

Détection des anomalies par machine learning avec Python


Depuis plusieurs années, la plupart de nos applications sont pilotées par les volumes considérables de données que nous collectons et traitons. Certains d’entre nous parlent de l’ère des données. L’un des aspects essentiels du traitement d’un tel volume de données est la détection des anomalies, à savoir un ensemble de processus qui permettent d’identifier les valeurs aberrantes, comme les données qui sont au-delà des limites des prévisions et qui démontrent qu’un comportement est en dehors des normes. En termes de recherche scientifique, les points de données anormaux peuvent être source de problèmes techniques et devoir être supprimés lorsque vous établissez des conclusions ou, au contraire, peuvent déboucher sur de nouvelles découvertes.
Dans cet article de blog, nous allons voir pourquoi l’utilisation du machine learning pour la détection des anomalies est utile et explorer les techniques clés pour détecter les anomalies avec Python. Vous allez découvrir comment implémenter des méthodes populaires, telles que OneClassSVM et Isolation Forest, voir des exemples de méthodes de visualisation des résultats et comprendre comment les appliquer à des problèmes réels.
Dans quel cas la détection des anomalies est-elle utilisée ?
La détection des anomalies constitue également une facette fondamentale de la business intelligence moderne, car elle permet de comprendre ce qui pourrait mal se passer et d’identifier les problèmes potentiels. Voici quelques exemples de détection des anomalies dans les entreprises modernes.
Alertes de sécurité
Certaines cyber-attaques peuvent être détectées via la détection des anomalies. Par exemple, un pic du volume de requêtes peut signaler une attaque DDoS, tandis que des comportements suspects de connexion, tels que des échecs répétitifs, peuvent indiquer un accès non autorisé. La détection de comportements suspects peut refléter des menaces de cybersécurité et les entreprises peuvent agir en conséquence pour éviter les dommages ou les minimiser.
Détection des fraudes
Dans les organisations financières, par exemple, les banques peuvent utiliser la détection des anomalies pour mettre en évidence les activités suspectes sur un compte, ce qui peut indiquer des activités illégales, telles que le blanchiment d’argent ou le vol d’identité. Les transactions suspectes peuvent également être le signe d’une fraude à la carte bancaire.
Observabilité
L’une des pratiques les plus courantes pour les services web consiste à collecter des métriques de performances en temps réel du service en cas de comportement anormal du système. Par exemple, un pic d’utilisation de la mémoire peut signifier qu’une partie du système ne fonctionne pas correctement et que le service technique doit y remédier immédiatement pour éviter une interruption de service.
Pourquoi recourir au machine learning pour la détection des anomalies ?
Les méthodes statistiques traditionnelles permettent de trouver les anomalies, mais l’utilisation du machine learning en a véritablement révolutionné la procédure. Grâce aux algorithmes de machine learning, des données plus complexes (notamment avec des paramètres multiples) peuvent être analysées en une seule opération. Les techniques de machine learning permettent également d’analyser des données catégoriques qui sont difficiles à traiter avec les méthodes statistiques traditionnelles, plus adaptées aux données numériques.
Le plus souvent, ces algorithmes de détection des anomalies sont programmés et peuvent être déployés sous forme d’application (voir notre tutoriel FastAPI pour le machine learning) et exécutés à la demande ou à des intervalles spécifiques pour rechercher les anomalies. Cela signifie qu’ils peuvent déclencher des actions immédiates au sein de l’entreprise, voire être utilisés comme outils par les équipes de business intelligence, afin de vérifier et d’ajuster les stratégies.
Types de techniques et d’algorithmes de détection des anomalies
La détection d’anomalie peut être divisée en deux grandes catégories : la détection des anomalies et la détection des nouveautés.
Détection des anomalies
La détection des anomalies est parfois appelée détection d’anomalies non supervisée, car il est admis que les données d’entraînement contiennent un certain nombre d’anomalies non détectées, et donc non étiquetées, et que la meilleure approche consiste à employer des algorithmes de machine learning non supervisés pour les identifier. Une partie de ces algorithmes incluent les SVM (Support Vector Machines) à classe unique, Isolation Forest, LOF (Local Outlier Factor) et EE (Elliptic Envelope).
Détection des nouveautés
De son côté, la détection des nouveautés est parfois appelée « détection d’anomalies semi-supervisée ». Dans la mesure où nous partons de l’hypothèse selon laquelle les données d’entraînement ne contiennent pas seulement des anomalies, elles sont toutes étiquetées comme normales. L’objectif est de déterminer si les nouvelles données constituent une anomalie ou non, ce qui est parfois appelé une nouveauté. Les algorithmes intervenant dans la détection des anomalies peuvent également être utilisés pour la détection des nouveautés, à condition que les données d’entraînement ne contiennent pas d’anomalies.
En dehors de la détection des anomalies et des nouveautés que nous venons de voir, il est également très courant de procéder à la détection des anomalies dans les séries chronologiques. Toutefois, dans la mesure où l’approche et la technique appliquées aux séries chronologiques diffèrent des algorithmes mentionnés ci-dessus, nous allons les examiner plus en détail ultérieurement.
Exemple de code : recherche d’anomalies dans l’ensemble de données Beehives
Dans cet article de blog, nous allons utiliser cet ensemble de données Beehives comme exemple pour détecter les anomalies au niveau des ruches. Cet ensemble de données fournit différentes mesures de la ruche (avec notamment la température et l’humidité relative) à différents moments.
Dans cet article, nous allons voir deux méthodes très différentes de découverte des anomalies. Il s’agit de OneClassSVM, qui est basée sur la technologie SVM (support vector machine), que nous allons utiliser pour dessiner des frontières de décision, et Isolation Forest, qui est une méthode d’ensemble similaire à Random Forest.
Exemple : OneClassSVM
Dans ce premier exemple, nous allons utiliser les données de la ruche 17 et faire l’hypothèse que les abeilles maintiennent la température de la ruche à un niveau constant et adapté à la colonie. Nous pourrons vérifier cette prémisse et déterminer si la ruche est exposée à des anomalies de température et d’humidité relative. Nous allons utiliser OneClassSVM pour ajuster le modèle aux données et examiner les frontières de décision sur un nuage de points.
Le SVM de OneClassSVM se rapporte à support vector machine, qui est un algorithme populaire de machine learning pour la classification et les régressions. La méthode SVM permet de classer les points de données dans les dimensions élevées, en choisissant un noyau et un paramètre scalaire pour définir une frontière. Nous pouvons créer une frontière de décision incluant la plupart des points de données (données normales), tout en conservant un petit nombre d’anomalies en dehors des frontières pour représenter la probabilité (nu) de découverte d’une nouvelle anomalie. La méthode d’utilisation de SVM pour la détection d’anomalie est couverte par une publication de Scholkopf et al. intitulée Estimating the Support of a High-Dimensional Distribution (en anglais uniquement).
1. Créer un projet Jupyter
Lors de la création d’un projet dans PyCharm (Professional 2024.2.2), sélectionnez Jupyter dans la section Python.
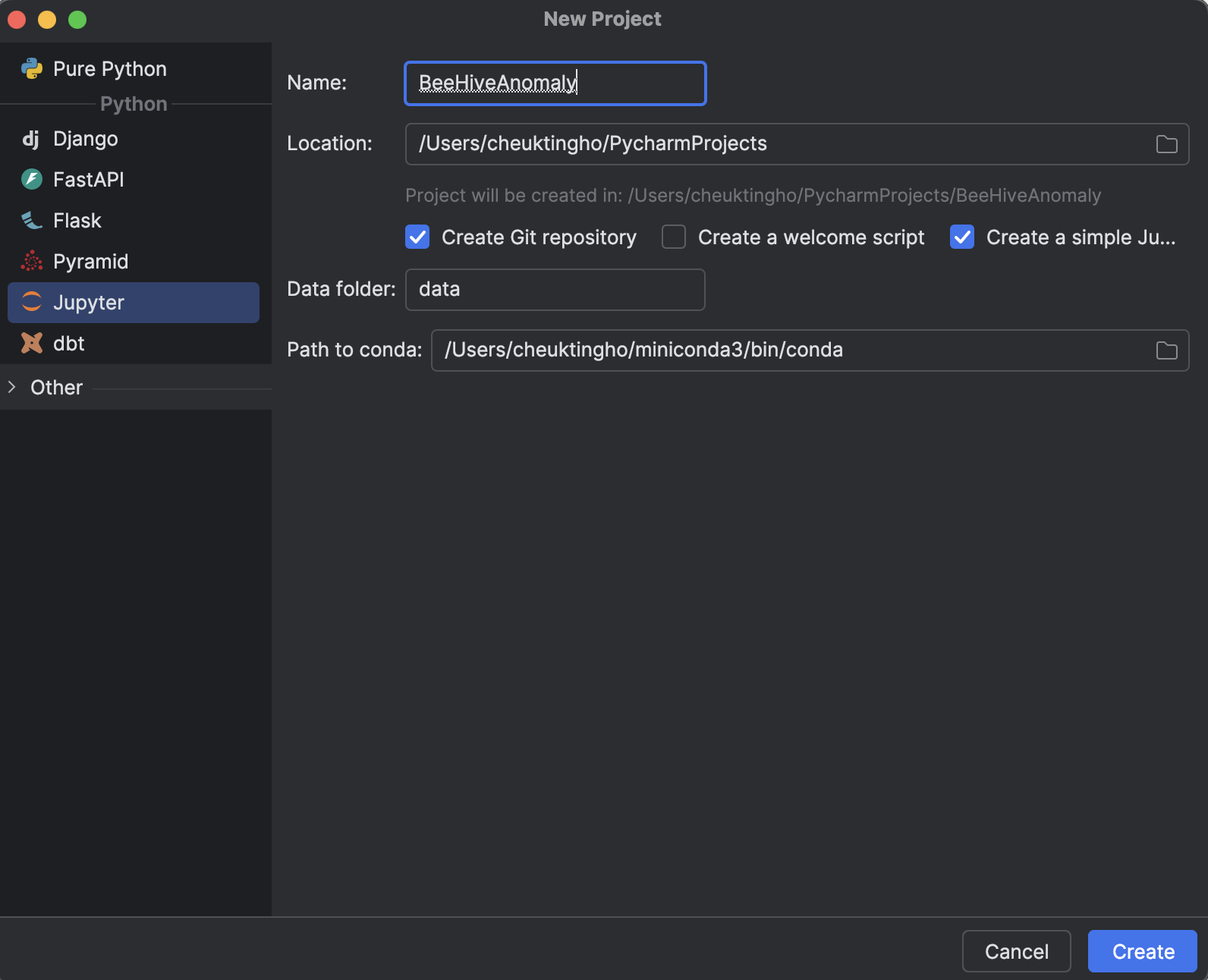
L’avantage de l’utilisation d’un projet Jupyter (ce que l’on appelait précédemment un projet scientifique) dans PyCharm réside dans le fait que la structure de fichiers est générée automatiquement, ce qui inclut deux dossiers, un pour stocker vos données et un autre pour stocker tous les notebooks Jupyter, afin de conserver toutes vos expériences au même endroit.
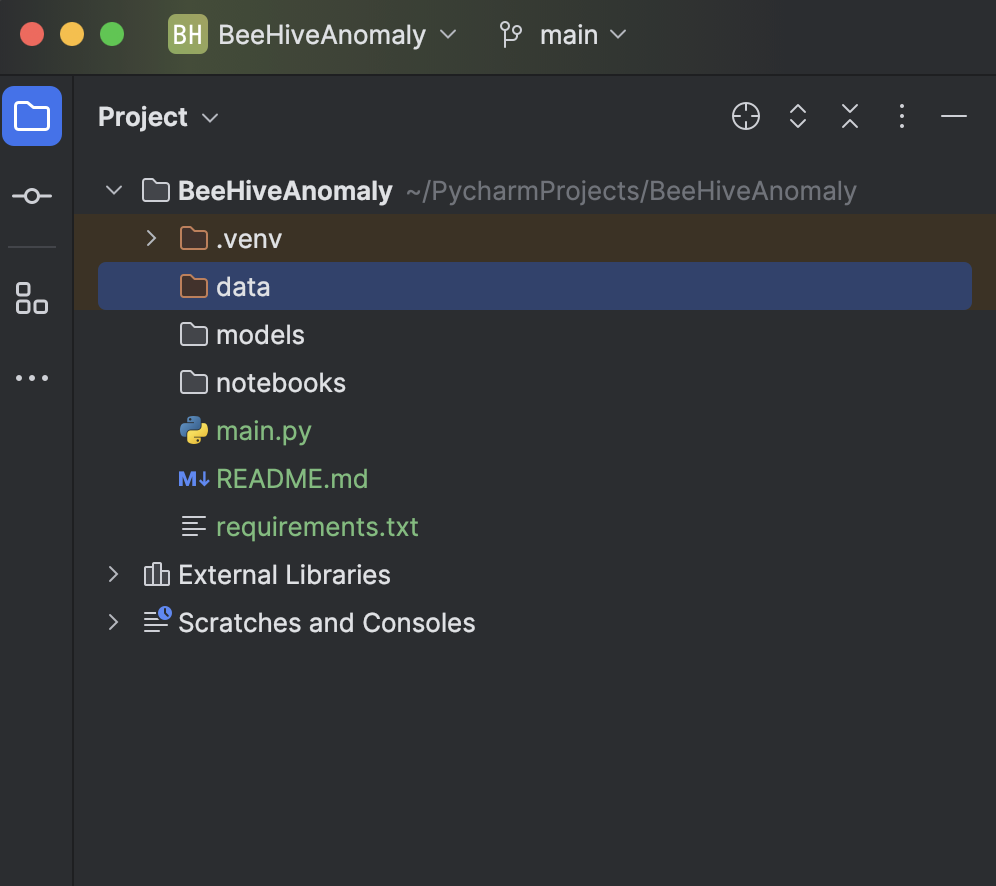
Un autre avantage considérable est que vous pouvez rendre les graphiques très facilement avec Matplotlib. Vous verrez cela dans les instructions ci-dessous.
2. Installation des dépendances
Téléchargez le fichier requirements.txt depuis le référentiel GitHub voulu. Lorsque vous le placez dans le répertoire du projet et l’ouvrez dans PyCharm, une invite vous demande d’installer les bibliothèques manquantes.
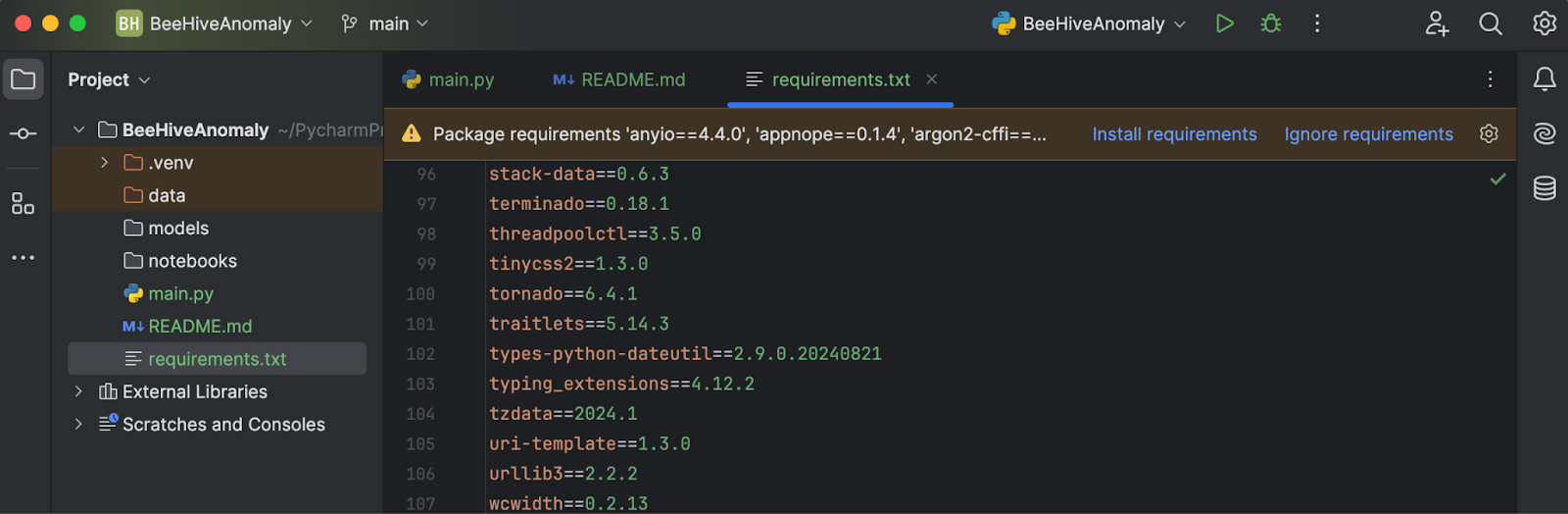
Cliquez sur Install requirements et toutes les dépendances seront installées automatiquement. Dans ce projet, nous utilisons Python 3.11.1.
3. Importation et inspection des données
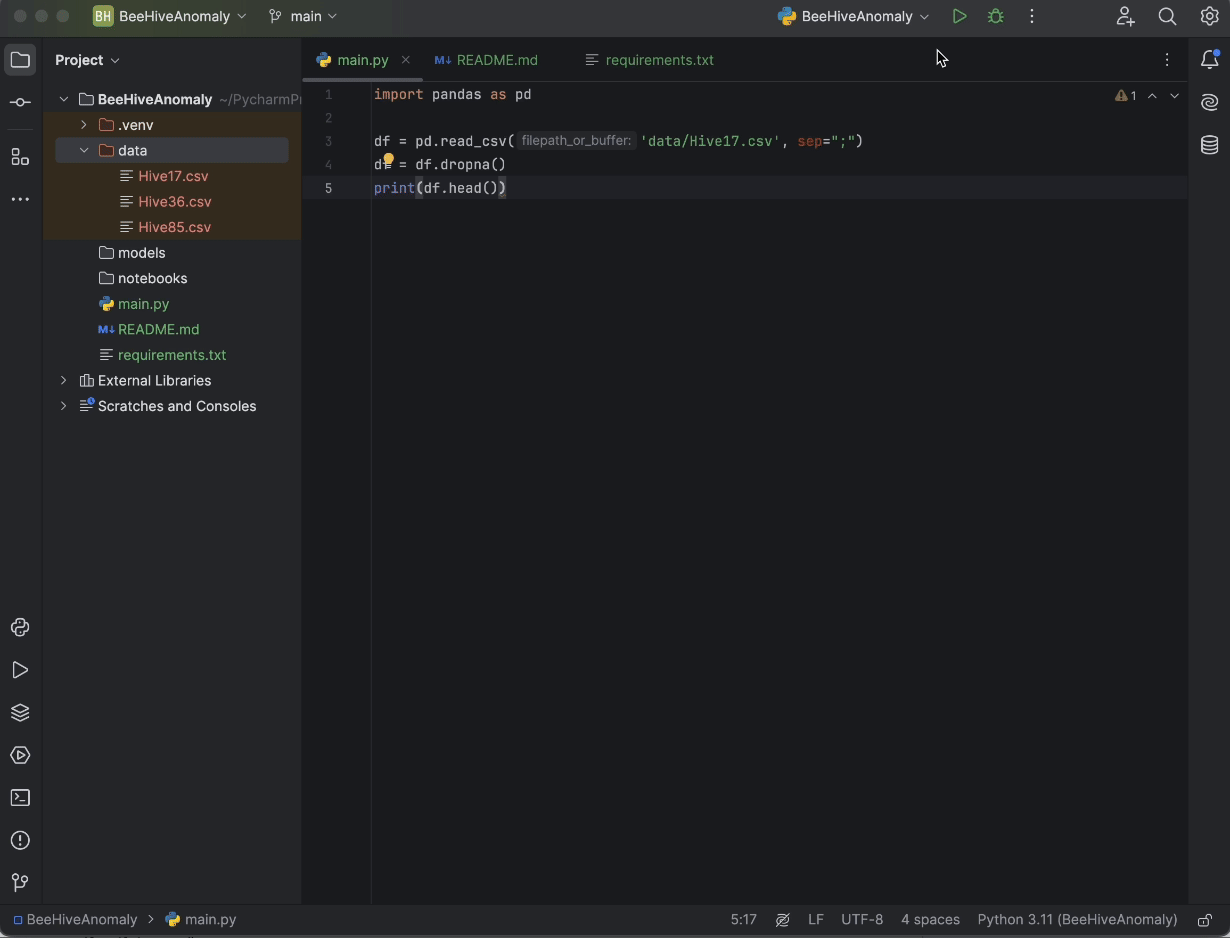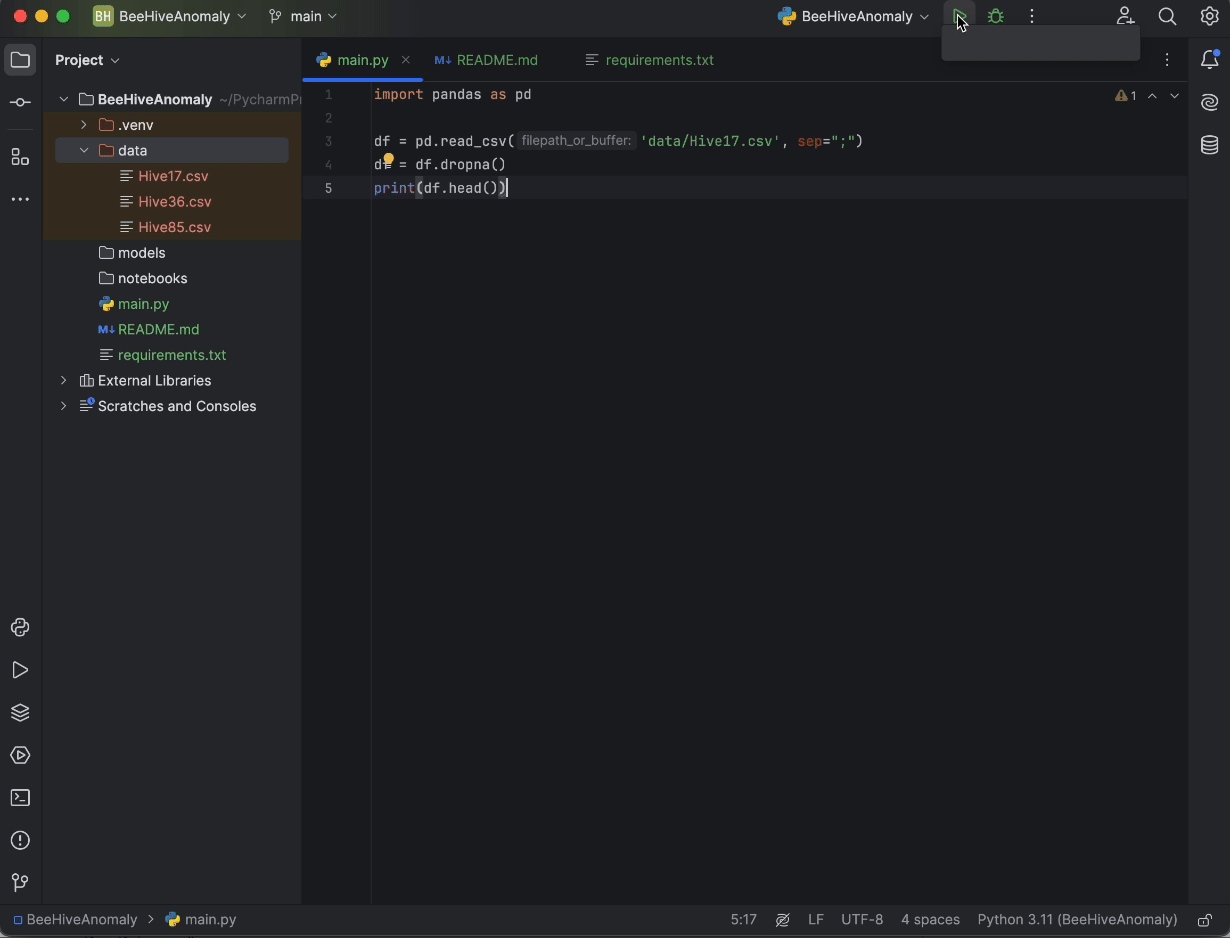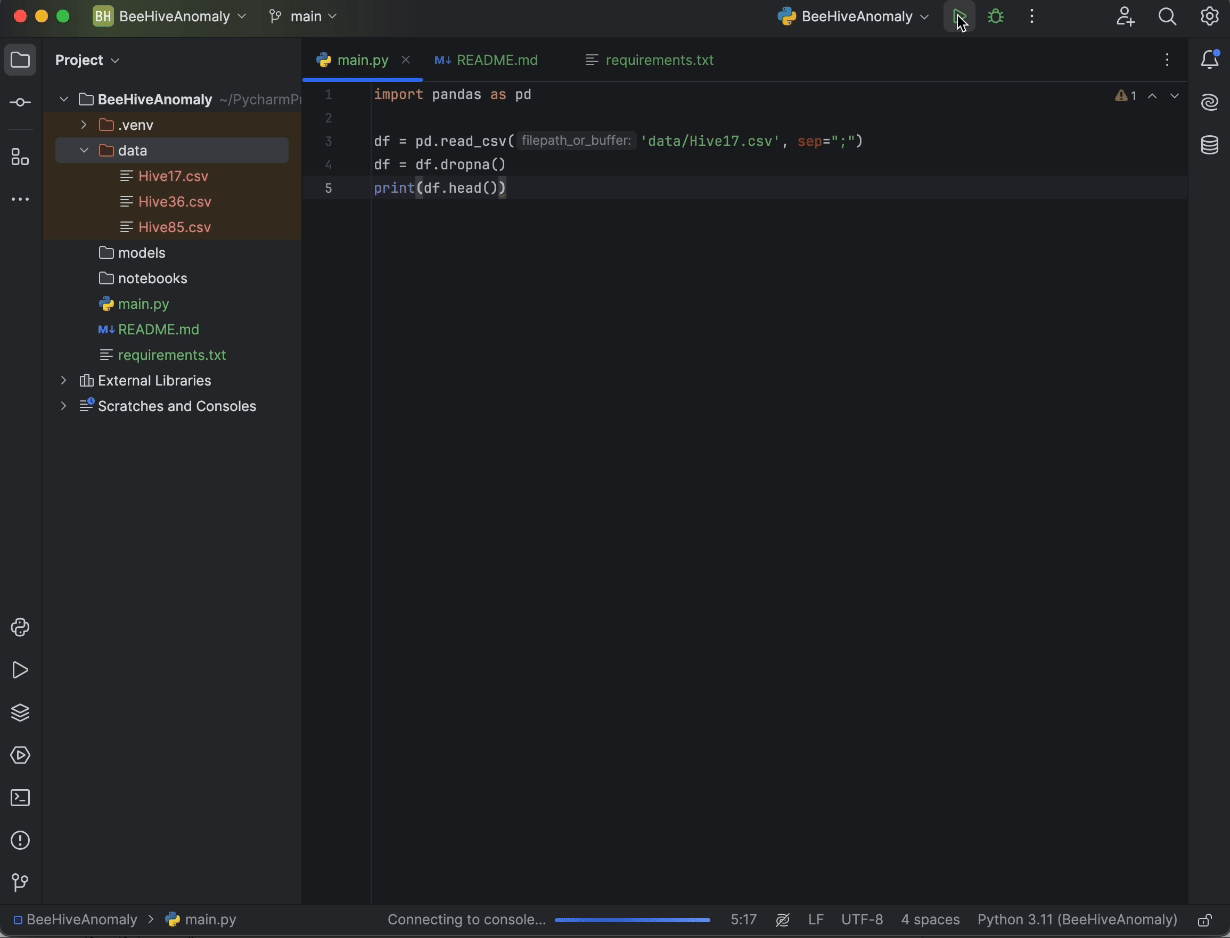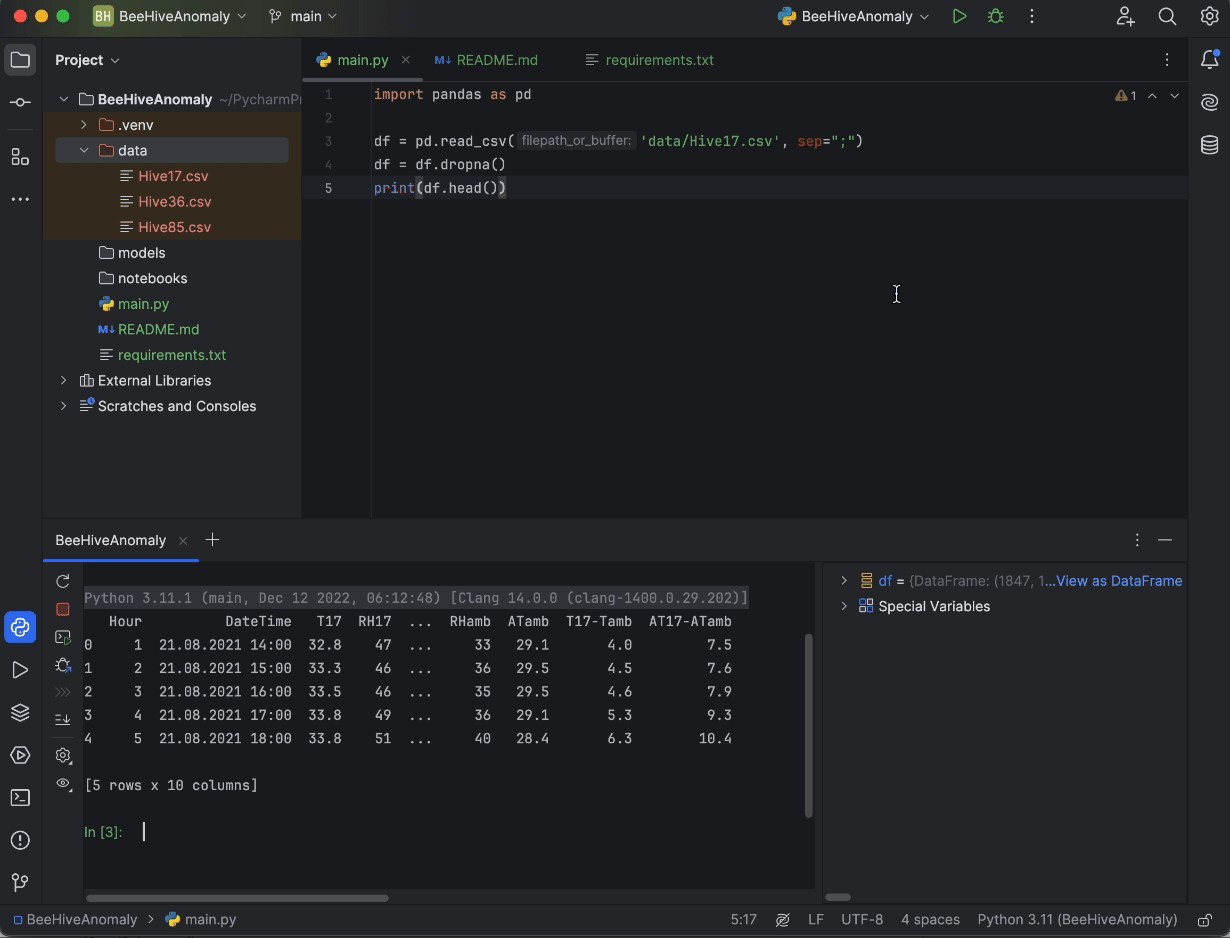
Vous pouvez télécharger l’ensemble de données « Beehives » depuis Kaggle ou ce référentiel GitHub. Placez les trois CSV dans le dossier Data. Ensuite, dans main.py, saisissez le code suivant :
import pandas as pd
df = pd.read_csv('data/Hive17.csv', sep=";")
df = df.dropna()
print(df.head())
Enfin, appuyez sur le bouton Run dans le coin supérieur droit de l’écran, ce qui exécute le code dans la console Python et permet d’avoir un aperçu de nos données.
4. Ajustement et inspection des points de données sur un graphique
Dans la mesure où nous utilisons OneClassSVM de scikit-learn, nous allons l’importer avec DecisionBoundaryDisplay et Matplotlib en utilisant le code ci-dessous :
from sklearn.svm import OneClassSVM from sklearn.inspection import DecisionBoundaryDisplay import matplotlib.pyplot as plt
Conformément à la description des données, nous savons que la colonne T17 représente la température de la ruche, tandis que RH17 reflète son humidité relative. Nous allons extraire la valeur de ces deux colonnes en tant qu’entrée :
X = df[["T17", "RH17"]].values
Ensuite, nous allons créer et ajuster le modèle. Il est à noter que nous allons essayer les paramètres par défaut en premier :
estimator = OneClassSVM().fit(X)
Ensuite, nous allons afficher la frontière de décision, ainsi que les points de données :
disp = DecisionBoundaryDisplay.from_estimator(
estimator,
X,
response_method="decision_function",
plot_method="contour",
xlabel="Temperature", ylabel="Humidity",
levels=[0],
)
disp.ax_.scatter(X[:, 0], X[:, 1])
plt.show()
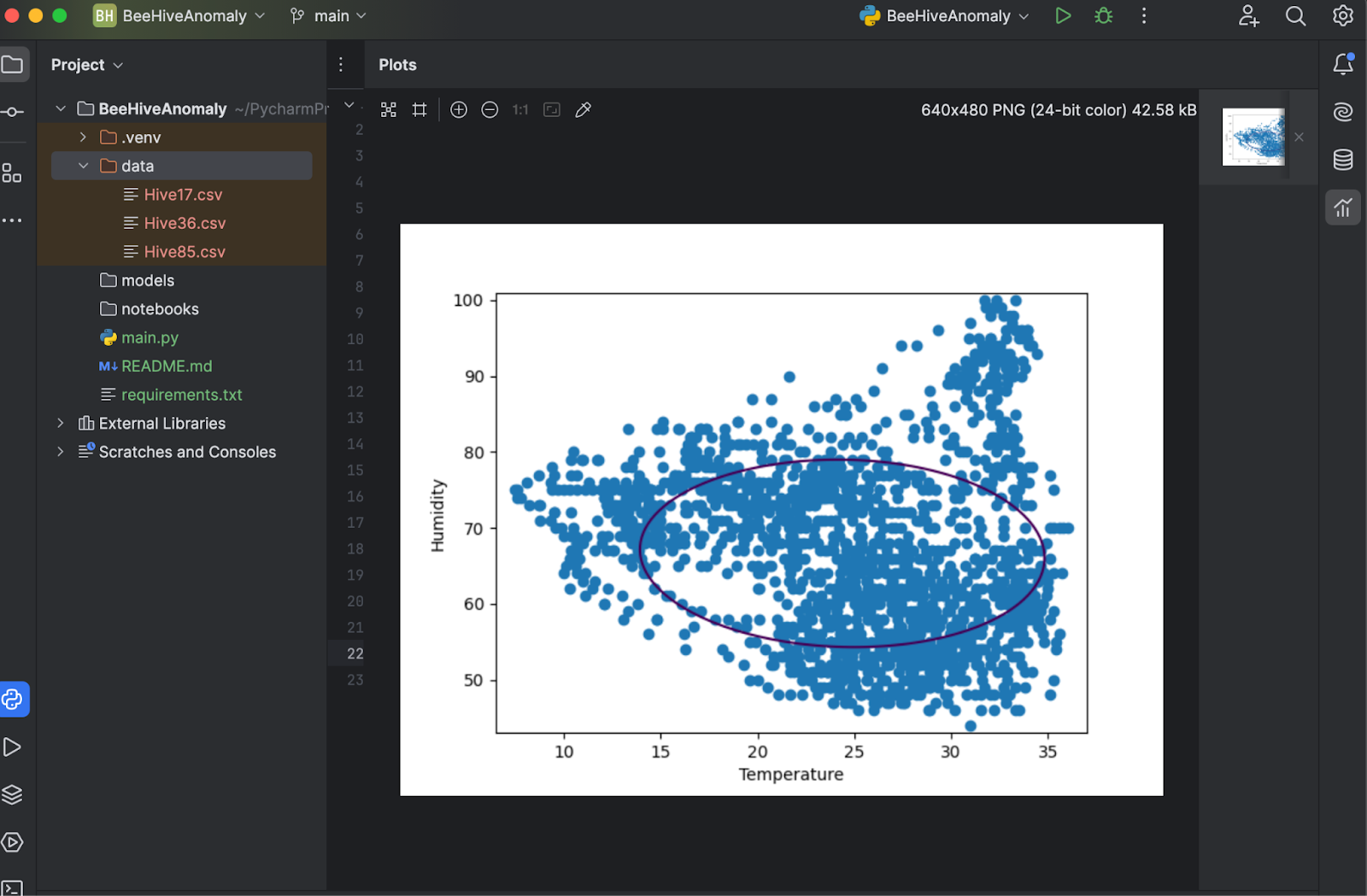
Maintenant, enregistrons et appuyons à nouveau sur Run, ce qui affiche le tracé dans une autre fenêtre où vous pouvez l’inspecter.
5. Optimisation des hyperparamètres
Comme le démontre le tracé ci-dessus, la frontière de décision ne suit pas les points de données. Les points de données consistent en deux formes irrégulières au lieu d’un ovale. Pour optimiser notre modèle, nous devons fournir des valeurs « nu » et « gamma » spécifiques au modèle OneClassSVM. Vous pouvez faire un essai, mais après deux ou trois tentatives, il semble que « nu=0.1, gamma=0.05 » donne le meilleur résultat.
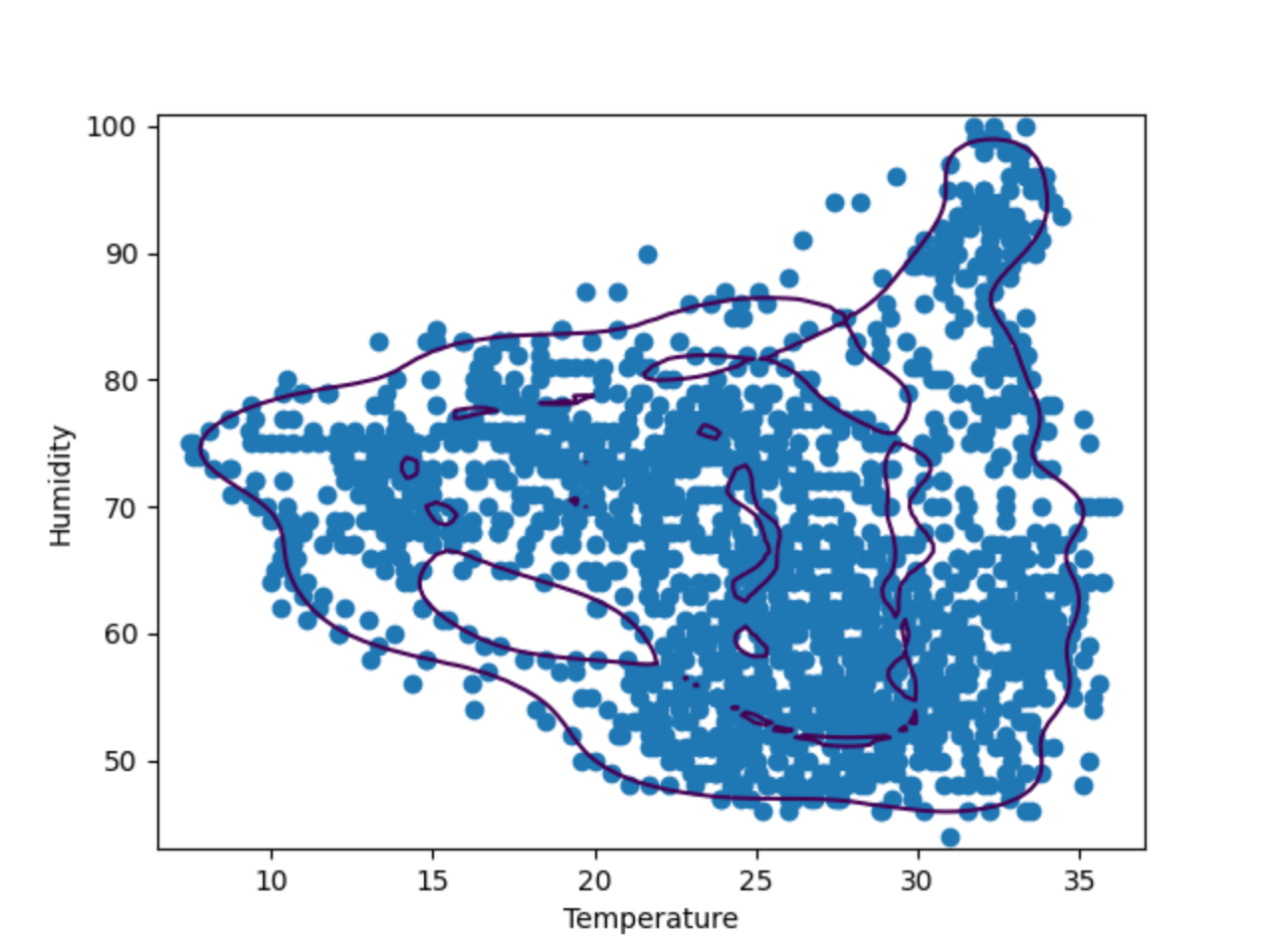
Exemple : Isolation Forest
Isolation Forest est une méthode basée sur un ensemble, similaire à la méthode de classification Random Forest qui est plus populaire. La création au hasard de fonctionnalités et de valeurs de séparation crée de nombreux arbres décisionnels, et la moyenne de la longueur du chemin entre la racine et les nœuds décisionnels de l’ensemble des arbres sera calculée, d’où le terme « forest ». Un chemin moyen court dénote des anomalies.
Désormais, nous allons comparer le résultat de OneClassSVM avec IsolationForest. Pour ce faire, nous allons créer deux tracés de frontières de décision générés par les deux algorithmes. Dans les étapes suivantes, nous allons développer le script ci-dessus en utilisant toujours les données de la ruche 17.
1. Importation d’IsolationForest
IsolationForest peut être importé depuis les catégories d’ensemble de Scikit-learn :
from sklearn.ensemble import IsolationForest
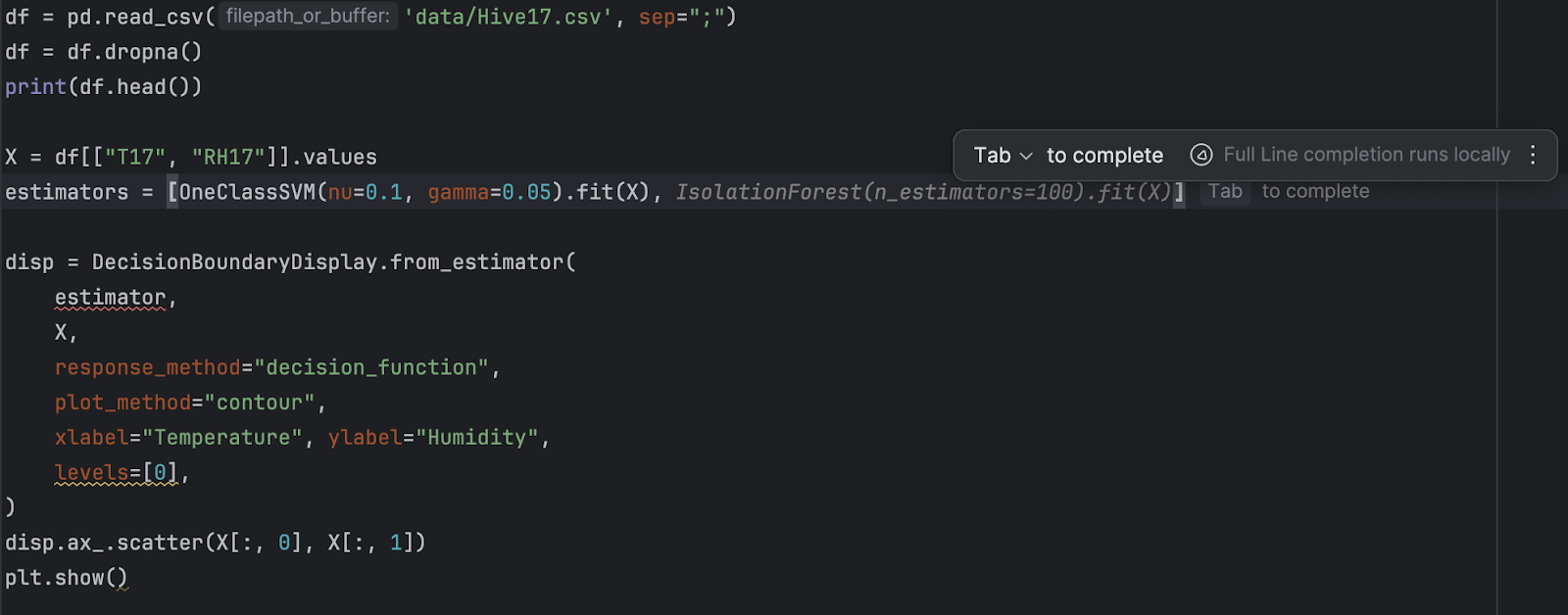
2. Refactorisation et ajout d’un nouvel estimateur
Dans la mesure où nous aurons deux estimateurs différents, nous allons les placer dans une liste :
estimators = [
OneClassSVM(nu=0.1, gamma=0.05).fit(X),
IsolationForest(n_estimators=100).fit(X)
]
Ensuite, nous allons utiliser une boucle for pour traiter tous les estimateurs.
for estimator in estimators:
disp = DecisionBoundaryDisplay.from_estimator(
estimator,
X,
response_method="decision_function",
plot_method="contour",
xlabel="Temperature", ylabel="Humidity",
levels=[0],
)
disp.ax_.scatter(X[:, 0], X[:, 1])
plt.show()
Pour donner une touche finale, nous allons aussi donner un titre à chacun des graphiques pour simplifier l’inspection. Pour ce faire, nous allons ajouter ce qui suit après disp.ax_.scatter :
disp.ax_.set_title(
f"Decision boundary using {estimator.__class__.__name__}"
)
Vous trouverez peut-être que la refactorisation avec PyCharm est très simple grâce aux suggestions de saisie semi-automatique proposées.
3. Exécution du code
Comme précédemment, l’exécution du code se fait par simple pression du bouton Run dans le coin supérieur droit. Après avoir exécuté le code, nous devons obtenir deux graphiques.
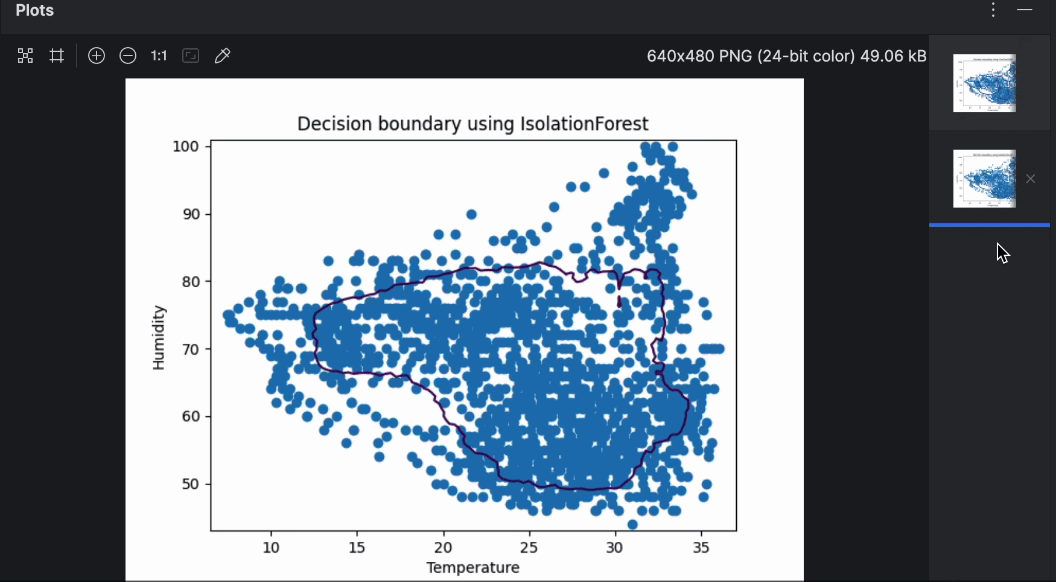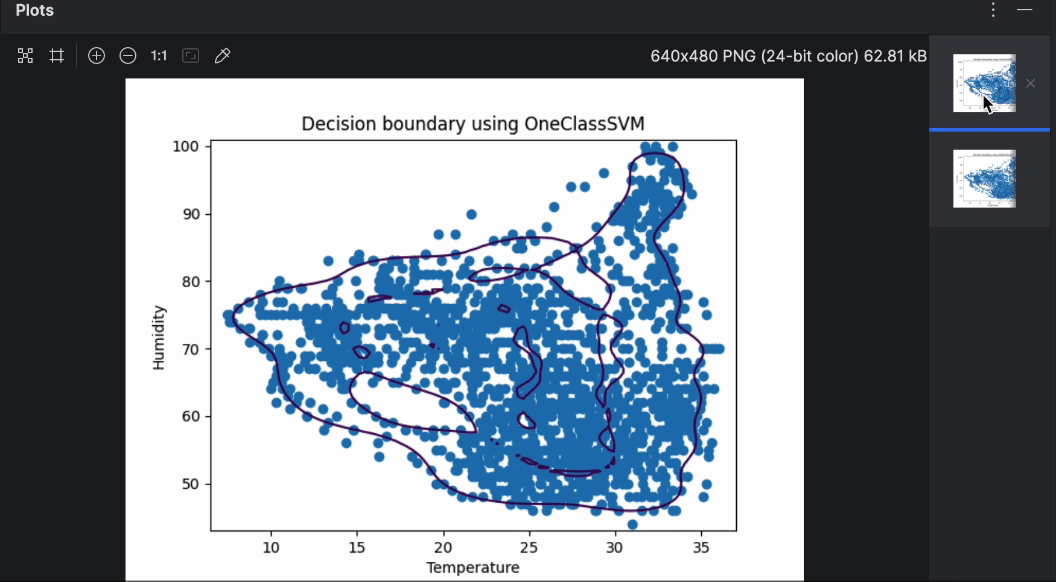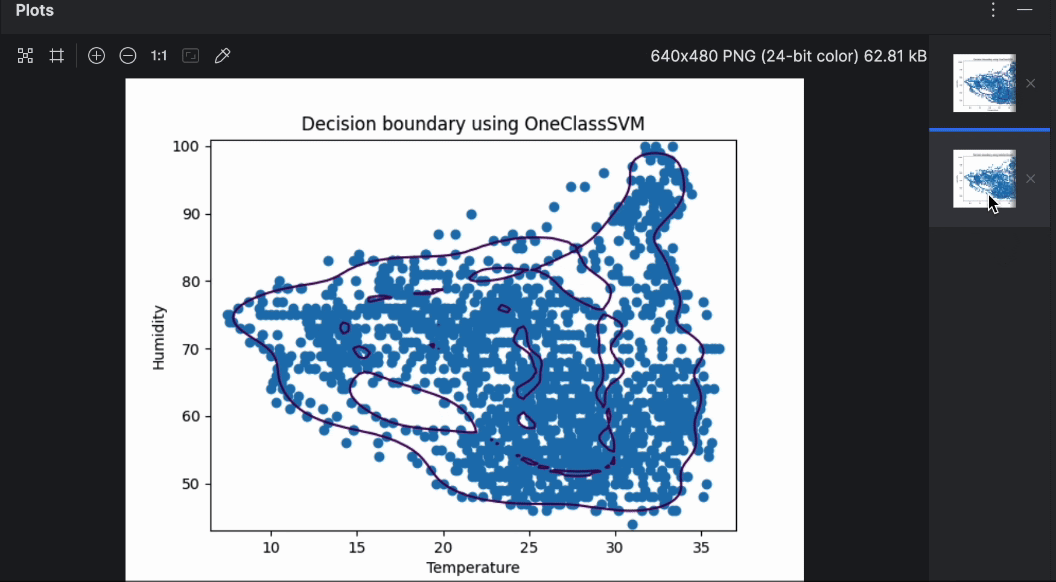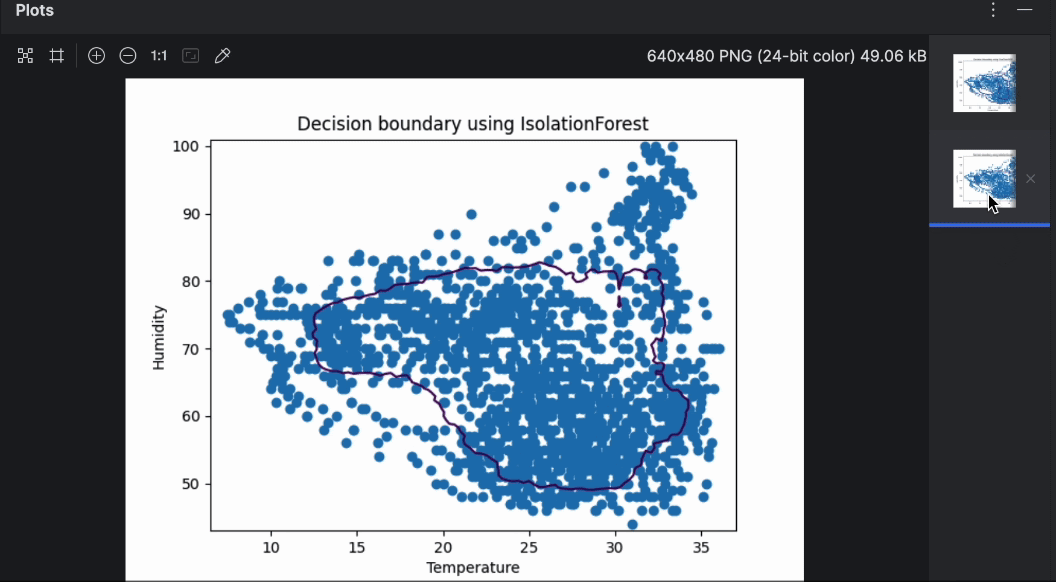
Vous pouvez parcourir rapidement les deux graphiques en utilisant l’aperçu situé à droite. Comme vous pouvez le voir, la frontière de décision est très différente en cas d’utilisation de différents algorithmes. Lors de la détection d’anomalies, il est recommandé d’essayer différents algorithmes et paramètres pour trouver celui qui est le mieux adapté au cas étudié.
Étape suivante : détection d’anomalies dans les séries chronologiques
En présence de données semblables aux données de la ruche, qui forment une série chronologique, il existe d’autres méthodes permettant d’identifier les anomalies. Dans la mesure où les séries chronologiques comportent des tendances et des périodes, tout ce qui n’entre pas dans ce schéma peut être considéré comme une anomalie. Les méthodes populaires de détection des anomalies dans les séries chronologiques incluent la décomposition STL et les prévisions LSTM.
Découvrez comment utiliser ces méthodes pour détecter des anomalies dans des séries chronologiques dans cet article de blog.
Résumé
La détection des anomalies est devenue un aspect important de la business intelligence et il est essentiel d’être en mesure d’identifier des anomalies et de prendre des mesures immédiates dans certains secteurs d’activité. L’utilisation d’un modèle de machine learning adapté pour détecter les anomalies permet d’analyser des gros volumes de données complexes très rapidement. Dans cet article de blog, nous avons vu comment identifier les anomalies avec des modèles statistiques, tels que OneClassSVM.
Pour en savoir plus sur l’utilisation de PyCharm pour le machine learning, consultez les articles « Commencer l’étude du machine learning avec PyCharm » et « Comment utiliser les notebooks Jupyter dans PyCharm » dans notre blog.
Détecter les anomalies avec PyCharm
Le projet Jupyter de PyCharm Professional permet d’organiser facilement votre projet de détection des anomalies avec de nombreux fichiers de données et notebooks. La génération de graphiques permet d’inspecter les anomalies, d’autant plus que les tracés sont très accessibles dans PyCharm. D’autres fonctionnalités, telles que les suggestions de saisie semi-automatique, permettent de naviguer dans tous les modèles Scikit-learn et les paramètres de traçage Matplotlib très facilement.
Boostez vos projets de science des données en utilisant PyCharm et découvrez les fonctionnalités de science des données offertes pour simplifier votre workflow de science des données.
Auteur de l’article original en anglais :





