Rust Iterators Beyond the Basics, Part III – Tips & Tricks

In this third and final part of the Rust Iterators series, we’ll learn by example. We’ll explore some useful yet lesser-known iterator features, along with their applications in various popular open-source projects developed in Rust.
This multipart series focuses on Rust iterators, covering both their implementation details and practical usage.
- Part I – Building Blocks: Iterator Traits, Structures, and Adapters
- Part II – Key Aspects: Memory Ownership, Structuring Code, Performance
- Part III – Tips & Tricks
Getting iterators from data sources
Tip #1 is to always verify that your data sources can offer data access through iterators.
For our first example, let’s consider regular expressions. As mentioned in the first part of this series, regular expressions can deliver search results in the form of an iterator. The Regex::find_iter method is particularly useful when you need to search through a large string, are looking for multiple occurrences, and prefer not to load all results into memory simultaneously. For example, this is how it is used in Bloop, a code search engine:
let data = target
.find_iter(&doc.content)
.map(|m| TextRange::from_byte_range(m.range(), &doc.line_end_indices))
.filter(|range| hoverable_ranges.iter().any(|r| r.contains(range)))
...
In this scenario, we have a regular expression, target, that we use to search through a document’s content, aiming to find and process all occurrences one by one. The iterator created by find_iter produces Match structs, which hold details about each match, including the start and end indices within the original string. In our example, these indices are used to highlight certain occurrences as we iterate through the matches.
For another example, let’s examine the Bevy project. Bevy employs the ECS (entity, component, system) pattern, where systems are tasked with processing components. To orchestrate the execution of various systems, Bevy’s ECS leverages schedules. These schedules are devised using graphs, supported by the petgraph crate. Graphs, being intricate data structures, offer access to their internal data through several iterators. In the code snippet below, we access the nodes of a graph in reverse order. For each node, we then explore its neighbors by traversing the outgoing edges:
for a in topsorted.nodes().rev() {
let index_a = *map.get(&a).unwrap();
// iterate their successors in topological order
for b in topsorted.neighbors_directed(a, Outgoing) {
...
Both the nodes and neighbors_directed methods return iterators. It’s worth noting that Bevy developers do not try to consolidate all their code into iterator pipelines. The decision to use explicit loops instead can be easily justified by the complexity involved in each iteration and the potential for deep nesting.
Complex data structures, such as graphs, often offer multiple iterators for accessing their data. Taking the time to explore these interfaces and identify the iterators available can be incredibly beneficial for writing idiomatic Rust code.
In general, many data sources feature an iterator interface. Once you’ve obtained an iterator, you can leverage the full suite of iterator tools to process your data efficiently.
Constructing iterators: successors and from_fn
Sometimes, data sources may not offer an iterator interface directly, instead providing a function to retrieve the next element or a means to construct an iterator. Additionally, in cases where there’s no pre-existing data and it must be generated by an algorithm, iterators can still be employed.
The std::iter::successors function presents a prime solution for these scenarios. This function accepts an initial element along with a function that returns an Option containing either the next element or None. An iterator that is created this way can be used in the usual manner. Ruff, the Python linter and formatter known for its exceptional speed, demonstrates the use of this function as follows:
std::iter::successors( Some(AnyNodeRef::from(preceding)), AnyNodeRef::last_child_in_body, ) .take_while(|last_child|...) .any(|last_child| ...)
In this scenario, we determine whether a particular preceding code element requires empty lines before or after it. All these elements are part of a tree structure, and we utilize a function that identifies the last child in the last branch of a subtree. By employing successors, we create a data stream consisting of all such last children and iterate over them in the standard manner.
The std::iter::successors function requires an initial seed to begin. It also relies on the preceding element to generate the next one. At times, the pattern for generating these elements isn’t straightforward, especially when we need to maintain some state to derive subsequent elements. The std::iter::from_fn function is specifically designed for such situations.
In the example below, taken from the Meilisearch project, the std::iter::from_fn function is employed to generate an infinite sequence of random numbers. This sequence is constructed using a random number generator:
let mut rng = rand::rngs::SmallRng::from_seed([0; 32]);
for key in std::iter::from_fn(|| Some(rng.gen_range(0..256))).take(128) {
...
}
The from_fn function offers the flexibility to perform whatever operations are necessary to construct the next element. In this example from the InfluxDb project, a function passed as an argument to from_fn incorporates a loop. This loop reads from a buffer, decodes the data, and returns the next element once it’s ready:
fn decode_entries<R: BufRead>(mut r: R) -> Result<Vec<ListEntry>> {
let mut decoder = ListDecoder::default();
let iter = std::iter::from_fn(move || {
loop {
let buf = r.fill_buf().unwrap();
// ...
}
decoder.flush().transpose()
});
iter.collect()
}
It’s worth noting that it’s common practice to move mutable variables captured by a closure into the from_fn function. This closure is invoked each time an iterator requests the next element. It alters the state with every call, necessitating ownership of that state.
Combining data streams: chain, zip, once, and repeat
Once you’ve obtained an iterator, it’s not always immediately ready for element processing. You might need to prepend or append some elements to facilitate your algorithms, merge several data streams for uniform processing, or enrich every element with additional information from another source.
In such scenarios, two iterator features prove invaluable: chain and zip. The std::iter::Iterator::chain method concatenates two iterators, creating a single iterator that yields elements from the first until it’s exhausted, followed by elements from the second. The std::iter::Iterator::zip method pairs elements from two iterators, forming an iterator of tuples.
Additionally, the functions once and repeat are designed to generate iterators that return a single specified element or an infinite sequence of a repeated element, respectively. Their counterparts, once_with and repeat_with, dynamically create elements upon request. These functions are particularly beneficial when used in conjunction with other iterators through the chain or zip adapters. To illustrate, let’s examine how the redis-rs crate employs this strategy to manage access between a primary node and its replicas:
std::iter::once(&self.primary).chain(self.replicas.iter())
As a result, this approach yields an iterator that seamlessly iterates over the primary node and all its replicas without distinction.
Moving on to Deno, a JavaScript runtime, we find a yet another illustrative example:
self
.open_docs
.values()
.chain(file_system_docs.docs.values())
.filter_map(|doc| { ...
We have documents that are open and others that are stored in the file system, requiring uniform processing.
As for using zip, let’s examine Deno’s approach to encrypting 16-byte chunks of input into matching output chunks:
for (input, output) in input.chunks(16).zip(output.chunks_mut(16)) {
encryptor.encrypt_block_b2b_mut(input.into(), output.into());
}
Immutable chunks of input are zipped with the corresponding mutable chunks of output, so that encryptor always knows where to put the encrypted data.
Clippy, the Rust linter, uses zip with repeat_with to come up with elements enumerated in descending order:
let mut i = end_search_start;
let end_begin_eq = block.stmts[block.stmts.len() - end_search_start..]
.iter()
.zip(iter::repeat_with(move || {
let x = i;
i -= 1;
x
}))
Note that the repeat_with closure is executed multiple times, producing a new element each time.
There’s another variant of zip: the std::iter::zip function. It accepts two arguments that implement the IntoIterator trait, converts them into iterators, and then zips them together. For instance, in Ruff, this function is used to zip elements of a vector and a slice without having to reference the corresponding iterators initially:
std::iter::zip(&tuple.elts, args)
The zip adapter has its iterator-consuming counterpart, the Iterator::unzip method, which operates on iterators over pairs, simultaneously collecting their first and second components into two separate containers. This traditional use case is found in the implementation of Tauri, an application framework for multi-platform deployment:
let (paths, attrs): (Vec<Path>, Vec<Vec<Attribute>>) = command_defs
.into_iter()
.map(|def| (def.path, def.attrs))
.unzip();
We have a vector of structs, each with two members, and aim to split it into separate vectors. Combining a pair-building map with unzip accomplishes this task.
Processing parts of a data stream differently: by_ref
In many cases, our code follows a linear progression: we obtain or create an iterator, apply several processing steps, and finally consume it. However, situations arise where this linear approach doesn’t suffice, particularly when we wish to handle different sections of a data stream in varied ways. For instance, processing the initial group of elements distinctively necessitates specific actions:
- Binding an iterator to a local variable or storing it within a struct’s member.
- Ensuring we do not transfer ownership of an iterator when processing the initial group of elements.
While the first action is relatively straightforward (though it may require making the variable mutable, especially if you’re explicitly invoking next()), the second involves more nuanced knowledge of how to use the by_ref adapter.
Consider the following code fragment:
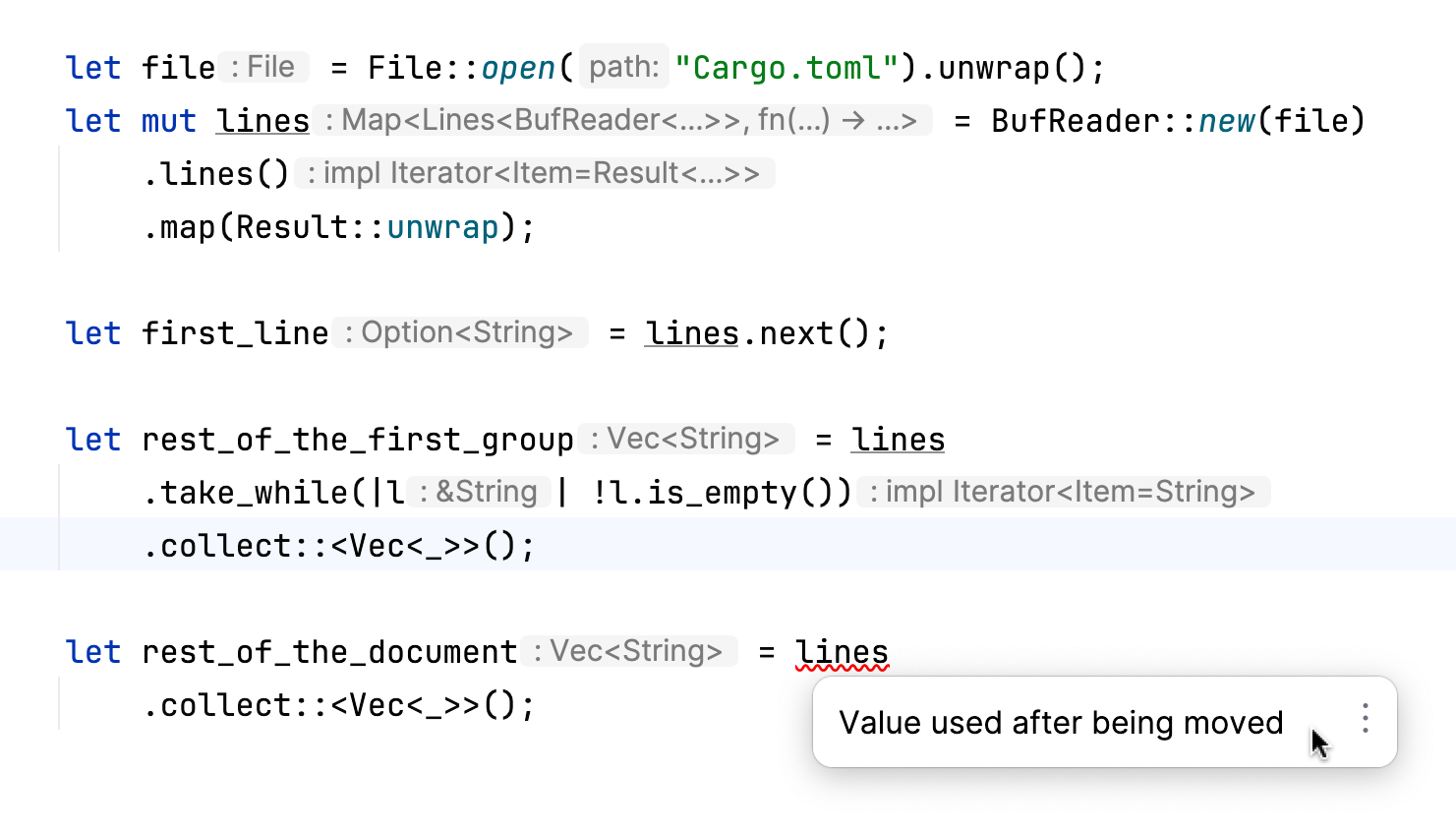
We open a file and prepare an iterator for all its lines. We read the first line – this action necessitates that the lines variable is mutable. We continue to read lines until we encounter an empty one, and then we proceed to read the rest. The complication arises with the take_while adapter, which assumes ownership of the lines iterator and precludes us from using it further. To deal with this, we must provide a mutable reference to this iterator when it’s first used with an iterator adapter, as follows:
let rest_of_the_first_group = lines .by_ref() .take_while(|l| !l.is_empty()) .collect::<Vec<_>>();
Note the invocation of the by_ref method here: its primary function is to pass the mutable reference onwards, as evidenced by its implementation:
fn by_ref(&mut self) -> &mut Self
where
Self: Sized,
{
self
}
Here’s the simplified example from Ruff’s source code:
let mut lines = ...
for line in lines.by_ref() {
if ... {
...
break;
}
}
for line in lines {
if ... {
...
break;
}
}
We start with the first group of elements, followed by the remainder. The by_ref method enables us to retain ownership of the lines iterator.
Debugging iterator pipelines
Let’s look at the following code:
let chars = vec!['A', 'B', 'C', 'D', 'E'];
let mut ix = 0;
chars
.iter()
.map(|&ch| {
ix += 1;
(ix, ch)
})
.rev()
.for_each(|x| println!("PRINT: {x:?}"));
Predicting the output in this scenario requires understanding the interplay between side effects in mapping and the use of the rev adapter in iterator pipelines. The key point here is to warn you against mixing mapping operations that involve side effects – such as reading from and mutating a variable – with the rev adapter. The output remains the same regardless of the order in which rev and map are mentioned in the iterator pipeline, illustrating the complexity and potential for unexpected results when combining these operations:
PRINT: (1, 'E') PRINT: (2, 'D') PRINT: (3, 'C') PRINT: (4, 'B') PRINT: (5, 'A')
The underlying cause is the inherent laziness of iterators. The closure within map is executed immediately prior to the action of printing in for_each. By this stage, all elements are already presented in reverse order. Consequently, the last element of the original vector is assigned the initial value of ix.
A debugging session would quickly uncover this behavior:
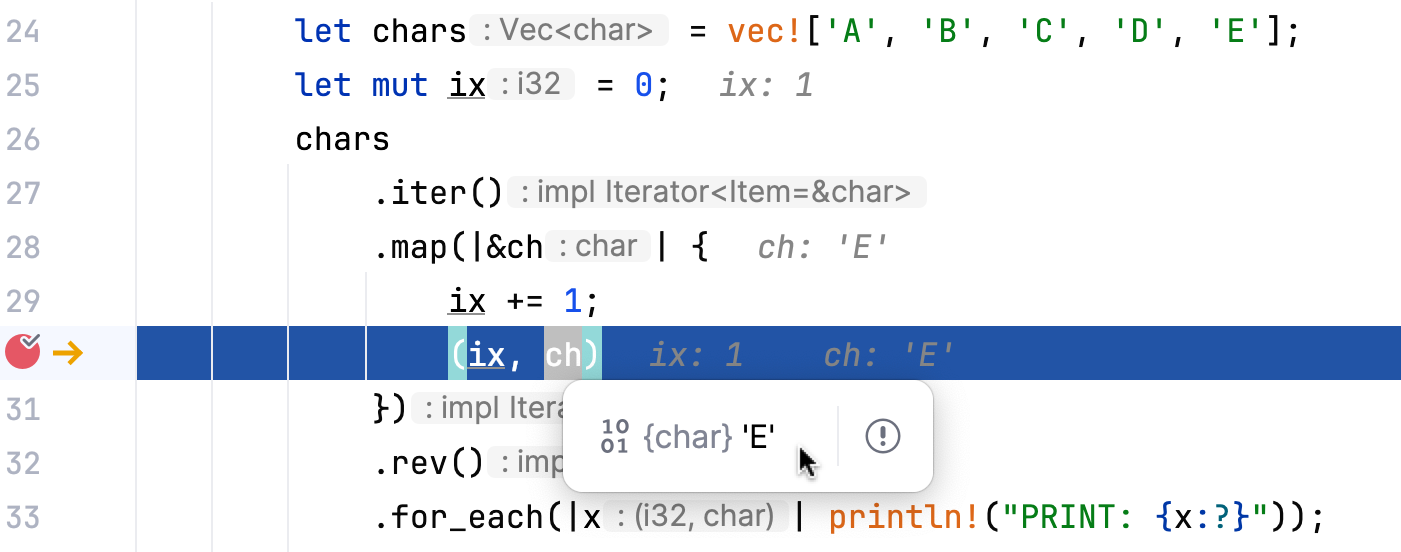
If you prefer to analyze program output, the inspect iterator adapter serves as another valuable tool in this context.
chars
.iter()
.inspect(|ch| println!("INSPECT: {ch}"))
.map(|&ch| {
ix += 1;
(ix, ch)
})
.rev()
.for_each(|x| println!("PRINT: {x:?}"));
This code results in the following output:
INSPECT: E PRINT: (1, 'E') INSPECT: D PRINT: (2, 'D') ...
Placing multiple inspect calls between other iterator adapters can be beneficial for tracking the processing pipeline and gaining a correct understanding of the sequence of operations. In more complex scenarios, dividing pipelines into separate functions, as mentioned in the previous part, can also aid in comprehension and management.
Summary
This last part of the series has explored scenarios of using lesser-known features of Rust iterators. Through examples from real-world projects like Ruff, Deno, Bevy, Clippy, redis-rs, Tauri, Meilisearch, and Bloop, we’ve seen how iterators facilitate operations such as constructing iterables, chaining, zipping, and transforming data. We highlighted techniques for handling iterators, including the use of the by_ref method to retain ownership and avoid consuming iterators prematurely. Additionally, we discussed the importance of understanding iterator laziness and the placement of inspect calls for debugging and analysis. In all the examples, RustRover’s code analysis and debugger helped us understand code and quickly solve whatever issues arose. Overall, these tips and tricks enable writing idiomatic and efficient Rust code for a variety of applications.