

JetBrains AI
Supercharge your tools with AI-powered features inside many JetBrains products
AI エージェントを Kotlin で構築する - 第 3 回:観測

この連載の過去記事:
この連載の第 2 回が終了し、コーディングエージェントがかなりの処理を行えるようになりました。プロジェクトの探索、コードの読み書き、シェルコマンドの実行、およびテストの実行を行えます。前回の記事で完了の定義(DoD)を追加したことで、必要とされていたフィードバックループが完成し、エージェントが完了を判断するまでではなく、すべてのテストが合格するまで処理を反復するようになりました。
これは喜ぶべきことでしょうか? いいえ、そうとも言い切れません。
エージェントの機能が増えていくと、デバッグはさらに困難になります。ツールごとにサーフェスエリアが増えるからです。DoD ループにより、呼び出しやトークンも増加します。評価の実行には数時間かかることもあり、何かが失敗した場合、何が失敗し、その問題の原因が何なのかはっきりしないことはよくあります。
エージェントはタスクを解決できるようになったものの、 どのように解決しているのかは残念ながら分かりません。
これは、エージェントの改善や失敗のデバッグ、またはコストの見積の際に問題となります。この記事では、このような不明確さの解消に取り組みます。分かりやすいもの(あまり効果がないもの)から着手し、LLM アプリ用の一般的な可観測性ツールを確認し、Langfuse を使用してトレース機能を組み込みます。これにより、アクションあたりのコストを含め、エージェントのアクションをステップごとに把握できるようになります。この過程では動作パターンが明らかになり、存在すら知らなかったバグも見つかります。
では、何が不足しているのかを理解することから始めましょう。
エージェントのストーリー
エージェントがコーディングタスクを完了すると、このファイルを読み取る、あの関数を解析する、このコードを変更する、これらのテストを実行するといった決定とアクションから構成されるチェーンがエージェントによって生成されます。このチェーンはエージェントがどのような軌跡をたどり、どのように機能するのかを伝えます。
軌跡はエージェントが時間を無駄にしている箇所や起動から外れた箇所を明確にするため、重要です。エージェントが同じファイルを 47 回読み取っていることや、単純なバグ修正を依頼したのにコードベースの半分を書き直した理由が示されます。端的に言えば、観測不可能なものは改善できません。
これまでは以下のような単純な構成で進めてきました。
handleEvents {
onToolCallStarting { ctx ->
println("Tool '${ctx.tool.name}' called with args: ${ctx.toolArgs.toString().take(100)}")
}
}
最初の段階ではこの構成でも十分で、 少なくとも動作は示されました。しかし、それ以上の情報が必要になっています。完全なパラメーターと観測値がなければ、エージェントの動作を十分に把握できません。また、何もかも出力すれば、コンソールの出力はオブジェクトのダンプ、ファイルの内容、エラーメッセージがすべて混在し、ノイズと化してしまいます。
もっと優れたツールが必要です。
「単にログを記録する」
まずは分かりやすい解決策から試してみましょう。Koog にはデバッグログを記録する仕組みがあるため、Logback を ERROR から DEBUG に切り替えてから再実行します。
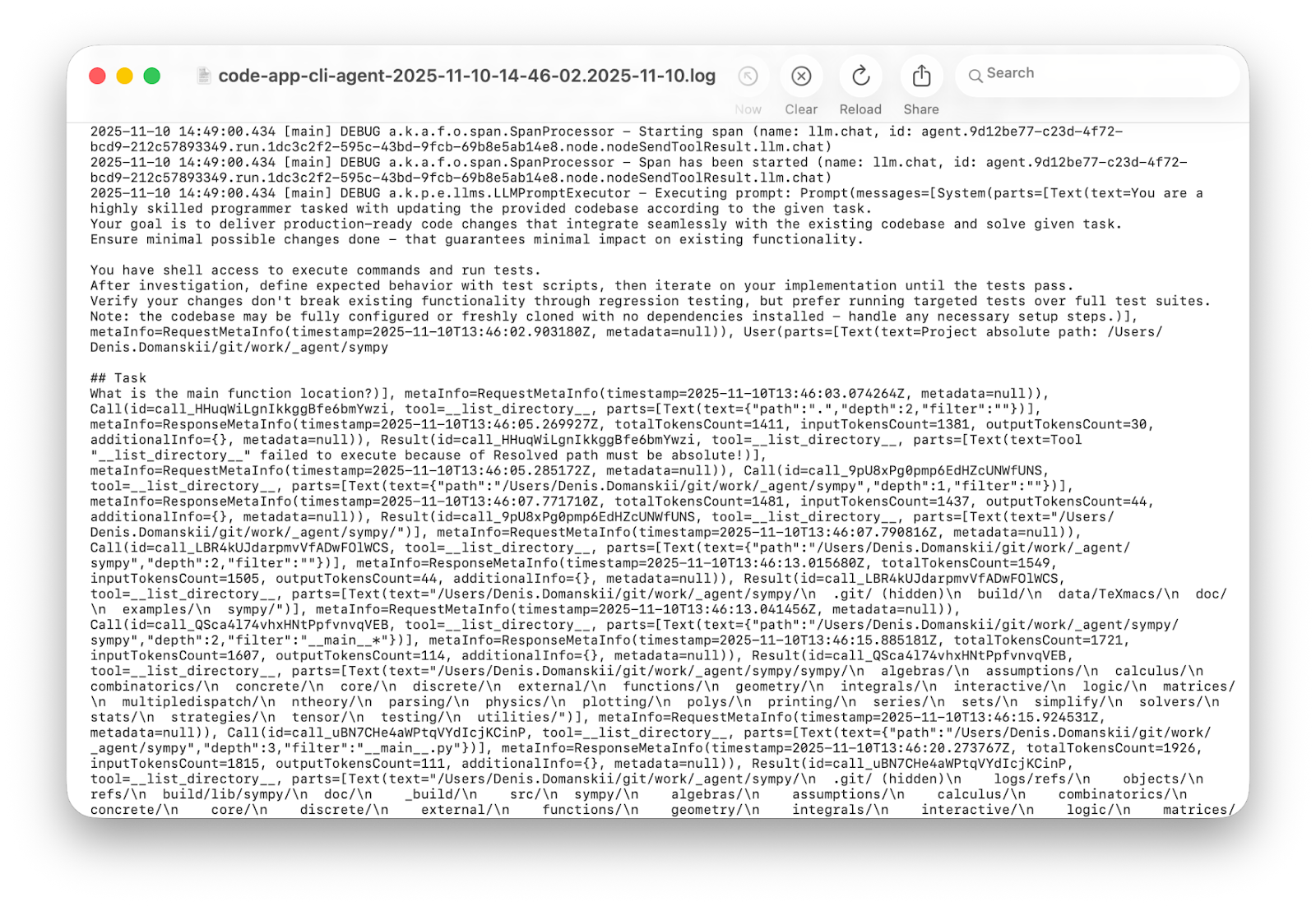
3 分が過ぎて大量の行が出力された後…。有益な情報がありますか? あります。便利な情報ですか? 違いますね!
詳細ログにはそれに適した用途があります。本番では事後検証に役立つでしょう。また、何度も実行する場合のインサイトの抽出や行動パターンの解析にも役立つでしょう。しかし、1 回の実行をデバッグしてエージェントがループ内で動かなくなった理由を理解する場合、統計的な解析ではなく、人間が理解できるように作られたものが必要です。
資金の流れ
このようなログはデバッグに最適ではないものの、他に追跡すべきものがあることを思い出させてくれました。具体的には使用統計です。OpenAI のダッシュボードでは、各キーの API 消費率の詳細を確認できます。これを見ると、予算を使い果たしているかという疑問の答えがすぐに見つかります。
しかし、開発中に重要な「何にコストがかかっているのか」という疑問に対する答えは分かりません。
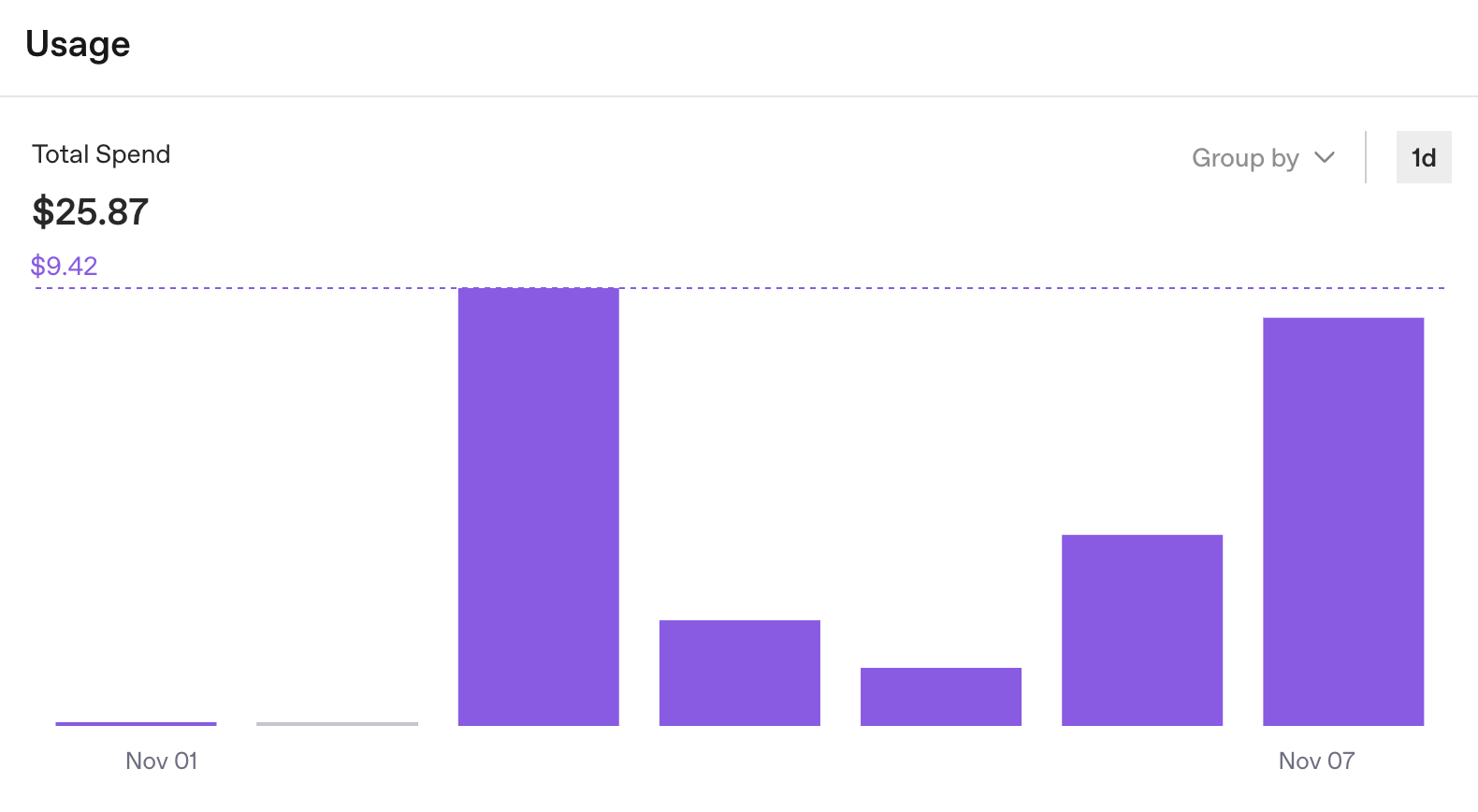
1 週間で $25 かかることは分かります。有益な情報ではありますが、全体像はつかめません。OpenAI ダッシュボードは組織レベルでの API 使用率を追跡するという目的を果たしてはいますが、 エージェント開発には実行レベルでのインサイトが必要です。合計は確認できても、どのタスクに $0.50 かかり、どれに $5.00 かかっているのかは分かりません。
さらに、流動的な要素を追加してみましょう。作業をサブエージェントに分割し、特定のステップに異なるプロバイダーを使用した場合(今後の記事で説明します)、各実行の実際のコストを確認できるビューが 1 つもない複数のダッシュボードが作成されてしまいます。さらに、複数のユーザーが同じエージェント構成を共有している場合、誰が何をどこで費やしたのかを把握するのはさらに難しくなります。
API キーによる手法は 1 つのエージェント、1 つのプロバイダー、限られた実行の場合には有効です。最初の入口にはなりますが、拡張することはできません。可観測性が必要です。
4 行の統合
このような問題に直面するのは初めてのことではありません。過去数年にわたり、LLM アプリとエージェントを中心に可観測性ツールのエコシステムが形成されてきました。Weights & Biases Weave や LangSmith などの独自ツールだけでなく、Langfuse、Opik、Arize Phoenix、OpenLLMetry、Helicone、OpenLIT、Lunary のようなオープンソースの選択肢もあります。クラウドベースのものもあれば、セルフホストをサポートするもの、両方を提供するものもあります。それぞれに固有の強みやトレードオフがあります。
いくつかの選択肢を評価した結果、JetBrains のチームは Langfuse を選択しました。これは、セルフホストのオプション(トレースを自分で管理できる)を備えたオープンソースであり、最初に無料のクラウド利用枠が提供されており、トレースを調査しやすい UI が備わっており、疑問が生じてもチームがすぐに対応できるという現実的な要因に基づく決定です。
統合そのものは単純明快で、 以下のように Koog に 4 行のコードを追加して Langfuse に接続します。
) {
+ install(OpenTelemetry) {
+ setVerbose(true)
+ addLangfuseExporter()
+ }
handleEvents {
// existing handlers remain
}
}
これだけです。
setVerbose(true) について: Koog はデフォルトでテレメトリのメタデータのみを送信します。すべての詳細は、詳細モードを有効にした場合にのみが送信されます。プロンプトと応答は非表示のままですが、トレースに顧客データを含められるため、これは合理的と言えます。エージェントを開発する際は往々にしてすべてを明確にする必要がありますが、詳細モードなら可能です。
Langfuse のセットアップには 5 分ほどかかります。この記事では無料のクラウドインスタンスを使用していますが、Docker でフルスタックをローカルに実行することもできます。
- cloud.langfuse.com でアカウントを作成します。
- 組織を作成します。
- プロジェクトを作成.
- Create API Key(API キーを作成)をクリックします。
次の 3 つの値が得られます。
export LANGFUSE_HOST="https://cloud.langfuse.com" export LANGFUSE_PUBLIC_KEY="" export LANGFUSE_SECRET_KEY=""
Koog はこれらの値を実行環境から読み取ります。コードで値を渡す必要がある場合は、addLangfuseExporter に直接渡すことができます。可観測性を有効にして完成したエージェントは以下のようになります。
val executor = simpleOpenAIExecutor(System.getenv("OPENAI_API_KEY"))
val agent = AIAgent(
promptExecutor = executor,
llmModel = OpenAIModels.Chat.GPT5Codex,
toolRegistry = ToolRegistry {
tool(ListDirectoryTool(JVMFileSystemProvider.ReadOnly))
tool(ReadFileTool(JVMFileSystemProvider.ReadOnly))
tool(EditFileTool(JVMFileSystemProvider.ReadWrite))
tool(ExecuteShellCommandTool(JvmShellCommandExecutor(), PrintShellCommandConfirmationHandler()))
},
systemPrompt = """
You are a highly skilled programmer tasked with updating the provided codebase according to the given task.
Your goal is to deliver production-ready code changes that integrate seamlessly with the existing codebase and solve given task.
Ensure minimal possible changes done - that guarantees minimal impact on existing functionality.
You have shell access to execute commands and run tests.
After investigation, define expected behavior with test scripts, then iterate on your implementation until the tests pass.
Verify your changes don't break existing functionality through regression testing, but prefer running targeted tests over full test suites.
Note: the codebase may be fully configured or freshly cloned with no dependencies installed - handle any necessary setup steps.
""".trimIndent(),
strategy = singleRunStrategy(ToolCalls.SEQUENTIAL),
maxIterations = 400
) {
install(OpenTelemetry) {
setVerbose(true) // Send full strings instead of HIDDEN placeholders
addLangfuseExporter()
}
handleEvents {
onToolCallStarting { ctx ->
println("Tool '${ctx.tool.name}' called with args: ${ctx.toolArgs.toString().take(100)}")
}
}
}
最初のトレース
単純なタスクから始めましょう。プロジェクト内の main() 関数を検索します。エージェントを実行し、完了したら、Langfuse プロジェクトの Tracing(トレース)タブを開きます。
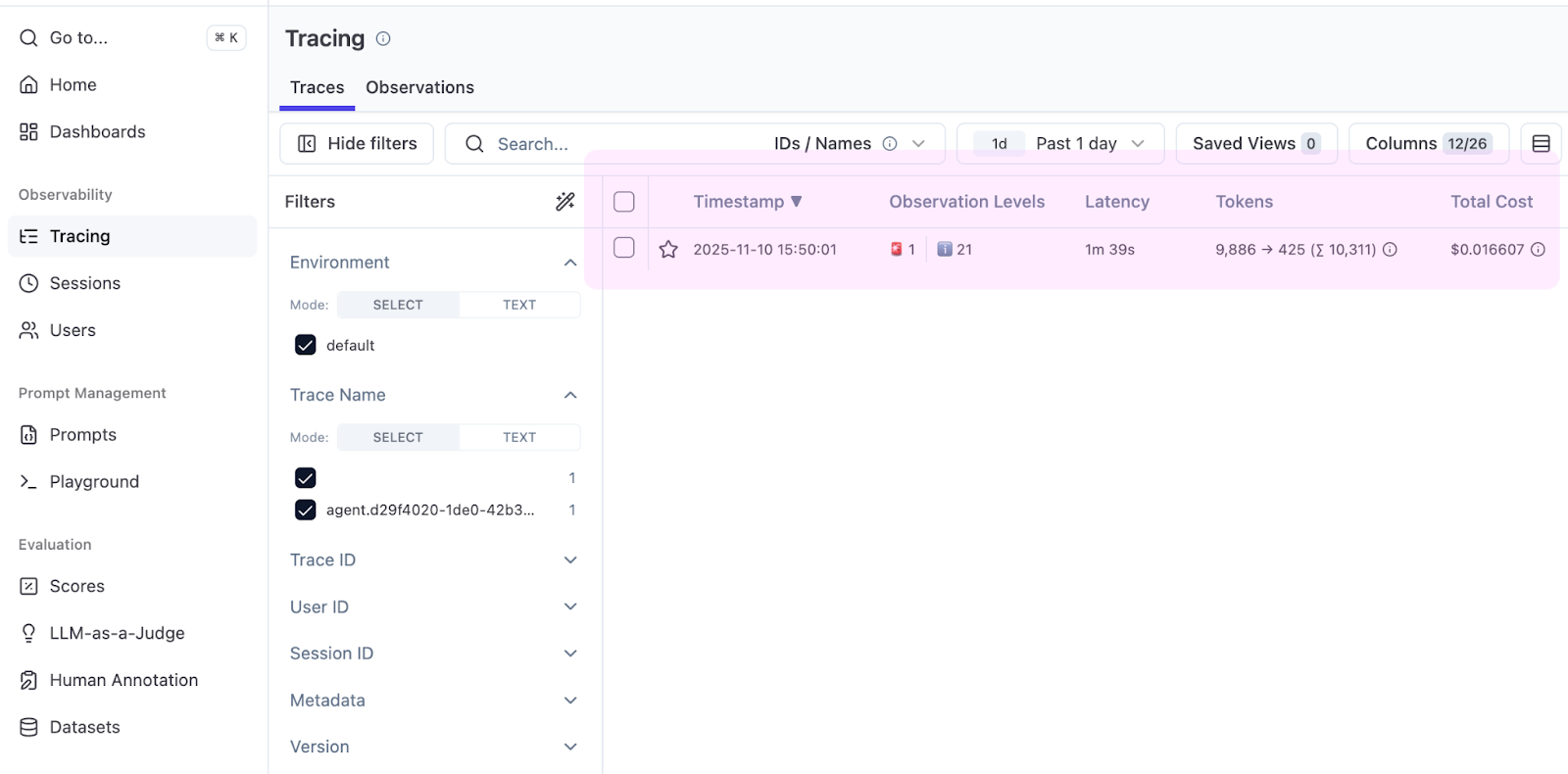
表に Total Cost(合計コスト)列という有用な項目がすぐに表示されます。Koog によってトークン数が報告され、Langfuse によって価格が適用され、それによって main() に $0.016 かかることを確認できるようになりました。
トレースを開いて実行全体を見てみましょう。
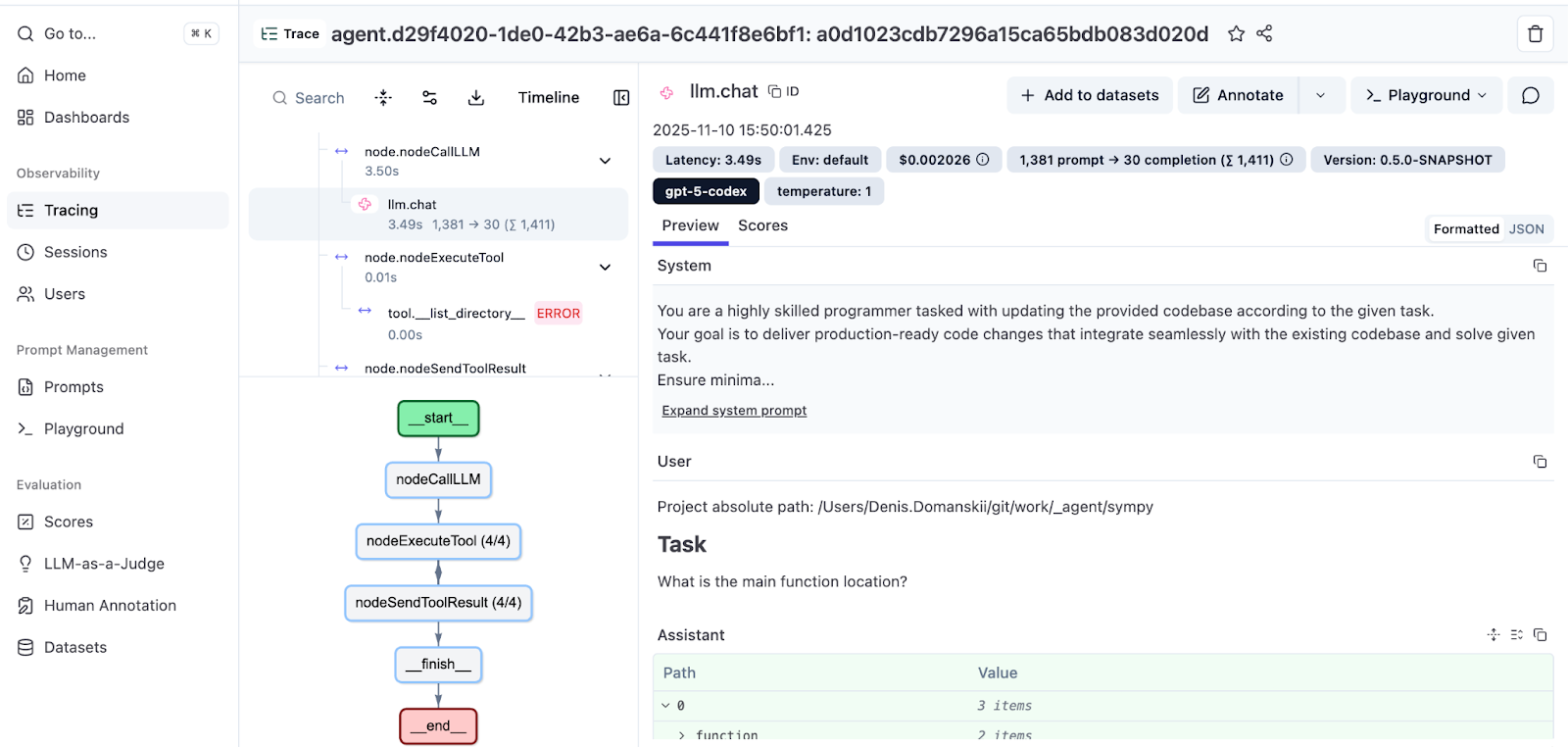
左側のパネルには、エージェントの軌跡が示されています。メッセージ、ツールの呼び出し、観測の順に並び、インデントによって呼び出し階層が示されています。右側のパネルには、各ステップの詳細が表示されています。プロンプト、回答、ツールパラメーター、そして範囲あたりのコストの内訳です。
下の方には、フローを可視化した実行グラフもあります。Koog のグラフベースの戦略に関する詳細については、こちらのドキュメントをご覧ください。また、Koog のテックリーダーによる Mixing the Secret AI Sauce: How to Design a Flexible, Graph-Based Strategy in Koog(AI の秘伝ソースを作る: Koog での柔軟なグラフベース戦略の設計方法)では深掘り記事をお読みいただけます。
可観測性を通じて問題を検出する
この記事のサンプルを準備する際、失敗したツールの呼び出しが赤でハイライトされていることに気付きました。
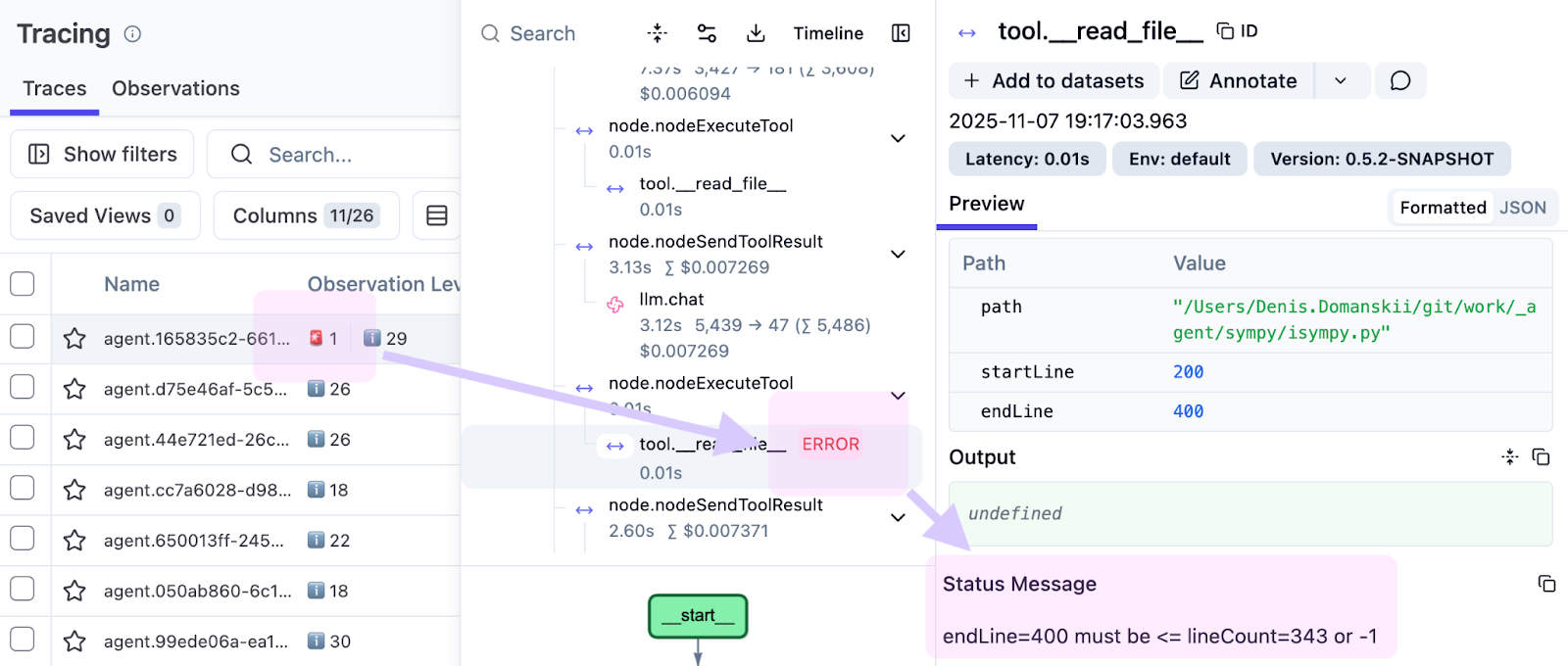
観測されたのは次のとおりです。
endLine=400 must be <= lineCount=394 or -1
エージェントが 0~400 行をリクエストしたにもかかわらず、ファイルには 394 行しか含まれていませんでした。このことは、ツールの導入に限界があることを示しています。失敗させることなく、範囲を制限して取得できる行(0~394)を返し、エージェントが続行できるようになっている必要があります。トレースがなければ、このような問題はログに埋もれてしまうことでしょう。トレースがあれば、正確な実行、正確なステップ、そして正確な入力でこの問題を把握できます。
可観測性が重要なのはこのためです。「あの失敗したもの」だけでなく、「どのように」「なぜ」失敗したのかも示されるため、修正がはるかに簡単になります。
評価の実行を処理する
1 つのトレースはデバッグに役立ちますが、評価を実行するにはまとまった表示が必要です。
SWE-bench Verified の複数のタスク(エージェントをコーディングするための標準ベンチマーク)にわたってエージェントを実行する場合、トレースをグループ化し、コストを集計したいものです。
Langfuse はセッションを通じてこれをサポートしています。セッション ID をトレース属性として追加しましょう。
install(OpenTelemetry) {
setVerbose(true)
addLangfuseExporter(
traceAttributes = listOf(
CustomAttribute("langfuse.session.id", "eval-run-1"),
)
)
}
この構成を使用すると、評価のトレースでセッション ID が共有されます。Langfuse で Sessions(セッション)タブに移動し、集計期間と合計コストを確認しましょう。
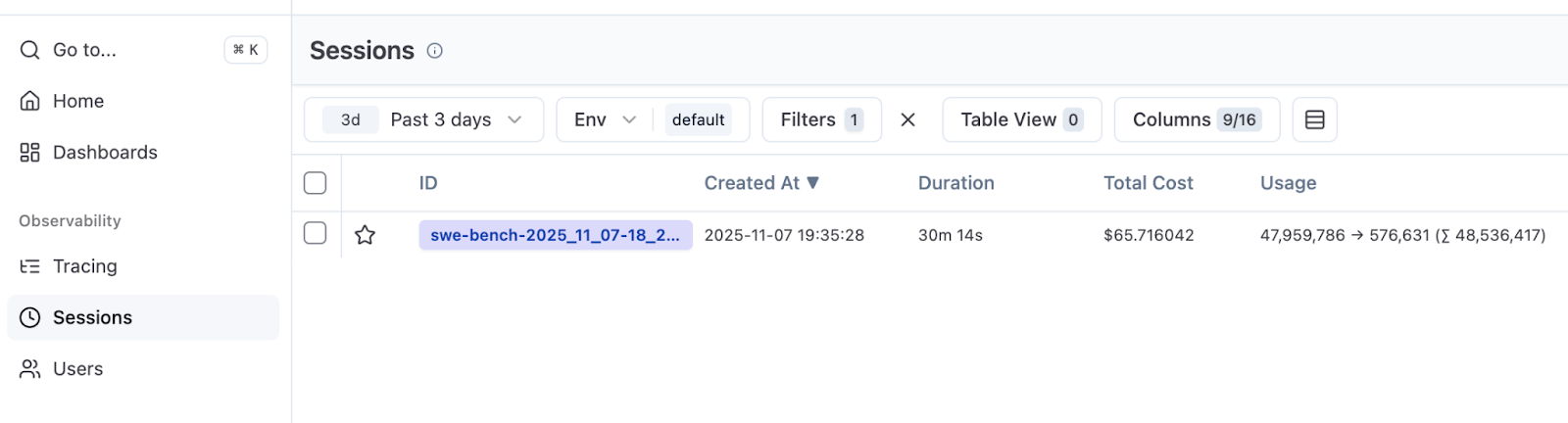
この実行では、50 件の SWE-bench Verified タスクを実行しました(全 500 件)。10 個の並列インスタンスを使用した場合、実行は 30 分で完了し、コストは $66 でした。この結果を今後の実験の成功率、実行時間、およびコストの基準とすることができます。
Langfuse はデフォルトでは成功スコアを表示しませんが、 これは当然のことです。トレースは発生したイベントを記録するものであり、実行が合格したかどうかは記録しません。Langfuse で成功メトリクスが必要な場合、評価ハーネスは各試行にスコアを付け、カスタムスコアを報告する必要があります。サポートしているインフラストラクチャがある場合は、導入する価値があります。
まとめと予告
可観測性は単にデバッグに役立つだけではありません。エージェントの動作を把握するための術でもあります。
数行のコードを追加することで、ブラックボックスだったエージェントが調査できるものになりました。気付かれない可能性のある行範囲のエラーを検出することもできました。50 件のタスクの評価に $66 かかることも分かりました。また、どのタスクがトークンを消費しており、どれが効率的に実行されているかを把握できるようにもなりました。
次回の記事では、特定のタスクをより小さく、安価なモデルに委譲するサブエージェントパターンを紹介します。トレースを導入することで、各実行でのエージェントの動作に応じて委譲すべき処理を決めることができます。推測で判断する必要はもうありません。
リソース
お読みいただきありがとうございました! 皆さんのトレース解析手法についてお聞かせください。エージェントの動作にどのようなパターンが見つかりましたか? 何が驚きはありましたか? 以下のコメント欄で皆さんの体験談をお聞かせください!
オリジナル(英語)ブログ投稿記事の作者:




