

IntelliJ IDEA
IntelliJ IDEA – the Leading IDE for Professional Development in Java and Kotlin
Use the UTF-8, Luke! File Encodings in IntelliJ IDEA

Today we would like to answer the most frequent questions about file encodings in the IDE and show you a few tricks, which may help you to avoid potential pitfalls.
What is the problem with file encodings?
To be able to display the text correctly, IntelliJ IDEA needs to know which file encoding to use. Unfortunately, it is not always possible to tell the file encoding without additional information. Especially when single-byte encodings are used, there are multiple mappings possible.
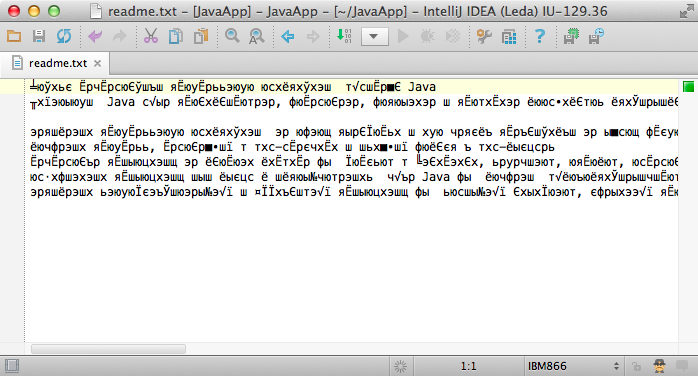
However, things look better for UTF-family encodings. The UTF family consists of:
- Several multi-byte encodings like UTF-16 or UTF-32, which are easily detectable by the BOM (Byte Order Mark) word in the beginning of the file.
- The UTF-8 variable-bytes-per-character encoding which also can be auto-detected either by optional BOM or some specific byte combinations.
In particular, for an English character subset, the UTF-8 encoded file looks exactly like old plain ASCII text. That’s why UTF-8 is so popular and that’s why it’s the most preferred encoding.
How does the IDE determine encoding for the file?
IntelliJ IDEA uses multi-stage educated guessing, from most obvious to far-stretched.
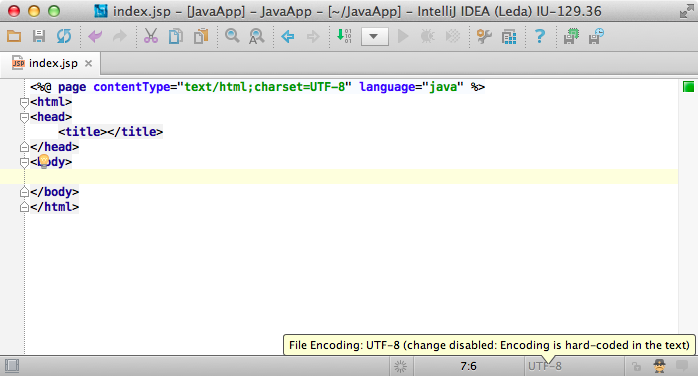
First, if the BOM present, use the corresponding UTF-family encoding. Check if the file type declares the encoding itself and use that. For example, JSP files can specify the encoding right in the text:
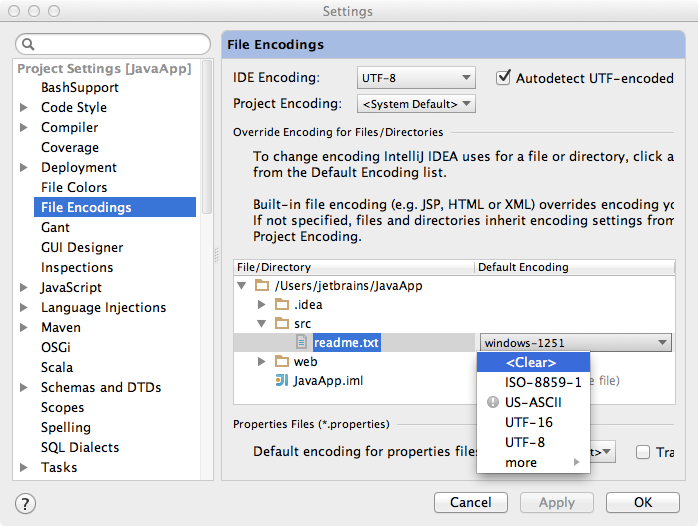
Check if you have specified the encoding explicitly and use that. You can specify the desired encoding for the file or for the containing directory or for the whole project or for the IDE. IntelliJ IDEA will use the most specific encoding:
Try to figure out the encoding using some hints or heuristics. For example, when Auto-detect UTF-8 is selected, the IDE will analyze the file looking for some byte combinations which are UTF-8-specific.
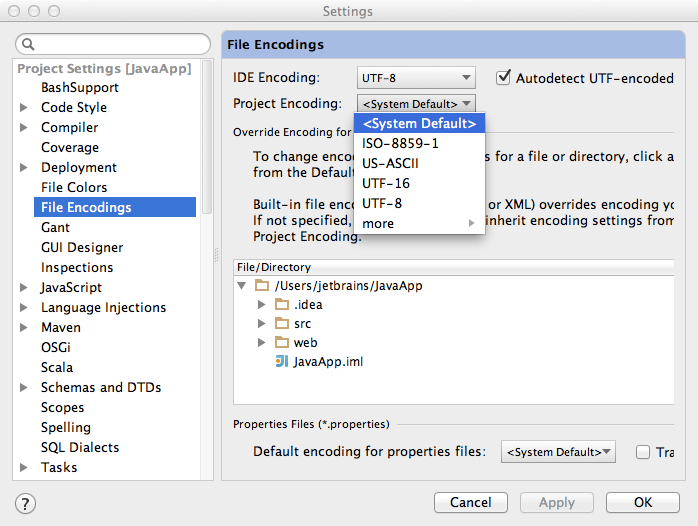
Finally, use the project-level or, if the project is unavailable, the application-level encoding.
See Settings → File Encoding → Project Encoding → IDE Encoding.
What happens when I try to change the file encoding?
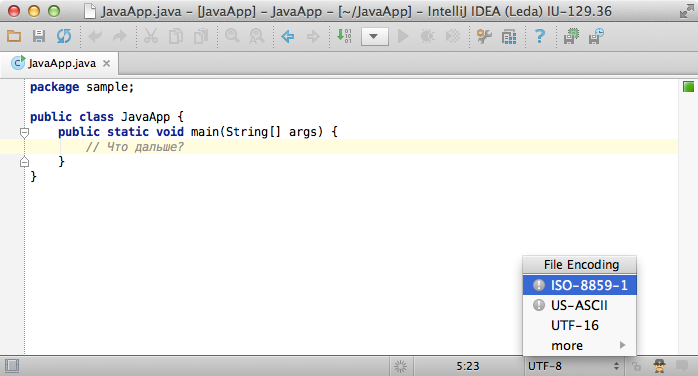
If the file encodings are completely compatible for this text, e.g. when changing English characters text from US_ASCII to UTF-8, IntelliJ IDEA just silently re-assigns encoding.
However, if the encodings are sufficiently different, the IDE have to ask you:
- Whether you want to reload the file from disk in the other encoding.
In this case IDEA will replace editor with text from the file decoded with the new encoding. - Or you would like to convert the text on the editor to the file using the other encoding.
Here, IDEA will encode the text in the editor window using the new encoding and overwrite the file.

Please note these little gray exclamation marks, meaning that that particular conversion/reload can cause information loss.
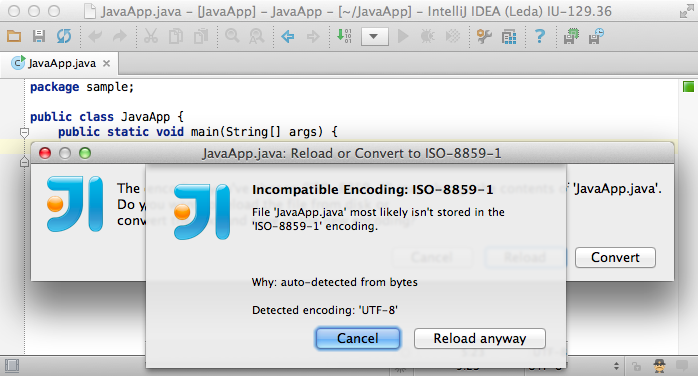
For example when you try to reload UTF-8 encoded file with the US-ASCII encoding, losing the non-english characters in the process.
Or when you try to save the German umlauts to the plain text ISO-8859-1 file.
What else IntelliJ IDEA can do for me?
IntelliJ IDEA will warn you when you try to swear in German in an ASCII-only document:
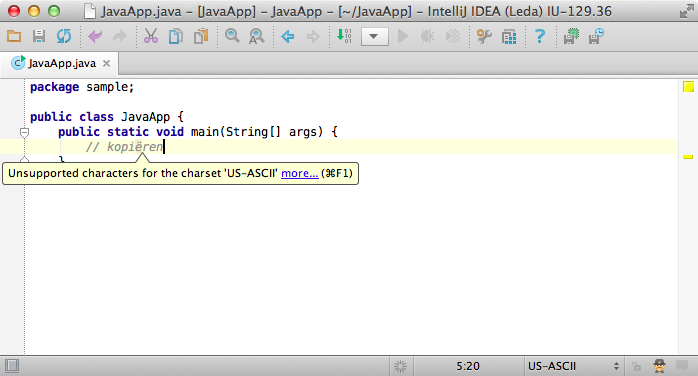
To enable this inspection, go to Settings → Inspections → Lossy Encoding.
Likewise, IntelliJ IDEA will try to detect the situation when you load rich-encoded text with incompatible encoding:
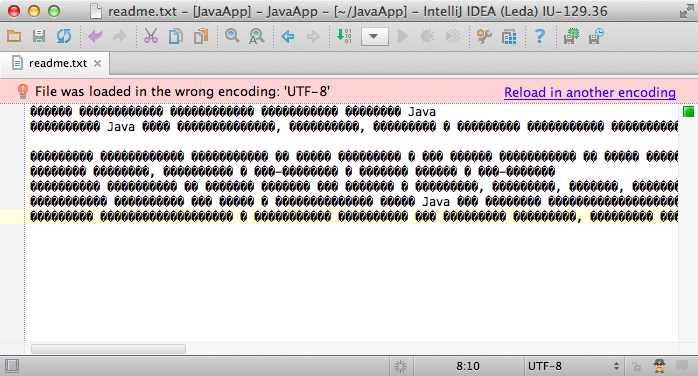
What is the ultimate advice you have regarding file encodings?
To avoid any problems with file encoding we strongly recommend to use UTF-8.
That’s all for today and we hope this article was useful for you!
Develop with Pleasure!






