

.NET Tools
Essential productivity kit for .NET and game developers
dotMemory를 활용한 dotMemory 최적화

dotMemory는 JetBrains의 .NET 메모리 프로파일러입니다.
이 글에서 JetBrains에서 dotMemory 및 dotTrace라는 자체 도구를 직접 사용하여 개선점을 찾고, dotMemory의 알고리즘 중 하나를 최적화한 방법을 소개하려 합니다. 또한, 저희 팀은 dotTrace를 사용하여 알고리즘을 한층 더 개선하고 BenchmarkDotNet을 통해 최적화 프로세스를 완료했습니다.
제가 이 글을 공유하는 데 영감을 준 2가지 글(1, 2)의 저자에게 감사를 전하고 싶습니다.
이 개선 작업은 Slack에서 dotMemory의 도미네이터 트리 문제와 관련한 동료의 메시지를 받았을 때 시작되었습니다. 해당 트리의 데이터는 계산에 매우 긴 시간이 소요되었죠. 계산 시간이 너무 긴 나머지 그는 프로세스가 끝날 때까지 기다릴 수 없었습니다. 다행히 해당 문제는 내부 문제였으므로, 메모리 스냅샷을 수집하여 조사에 착수했습니다.
로컬 시스템에서 문제를 재현하자마자 메모리 사용량이 초당 1.17GB의 속도로 빠르게 증가하기 시작하여, 프로세스에서 스왑 파일이 사용되는 것을 확인했습니다. 일반적으로 이런 문제가 발생하면 적절한 시간 내에 결과를 받지 못할 가능성이 높습니다. 그러므로 dotMemory를 사용하여 dotMemory의 문제를 해결해야 했습니다.
프로세스가 물리적 메모리를 완전히 소모하면 스냅샷을 캡처하는 것은 쉽지 않으며, 운영 체제까지 불안정해질 수 있습니다. 따라서 메모리 사용량이 빠르게 증가하기 시작하나, 물리적 메모리가 약간 남았을 때 스냅샷을 캡처하기로 결정했습니다. dotMemory 콘솔 프로파일러는 이 작업에 가장 적합한 도구였습니다.

이 명령어는 프로파일링 모드에서 dotMemory.UI.64.exe를 시작합니다. “프라이빗 바이트”가 20GB에 도달하는 즉시 스냅샷이 캡처되며, 프로파일링 완료 후 dotMemory에서 스냅샷이 열립니다. 저희 팀은 스왑이 다시 발생하지 않도록 수동으로 프로파일링을 중지해야 했습니다. 그렇기에 데이터를 충분히 확보할 때까지 기다린 후 Ctrl+C를 눌렀습니다.
다음으로 캡처된 스냅샷을 dotMemory에서 열고, 저는 동료는 하지 못했지만, 제 스냅샷에서 확인할 수 있었던 도미네이터 트리를 분석하는 것으로 시작했습니다.

보시다시피 6천만 개에 달하는 CompactDominatorTreeNode+Builder 객체가 메모리를 채우고 있으며, 각 객체에는 딕셔너리가 포함되어 있습니다. 대부분의 딕셔너리에 크기 < 용량이라는 문제가 있어, 많은 메모리가 낭비되고 있다는 사실을 곧 파악했습니다.
그렇게 많은 딕셔너리가 필요하지 않을 수 있으니, 모든 딕셔너리의 용도를 확인해야 했습니다. CompactDominatorTreeNode+Builder 노드를 선택하고 선언으로 이동했습니다(컨텍스트 메뉴를 사용하거나 Ctrl+L을 눌러 이동 가능). 다음으로 해당 클래스가 열린 제 IDE(Rider)로 이동했습니다. Find Usages(사용 위치 찾기)를 실행하자 도미네이터 트리 압축 알고리즘이 포함된 CompactDominatorTree.Build 메서드가 표시되었습니다.
배경지식을 약간 설명드리자면, dotMemory에서 도미네이터 트리를 빌드하는 방식은 다음과 같습니다. 먼저, 각 객체에 대해 해당 객체만을 보유하는 객체를 검색하여 보유 객체를 저장하거나, 그러한 보유 객체가 없는 경우 이를 표시하는 마커를 저장합니다. 이 트리는 매우 커질 가능성이 있으므로, 사용자에게 ‘있는 그대로’ 표시하는 것은 의미가 없습니다. 따라서 dotMemory는 트리의 각 수준에서 객체 타입별로 트리 노드의 그룹을 생성합니다. CompactDominatorTreeNode+Builder는 빌드 중인 압축 트리의 노드를 표시하며, 딕셔너리는 타입별로 노드의 그룹을 생성하는 데 사용됩니다.
이 알고리즘은 “하위→ 상위” 형식으로 트리를 수신합니다. 즉, 각 객체는 상위 요소에 대응됩니다. 알고리즘은 스냅샷의 모든 객체를 순차적으로 탐색하며, 도미네이터 상위 트리가 아직 처리되지 않은 각 객체에 대해 압축 트리에 새 그룹 노드가 생성됩니다. 현재 노드는 그룹 노드(기존 노드 또는 새로 생성된 노드)의 하위 노드가 됩니다.
이 방법을 사용하면 트리는 임의의 순서에 따라 순회합니다. 각 노드는 타입별로 노드의 그룹을 생성하는 딕셔너리를 저장해야 합니다. 압축 트리는 모든 객체를 포함하는 트리보다 훨씬 작고, 심한 메모리 과용이 발생하지 않으므로 대부분의 경우엔 문제가 되지 않습니다. 그러나 이 스냅샷은 압축 트리마저 매우 큰 예외적 경우였습니다.
따라서 ‘사용하는 딕셔너리 개수를 줄일 방법’을 고민하게 되었습니다. 복합키가 있는 딕셔너리가 단 하나뿐이라면 어떨까요? 안타깝게도 이 방법을 사용하더라도 분해를 수행해야 하므로 메모리 과용 또는 더 높은 계산 복잡성이 초래될 가능성이 있었습니다. 다른 해결책을 모색해야 했습니다.
한발 물러서 더 넓은 시야로 문제를 바라보았습니다. 너비 우선 탐색과 같은 다른 방법을 사용하여 트리를 순회하는 방법이 도움이 될 것 같았습니다. 일반키가 사용된 딕셔너리 하나면 충분할 테고, 압축 트리의 새로운 수준을 빌드할 때마다 딕셔너리를 지우면 다음 반복 시 다시 사용할 수 있습니다.
이 방법에도 주의해야 할 점이 있었습니다. “하위 → 상위” 형식은 주어진 노드의 하위 노드를 불러오기 위한 계산 복잡도가 높으므로, 너비 우선 탐색을 사용하기에 적합하지 않았습니다. 입력 트리를 위한 다른 형식이 필요했습니다. 다행히 이미 적절한 형식을 알고 있었습니다. dotMemory를 활용하면 도미네이터 트리를 “상위 → 하위” 인접 리스트로 저장할 수 있습니다. 즉, 계산 복잡도를 높이지 않고도 너비 우선 탐색을 사용하도록 알고리즘을 변경할 수 있게 된 것입니다.
저희 팀은 그에 따라 알고리즘을 수정하고 실행했습니다. 메모리 사용량의 증가 속도가 전보다 훨씬 느려진 것이 확인되었습니다. 이전에는 초당 1.17GB로 메모리 사용량이 증가했다면, 수정 후 증가 속도는 초당 7MB에 불과했습니다. 하지만 아직도 프로세스가 완료되지 않고, 스왑 파일을 다시 사용하기 시작했습니다.
다시 이미지를 살펴보겠습니다. 다른 스냅샷을 캡처하여 열었고, 새로운 도미네이터 트리는 다음과 같았습니다.

이번에는 압축 트리에서 사용된 크기만 16GB였습니다. 적당한 수준이었을까요? 더 효율적인 방식으로 트리를 저장할 방법이 있지 않을까요?
저희 팀은 타입별로 노드 그룹을 생성하여, 보유한 노드 개수를 확인했습니다.
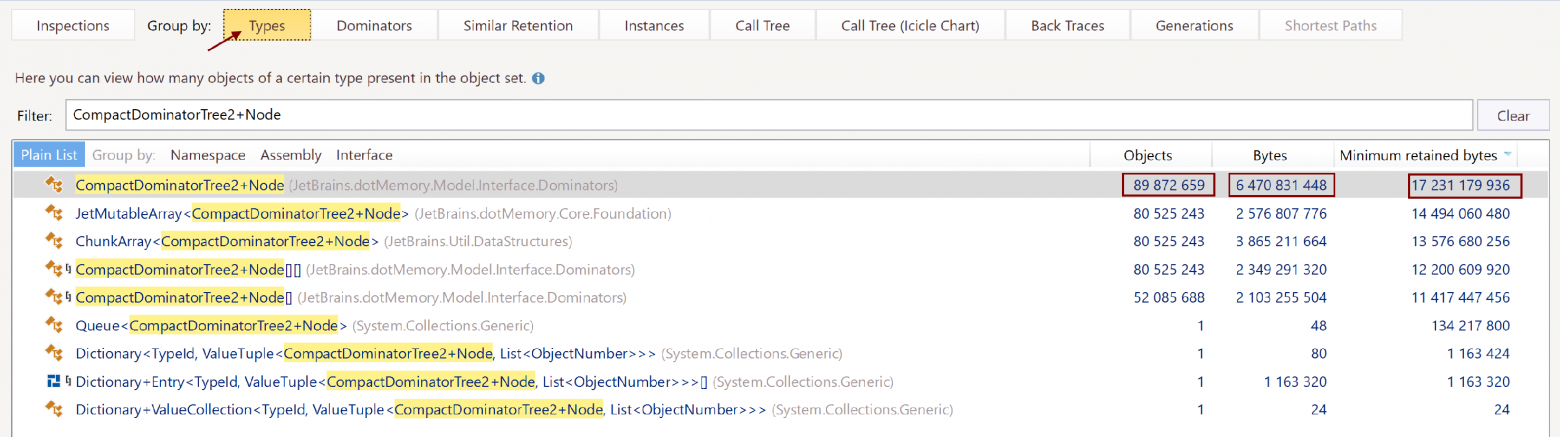
트리에 포함된 노드 9천만 개의 크기는 총 16GB 크기 중 6GB만 차지했습니다. 왠지 수상하게 느껴졌기에 CompactDominatorTree2+Node 선언 코드로 이동했습니다.
public sealed class Node
{
public DfsNumber DfsNumber { get; } // 8 bytes
public TypeId ObjectsType { get; } // 4 bytes
public int ObjectsCount { get; } // 4 bytes
public int RetainedObjectsCount { get; } // 4 bytes
public ulong RetainedBytes { get; } // 8 bytes
public bool IsContainedInSet { get; } // 1 byte
public Node Parent { get; } // 8 bytes
internal JetArray<Node> ChildrenImpl { get; } // 8 bytes
// we have omitted unnecessary details
}
여기서 페이로드는 45바이트에 불과했지만 헤더 및 정렬을 포함하여 Node 객체는 72바이트를 차지했습니다. 또한 보유 크기도 평균적으로 192바이트로 훨씬 더 컸습니다. 자세한 정보를 확인하기 위해 인스턴스 탭으로 전환하고 “CompactDominatorTree2+Node !g !a” 쿼리를 사용하여 콘텐츠를 필터링했습니다(“!g”로 제네릭 제외, “!a”로 배열 제외). 임의의 인스턴스는 다음과 같았습니다.

인스턴스 세부 정보를 확인해 보시죠.

오버헤드가 정말 많지 않나요?
JetMutableArray가 큰 트리의 하위 노드를 저장하는 가장 효율적인 방법이 아니라는 것을 확실히 알게 되었습니다. 물론 가장 먼저 하위 노드 저장 방식을 최적화하는 솔루션을 떠올렸습니다. 예를 들어, 하위 노드를 표준 배열에 저장하는 방법이 있죠. 하지만 저희 팀은 더 근본적인 방식을 시도하기로 결정했습니다.
dotMemory에서 대규모 데이터 구조를 흔히 볼 수 있습니다. 예를 들어, 정수 배열 색인을 통해 서로 참조하는 두 개의 구조체 배열을 사용하여 객체 그래프가 인접 리스트로 저장됩니다. dotMemory에서 관리 배열 사용을 중단하고 메모리 매핑 파일을 기반으로 한 자체적 구현을 선택했다는 점에서 이는 매우 흥미롭습니다. 이 방식을 활용하면 요소 액세스 시 최소 오버헤드(기존에 C에서 수행된 방식으로 네이티브 메모리 인덱싱)를 달성하고 완전한 OS 수준에서 배열을 빠르게 로드하고 저장할 수 있으며, 직렬화/역직렬화 중에 오버헤드도 없습니다. 그뿐 아니라 이러한 배열 조각은 개입 없이 메모리에서 언로드될 수 있으므로, 물리적 메모리를 확보하고 배열을 (어느 정도) 순차적으로 순회하는 데 도움이 됩니다.
저희 팀은 압축 도미네이터 트리에도 동일한 접근 방식을 적용하기로 결정했습니다. 또한 IsContainedInSet 속성을 비트 플래그로 바꾸고 사용되지 않는 Parent 프로퍼티를 제거했습니다. 결국 트리 노드는 다음과 같은 구조로 완성되었습니다.
[StructLayout(LayoutKind.Sequential, Pack = 4)]
public readonly struct Node
{
public readonly TypeId ObjectsType;
private readonly uint _objectsCount;
public int ObjectsCount => (int)(_objectsCount & 0x7FFFFFFF);
public bool IsContainedInSet => (_objectsCount & 0x80000000) != 0;
public readonly int RetainedObjectsCount;
public readonly ulong RetainedBytes;
public readonly DfsNumber DfsEnter;
public readonly Range<uint> Children;
}

이처럼 순차적 표현을 사용하면 하위 노드를 가리키는 하나의 정수 링크로도 충분하다는 점은 주목할 만합니다. 하지만 저희 팀은 그 대신 빌드된 트리의 하위 노드를 RetainedBytes를 기준으로 오름차순으로 정렬할 수 있는 범위를 사용한 다음, 정렬된 노드를 사용하여 선버스트 다이어그램을 작성할 수 있었습니다. 위의 표현에서 노드 #1, #2, #3의 순서가 변경될 수 있습니다.
긴장한 상태로 프로그램을 실행했고, 그 결과는 훌륭했습니다! 최대 메모리 사용량은 12GB였고, 도미네이터 트리를 빌드하는 데 55분이 소요되었습니다. 목표 시간보다는 길지만 적당한 수준입니다. 스냅샷에 총 2억 7,500만 개의 객체가 포함되고, 압축 트리에는 2억 개의 노드가 있습니다.
어떤 기준으로 보아도 훌륭한 결과입니다. 처음에는 32GB 미만으로 크기를 줄일 수 없었고, 시간도 매우 오래 걸렸습니다. 이제 크기는 12GB로 감소했으며, 55분만에 준비가 완료되었습니다. 그러나 여전히 개선의 여지가 있을 것 같았습니다. 55분은 이상적인 수치가 아닙니다. 그 시간을 모두 정확히 살펴보기로 했습니다. dotTrace의 성능을 보시죠.

다행히 프로세스가 완료될 때까지 기다릴 필요는 없었으며, 몇 분 동안의 성능을 녹화하는 것만으로 충분했습니다. ‘--timeout=3m‘ 키를 사용하여 3분 후에 프로파일링을 자동으로 중단했습니다. 스냅샷을 열고 작업을 수행하는 스레드를 식별하기 위해 필터링을 적용했습니다. 오랫동안 완전히 로드된 상태로 남아 있는 스레드입니다. 다음은 호출 트리입니다.

놀랍게도 Dictionary.Clear 단독으로 92%의 시간을 소모했습니다! 정말 놀라운 결과였습니다. 왜 표준 라이브러리 딕셔너리에서 Clear의 성능이 그렇게 안 좋았을까요? 문제는 알고리즘의 첫 반복 동안 딕셔너리의 요소가 무려 22,000개로 증가한 것입니다. 다음 반복에서는 정상적으로 수십 개의 요소만 포함되었습니다. Dictionary.Clear의 계산 복잡도는 Capacity(Count가 아님), 그중에서도 Capacity에 선형적으로 의존하는 buckets.Length에 비례합니다. 즉, 애초에 비어 있는 요소를 계속 지워온 것입니다! 딕셔너리를 지우고 다시 사용하기로 선택했을 때 모델 최적화가 과도하게 이루어졌습니다.
한 발짝 물러서 가장 간단한 방법을 시도했습니다. 즉, 모든 반복에 대해 새 딕셔너리를 생성하는 방법입니다. 기대에 부푼 마음으로 스톱워치를 다시 켜고 코드를 실행했습니다. 놀랍게도 결과는 고작 1분 46초였습니다! GC에 대한 부하가 증가했지만 균등하게 분배되어 적절히 관리되었습니다. 이는 dotTrace를 사용하여 검증된 사실입니다.
이상입니다. 메모리 사용량이 12GB에 불과한 상태에서, 2분 내에 객체 2억 7,500만 개를 처리했습니다. 정말 만족스러웠죠. 드디어 최적화된 코드를 저장소에 커밋할 준비가 되었습니다!
이미 훌륭했지만 조금 더 개선하고자 추후 테스트를 한 번 더 시행했습니다. 성능 비교를 위해 다른 스냅샷에서 이전 알고리즘과 새 알고리즘을 실행했습니다. 크기는 같지만 토폴로지가 다른 스냅샷을 찾았습니다. 따라서 이전 알고리즘도 이를 처리할 수 있고, 두 알고리즘에 모두 제공할 수 있습니다. 놀랍게도 새 알고리즘은 계산 복잡도가 동일하게 유지되었음에도 이전 알고리즘보다 33% 더 느리게 실행되었습니다. 하지만 이 내용은 다음 기회에 말씀드리도록 하겠습니다. 궁금하시다면 아래에 댓글을 남기거나 직접 문의하여 알려주세요!
게시물 원문 작성자





