

더 빨라진 Python: Python의 전역 인터프리터 잠금 해제

Python의 전역 인터프리터 잠금(GIL)이란?
‘전역 인터프리터 잠금'(또는 GIL)은 Python 커뮤니티에서는 익숙한 용어로, 잘 알려진 Python 작동 방식입니다. 그렇다면 GIL은 정확히 무엇일까요?
다른 프로그래밍 언어(예: Rust)를 사용해 본 적이 있다면 뮤텍스가 무엇인지 아실 겁니다. 뮤텍스는 ‘mutual exclusion’의 줄임말입니다. 뮤텍스는 한 번에 하나의 스레드만 데이터에 액세스할 수 있도록 합니다. 그러면 여러 스레드가 동시에 데이터를 수정하는 것을 방지할 수 있습니다. 이는 키를 보유한 하나의 스레드를 제외한 모든 스레드가 데이터에 접근하지 못하도록 하는 일종의 ‘자물쇠’ 역할을 합니다.
GIL은 형식상 뮤텍스입니다. 한 번에 하나의 스레드만 Python 인터프리터에 액세스할 수 있습니다. 때로는 GIL이 Python의 운전대처럼 느껴지기도 합니다. 운전대를 두 명 이상이 잡는 것은 바람직하지 않으니까요! 하지만 단체 여행을 갈 때는 운전자를 교대하는 경우가 많이 있죠. 이는 다른 스레드에 인터프리터 액세스 권한을 부여하는 것과 비슷합니다.
하지만 GIL 때문에 Python에서는 진정한 멀티스레딩 프로세스가 허용되지 않습니다. 이 기능은 지난 10년 동안 논쟁을 불러일으켰으며, GIL을 제거하고 멀티스레딩 프로세스를 허용하여 Python 속도를 높이려는 시도가 많이 있었습니다. 최근 Python 3.13에서는 GIL없이 Python을 사용할 수 있는 옵션이 도입되었습니다. 이를 종종 no-GIL Python 또는 free-threaded Python(자유로운 스레드 처리 지원 Python)이라고 부릅니다. 이로써 Python 프로그래밍의 새로운 시대가 시작된 것입니다.
처음에 GIL이 구현된 이유
GIL이 그렇게 인기가 없다면 애초에 왜 이를 구현한 것일까요? 실제로 GIL에는 많은 이점이 있습니다. 진정한 멀티스레딩을 갖춘 다른 프로그래밍 언어에서는 여러 스레드가 데이터를 수정할 때 문제가 발생하는 경우가 있으며, 최종 결과가 어느 스레드나 프로세스가 먼저 끝나는지에 따라 달라질 수 있습니다. 이것을 ‘경쟁 상태’라고 합니다. Rust와 같은 언어는 프로그래머가 경쟁 상태를 방지하기 위해 뮤텍스를 사용해야 하기 때문에 배우기 어려운 경우가 많습니다.
Python에서 모든 객체는 자신에게 정보를 요청하는 객체의 수를 추적하는 참조 카운터를 가지고 있습니다. 참조 카운터가 0에 도달하면 GIL로 인해 Python에 경쟁 상태가 없다는 뜻이므로 해당 객체가 더 이상 필요하지 않으며 가비지 컬렉션이 가능하다고 확실히 선언할 수 있습니다.
1991년 Python이 처음 출시되었을 당시 대부분의 개인용 컴퓨터에는 코어가 하나뿐이었고, 멀티스레딩 지원을 요청한 프로그래머는 많지 않았습니다. GIL을 사용하면 프로그램 구현 시 많은 문제를 해결할 수 있고, 코드 유지 관리도 더 쉬워집니다. 이러한 이유로 Python을 만든 Guido van Rossum은 1992년에 GIL을 추가했습니다.
2025년이 된 지금, 개인용 컴퓨터에는 멀티코어 프로세서가 탑재되어 예전보다 훨씬 강력한 컴퓨팅 성능이 크게 향상되었습니다. 이 추가적인 컴퓨팅 성능을 활용해 GIL을 없애지 않고도 진정한 동시성을 얻을 수 있게 되었습니다.
이를 제거하는 과정은 이 글의 뒷부분에서 자세히 설명하겠습니다. 지금은 GIL이 있는 상태에서 진정한 동시성이 어떻게 작동하는지 살펴보겠습니다.
Python에서의 멀티프로세싱
GIL 제거 과정을 자세히 살펴보기 전에 먼저 Python 개발자가 멀티프로세싱 라이브러리를 사용하여 진정한 동시성을 달성할 수 있는 방법을 알아보겠습니다. 멀티프로세싱 표준 라이브러리는 로컬 및 원격 동시성을 모두 제공하며, 스레드 대신 하위 프로세스를 사용하여 전역 인터프리터 잠금을 효과적으로 우회합니다. 이런 식으로 멀티프로세싱 모듈을 사용하면 프로그래머가 특정 컴퓨터의 여러 프로세서를 완전하게 활용할 수 있습니다.
하지만 멀티프로세싱을 수행하려면 프로그램을 약간 다른 방식으로 설계해야 합니다. 다음 예시에서는 Python에서 멀티프로세싱 라이브러리를 사용하는 방법을 보여줍니다.
블로그 시리즈 1부에서 소개한 비동기 햄버거집을 기억하시나요?
import asyncio
import time
async def make_burger(order_num):
print(f"Preparing burger #{order_num}...")
await asyncio.sleep(5) # time for making the burger
print(f"Burger made #{order_num}")
async def main():
order_queue = []
for i in range(3):
order_queue.append(make_burger(i))
await asyncio.gather(*(order_queue))
if __name__ == "__main__":
s = time.perf_counter()
asyncio.run(main())
elapsed = time.perf_counter() - s
print(f"Orders completed in {elapsed:0.2f} seconds.")
멀티프로세싱 라이브러리를 사용하여 동일한 작업을 수행할 수 있습니다. 예를 들면 다음과 같습니다.
import multiprocessing
import time
def make_burger(order_num):
print(f"Preparing burger #{order_num}...")
time.sleep(5) # time for making the burger
print(f"Burger made #{order_num}")
if __name__ == "__main__":
print("Number of available CPU:", multiprocessing.cpu_count())
s = time.perf_counter()
all_processes = []
for i in range(3):
process = multiprocessing.Process(target=make_burger, args=(i,))
process.start()
all_processes.append(process)
for process in all_processes:
process.join()
elapsed = time.perf_counter() - s
print(f"Orders completed in {elapsed:0.2f} seconds.")
멀티프로세싱의 많은 메서드가 스레딩과 매우 유사하다는 것을 기억하실 겁니다. 멀티프로세싱의 차이점을 이해하기 위해 좀 더 복잡한 사용 사례를 살펴보겠습니다.
import multiprocessing
import time
import queue
def make_burger(order_num, item_made):
name = multiprocessing.current_process().name
print(f"{name} is preparing burger #{order_num}...")
time.sleep(5) # time for making burger
item_made.put(f"Burger #{order_num}")
print(f"Burger #{order_num} made by {name}")
def make_fries(order_num, item_made):
name = multiprocessing.current_process().name
print(f"{name} is preparing fries #{order_num}...")
time.sleep(2) # time for making fries
item_made.put(f"Fries #{order_num}")
print(f"Fries #{order_num} made by {name}")
def working(task_queue, item_made, order_num, lock):
break_count = 0
name = multiprocessing.current_process().name
while True:
try:
task = task_queue.get_nowait()
except queue.Empty:
print(f"{name} has nothing to do...")
if break_count > 1:
break # stop if idle for too long
else:
break_count += 1
time.sleep(1)
else:
lock.acquire()
try:
current_num = order_num.value
order_num.value = current_num + 1
finally:
lock.release()
task(current_num, item_made)
break_count = 0
if __name__ == "__main__":
print("Welcome to Pyburger! Please place your order.")
burger_num = input("Number of burgers:")
fries_num = input("Number of fries:")
s = time.perf_counter()
task_queue = multiprocessing.Queue()
item_made = multiprocessing.Queue()
order_num = multiprocessing.Value("i", 0)
lock = multiprocessing.Lock()
for i in range(int(burger_num)):
task_queue.put(make_burger)
for i in range(int(fries_num)):
task_queue.put(make_fries)
staff1 = multiprocessing.Process(
target=working,
name="John",
args=(
task_queue,
item_made,
order_num,
lock,
),
)
staff2 = multiprocessing.Process(
target=working,
name="Jane",
args=(
task_queue,
item_made,
order_num,
lock,
),
)
staff1.start()
staff2.start()
staff1.join()
staff2.join()
print("All tasks finished. Closing now.")
print("Items created are:")
while not item_made.empty():
print(item_made.get())
elapsed = time.perf_counter() - s
print(f"Orders completed in {elapsed:0.2f} seconds.")
나오는 출력은 다음과 같습니다.
Welcome to Pyburger! Please place your order. Number of burgers:3 Number of fries:2 Jane has nothing to do... John is preparing burger #0... Jane is preparing burger #1... Burger #0 made by John John is preparing burger #2... Burger #1 made by Jane Jane is preparing fries #3... Fries #3 made by Jane Jane is preparing fries #4... Burger #2 made by John John has nothing to do... Fries #4 made by Jane Jane has nothing to do... John has nothing to do... Jane has nothing to do... John has nothing to do... Jane has nothing to do... All tasks finished. Closing now. Items created are: Burger #0 Burger #1 Fries #3 Burger #2 Fries #4 Orders completed in 12.21 seconds.
위 코드가 이런 방식으로 설계된 이유는 멀티프로세싱의 몇 가지 제한 때문입니다. 하나씩 살펴보겠습니다.
먼저, 앞서 올바른 order_num을 갖는 함수를 생성하기 위해 make_burger 및 make_fries 함수가 있었다는 점을 기억하세요.
def make_burger(order_num):
def making_burger():
logger.info(f"Preparing burger #{order_num}...")
time.sleep(5) # time for making burger
logger.info(f"Burger made #{order_num}")
return making_burger
def make_fries(order_num):
def making_fries():
logger.info(f"Preparing fries #{order_num}...")
time.sleep(2) # time for making fries
logger.info(f"Fries made #{order_num}")
return making_fries
멀티프로세싱을 사용하면 동일한 작업을 수행할 수 없습니다. 그렇게 시도하면 다음 줄에서 오류가 발생합니다.
AttributeError: Can't get local object 'make_burger..making_burger'
그 이유는 멀티프로세싱이 일반적으로 최상위 모듈 수준 함수만 직렬화할 수 있는 pickle을 사용하기 때문입니다. 이는 멀티프로세싱의 한계 중 하나입니다.
두 번째로, 위의 멀티프로세싱을 사용한 예제 코드 스니펫에서 공유 데이터에 대해 전역 변수를 사용하지 않았다는 점에 유의하세요. 예를 들어, item_made와 order_num에 전역 변수를 사용할 수 없습니다. 서로 다른 프로세스 간에 데이터를 공유하기 위해 멀티프로세싱 라이브러리의 특수 클래스 객체(예: Queue 및 Value)가 사용되고 프로세스에 인수로 전달됩니다.
일반적으로, 서로 다른 프로세스 간에 데이터와 상태를 공유하는 것은 더 많은 문제를 야기할 수 있으므로 권장되지 않습니다. 위의 예에서는 잠금을 사용하여 order_num의 값이 한 번에 하나의 프로세스에 의해서만 접근되고 증가하도록 해야 합니다. 잠금이 없으면 품목의 주문 번호가 다음과 같이 엉망이 될 수 있습니다.
Items created are: Burger #0 Burger #0 Fries #2 Burger #1 Fries #3
문제를 피하기 위해 잠금을 사용하는 방법은 다음과 같습니다.
lock.acquire()
try:
current_num = order_num.value
order_num.value = current_num + 1
finally:
lock.release()
task(current_num, item_made)
멀멀티프로세싱 표준 라이브러리 사용법을 더 알아보고 싶으시다면, 이 문서를 참고하세요.
GIL 제거
GIL 제거는 거의 10년 동안 논의된 주제였습니다. 2016년 Python Language Summit에서 Larry Hastings는 CPython 인터프리터의 ‘GIL 제거’에 대한 자신의 아이디어와 이 아이디어로 이룬 성과를 발표했습니다[1]. 이는 Python GIL을 제거하려는 획기적인 시도였습니다. 2021년에 Sam Gross는 GIL[2] 제거에 대한 논의를 다시 시작했고, 이로 인해 2023년에 CPython에서 전역 인터프리터 잠금을 선택 사항으로 만드는 PEP 703이 출시되었습니다.
보시다시피, GIL을 제거하는 것은 결코 성급한 결정이 아니었으며 이미 커뮤니티 내에서 상당한 논쟁의 대상이 되어 왔습니다. 위의 멀티프로세싱 예제(및 위에 링크된 PEP 703)에서 볼 수 있듯이 GIL이 제공하던 보장이 사라지면 상황은 빠르게 복잡해집니다.
[1]: https://lwn.net/Articles/689548/
[2]: https://lwn.net/ml/python-dev/CAGr09bSrMNyVNLTvFq-h6t38kTxqTXfgxJYApmbEWnT71L74-g@mail.gmail.com/
참조 계산
GIL이 있으면 참조 계산과 가비지 컬렉션이 더 간단해집니다. 한 번에 하나의 스레드만 Python 객체에 접근할 수 있는 경우 간단한 비원자적 참조 계산을 사용하고 참조 계산이 0에 도달하면 객체를 제거할 수 있습니다.
GIL을 제거하면 상황이 조금 까다로워집니다. 스레드 안전이 보장되지 않으므로 비원자적 참조 계산을 더 이상 사용할 수 없습니다. 여러 스레드가 Python 객체에 대한 참조의 증가와 감소를 동시에 수행하는 경우 문제가 발생할 수 있습니다. 이상적으로는 원자적 참조 계산을 사용하여 스레드 안전성을 보장할 수 있습니다. 하지만 이 방법은 오버헤드가 높고 스레드가 많을 경우 효율성에 영향을 미칩니다.
해결책은 편향된 참조 계산을 사용하는 것인데, 이를 통해 스레드 안전성도 보장됩니다. 여기서 아이디어는 각 객체를 소유자 스레드, 즉 대부분의 시간 동안 객체에 액세스하는 스레드에 편향시키는 것입니다. 소유자 스레드는 자신이 소유한 객체에 대해 비원자적 참조 계산을 수행할 수 있는 반면, 다른 스레드는 이러한 객체에 대해 원자적 참조 계산을 수행해야 합니다. 이러한 접근 방식은 대부분의 객체가 대부분의 시간 동안 하나의 스레드에 의해서만 액세스되기 때문에 순수한 원자적 참조 계산보다 더 바람직합니다. 소유자 스레드가 비원자적 참조 계산을 수행하도록 허용하면 실행 오버헤드를 줄일 수 있습니다.
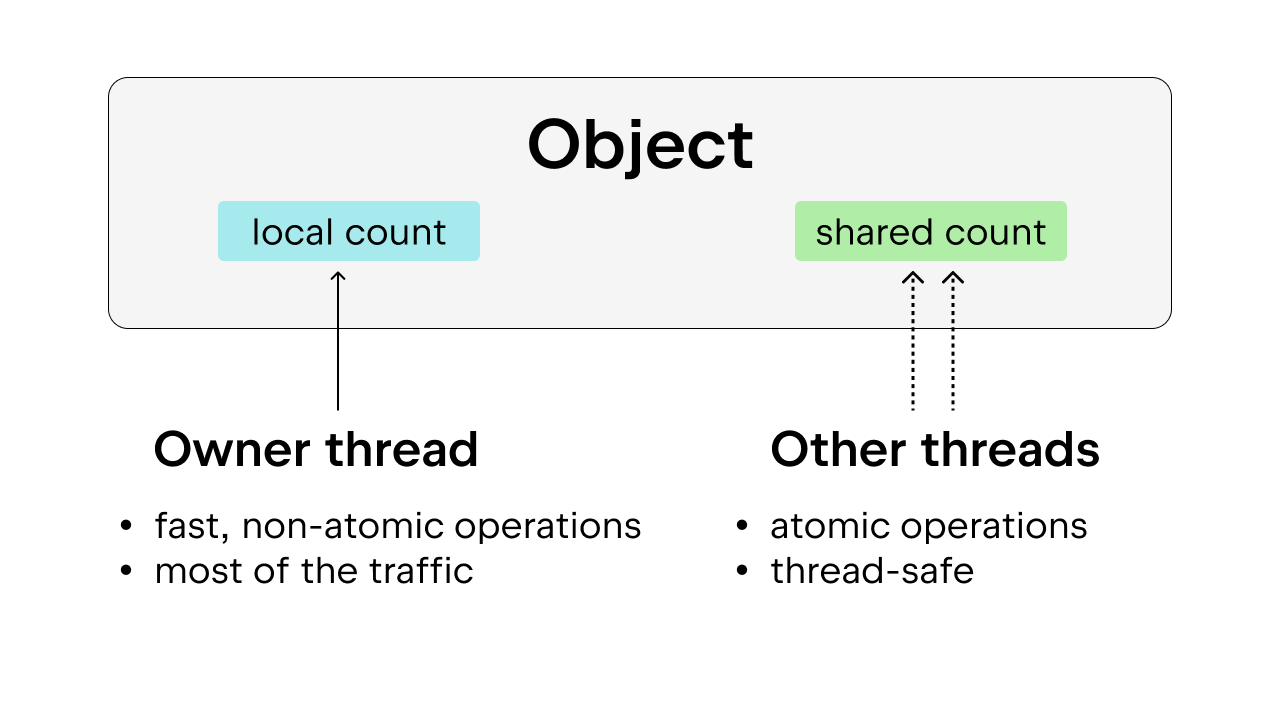
또한 True, False, 작은 정수 및 일부 임시 문자열과 같이 일반적으로 사용되는 일부 Python 객체는 영구적입니다. 여기서 ‘영구적’이란 객체가 프로그램의 수명 동안 보존되므로 참조 계산이 필요하지 않다는 것을 의미합니다.
가비지 컬렉션
가비지 컬렉션이 수행되는 방식도 수정해야 합니다. 참조가 해제될 때 참조 카운트는 즉시 감소하지 않으며, 참조 카운트가 0에 도달해도 객체는 즉시 제거되지 않습니다. 대신 ‘지연 참조 계산’이라는 기법이 사용됩니다.
참조 카운트를 감소시켜야 하는 경우, 객체는 테이블에 저장되고 이후 두 번 검사되어 참조 카운트가 올바르게 감소했는지 확인합니다. 이를 통해 GIL을 사용하지 않으면 참조 계산이 GIL만큼 직관적이지 않기 때문에 참조 중인 객체가 조기에 제거되는 일이 발생하지 않습니다. 이렇게 되면 가비지 컬렉션 프로세스가 더 복잡해집니다. 가비지 컬렉션이 각 스레드의 자체 참조 카운트를 얻기 위해 각 스레드의 스택을 탐색해야 할 수도 있기 때문입니다.
고려해야 할 또 다른 사항은 가비지 컬렉션 중에 참조 카운트가 안정적으로 유지되어야 한다는 것입니다. 객체가 삭제되려고 할 때 갑자기 참조되는 경우 심각한 문제가 발생할 수 있습니다. 따라서 가비지 컬렉션 주기 동안 스레드 안전을 보장하기 위해 ‘세계를 멈춰야’ 합니다.
메모리 할당
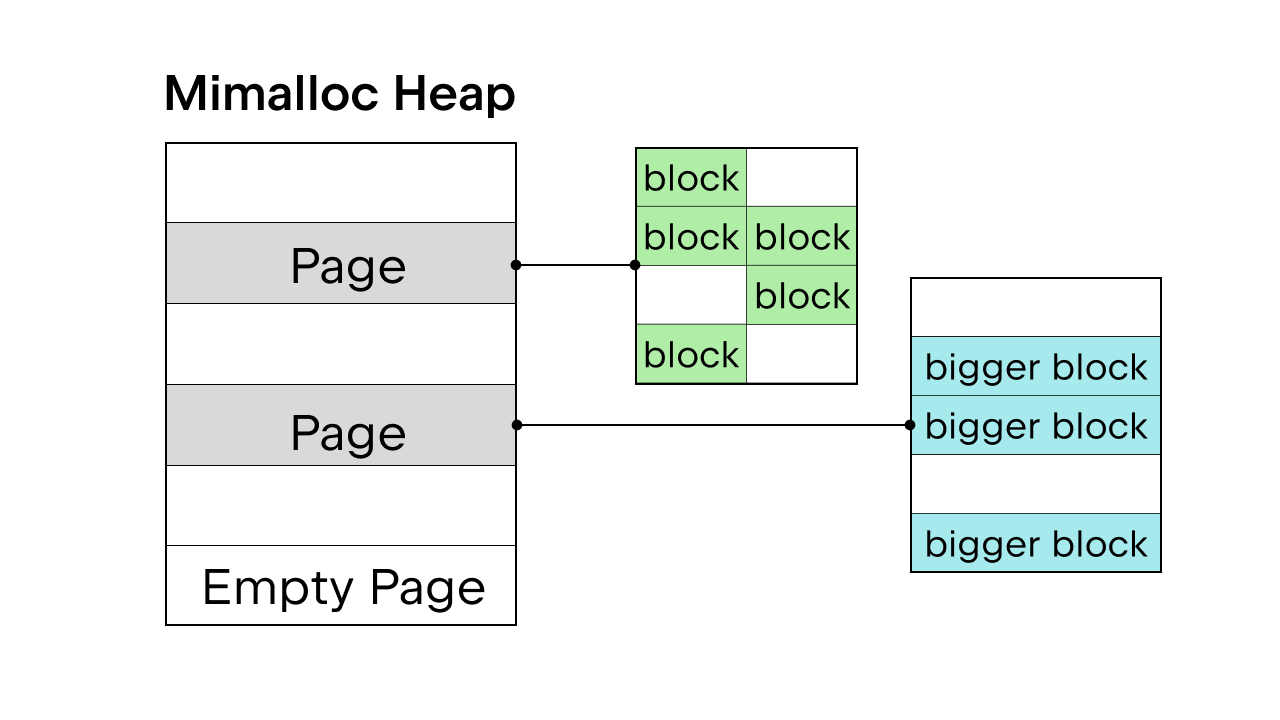
GIL을 사용하여 스레드 안전을 보장하는 경우 Python의 내부 메모리 할당자 pymalloc이 사용됩니다. 하지만 GIL이 없다면 새로운 메모리 할당자가 필요할 것입니다. Sam Gross는 Daan Leijen이 만들고 Microsoft에서 유지 관리하는 범용 할당자인 mimalloc을 PEP에서 제안했습니다. 이 방법은 스레드로부터 안전하고 작은 객체에서도 양호한 성능을 발휘하므로 좋은 선택입니다.
Mimalloc은 힙을 페이지로 채우고 페이지 블록으로 채웁니다. 각 페이지에는 블록이 포함되어 있으며, 각 페이지 내의 블록 크기는 모두 동일합니다. 목록과 사전 액세스에 몇 가지 제한을 추가함으로써 가비지 컬렉터는 모든 객체를 찾기 위해 연결 목록을 유지할 필요가 없으며, 잠금을 획득하지 않고도 목록과 사전에 대한 읽기 액세스를 허용합니다.
GIL 제거에 대해 더 깊이 있는 내용들이 많지만 여기서 모두 다루는 것은 불가능합니다. 자세한 내용은 PEP 703 – CPython에서 전역 인터프리터 잠금을 선택 사항으로 만들기에서 확인할 수 있습니다.
GIL이 있는 경우와 없는 경우의 성능 차이
Python 3.13은 자유 스레드 옵션을 제공하므로 표준 Python 3.13 버전과 자유 스레드 버전의 성능을 비교할 수 있습니다.
자유 스레드 Python 설치
pyenv를 사용하여 두 버전을 설치합니다. 표준 버전(예: 3.13.5)과 자유 스레드 버전(예: 3.13.5t)입니다.
또는 Python.org에서 설치 프로그램을 사용할 수도 있습니다. 자유 스레드 Python을 설치하려면 설치하는 동안 Customize(사용자 지정) 옵션을 선택하고 추가 상자를 선택하세요(이 블로그 글의 예시 참조).
두 버전을 모두 설치하면 PyCharm 프로젝트에 인터프리터로 추가할 수 있습니다.
먼저, 오른쪽 하단에 있는 Python 인터프리터의 이름을 클릭합니다.
메뉴에서 Add New Interpreter(새 인터프리터 추가)를 선택한 다음, Add Local Interpreter(지역 인터프리터 추가)를 선택합니다.
Select existing(기존 항목 선택)을 선택하고 인터프리터 경로가 로드될 때까지 기다립니다(저처럼 인터프리터가 많으면 시간이 좀 걸릴 수 있습니다). 그런 다음 Python path(Python 경로) 드롭다운 메뉴에서 방금 설치한 새 인터프리터를 선택합니다.
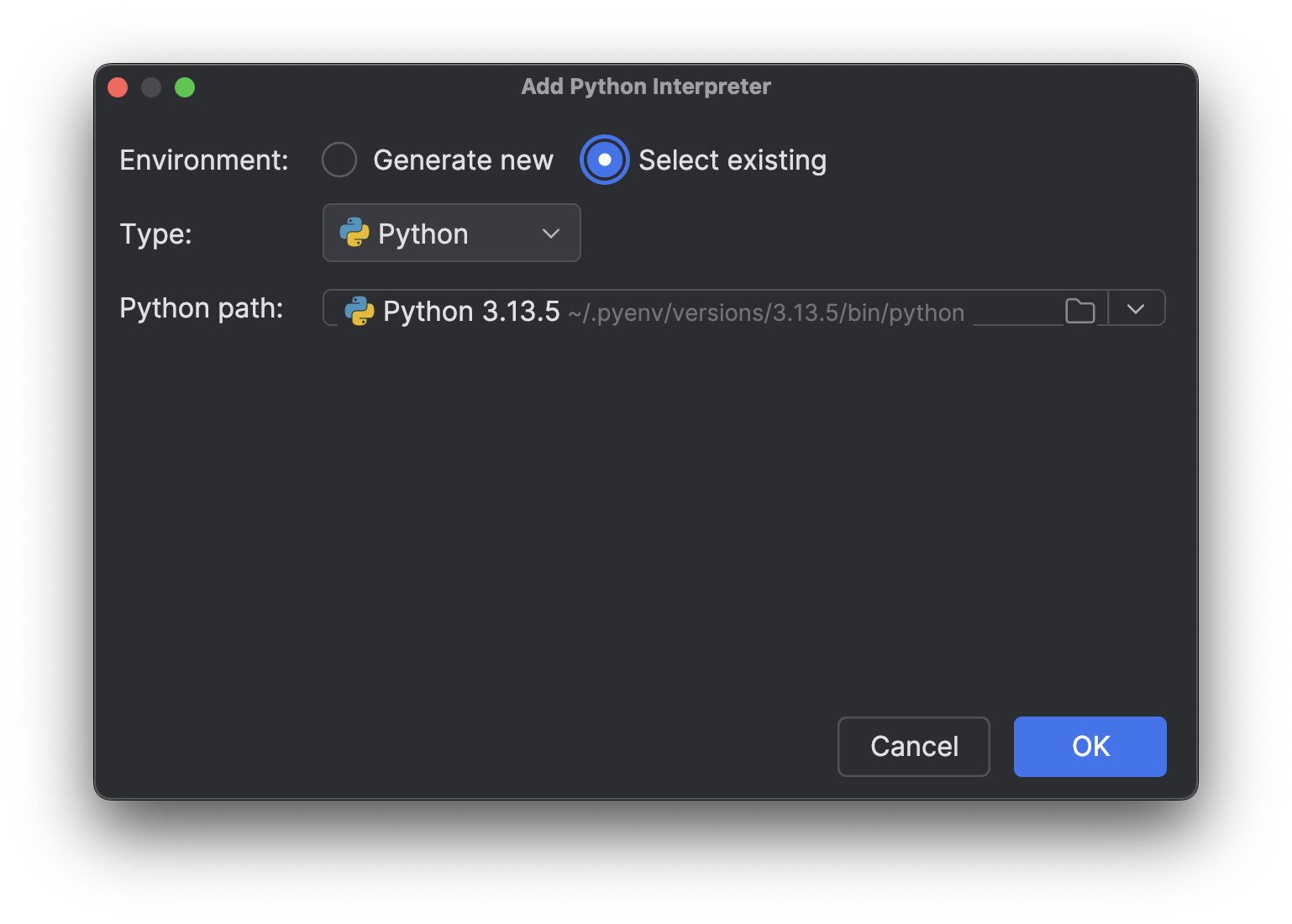
OK(확인)를 클릭하여 추가합니다. 다른 인터프리터에도 같은 단계를 반복합니다. 이제 오른쪽 하단에 있는 인터프리터 이름을 다시 클릭하면 위의 이미지와 같이 여러 개의 Python 3.13 인터프리터가 표시됩니다.
CPU 집약적 프로세스로 테스트
다음으로, 여러 버전을 테스트하기 위한 스크립트가 필요합니다. 이 블로그 시리즈의 1부에서 CPU 집약적 프로세스의 속도를 높이려면 진정한 멀티스레딩이 필요하다고 설명했습니다. GIL을 제거하여 진정한 멀티스레딩이 실행되고 Python이 더 빨라지는지 확인하려면 여러 스레드에서 CPU를 많이 사용하는 프로세스로 테스트해 볼 수 있습니다. 제가 Junie에게 생성해달라고 한 스크립트는 다음과 같습니다(최종적으로 몇 가지를 수정했음).
import time
import multiprocessing # Kept for CPU count
from concurrent.futures import ThreadPoolExecutor
import sys
def is_prime(n):
"""Check if a number is prime (CPU-intensive operation)."""
if n <= 1:
return False
if n <= 3:
return True
if n % 2 == 0 or n % 3 == 0:
return False
i = 5
while i * i <= n:
if n % i == 0 or n % (i + 2) == 0:
return False
i += 6
return True
def count_primes(start, end):
"""Count prime numbers in a range."""
count = 0
for num in range(start, end):
if is_prime(num):
count += 1
return count
def run_single_thread(range_size, num_chunks):
"""Run the prime counting task in a single thread."""
chunk_size = range_size // num_chunks
total_count = 0
start_time = time.time()
for i in range(num_chunks):
start = i * chunk_size + 1
end = (i + 1) * chunk_size + 1 if i < num_chunks - 1 else range_size + 1
total_count += count_primes(start, end)
end_time = time.time()
return total_count, end_time - start_time
def thread_task(start, end):
"""Task function for threads."""
return count_primes(start, end)
def run_multi_thread(range_size, num_threads, num_chunks):
"""Run the prime counting task using multiple threads."""
chunk_size = range_size // num_chunks
total_count = 0
start_time = time.time()
with ThreadPoolExecutor(max_workers=num_threads) as executor:
futures = []
for i in range(num_chunks):
start = i * chunk_size + 1
end = (i + 1) * chunk_size + 1 if i < num_chunks - 1 else range_size + 1
futures.append(executor.submit(thread_task, start, end))
for future in futures:
total_count += future.result()
end_time = time.time()
return total_count, end_time - start_time
def main():
# Fixed parameters
range_size = 1000000 # Range of numbers to check for primes
num_chunks = 16 # Number of chunks to divide the work into
num_threads = 4 # Fixed number of threads for multi-threading test
print(f"Python version: {sys.version}")
print(f"CPU count: {multiprocessing.cpu_count()}")
print(f"Range size: {range_size}")
print(f"Number of chunks: {num_chunks}")
print("-" * 60)
# Run single-threaded version as baseline
print("Running single-threaded version (baseline)...")
count, single_time = run_single_thread(range_size, num_chunks)
print(f"Found {count} primes in {single_time:.4f} seconds")
print("-" * 60)
# Run multi-threaded version with fixed number of threads
print(f"Running multi-threaded version with {num_threads} threads...")
count, thread_time = run_multi_thread(range_size, num_threads, num_chunks)
speedup = single_time / thread_time
print(f"Found {count} primes in {thread_time:.4f} seconds (speedup: {speedup:.2f}x)")
print("-" * 60)
# Summary
print("SUMMARY:")
print(f"{'Threads':<10} {'Time (s)':<12} {'Speedup':<10}")
print(f"{'1 (baseline)':<10} {single_time:<12.4f} {'1.00x':<10}")
print(f"{num_threads:<10} {thread_time:<12.4f} {speedup:.2f}x")
if __name__ == "__main__":
main()
다양한 Python 인터프리터를 사용하여 스크립트를 더 쉽게 실행할 수 있도록 PyCharm 프로젝트에 사용자 지정 실행 스크립트를 추가할 수 있습니다.
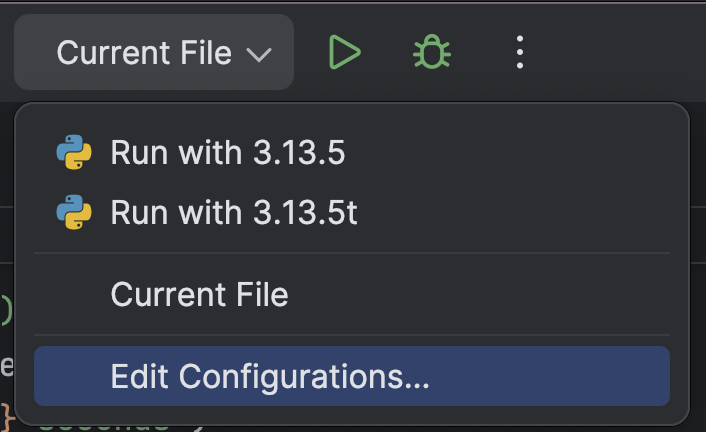
맨 위에서 Run(실행) 버튼(![]() ) 옆에 있는 드롭다운 메뉴에서 Edit Configurations(구성 편집)…을 선택합니다.
) 옆에 있는 드롭다운 메뉴에서 Edit Configurations(구성 편집)…을 선택합니다.
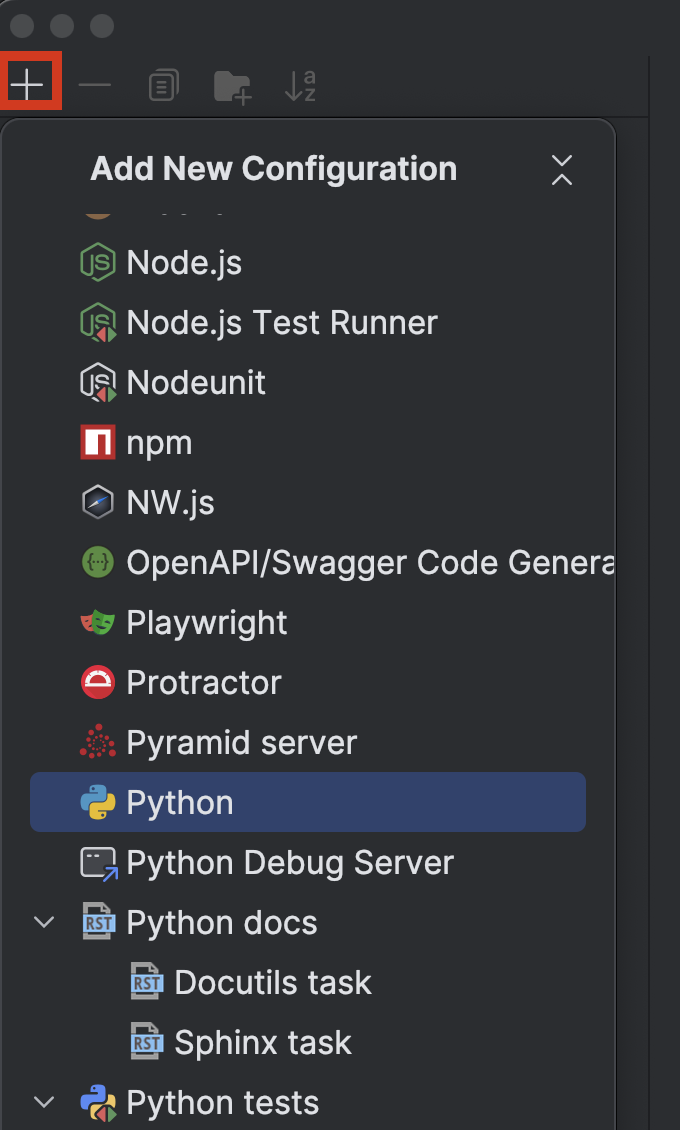
왼쪽 상단에 있는 + 버튼을 클릭하고 Add New Configuration(새 구성 추가) 드롭다운 메뉴에서 Python을 선택합니다.
어떤 인터프리터가 사용되고 있는지 알 수 있는 이름을 선택합니다(예를 들어 3.13.5와 3.15.3t). 아래에 표시된 대로 올바른 인터프리터를 선택하고 테스트 스크립트 이름을 추가합니다.
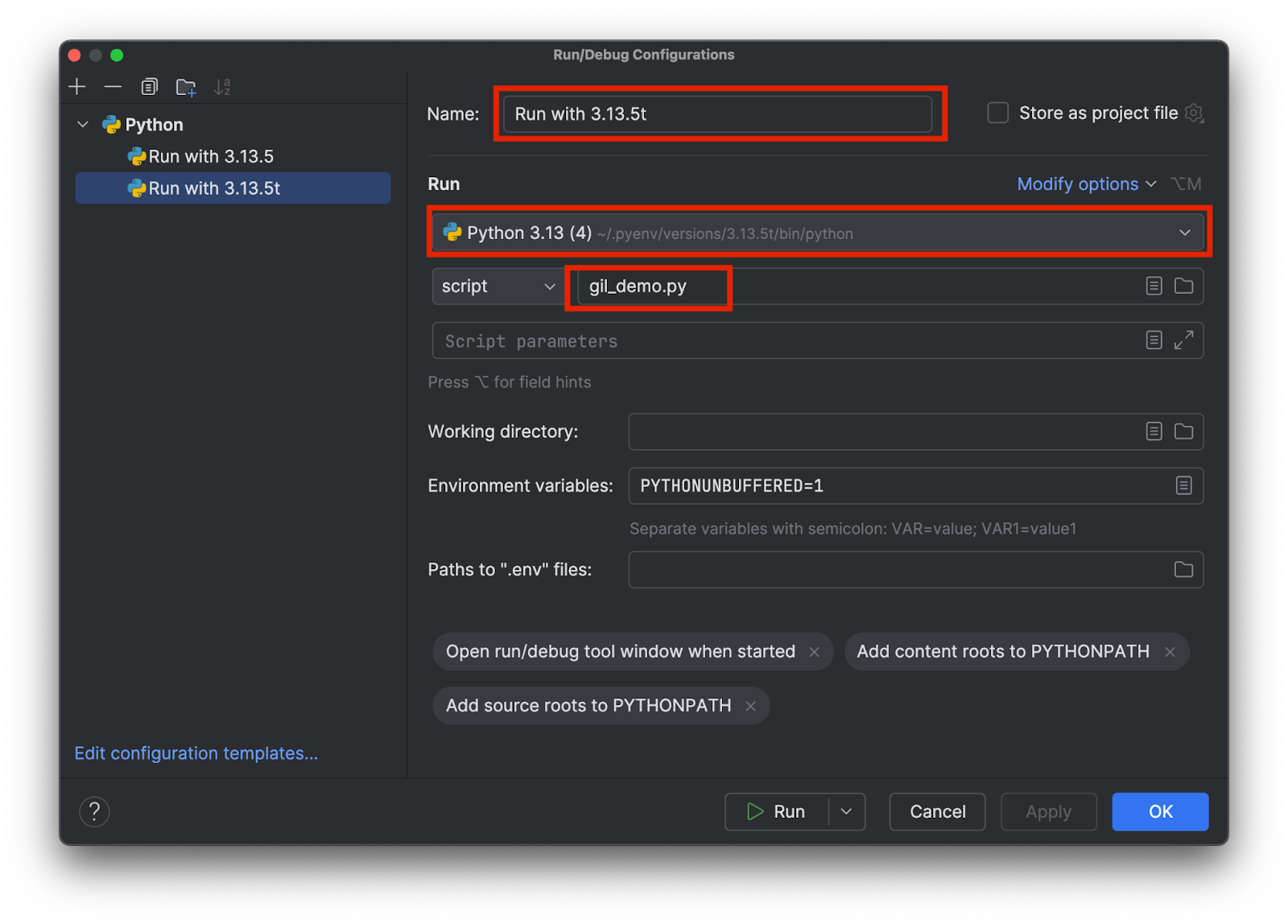
각 인터프리터에 대해 하나씩 두 개의 구성을 추가합니다. 그런 다음 OK(확인)를 클릭합니다.
이제 구성을 선택하고 상단의 Run(실행) 버튼(![]() )을 클릭하면 GIL을 포함하거나 포함하지 않고 테스트 스크립트를 쉽게 선택하고 실행할 수 있습니다.
)을 클릭하면 GIL을 포함하거나 포함하지 않고 테스트 스크립트를 쉽게 선택하고 실행할 수 있습니다.
결과 비교
GIL이 사용된 표준 버전 3.13.5를 실행하면 다음과 같은 결과가 나옵니다.
Python version: 3.13.5 (main, Jul 10 2025, 20:33:15) [Clang 17.0.0 (clang-1700.0.13.5)] CPU count: 8 Range size: 1000000 Number of chunks: 16 ------------------------------------------------------------ Running single-threaded version (baseline)... Found 78498 primes in 1.1930 seconds ------------------------------------------------------------ Running multi-threaded version with 4 threads... Found 78498 primes in 1.2183 seconds (speedup: 0.98x) ------------------------------------------------------------ SUMMARY: Threads Time (s) Speedup 1 (baseline) 1.1930 1.00x 4 1.2183 0.98x
보시다시피, 4 스레드 버전을 실행할 때와 기준인 단일 스레드를 실행할 때 속도에 큰 변화가 없습니다. 자유 스레드 버전 3.13.5t를 실행하면 어떤 결과가 나오는지 살펴보겠습니다.
Python version: 3.13.5 experimental free-threading build (main, Jul 10 2025, 20:36:28) [Clang 17.0.0 (clang-1700.0.13.5)] CPU count: 8 Range size: 1000000 Number of chunks: 16 ------------------------------------------------------------ Running single-threaded version (baseline)... Found 78498 primes in 1.5869 seconds ------------------------------------------------------------ Running multi-threaded version with 4 threads... Found 78498 primes in 0.4662 seconds (speedup: 3.40x) ------------------------------------------------------------ SUMMARY: Threads Time (s) Speedup 1 (baseline) 1.5869 1.00x 4 0.4662 3.40x
이번에는 속도가 이전보다 3배 이상 빨라졌습니다. 두 경우 모두 멀티스레딩의 오버헤드가 있다는 점에 유의하세요. 따라서 진정한 멀티스레딩을 사용하더라도 4개 스레드에서 4배의 속도가 나오지는 않습니다.
결론
Faster Python 블로그 시리즈 2부에서는 과거에 Python GIL을 사용했던 이유, 멀티프로세싱을 사용하여 GIL의 한계를 우회하는 방법, 그리고 GIL을 제거하는 프로세스와 효과에 대해 논의했습니다.
이 블로그 게시물을 작성할 당시 Python의 자유 스레드 버전은 여전히 기본 버전이 아니었습니다. 하지만 커뮤니티와 타사 라이브러리의 채택으로 인해 앞으로는 자유 스레드 버전의 Python이 표준이 될 것으로 커뮤니티에서는 기대하고 있습니다. 발표에 따르면, Python 3.14에는 실험 단계를 넘어서는 자유 스레드 버전이 포함될 예정이지만, 이는 선택 사항으로 남을 것입니다.
PyCharm은 속도와 정확성을 보장하며 최고 수준의 Python 지원을 제공합니다. 모든 코딩 요구 사항에 대해 가장 스마트한 코드 완성, PEP 8 준수, 스마트 리팩터링 및 검사 기능을 활용하세요. 이 블로그 게시물에서 보여 드렸듯이 PyCharm은 Python 인터프리터와 실행 구성에 대한 사용자 지정 설정을 제공하므로 몇 번의 클릭만으로 다양한 Python 프로젝트에 맞게 인터프리터를 전환할 수 있습니다.




