

Rust Iterators Beyond the Basics, Part I – Building Blocks

Iterators are heavily used across codebases in Rust, making it worthwhile to understand them in detail, beyond just the basics. In this blog post series, we will discuss topics that every beginner-to-intermediate-level Rust developer must keep in mind. For those with a limited understanding of Rust iterators, it is advisable to first read through the corresponding section of The Rust Programming Language. Reading the documentation for the std::iter module is also highly beneficial since it will give a comprehensive overview of the iterator functionality provided by the Rust standard library.
This multipart series focuses on Rust iterators, covering both the specifics of their implementation and some practical use cases.
- Part I – Building Blocks: Iterator Traits, Structures, and Adapters
- Part II – Key Aspects: Memory Ownership, Structuring Code, Performance
- Part III – Tips & Tricks
Iterator traits, structures, and adapters
Programming is largely about processing data that originates from various sources and is typically divided into manageable elements. An iterator is an object that enables us to fetch the next element from a data source in a seamless manner. The richness of the ecosystem that emerges from such basic concepts is truly astonishing.
In Rust, the fundamental piece of iterator functionality comes in the form of a trait:
pub trait Iterator {
type Item;
fn next(&mut self) -> Option<Self::Item>;
}
The full definition of this trait is extensive, spanning over 4,000 lines of code and documentation. However, the foundation of iterator functionality in Rust is built upon two key components:
- The type of the elements being iterated over.
- The
nextfunction, which fetches the next element if one is available.
The next function is crucial as it provides the data for a single iteration within the entire data source processing loop, facilitating sequential access to elements.
A key aspect of the iterator definition in Rust is its deliberate omission of a specific data source. While the structures implementing the Iterator trait often reference a data source or encapsulate an algorithm to generate new elements, decoupling the trait from these sources enhances its flexibility.
The implementation of an iterator, however, is closely tied to the nature of its data source. For continuous blocks of equally sized elements stored in memory, such as arrays or slices, the implementation may simply involve maintaining an offset for the current element and incrementing this offset when fetching the next element. In Rust, these implementations typically manifest as structs with members referencing specific data sources. They detail the exact locations within these sources and allow them to be fetched on request.
Implementing the next method often suffices, but in some instances, it may be beneficial to override other Iterator methods to achieve more efficient operations.
This approach enables the creation of iterators that can traverse a wide variety of data sources, including arrays, strings, sets, hash maps, and other data structures, as well as input streams, environment variables, regular expression matches, command-line arguments, and much more.
Once we have an iterator capable of traversing a collection of elements, it’s possible to adapt it for additional functionalities beyond its basic behavior, or to iterate in a different manner. In this context, “adapting” means we can create a new iterator based on the original one. The Iterator trait includes numerous methods designed for this purpose, such as:
map, which applies a specified function to every element.filter, which allows you to skip certain elements that you consider unnecessary.enumerate, which produces pairs consisting of an index (starting with 0) and an element.
These methods, among others, serve as iterator adapters, constructing new iterators rather than executing the specified behavior directly. They act as building blocks to define processing pipelines, providing a modular approach to data manipulation.
In addition to iterator adapters, the Iterator trait includes methods that directly initiate actions, such as:
for_each, which iterates through the elements, applying a provided closure to each one.count, which counts the elements until the iterator is exhausted.collect, which aggregates all the elements into a specified data structure in memory.
Let’s look at an example to illustrate the points mentioned above. Suppose we have a collection of books:
struct Book {
title: String,
author: String,
year: i32
}
fn collection() -> Vec<Book> {
vec![
// ...
]
}
We are interested in books from the twentieth century. Let’s count how many such books we actually have in our collection:
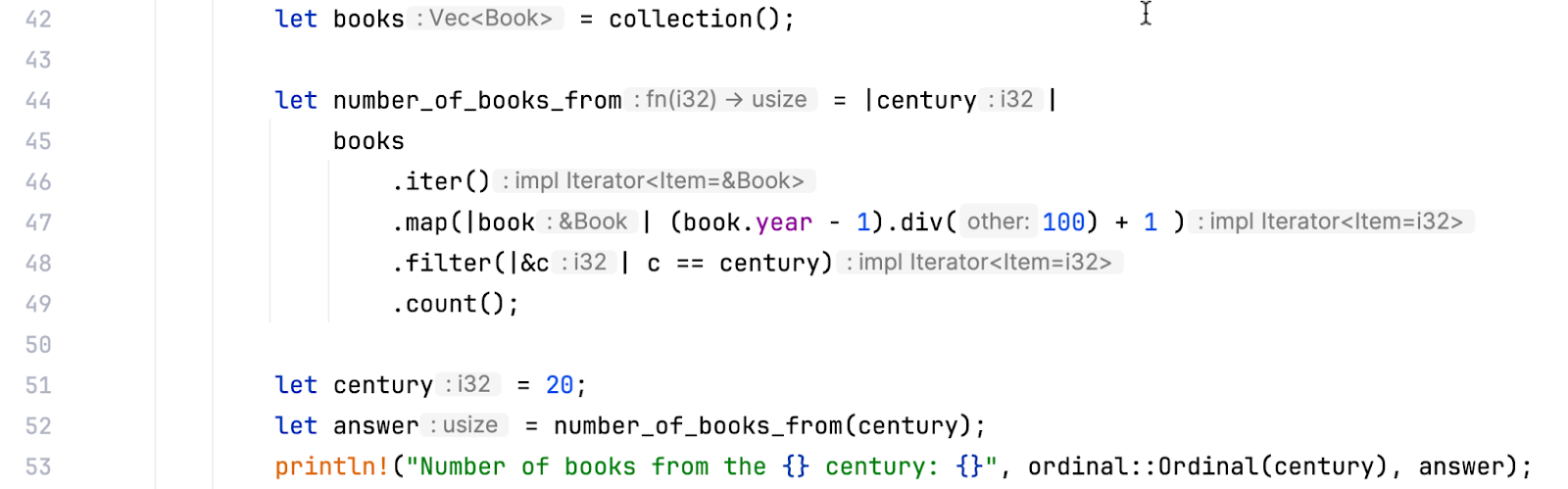
I’ve defined the number_of_books_from function using the closure syntax to count books from the given century and made it an iterator-based pipeline. Let’s dissect lines 46–49, comprising this pipeline. The iter function called on the books vector in line 46 provides an iterator structure closely linked to it. RustRover displays some information about the types, as illustrated in the screenshot below:

We see that the vector here is interpreted as a slice, and the iter function returns the Iter struct. However, RustRover shows impl Iterator<Item=&Book> in the inlay hint. This is an impl trait type, an iterator that iterates over &Book. It hides implementation details such as the particular iterator struct.
Continuing with the pipeline, in line 47, we use map to associate books with centuries, which is indicated by the impl Iterator<Item=i32> inlay hint. Although the exact type returned by map differs, this, once again, is an implementation detail:
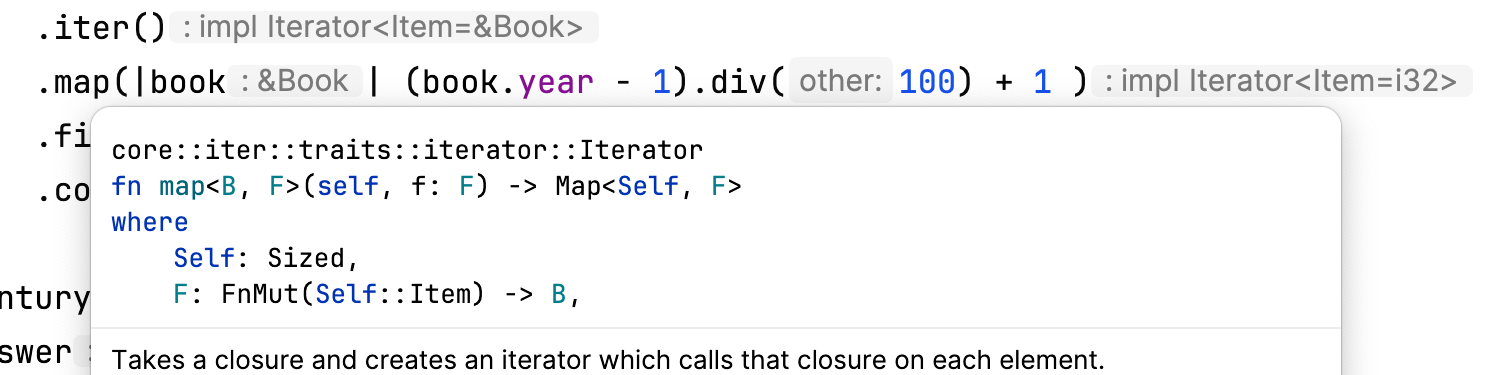
Then, we filter the centuries, retaining only books from the specified century. While filtering does not alter the displayed type of the iterator, it does change the underlying structure returned. If we assign the resulting iterator to a variable and then use RustRover to explicitly request its type (by pressing Alt+Enter on Windows or Linux, or ⌥⏎ on macOS), we receive an output similar to the following:

We discover that the exact type is quite intricate. It’s composed of Filter, Map, and Iter iterator structures along with their corresponding closure types. In fact, specifying such a type explicitly in code is not allowed; closure types are anonymous, and we cannot refer to them directly in Rust’s syntax. Nonetheless, realizing what lies beneath the simple impl Iterator<Item=i32> notation is crucial.
Ultimately, we proceed to count all elements that pass through the filter. This action of counting triggers the computation, yielding our desired result.
In this scenario, Rust’s generics enable iteration over elements of the user-defined Book type. Through uniformity, we efficiently iterate, map, and filter elements by leveraging pre-defined behaviors. But what about the declarative aspect? Does the code sequence – mapping, filtering, and then counting – imply multiple traversals over the book vector, as suggested by the code structure? Conducting a debugger session sheds light on these intricacies:
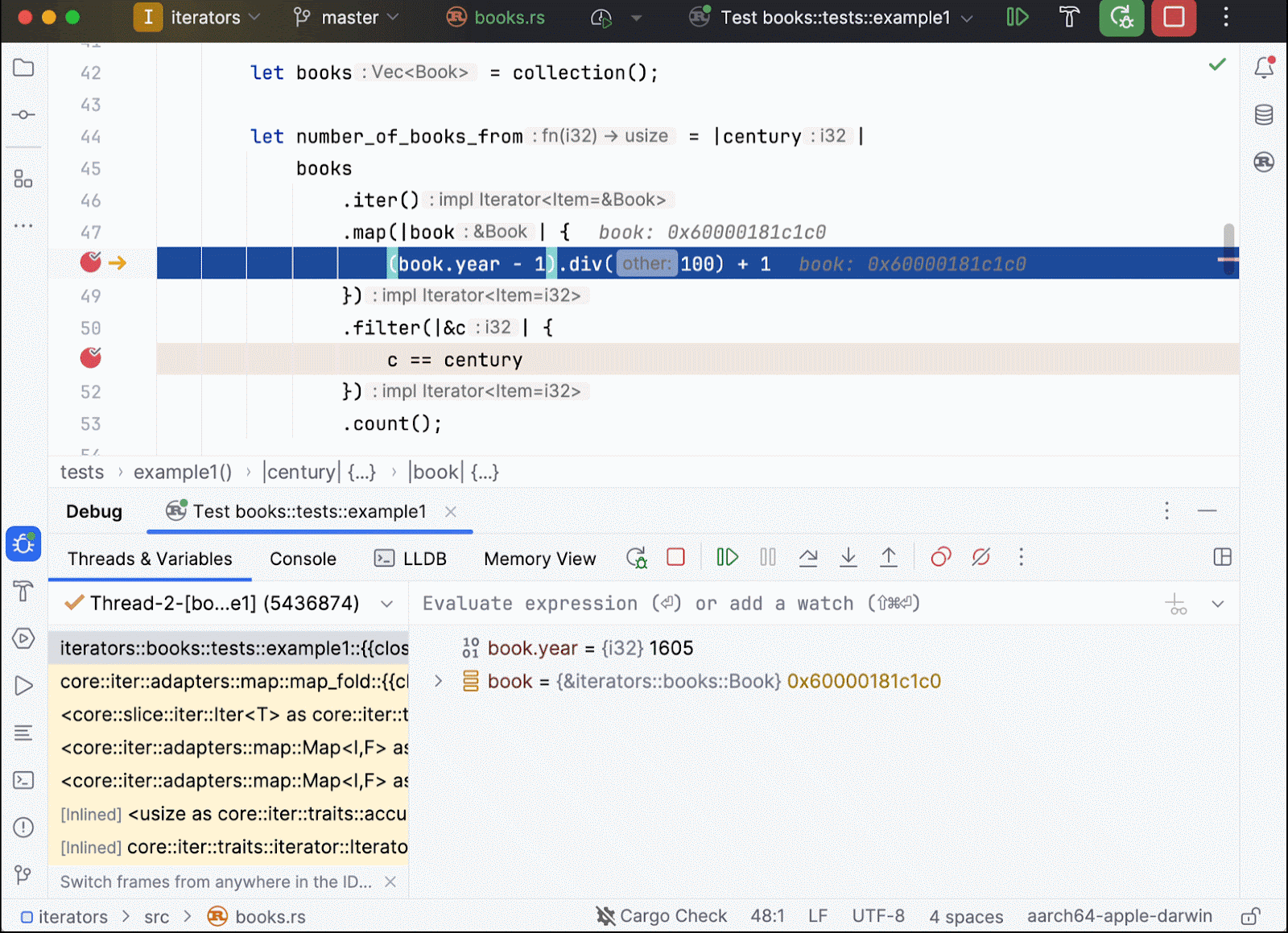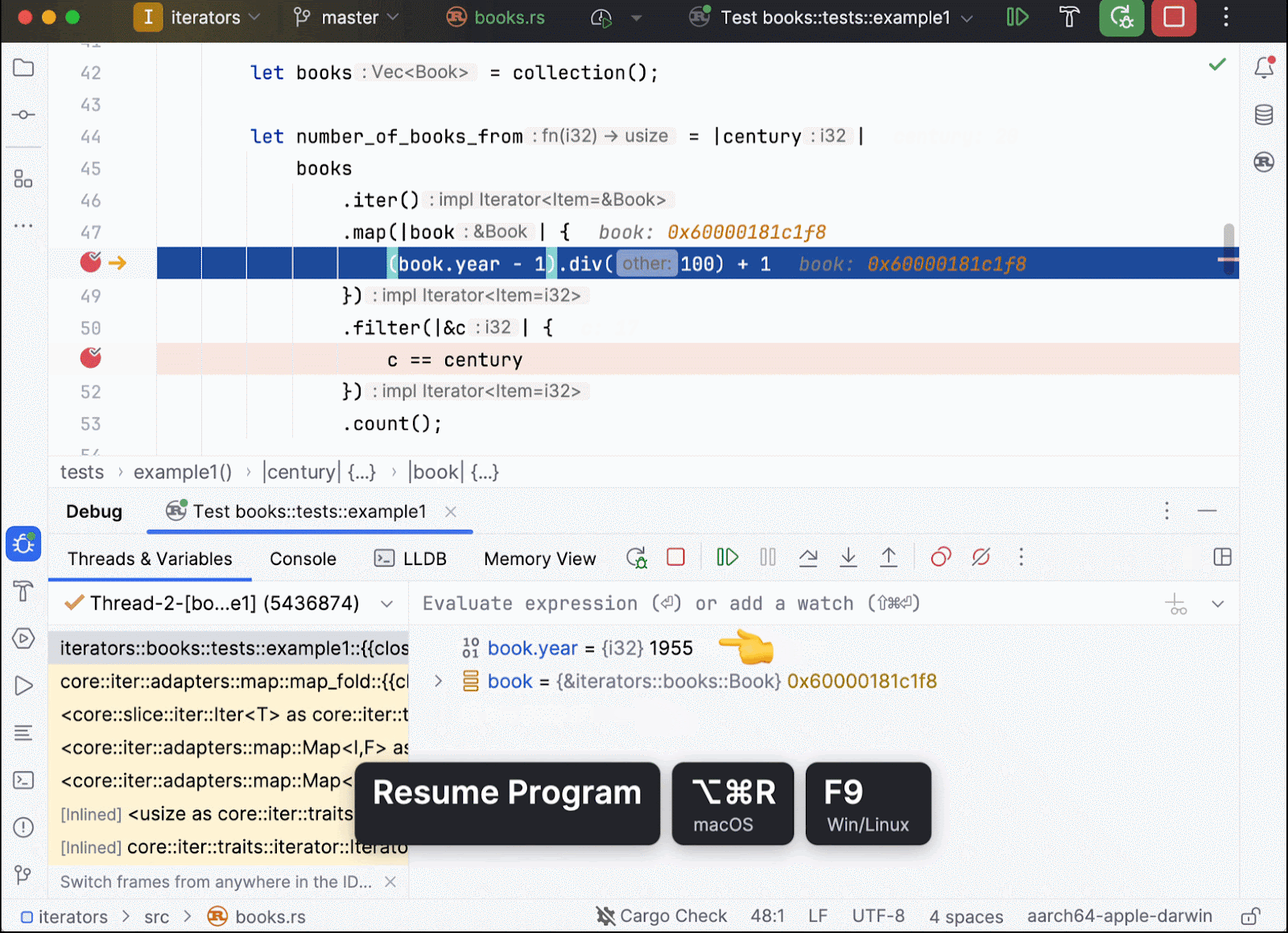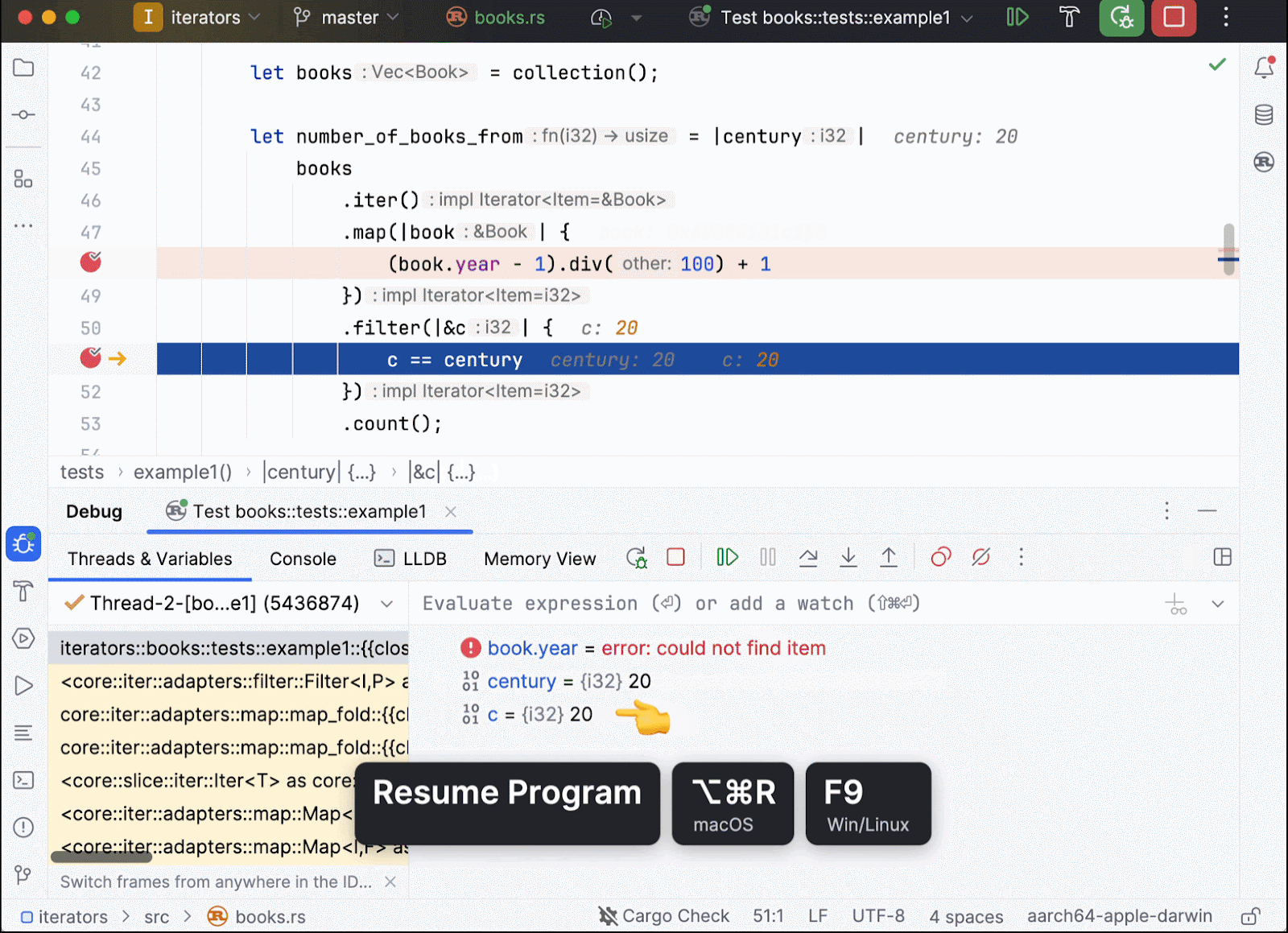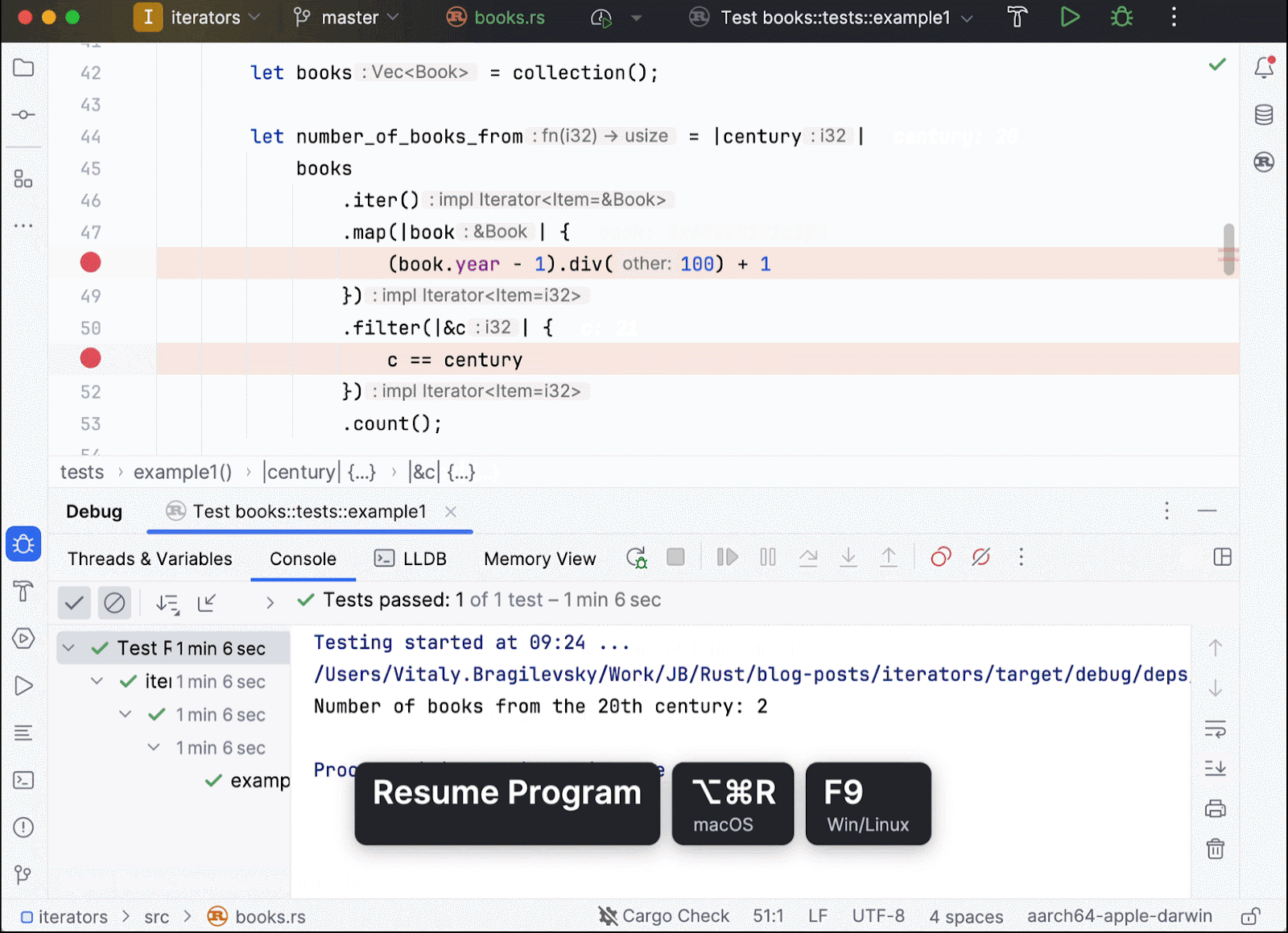
In this code example (which is the same one as above except that it has been refined for enhanced clarity), we place several breakpoints. Tracking the book.year and c values tells us that there is only a single traversal involved. Each book is received, mapped to its corresponding century, and then this century value is used to filter out unnecessary elements. This process can now be repeated for all of the remaining books.
For those questioning the efficiency of the counting process, I recommend substituting .count(); with the following code, which achieves the same result:
.fold(0, |acc, _| {
acc+1
});
Initiating a debugging session with this modification clearly shows that acc is incremented immediately after a book from the twentieth century is encountered, which aligns perfectly with our expectations.
The Iterator trait is not the only iterator trait provided by the Rust standard library. Others add new functionalities on top of it, including:
DoubleEndedIterator, which can iterate from the last element of a data source back to the first, enhancing backward traversal capabilities.ExactSizeIterator, which knows the exact number of elements, allowing for more precise control and optimizations.FusedIterator, which is guaranteed to return onlyNoneafter the firstNoneis returned by thenextmethod, ensuring more predictable behavior at the end of the iteration.
It’s crucial to recognize that extending iterator functionality is made possible by imposing additional requirements on data sources. For instance, the rev iterator adapter, which allows iterating over elements in the reverse order, operates exclusively on double-ended iterators. This means it can be applied to vectors but not to input streams or other structures that do not implement DoubleEndedIterator.
Iterator traits, adapters, and the structures they operate on enable the declarative processing of any data source in a generic and uniform manner. However, when leveraging the iterator machinery, it’s important to consider other factors to ensure that the code remains both readable and efficient.
Summary
Rust’s iterator system, featuring traits like Iterator, DoubleEndedIterator, ExactSizeIterator, and FusedIterator, offers a robust framework for data processing, allowing for flexible and efficient code patterns across various data structures. By abstracting complexities and emphasizing a declarative approach, it enables concise, readable, and reusable code. Iterator adapters further enhance this system, providing clear and optimized building blocks for data manipulation pipelines. However, leveraging these capabilities effectively requires an understanding of the specific requirements and capabilities of the underlying data sources. Ultimately, Rust’s iterators strike a balance between abstraction and performance, facilitating elegant solutions to complex programming challenges.
In the subsequent parts of this series, we’ll explore key aspects of writing code with iterators and examine some of the lesser-known functionalities they offer by looking at real-world examples.






