

Kotlin
A concise multiplatform language developed by JetBrains
Kotlin DataFrame Preview

TL;DR: We at the Kotlin team have developed a Kotlin library for data frames. Today we’re releasing its first public preview version. It provides a readable and powerful DSL for data wrangling and i/o via CSV, JSON, Excel, and Apache Arrow, as well as interop with Kotlin data classes and hierarchical data schemas. The library is ready for you to try, and we’re keen to get your feedback.
Today we’re unveiling a new member of the collection of Kotlin libraries for data science. We’ve previously written about KotlinDL for deep learning and Multik for tensors. Now we’d like to introduce Kotlin DataFrame, a library for working with data frames.
Overview
One blog post is not enough to cover every aspect of the library, so we started a series of videos about Kotlin DataFrame. Below you’ll find the first video, which covers basic operations and the process of working with plain (non-hierarchical) tables. More videos are in the works, so please let us know whether you like this format and what we can improve.
What does it look like?
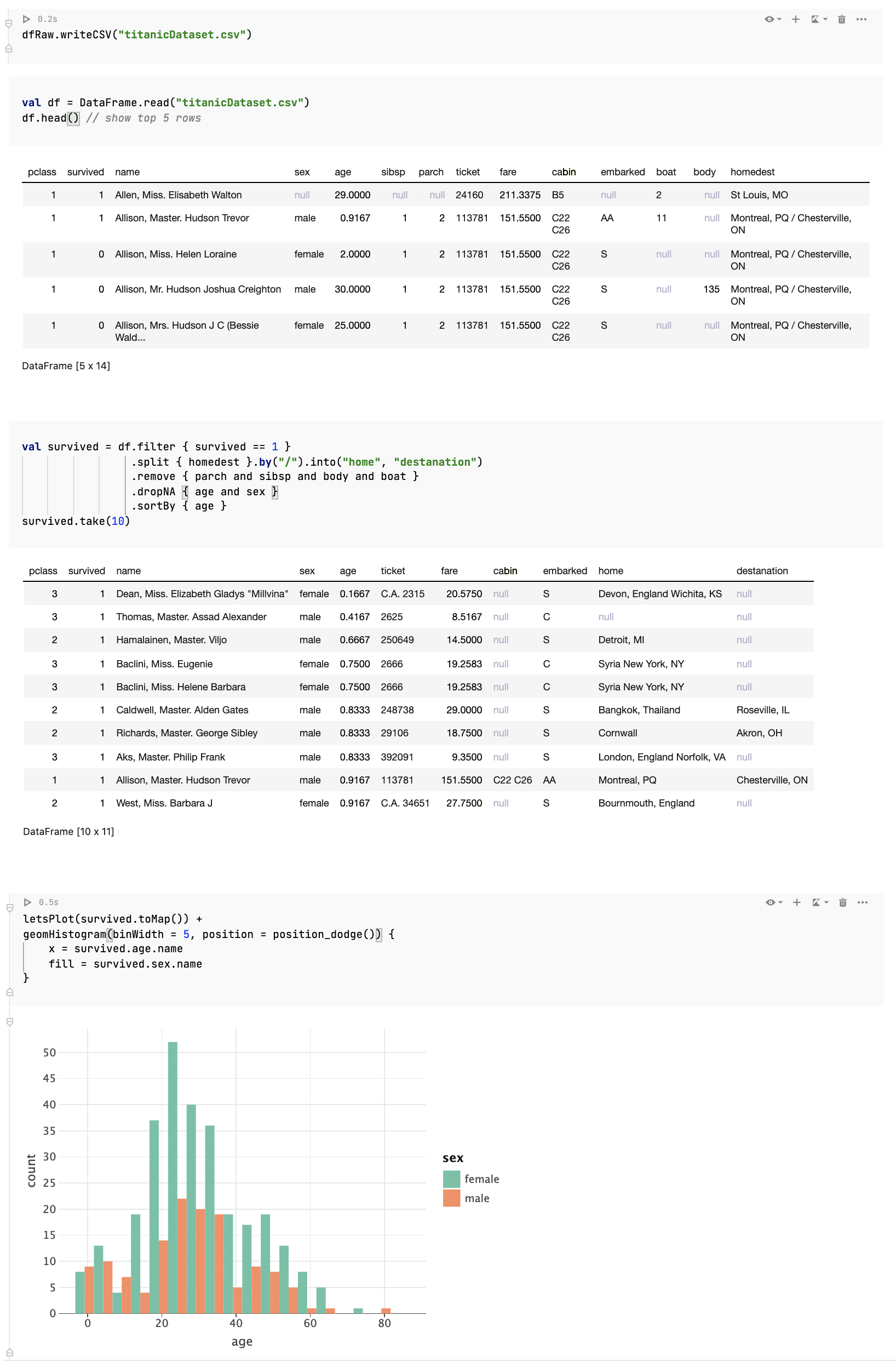
What is a data frame?
So what is a data frame? A data frame is a convenient abstraction for working with structured data. Essentially, it’s a 2-dimensional table with labeled columns of potentially different types. You can think of it as a spreadsheet or SQL table, or a dictionary of collections. If you’ve ever worked with Excel or CSV files, you are already more or less familiar with the concept of data frames.
But what makes this abstraction so convenient is not the table itself, but rather the set of operations defined in on it. And Kotlin DataFrame is an idiomatic Kotlin DSL-based language for defining such operations. The process of working with data frames is often called data wrangling. This involves transforming and mapping data from a “raw” data format onto another format that is more appropriate for analytics and visualization. The goal of data wrangling is to ensure that data is useful and of high quality. Data analysts typically spend the majority of their time wrangling data, rather than analyzing. And that’s why it is so important to make this process easy, smooth, and enjoyable.
I’m not a data scientist, why should I care?
First of all, who knows? Maybe you will become a data scientist one day. :-)
Analyzing data is not restricted to the field of data science. We often do it in our roles as software developers. For example, we analyze what’s actually inside collections when debugging, dig into memory dumps or databases, work with REST APIs, and receive JSON files with data in them. Having a typesafe and easy DSL for these sorts of tasks would be really beneficial.
Why a new library?
Why are we developing a new library if several JVM-based data frames already exist?
Kotlin DataFrame was inspired by the Krangl library and started as a wrapper on top of it. Over time, however, we had to rewrite more and more of the library, and we ended up changing almost all of it. While rewriting it, we’ve followed these guiding principles:
- Idiomatic – The API should be natural for Kotlin developers and consistent with the Kotlin standard library.
- Hierarchical – Data frames should be able to read and present data from different sources, including not only plain CSV but also JSON, e.g. directly from REST APIs. That’s why data frames have been designed hierarchically and allow the nesting of columns and cells.

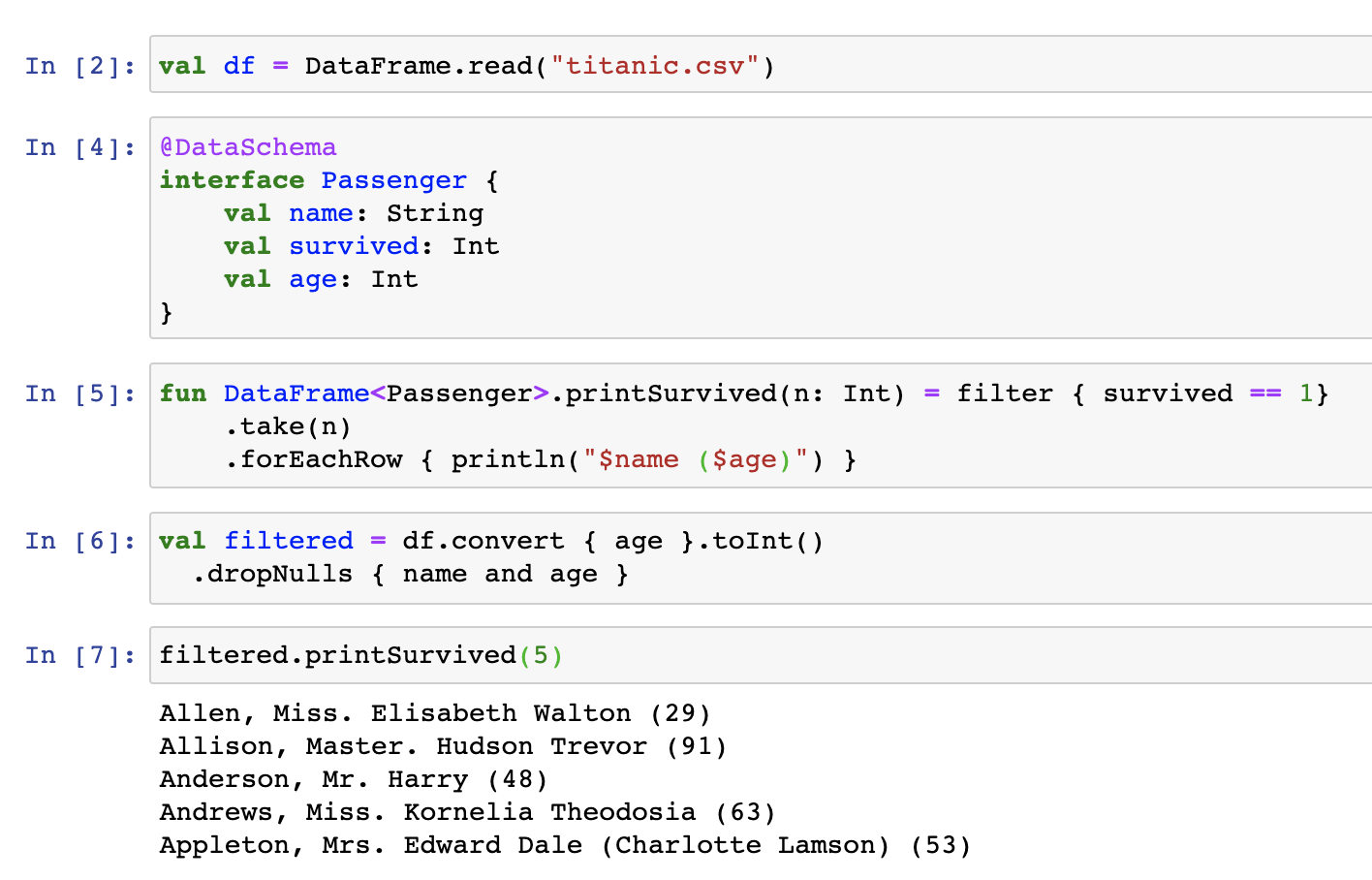
- Generic – Data frames should be able to store not just a limited set of value types, but any Kotlin object, providing null-safety support for all of them.
- Interoperable – We need to add seamless integration with Kotlin collections, converting any object structure in application memory to a data frame, and vice versa.
- Typesafe and practical – Data frames are highly dynamic objects. Their labels depend on the input source, and new columns can also be added or removed during data wrangling. To make it possible to access them in a safe and convenient way, we’ve developed a mechanism for the on-the-fly generation of extension properties that correspond to the columns of a data frame. In interactive notebooks like Jupyter or Datalore, this generation runs after the execution of each cell. Currently, we’re working on a compiler plugin that infers and transforms the data frame schema while typing.
The generated properties ensure you’ll never misspell column names or mess up their types. And of course, nullability is also preserved.
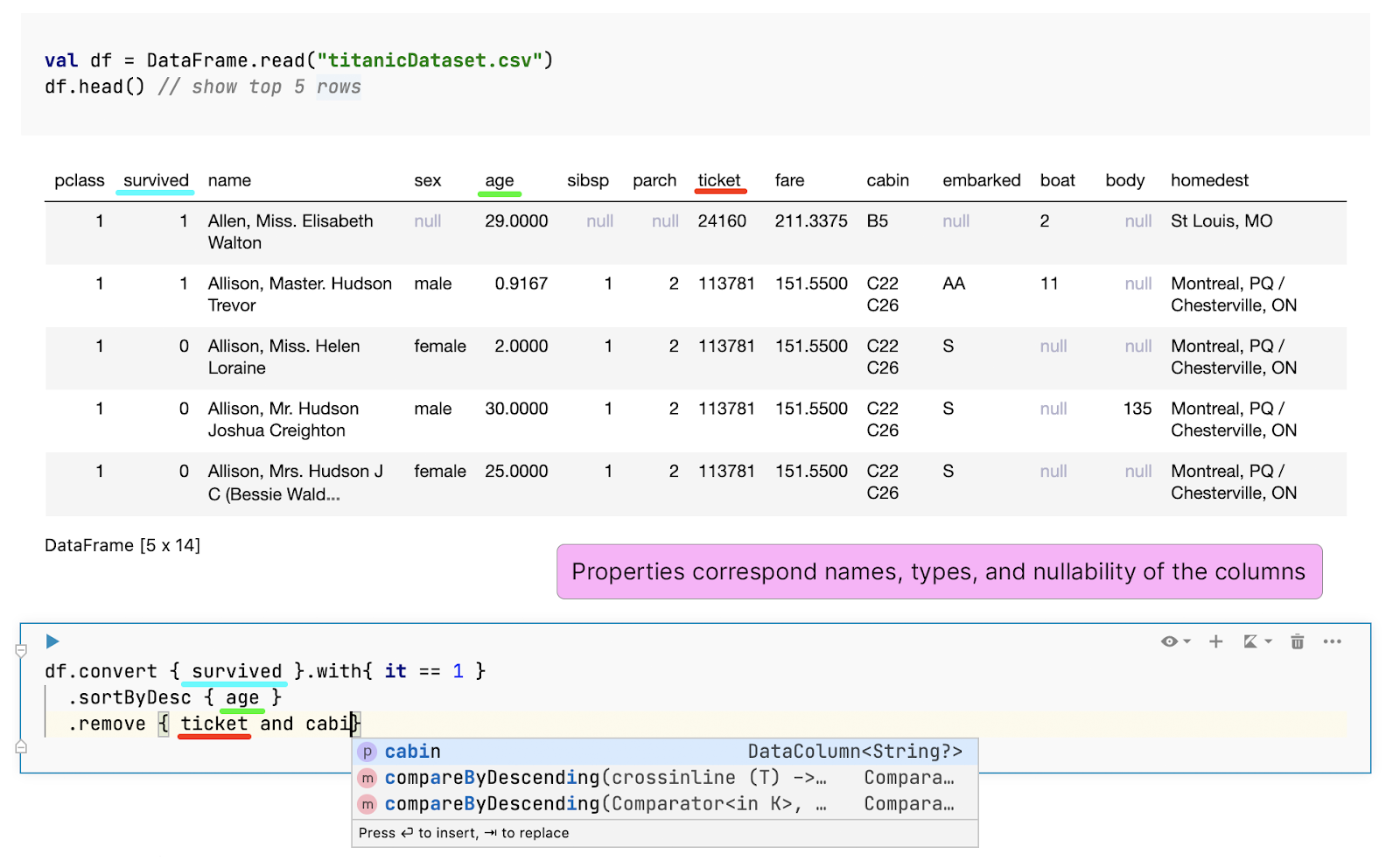
- Polymorphic – If all the columns of one data frame are presented in some other data frame, then the former can be a supertype for the latter. This means we can define a function for a data frame with an expected set of columns and later safely execute it for any data frame that contains them
Where to start?
- Documentation (check it out; it’s really helpful)
- Installation (Jupyter, Datalore, Gradle)
- Repository
- Samples
- You’re also welcome to join the #datascience channel in Kotlin Slack (get an invite here). In this channel, you can ask questions, participate in discussions, and get notifications about the new releases
Let’s Kotlin!







