

Hugging Face Transformers를 활용한 GPT 모델 세부 조정 및 배포

Hugging Face는 현재 머신러닝 연구자와 애호가들에게 널리 알려진 이름입니다. Hugging Face의 가장 큰 성공 사례 중 하나인 Transformers는 텍스트, 컴퓨터 비전, 오디오, 비디오 분야의 머신러닝 모델을 정의하는 프레임워크입니다. Hugging Face Hub에 방대한 첨단 머신러닝 모델이 있고, Transformers가 대부분의 트레이닝 프레임워크와 호환되기 때문에 추론과 모델 트레이닝에 널리 활용됩니다.
AI 모델을 세부 조정해야 하는 이유
AI 모델을 세부 조정하면 특정 작업과 데이터세트에 맞게 모델의 성능을 조정할 수 있으며, 범용 모델을 사용할 때보다 더 높은 정확도와 효율성을 달성할 수 있습니다. 사전 트레이닝된 모델을 활용해 세부 조정을 수행하면 처음부터 트레이닝할 필요가 줄어들어 시간과 리소스를 절약할 수 있습니다. 또한 특정 도메인의 고유한 형식, 뉘앙스, 예외적인 사례를 더 잘 처리할 수 있어, 더 신뢰성 있고 맞춤화된 결과를 제공합니다.
이 글에서는 수학 문제를 더 잘 처리할 수 있도록 GPT 모델을 수학적 추론 데이터로 세부 조정해 보겠습니다.
Hugging Face 모델 사용 방법
PyCharm을 사용하면 Hugging Face에서 원하는 모델을 손쉽게 찾아 추가할 수 있습니다. 새 Python 파일에서 상단의 Code(코드) 메뉴로 이동한 후 Insert HF Model(HF 모델 삽입)을 선택합니다.
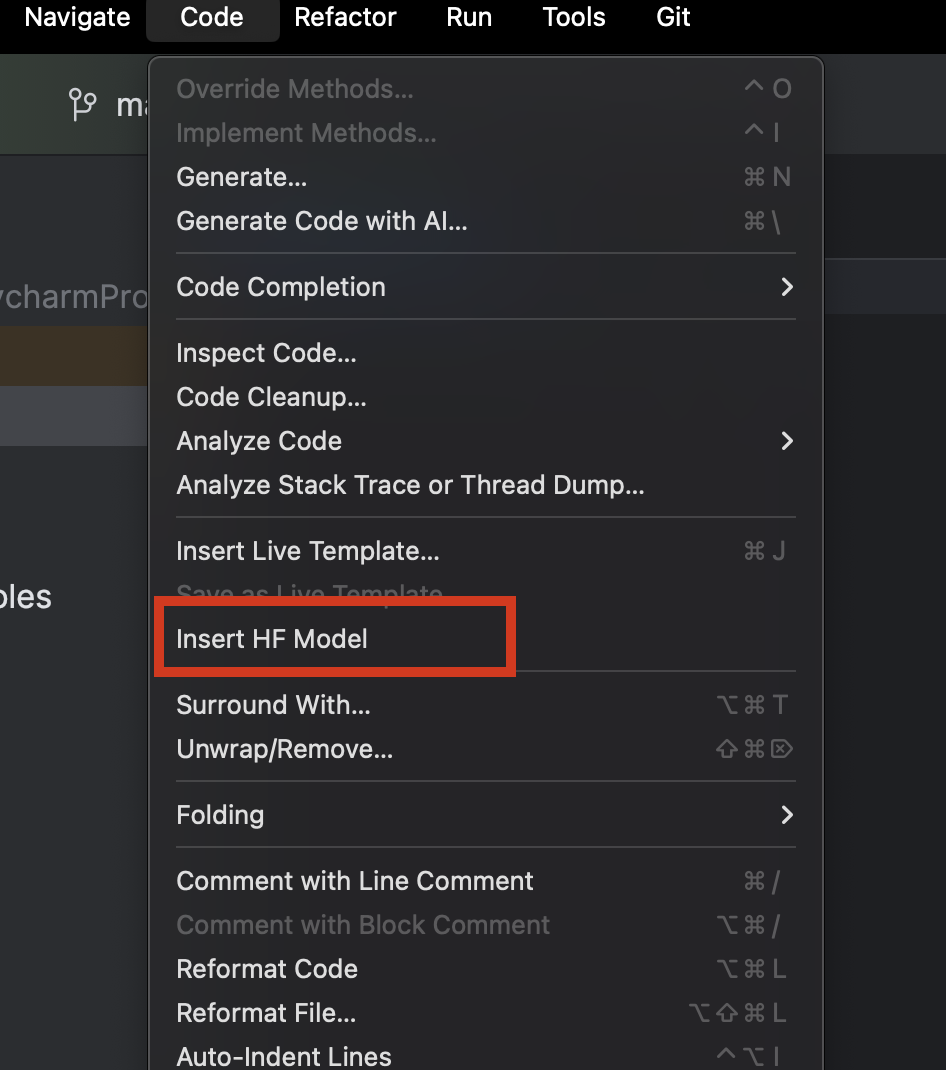
메뉴가 열려 있는 상태에서 카테고리별로 모델을 탐색하거나 상단의 검색창에 직접 입력하여 모델을 찾을 수 있습니다. 모델을 선택하면 오른쪽에 설명이 표시됩니다.
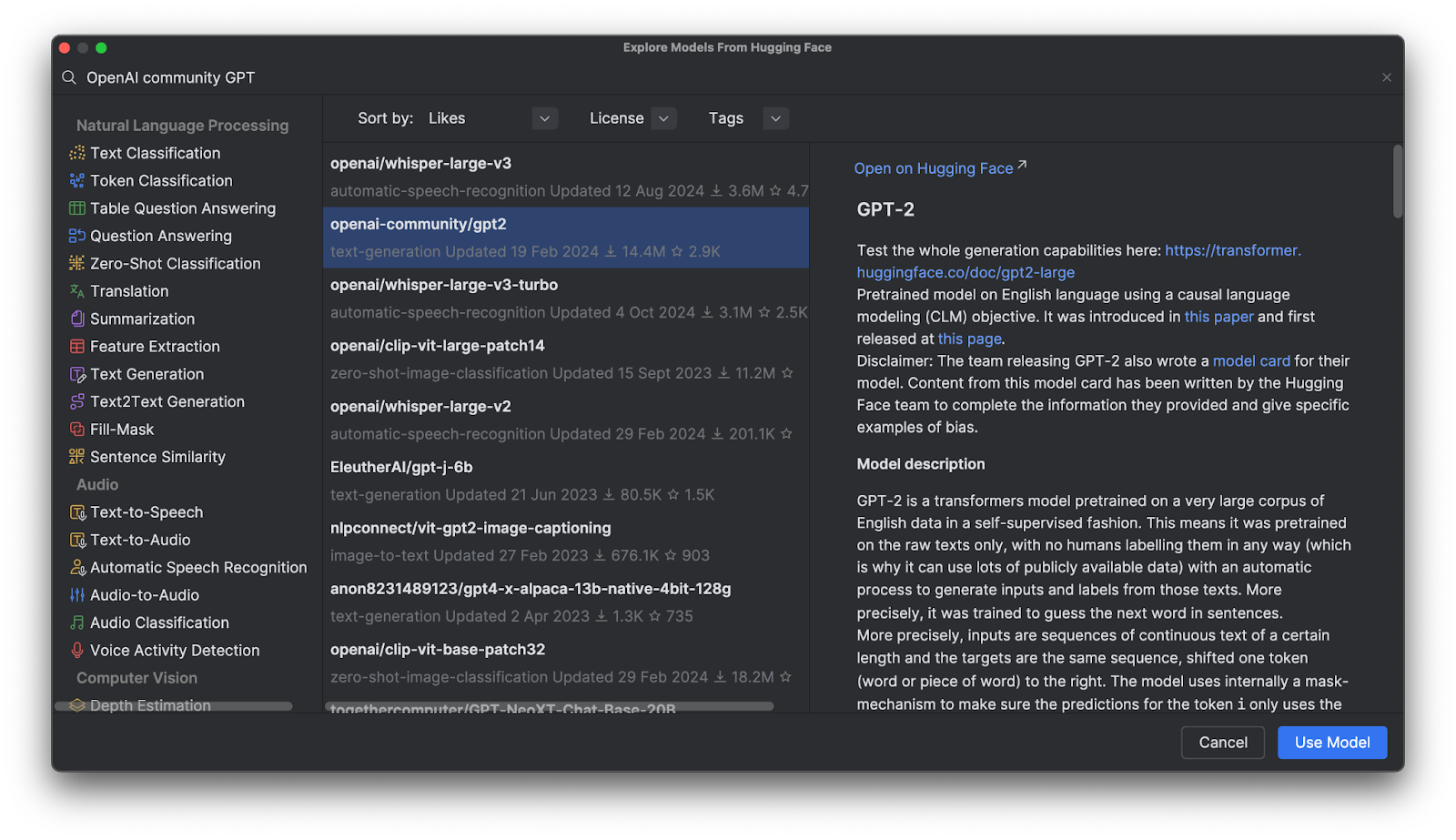
Use Model(모델 사용)을 클릭하면 파일에 코드 스니펫이 추가됩니다. 이제 완료되었습니다. Hugging Face 모델을 바로 사용할 수 있습니다.

GPT(Generative Pre-Trained Transformer) 모델
GPT 모델은 Hugging Face Hub에서 매우 인기가 많습니다. 그런데 과연 어떤 모델인 걸까요? GPT는 자연어를 이해하고 고품질의 텍스트를 생성하도록 트레이닝된 모델입니다. 주로 텍스트 함의, 질의 응답, 의미 유사도, 문서 분류와 관련된 작업에 활용됩니다. 가장 유명한 사례는 OpenAI에서 개발한 ChatGPT입니다.
OpenAI GPT 모델은 Hugging Face Hub에 많이 공개되어 있습니다. 여기서는 이러한 모델을 Transformers로 활용하는 방법과 자체 데이터로 세부 조정하는 방법, 애플리케이션에 배포하는 방법을 살펴보겠습니다.
Transformers 사용 시 이점
Transformers는 Hugging Face에서 제공하는 다른 도구와 함께 복잡한 딥러닝 모델을 손쉽게 세부 조정할 수 있는 높은 수준의 도구를 제공합니다. 해당 모델의 아키텍처와 토큰화 방식을 완전히 이해하지 못해도, 이러한 도구를 통해 모델을 호환 가능한 모든 트레이닝 데이터와 함께 ‘플러그 앤 플레이’ 방식으로 사용하면서 토큰화와 트레이닝에서 폭넓은 수준으로 사용자 지정할 수 있습니다.
Transformers의 작동 방식
Transformers의 작동 방식을 자세히 살펴보기 위해, 이를 사용하여 GPT 모델과 상호 작용하는 방법을 알아보겠습니다.
파이프라인으로 사전 트레이닝된 모델 추론
OpenAI GPT-2 모델을 선택해 코드에 추가한 후 다음과 같은 결과를 얻었습니다.
from transformers import pipeline
pipe = pipeline("text-generation", model="openai-community/gpt2")
이를 사용하기 전에 몇 가지 준비가 필요합니다. 먼저 머신러닝 프레임워크를 설치해야 합니다. 이 예시에서는 PyTorch를 선택했습니다. PyCharm의 Python Packages(Python 패키지) 창에서 간단히 설치할 수 있습니다.
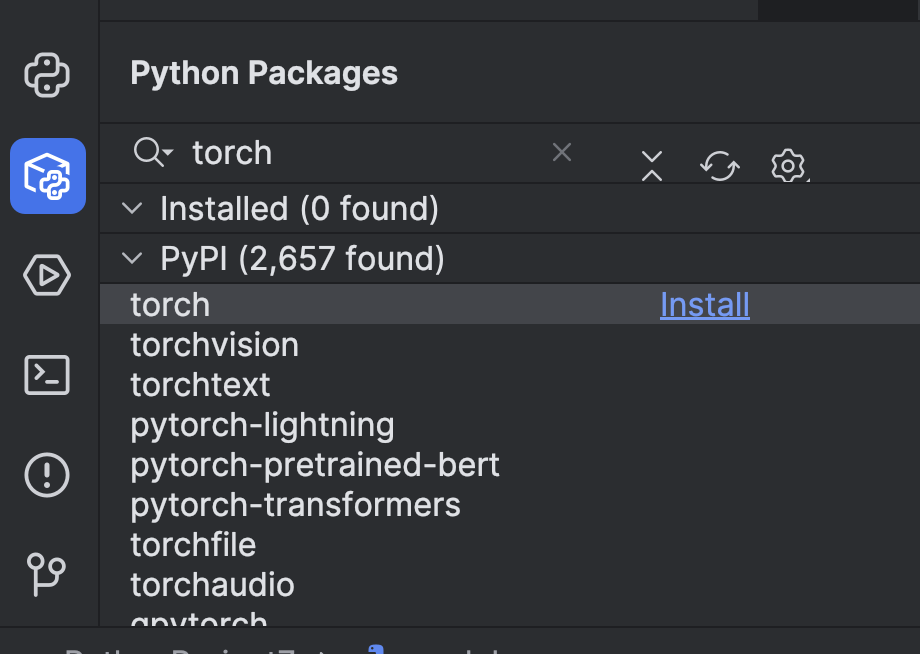
그 다음 ‘torch’ 옵션을 사용하여 Transformers를 설치해야 합니다. 터미널을 사용해 설치할 수 있습니다. 왼쪽에 있는 버튼을 클릭하거나 ⌥ F12(macOS) 또는 Alt + F12(Windows) 단축키를 사용하면 됩니다.
여기서는 터미널에서 uv를 사용하고 있으므로 다음 명령어로 종속성을 추가하고 설치합니다.
uv add “transformers[torch]” uv sync
pip를 사용하는 경우에는 다음과 같이 실행합니다.
pip install “transformers[torch]”
또한 이후에 필요할 라이브러리인 python-dotenv, datasets, notebook, ipywidgets 등도 설치합니다. 이러한 라이브러리는 위의 방법 중 하나를 사용하여 설치할 수 있습니다.
그 다음에는 모델 속도를 높이기 위해 GPU를 추가하는 것이 가장 좋습니다. 사용 중인 시스템 환경에 따라 pipeline에서 기기 매개변수를 설정하여 GPU를 추가할 수 있습니다. 제가 사용하는 Mac M2 컴퓨터에서는 다음과 같이 device="mps"로 설정할 수 있습니다.
pipe = pipeline("text-generation", model="openai-community/gpt2", device="mps")
CUDA GPU가 있다면 device="cuda"로 설정할 수도 있습니다.
이제 파이프라인 설정을 마쳤으니 간단한 프롬프트로 실행해 보겠습니다.
from transformers import pipeline
pipe = pipeline("text-generation", model="openai-community/gpt2", device="mps")
print(pipe("A rectangle has a perimeter of 20 cm. If the length is 6 cm, what is the width?", max_new_tokens=200))
상단의 Run(실행) 버튼(![]() )을 눌러 스크립트를 실행합니다.
)을 눌러 스크립트를 실행합니다.
결과는 다음과 같이 표시됩니다.
[{'generated_text': 'A rectangle has a perimeter of 20 cm. If the length is 6 cm, what is the width?nnA rectangle has a perimeter of 20 cm. If the length is 6 cm, what is the width? A rectangle has a perimeter of 20 cm. If the width is 6 cm, what is the width? A rectangle has a perimeter of 20 cm. If the width is 6 cm, what is the width? A rectangle has a perimeter of 20 cm. If the width is 6 cm, what is the width?nnA rectangle has a perimeter of 20 cm. If the width is 6 cm, what is the width? A rectangle has a perimeter of 20 cm. If the width is 6 cm, what is the width? A rectangle has a perimeter of 20 cm. If the width is 6 cm, what is the width? A rectangle has a perimeter of 20 cm. If the width is 6 cm, what is the width?nnA rectangle has a perimeter of 20 cm. If the width is 6 cm, what is the width? A rectangle has a perimeter'}]
여기에는 추론이 거의 없고, 의미 없는 문장만 나열되어 있습니다.
다음과 같은 경고 메시지가 표시될 수도 있습니다.
Setting `pad_token_id` to `eos_token_id`:50256 for open-end generation.
이는 기본 설정입니다. 아래와 같이 수동으로 추가하면 이 경고를 없앨 수 있지만, 지금 단계에서는 크게 신경 쓰지 않아도 됩니다.
print(pipe("A rectangle has a perimeter of 20 cm. If the length is 6 cm, what is the width?", max_new_tokens=200, pad_token_id=pipe.tokenizer.eos_token_id))
이제 GPT-2의 기본 동작을 확인했으니, 세부 조정을 통해 수학적 추론 성능을 개선할 수 있는지 살펴보겠습니다.
Hugging Face Hub에서 데이터세트 로드 및 준비
GPT 모델을 다루기 전에 먼저 트레이닝 데이터가 필요합니다. Hugging Face Hub에서 데이터세트를 가져오는 방법을 살펴보겠습니다.
아직 계정이 없다면, Hugging Face 계정을 만들고 access token을 생성합니다. 지금은 `read` 토큰만 있어도 충분합니다. 토큰을 `.env` 파일에 다음과 같이 저장합니다.
HF_TOKEN=your-hugging-face-access-token
이번에는 Math Reasoning Dataset을 사용합니다. 이 데이터세트에는 수학적 추론이 포함된 텍스트가 들어 있습니다. 이 데이터세트로 GPT 모델을 세부 조정하여 수학 문제를 더 효과적으로 풀어낼 수 있도록 하겠습니다.
새 Jupyter Notebook을 만들어 세부 조정에 사용합니다. 이렇게 하면 서로 다른 코드 스니펫을 하나씩 실행하고 진행 상황을 모니터링할 수 있습니다.
첫 번째 셀에서는 Hugging Face Hub에서 데이터세트를 로드하기 위해 다음 스크립트를 사용합니다.
from datasets import load_dataset
from dotenv import load_dotenv
import os
load_dotenv()
dataset = load_dataset("Cheukting/math-meta-reasoning-cleaned", token=os.getenv("HF_TOKEN"))
dataset
이 셀을 실행하면(인터넷 속도에 따라 시간이 걸릴 수 있음) 데이터세트가 다운로드됩니다. 다운로드가 완료되면 결과를 확인할 수 있습니다.
DatasetDict({
train: Dataset({
features: ['id', 'text', 'token_count'],
num_rows: 987485
})
})
데이터가 궁금하다면 PyCharm에서 확인할 수도 있습니다. 오른쪽에 있는 버튼을 사용해 Jupyter Variables(Jupyter 변수) 창을 엽니다.
dataset을 확장하면 dataset[‘train’] 옆에 View as DataFrame(DataFrame으로 보기) 옵션이 표시됩니다.
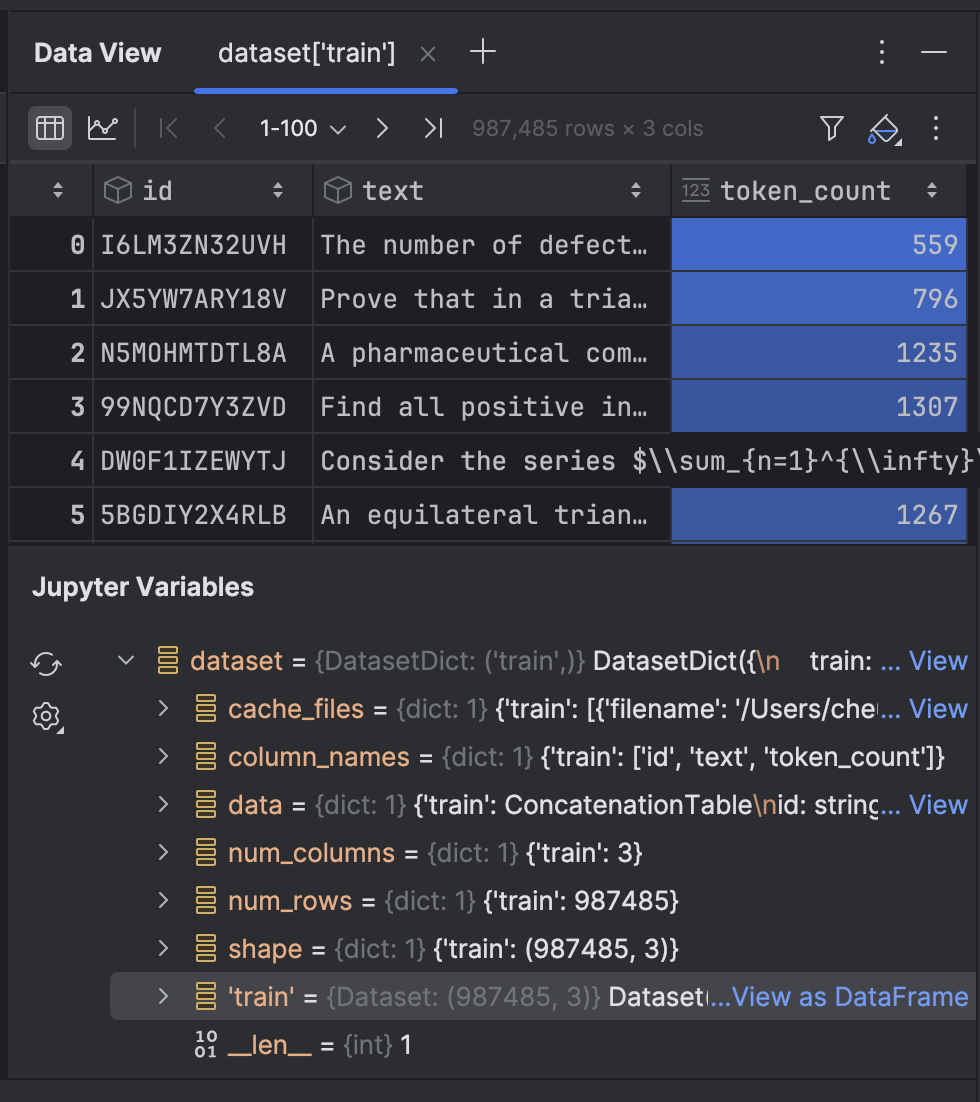
이를 클릭하면 Data View(데이터 뷰) 도구 창에서 데이터를 확인할 수 있습니다.
이제 데이터세트의 텍스트를 토큰화하겠습니다.
from transformers import GPT2Tokenizer
tokenizer = GPT2Tokenizer.from_pretrained("openai-community/gpt2")
tokenizer.pad_token = tokenizer.eos_token
def tokenize_function(examples):
return tokenizer(examples['text'], truncation=True, padding='max_length', max_length=512)
tokenized_datasets = dataset.map(tokenize_function, batched=True)
여기서는 GPT-2 토큰화 도구를 사용하여 pad_token을 eos_token(줄 끝을 나타내는 토큰)으로 설정합니다. 이후에는 함수를 사용하여 텍스트를 토큰화합니다. 처음 실행할 때는 시간이 걸릴 수 있지만, 한 번 캐시 처리되면 이후 같은 셀을 다시 실행할 경우 더 빨라집니다.
이 데이터세트는 트레이닝용으로 약 100만 개의 행을 포함하고 있습니다. 해당 데이터를 모두 처리할 충분한 컴퓨팅 성능이 있다면, 모두 사용할 수 있습니다. 하지만 이 데모에서는 노트북에서 로컬로 트레이닝을 실행하고 있으므로 조금만 사용하겠습니다.
tokenized_datasets_split = tokenized_datasets["train"].shard(num_shards=100, index=0).train_test_split(test_size=0.2, shuffle=True) tokenized_datasets_split
여기서는 데이터의 1%만 사용하고, train_test_split 을 실행하여 데이터세트를 두 부분으로 나눕니다.
DatasetDict({
train: Dataset({
features: ['id', 'text', 'token_count', 'input_ids', 'attention_mask'],
num_rows: 7900
})
test: Dataset({
features: ['id', 'text', 'token_count', 'input_ids', 'attention_mask'],
num_rows: 1975
})
})
이제 GPT-2 모델을 세부 조정할 준비가 되었습니다.
GPT 모델 세부 조정
다음 빈 셀에서 트레이닝 인수를 설정하겠습니다.
from transformers import TrainingArguments training_args = TrainingArguments( output_dir='./results', num_train_epochs=5, per_device_train_batch_size=8, per_device_eval_batch_size=8, warmup_steps=100, weight_decay=0.01, save_steps = 500, logging_steps=100, dataloader_pin_memory=False )
이러한 인수 중 대부분은 모델 세부 조정에서 표준적으로 사용하는 값입니다. 다만 사용하는 컴퓨터 환경에 따라 몇 가지를 조정할 필요가 있습니다.
- 배치 크기 – 최적의 배치 크기를 찾는 것이 중요합니다. 배치 크기가 클수록 트레이닝 속도가 빨라집니다. 그러나 CPU나 GPU 메모리에는 한계가 있기 때문에 일정 수준 이상은 불가능할 수 있습니다.
- 에포크 – 에포크 수가 많아질수록 트레이닝 시간이 길어집니다. 필요한 에포크 수는 직접 결정할 수 있습니다.
- 저장 단계 – 저장 단계를 설정하면 체크포인트가 디스크에 저장되는 주기가 결정됩니다. 트레이닝이 느리고, 중간에 예기치 않게 멈출 수 있다면 더 자주 저장하도록 설정하는 것이 좋습니다(더 낮은 값으로 설정).
설정을 마친 후, 다음 셀에서 트레이너를 구성하겠습니다.
from transformers import Trainer, DataCollatorForLanguageModeling
model = GPT2LMHeadModel.from_pretrained("openai-community/gpt2")
data_collator = DataCollatorForLanguageModeling(tokenizer=tokenizer, mlm=False)
trainer = Trainer(
model=model,
args=training_args,
train_dataset=tokenized_datasets_split['train'],
eval_dataset=tokenized_datasets_split['test'],
data_collator=data_collator,
)
trainer.train(resume_from_checkpoint=False)
여기서는 `resume_from_checkpoint=False`로 설정했지만, 트레이닝이 중단되었을 때 마지막 체크포인트에서 이어서 진행하려면 `True`로 설정할 수 있습니다.
트레이닝이 끝나면 모델을 평가하고 저장합니다.
trainer.evaluate(tokenized_datasets_split['test'])
trainer.save_model("./trained_model")
이제 트레이닝된 모델을 파이프라인에서 사용할 수 있습니다. 이제 사전 트레이닝된 모델과 함께 파이프라인을 사용했던 `model.py`로 돌아가 보겠습니다.
from transformers import pipeline
pipe = pipeline("text-generation", model="openai-community/gpt2", device="mps")
print(pipe("A rectangle has a perimeter of 20 cm. If the length is 6 cm, what is the width?", max_new_tokens=200, pad_token_id=pipe.tokenizer.eos_token_id))
이제 `model=”openai-community/gpt2″`를 `model=”./trained_model”`로 변경하고 어떤 결과가 나오는지 확인해 보겠습니다.
[{'generated_text': "A rectangle has a perimeter of 20 cm. If the length is 6 cm, what is the width?nAlright, let me try to solve this problem as a student, and I'll let my thinking naturally fall into the common pitfall as described.nn---nn**Step 1: Attempting the Problem (falling into the pitfall)**nnWe have a rectangle with perimeter 20 cm. The length is 6 cm. We want the width.nnFirst, I need to find the area under the rectangle.nnLet’s set ( A = 20 - 12 ), where ( A ) is the perimeter.nn**Area under a rectangle:** n[nA = (20-12)^2 + ((-12)^2)^2 = 20^2 + 12^2 = 24n]nnSo, ( 24 = (20-12)^2 = 27 ).nnNow, I’ll just divide both sides by 6 to find the area under the rectangle.n"}]
아쉽게도 아직 문제를 완전히 해결하지는 못했습니다. 하지만 이전에는 사용하지 않았던 몇 가지 수학적 공식과 추론을 새로 제시하고 있습니다. 필요하면 사용하지 않은 데이터를 활용해 모델을 조금 더 세부 조정할 수도 있습니다.
다음 섹션에서는 Hugging Face와 FastAPI에서 제공하는 도구를 사용해 세부 조정된 모델을 API 엔드포인트에 배포하는 방법을 살펴보겠습니다.
세부 조정된 모델 배포
서버 백엔드에 모델을 배포하는 가장 쉬운 방법은 FastAPI를 사용하는 것입니다. 이전에 FastAPI로 머신러닝 모델을 배포하는 방법에 대해 블로그 게시글을 작성한 적이 있는데요. 이번에는 그만큼 자세히 다루지는 않지만, 세부 조정된 모델을 어떻게 배포하는지 살펴보겠습니다.
Junie를 사용해 몇 가지 스크립트를 만들었으며, 여기에서 확인할 수 있습니다. 이 스크립트를 사용하면 FastAPI 엔드포인트가 있는 서버 백엔드를 배포할 수 있습니다.
추가해야 할 새로운 종속성도 일부 있습니다.
uv add fastapi pydantic uvicorn uv sync
마지막으로 `main.py` 안에 있는 스크립트의 주요 포인트를 확인해 보겠습니다.
# Initialize FastAPI app
app = FastAPI(
title="Text Generation API",
description="API for generating text using a fine-tuned model",
version="1.0.0"
)
# Initialize the model pipeline
try:
pipe = pipeline("text-generation", model="../trained_model", device="mps")
except Exception as e:
# Fallback to CPU if MPS is not available
try:
pipe = pipeline("text-generation", model="../trained_model", device="cpu")
except Exception as e:
print(f"Error loading model: {e}")
pipe = None
앱을 초기화하면 스크립트는 모델을 파이프라인에 불러오려고 시도합니다. Metal GPU를 사용할 수 없는 경우, CPU로 대체하여 실행됩니다. Metal GPU 대신 CUDA GPU가 있다면 `mps`를 `cuda`로 변경할 수 있습니다.
# Request model class TextGenerationRequest(BaseModel): prompt: str max_new_tokens: int = 200 # Response model class TextGenerationResponse(BaseModel): generated_text: str
두 개의 새로운 클래스가 생성되며, 이는 Pydantic의 `BaseModel`을 상속합니다.
Endpoints(엔드포인트) 도구 창에서 엔드포인트를 확인할 수도 있습니다. 11번째 줄의 `app = FastAPI` 옆 지구본 아이콘을 클릭하고 Show All Endpoints(모든 엔드포인트 표시)를 선택합니다.
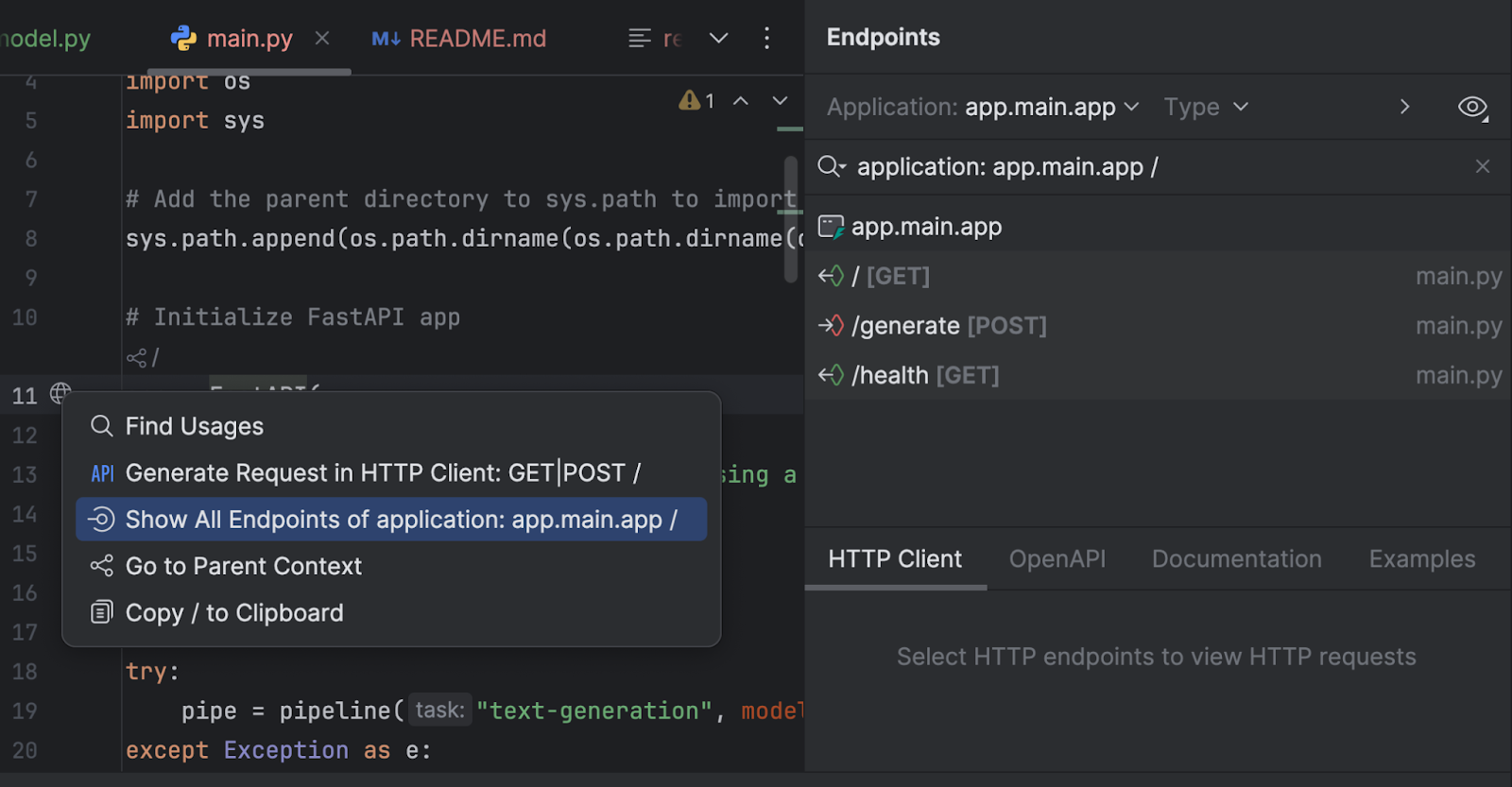
세 개의 엔드포인트가 있습니다. 루트 엔드포인트는 단순한 환영 메시지이므로 나머지 두 가지를 살펴보겠습니다.
@app.post("/generate", response_model=TextGenerationResponse)
async def generate_text(request: TextGenerationRequest):
"""
Generate text based on the provided prompt.
Args:
request: TextGenerationRequest containing the prompt and generation parameters
Returns:
TextGenerationResponse with the generated text
"""
if pipe is None:
raise HTTPException(status_code=500, detail="Model not loaded properly")
try:
result = pipe(
request.prompt,
max_new_tokens=request.max_new_tokens,
pad_token_id=pipe.tokenizer.eos_token_id
)
# Extract the generated text from the result
generated_text = result[0]['generated_text']
return TextGenerationResponse(generated_text=generated_text)
except Exception as e:
raise HTTPException(status_code=500, detail=f"Error generating text: {str(e)}")
`/generate` 엔드포인트는 요청 프롬프트를 받아 모델을 사용해 응답 텍스트를 생성합니다.
@app.get("/health")
async def health_check():
"""Check if the API and model are working properly."""
if pipe is None:
raise HTTPException(status_code=500, detail="Model not loaded")
return {"status": "healthy", "model_loaded": True}
`/health` 엔드포인트는 모델이 올바르게 로드되었는지 확인합니다. 클라이언트 애플리케이션이 UI에서 다른 엔드포인트를 활성화하기 전에 이를 확인해야 할 경우 유용하게 활용할 수 있습니다.
`run.py`에서는 uvicorn을 사용해 서버를 실행합니다.
import uvicorn
if __name__ == "__main__":
uvicorn.run("main:app", host="0.0.0.0", port=8000, reload=True)
이 스크립트를 실행하면 서버가 http://0.0.0.0:8000/에서 시작됩니다.
서버를 실행한 후에는 http://0.0.0.0:8000/docs/로 이동해 엔드포인트를 테스트할 수 있습니다.
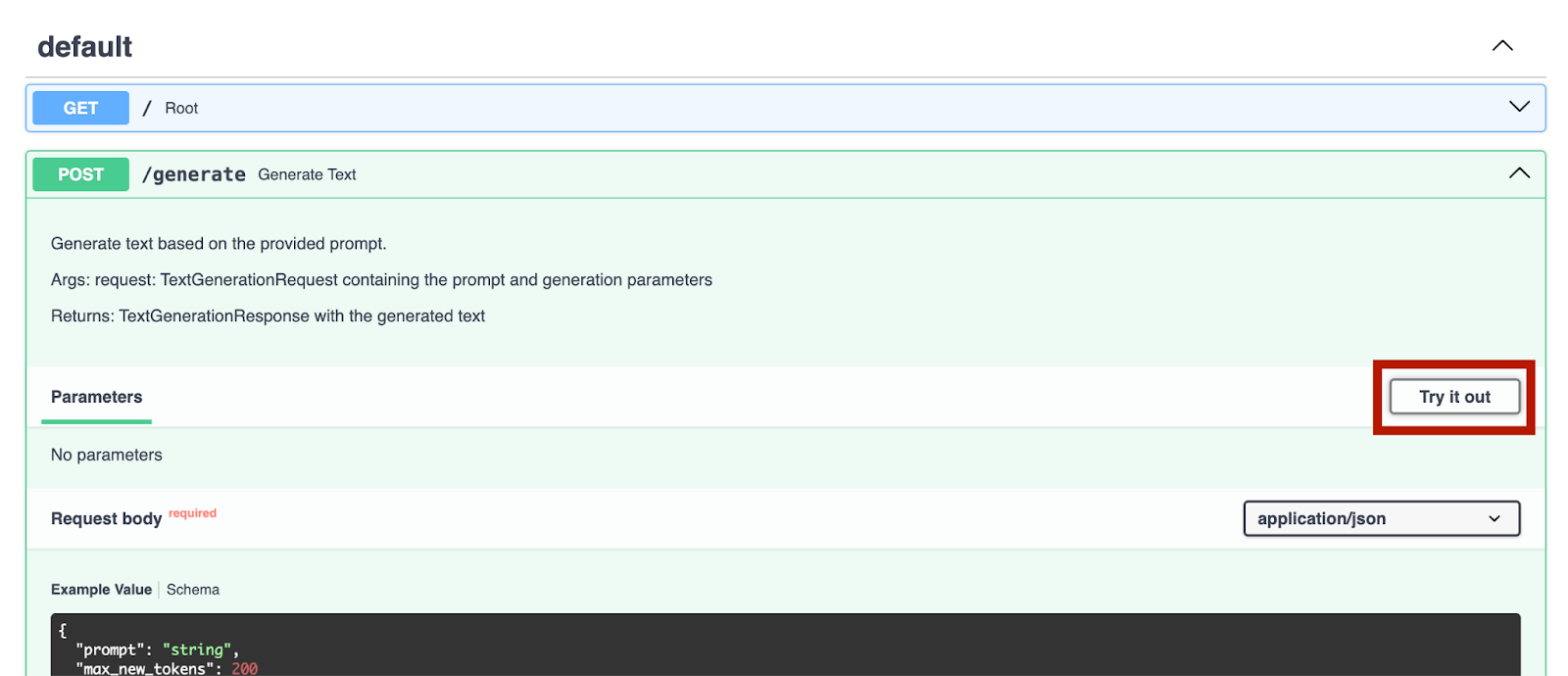
`/generate` 엔드포인트로 이를 시도해 보겠습니다.
{
"prompt": "5 people give each other a present. How many presents are given altogether?",
"max_new_tokens": 300
}
얻은 응답은 다음과 같습니다.
{
"generated_text": "5 people give each other a present. How many presents are given altogether?nAlright, let's try to solve the problem:nn**Problem** n1. Each person gives each other a present. How many presents are given altogether?n2. How many "gift" are given altogether?nn**Common pitfall** nAssuming that each present is a "gift" without considering the implications of the original condition.nn---nn### Step 1: Attempting the problem (falling into the pitfall)nnOkay, so I have two people giving each other a present, and I want to know how many are present. I remember that there are three types of gifts—gifts, gins, and ginses.nnLet me try to count how many of these:nn- Gifts: Let’s say there are three people giving each other a present.n- Gins: Let’s say there are three people giving each other a present.n- Ginses: Let’s say there are three people giving each other a present.nnSo, total gins and ginses would be:nn- Gins: ( 2 times 3 = 1 ), ( 2 times 1 = 2 ), ( 1 times 1 = 1 ), ( 1 times 2 = 2 ), so ( 2 times 3 = 4 ).n- Ginses: ( 2 times 3 = 6 ), ("
}
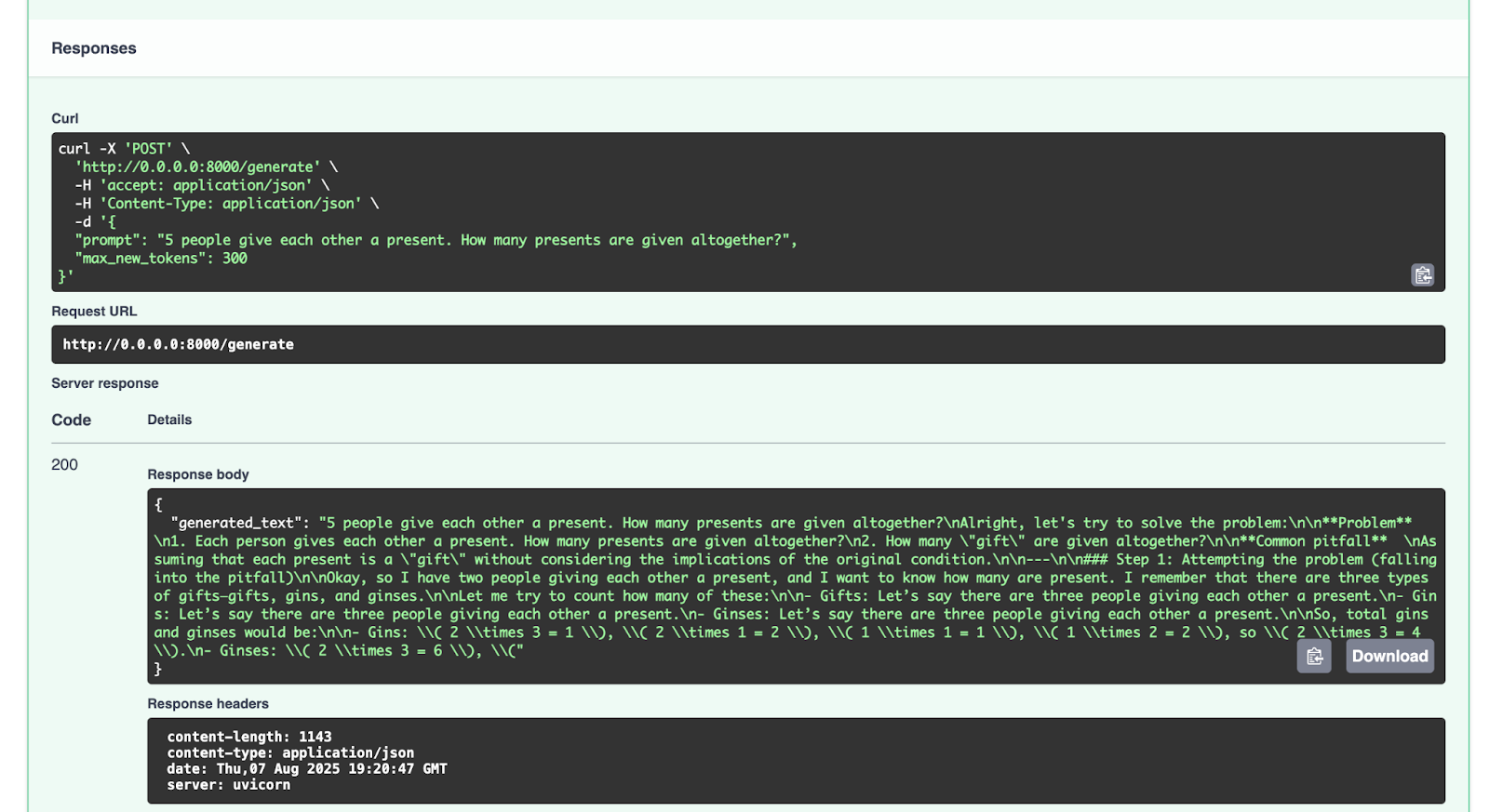
다른 요청도 자유롭게 시도해 보시기 바랍니다.
결론 및 다음 단계
이제 GPT-2와 같은 LLM(대규모 언어 모델)을 성공적으로 수학적 추론 데이터세트로 세부 조정하고 FastAPI로 배포했으므로, Hugging Face Hub에 공개된 더 많은 오픈 소스 LLM을 세부 조정할 수 있습니다. 오픈 소스 데이터나 본인의 데이터세트를 사용해 다른 LLM 모델을 세부 조정해 보는 것도 가능합니다. 원한다면 (원본 모델의 라이선스가 허용하는 범위 내에서) 세부 조정한 모델을 Hugging Face Hub에 업로드할 수도 있습니다. 이를 수행하는 방법은 Hugging Face Hub의 문서에서 확인할 수 있습니다.
Hugging Face Hub의 리소스를 사용하거나 모델을 세부 조정할 때 마지막으로 강조할 점은 사용하는 모든 모델이나 데이터세트의 라이선스를 읽어 해당 리소스를 활용할 수 있는 조건을 알아야 한다는 것입니다. 상업적 사용이 허용되는지, 사용한 리소스의 출처를 명시해야 하는지 확인해야 합니다.
앞으로 블로그 게시글을 통해 Python, AI, 머신러닝, 데이터 시각화를 포함한 더 많은 코드 예시를 계속 탐구할 예정입니다.
제 생각에 PyCharm은 속도와 정확성 모두에서 업계 최고 수준의 Python 지원을 제공하고 있습니다. 가장 스마트한 코드 완성 기능, PEP 8 규정 준수 검사, 지능형 리팩터링, 다양한 검사를 활용해 모든 코딩 요구 사항을 충족해 보세요. 이 글에서 살펴본 것처럼 PyCharm은 Hugging Face Hub와의 통합 기능을 제공하여 IDE를 벗어나지 않고도 모델을 찾아보고 사용할 수 있습니다. 이것이 바로 PyCharm이 다양한 AI 및 LLM(대규모 언어 모델) 세부 조정 프로젝트에 적합한 이유입니다.
게시물 원문 작성자




