

TeamCity
Powerful CI/CD for DevOps-centric teams
Testing AI Coding Agents With TeamCity and SWE-bench

Introduction
AI coding agents are no longer research experiments. They are quickly becoming practical tools that can help developers solve real problems.
But how do you know whether an agent is good enough for serious use? How do you measure progress when its answers are not always predictable and when there may be various correct solutions to the same task?
This is where systematic testing comes in. At JetBrains, we needed a way to test our own coding agent, Junie, on real-world development tasks. To achieve this, we built an evaluation pipeline powered by TeamCity and SWE-bench, a popular benchmark that provides real bugs and fixes from open-source projects.

In this post, I will walk you through how it works, the challenges we faced, and the solutions we found.
Prerequisites
In our GitHub project, you can find a repository that contains the TeamCity Kotlin DSL and describes every component you need. You can plug it into your own TeamCity and run the full pipeline, just as I’ll demonstrate in this blog post.
? Check out and fork the project ?
Why this matters
Testing AI coding agents is not like testing ordinary software. With regular programs, you can rely on unit and integration tests. With agents, things are different. Their output can vary from run to run, and there are often multiple valid ways to solve the same problem. This makes traditional testing methods ineffective.
To use coding agents effectively, you must answer a few critical questions: Are the results correct? Are they consistent over time? What does each run cost in compute and API usage?
At JetBrains, Junie’s team tracks metrics such as solved-task percentage, cost per run, common failure types, and performance across versions. This data provides clear evidence of progress and ensures that development decisions are based on facts rather than impressions.
?Read also: How Junie Uses TeamCity to Evaluate Coding Agents
SWE-bench: Your benchmark toolkit
Benchmarks give us a consistent way to test agents. SWE-bench is one of the most widely used because it is based on real issues from real projects. For every task, we know:
- The exact project and commit where the problem appeared.
- The correct fix.
- Tests that prove both the bug and the solution.
The evaluation method is straightforward: Provide the agent with the project and task, let it propose a fix, run the tests, and see if they pass. SWE-bench also provides Python tooling to prepare Docker images with the correct dependencies and environments, as well as scripts to evaluate solutions.
In our project, we used SWE-bench Lite, a smaller variant of the full benchmark. The pipeline is flexible, so you can adapt it to any benchmark you prefer.
Building stable, reusable pipelines
One of the biggest challenges is ensuring that every run happens in a stable, identical environment. Without this, it is impossible to know whether a failure was due to the agent or some minor setup difference.
Why stability matters
To reproduce each task, we must download the code, install dependencies, and prepare the environment. Any external hiccup, like a slow package server or rate limits on Hugging Face (which hosts the datasets), can cause tasks to fail incorrectly.
The Hugging Face bottleneck
If every TeamCity agent downloads datasets directly from Hugging Face, the requests quickly hit limits. This results in HTTP 429 errors and failed runs – not because the agent was wrong, but because the dataset could not be retrieved.
The solution: Caching with artifacts
To fix this, we created a dedicated TeamCity job that downloads the dataset and tooling once, packages them into ZIP archives, and publishes them as artifacts. All other build configurations use these cached artifacts instead of contacting Hugging Face.
The dataset download build type uses a Python script to cache the SWE-bench Lite dataset:
# Download the dataset with caching
dataset = load_dataset(
"princeton-nlp/SWE-bench_Lite",
cache_dir=cache_dir,
split="test"
)
Source: scripts/download_dataset.py
The build configuration packages the cache as artifacts:
artifactRules = """
dataset_cache/** => dataset_cache.zip
.venv => venv.zip
""".trimIndent()
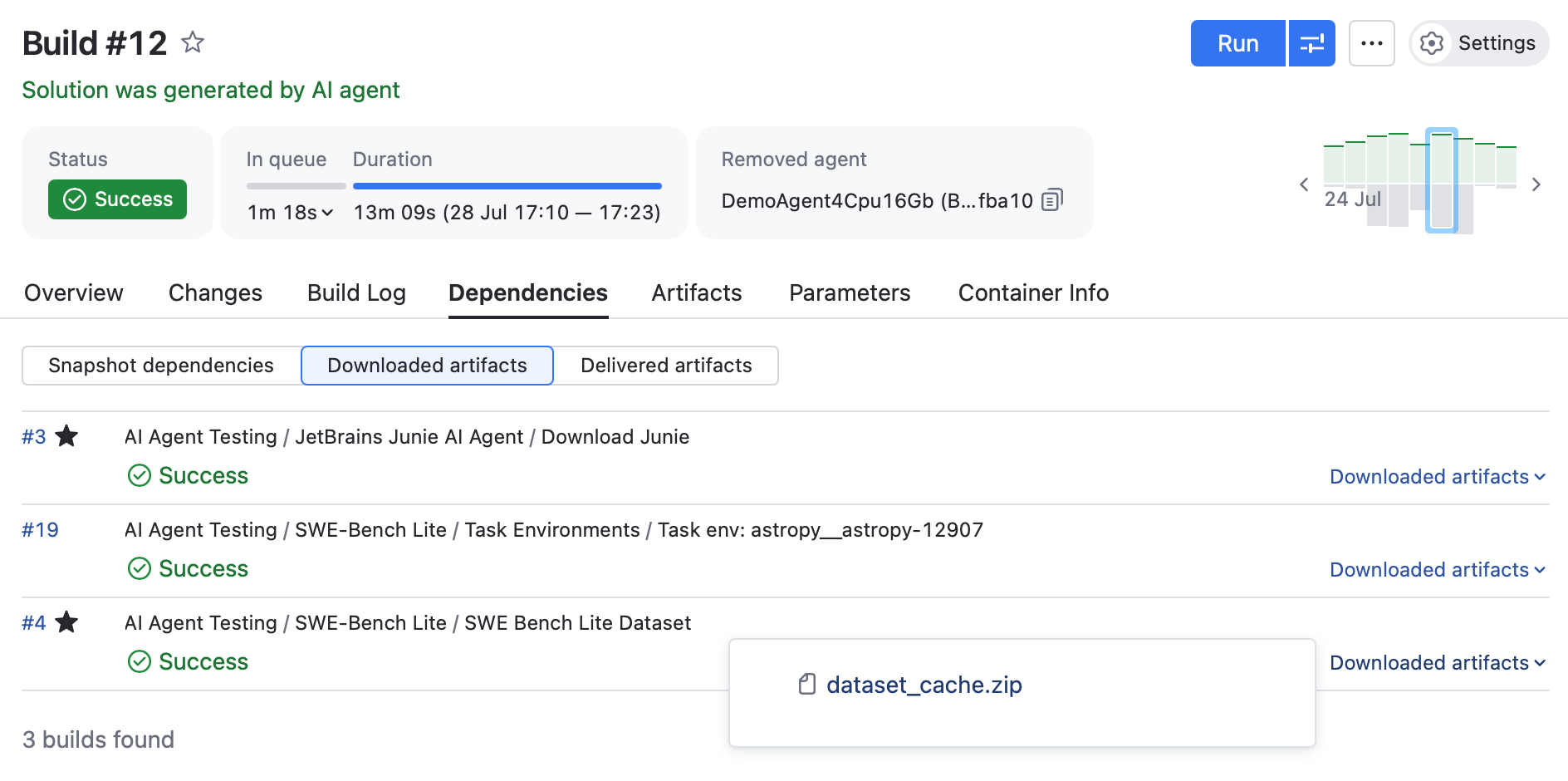
The benefits include:
- No more rate limits.
- Faster builds with less wasted time.
- More reliable runs.
- Consistent datasets across all tests.
Docker image caching
We extended this same caching approach to Docker images. Each task gets its own image with the project source code, Python version, dependencies, and test environment. These images are cached and reused. When new tasks are added, only their images are rebuilt.
python {
name = "Build Docker image for $taskId"
command = module {
module = "swebench.harness.prepare_images"
scriptArguments = "--instance_ids $taskId --tag $instanceImageOrigTag"
}
}
dockerCommand {
name = "Save Docker Image for $taskId"
commandType = other {
subCommand = "save"
commandArgs = "-o $taskId.tar $instanceImageOrig"
}
}
Source: SWE_Bench_lite_TaskEnv.kt
This ensures stability and lowers costs, and it has the added advantage of making results reproducible.
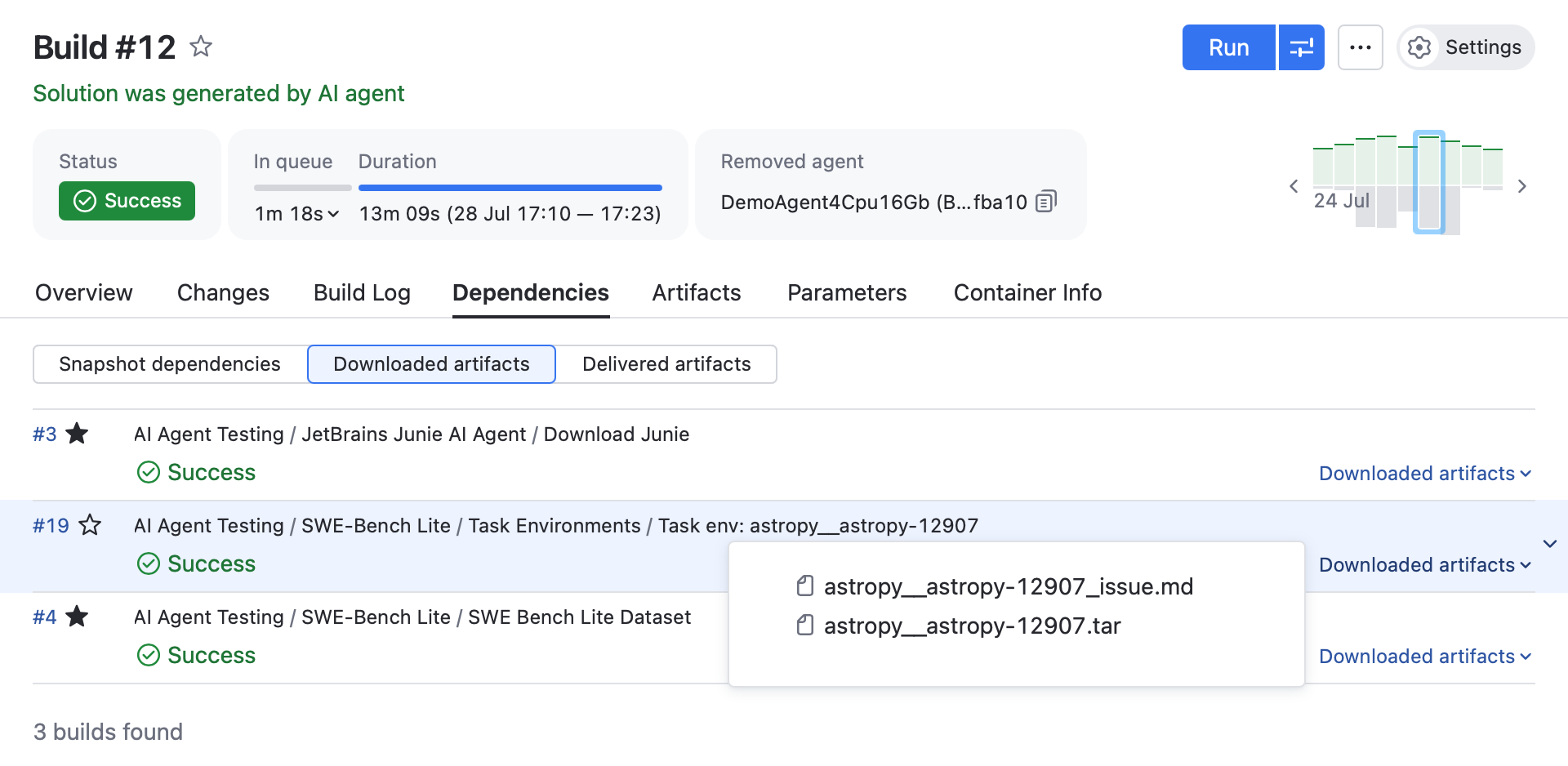
Cost-efficient and scalable execution
Though possible, running hundreds of tasks at once is wasteful. Instead, we built configurations that run smaller subsets: 10 tasks, 30 tasks, or 50 tasks.
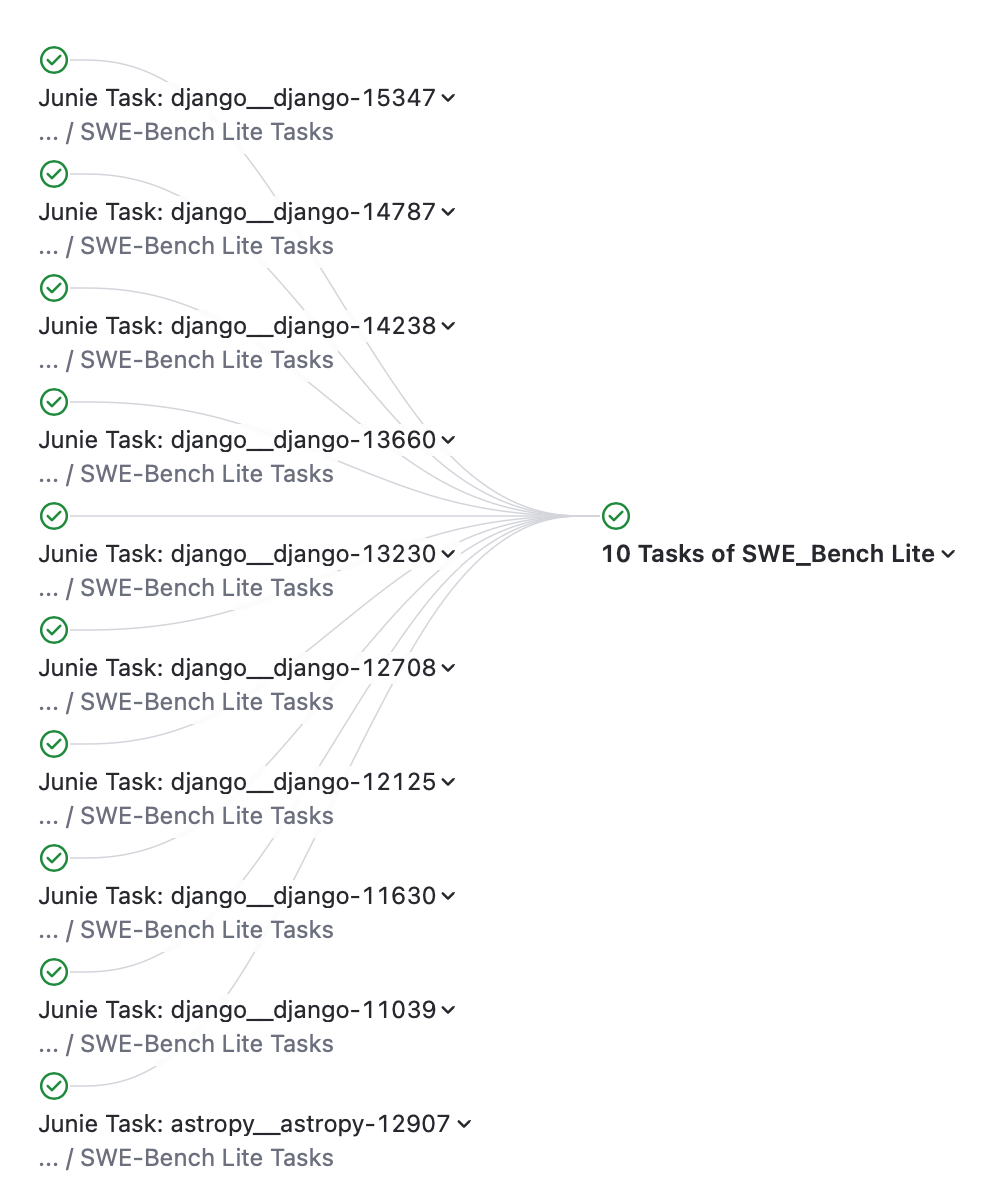
The project creates different-sized task sets for cost-efficient testing:
val tenTasksSet = mutableListOf<Task>()
val thirtyTasksSet = mutableListOf<Task>()
val fiftyTasksSet = mutableListOf<Task>()
tasks.forEachIndexed { index, task ->
val taskConfiguration = createTaskForGeminiBuildType(task)
if (index % 10 == 0 && tenTasksSet.size < 10) tenTasksSet.add(taskConfiguration)
if (index % 7 == 0 && thirtyTasksSet.size < 30) thirtyTasksSet.add(taskConfiguration)
if (index % 5 == 0 && fiftyTasksSet.size < 50) fiftyTasksSet.add(taskConfiguration)
}
buildType(create_SWE_Bench_Lite_XxTaskSlice(tenTasksSet, agentGemini))
buildType(create_SWE_Bench_Lite_XxTaskSlice(thirtyTasksSet, agentGemini))
buildType(create_SWE_Bench_Lite_XxTaskSlice(fiftyTasksSet, agentGemini))
Source: Google_Gemini_CLI_AI_Agent.kt
This setup gives us flexibility: Daily runs can use the smaller sets for quick checks, while strong-performing agents can be scaled up to larger runs. If an agent fails early, we can stop immediately and save resources.
The 10-task run in particular works like a build verification test. It is fast and inexpensive, yet still provides statistical insight into the agent’s health.
Infrastructure stability and resource control
By caching datasets and Docker images, our pipelines no longer depend on unstable network downloads. Failures now reflect the agent’s quality, not infrastructure problems.
TeamCity’s resource management features also help us control concurrency. Since providers may limit request rates, we can set a maximum number of parallel agent runs. This prevents overload, avoids provider errors, and keeps the evaluation system available for everyone on the team.
This defines a shared resource with a quota of 20 concurrent connections, which limits how many builds can simultaneously access Hugging Face services, preventing rate limit issues:
sharedResource {
id = "HuggingFaceConnections"
name = "HuggingFaceConnection"
resourceType = quoted(20)
}
features {
sharedResources {
readLock("HuggingFaceConnection")
}
}
Source: SWE_Bench_Lite_TaskEnv.kt
A summary of the benefits
With this setup, we gain:
- Economy: We can reuse datasets and environments efficiently.
- Stability: The setup leads to fewer random failures.
- Reproducibility: Runs are carried out in identical environments.
- Trustworthy metrics: Results reflect agent performance rather than noise.
- Flexibility: The Kotlin DSL makes it easy to generate hundreds of configurations.
- Visibility: We gain clear insight into agent quality over time.
- Power: TeamCity proves itself useful beyond CI/CD by serving as a robust testing platform.
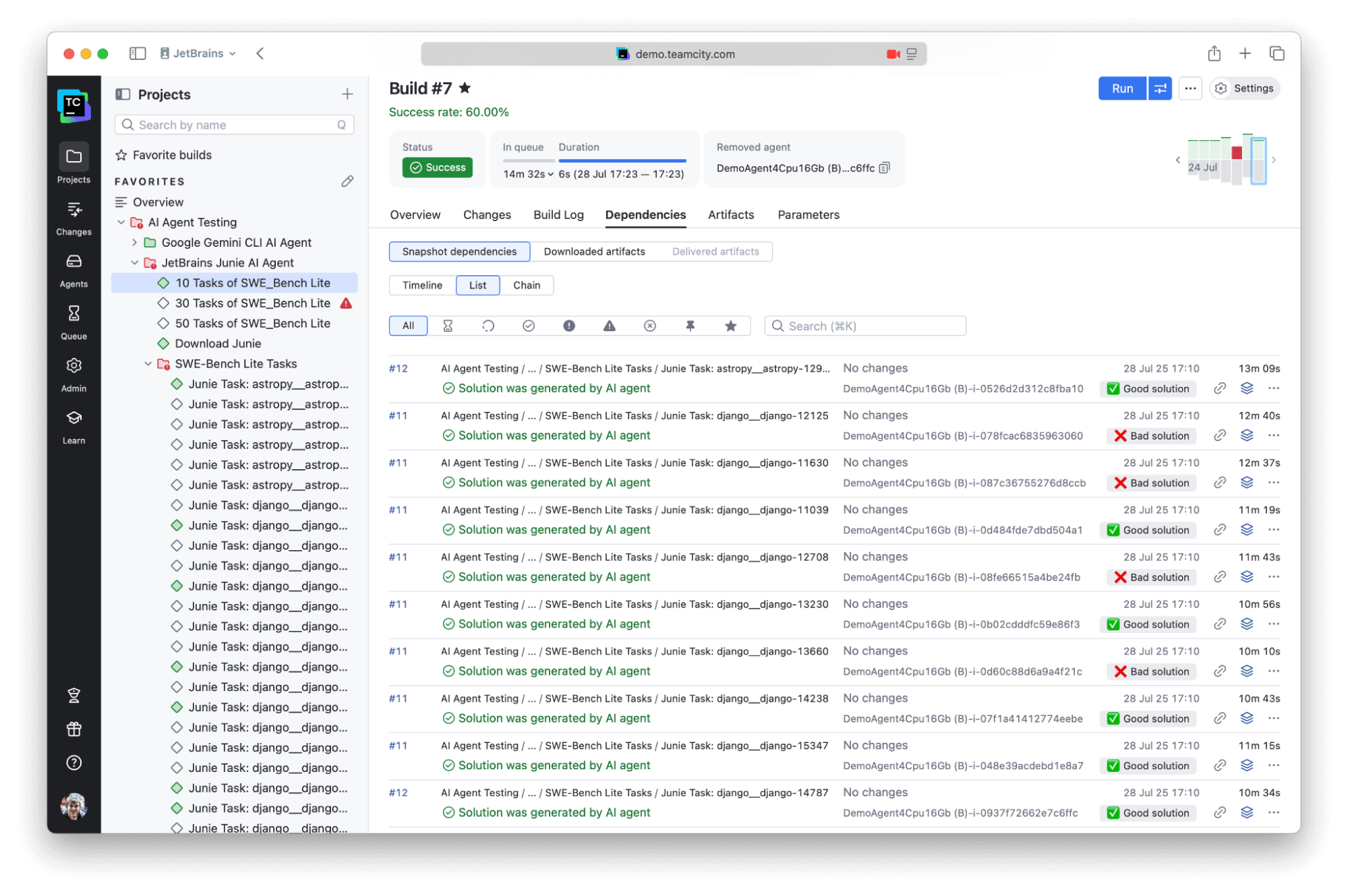
Our pipeline automatically tags runs with visual indicators for quick assessment:
resolved_instances = data.get('resolved_instances', 0)
unresolved_instances = data.get('unresolved_instances', 0)
error_instances = data.get('error_instances', 0)
if resolved_instances > 0:
print("##teamcity[addBuildTag '✅ Good solution']")
if unresolved_instances > 0:
print("##teamcity[addBuildTag '❌ Bad solution']")
if error_instances > 0 or empty_patch_instances > 0:
print("##teamcity[addBuildTag ' Error']")
Source: scripts/tag_task_execution.py
Conclusion
We built a reliable and efficient system for testing AI coding agents with TeamCity and SWE-bench Lite. Repeatable, cost-effective, and adaptable, the pipeline provides reliable metrics.
TeamCity is not just for continuous integration and deployment – it is also an excellent platform for evaluating AI agents.
You can find all repositories and resources linked in our project. If you’d like help setting up a similar pipeline for your own agents, just leave a comment below. We’ll be happy to help.
Subscribe to TeamCity Blog updates





