

IntelliJ IDEA
IntelliJ IDEA – the Leading IDE for Professional Development in Java and Kotlin
Big Data Tools Update Is Out: SSH Tunnels, Filters and Limits for Spark, User Defined Modules and More

I am pleased to announce that the EAP of Big Data Tools plugin compatible with IntelliJ IDEA Ultimate 2020.2 is available from today.
Our goal was to fix as many problems as possible and improve the plugin from the inside out. In addition to some under-the-hood changes, two visible improvements have been made:
- With just a couple of mouse clicks, you can enable SSH tunnels to forward ports for Hadoop and Spark connections.
- Filters and limits in the Applications tab of the Spark Monitoring tool window give you control over how much data is loaded from servers.
SSH tunneling
The servers we need are not always accessible directly. For example, they may be located inside a protected corporate environment or blocked by special firewall rules. A tunnel or VPN may help us get inside. SSH is the simplest of the tunnels and is always to hand.
You can create a tunnel with a single console command on Linux or Mac:
ssh -f -N -L 1005:127.0.0.1:8080 user@spark.server
Instead of filling the flags repeatedly, you can save them into the ~/.ssh/config, like so:
Host spark
HostName spark.server
IdentityFile ~/.ssh/spark.server.key
LocalForward 1005 127.0.0.1:8080
User user
Now, all you need is to run ssh -f -N spark in the console to get the tunnel up and running, without entering the IP addresses ever again.
But there are two obvious problems.
First, what is -f -N -L? Which port should I write on the left and which on the right? And, how do we choose the addresses for connections? For most of us (professional systems engineers excluded), this can be a nuisance if not an ordeal.
Second, we always write code in the IDE instead of terminal emulators. Everything you run in the console works globally; it changes the behavior of the entire operating system. In the IDE though, we would like to have per-project sets of tunnels.
Fortunately, starting with this release, Big Data Tools can create tunnels without manually managing SSH connections in a console.
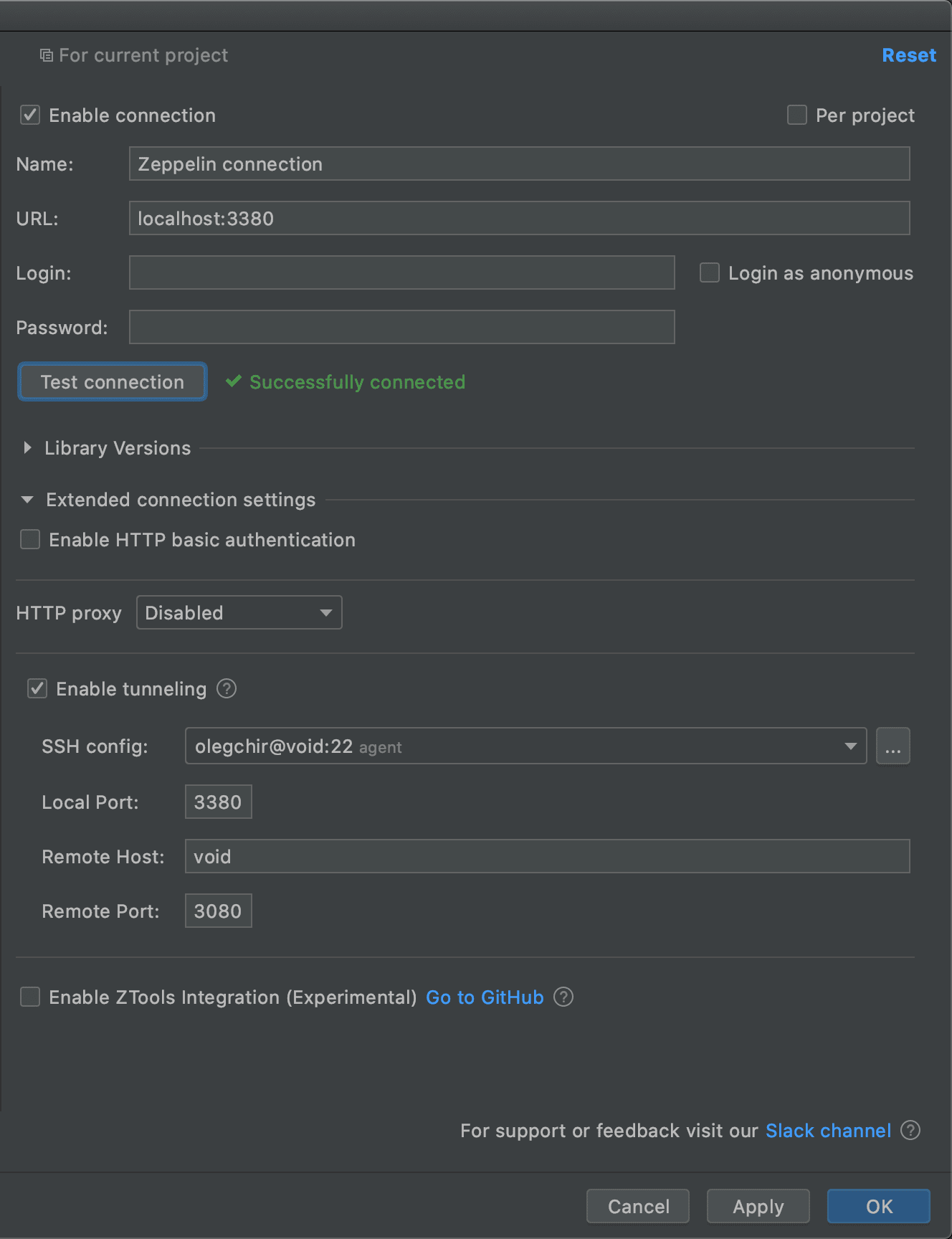
As the screenshot shows, you can use any existing SSH configuration file instead of manually entering all the data.
The “Enable tunneling” option is available for the following connection types:
- Zeppelin
- HDFS
- Hadoop
- Spark Monitoring
There’s no magic. Under the hood, it reflects the console SSH behavior. For example, if you try to open a tunnel to a local port already occupied by another application or tunnel, you will get a standard error.
Overall, this is a pretty useful feature that makes life easier in most everyday cases. If you need to do something complicated and non-standard, you can manually use SSH, VPN, or other methods the old-fashioned way.
Comments for this feature are tracked in the ticket BDIDE-1063.
Filters and limits for Spark
There are two types of people using Spark: those who have only a couple of applications in their Spark Monitoring tool window, and those who have hundreds.
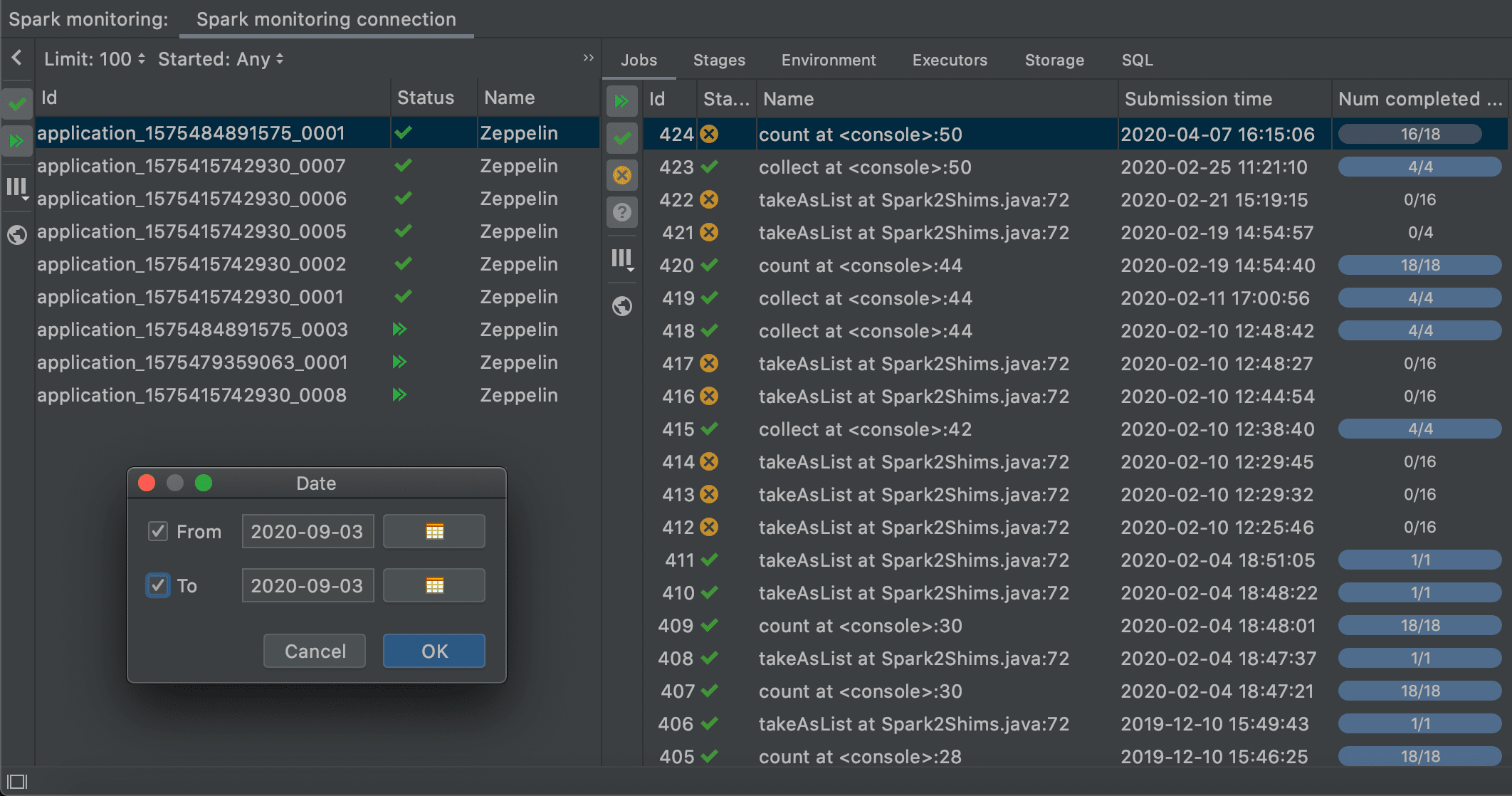
Loading a massive list of applications can take time. During this time, you can only guess at what state the server might be in.
In this version of Big Data Tools, you can significantly limit the waiting time by manually selecting the data range to load. For example, you can open the date range dialog box and manually select a single day.
This option can save you a lot of time if you work in large production environments.
Comments on this feature are tracked in the ticket BDIDE-1077.
User-defined modules for Zeppelin
Many Zeppelin projects use custom JAR file dependencies. Big Data Tools uses knowledge about these dependencies to power its auto-completion, refactorings, and other smart features.
Big Data Tools tries to download all JAR dependencies when you synchronize Zeppelin with the IDE. When this isn’t possible, you have to add them to IntelliJ IDEA manually.
In our previous EAP, you could only use Maven artifacts or standalone JAR files as user-defined dependencies. To get these artifacts and files, you had to either download them from somewhere or build the entire project, which is a long and tedious process.
Now, any module of the current project can also be used as a dependency. Such dependencies fall into the “User dependencies” section:
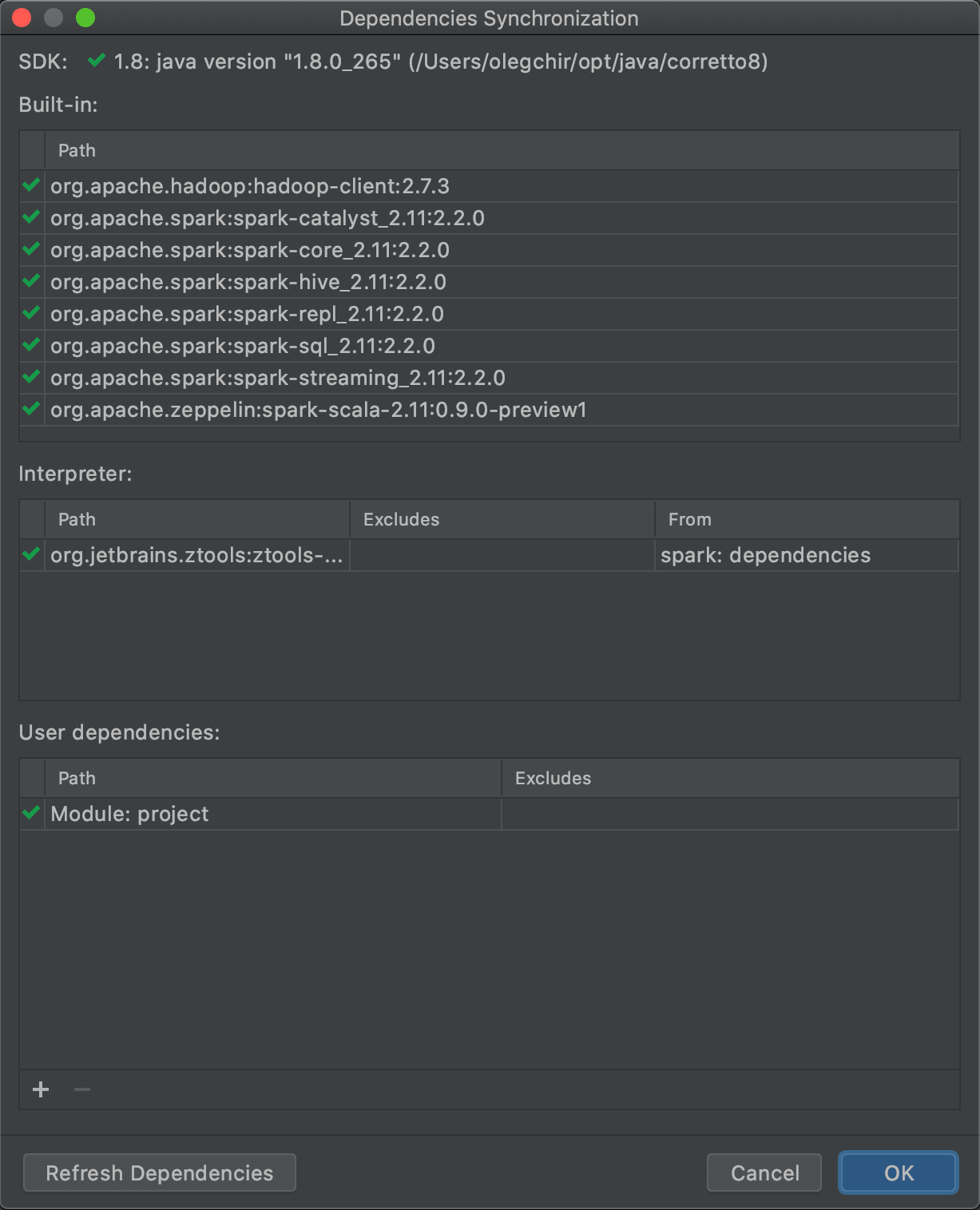
Comments on this feature are tracked in the ticket BDIDE-1087.
Notable changes and bug fixes
- [BDIDE-1078] When cells were collapsed, the cell title disappeared. Now the cells display correctly, but you still cannot edit them with the Big Data Tools plugin. This will be fixed in the future.
- [BDIDE-1137] Removing a Spark Monitoring connection from a Hadoop connection resulted in IncorrectOperationException.
- [BDIDE-570] In the Jobs table of the Spark Monitoring tool window, the highlighted tasks could occasionally lose their selection.
- [BDIDE-706] When updating a job tree in the Spark Monitoring tool window, the selected job could lose its selection.
- [BDIDE-737] You had to restart the IDE to obtain information about the Spark applications after you woke your computer from sleep.
- [BDIDE-1049] Restarting the IDE could throw a DisposalException.
- [BDIDE-1060] Restarting the IDE with a “Variable View” open could result in an IllegalArgumentException.
- [BDIDE-1066] Editing any properties of an inactive Spark Monitoring connection occasionally enabled it in the panel.
- [BDIDE-1091] Deleting a Zeppelin connection resulted in a ConcurrentModificationException.
- [BDIDE-1092] The Refresh button sometimes failed to update jobs in the Spark Monitoring tool window.
- [BDIDE-1093] After restarting Spark, the Spark Monitoring tool window displayed a connection error.
- [BDIDE-1094] It was not possible to resize error connection windows in Spark Monitoring.
- [BDIDE-1099] In Spark Monitoring, the SQL tab could display an “Empty List” message instead of “Loading”.
- [BDIDE-1119] Spark Monitoring displayed SQL properties even when the connection was dropped, or when the interpreter was restarted.
- [BDIDE-1130] An IndexOutOfBoundsException error occurred after filtering out all applications in the Spark Monitoring tool window.
- [BDIDE-1133] Charts displayed only a single range of data even if multiple ranges were specified in the table properties.
- [BDIDE-406] After establishing a connection to some Zeppelin instances, a sync error was displayed. This issue is fixed now. As part of the same ticket, we’ve introduced Zeppelin 0.9 support, a new collaborative mode.
- [BDIDE-746] A connection error was displayed on the Details page when there was no selection in the Application or Job tabs of the Spark Monitoring tool window.
- [BDIDE-769] When switching between some connection and Spark Monitoring, information about this connection could fail to be displayed.
- [BDIDE-893] The task list in the Spark Monitoring tool window occasionally disappeared, and an incorrect filtering message was displayed instead.
- [BDIDE-1010] After launching a cell, the “Ready” status was displayed for a long time.
- [BDIDE-1013] Local notebooks in Zeppelin had reconnection problems.
- [BDIDE-1020] Because of a combination of factors, SQL code formatting could be broken.
- [BDIDE-1023] An intermediate execution output for cells was not displayed; now this output is displayed below the cells.
- [BDIDE-1041] Non-empty files on HDFS were displayed as empty and could be accidentally saved and erased.
- [BDIDE-1061] Fixed a bug in displaying SQL jobs. Previously, it was unclear if the Spark server was a History Server or not.
- [BDIDE-1068] A link to a job in Spark could occasionally get lost and reappear again.
- [BDIDE-1072], [BDIDE-838] The Big Data Tools panel did not display Hadoop and Spark connection errors.
- [BDIDE-1083] If at least one task with a progress indicator was running when closing the IDE, a “Memory leak detected” error occurred.
- [BDIDE-1089] Charts now support internationalization.
- [BDIDE-1103] If a connection to Zeppelin was suddenly lost, the disconnection warning was not displayed.
- [BDIDE-1104] Horizontal scroll bars in Zeppelin inlays were overlapping some text.
- [BDIDE-1120] A RuntimeExceptionWithAttachments occurred if the Spark Monitoring connection was lost.
- [BDIDE-1122] Restarting any interpreter resulted in a KotlinNullPointerException.
- [BDIDE-1124] Hadoop connections could not use the SOCKS proxy.
Documentation and Social Networks
And last but not least, in case you need help on how to use any feature of the plugin, make sure to check out the documentation. Still need help? Please don’t hesitate to leave us a message either here in the comments or on Twitter.
The Big Data Tools team








