

在 DataSpell 中使用 Jupyter Notebook 与 WSL 2

对于使用 Windows 的数据科学家或机器学习工程师来说,Windows Subsystem for Linux 2 (WSL 2) 的功能一定不算陌生。 WSL 2 允许使用 Hyper-V 虚拟化在 Windows 10 或 11 上完全安装 Linux 发行版。 涉及数据科学或机器学习任务时,这提供了来自两个方面的优势:在 Windows 上访问所有应用程序或文件,以及使用 Linux 运行 Python 代码。 这完美契合使用 Linux 专属软件包的分析或模型,无需手动编译。

WSL 2 比传统虚拟机更轻量,仅提供命令行功能,一直将 Python 中的开发环境选项限制为 Jupyter Notebook。 好在 DataSpell 2022.2 具有通过 WSL 2 配置 Python 解释器的功能,您可以在 Windows 上通过 DataSpell 轻松运行所有想要使用的 Linux 兼容软件包。 我们来看看它是如何运作的。
设置 WSL 2
使用 WSL 2 之前,需要确保使用的是兼容版本的 Windows。 Windows 10 版本 2004 及更高版本(家庭版及更高版本)和所有版本的 Windows 11 都支持 WSL 2。
然后,安装 Ubuntu 或首选 Linux 发行版。 Ubuntu 和许多其他发行版都可以从 Microsoft Store 获得,可以直接安装。

接下来,按照 Microsoft 的指南设置 WSL 2 与所选 Linux 发行版。 指南中有多个步骤,确保在继续之前仔细完成所有步骤。
使用 Powershell,可以通过在命令行中输入 wsl 来使用 WSL 2。 您随时可以在命令提示符中输入 exit 退出 WSL 2。最后,在 WSL 2 中,确保已安装或更新到所需版本的 Python 3。
使用 WSL 2 在 DataSpell 中配置解释器
Python 是一种解释型语言,需要解释器才能运行。 大多数情况下,这是用来运行脚本的 python 命令。 Python 解释器负责将 Python 代码转换为可以由计算机处理器执行的内容,如本视频中所述。 解释器特定于每个处理器和操作系统。
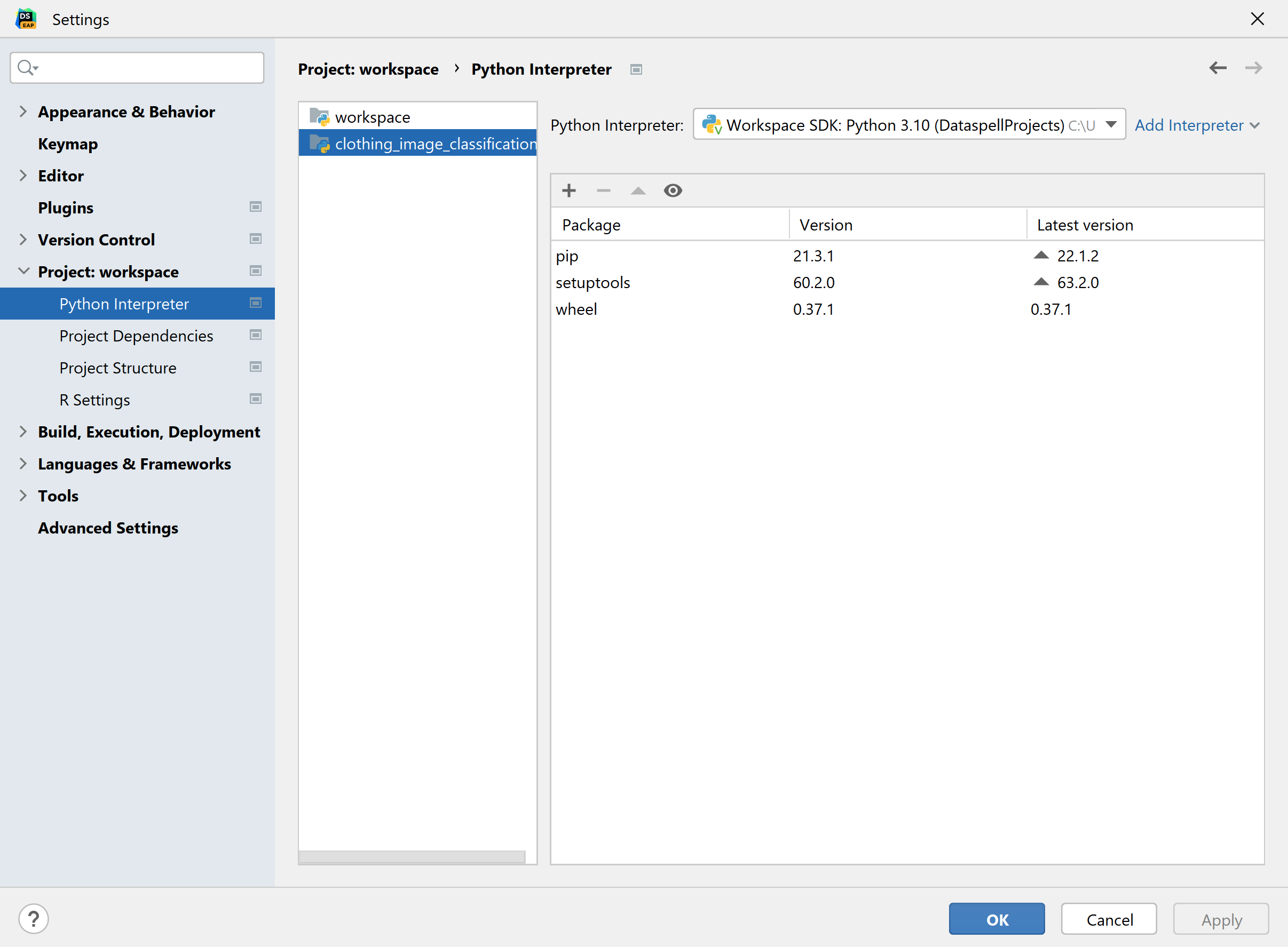
您可能已经在 Windows 中运行过 Python,但是,要将 WSL 2 与 DataSpell 一起使用,我们需要告诉它使用 WSL 2 发行版的 Python 解释器。 转到 File | Settings | Project Workspace | Python Interpreter(文件 | 设置 | 项目工作区 | Python 解释器)进行设置。 我个人偏向于为每个工作区设置一个解释器,所以我在左侧列表中选择了 clothing_image_classification。如果您愿意让所有项目都有一个通用解释器,可以将选项保留为 workspace。
Next, sele接下来,选择右上角下拉菜单旁边的 Add Interpreter(添加解释器),选择 On WSL…(在 WSL 上…)选项。

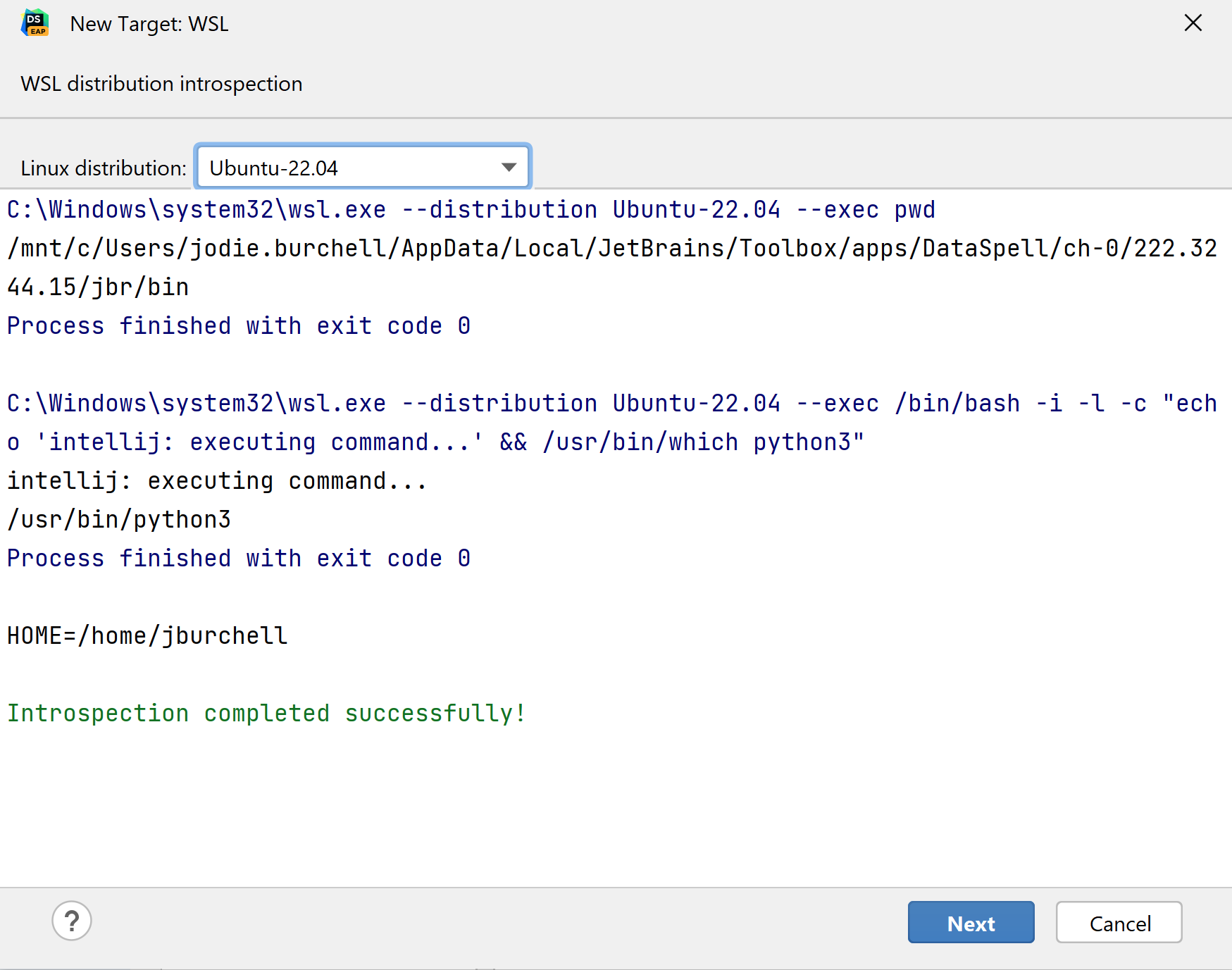
在下一个屏幕上,确保从下拉菜单选择首选 Linux 发行版。 内省完成后选择 Next(下一步)。
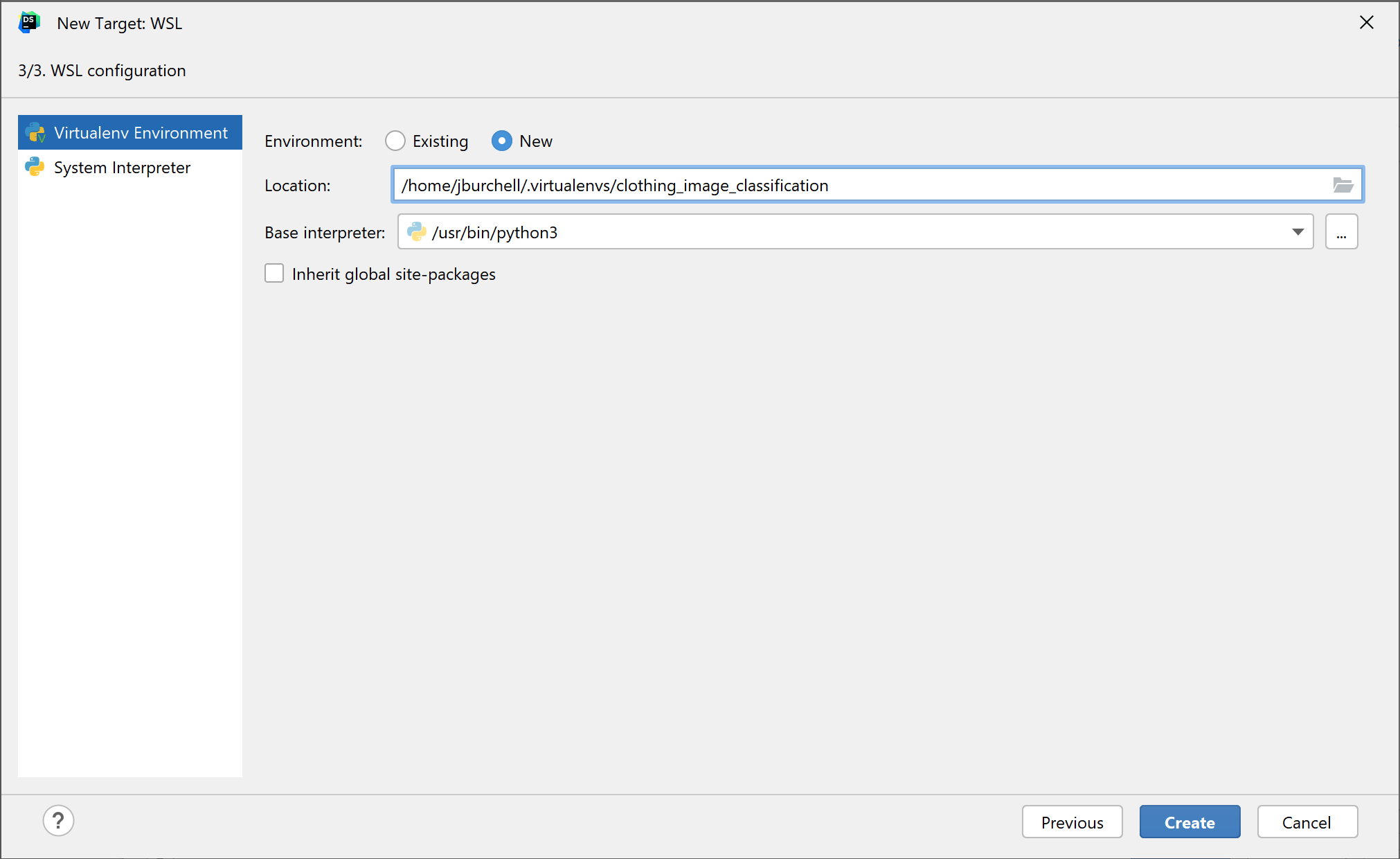
现在,我们可以配置解释器了。 DataSpell 当前支持使用系统解释器或创建虚拟环境(即 virtualenv)。 使用系统解释器时,计算机上的默认 Python 版本将用于解释代码,并且安装的软件包都将针对该 Python 版本进行定制。 使用虚拟环境时,可以使用特定 Python 版本创建隔离环境,带有其自己的解释器和软件包版本。 我选择创建新的 virtualenv 并将其重命名为 clothing_image_classification。
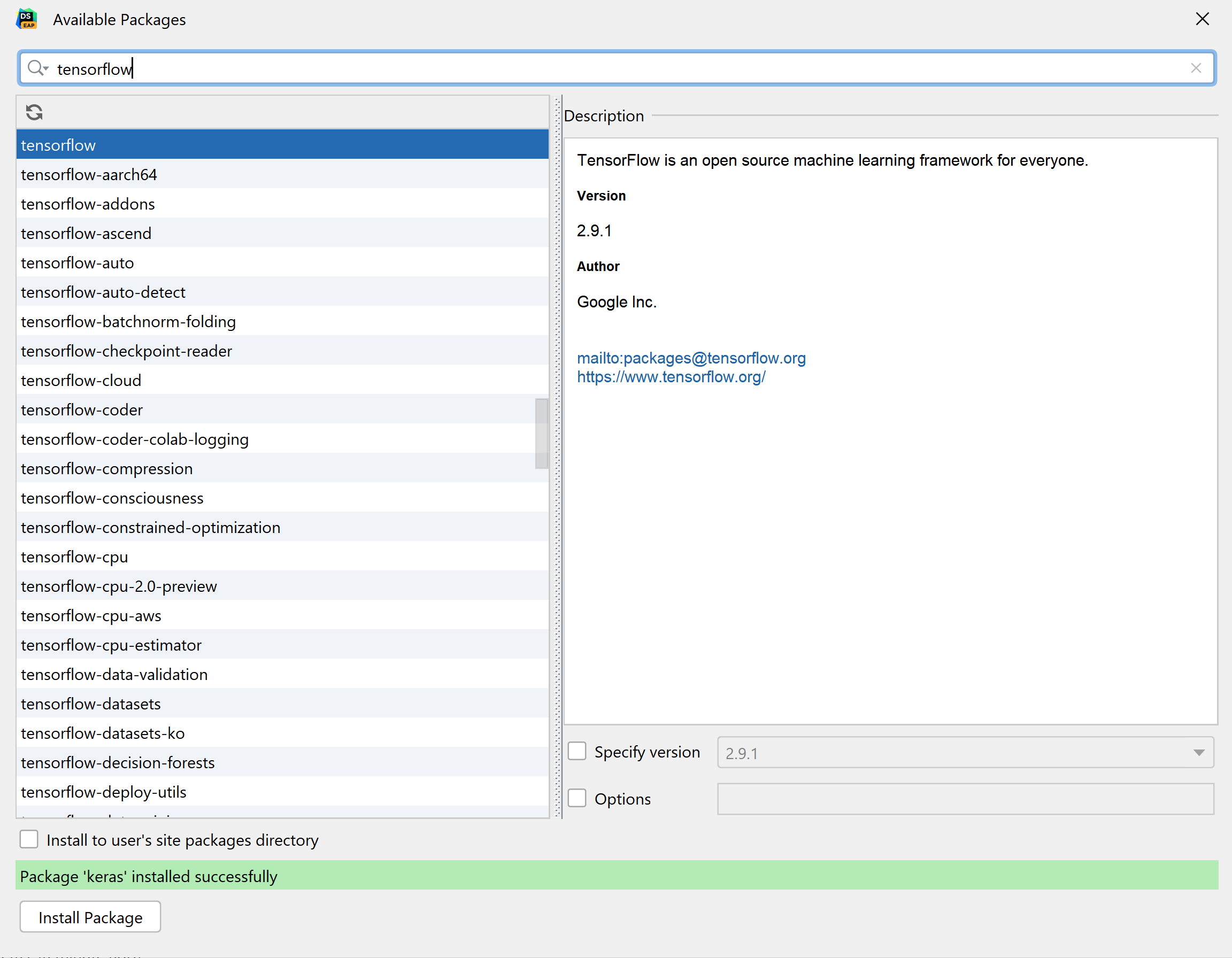
现在,我们已配置解释器和 virtualenv,可以导入所需软件包了。 我将在这个项目中使用 Tensorflow、Keras 和 Matplotlib,所以我使用了 UI 来查找和 pip 安装它们,如下所示。
要创建 Jupyter Notebook,请转到 File | New | Jupyter Notebook(文件 | 新建 | Jupyter Notebook),在出现提示时输入名称。
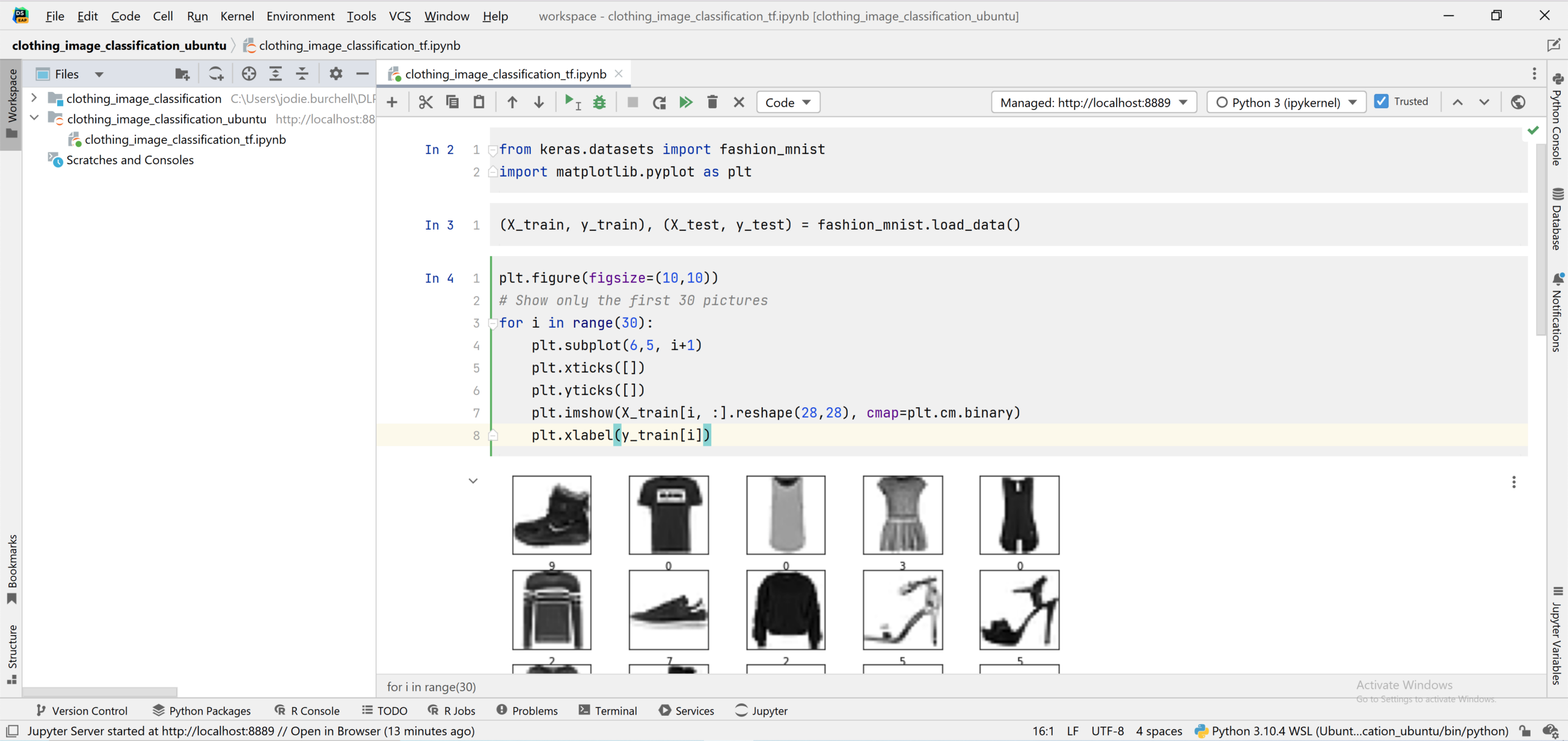
现在,我们有一个 Jupyter Notebook 在 Windows 上的 DataSpell 中运行,但使用的是在 Ubuntu 上运行的解释器。 可以看到,我们已经能够从 Keras 数据集导入数据集并使用 Matplotlib 呈现其中的一部分。
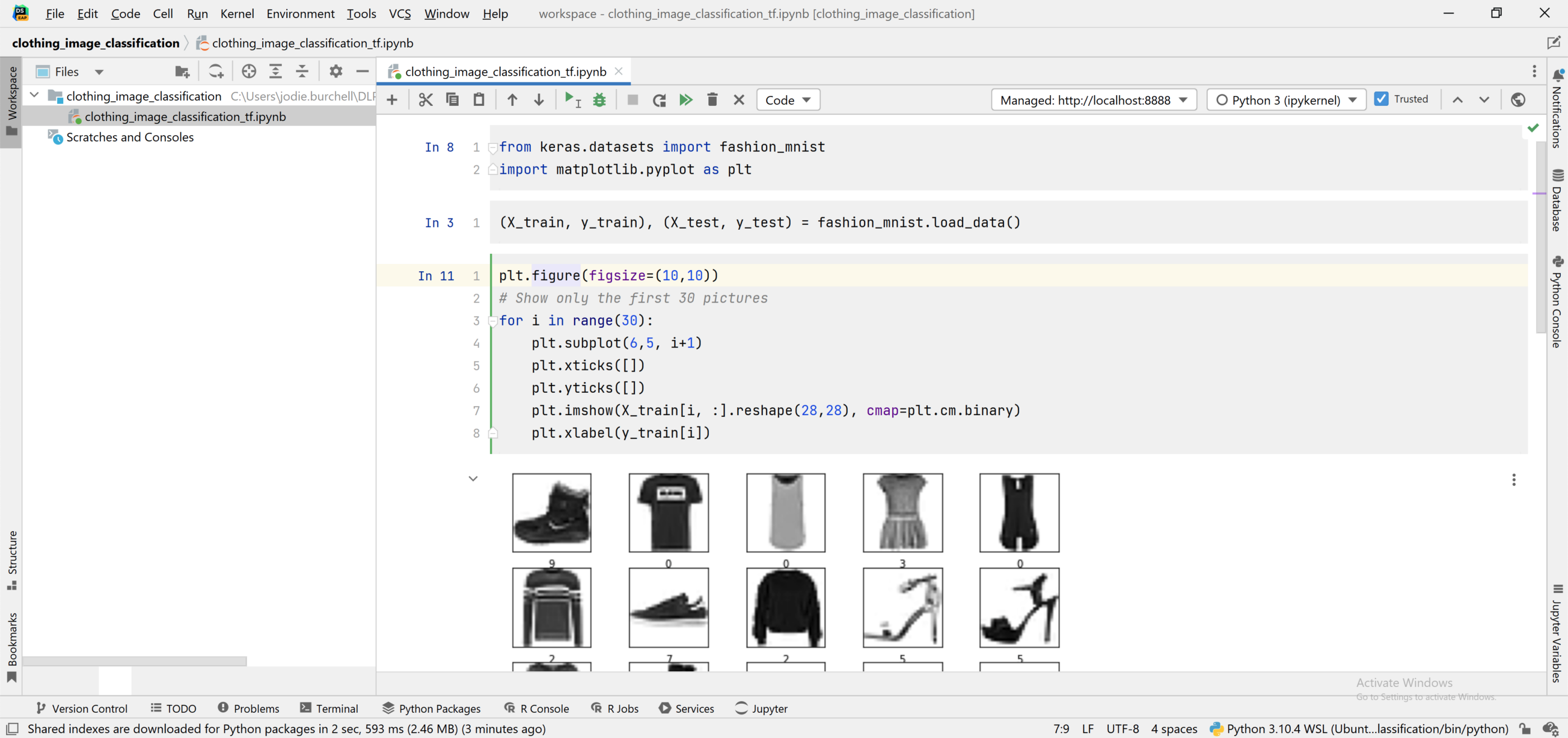
通过终端使用 WSL 2
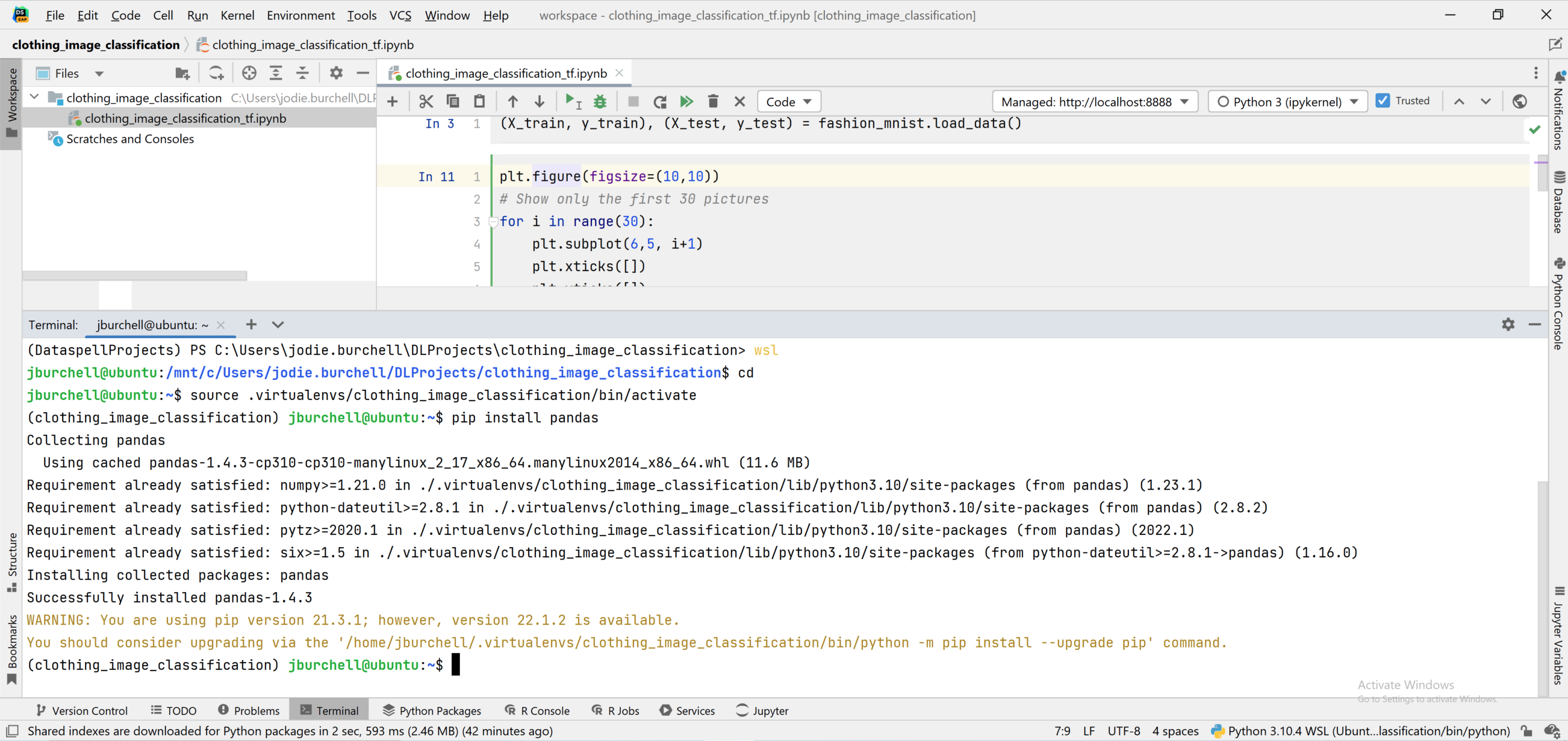
通过 DataSpell 中的终端也可以访问 WSL 2。 打开 Terminal(终端)选项卡,在命令提示符下输入 wsl。 这将允许您在 Linux 中运行命令行实参,无需离开 IDE。 可以看到,我已经在 Ubuntu 中激活了 virtualenv,并使用下面的命令行 pip 安装了 pandas。
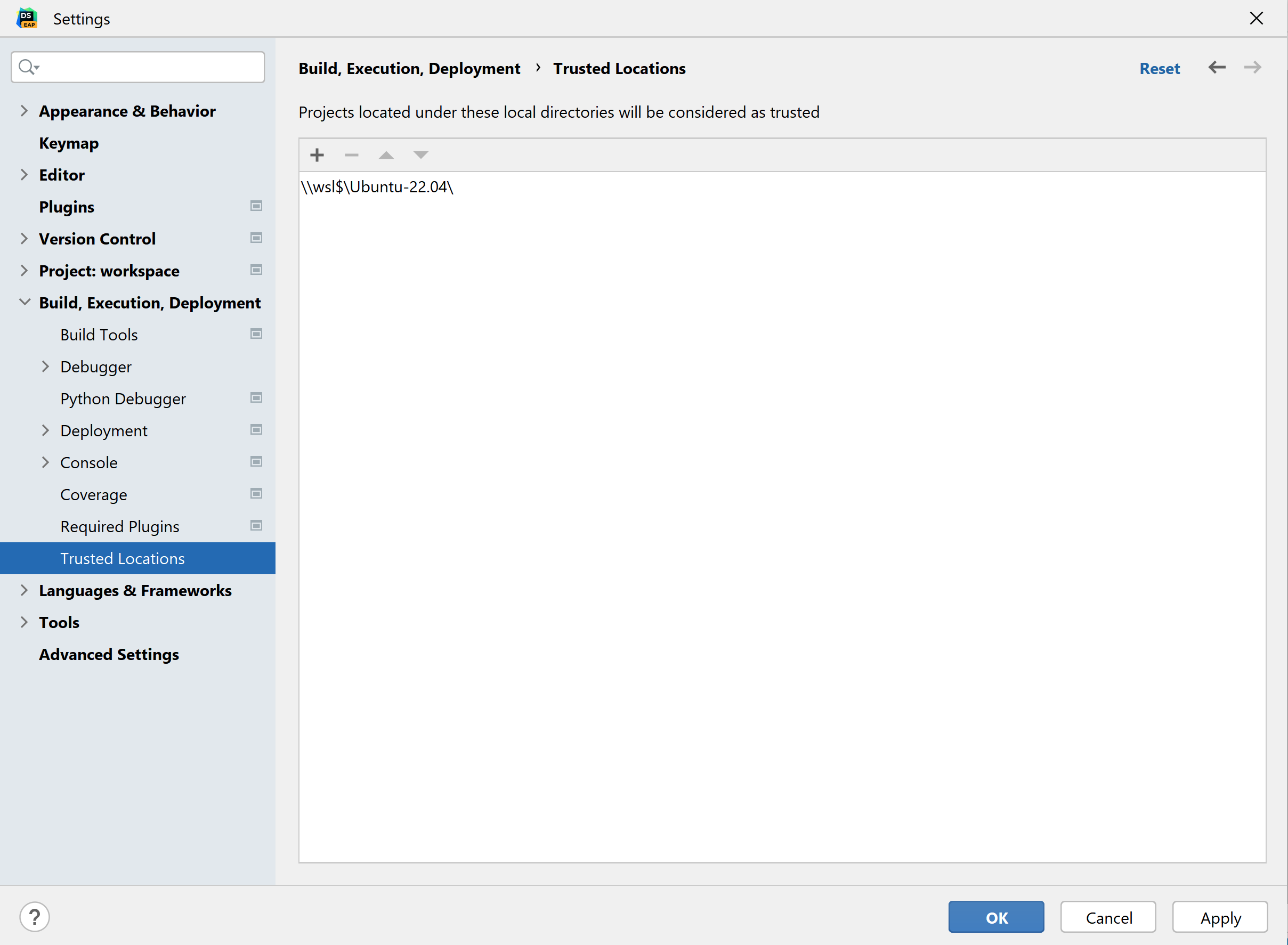
访问存储在 Linux 上的文件
除了为解释器使用 Linux 发行版,您可能也想在 Linux 而不是 Windows 上存储用于分析的文件, DataSpell 可以自动检测 WSL 2 文件系统 “\\wsl$”,因此您可以像从 Windows 目录一样轻松地从 Linux 目录创建工作区。 在 Linux 中创建工作区之前,首先需要将 “\\wsl$” 添加到受信任位置列表。
然后,您可以从 “\wsl$” 目录中的位置创建工作区。
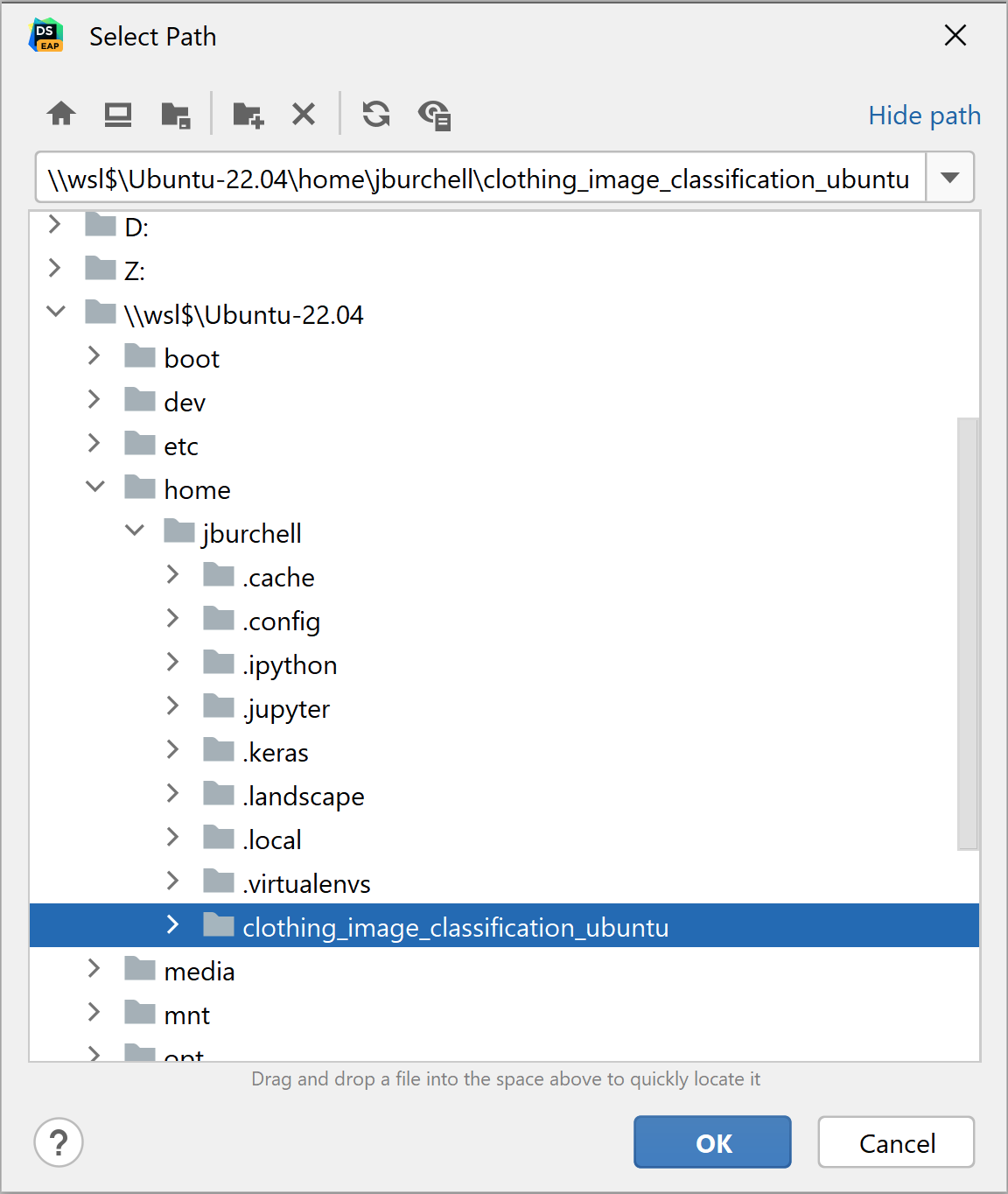
从这里开始,工作流与在 Windows 中创建的工作区完全相同:我们可以使用 WSL 2 在 Linux 上设置解释器,甚至在 Windows 上也可以。 下面我复制了在 Ubuntu 工作区的 Windows 中创建的同一个 Notebook,使用的是全新的解释器和配置了 WSL 2 的 virtualenv。
我希望这篇指南能够展示出在 DataSpell 中使用 Jupyter Notebook 和 Windows Subsystem for Linux 2 是多么简单直接。 只需几个简单的步骤,您就可以收获来自两方面的优势:在舒适的 Windows 中工作,同时能够访问 Linux 的强大功能,并且无需离开 IDE。
将 DataSpell 语言设置为中文!
中文语言包插件现已支持 DataSpell。在 Preferences | Plugins 中搜索 “Chinese Language Pack”,一键完成安装。
本博文英文原作者: