

PyCharm で Jupyter ノートブックを活用する 7 つの方法 | データサイエンスに最適なツール

Jupyter ノートブックではデータ、式、および視覚表現を順に作成して共有し、ノートブックを読み進めながら補足的なナラティブを付けることで、ストーリーを伝えることができます。
PyCharm Professional での Jupyter ノートブックでは、ブラウザーベースの Jupyter ノートブックの機能を凌駕するコード補完、動的プロット、クイック統計などの機能を使用できるため、素早く効果的にデータを探索して処理できます。
PyCharm で Jupyter ノートブックを使用して目標を達成するための 7 つの方法を見てみましょう。 紹介するのは以下の方法です。
- Jupyterノートブックの作成と接続方法 | PyCharm ガイド
- データインポート手順 | CSVとデータベースからのインポート
- データ解析の基本 | DataFrame を使ったデータの確認
- JetBrains AI Assitant の活用 | PyCharm での効率化
- PyCharm でのコードの詳細確認とリファクタリング
- データからインサイトを引き出す方法 | Jupyter ノートブック活用
- インサイトの共有とエクスポート方法 | データ可視化
このデモで使用する Jupyter ノートブックは GitHub で提供されています。
1. Jupyter ノートブックの作成と接続方法 | PyCharm ガイド
PyCharm ではローカルまたはリモート接続で Jupyter ノートブックを作成および操作できます。 両方のオプションを見て自分で決められるようにしましょう。
Jupyter ノートブックの新規作成
ローカルで Jupyter ノートブックを操作するには、PyCharm の Project(プロジェクト)ツールウィンドウを開き、ノートブックを追加する場所に移動してから新しいファイルを呼び出します。 これはキーボードショートカットの ⌘N(macOS)/ Alt+Ins(Windows/Linux)を使用するか、右クリックして New(新規)| Jupyter Notebook(Jupyter ノートブック)を選択することで実行できます。
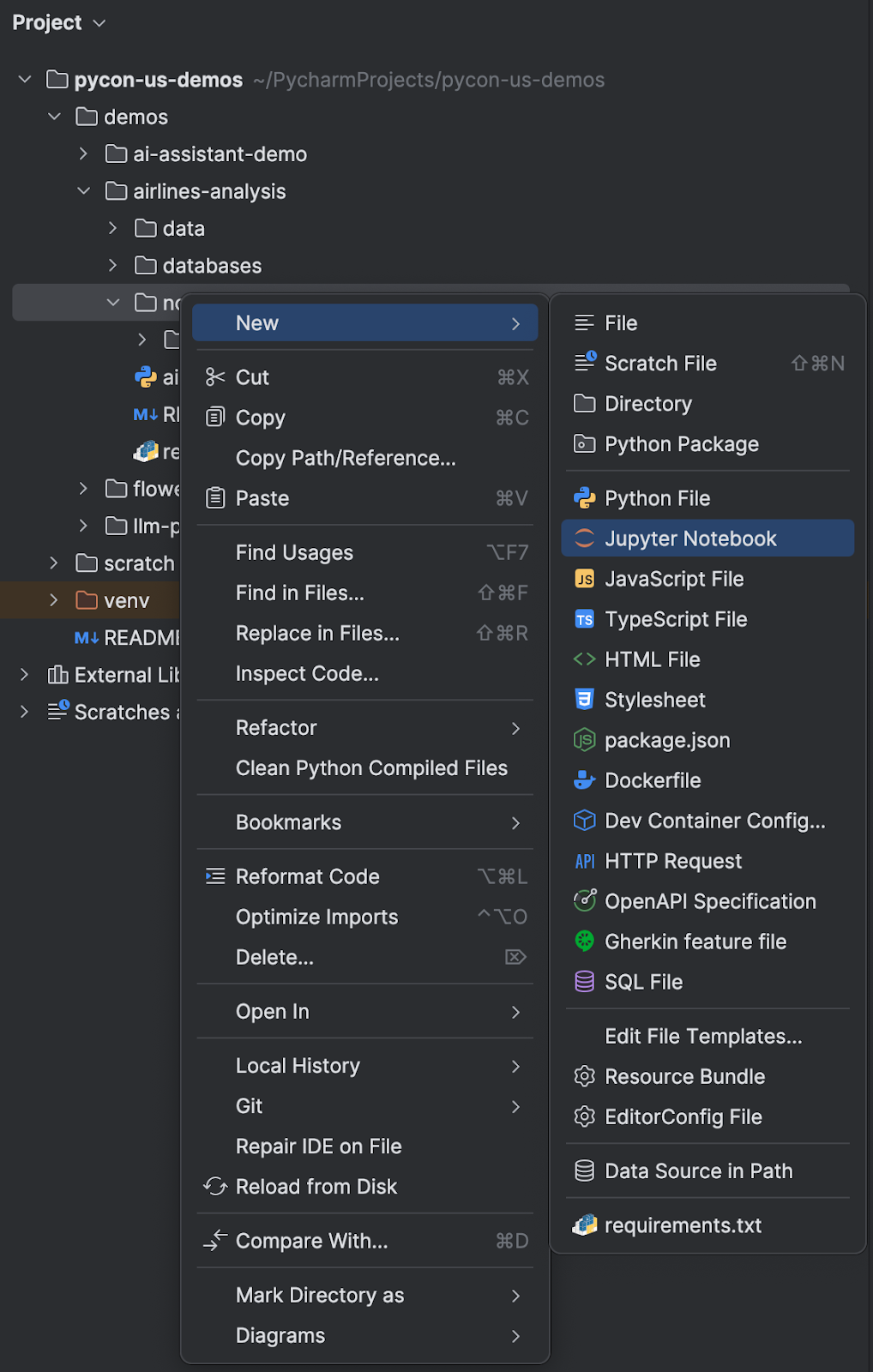
新しいノートブックに名前を付けると、PyCharm ですぐに作業できる状態で開かれます。 また、Jupyter ノートブックを PyCharm にドラッグした場合は IDE が自動的にノートブックを認識します。
リモート Jupyter ノートブックへの接続
リモートの Jupyter ノートブックに接続することもできます。Tools(ツール)| Add Jupyter Connection(Jupyter 接続の追加)を選択したら、 起動するローカルの Jupyter サーバーを選択し、実行中の既存の Jupyter サーバーに接続するか、URL を使用して Jupyter サーバーに接続します。これらのすべてのオプションがサポートされています。
これで Jupyter ノートブックの準備ができました。次はデータが必要です!
2. データインポート手順 | CSV とデータベースからのインポート
データは一般的に CSV とデータベースの 2 つの形式があります。 まずは CSV ファイルからデータをインポートする方法を見てみましょう。
CSV ファイルからのインポート
Jupyter ノートブックにデータをインポートする際には、Polars と pandas の 2 つのライブラリが最もよく使用されています。 このセクションでは両方のライブラリのコードを提供しますので、Polars と pandas の両方のドキュメントを確認し、Polars と pandas との違いを理解してください。
CSV は PyCharm プロジェクト内(たとえば `data` というフォルダー)に置く必要があります。 次に import で pandas を呼び出し、それを使用して CSV を読み取ることができます。
import pandas as pd
df = pd.read_csv("../data/airlines.csv")
この例では、airlines.csv が操作対象のデータを含むファイルです。 PyCharm でこのセルと任意のコードセルを実行するには、⇧⏎ (macOS)/ Shift+Enter(Windows/Linux)を使用します。 上部のツールバーにある緑色の実行矢印を使用することもできます。
Polars を使用する場合は以下のコードを使用できます。
import polars as pl
df = pl.read_csv("../data/airlines.csv")
データベースからのインポート
社内プロジェクトではデータベース内にデータがあることもしばしばです。このような場合に Jupyter ノートブックへデータをインポートするには、さらに数行のコードが必要になります。 まずはデータベース接続のセットアップが必要です。 この例では PostgreSQL を使用しています。
pandas の場合は以下のコードを使用してデータを読み取る必要があります。
import pandas as pd
engine = create_engine("postgresql://jetbrains:jetbrains@localhost/demo")
df = pd.read_sql(sql=text("SELECT * FROM airlines"),
con=engine.connect())
また、Polars の場合は以下のコードを使用します。
import polars as pl
engine = create_engine("postgresql://jetbrains:jetbrains@localhost/demo")
connection = engine.connect()
query = "SELECT * FROM airlines"
df = pl.read_database(query, connection)
3. データ解析の基本 | DataFrame を使ったデータの確認
データを読み取り、DataFrame を確認できるようになりました。この例のコードでは `df` として参照します。 DataFrame を出力するには、次の 1 行のコードのみが必要です。データの読み取りに使用した方法は関係ありません。
df
DataFrame
PyCharm は最初に DataFrame をテーブル形式で表示し、参照しやすくします。 DataFrame は横方向にスクロール可能で、任意の列ヘッダーをクリックしてその列でデータを並べ替えることもできます。 右側にある Show Column Statistics(列統計の表示)アイコンをクリックし、Compact(コンパクト)または Detailed(詳細)を選択することで、データの各列の有用な統計を取得できます。
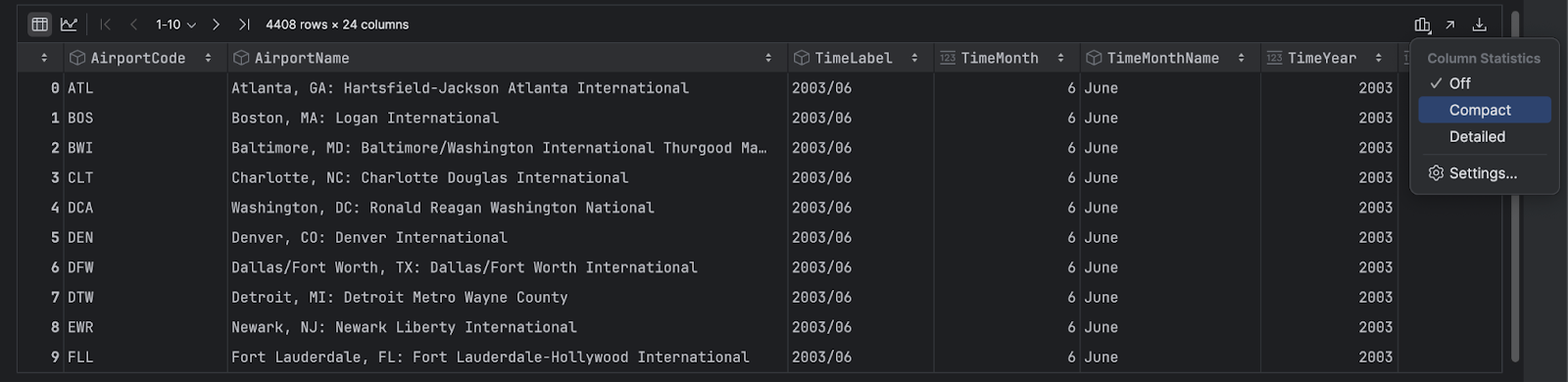
動的チャート
PyCharm で左側の Chart View(チャートビュー)アイコンをクリックすると、DataFrame の動的チャートを取得できます。 この例では pandas を使用していますが、Polars DataFrame でも同じオプションを使用できます。
右側にある Show Series Settings(系列の設定の表示)アイコン(歯車)をクリックし、プロットをニーズに合わせて構成します。
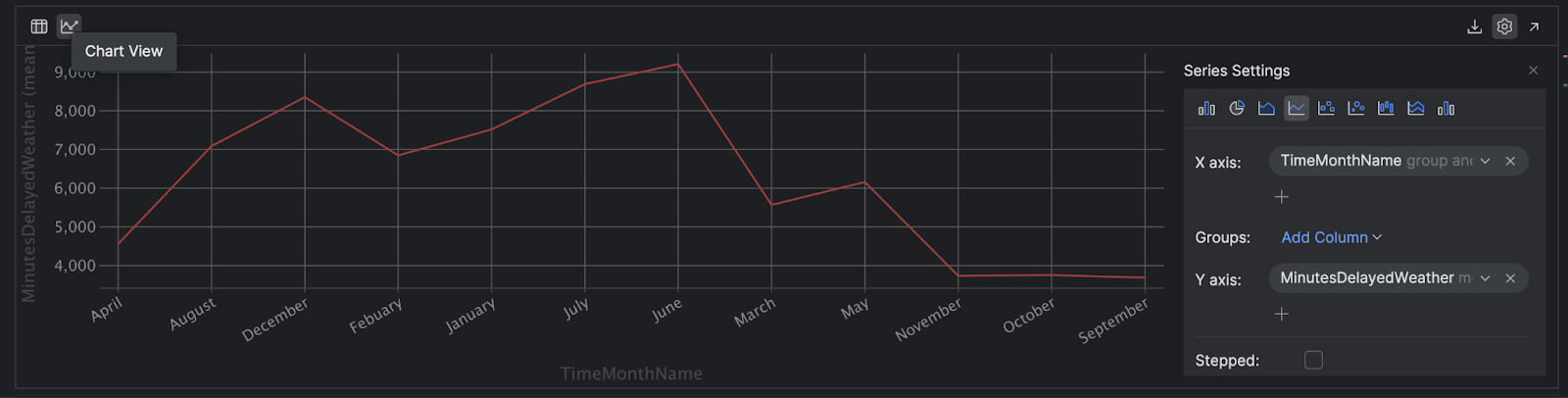
このビューでデータにマウスポインターを合わせると、そのデータの詳細を見て簡単に外れ値を確認できます。
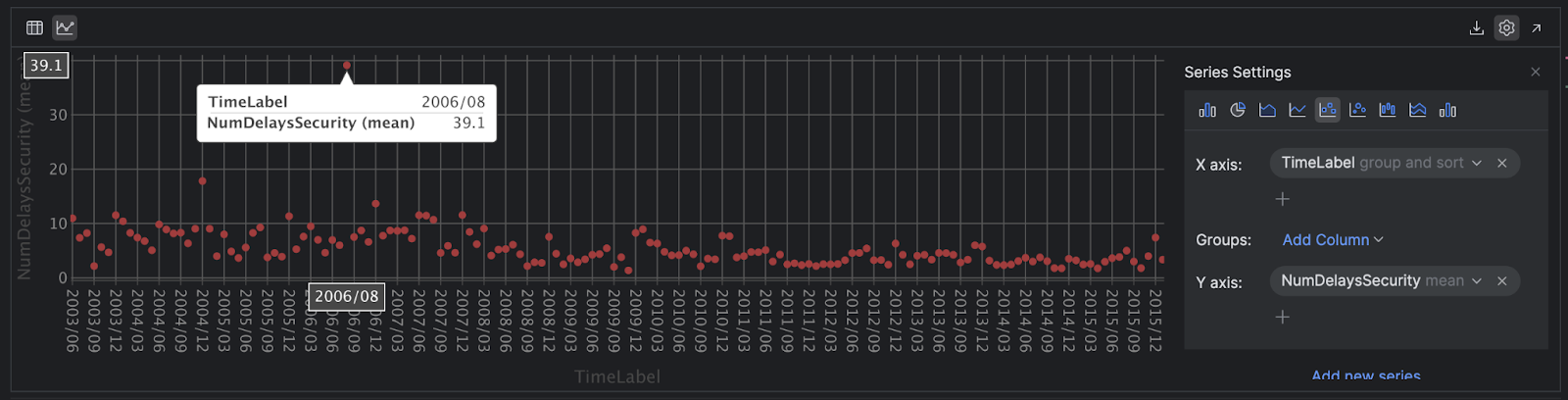
これらすべての操作は Polars でも可能です。
4. JetBrains AI Assistant の活用 | PyCharm での効率化
JetBrains AI Assistant には、PyCharm 内で Jupyter ノートブックを扱う際の生産性を高める機能が複数備わっています。 JetBrains AI Assistant を使用して DataFrame の説明、コーディング支援、エラーの説明を得る方法を詳しく見てみましょう。
DataFrame の説明
DataFrame があるものの、何から着手すべきか分からない場合、DataFrame の右側にある紫色の AI アイコンをクリックして Explain DataFrame(DataFrame の説明)を選択できます。 JetBrains AI Assistant が DataFrame の概要をそのコンテキストを使用して示します。
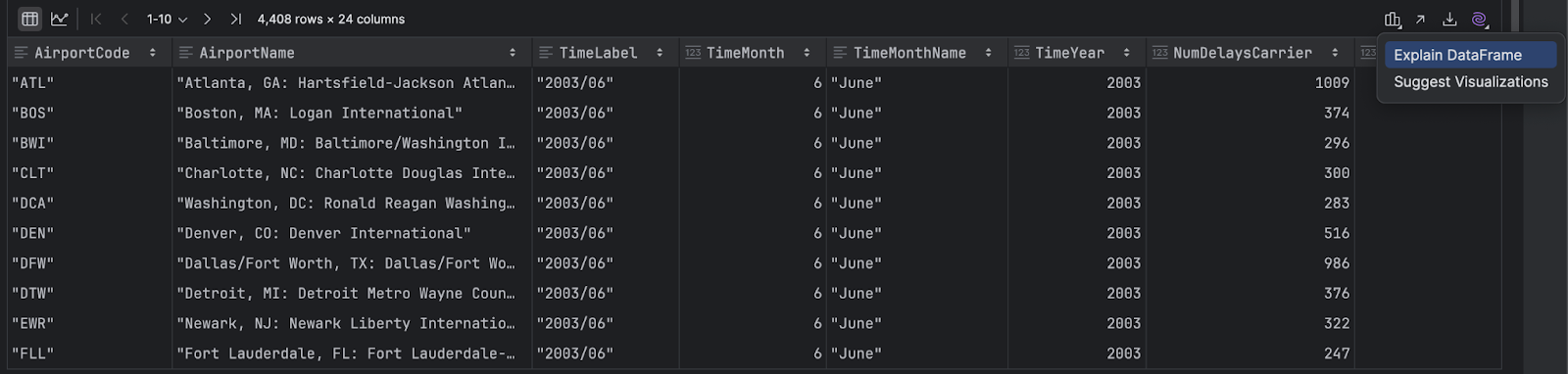
生成された説明を使用することで、理解を高めることができます。
コーディング
JetBrains AI Assistant からコーディング支援を得ることもできます。 どのようなプロットが必要かは分かっていても、どのようにコーディングすればよいのかは確信を持てないことがあるかと思います。 そのような場合に JetBrains AI Assistant を使用して支援を得られるようになりました。 ‘matplotlib’ を使用して ‘TimeMonthName’ と ‘MinutesDelayedWeather’ の関係を明らかにするチャートを作成したいと仮定しましょう。 列名を指定することで、生成コードの信頼性を高めるのに役立つコンテキストをより多くリクエストに含めることができます。 以下のプロンプトを試してみてください。
Give me code using matplotlib to create a chart which finds the relationship between ‘TimeMonthName’ and ‘MinutesDelayedWeather’ for my dataframe df
(matplotlib を使って DataFrame df の ‘TimeMonthName’ と ‘MinutesDelayedWeather’ の関係を明らかにするチャートを作成するコードを生成してください)
生成されたコードが適切であれば、Insert Snippet at Caret(キャレット位置にスニペットを挿入)ボタンを使用してコードを挿入し、実行できます。
import matplotlib.pyplot as plt
# Assuming your data is in a DataFrame named 'df'
# Replace 'df' with the actual name of your DataFrame if different
# Plotting
plt.figure(figsize=(10, 6))
plt.bar(df['TimeMonthName'], df['MinutesDelayedWeather'], color='skyblue')
plt.xlabel('Month')
plt.ylabel('Minutes Delayed due to Weather')
plt.title('Relationship between TimeMonthName and MinutesDelayedWeather')
plt.xticks(rotation=45)
plt.grid(axis='y', linestyle='--', alpha=0.7)
plt.tight_layout()
plt.show()
AI Assistant ツールウィンドウを開きたくない場合は、AI セルのプロンプトを使用して質問することができます。 たとえば、ここでも同じ質問をして必要なコードを取得できます。
![]()
エラーの説明
JetBrains AI Assistant にエラーを説明してもらうこともできます。 エラーが発生したら、Explain with AI(AI で説明)をクリックします。

生成された出力を使用して問題に対する理解を深めるだけでなく、コードを自動修正することも可能です!
5. PyCharm でのコードの詳細確認とリファクタリング
PyCharm を使用すると、Jupyter ノートブックの概要を把握したり、コードの一部を補完して労力を節約したり、必要に応じてリファクタリングやデバッグを行ったり、さらには統合を追加してコードをレベルアップしたりできます。
コード内の移動操作とコードの最適化に関するヒント
Jupyter ノートブックはすぐに大規模になりがちですが、PyCharm の Structure(構造)ビューでは ⌘7(macOS)/ Alt+7(Windows/Linux)をクリックしてノートブックのすべての見出しを確認することができます。

コード補完
PyCharm 内で Jupyter ノートブックを使用する際には、コード補完機能を活用するのも便利です。 PyCharm では初期状態で基本的なコード補完と型ベースのコード補完の両方を使用できますが、PyCharm Professional ではローカルの AI モデルを使用して候補を提示する行全体コード補完も有効にできます。 最後に付け加えますが、JetBrains AI Assistant はコーディングや新しいライブラリとフレームワークの発見にも役立ちます。

リファクタリング
時にはコードをリファクタリングする必要があります。そんなときは ⌃T(macOS)/ Shift+Ctrl+Alt+T(Windows/Linux)のキーボードショートカットを 1 つだけ覚えておくだけで、呼び出したいリファクタリングを選択できます。 Rename(名前の変更)、Change Signature,(シグネチャーの変更)、Introduce Variable(変数の導入)などの一般的なオプションやあまり知られていない Extract Method(メソッドの抽出)などのオプションを選択することで、セマンティクスを変更せずにコードを書き換えることができます。
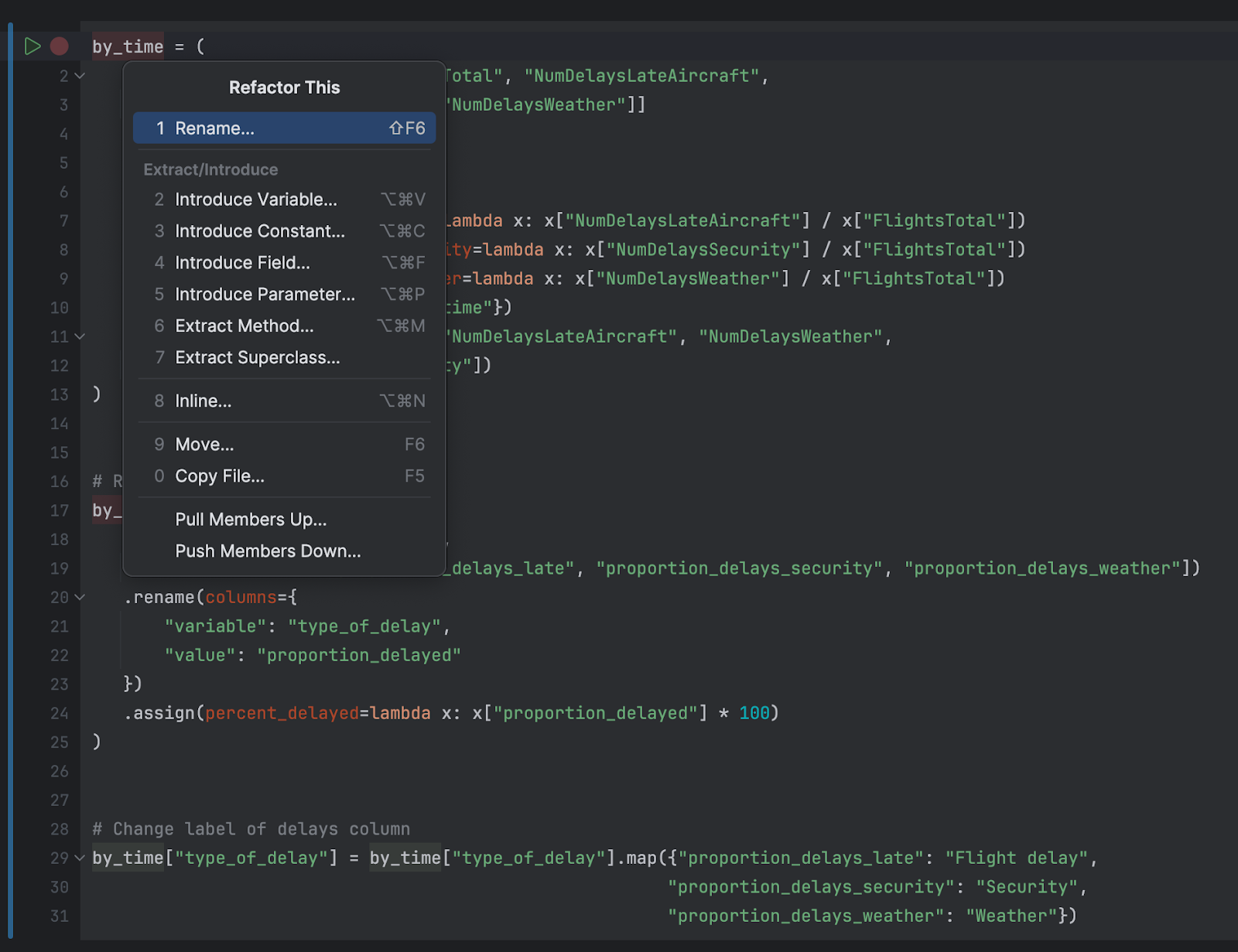
Jupyter ノートブックが大きくなるほど、import ステートメントの量も多くなりがちです。 polars や numpy などのパッケージをインポートしているのに、Polars ライブラリの推移的な依存関係である numpy は個別にインポートする必要がないということを忘れてしまうこともあるかと思います。
このような状況を検出してコードをクリーンに維持するため、⌃⌥O(macOS)/ Ctrl+Alt+O (Windows/Linux)で Optimize Imports(インポートの最適化)を呼び出し、PyCharm に不要なパッケージを除去させることができます。
コードのデバッグ
PyCharm でデバッガーを使用したことがなくても大丈夫です。 デバッガーがあり、Jupyter ノートブック内で何らかの動作への理解を深めたい場合にすぐに支援を得られることさえ覚えておけば十分です。
ガターをクリックするか ⌘F8(macOS)/ Ctrl+F8(Windows/Linux)を使用して調べたい行にブレークポイントを設定し、上部のツールバーにあるデバッグアイコンからアタッチされたデバッガーを使用してコードを実行します。

PyCharm のデバッガーは、Jupyter ノートブックで ⌥⇧⏎(macOS)/ Shift+Alt+Enter(Windows/Linux)を使用して呼び出すこともできます。 Jupyter ノートブックでのコードのデバッグにはいくつかの制約がありますが、実際にお試しになり、フィードバックをお寄せください。
PyCharm への統合の追加
必要な統合がなければ、IDE は完全とは言えません。 PyCharm Professional 2024.2 では、DataBricks と HuggingFace の 2 つの新しい統合をワークフローに導入できるようになっています。
Databricks と HuggingFace の両方との統合は、設定 ⌘(macOS)/ Ctrl+Alt+S(Windows/Linux)に移動し、Marketplace タブで Plugins(プラグイン)を選択して、それぞれの名前でプラグインを検索することで実現できます。
6. データからインサイトを引き出す方法 | Jupyter ノートブック活用
データを解析する場合、カテゴリ変数と連続変数には違いがあります。 カテゴリデータには有限の数の個別のグループまたはカテゴリが含まれますが、連続データは 1 つの連続した測定値です。 航空会社のデータセットに含まれるカテゴリ変数と連続変数の両方からどのように異なるインサイトを抽出できるかを見てみましょう。
連続変数
連続データの分布状況を知るには、そのデータ内の平均値の尺度と、平均値の周りのデータの広がりを調べます。 正規分布データでは平均値を使用して平均を測定し、標準偏差を使用して広がりを測定することができますが、 データが正規分布していない場合は、中央値と四分位範囲(75 パーセンタイルと 25 パーセンタイルの差)を使用すると、より正確な情報を得ることができます。 これらの測定値の違いを理解するため、連続変数の 1 つを見てみましょう。
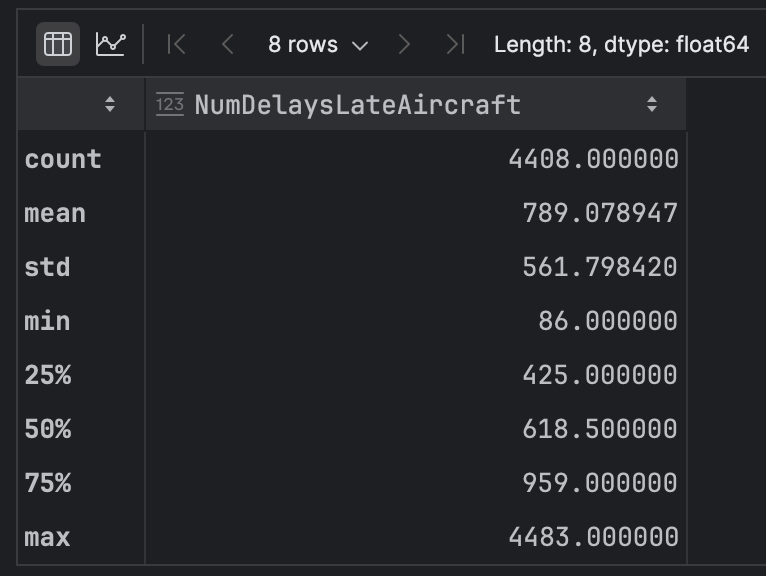
この例のデータセットには多数の連続変数がありますが、`NumDelaysLateAircraft` を使用して何を知ることができるのかを見ることにします。 以下のコードを使用して、その列だけの要約統計を取得してみましょう。
df['NumDelaysLateAircraft'].describe()
このデータを見ると、約 789 の `mean` と約 618 の ‘median’(以下のテーブルでは 50 パーセンタイルは「50%」と示されています)に大きな差があるのが分かります。
これは変数の分布に偏りがあることを意味していますので、PyCharm を使用してさらに詳しく調査してみましょう。 左上の Chart View(チャートビュー)アイコンをクリックします。 チャートが表示されたら、画面の右側の歯車アイコンで系列の設定を変更します。 x 軸を `NumDelaysLateAircraft` に、y 軸を `NumDelaysLateAircraft` に変更します。
次に、小さな矢印を使用して y 軸のドロップダウンから `count` を選択します。 最後に、右上のアイコンを使用してチャートタイプを Histogram(ヒストグラム)に変更します。
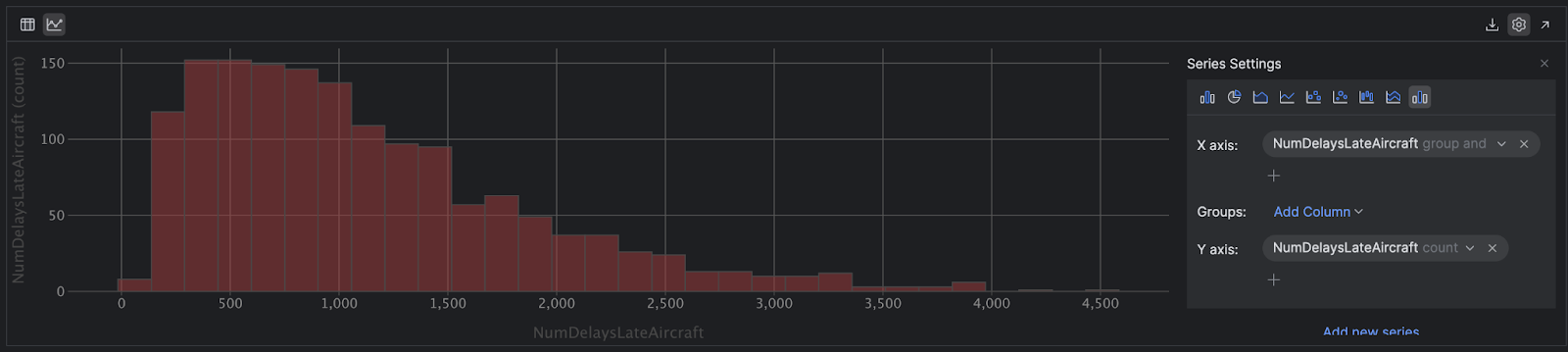
偏りが視覚的に表示されたことで、ほとんどの場合は遅延が過剰ではないことが分かりました。 ただし、さらに極端な遅延もいくつか発生しています。右側の 1 機は外れ値であり、4,509 分(3 日強)の遅延が発生しています!
統計学では平均値は幾何平均であるため、外れ値に大きく左右されます。変数内のすべての観測値を順序付けた場合、これらの値のちょうど真ん中に位置する中央値とは異なります。 平均値が中央値よりも高くなるのは、この例のようにデータの右側の高い側に外れ値があるためです。 ヒストグラムを見れば分かるように、このような場合は中央値が実際の平均遅延をより適切に示す指標となります。
カテゴリ変数
コードを使用してカテゴリ変数からインサイトを得る方法を見てみましょう。 `AirportCode` 単独よりもう少し興味深いものを得るため、1 年のさまざまな月(`TimeMonthName`)で天候によって遅延した航空機の数(`NumDelaysWeather`)を解析します。
以下のコードを使用して `NumDelaysWeather` と `TimeMonthName` をグループ化します。
result = df[['TimeMonthName', 'NumDelaysWeather']].groupby('TimeMonthName').sum()
result
ここでもテーブル形式で DataFrame が得られますが、PyCharm UI の左側にある Chart View(チャートビュー)をクリックして何が分かるかを見てみましょう。
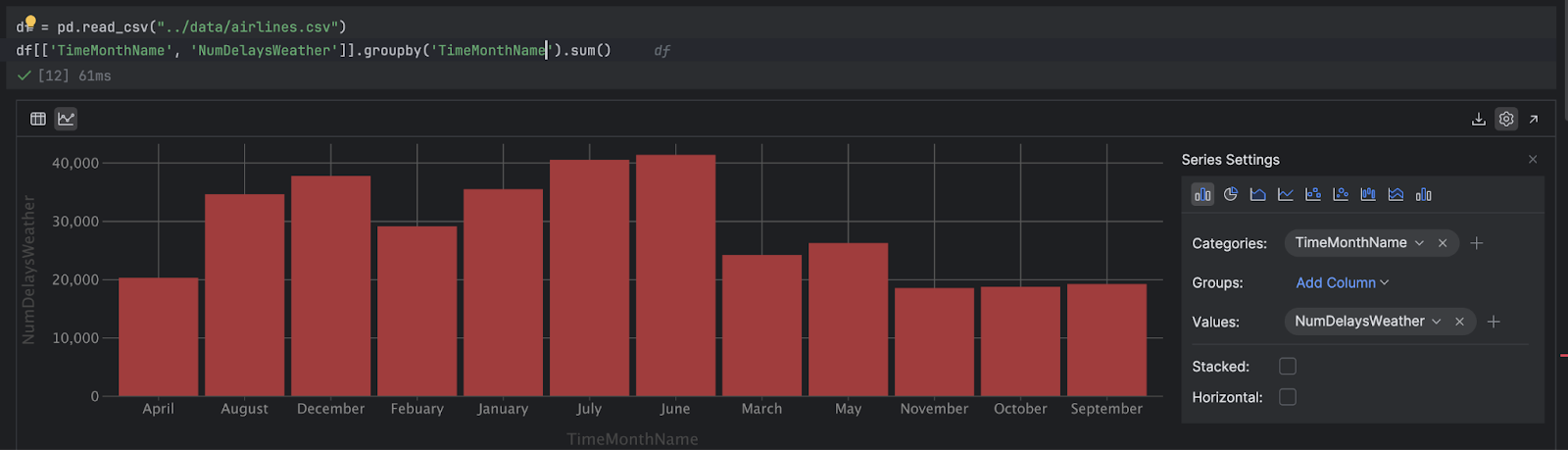
これでもいいですが、月をグレゴリオ暦に従って並べると便利でしょう。 まずは必要な月の変数を作成します。
month_order = [ "January", "February", "March", "April", "May", "June", "July", "August", "September", "October", "November", "December" ]
次に、`month_order` に定義したばかりの順序を使用するように PyCharm へ指示します。
# Convert the 'TimeMonthName' column to a categorical type with the specified order
df["TimeMonthName"] = pd.Categorical(df["TimeMonthName"], categories=month_order, ordered=True)
# Now you can group by 'TimeMonthName' and perform sum operation, specifying observed=False
result = df[['TimeMonthName', 'NumDelaysWeather']].groupby('TimeMonthName', observed=False).sum()
result
そして、もう一度 Chart View(チャートビュー)アイコンをクリックします。しかし、ここで問題が起きました!
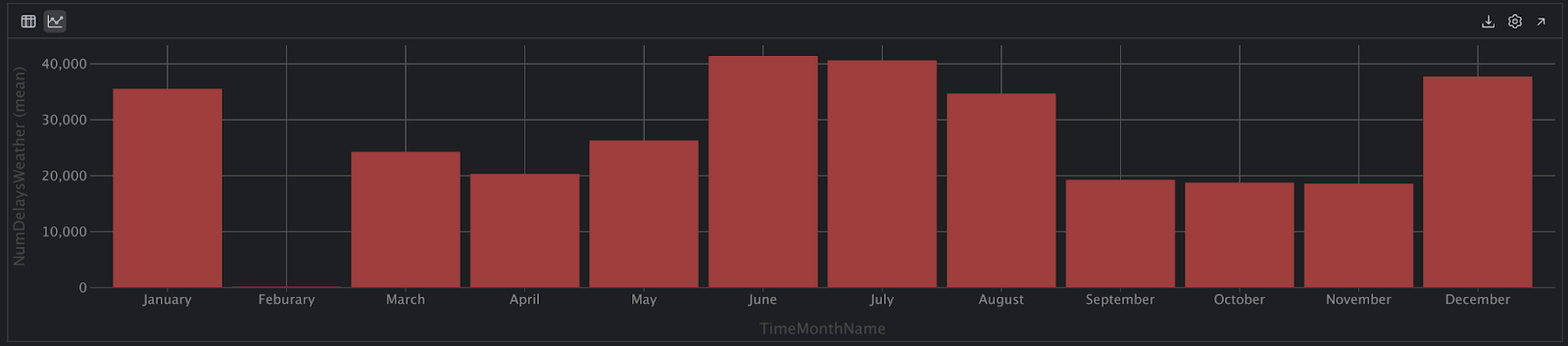
2 月には一便も遅延がなかったということでしょうか? そんなはずはありません。 さらに次のコードを使用して、仮説を検証してみましょう。
df['TimeMonthName'].value_counts()
やっぱり! データセット内の `Febuary` はスペルが間違っていたため、正しいスペルの変数名と一致していなかったことが分かりました。 以下のコードを使用してデータセットのスペルを更新しましょう。
df["TimeMonthName"] = df["TimeMonthName"].replace("Febuary", "February")
df['TimeMonthName'].value_counts()
これで大丈夫そうです。 先ほどのコードをもう一度実行し、解釈できるチャートビューを取得できるようになっているはずです。
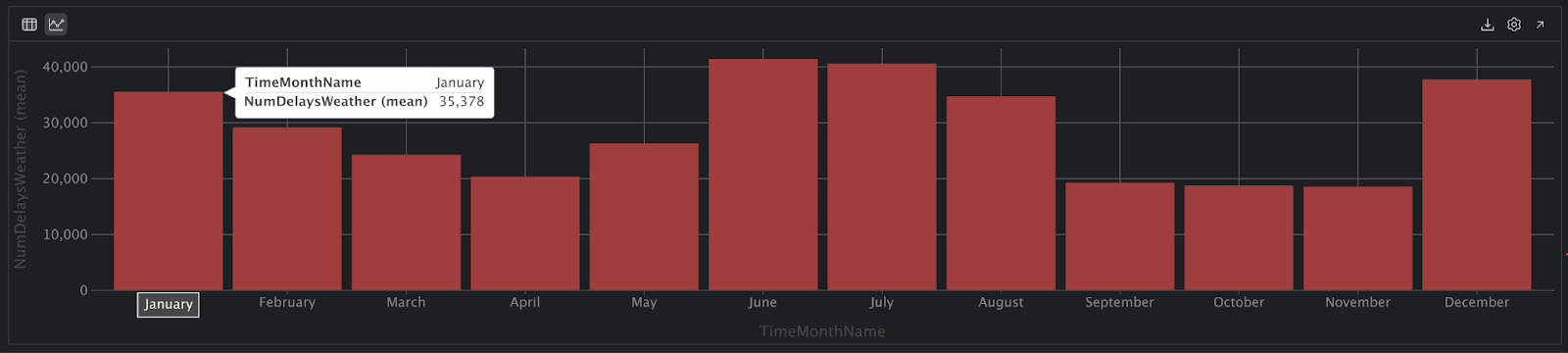
このビューから、12 月、1 月、2 月、そして 6 月、7 月、8 月の遅延数が高くなっているのがわかります。 ただし、このデータはフライトの合計数に対して標準化されていないため、これらの月のフライト数が多くなり、夏季と冬季の遅延も増加している可能性もあります。
7. インサイトの共有とエクスポート方法 | データ可視化
作品が完成したら、データをエクスポートしたくなるかと思います。PyCharm の Jupyter ノートブックでは、さまざまな方法でエクスポートできます。
DataFrame のエクスポート
右側にある下向きの矢印をクリックすると、DataFrame をエクスポートできます。
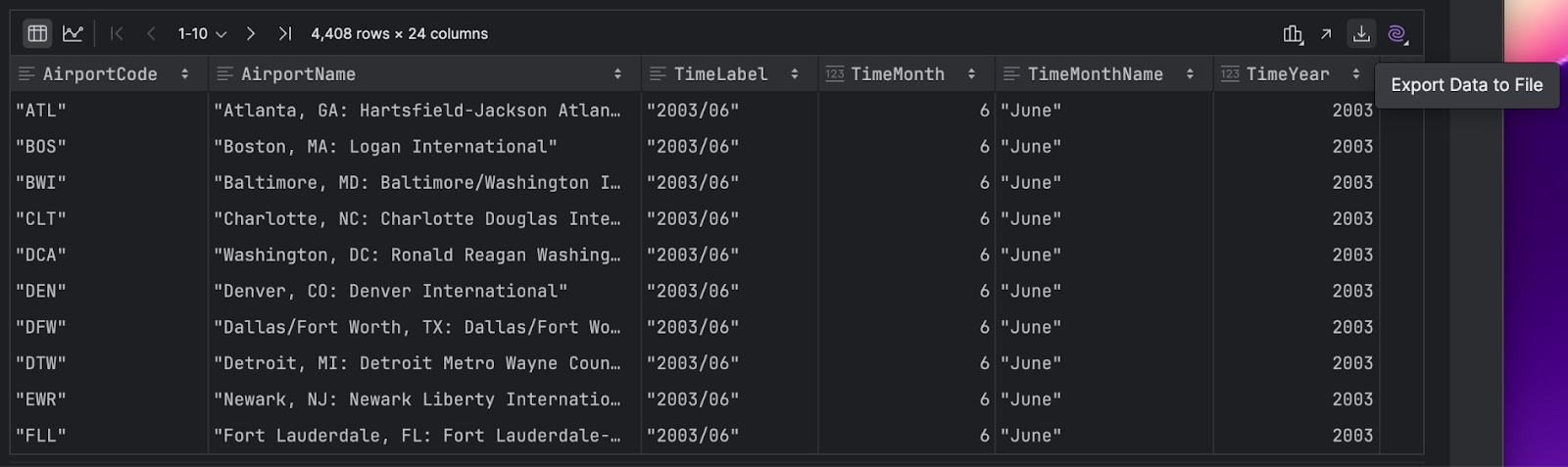
SQL、CSV、JSON など、多数の便利な形式から選択できます。
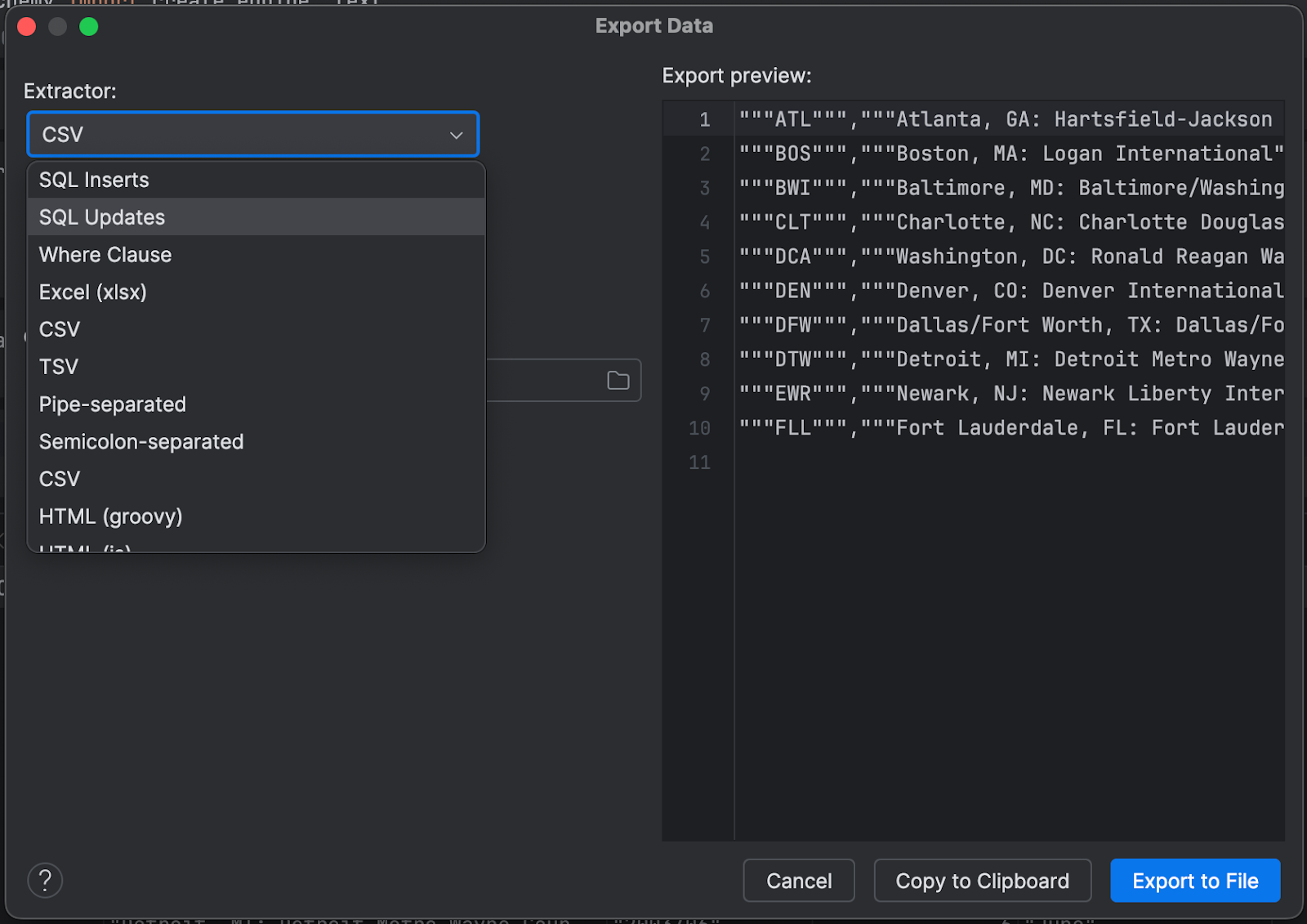
チャートのエクスポート
対話型プロットをエクスポートする場合は、右側の Export to PNG(PNG にエクスポート)アイコンをクリックして行えます。
ブラウザーでのノートブックの表示
ノートブックの右上のアイコンをクリックすることで、いつでも Jupyter ノートブック全体をブラウザーで表示できます。

最後に付け加えますが、2024.2 では Jupyter ノートブックを Python ファイルにエクスポートすることも可能です! Project(プロジェクト)ツールウィンドウで Jupyter ノートブックを右クリックし、Convert to Python File(Python ファイルに変換)を選択します。 指示に従えば完了します!
まとめ
PyCharm Professional 内で Jupyter ノートブックを使用すると幅広い機能を使用できるため、コードをより素早く作成し、データを簡単に探索し、必要な形式でプロジェクトをエクスポートできます。
PyCharm Professional をダウンロードして実際にお試しください! 今すぐ延長体験版を入手し、データサイエンス活動に大きな変化をもたらす PyCharm Professional をご体験ください。
お支払いの際にプロモコ―ド「PyCharmNotebooks」をご利用いただくと、PyCharm Professional の無料 60 日間サブスクリプションを有効化できます。 無料サブスクリプションは個人ユーザーのみに提供されます。





