JetBrains AI
Supercharge your tools with AI-powered features inside many JetBrains products
AI 代码补全:少即是多

如果您一直在跟随我们的历程,您可能已经阅读过我们最近的博文完成不可完成的补全任务:JetBrains IDE 中 AI 补全的现状。 在那篇文章中,您可能还记得这张很酷的代码补全图表。 4 月份出现了些有趣的变化:我们的接受率有所上升,显式取消率(explicit cancel rate)有所下降。
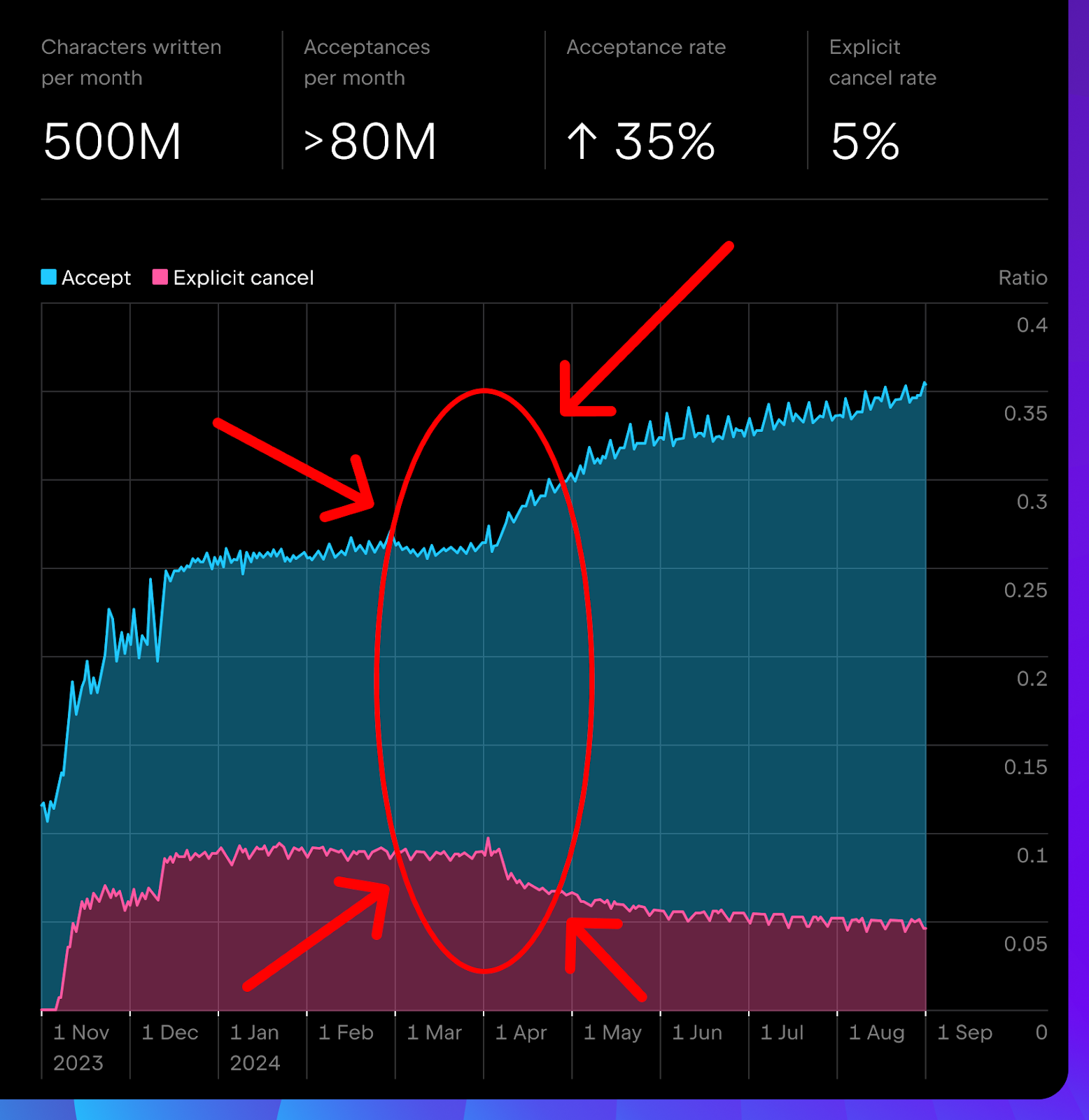
在这篇博文中,我们将分析为什么以及如何在不重新训练生成模型的情况下获得这样的结果。
不能只依靠 LLM
提供代码建议的 LLM 是 AI 代码补全的核心,但不是全部。 幕后有很多事在发生,特别是在插件方面,例如决定:
- 何时显示建议。
- 建议应该是单行还是多行。
- 建议应该显示还是隐藏 – 例如,某个建议可能语义不正确、分数过低,或者使用了冒犯性或不恰当的语言。
但有时,定义筛选规则并不那么简单。
我们想要实现的目标
简而言之,我们只想展示您真正会用到的建议。 这意味着减少多余的建议(您会取消、编辑或删除的建议),同时不影响我们强大的代码补全功能。 在指标方面,我们正在努力:
- 提高接受率。
- 降低显式取消率和编辑/删除建议的百分比。
- 维持或提高已补全代码的比例。
只需要日志
那么,我们怎样才能做到这一切呢? 直接的答案是改进补全模型。
不过,事情并没有那么简单:
- 它既昂贵又费时。 训练更好的模型需要大量资源。
- 我们看不出哪里出了问题。 我们不存储用户的代码,所以我们无法分析坏建议。
- 仅有上下文还不够,用户行为和建议与附近行的匹配等因素也很重要。
轻量级本地筛选模型
我们没有走改进补全 LLM 的漫长道路,而是采取了另一种方式:轻量级本地筛选模型。
这个模型在补全 LLM 的基础上运行,通过已进行匿名处理的日志进行训练。
模型会通过分析以下内容来帮助决定是否应该显示建议:
- 上下文:文件/项目上下文(如使用的语言以及 import 的数量和类型)和补全上下文(如描述文本光标位置的特征)。
- 用户行为:输入速度以及自上次输入以来的时间。
- 建议本身:引用是否得到解决,建议是否重复或与周围行相似,以及其他模型输出,如词元分数和词元熵。
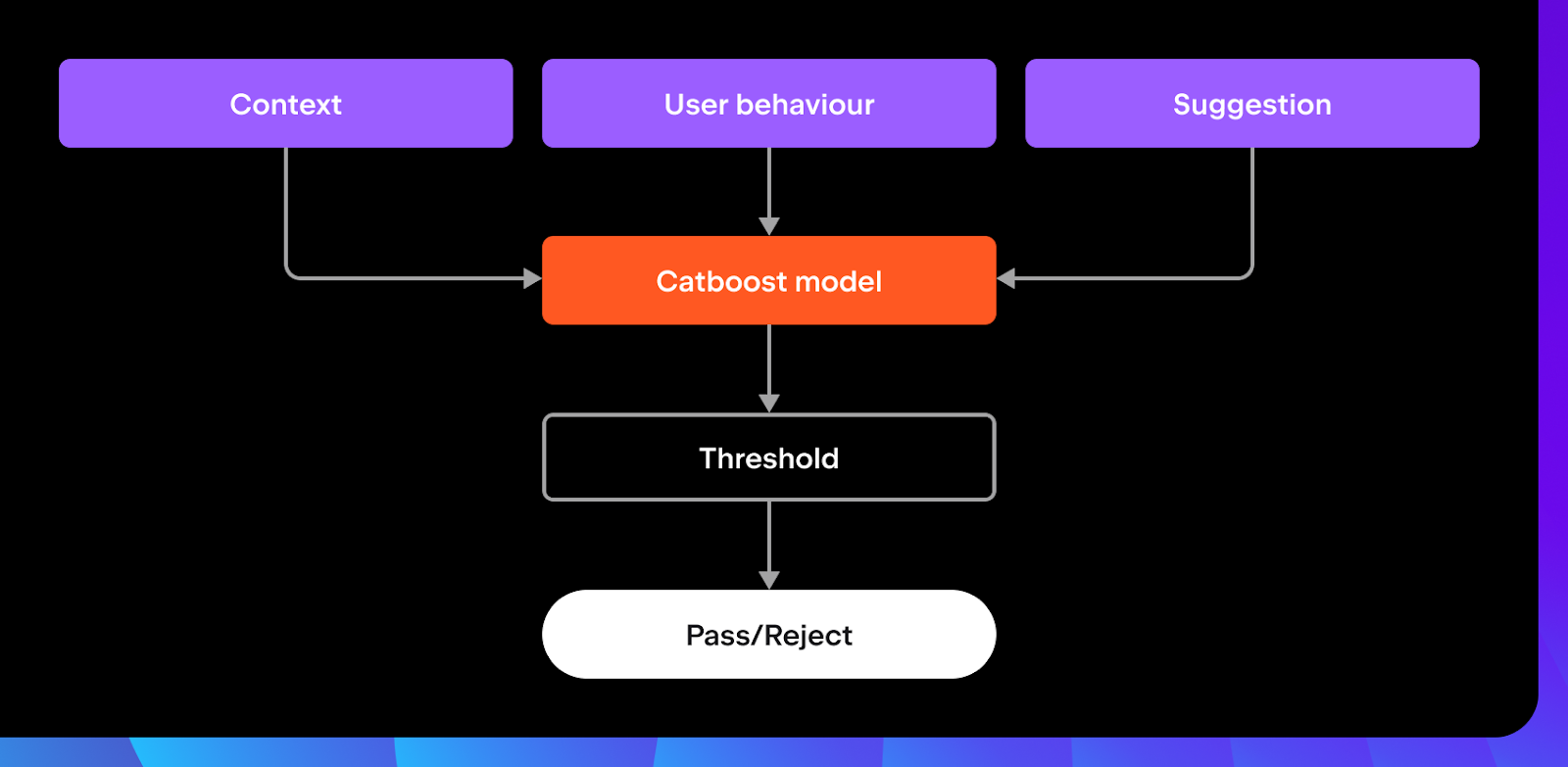
轻量级本地筛选模型的工作很简单:根据您的操作决定接受或拒绝建议。 不过,我们在训练过程中对模型进行了一些指导。 我们对显式用户操作给予了额外权重,例如显式接受或取消建议时。 如果您在接受建议后对其进行编辑或删除,我们会将其视为不那么成功的建议 – 您更改的越多,权重就越小。
从技术上讲,模型通过 CatBoost 构建,效率高且不需要大量数据。 模型专门设计为轻量级 – 训练后,它会变成一个 2.5 MB 的紧凑文件,直接在用户机器上以 Kotlin 运行,在 1-2 毫秒内做出预测。
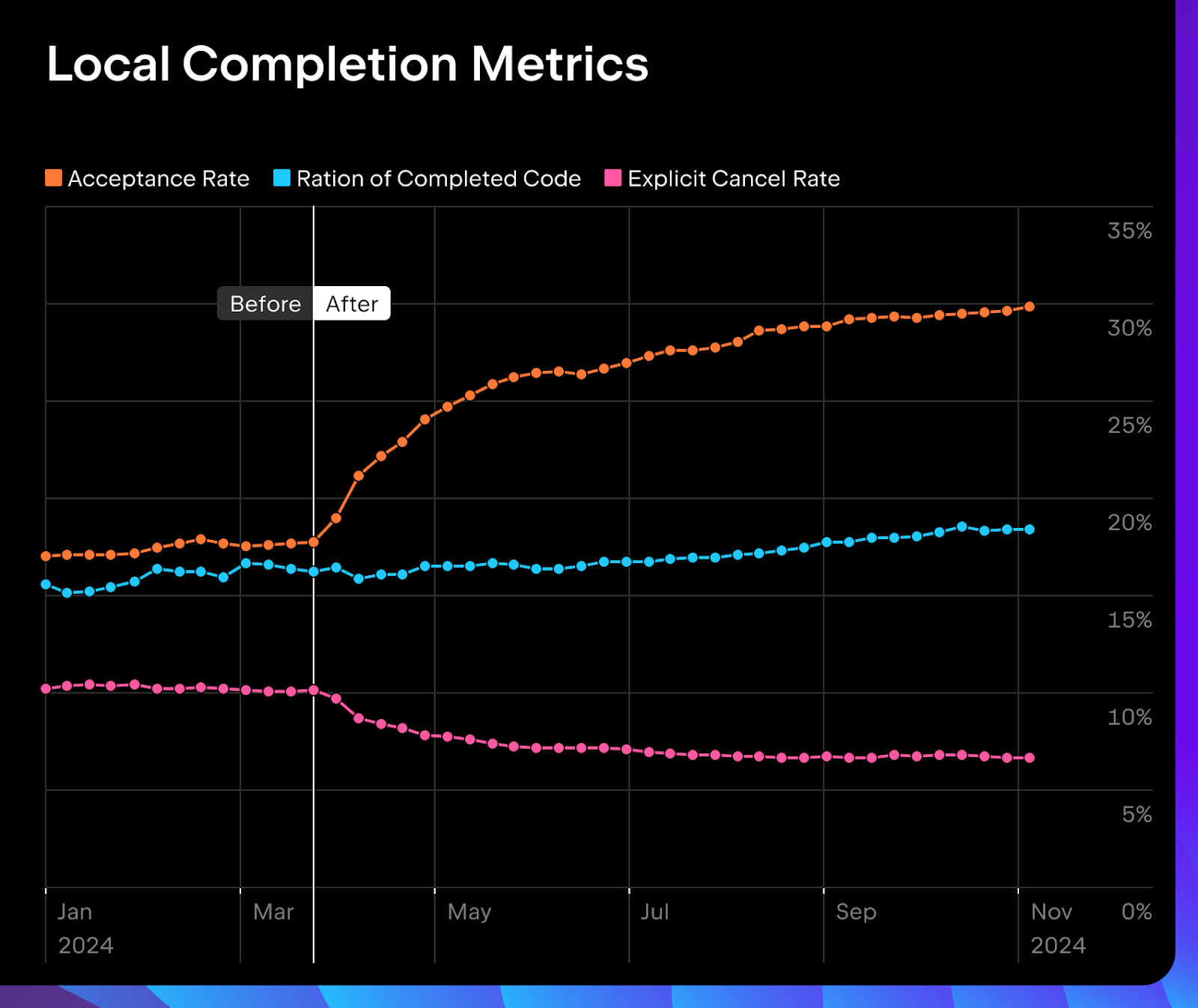
我们的成果
我们在 EAP 中的 A/B 测试取得了很好的结果,而且结果还在越来越好。 筛选模型将接受率提高了约 50%,将显式取消率降低了约 40%,同时保持已补全代码比例稳定。
我们在 2024.1 版 JetBrains IDE 中正式推出了适用于多种语言的筛选模型,包括 Java、Kotlin、Python、PHP、JavaScript/TypeScript、Go、CSS 和 Ruby。 在后续版本中,我们还涵盖了 C#、C++、Rust 和 HCL,并推出了在 Python、Java 和 Kotlin 中使用 Mellum 进行云补全的本地筛选模型。 我们计划尽快涵盖更多语言。
同时,本地代码补全模型和轻量级本地筛选模型也在不断发展和完善。
我们的收获
即使您的 LLM 已经很出色,它也还是会有进步的空间。 您并不一定需要庞大、复杂的模型来改变现状。 有时,巧妙使用日志之类的额外数据可以起到事半功倍的效果。 那么,AI 代码补全下一步将如何发展? 我们能推动它走多远?
请在下方评论区中与我们分享您的想法!
本博文英文原作者: