Rust Iterators Beyond the Basics, Part II – Key Aspects

Developers transitioning to Rust from other programming languages, such as Python, JavaScript, or even C++ or Java, often face challenges with iterators. Rust’s ownership rules, the intricacies of its type system, and its commitment to generating efficient code give Rust iterators a distinctive character. Let’s dig into the details to gain a deeper understanding.
This multipart series focuses on Rust iterators, covering both their implementation details and practical usage.
- Part I – Building Blocks: Iterator Traits, Structures, and Adapters
- Part II – Key Aspects: Memory Ownership, Structuring Code, Performance
- Part III – Tips & Tricks
Data sources and iterators: who owns the memory?
Iterators are derived from data sources. Depending on the data source, we can iterate over:
- References to elements of type
&T. - Mutable references to elements of type
&mut T. - The elements of type
Tthemselves by taking ownership.
For containers, we typically obtain the corresponding iterators using the iter, iter_mut, or into_iter methods, but there are often additional options. For instance, std::collections::HashMap offers a wide choice of iterators:
iter, to visit all the key-value pairs (with both the key and the value as references).iter_mut, to visit all the key-value pairs (with key as a reference and the value as a mutable reference).keys, to visit all the keys as references.valuesandvalues_mut, to visit all the values as references and mutable references, respectively.drain, to remove all elements from the hash map, with the ability to visit them as key-value pairs before they are dropped.
And there are even more options in the experimental phase.
Certain data sources may use other names, for example:
std::env::varsgives usimpl Iterator<Item=(String, String)>.std::io::BufRead::linesreturnsimpl Iterator<Item=Result<String>>.- The regex crate provides
find_iter,captures,captures_iter,split, andsplitnmethods, returning different kinds of iterators over values containing&str.
Unlike collections, these data sources don’t store their data, but generate it upon request. As a result, we cannot iterate over them more than once. If we need the received data elsewhere, we must either move it (after gaining ownership) or explicitly create our own copies (in the case of references). Failing to do so will result in an error from the lifetime checker. We can transition from references to owned values using the following iterator methods:
copied, to copy each element (available if the elements implement theCopytrait).cloned, to clone the elements (applicable when theClonetrait is implemented).
One of the most significant guarantees provided by the iterators in the Rust standard library is that they do not perform implicit heap allocations for each element processed in our pipeline.
Although iterators from the Rust standard library adhere to these guarantees, external data sources may not. For instance, std::io::BufRead::lines produces Result<String> as a stream element, indicating that there is a heap allocation at each iteration. Characters read from a stream are placed into a newly allocated String, allowing the string to be owned. To circumvent this behavior, we should use the std::io::BufRead::read_line function instead and supply our own String as a buffer to hold characters from the stream. Challenges like The One Billion Row Challenge exemplify how excessive, unnecessary allocations can significantly impact performance.
Say “No” to a lengthy chain of calls and deep nesting
The process of writing any code that utilizes iterators comprises the following stages:
- First, we construct an iterable by transitioning from a data source to an iterator, and then we refine it to make it suitable for subsequent stages.
- Second, we execute a processing pipeline by applying as many iterator adapters as necessary.
- Third, we either collect the resulting elements or consume the final iterator in some other manner.
Do we need to write all this code in a single block as a lengthy chain of calls? Not necessarily. Structuring code to enhance readability, thereby making it easier to comprehend and maintain, is crucial. Unfortunately, Rust can make this task slightly more challenging than expected.
Let’s work with the following example. As in the previous installment of this series, we have a collection of books. Now we want to print lists of books for every century represented in the collection. We also want to print book identifiers, which will be the books’ indices within the collection’s vector plus 1.
We need to compute centuries many times, so let’s add this functionality to the Book struct itself:
impl Book {
fn century(&self) -> i32 {
(self.year - 1).div(100) + 1
}
}
Here’s the code that solves our problem:
let books = collection();
books.iter()
.map(Book::century)
.collect::<BTreeSet<_>>()
.into_iter() // centuries in the ascending order:
.for_each(|century| {
println!("Books from the {} century:",
ordinal::Ordinal(century));
books
.iter()
.enumerate()
.filter_map(|(ix, b)|
if b.century() == century {
Some((ix+1, b)) // book's id is ix + 1
} else {
None
}
)
.for_each(|(id, book)| {
println!("#{id}: {book:?}")
});
});
We break this problem down into two main steps:
- Identify all the centuries represented in the collection. This initial step involves analyzing the collection to extract the unique centuries to which the books belong.
- Process each century individually:
– Enumerate the elements of the vector.
– Filter the books based on the century in question while simultaneously computing each book’s identifier (the book’s index in the enumeration plus 1).
– Print the details of each remaining book.
This structured approach allows for a clear separation of concerns: identifying the range of centuries involved and then focusing on the specific criterion (century) to process and display the books accordingly.
The readability of code involving nested iterator chains can be subjective. While some may find it clear, others may have reservations. The primary concern is the obscured visibility of the two nested iterator chains at first glance, which effectively conceals the actual logic and structure of the code behind the iterator adapters. Iterators are intended to clarify the operations being performed through descriptively named methods and processes. However, this clarity is compromised when the logic is deeply nested within multiple layers of iterators, making it harder to understand the flow and intention of the code. It’s important to remember that the use of iterators, although powerful, is not an end in itself. The goal should always be to write code that is efficient, maintainable, and understandable, rather than striving to use iterators for every possible scenario without considering the impact on your code’s readability and maintainability.
To improve our code, we can follow this streamlined plan:
- Introduce Book ID and Explicit Iterable: Create a function that returns an iterator of books with their IDs, providing a clear iterable construction.
- Collect Centuries: Gather all unique centuries from the collection.
- Iterate Over Centuries with For Loop: Use a for loop to iterate over centuries. This simplifies the code by avoiding iterator chain nesting.
- Filter and Print Books: Within the loop, use a concise iterator chain to filter and print books for each century.
This plan aims to improve code readability and maintain the use of iterators for efficiency.
Step 1: Introduce Book ID and Explicit Iterable
struct BookId(usize);
fn books_with_ids<'a>(books_iter: impl Iterator<Item=&'a Book>) ->
impl Iterator<Item=(BookId, &'a Book)> {
books_iter
.enumerate()
.map(|(ix, b)| (BookId(ix+1), b)) // book's id is ix + 1
}
This function processes an iterator over &Book and yields an iterator over pairs of BookId and &Book. To encapsulate part of our pipeline into a function, we utilize the impl trait type for both the argument and return type. We need to specify the lifetime explicitly due to the use of references, as we must ensure that the returned books remain valid as long as they are in the provided iterator.
Step 2: Collect Centuries
let centuries: BTreeSet<_> = books.iter() .map(Book::century) .collect();
These lines are highly readable. Assigning their result to a variable with an explicit type makes it easier to mentally picture a set containing all centuries represented in the collection, a task that was more challenging with the prior implementation. I favor specifying explicit types rather than employing the turbofish (::<_>) syntax, as I find code written this way to be more accessible.
Steps 3 and 4: Iterate Over Centuries with For Loop, Filter and Print Books
for century in centuries {
println!("Books from the {} century:", ordinal::Ordinal(century));
books_with_ids(books.iter())
.filter(|(_, b)| b.century() == century)
.for_each(|(BookId(id), book)| {
println!("#{id}: {book:?}")
});
}
These steps are also very straightforward.
The use of the impl Iterator type in implementing a function that returns an iterator serves to obscure that iterator’s specific structure. However, its application is confined to function arguments and results. What happens when we want to retain an intermediate iterator structure as a field, possibly to construct an iterator pipeline based on provided input? This challenge will be the focus of exploration in the next section.
Iterators as variables and struct members
Let’s start with a small experiment. Suppose we have a collection of numbers. Sometimes we need to filter this collection to retain only the even numbers, and at other times, we do not apply any filter. Let’s explore how to tackle this problem using iterators:
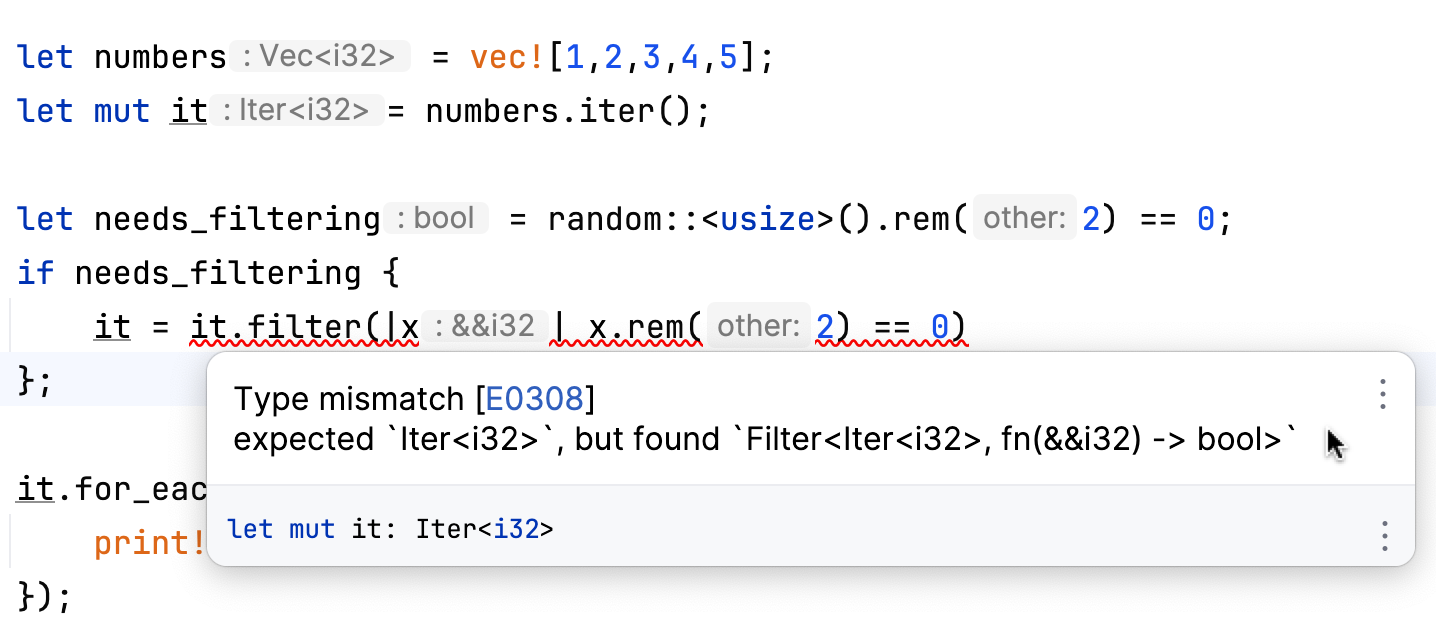
The challenge lies in devising a type that can accommodate both the original iterator and the filtered one. The limitation here is that we cannot use impl Iterator for variable types. The reason is that impl Trait specifies a particular type that implements the trait, and this type must be known at compile time. However, in the scenario described, the type remains undetermined until runtime, when a random number is generated. To address this issue, we turn to trait objects.
To approach the broader problem of combining filters with maps as needed, we aim to construct an iterator pipeline capable of integrating any number of mappings or filters, with the specific operations to be determined at runtime. Furthermore, our goal is to maintain as much generality as possible in this solution.
Our pipeline encapsulates a heap-allocated Iterator trait object:
struct PipelineBuilder<'a, T> {
iter: Box<dyn Iterator<Item = T> + 'a>
}
To manage the scenario where the size of an iterator is unknown in advance and varies based on runtime input, we must utilize Box. Box allows us to allocate heap memory for an iterator, thus overcoming the limitation of needing to know its size at compile time. Additionally, controlling lifetimes is crucial in this context to ensure that the data the iterator references remains valid for its intended use. Using Box<dyn Iterator<Item=T> + 'a> enables both dynamic dispatch to the appropriate iterator methods and the explicit management of lifetimes, ensuring the iterator and its references are valid throughout their usage.
The pipeline is initially constructed using an iterator provided in the parameters of the new function:
impl<'a, T: 'a> PipelineBuilder<'a, T> {
fn new(iter: impl Iterator<Item = T> + 'a) -> Self {
Self {
iter: Box::new(iter)
}
}
}
By explicitly requiring the same lifetimes for both elements and iterators, we create a versatile solution that accommodates iterating over both owned elements and references.
Now we can construct pipelines from different sources. For example, we can start with lines from a file:
let file = File::open("Cargo.toml").unwrap();
let lines = BufReader::new(file).lines().map(Result::unwrap);
let pipeline= PipelineBuilder::new(lines);
Or with an iterator built from a range of integer numbers:
let mut pipeline = PipelineBuilder::new((1..10).into_iter());
Adding filters or maps requires changing the value of the PipelineBuilder::iter struct member. To avoid ownership issues, we’ll return a new builder each time we add a filter or map.
impl<'a, T: 'a> PipelineBuilder<'a, T> {
fn with_filter(self, cond: impl FnMut(&T) -> bool + 'a) -> Self {
Self {
iter: Box::new(self.iter.filter(cond))
}
}
fn with_map<S>(self, f: impl FnMut(T) -> S + 'a) -> PipelineBuilder<'a, S> {
PipelineBuilder {
iter: Box::new(self.iter.map(f))
}
}
}
The with_filter and with_map methods both return a new pipeline builder, incorporating the previous iter before the newly added one. This approach allows us to add a new processing stage whenever necessary. Since the with_map method can change the type of elements within the pipeline, we must explicitly refer to the type name; it is no longer Self.
Now we can easily manipulate the pipeline. For example, with lines from a file:
let pipeline = if random::<usize>().rem(2) == 0 {
pipeline.with_filter(|s| s.len() > 5 )
} else {
pipeline.with_map(|s| format!("{s}!"))
}.with_map(|s| s.len());
Depending on the random value obtained at runtime, our pipeline will either incorporate a filter and a map or two consecutive maps. Thanks to the last map applied here, the original PipelineBuilder<String> is transformed into PipelineBuilder<usize>.
To complete this implementation, we need to address how to consume iterators from a pipeline. Let’s proceed by implementing the convenient for_each method:
impl<'a, T: 'a> PipelineBuilder<'a, T> {
fn for_each(self, f: impl FnMut(T) -> () + 'a) {
self.iter.for_each(f)
}
}
The for_each method does not return anything. Since it takes ownership of self, the pipeline builder will be dropped after the method is called. This method can be used in the following manner:
pipeline.for_each(|s| {
print!("{s} ")
});
Returning to the second example of a pipeline builder (the one using integer numbers from a range), our PipelineBuilder allows us to manipulate the data with completely unpredictable results:
let cnt = random::<usize>().rem(10);
for i in 0..cnt {
pipeline = pipeline.with_map(move |x| x + i)
}
pipeline
.with_filter(|x| x.rem(2) == 0)
.for_each(|x| print!("{x} "));
Well, at least we know that something will be printed.
Impl traits or trait objects
It is essential to understand the difference between impl traits, which are used to break up long chains of calls by extracting stages into functions, and dyn trait objects, employed to store iterators as struct members. Trait objects enable method dispatch to be deferred to runtime, allowing the use of iterators whose types are unknown at compile time. While impl trait types are useful for concealing complex iterator types, they require the type to be known at compile time. For instance, it’s not allowed to use impl Iterator as a return type for a function that might return either filter or map iterators based on its input, due to their differing types. In such scenarios, dyn trait objects are necessary to accommodate the variability in return types. This approach provides the flexibility needed for dynamic iterator manipulation, ensuring compatibility with a wide range of runtime conditions.
Down to bare metal
There’s a prevalent belief that using iterators is slower than using explicit loops. However, finding evidence to support this claim is challenging. If you avoid using collect midway through iterator pipelines, the Rust compiler ensures that there’s no significant difference in the optimized code generated compared to an explicit loop implementation. This demonstrates the efficiency of Rust’s iterator design and the compiler’s ability to optimize iterator-based code to match the performance of traditional loop constructs.
Here I have a couple of functions that do the same thing:
#[no_mangle]
fn add_even_sum(numbers: &Vec<i32>, a: i32) -> i32 {
numbers.iter()
.map(|x| x + a)
.filter(|&x| x > 2)
.sum()
}
#[no_mangle]
fn add_even_sum_loop(numbers: &Vec<i32>, a: i32) -> i32 {
let mut sum = 0;
for x in numbers {
let x = x + a;
if x > 2 {
sum += x
}
}
sum
}
The iterator approach is more concise, cleaner, and easier to comprehend. Additionally, comparisons of the generated code reveal no indications of inefficiency.
For those interested in diving deeper into comparing assembly codes, it’s advisable to start with the basics. When it comes to iterators and their performance, the recommended steps are as follows:
- Write Iterative Code Focusing on Readability: Initially, focus on writing readable code using iterators, acknowledging that in some cases, explicit loops might be more appropriate.
- Benchmark and Monitor Performance: Use benchmarks or monitor performance and memory usage metrics to understand how your code performs in practice.
- Profile If Necessary: If performance issues are detected, profile the code to pinpoint the problem. Ensure that the issue indeed stems from the use of iterators.
- Revisit Reduce/Fold Structures: If you identify performance bottlenecks related to iterators, examine the structures used in
reduce/foldoperations. Large structures passed between iterations could be the culprit. In such cases, opting for mutable structures to maintain an intermediate state could be beneficial. - Report Issues to the Rust Compiler: If all else fails, consider submitting an issue to the Rust compiler or libraries team for further assistance.
It’s important to note that “rewriting your code with explicit loops” is not listed as a step here. Performance alone should not dictate a move away from iterators. However, it’s worth acknowledging that some data sources may inherently provide less efficient iterators. In such instances, the options are to either attempt to create more efficient iterators yourself or resort to implementations that do not rely on them.
Summary
Rust’s iterator paradigm may be considered challenging due to its unique approach to ownership, type systems, and efficiency. Iterators in Rust can iterate over references, mutable references, or owned values, with the standard library offering various iterator methods to handle collections and other data sources efficiently. Rust prioritizes avoiding implicit heap allocations in iterators, prompting the use of crates like itertools for more complex operations. However, when iterator chains become long or deeply nested, readability may suffer, suggesting a need for refactoring through function extraction or type introduction. Despite concerns about performance, Rust’s efficient compiler optimizations generally ensure that well-structured iterator-based code is as performant as traditional loop constructs, emphasizing code readability and maintainability over premature optimization.
In the last part of this series, we will explore several important scenarios involving the use of lesser-known Rust iterator features in practice.