

Fleet
More Than a Code Editor
Fleet의 내부 구조, 파트 II – 에디터 해부하기

목차
JetBrains의 차세대 IDE인 Fleet 구축에 대해 알아보는 연재 게시물입니다.
- 파트 I – 아키텍처 개요
- 파트 II – 에디터 해부하기
이 시리즈의 첫 파트에서는 Fleet 아키텍처의 개요를 살펴보았습니다. 이 두 번째 파트에서는 에디터 내부에서 사용되는 알고리즘과 데이터 구조를 다룹니다.
데이터 구조의 집합체
다음에 나온 Fleet의 에디터 창 스크린샷을 살펴보세요.

구문 강조 표시가 되어 있는 텍스트 줄과 특정 변수의 사용 위치에 대한 정보를 제공하는 위젯이 있습니다. 이제 이 정보를 표시하는 방법에는 여러 가지가 있지만 에디터에서 문제는 이것이 읽기 전용이 아니라는 것입니다. 데이터는 시각적으로 표시될 뿐만 아니라 업데이트될 수도 있습니다. 함수 이름을 변경하는 것과 같은 간단한 작업도 구문 강조 표시, 사용 위치는 물론 정적 분석이나 즉석 컴파일과 같은 기타 많은 제공 기능에 영향을 미칠 수 있습니다.
훌륭한 사용자 경험을 제공하기 위해서는 텍스트 편집과 그에 따른 시각화 작업을 최대한 매끄럽게 수행할 수 있도록 해야 합니다. 이를 위해서는 효율적인 방식으로 데이터를 저장하고 조작해야 합니다. 그러나 이것이 데이터를 저장하는 유일한 방법은 아닙니다. 사실 위의 이미지는 서로 다른 데이터 구조를 사용하여 다양한 방식으로 데이터를 저장합니다. 이러한 구조가 모여서 에디터라고 하는 도구를 형성하는 것이죠. 즉, 에디터를 데이터 구조의 집합체로 생각하면 이해하기 쉽습니다!
그러면 자세히 알아봅시다!
모든 곳에 있는 로프
많은 양의 텍스트로 작업하는 데 익숙한 분들은 문자열(즉, 문자 배열)을 사용하여 이를 저장하는 것이 그다지 효율적이지 않다는 사실을 이미 알고 계실 겁니다. 일반적으로 배열에서 이루어지는 작업은 더 크거나 작은 새 배열을 만들고 내용을 이전 배열에서 새 배열로 복사해야 함을 의미합니다. 이러한 작업은 효율적이기가 매우 어렵습니다.
이보다 우수하고 표준화된 접근 방식은 로프 구조를 사용하는 것입니다. 이 추상 데이터 형식의 기본 개념은 트리의 리프 노드에 문자열을 저장하는 것입니다.
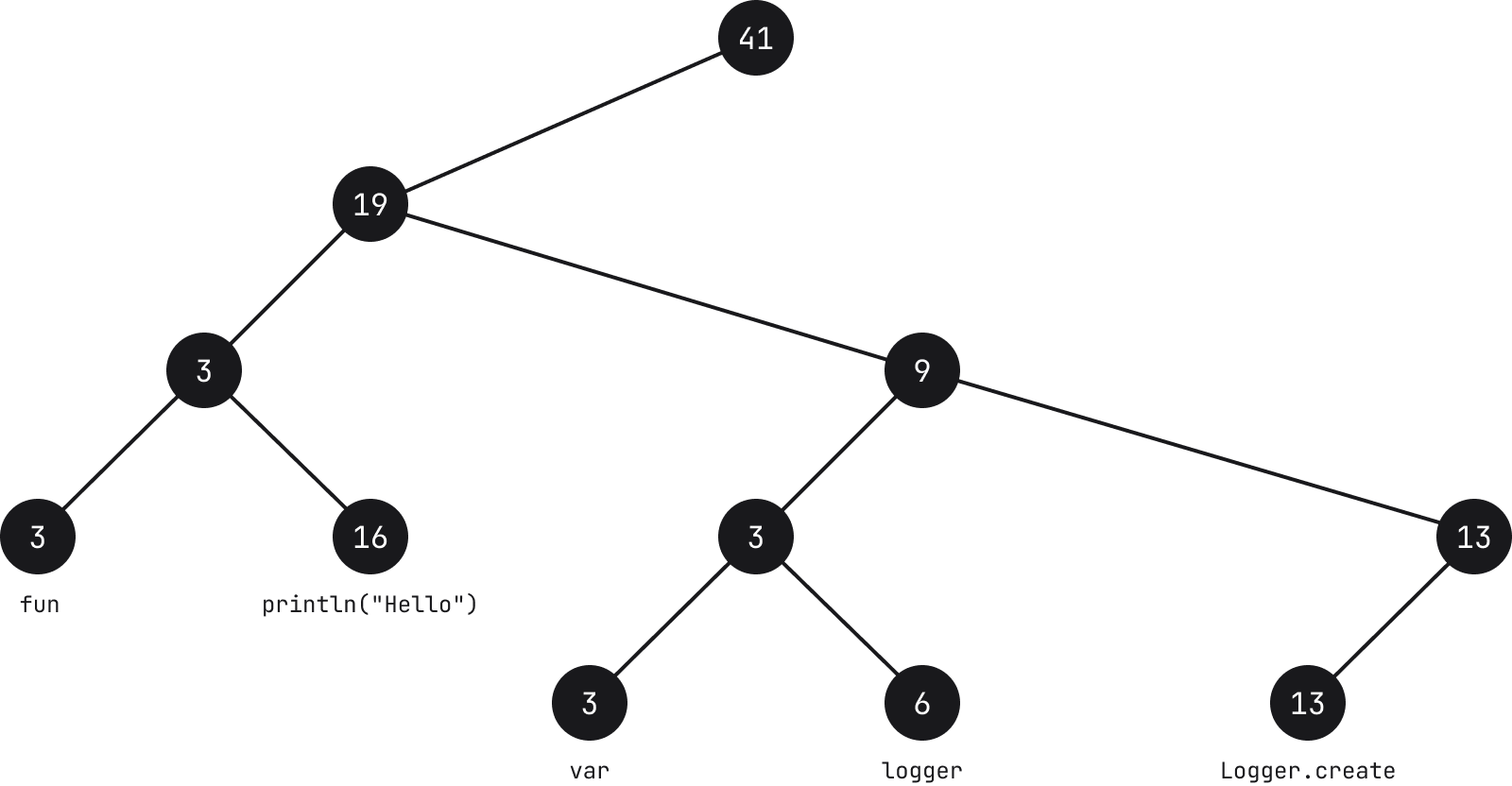
각 리프 노드에는 문자열(아래 참고 참조)과 가중치라고 하는 길이가 포함됩니다. 각 중간 노드에는 왼쪽 하위 트리에 있는 모든 리프의 합에 해당하는 가중치도 포함됩니다.
참고: 리프에 사용된 텍스트는 단순한 예이며 Fleet에서 실제 텍스트가 어떻게 세분화되는지를 나타내지 않습니다.
위의 예에서 문자 fun을 가지고 있는 노드를 예로 들면 문자열의 길이가 3이기 때문에 노드의 수는 3개입니다. 상위 노드로 이동하면 왼쪽에 있는 모든 노드의 가중치 합이 3이므로 개수도 3개입니다. 그러면 상위의 개수는 왼쪽에 있는 리프의 합이 3과 16이기 때문에 19가 됩니다.
문자열 검색, 추가, 제거, 분할과 같은 일반적인 작업은 O(log N) 시간 복잡도로 수행할 수 있습니다(여기서 N은 문자열 길이). 작업은 트리를 횡단하는 것으로 시작하고 노드의 정보가 주어지면 작업이 더 빨라집니다. 예를 들어 위치 i = 30에서 문자를 찾고 싶다면 노드에서 시작하고 30이 노드의 가중치(문자 수)보다 작으면 왼쪽으로 이동하여 i에서 가중치 값을 뺍니다(아래 참고 참조). 반대로 i가 더 크면 오른쪽으로 이동합니다. 아래로 이동하고 i 값이 감소함에 따라 리프 노드에 도달하면 리프 노드가 보유한 문자열의 i 위치에 있는 문자가 바로 우리가 찾고 있던 문자입니다.
참고: 사용된 메트릭에 따라 감산이 필요하지 않을 수도 있습니다. 중요한 것은 트리 아래로 이동할 때 해당 지점까지 메트릭을 누적하고 이를 스캔 중인 키와 비교한다는 것입니다.
Fleet의 로프 구조에서 노드를 삽입하거나 삭제할 때 자체 균형을 유지하는 B-Tree를 사용합니다. 64자의 청크를 읽는 것으로 시작하고 32개의 청크에 도달하면 노드를 만들고 두 번째 노드에 대한 청크 수집을 시작합니다. 각 노드에는 두 개의 숫자가 있으며, 가중치 외에 행 수도 저장합니다(이 둘의 조합을 메트릭이라고 함).

행 수를 저장하면 특정 오프셋으로 더 빠르게 이동할 수 있습니다. Fleet 트리의 또 다른 특성은 깊게가 아닌 넓게 유지하는 데 목표를 둔다는 것입니다.
위젯 등의 간격 트리
앞에서 본 것처럼 코드 조각에는 실제 텍스트뿐만 아니라 사용 위치와 같은 추가 요소도 포함될 수 있습니다.

우리는 이러한 위젯을 호출하며 이는 Find Usages(사용 위치 찾기) 또는 Run(실행) 위젯과 같은 행 간 위젯이거나 포스트라인(예: 코드 줄 뒤에 나타나는 디버그 정보) 또는 인레이(예: 변수 및 람다에 대한 타입 힌트)일 수 있습니다.
위젯 자체는 단순히 마크업 요소이며 이를 보유하는 데이터 구조는 어떤 면에서 일종의 로프 구조인 간격 트리가 변화된 형태입니다. 간격 트리에서 노드는 범위를 가지며 가중치는 하위 트리 범위의 최댓값에 해당합니다.
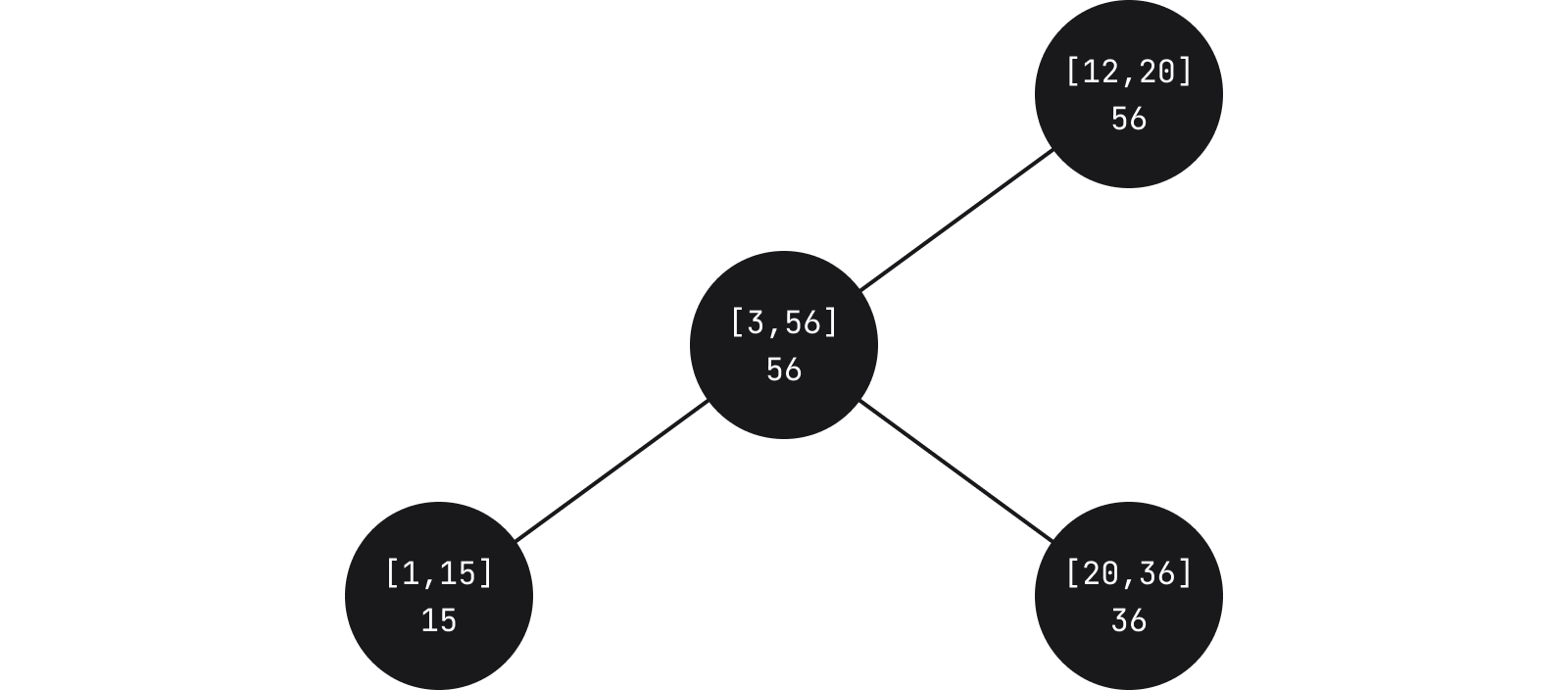
Fleet에서 각 노드는 하위 노드의 상대적 시작과 끝을 포함합니다. 리프는 다시 실제 위젯을 포함합니다. 특정 좌표를 기반으로 특정 위젯을 표시해야 하는지 확인하기 위해 쿼리를 실행할 때 쿼리 중인 항목과 범위의 교차점을 찾을 때까지 트리를 횡단합니다.
중요한 측면은 리프에도 위젯 ID가 포함된다는 것입니다. 즉, 특정 범위와 교차하는 항목을 쿼리하는 외에도 모든 위젯에 대해 실제로 존재하는 위치를 확인하기 위해 쿼리할 수도 있습니다.
표준 간격 트리에서 변형된 것 중 하나는 Fleet에서 노드가 겹칠 수 있다는 것입니다. 이로 인해 검색 효율이 다소 떨어질 수 있지만 이를 허용하면 균형 잡힌 트리를 만들고 입력 시 트리가 업데이트되도록 할 수 있습니다.
위젯 외에도 Fleet의 간격 트리는 캐럿, 텍스트 강조 표시, 앵커라고 부르는 텍스트의 고정 위치를 추적하는 데에도 사용됩니다.
토큰에 대한 로프 및 추상 구문 트리
소스 코드로 작업할 때 컴파일러든 에디터든 일반적으로 추상 구문 트리(AST)를 사용합니다. 추상 구문 트리의 작동 방식은 파서가 소스 코드를 분석하고 일련의 토큰을 생성하는 것입니다. 이렇게 생성된 토큰은 AST를 빌드하는 데 사용됩니다.
다음과 같은 코드가 있다고 가정해보겠습니다.
fun compileBundles(ship: JpsModule, model: JpsModel, src: SrcBundles): DstBundles
이는 다음과 같은 토큰으로 세분화됩니다.
[fun][ ][compileBundles][(][ship][:][ ][JpsModule][,][ ][model][:][ ][JpsModel][,][ ][src][:][ ][SrcBundles][)][:][ ][DstBundles]
여기서 각 토큰은 대괄호로 표시됩니다(빈 공간도 토큰이라는 점에 주목). 이러한 토큰은 해당 AST를 빌드하는 데 사용됩니다.
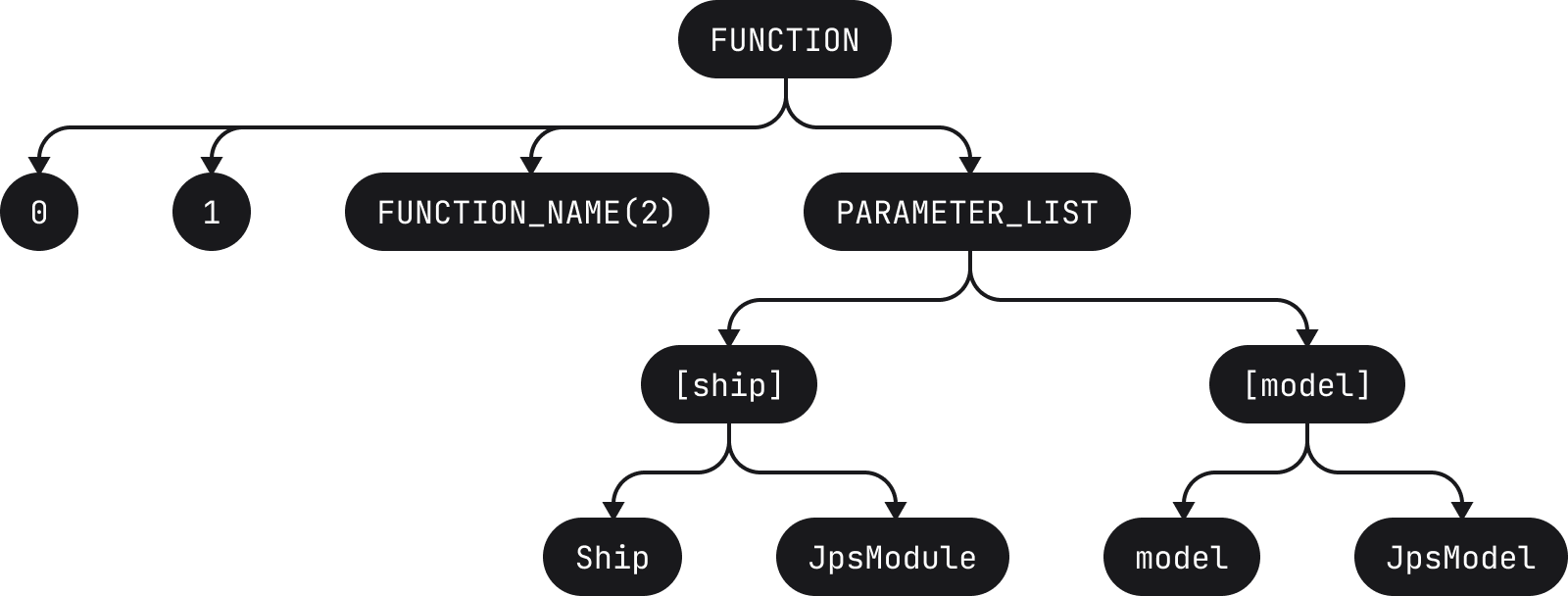
이 AST는 구문 강조 표시, 정적 분석 등과 같은 다양한 작업에 사용됩니다. 이는 모든 IDE에서 중요한 부분입니다.
일부 코드가 AST로 변환되는 방식에 관심이 있는 분들은 이 멋진 온라인 AST 탐색기를 확인하세요(다양한 언어 지원)
에디터에 입력할 때 텍스트가 변경됩니다. 즉, 토큰이 변경되므로 위의 기능을 제공할 수 있도록 새 AST를 빌드해야 합니다.
Fleet에서는 AST를 직접 업데이트하는 것을 피하기 위해 로프 구조를 사용하여 토큰을 리프에 저장합니다(실제로는 길이만 저장됨). 예를 들어 위의 토큰 목록은 다음 트리로 나타낼 수 있습니다.

예를 들어 사용자가 공백 문자와 같이 무언가를 입력하면 트리가 업데이트됩니다(가장 왼쪽 리프에 길이 1이 추가되어 해당 경로를 따라 개수가 증가함)
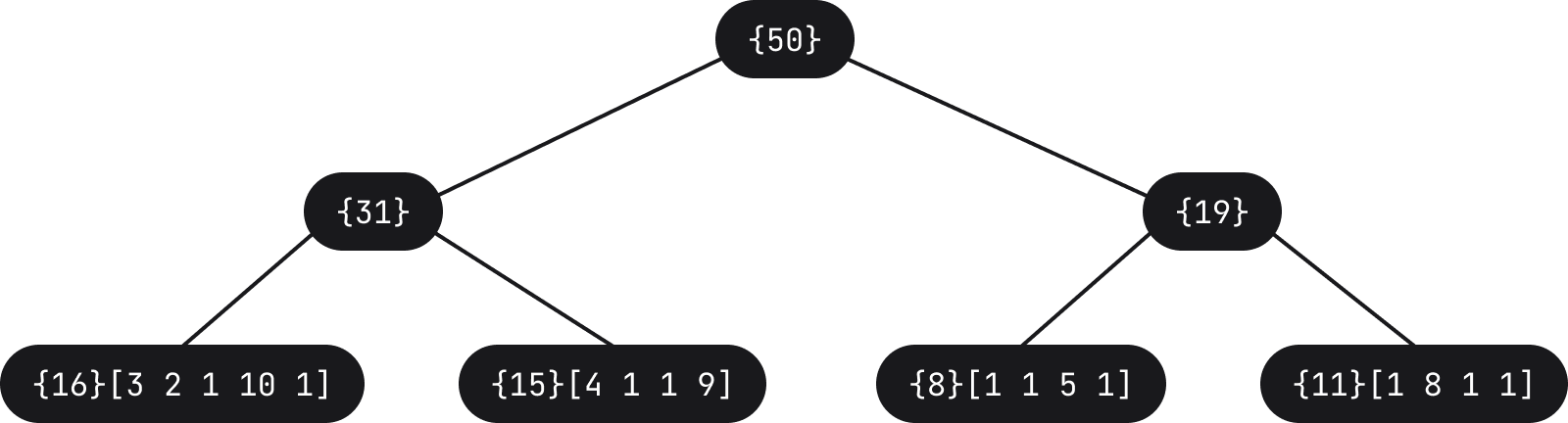
특정 리프에 새로운 토큰 길이가 추가되고, 이로 인해 가중치 조정을 위해 트리의 특정 노드가 업데이트됩니다. 그러면 파서가 AST를 업데이트하고 재분석하도록 하는 알림을 수신합니다. 따라서 몇 초 동안 AST가 완전히 정확하지 않을 수 있지만 업데이트해야 할 내용이 거의 없기 때문에 편집할 때 사용자 경험이 훨씬 더 개선됩니다.
렌더링을 위한 로프
아래 이미지는 에디터의 또 다른 예이지만 이번에는 몇 가지 추가 요소, 즉 사용 위치를 표시하도록 확장된 실제 사용 위치 위젯, 행의 소프트 랩 및 스크롤 막대의 색상 지정된 세로선과 같은 기타 요소가 있습니다.
위의 내용을 렌더링하려면 특정 Y 좌표에 대해 어떤 줄이 표시되는지 알아야 할 뿐만 아니라 모든 위젯과 소프트 랩이 적용된 행도 고려해야 합니다.
재미있는 사실: 사용 위치 위젯에서 렌더링된 에디터는 이 게시물에서 알아보고 있는 것과 동일한 기본 데이터 구조를 사용합니다. 동일한 파일에서 사용하는 경우, 이 오버레이 에디터를 빌드하고 렌더링하는 데 동일한 로프가 사용됩니다.
위젯과 소프트 랩 정보도 로프 구조로 저장됩니다. 이전에는 트리의 리프가 문자열과 그 길이를 담았지만 이 경우에는 리프에 SoftLine 객체라는 것을 포함합니다. 이 객체는 높이에 수반되는 텍스트 청크이며, 시각적 선으로 간주됩니다. 이 경우에 노드의 가중치(메트릭이라고 함)는 SoftLine의 높이와 길이입니다. 뷰포트 쿼리를 지원할 수 있도록 높이가 저장됩니다. 이 높이는 내부에 있는 인터라인의 영향을 받습니다. 또한 소프트 랩이 사용되면 SoftLine이 실제 라인과 일대일로 대응하지 않으며 여러 라인에 걸쳐질 수 있습니다.
불변성에 대한 참고 사항
Fleet에서는 불변성이 수용된다는 점이 중요합니다. 순수한 함수와 불변 객체로 작업하면 많은 이점을 얻을 수 있습니다. 순수 함수를 사용하면 코드에 대해 더 잘 추론할 수 있을 뿐만 아니라 함수를 호출해도 시스템의 다른 부분이 자기도 모르게 변경(부작용이 따름)되지 않을 것이라는 사실을 알 수 있습니다. 데이터 측면에서 객체가 변경되지 않는다는 것은 스레드로부터 안전하다는 것을 의미하므로 업데이트를 시도할 때 경쟁 조건이 발생하지 않습니다. 다중 스레드 환경의 경우에 이는 엄청난 이점을 제공합니다.
이러한 불변성 개념은 로프 구조를 사용하는 작업에서도 핵심적입니다. 앞서 우리는 트리의 노드와 리프를 업데이트하는 방법에 대해 이야기했습니다. 이러한 작업은 모두 불변 조건에서 이루어집니다. 즉, 트리에서 어떤 작업을 수행하면 이전 트리와 구조가 동일한 트리의 새 복사본이 만들어집니다(단, 단일 노드에 대한 루트는 변경이 필요함). 일반적으로 트리는 넓기만 하고 깊지는 않기 때문에 경로가 매우 짧습니다. 작업으로 인해 참조되지 않은 노드가 발생하면 이러한 노드는 가비지 수집됩니다.
이는 읽기-쓰기 잠금 메커니즘을 사용하여 변경을 수행하는 IntelliJ 플랫폼과는 상당히 다른 접근 방식입니다.
요약
Fleet이 빌드된 방식에 대한 이 두 번째 파트에서 살펴보았듯이, 코드를 입력하고 읽을 수 있는 간단한 에디터의 경우에도 그 이면에는 다양한 데이터 구조의 복잡한 체계가 있고 그 중 많은 부분은 로프입니다. 로프에 대해 자세히 알아보려면 Fleet 개발 작업에 큰 영향을 주고 있는 로프 과학 시리즈를 확인하세요.
다음 시간까지 즐겁게 탐구하세요!
게시물 원문 작성자





