

在 PyCharm 中使用 Jupyter Notebook 的 7 种方式

Jupyter Notebook 允许您通过按顺序创建和共享数据、方程和可视化效果来讲述故事,并在您浏览 Notebook 时提供支持性叙述。
PyCharm Professional 中的 Jupyter Notebook 提供了比基于浏览器的 Jupyter Notebook 更多的功能,例如代码补全、动态绘图和快速统计,以帮助您快速有效地探索和处理数据。
我们来看看在 PyCharm 中使用 Jupyter Notebook 实现您的目标的 7 种方式。 它们是:
- 创建或连接到现有的 Notebook
- 导入数据
- 熟悉您的数据
- 使用 JetBrains AI Assistant
- 使用 PyCharm 探索您的代码
- 从代码中获得洞察
- 分享您的洞察和图表
可以在 GitHub 上获取我们在此演示中使用的 Jupyter Notebook。
1. 创建或连接到现有的 Notebook
您可以在本地创建和处理 Jupyter Notebook,也可以通过 PyCharm 远程连接到 Notebook。 我们来看看这两种选项,以便您自行决定。
创建新的 Jupyter Notebook
要在本地处理 Jupyter Notebook,您需要转到 PyCharm 中的 Project(项目)工具窗口,导航到您想要添加 Notebook 的位置,并调用新文件。 您可以通过使用键盘快捷键 ⌘N (macOS) / Alt+Ins (Windows/Linux) 或右键点击并选择 New | Jupyter Notebook(新建 | Jupyter Notebook)来执行此操作。
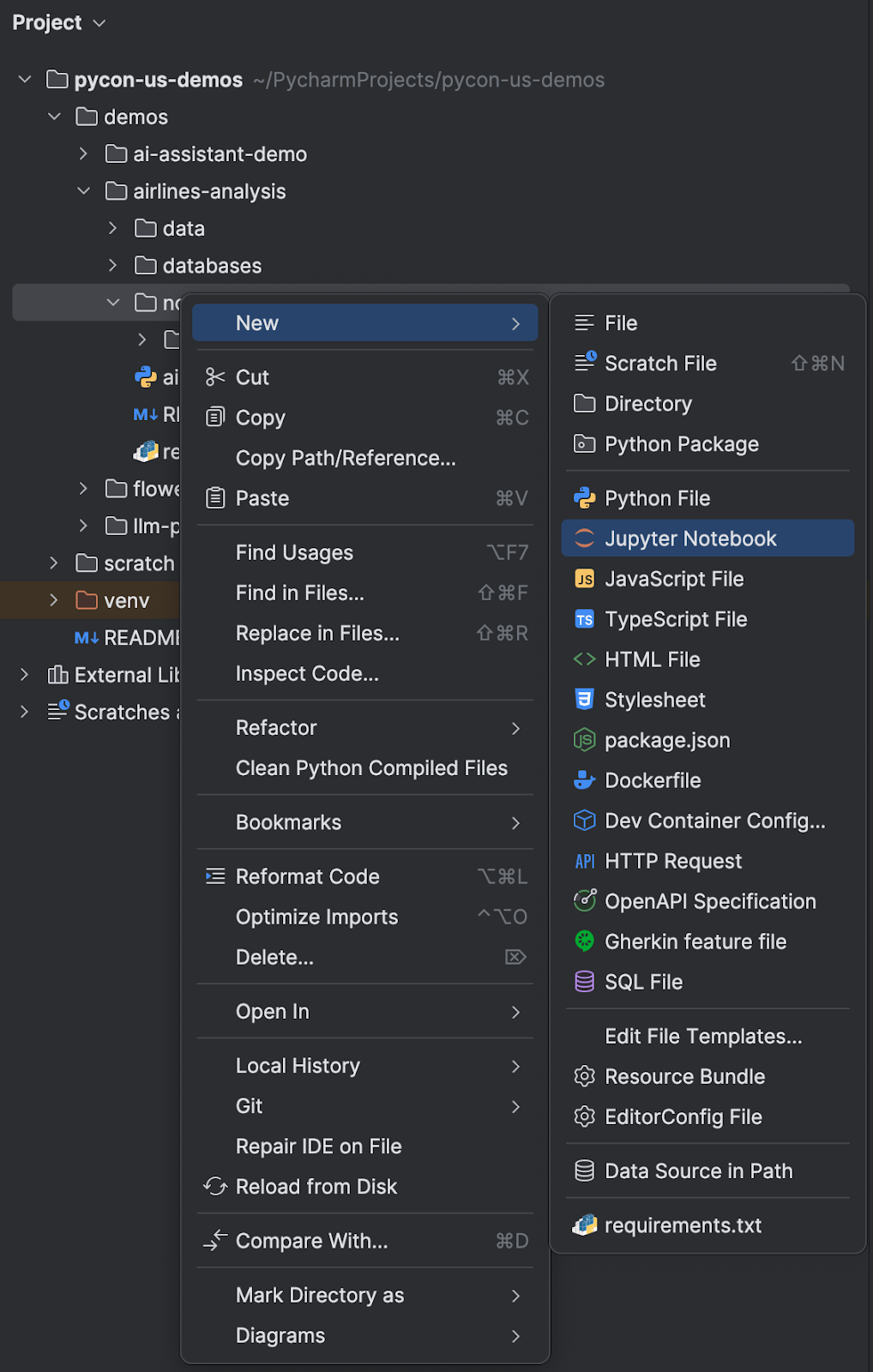
为您的新 Notebook 命名,PyCharm 会将其打开以便您开始工作。 您还可以将本地 Jupyter Notebook 拖入 PyCharm 中,IDE 会自动识别它们。
连接到远程 Jupyter Notebook
或者,您也可以通过选择 Tools | Add Jupyter Connection(工具 | 添加 Jupyter 连接)来连接到远程 Jupyter Notebook。 您可以选择启动本地 Jupyter 服务器、连接到现有正在运行的本地 Jupyter 服务器,或者使用 URL 连接到 Jupyter 服务器 – 所有这些选项均受支持。
现在,您有了 Jupyter Notebook,您需要一些数据!
2. 导入数据
数据通常有 CSV 或数据库两种格式。 我们先来看看如何从 CSV 文件导入数据。
从 CSV 文件导入
Polars 和 pandas 是用于将数据导入 Jupyter Notebook 的两种最常用库。 在本节中,我将为您提供两者的代码,您可以查看 Polars 和 pandas 的文档,并了解 Polars 与 pandas 的不同之处。
您需要确保您的 CSV 位于 PyCharm 项目中的某个位置,例如在一个名为 `data` 的文件夹中。 随后,您可以导入 pandas 并后续使用它来读取 CSV 文件:
import pandas as pd
df = pd.read_csv("../data/airlines.csv")
在此示例中,airlines.csv 是包含我们想要处理的数据的文件。 要在 PyCharm 中运行此代码和任何代码单元,请使用 ⇧⏎ (macOS) / Shift+Enter (Windows/Linux)。 您也可以使用顶部工具栏上的绿色运行箭头。
如果您更喜欢使用 Polars,则可以使用以下代码:
import polars as pl
df = pl.read_csv("../data/airlines.csv")
从数据库导入
如果您的数据在数据库中(内部项目的常见情况),则只需再编写几行代码便可将其导入 Jupyter Notebook。 首先,您需要设置您的数据库连接。 在此示例中,我们使用的是 PostgreSQL。
对于 pandas,您需要使用以下代码读取数据:
import pandas as pd
engine = create_engine("postgresql://jetbrains:jetbrains@localhost/demo")
df = pd.read_sql(sql=text("SELECT * FROM airlines"),
con=engine.connect())
而对于 Polars,使用以下代码:
import polars as pl
engine = create_engine("postgresql://jetbrains:jetbrains@localhost/demo")
connection = engine.connect()
query = "SELECT * FROM airlines"
df = pl.read_database(query, connection)
3. 熟悉您的数据
现在,我们已经读取了数据,接下来可以看一下 DataFrame 或 `df`,因为我们将在代码中引用它。 要打印出 DataFrame,只需一行代码,无论您使用哪种方法来读取数据:
df
DataFrame
PyCharm 首先以表形式显示您的 DataFrame,以便您可以进行探索。 您可以在 DataFrame 中水平滚动,并点击任何列标题以按该列对数据排序。 您可以点击右侧的 Show Column Statistics(显示列统计信息)图标并选择 Compact(紧凑)或 Detailed(详细),以获得每列数据的一些有用统计信息。
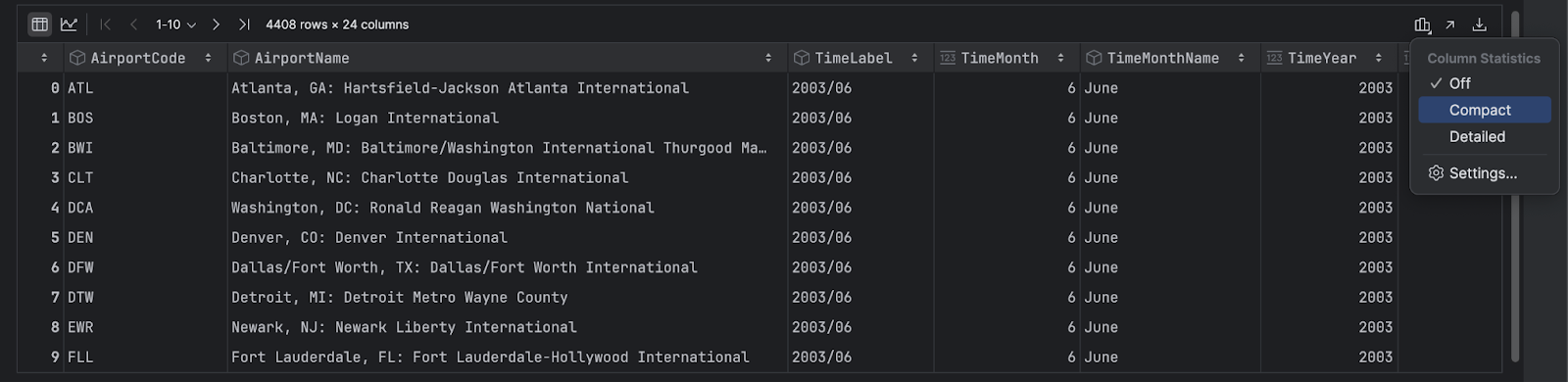
动态图表
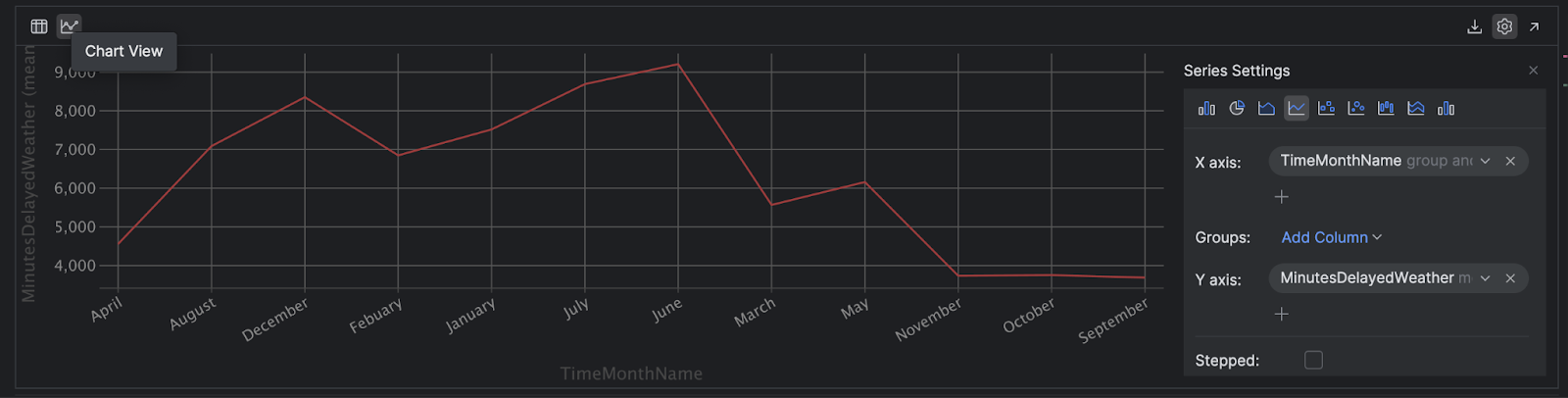
您可以点击左侧的 Chart View(图表视图)图标,利用 PyCharm 获得 DataFrame 的动态图表。 我们在此示例中使用 pandas,但 Polars DataFrame 也有相同的选项。
点击右侧的 Show Series Settings(显示连续设置)图标(齿轮)来配置您的绘图以满足您的需求:
在此视图中,您可以将鼠标悬停在数据上以了解更多信息,并轻松找出异常值:
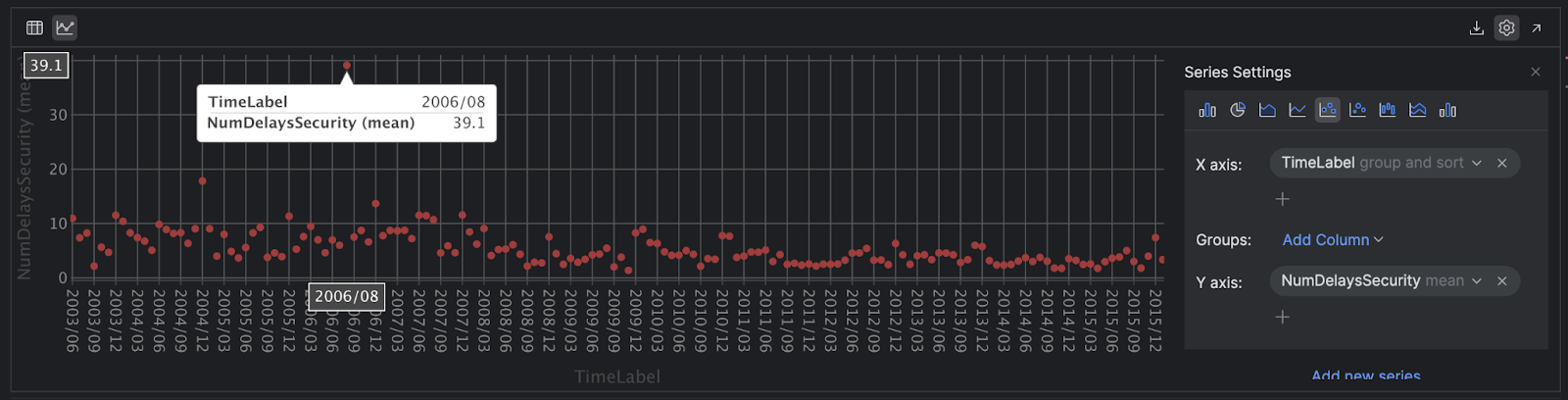
您也可以使用 Polars 完成所有操作。
4. 使用 JetBrains AI Assistant
JetBrains AI Assistant 提供了一些功能,可以使您在 PyCharm 内使用 Jupyter Notebook 时更加高效。 我们来仔细看看如何使用 JetBrains AI Assistant 解释 DataFrame、编写代码,甚至解释错误。
解释 DataFrame
如果您有 DataFrame 但不确定从哪里开始,可以点击 DataFrame 右侧的紫色 AI 图标并选择 Explain DataFrame(解释 DataFrame)。 JetBrains AI Assistant 将使用其上下文为您提供 DataFrame 的概览:
您可以使用生成的解释来帮助理解。
编写代码
您还可以让 JetBrains AI Assistant 帮助您编写代码。 也许您知道您想要什么样的绘图,但不能完全确定代码应该是什么样子。 现在,您可以使用 JetBrains AI Assistant 获得帮助。 假设您想使用 Matplotlib 创建一个用于查找“TimeMonthName”和“MinutesDelayedWeather”之间关系的图表。 通过指定列名,我们会为请求提供更多上下文,从而提高所生成代码的可靠性。 尝试使用以下提示:
Give me code using matplotlib to create a chart which finds the relationship between ‘TimeMonthName’ and ‘MinutesDelayedWeather’ for my dataframe df
如果您喜欢生成的代码,可以使用 Insert Snippet at Caret(在文本光标处插入代码段)按钮插入代码,随后运行该代码:
import matplotlib.pyplot as plt
# Assuming your data is in a DataFrame named 'df'
# Replace 'df' with the actual name of your DataFrame if different
# Plotting
plt.figure(figsize=(10, 6))
plt.bar(df['TimeMonthName'], df['MinutesDelayedWeather'], color='skyblue')
plt.xlabel('Month')
plt.ylabel('Minutes Delayed due to Weather')
plt.title('Relationship between TimeMonthName and MinutesDelayedWeather')
plt.xticks(rotation=45)
plt.grid(axis='y', linestyle='--', alpha=0.7)
plt.tight_layout()
plt.show()
如果您不想打开 AI Assistant 工具窗口,则可以使用 AI 单元提示提出您的问题。 例如,我们可以在这里提出相同的问题并获得我们需要的代码:
![]()
解释错误
您还可以让 JetBrains AI Assistant 为您解释错误。 当您遇到错误时,点击 Explain with AI(使用 AI 解释):

您可以使用生成的输出来加深对问题的理解,甚至可能获得一些代码来修正问题!
5. 探索您的代码
PyCharm 可以帮助您获得 Jupyter Notebook 的概览,补全部分代码以减少您的工作量,按需重构代码,调试代码,甚至添加集成以帮助您将其提升到新的水平。
代码导航和优化提示
我们的 Jupyter Notebook 增长得相当快,但幸运的是,您可以在 PyCharm 的Structure(结构)视图中通过按 ⌘7 (macOS) / Alt+7 (Windows/Linux) 查看所有 Notebook 的标题。

代码补全
在 PyCharm 内使用 Jupyter Notebook 时,您可以利用的另一项实用功能是代码补全。 PyCharm 提供开箱即用的基本代码补全和基于类型的代码补全,但您也可以在 PyCharm Professional 中启用全行代码补全,此功能使用本地 AI 模型提供建议。 最后,JetBrains AI Assistant 还可以帮助您编写代码并发现新的库和框架。

重构
有时您需要重构代码,在这种情况下,您只需要知道一个键盘快捷键 ⌃T (macOS) / Shift+Ctrl+Alt+T (Windows/Linux),随后就可以选择您要调用的重构。 选择如 Rename(重命名)、Change Signature(更改签名)和 Introduce Variable(引入变量)等流行选项,或者如 Extract Method(提取方法)等鲜为人知的选项,在不改变语义的情况下更改您的代码:
随着 Jupyter Notebook 的增长,您的 import 语句也可能相应增长。 有时您可能会导入像 polars 和 numpy 这样的软件包,但别忘了 numpy 是 Polars 库的传递依赖项,因此我们不需要单独导入它。
要捕获这些情况并保持代码整洁,您可以调用 Optimize Imports(优化导入)⌃⌥O (macOS) / Ctrl+Alt+O (Windows/Linux),PyCharm 会移除不需要的导入。
调试代码
您可能还没有在 PyCharm 中使用过调试器,不过这没关系。 只需知道,当您需要更好地理解 Jupyter Notebook 中的某些行为时,它就会出现并随时为您提供支持。
点击装订区域或使用 ⌘F8 (macOS) / Ctrl+F8 (Windows/Linux),在您感兴趣的行上放置断点,随后使用顶部工具栏上附有调试图标的调试器运行您的代码:

您也可以使用 ⌥⇧⏎ (macOS) / Shift+Alt+Enter (Windows/Linux) 在 Jupyter Notebook 中调用 PyCharm 的调试器。 在 Jupyter Notebook 中调试代码时存在一些限制,但请亲自尝试并与我们分享您的反馈。
将集成添加到 PyCharm 中
如果没有您需要的集成,IDE 将不完整。 PyCharm Professional 2024.2 为您的工作流带来了两个新集成:DataBricks 和 HuggingFace。
您可以转到 Settings(设置)⌘ (macOS) / Ctrl+Alt+S (Windows/Linux),选择 Plugins (插件)并在 Marketplace 标签页中搜索具有相应名称的插件来启用与 Databricks 和 HuggingFace 的集成。
6. 从代码中获得洞察
分析数据时,分类变量与连续变量之间存在差异。 分类数据具有有限数量的离散组或类别,而连续数据则是一种连续度量。 我们来看看如何根据航空公司数据集中的分类变量和连续变量提取不同的洞察。
连续变量
通过查看数据中平均值的度量标准和数据围绕平均值的分布程度,我们可以了解连续数据的分布情况。 在正态分布的数据中,我们可以使用均值来衡量平均值,使用标准差来衡量分布。 但是,当数据并非正态分布时,我们可以使用中值和四分位距(这是第 75 和第 25 百分位数之间的差异)来获得更准确的信息。 我们来看一个连续变量,以了解这些度量之间的区别。
我们的数据集中有很多连续变量,但我们使用 `NumDelaysLateAircraft` 来看看我们能了解哪些信息。 我们使用以下代码获取该列的一些汇总统计信息:
df['NumDelaysLateAircraft'].describe()
查看这些数据,我们可以看到 `mean` ~789 和 `median`(我们的第 50 百分位数,在下表中用“50%”表示)~618 之间存在较大差异。
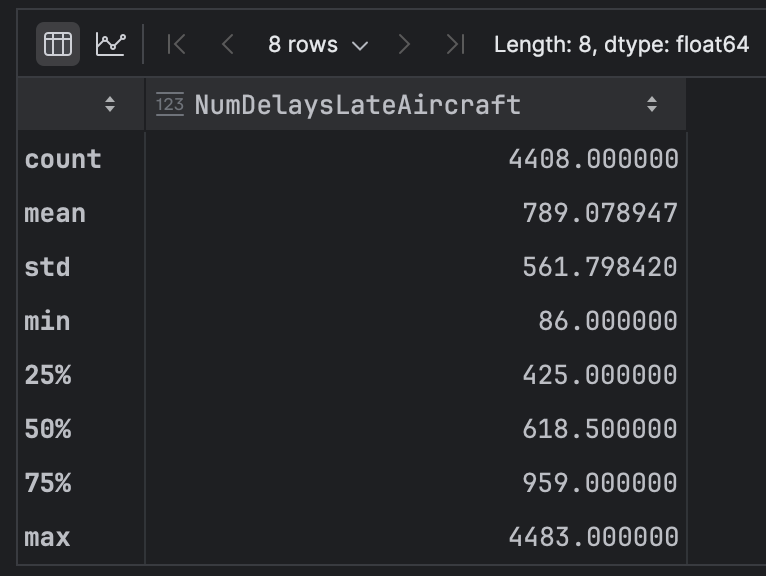
这表明我们的变量分布存在偏斜,因此我们使用 PyCharm 来进一步探索。 点击左上方的 Chart View(图表视图)图标。 在图表呈现后,我们更改屏幕右侧的齿轮表示的系列设置。 将 x 轴更改为 `NumDelaysLateAircraft`,将 y 轴更改为 `NumDelaysLateAircraft`。
现在,使用小箭头下拉 y 轴并选择 `count`。 最后一步是使用右上角的图标将图表类型更改为 Histogram(直方图):
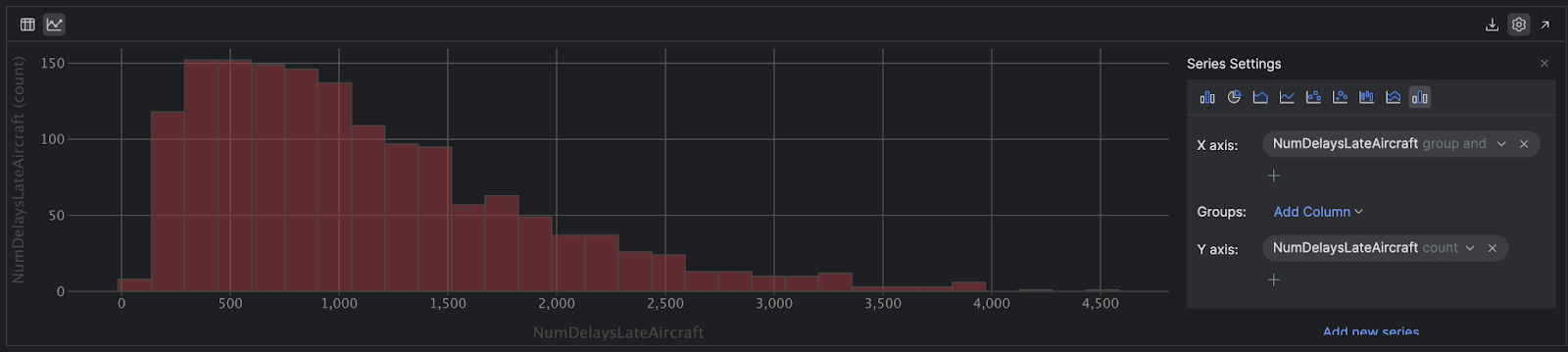
现在,我们可以从视觉上看到偏斜,可以看到在大多数情况下,延误不是太严重。 但是,其中有一些更极端的延误 – 有一架飞机是右侧的异常值,它延误了 4,509 分钟,超过三天!
在统计学中,均值对异常值非常敏感,因为它是几何平均值,而不像中值,如果您对变量中的所有观察值进行排序,中值将正好位于这些值的中间。 当均值高于中值时,说明数据的右侧(较高的一侧)有异常值,如我们这个示例中所示。 在这种情况下,中值能更好地指示真实的平均延误,查看一下直方图就能了解。
分类变量
我们来看看如何使用代码从分类变量中获得一些洞察。 为了获得比 `AirportCode` 更有趣的内容,我们将分析在一年的不同月份 `TimeMonthName` 中,由天气导致延误的航班数量 `NumDelaysWeather`。
使用以下代码将 `NumDelaysWeather` 与 `TimeMonthName` 分组:
result = df[['TimeMonthName', 'NumDelaysWeather']].groupby('TimeMonthName').sum()
result
这再次以表格式为我们提供了 DataFrame,但点击 PyCharm UI 左侧的 Chart View(图表视图)图标,看看我们能了解哪些信息:
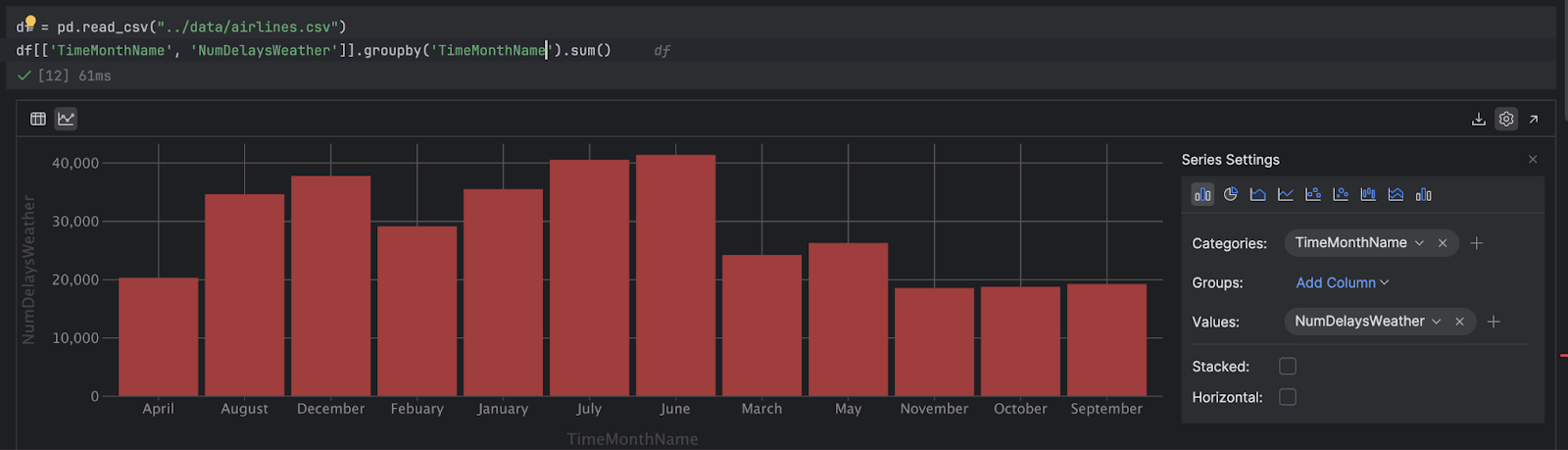
这没问题,但如果按照格里历对月份进行排列会更有帮助。 我们先来为我们预期的月份创建一个变量:
month_order = [ "January", "February", "March", "April", "May", "June", "July", "August", "September", "October", "November", "December" ]
现在,我们可以让 PyCharm 使用我们刚刚在 `month_order` 中定义的顺序:
# Convert the 'TimeMonthName' column to a categorical type with the specified order
df["TimeMonthName"] = pd.Categorical(df["TimeMonthName"], categories=month_order, ordered=True)
# Now you can group by 'TimeMonthName' and perform sum operation, specifying observed=False
result = df[['TimeMonthName', 'NumDelaysWeather']].groupby('TimeMonthName', observed=False).sum()
result
随后,我们再次点击 Chart View(图表视图)图标,但出错了!
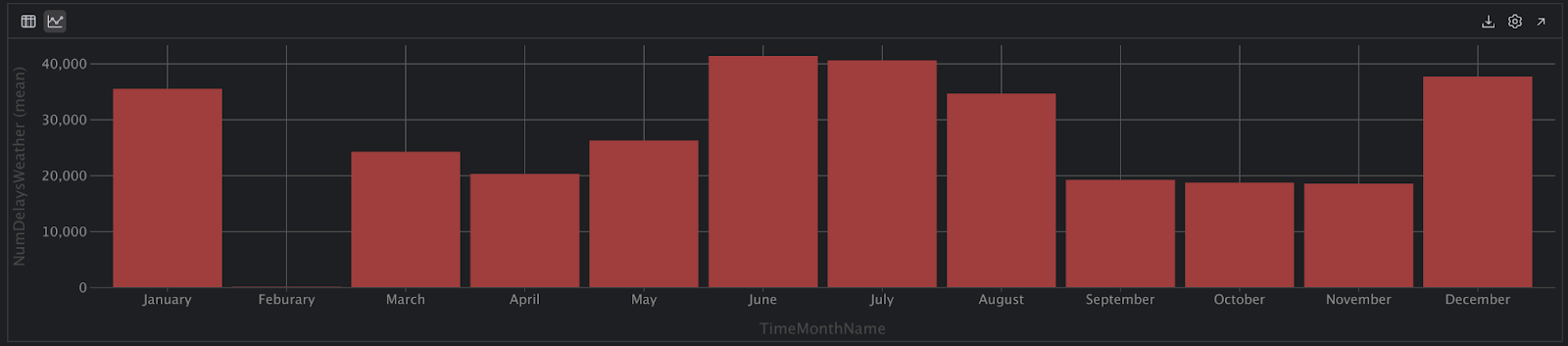
我们真的可以说 2 月没有航班延误吗? 这不可能是对的。 我们用更多的代码检查我们的假设:
df['TimeMonthName'].value_counts()
啊哈! 现在可以看到,我们数据集中的 `Feburary` 拼写错误,因此变量名称中的正确拼写不匹配。 我们使用以下代码更新数据集中的拼写:
df["TimeMonthName"] = df["TimeMonthName"].replace("Febuary", "February")
df['TimeMonthName'].value_counts()
很好,看起来对了。 现在,我们应该能够重新运行我们之前的代码并获得可以解释的图表视图:
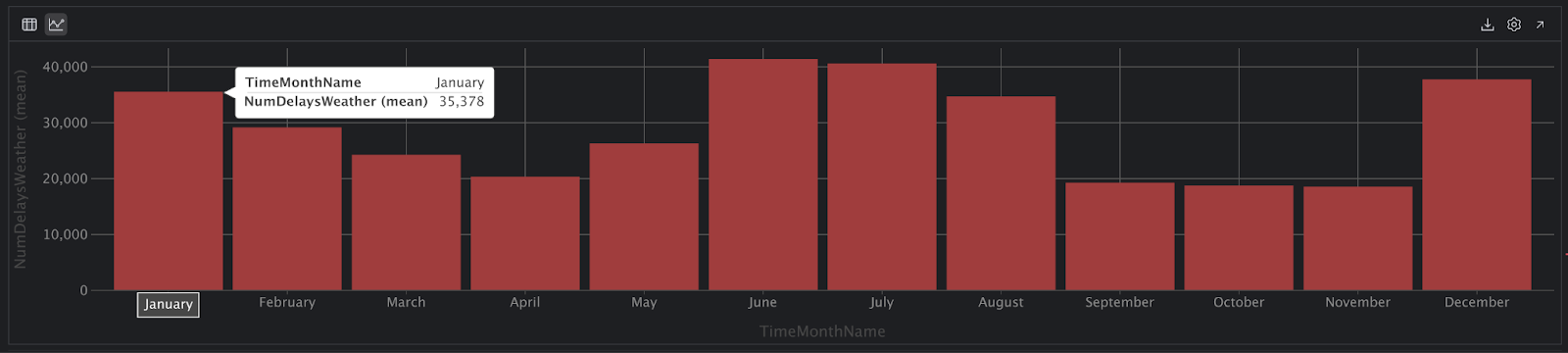
从这个视图中,我们可以看到 12 月、1 月和 2 月的延误次数较多,然后在 6 月、7 月和 8 月的延误次数也较多。 但是,我们还没有根据航班总数将这些数据标准化,因此这些月份的航班数量只会更多,这会导致这些结果以及夏季和冬季月份的延误次数增加。
7. 分享您的洞察和图表
当您的杰作完成时,您可能想要导出数据,此时可以在 PyCharm 中使用 Jupyter Notebook 以各种方式做到这一点。
导出 DataFrame
您可以通过点击右侧的向下箭头导出 DataFrame:
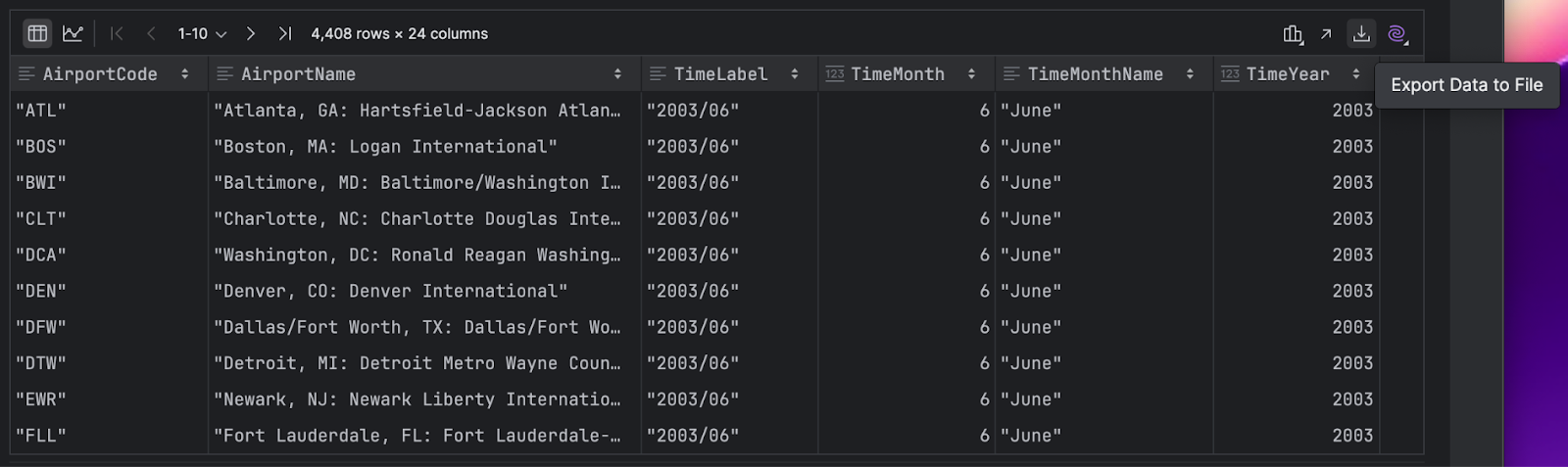
您可以从许多有用的格式中选择,包括 SQL、CSV 和 JSON:
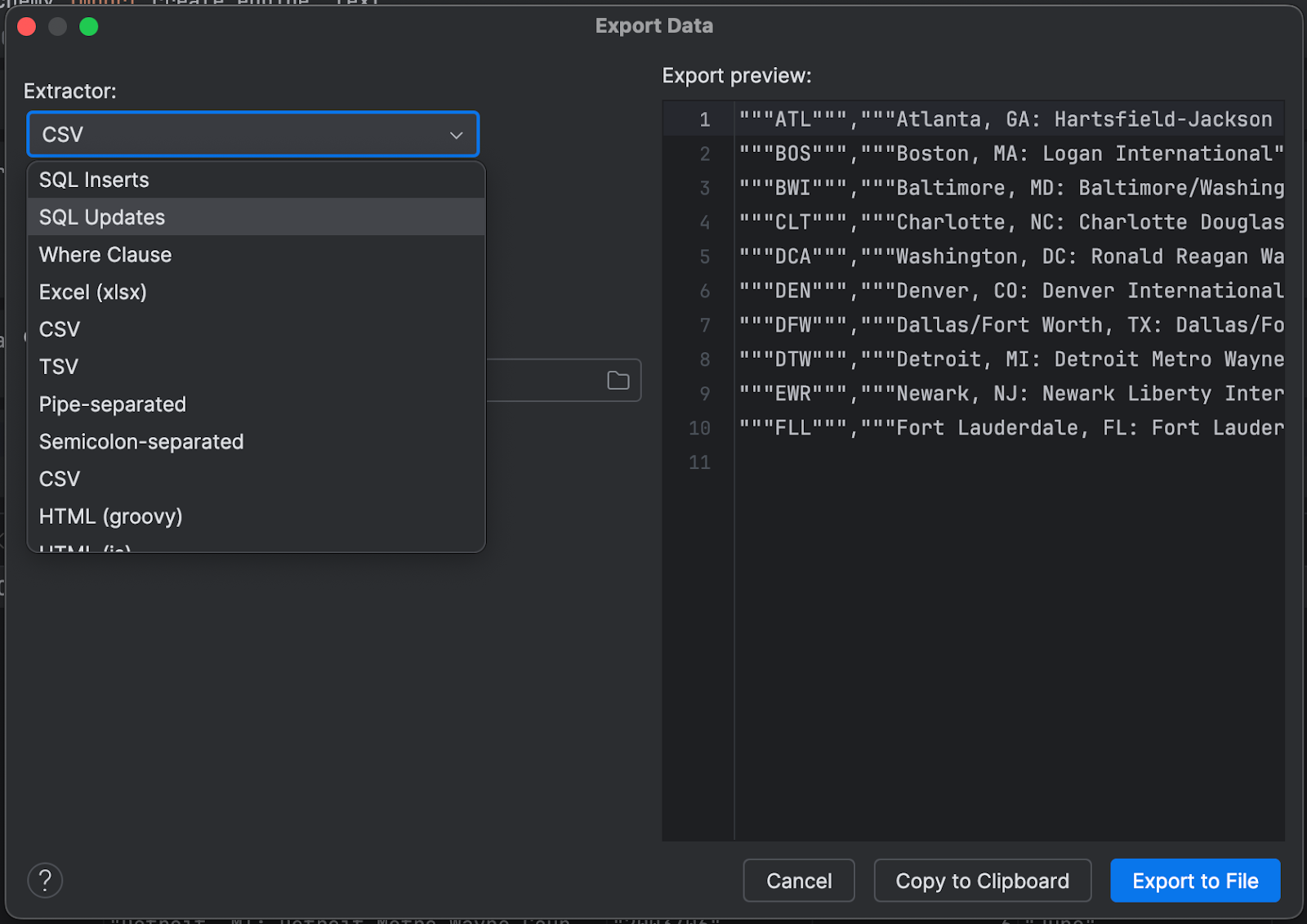
导出图表
如果您喜欢导出交互式绘图,也可以通过点击右侧的 Export to PNG (以 PNG 格式导出)图标做到这一点:
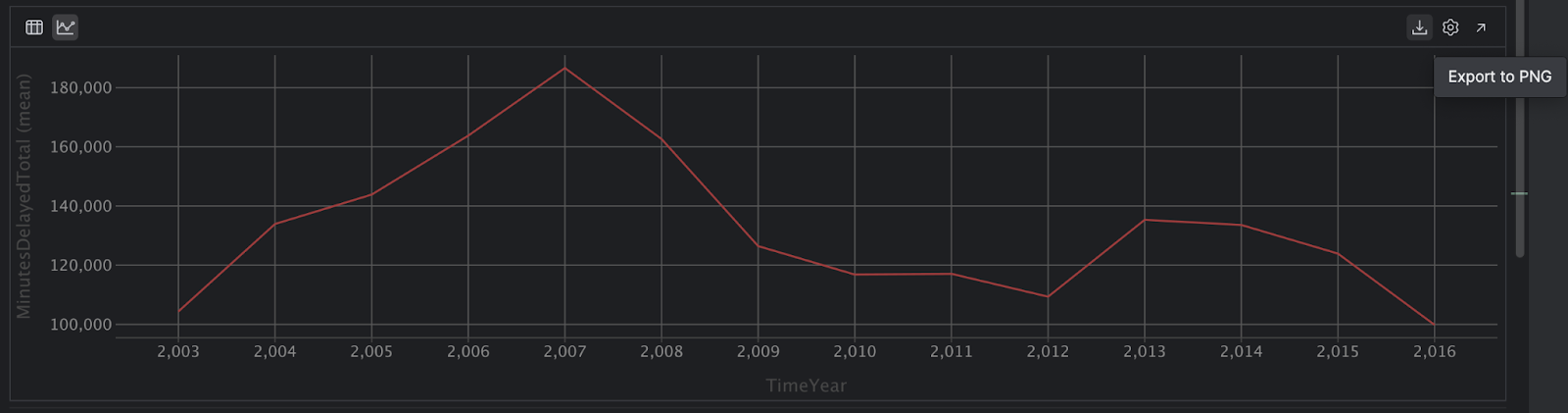
在浏览器中查看您的 Notebook
您可以点击 Notebook 右上角的图标,随时在浏览器中查看整个 Jupyter Notebook:

最后,如果您想将 Jupyter Notebook 导出为 Python 文件,2024.2 也支持这样做! 在 Project(项目)工具窗口中右键点击您的 Jupyter Notebook 并选择 Convert to Python File(转换为 Python 文件)。 按照说明操作即可!
总结
在 PyCharm Professional 中使用 Jupyter Notebook 提供了丰富的功能,使您能够更快地创建代码、轻松探索数据,并以满足您需求的格式导出项目。
下载 PyCharm Professional 亲自试用吧! 立即获得延长试用期,体验 PyCharm Professional 可以为您的数据科学工作带来哪些不同。
在结账时使用促销代码 PyCharmNotebooks 激活您的免费 60 天 PyCharm Professional 订阅。 免费订阅仅适用于个人用户。
本博文英文原作者:





