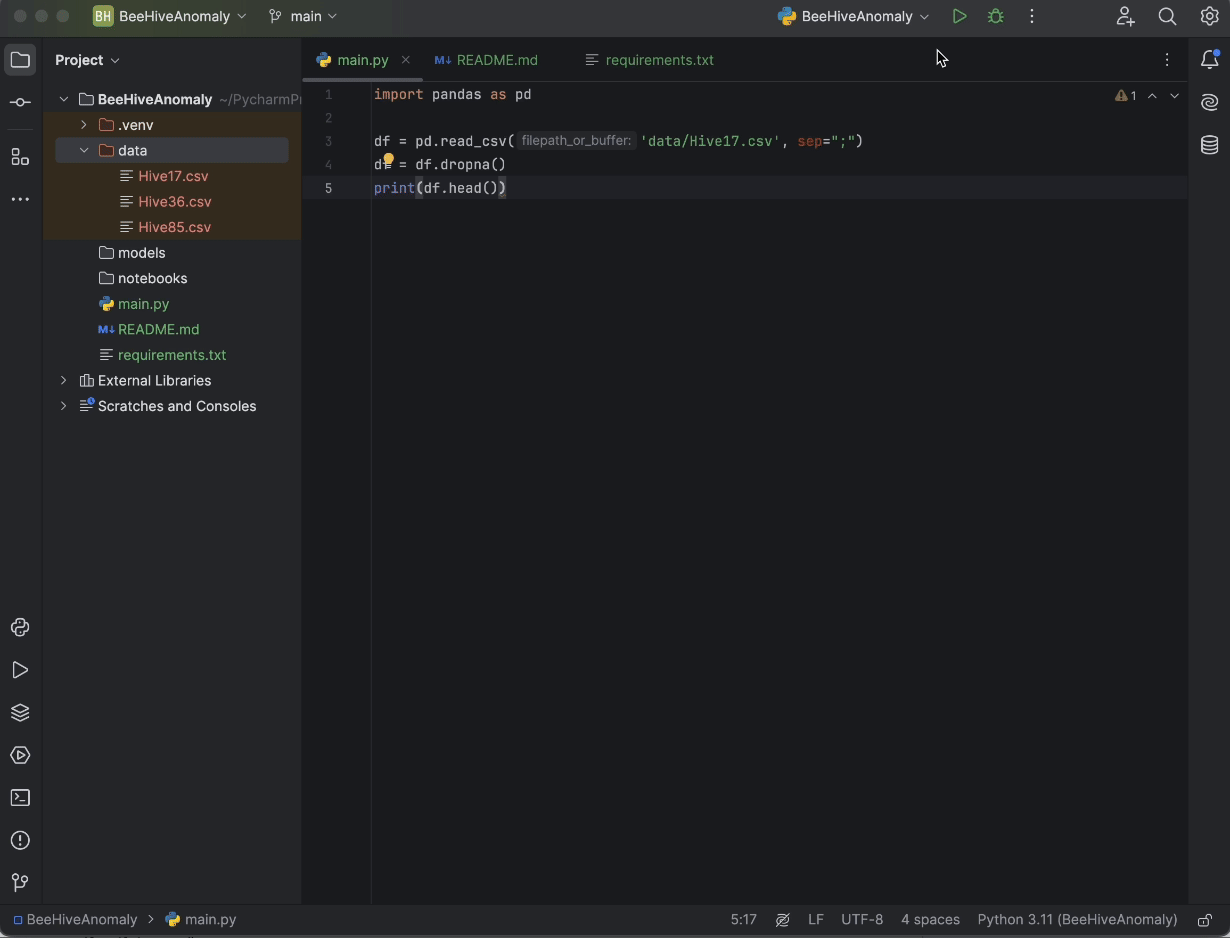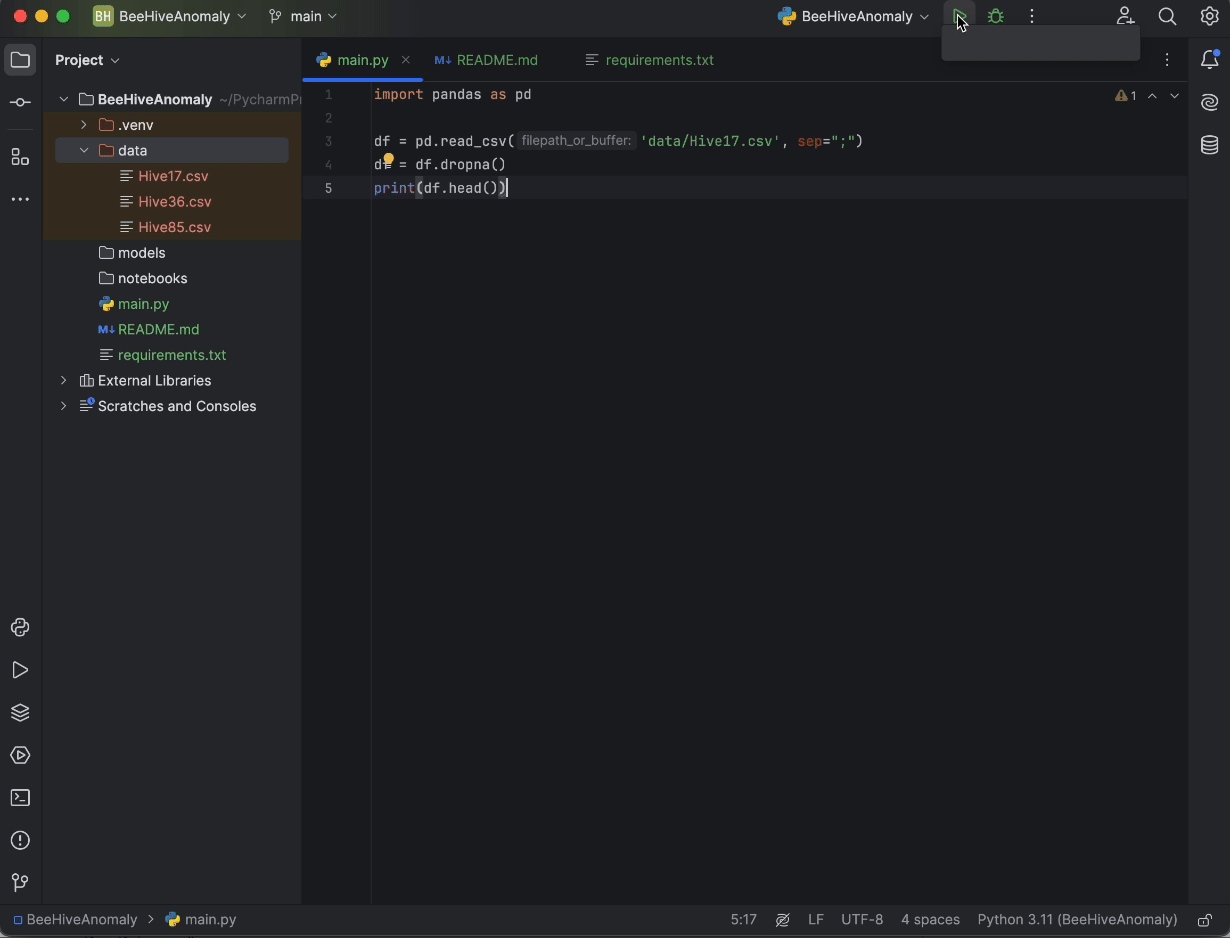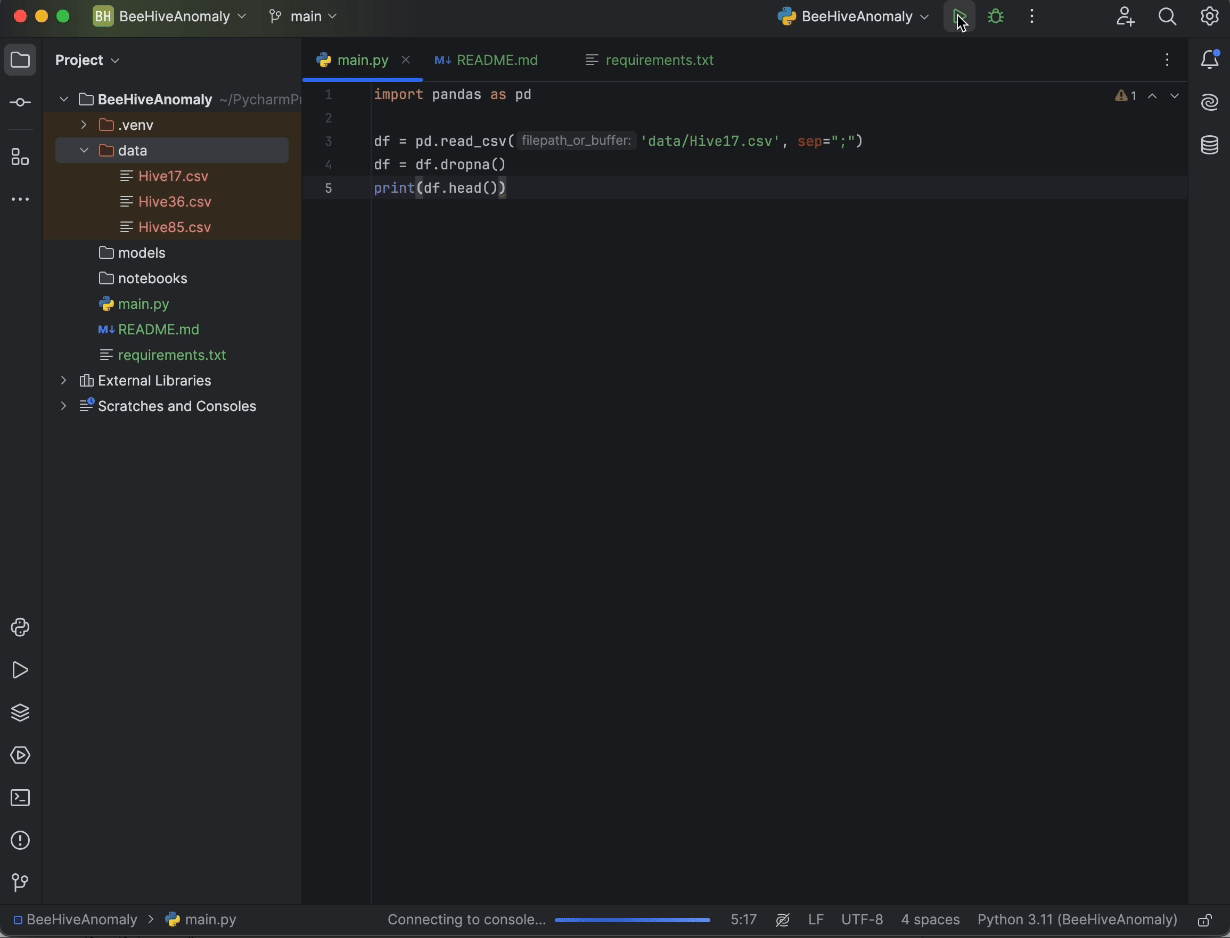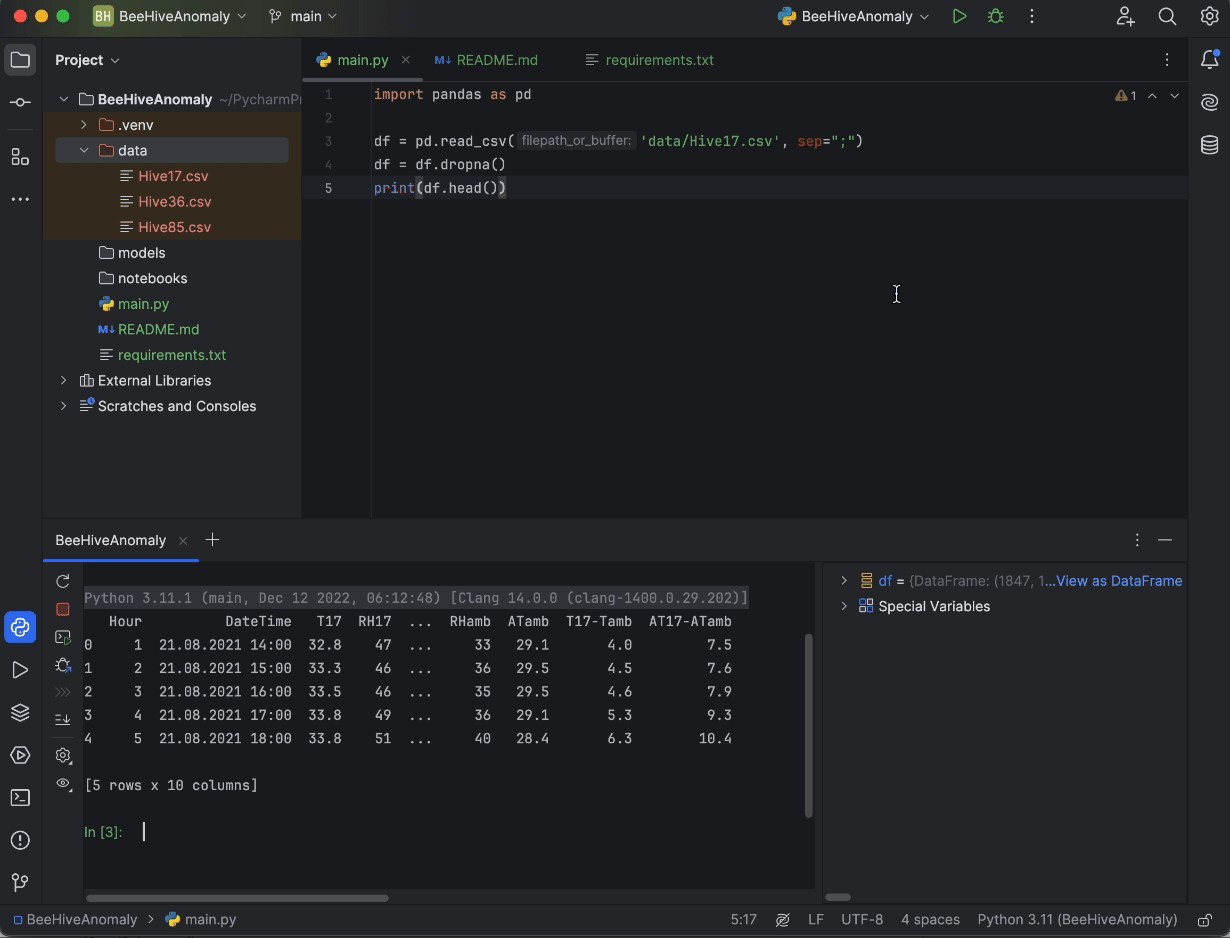
Kaggle から「Beehives」データセットをダウンロードします(こちらの GitHub リポジトリからもダウンロードできます)。 3 つすべての CSV を Data フォルダーに入れます。 次に、main.py に以下のコードを入力します。
import pandas as pd
df = pd.read_csv('data/Hive17.csv', sep=";")
df = df.dropna()
print(df.head())
最後に、画面の右上にある Run(実行)ボタンを押すと、Python コンソールでコードが実行され、どのようなデータかを確認できます。
4. データポイントを適合してグラフで検査する
scikit-learn の OneClassSVM を使用するため、以下のコードを使用して DecisionBoundaryDisplay と Matplotlib を一緒にインポートします。
from sklearn.svm import OneClassSVM from sklearn.inspection import DecisionBoundaryDisplay import matplotlib.pyplot as plt
データの説明を見ると、列 T17 は養蜂箱の温度を、RH17 は巣の相対湿度を表すことが分かります。 これらの 2 つの列の値を入力として抽出しましょう。
X = df[["T17", "RH17"]].values
次に、モデルを作成して適合します。 なお、最初はデフォルトの設定を試します。ご了承ください。
estimator = OneClassSVM().fit(X)
次に、決定境界とデータポイントを一緒に表示します。
disp = DecisionBoundaryDisplay.from_estimator(
estimator,
X,
response_method="decision_function",
plot_method="contour",
xlabel="Temperature", ylabel="Humidity",
levels=[0],
)
disp.ax_.scatter(X[:, 0], X[:, 1])
plt.show()
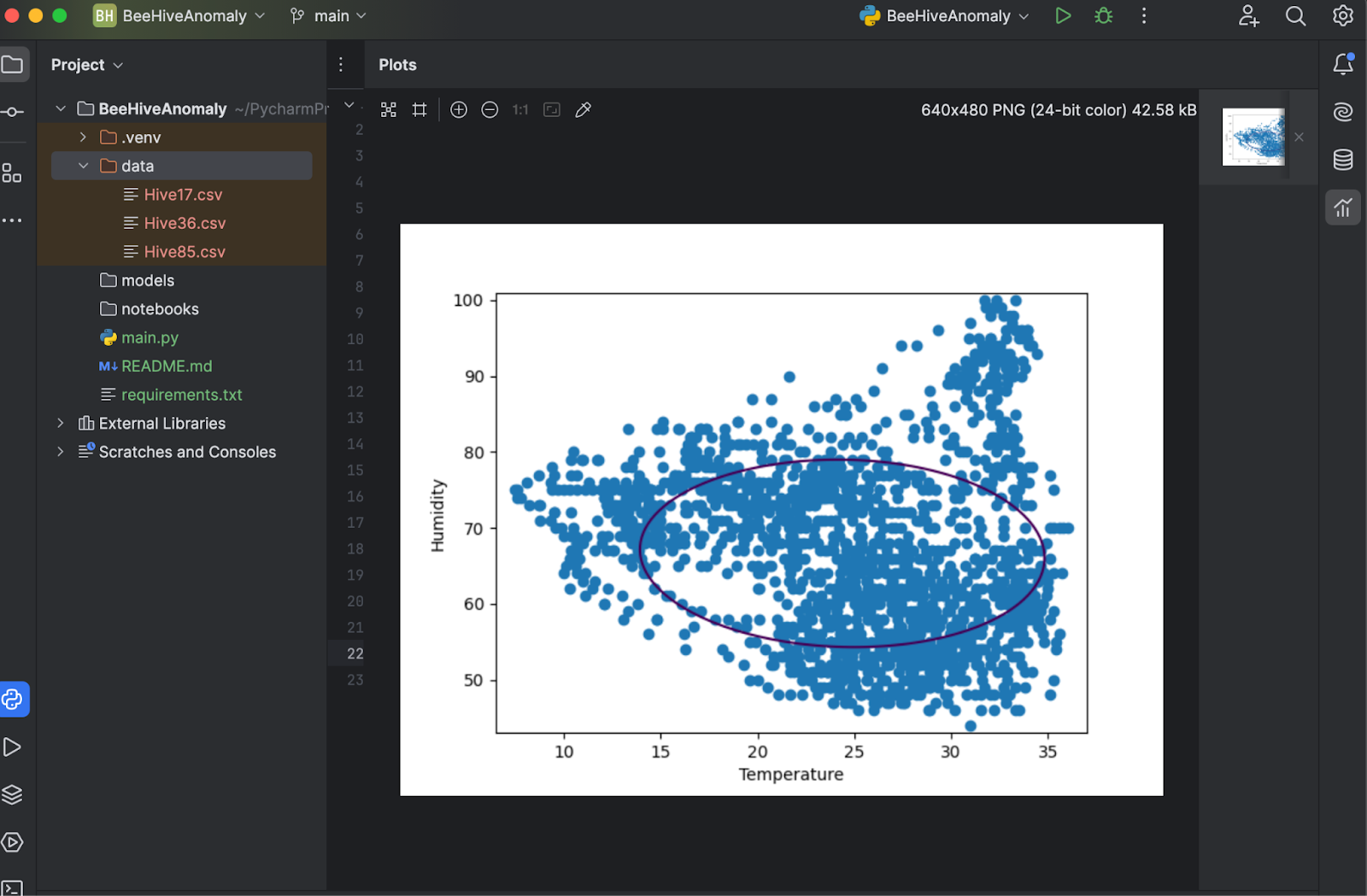
保存してもう一度 Run(実行)を押すと、プロットが検査用の別のウィンドウで表示されます。
5. ハイパーパラメーターをファインチューニングする
上記のプロットからわかるように、決定境界はデータポイントにあまりよく適合していません。 データポイントは楕円ではなく、いくつかの不規則な形状で構成されています。 モデルをファインチューニングするには、特定値の 「nu」と「gamma」を OneClassSVM モデルに提供する必要があります。 自分で試してみてもいいですが、何度かテストした限りでは、“nu=0.1, gamma=0.05” で最適な結果が得られるようです。
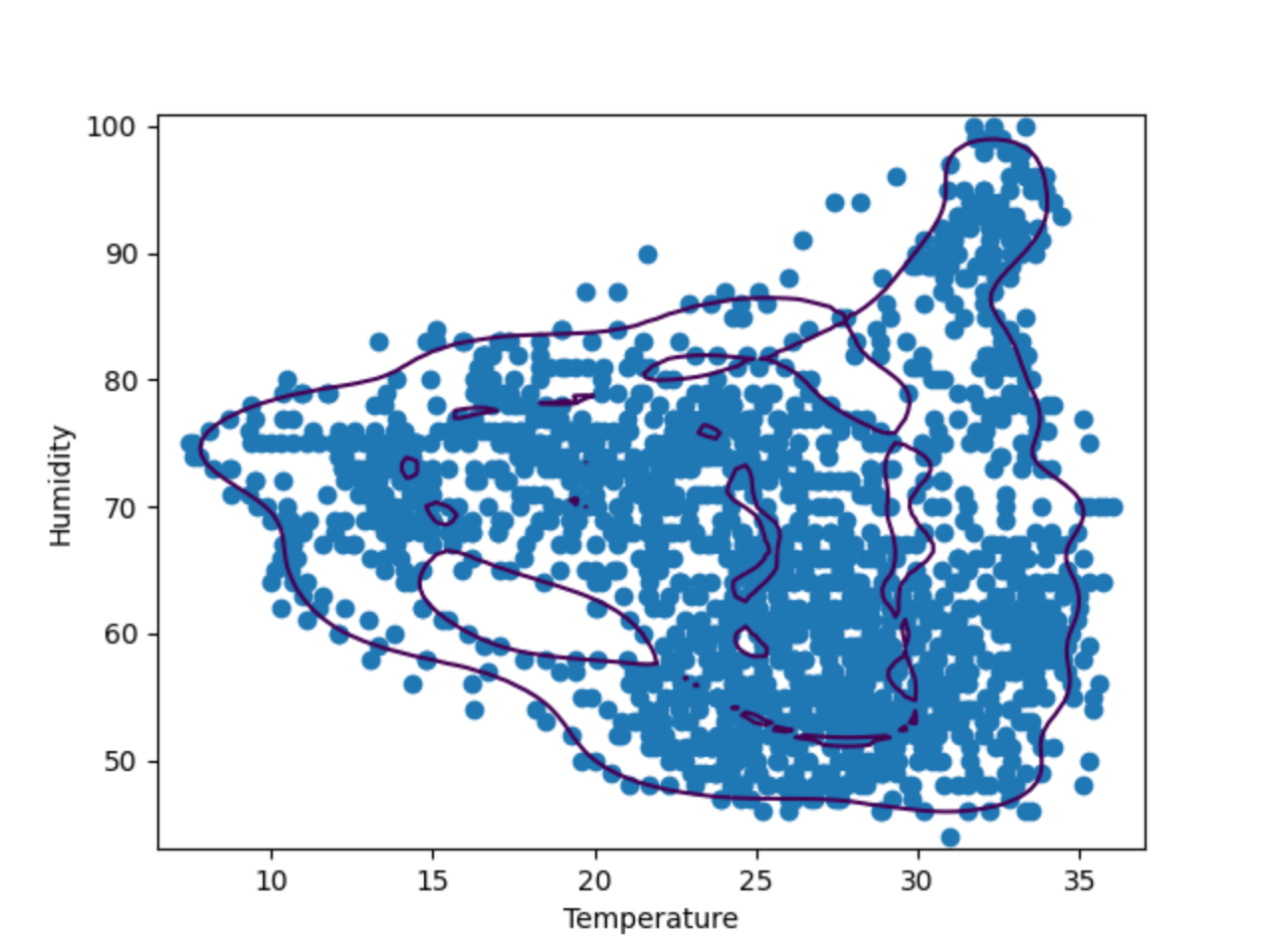
例: Isolation Forest
Isolation Forest は、より一般的な Random Forrest 分類手法に類似するアンサンブル手法です。 特徴量と値をランダムに選択してデータを分割することにより、多数の決定木が作成され、その木のルートから決定を行うノードまでのパスの長さがすべての木(そのため「森(Forest)」)にわたって平均化されます。 パスの長さの平均が短い場合、異常があることを示しています。
では、OneClassSVM と IsolationForest の結果を比較してみましょう。 それを行うため、2 つのアルゴリズムで作成された 2 つの決定境界のプロットを作成します。 以下の手順では、同じ養蜂箱 17 番のデータを使用して上記のスクリプトを基に構築していきます。
1. IsolationForest をインポートする
IsolationForest は、Scikit-learn の Ensemble カテゴリからインポートできます。
from sklearn.ensemble import IsolationForest
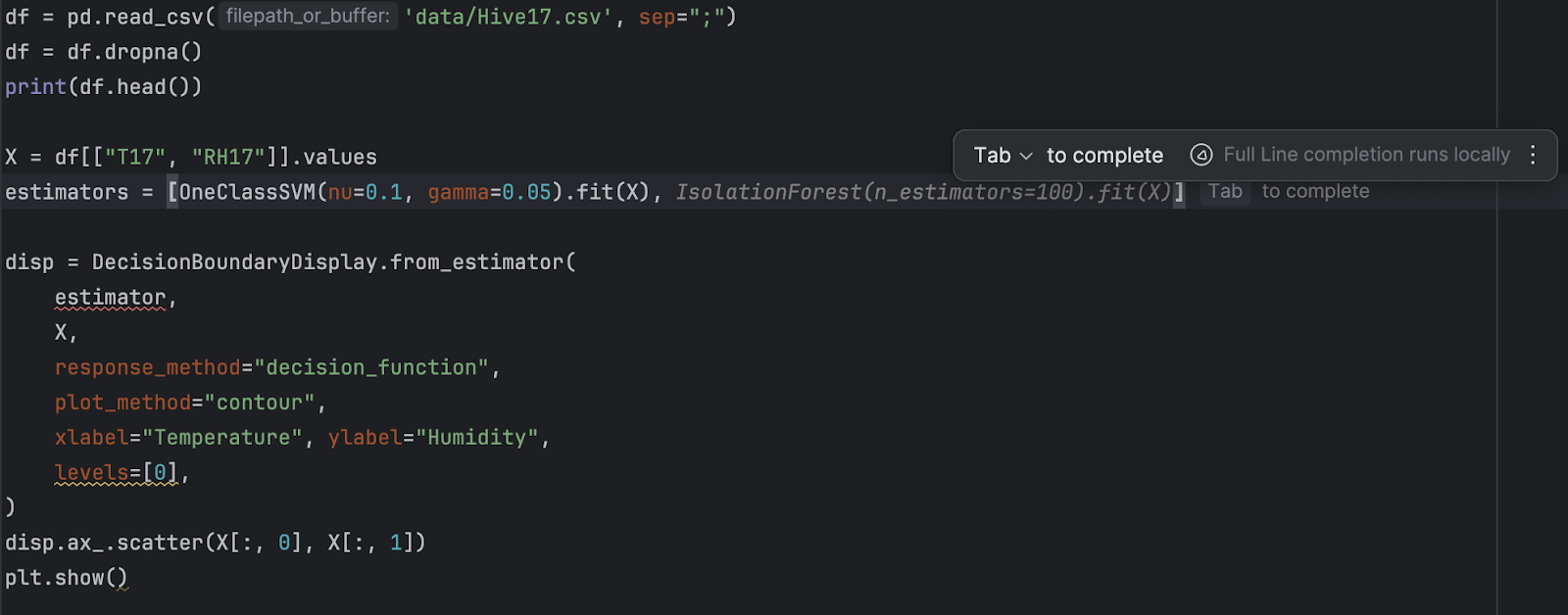
2. リファクタリングして新しい estimator を追加する
これ以降は 2 つの estimator が存在するため、それらをリストに格納します。
estimators = [
OneClassSVM(nu=0.1, gamma=0.05).fit(X),
IsolationForest(n_estimators=100).fit(X)
]
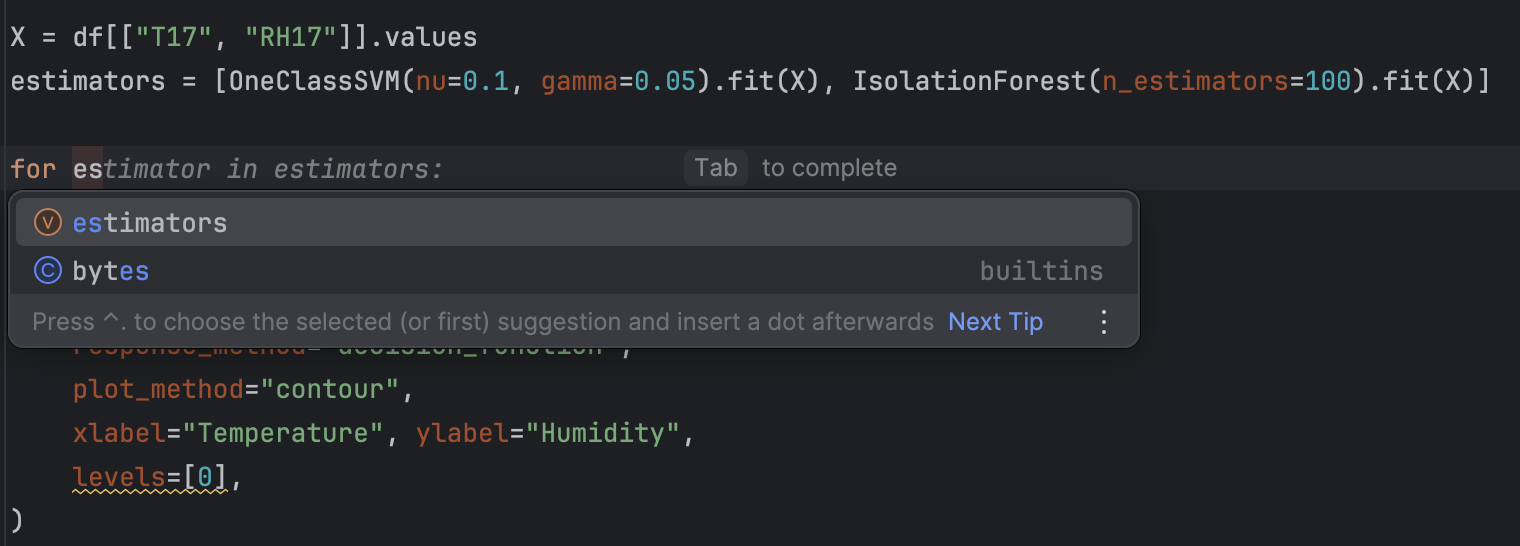
その後、for ループを使用してすべての estimator をループで処理します。
for estimator in estimators:
disp = DecisionBoundaryDisplay.from_estimator(
estimator,
X,
response_method="decision_function",
plot_method="contour",
xlabel="Temperature", ylabel="Humidity",
levels=[0],
)
disp.ax_.scatter(X[:, 0], X[:, 1])
plt.show()
最後にそれぞれのグラフにタイトルも追加し、検査しやすくします。 これを行うため、disp.ax_.scatter の後に以下のコードを追加します。
disp.ax_.set_title(
f"Decision boundary using {estimator.__class__.__name__}"
)
PyCharm を使用してリファクタリングすると自動補完の候補が表示されるため、非常に簡単だと思います。
3. コードを実行する
前と同じように、右上の Run(実行)ボタンを押すだけで簡単にコードを実行できます。 今回はコードを実行した後、2 つのグラフが得られます。
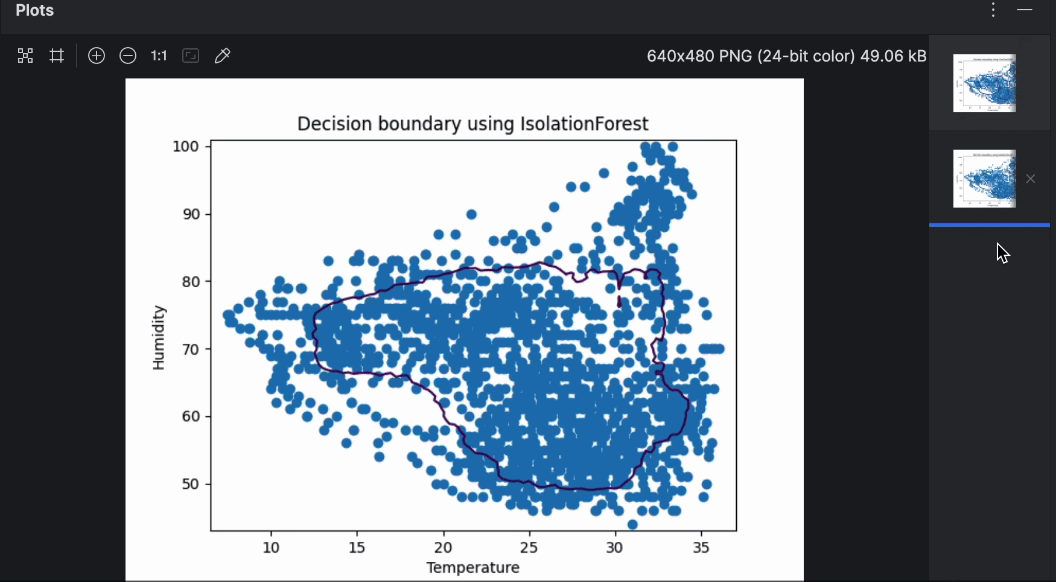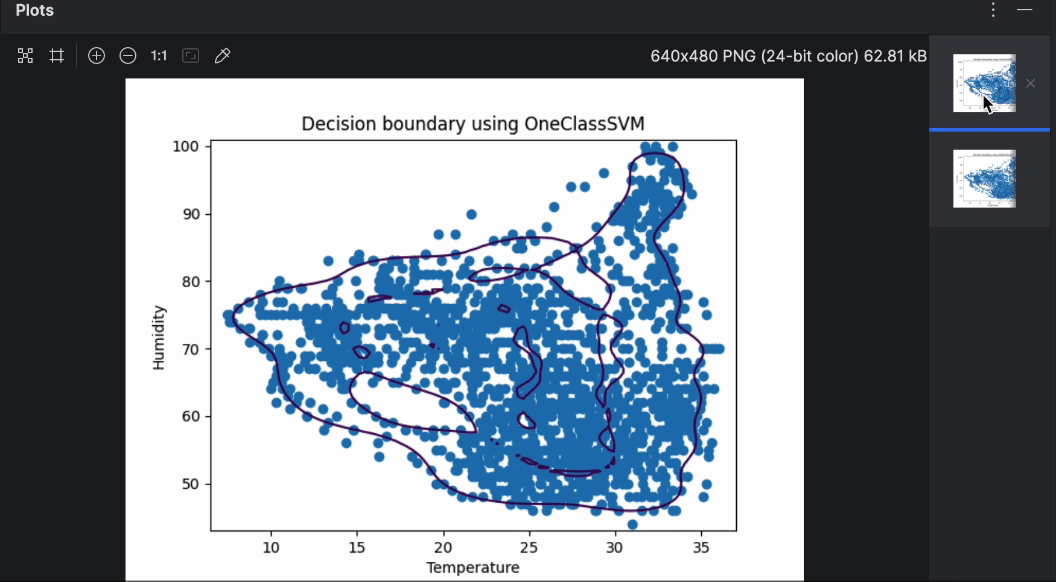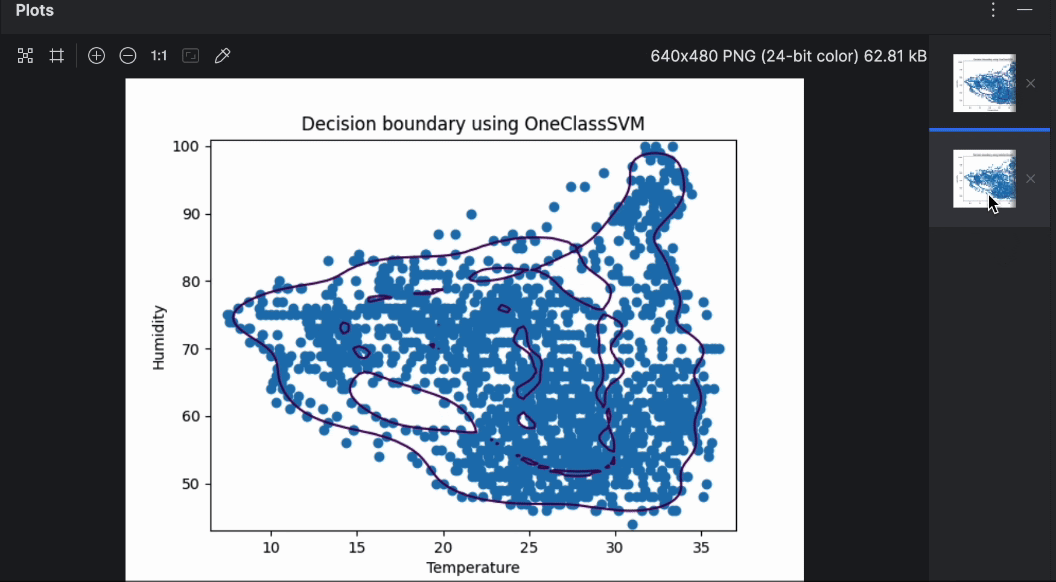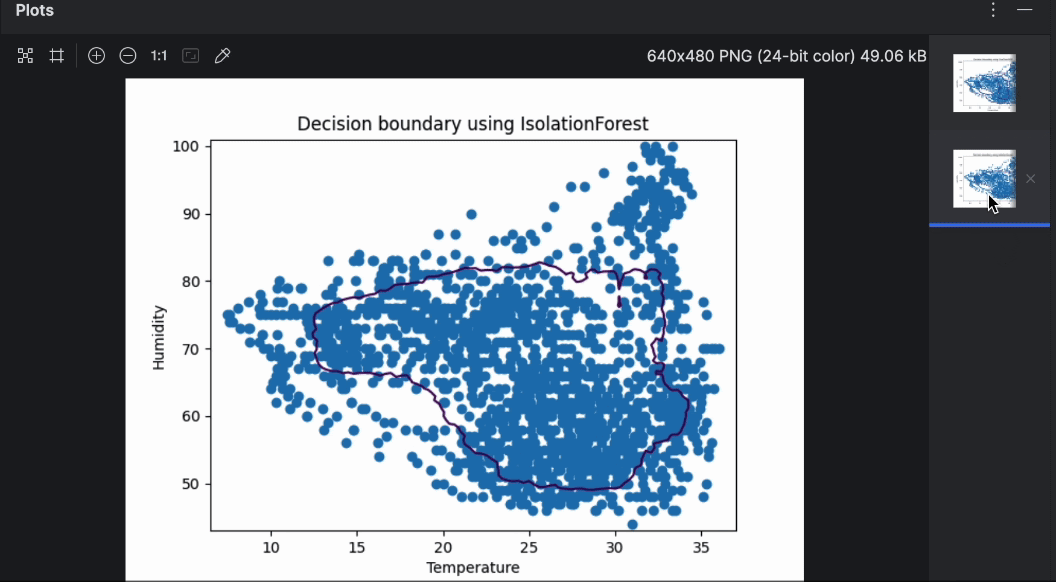
2 つのグラフは右側のプレビューで簡単に切り替えられます。 ご覧のとおり、決定境界は異なるアルゴリズムを使用するとかなり変わります。 異常検知を行う際にはさまざまなアルゴリズムとパラメーターを試し、ユースケースに最適なものを見つけることをお勧めします。
次のステップ: 時系列データの異常検知
この養蜂箱データのようにデータが時系列になっている場合、他にも異常を特定する方法があります。 時系列にはトレンドと期間があるため、このトレンドと期間のパターンから外れるデータはどれも異常として見なすことができます。 時系列で異常を検知するための一般的な手法には、STL 分解や LSTM 予測などがあります。
これらの手法を使って時系列の異常を検知する方法については、こちらのブログ記事をご覧ください。
まとめ
異常検知はビジネスインテリジェンスの重要な側面であることが実証されており、ビジネスのいくつかの分野では異常を特定して迅速な対応を指示できることが非常に重要です。 適切な機械学習モデルを使用して異常を自動的に検知することで、複雑かつ大量のデータを短時間で分析することができます。 このブログ記事では、One-Class SVM などの統計的手法を使って異常を特定する方法を紹介しました。
機械学習分野での PyCharm の使用についての詳細は、「PyCharm を使用して機械学習を学び始める」と「PyCharm で Jupyter ノートブックを使用する方法」をご覧ください。
PyCharm による異常の検知
PyCharm Professional で Jupyter プロジェクトを使用すると、多数のデータファイルとノートブックを使って異常検知プロジェクトを簡単に準備することができます。 PyCharm ではグラフ出力を生成して異常を検査することが可能で、プロットにも非常に簡単にアクセスできます。 自動補完による提案などのその他の機能を使用すれば、Scikit-learn モデルと Matplotlib プロットのすべての設定も簡単に操作できます。
PyCharm を使用してデータサイエンスプロジェクトをレベルアップしましょう。また、データサイエンスワークフローの合理化に役立つデータサイエンス機能もご覧ください。





