

IntelliJ IDEA
IntelliJ IDEA – the Leading IDE for Professional Development in Java and Kotlin
IntelliJ IDEA’s New Kotlin Coroutine Inspections, Explained

This article was written by an external contributor.

Every technology has its misuses, and different ecosystems use different approaches to prevent them. In the Kotlin ecosystem, I believe the philosophy has always been to make APIs so good that correct usage is simple and intuitive, while misuse is harder and more complicated. This differs from JavaScript, which has plenty of legacy practices (like using == instead of ===, or var instead of let/const) and relies more on warnings. However, not everything can be enforced by good design, and Kotlin also uses warnings to guide developers in writing better code.
Today, IntelliJ IDEA introduces a set of new inspections for the Kotlin coroutines library. I’ve seen these issues in many codebases and addressed them through my books, articles, and workshops. These patterns often show up, so let’s walk through why they are problematic and how to handle them correctly.
Note: These inspections are also available in Android Studio. You can check how IntelliJ IDEA versions map to Android Studio versions here.
awaitAll()and joinAll()
Available since IntelliJ IDEA 2025.2
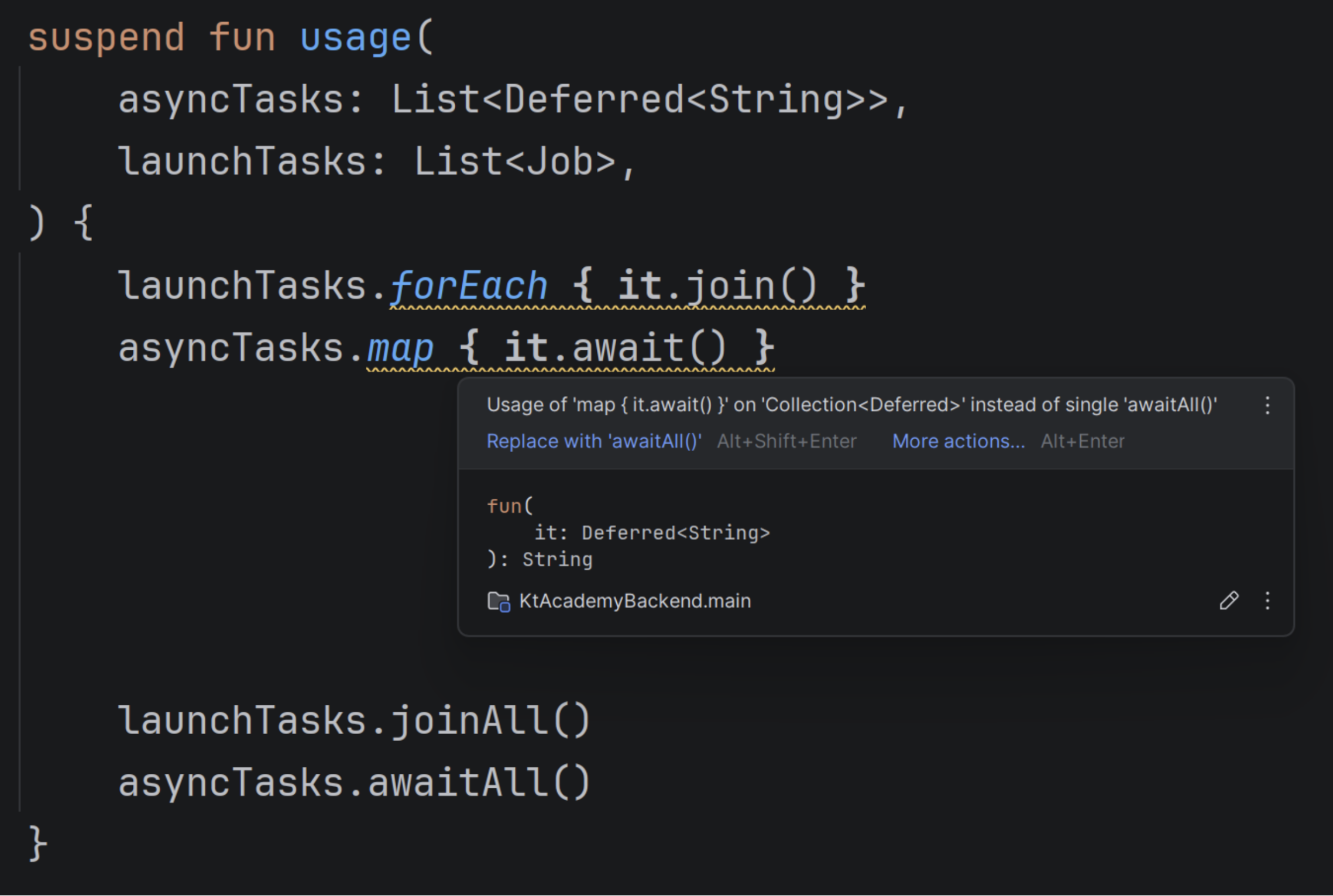
If you use map { it.await() }, IntelliJ IDEA will suggest awaitAll(). If you use forEach { it.join() }, it will suggest joinAll(). Why? These alternatives are cleaner, and awaitAll() is also more efficient and better represents waiting for multiple tasks, as it waits for all elements concurrently rather than one after another.
awaitAll() also behaves more efficiently in the presence of exceptions. Imagine awaiting 100 coroutines, and the fiftieth throws an exception. awaitAll() will immediately rethrow the exception, unlike map { it.await() }, which would wait for the first 49 coroutines before throwing the exception. In most cases, this behavior cannot be observed because of other exception propagation mechanisms.
currentCoroutineContext() over coroutineContext
Available since IntelliJ IDEA 2025.2
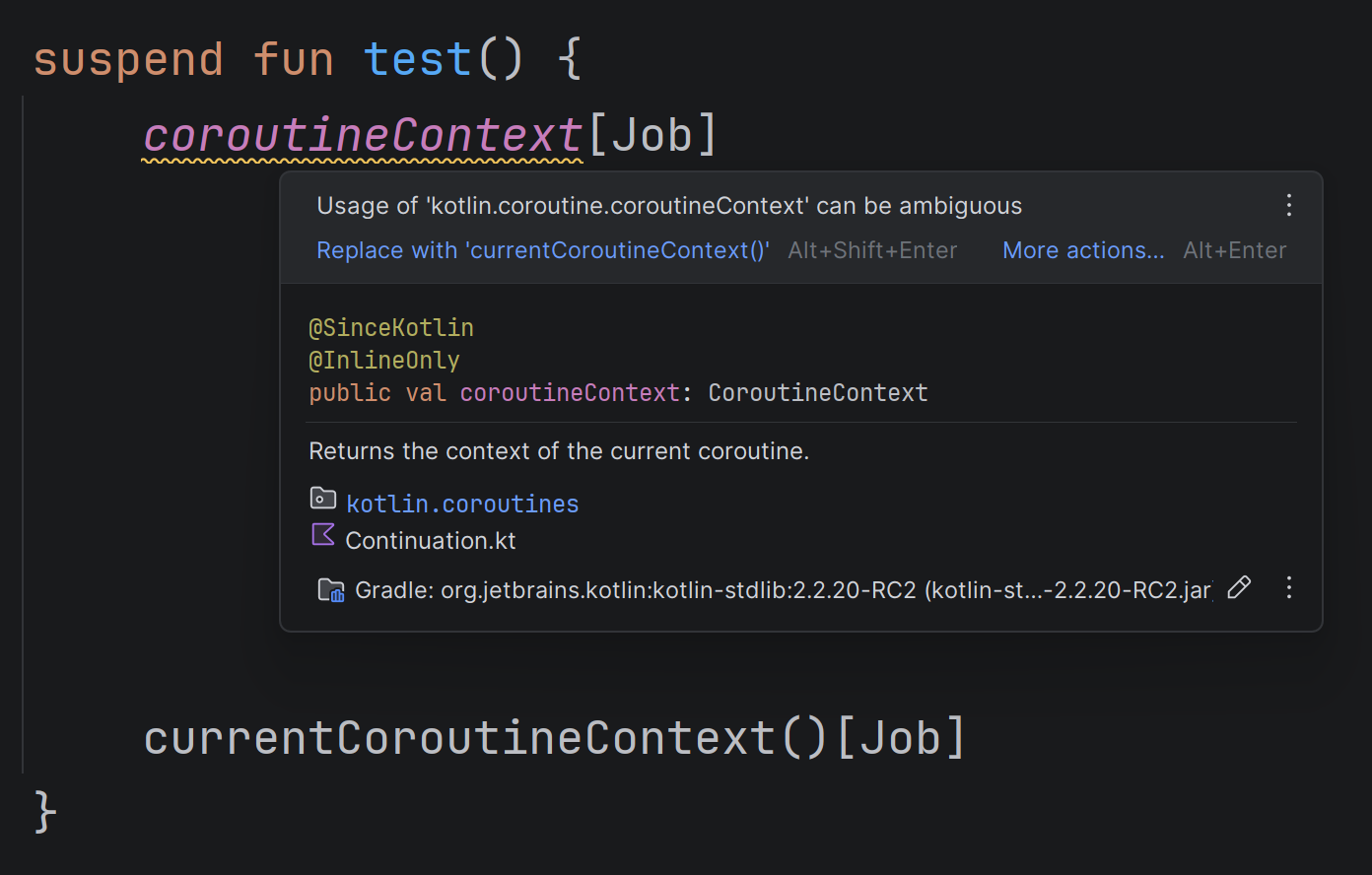
All suspending functions can access the context of the coroutine in which they are called. Traditionally, this was done via the coroutineContext property. The problem is that CoroutineScope, which is implicitly available in coroutine starters, such as launch, coroutineScope, and runTest, has a property with the same name. This can be confusing and lead to issues. Consider the following example:
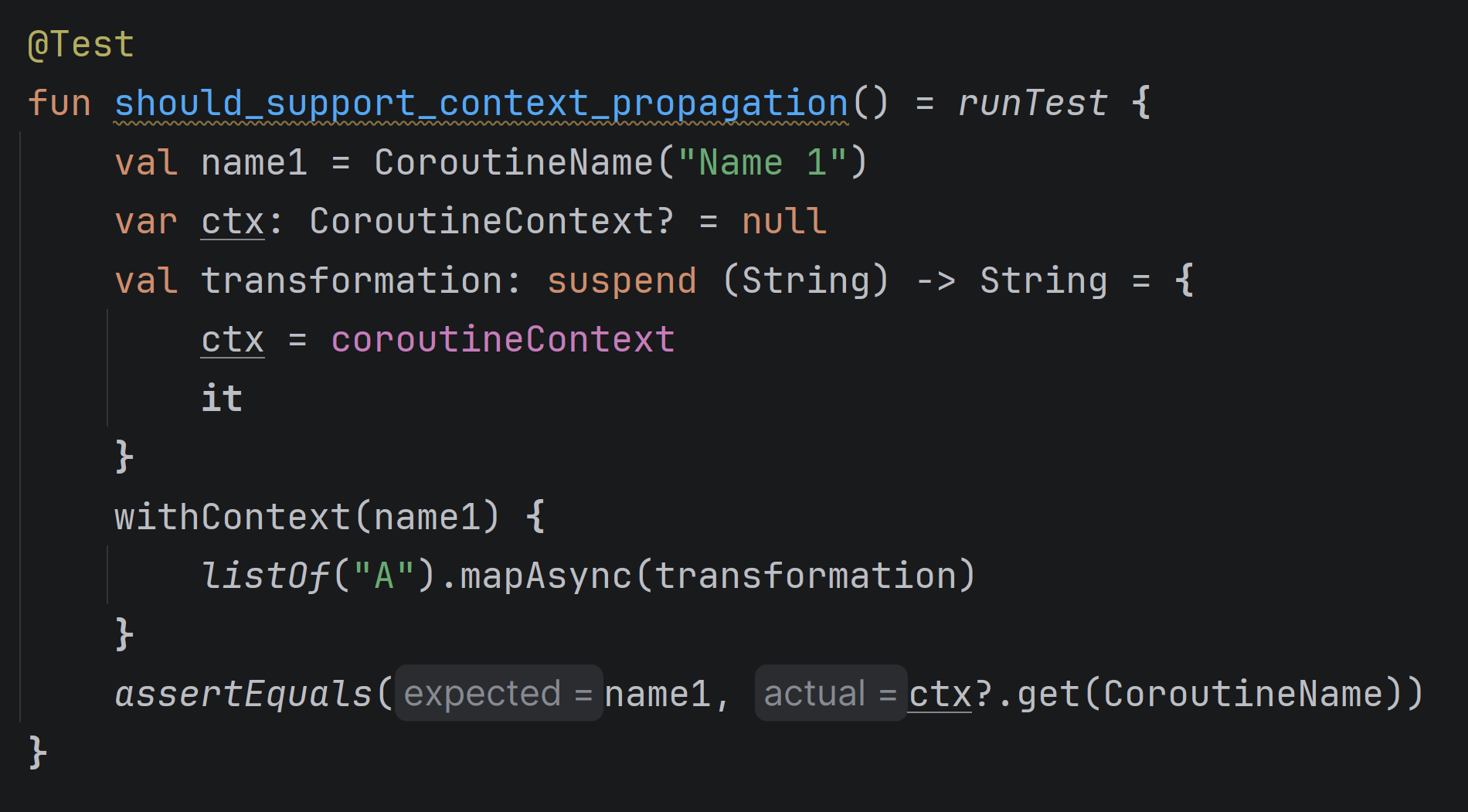
This code tests the mapAsync function and checks whether it correctly propagates context from the caller to the transformation. It is incorrect. Within the transformation, we could read the caller context from the coroutineContext, but not in this situation. This lambda is defined inside runTest, and the coroutineContext property from CoroutineScope (provided by runTest) takes priority over the top-level coroutineContext property. This kind of mistake is quite common, which is why the currentCoroutineContext() function was introduced to read the context of the coroutine that runs a suspending function. You should use it instead of coroutineContext.
runBlocking inside a suspending function
Available since IDEA 2025.2
Using runBlocking inside suspending functions is a serious issue. It blocks the calling thread, which defeats the purpose of coroutines.

So what can you use instead? That depends on what you want to achieve. In most cases, you don’t need it. If you need to create a coroutine scope, use coroutineScope { … }. If you need to change context, use withContext(ctx) { … }.
Watch out for situations where a suspending function calls a regular function that uses runBlocking. Opt for making this function suspend to avoid making a blocking call.

Unused Deferred
Available since IntelliJ IDEA 2025.3

This inspection appears when you use async without ever using its result. In such cases, you should use launch instead. This is the key difference between launch and async: async returns a result and is expected to await this result, while launch produces no result.
Because of this, exception handling differs. async doesn’t call CoroutineExceptionHandler because it is expected to throw an exception from await and propagate it this way.
Job used as an argument in a coroutine starter
Available since IntelliJ IDEA 2025.3
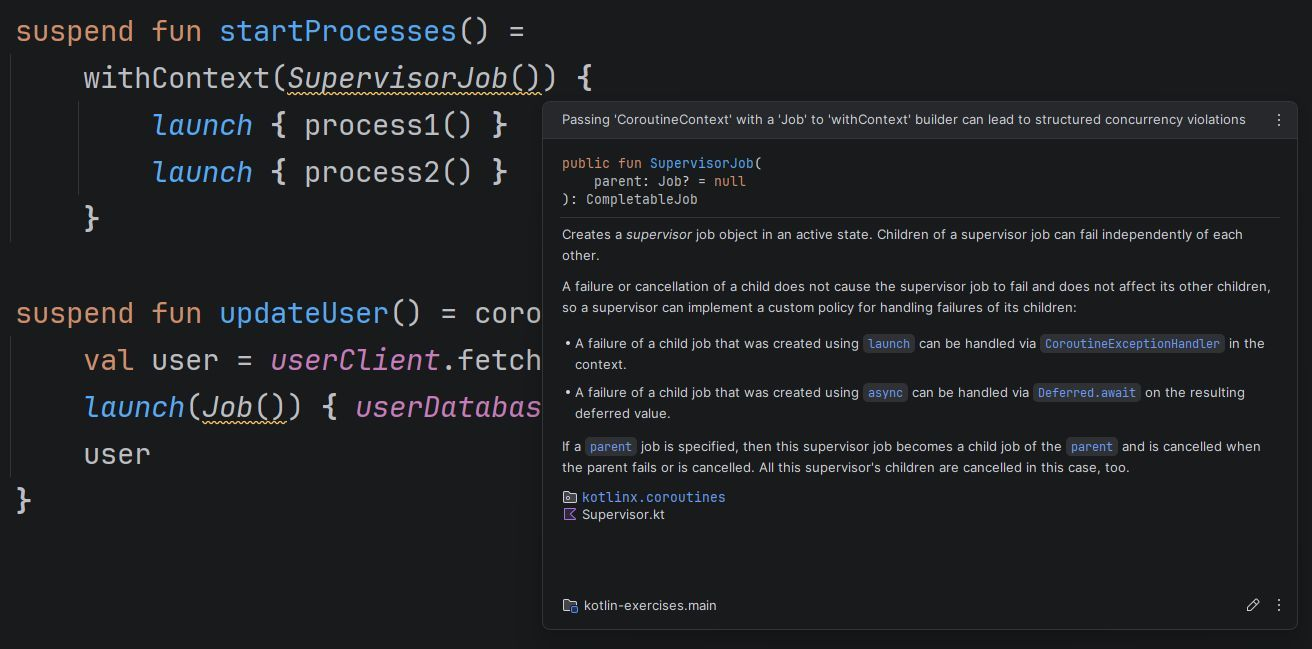
I’ve been looking forward to this inspection for years! Using Job as an argument to a coroutine starter causes issues, and it’s something I’ve seen in many projects. I covered this anti-pattern in my book and workshops, but it still appears quite often. This inspection should help clarify the correct approach. Let’s look at why Job shouldn’t be used as an argument for a coroutine.
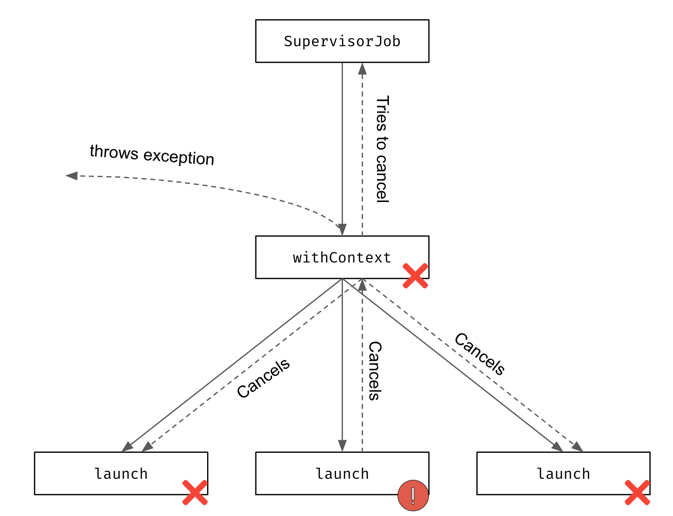
The key misunderstanding here is that Job cannot be overridden by an argument. If you use any other context, it will be used in the coroutine and its children, but not Job. Every coroutine creates its own job. A job contains a coroutine’s state and relations – it cannot be shared or enforced from outside. The Job that is used as an argument isn’t going to be a job of this coroutine. Instead, it overrides Job from the scope and becomes a parent. This breaks structured concurrency.
For example: Using withContext(SupervisorJob()) { … } behaves very differently from supervisorScope { … }.
supervisorScope creates a child coroutine of the caller of this function, and it uses a supervisor job (it doesn’t propagate its children’s exceptions). On the other hand, withContext(SupervisorJob()) creates a regular coroutine, which is a child of SupervisorJob and has no relation to the caller.
Consider the code below. An exception in the first launch propagates to withContext (which uses regular Job), cancels the other child coroutines, and is then rethrown. SupervisorJob() has no effect. In some cases, it can even be harmful, as it breaks structured concurrency. If the caller of withContext(SupervisorJob()) is cancelled, that cancellation won’t propagate, which will result in a memory leak.
import kotlinx.coroutines.*
val handler = CoroutineExceptionHandler { _, e ->
println("Exception: ${e.message}")
}
fun main(): Unit = runBlocking(handler) {
// DON'T DO THAT!
withContext(SupervisorJob()) {
launch {
delay(1000)
throw Error("Some error")
}
launch {
delay(2000)
println("AAA")
}
}
println("Done")
}
// (1 sec)
// Exception in thread "main"...
Using supervisorScope would prevent this problem:
import kotlinx.coroutines.*
val handler = CoroutineExceptionHandler { _, e ->
println("Exception: ${e.message}")
}
fun main(): Unit = runBlocking(handler) {
supervisorScope {
launch {
delay(1000)
throw Error("Some error")
}
launch {
delay(2000)
println("AAA")
}
}
println("Done")
}
// (1 sec)
// Exception: Some error
// (1 sec)
// AAA
// Done
A Job used as an argument breaks the relationship with the caller. In the case below, updateToken won’t be related to the caller of getToken:
suspend fun getToken(): Token = coroutineScope {
val token = tokenRepository.fetchToken()
launch(Job()) { // Poor practice
tokenRepository.updateToken(token)
}
token
}
This is generally discouraged, as it breaks structured concurrency. The standard approach would be to sequentially call updateToken:
suspend fun getToken(): Token {
val token = tokenRepository.fetchToken()
tokenRepository.updateToken(token)
return token
}
If we really want to detach updateToken from getToken, a better practice would be to start the launch on a different scope, like the backgroundScope we define in our application for background tasks. With this approach, the new coroutine is still attached to a scope, just a different one:
suspend fun getToken(): Token {
val token = tokenRepository.fetchToken()
backgroundScope.launch { // Acceptable
tokenRepository.updateToken(token)
}
return token
}
suspendCancellableCoroutine instead of suspendCoroutine
Available since IntelliJ IDEA 2025.3
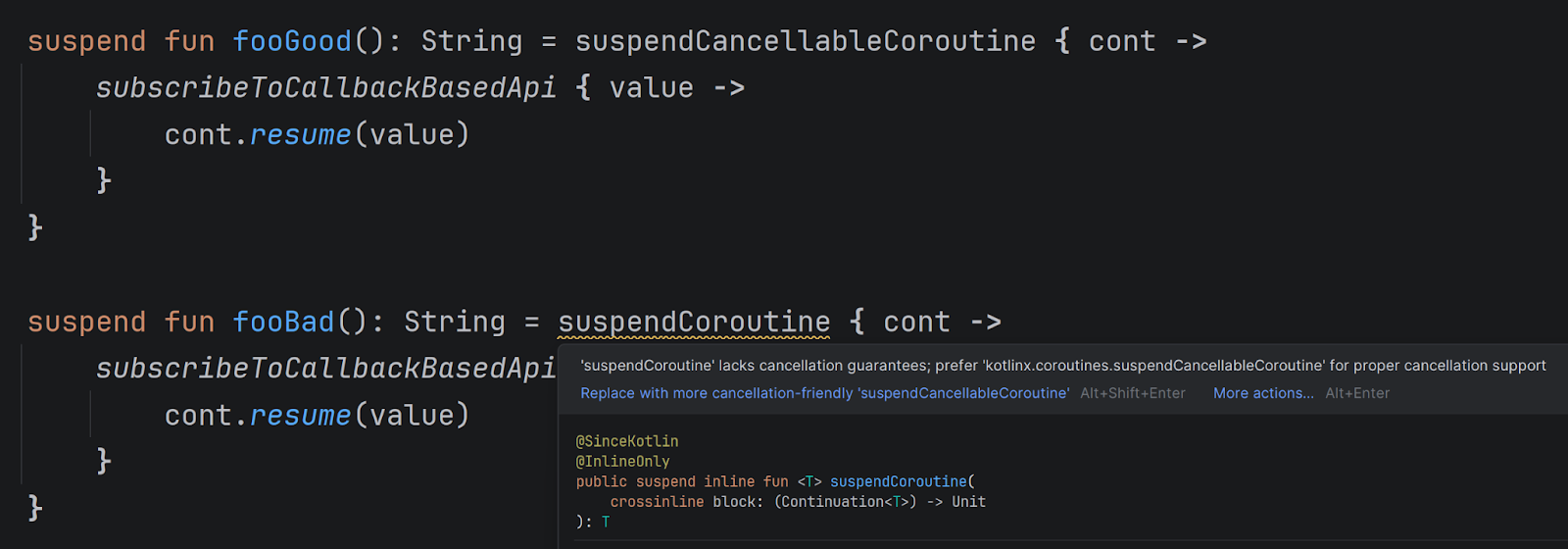
To suspend a coroutine, use suspendCancellableCoroutine. Its predecessor, suspendCoroutine, does not support cancellation and should be avoided.suspendCancellableCoroutine is a low-level API rarely used in application code, but often used by libraries that support suspending calls.
Suspicious implicit CoroutineScope receiver
Available since IntelliJ IDEA 2025.3, but this inspection is disabled by default and must be enabled manually.
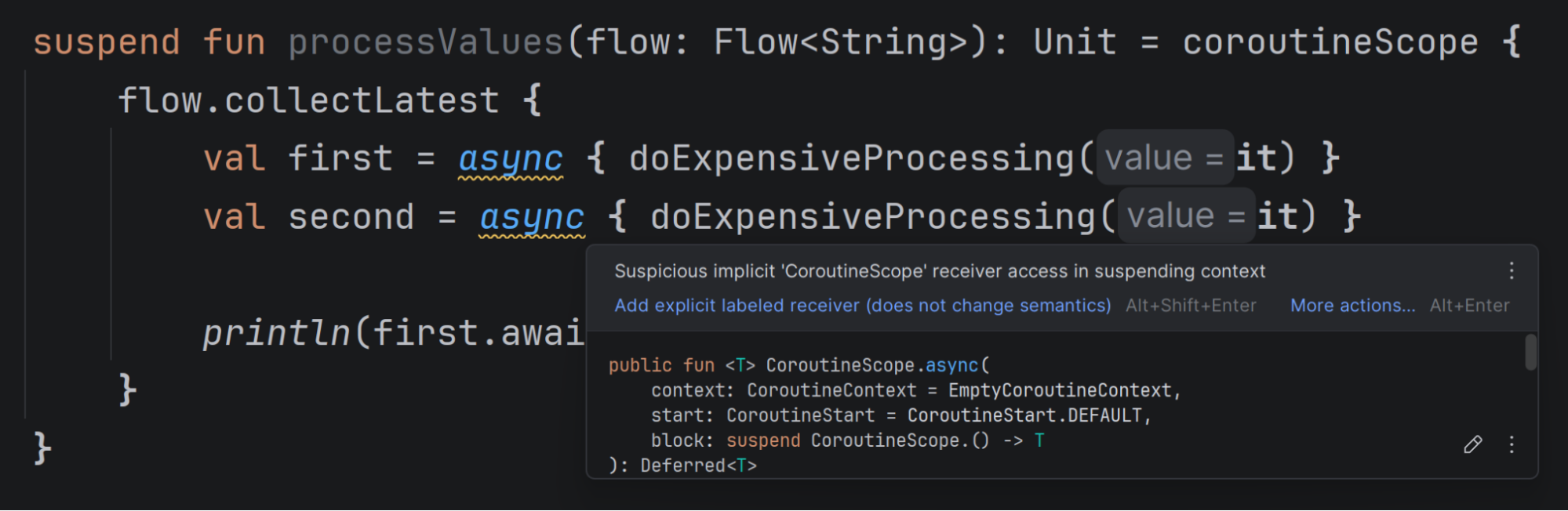
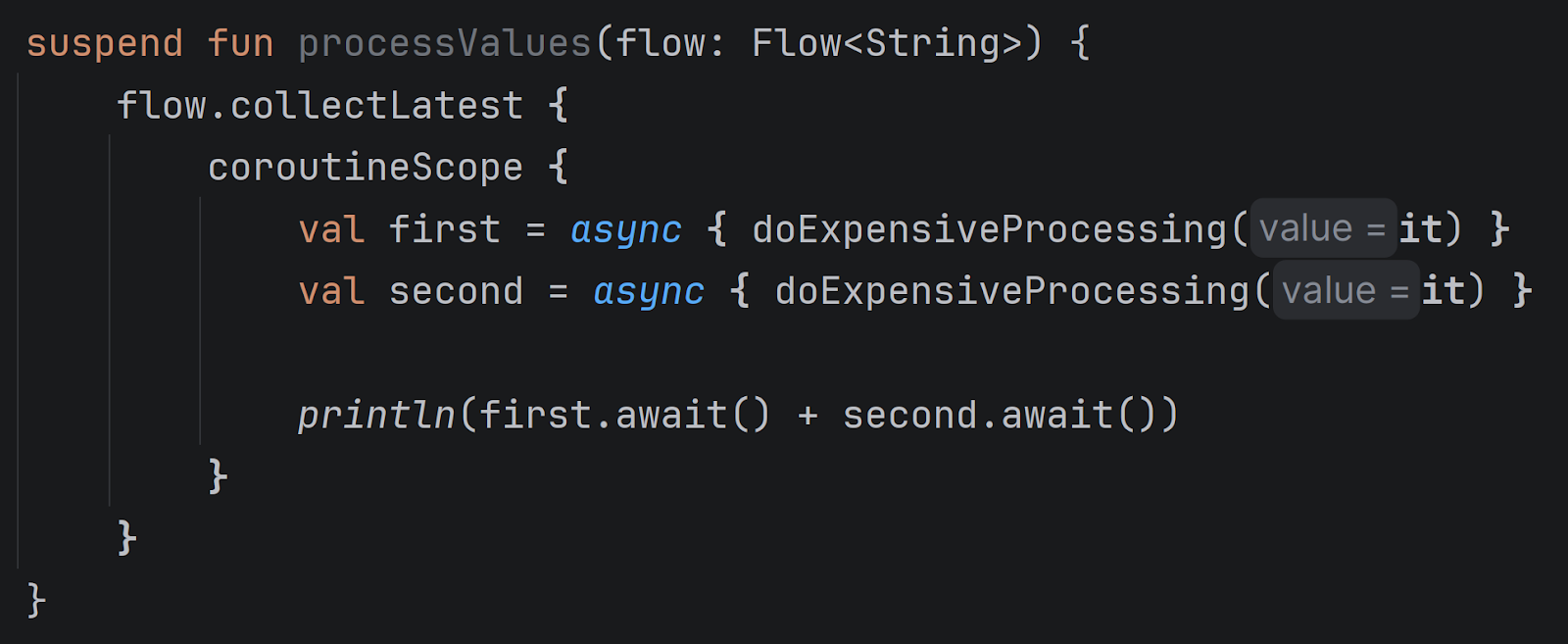
Implicit receivers within lambdas can be confusing. In the above example, async calls are executed on the scope created by coroutineScope because collectLatest doesn’t provide its own scope. This can lead to memory leaks. When a new value reaches collectLatest, it should cancel processing of the previous one. In this example, it cannot cancel the async coroutines, as they are attached to coroutineScope, not to collectLatest. To avoid this, define coroutineScope inside collectLatest, not outside it. This inspection highlights such cases to prevent these issues.
Simpler operations for flow processing
Available since IntelliJ IDEA 2026.1 (currently in EAP)
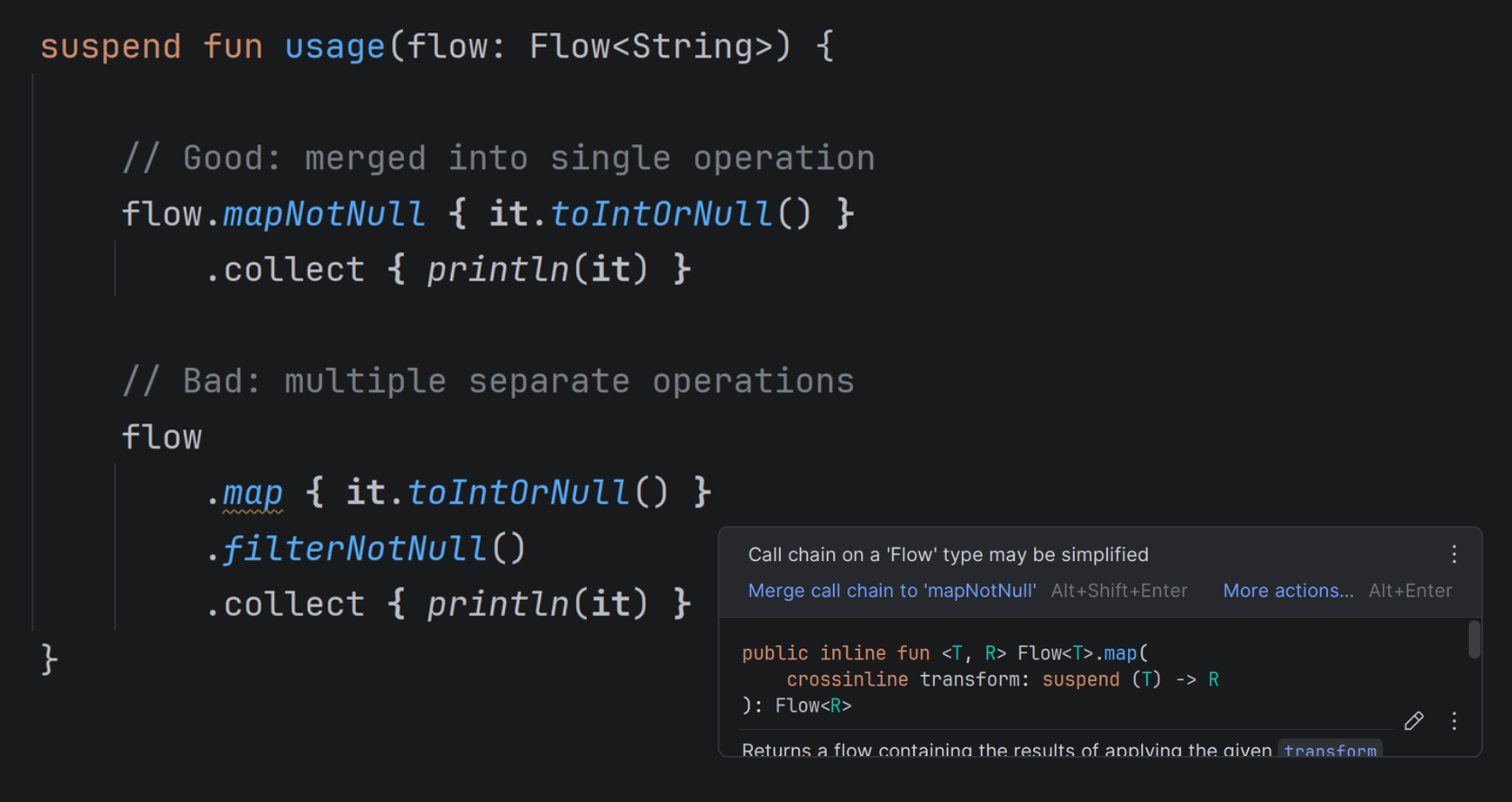
You may already know these from collection or sequence processing:
If you use filterNotNull after map, you’ll get the suggestion to use mapNotNull. If you use filter { it is T }, the IDE will suggest using filterNotNull<T>.
These suggestions are now also available for flows!
Summary
IntelliJ IDEA continues to help you write better code – not only by advancing its AI tools and agents, but also by improving the core development experience. There are still many inspections I would love to see in the IDE, but the current set already brings significant value.







