

JetBrains AI
Supercharge your tools with AI-powered features inside many JetBrains products
使用 Kotlin 构建 AI 智能体 – 第 3 部分:密切观察

本系列的前几篇文章:
读完两篇文章,我们知道,我们的编码智能体已经能做很多事情了。它可以探索项目、读写代码、执行 shell 命令和运行测试。我们在上一篇文章中添加了一个完成定义 (DoD),使其拥有所需的反馈循环,现在,智能体会进行迭代,直至所有测试都通过,而不是由它自己决定何时完成。
我们应该庆祝一下,对吧? 是,也不是。
随着智能体能力越来越强,调试变得更具挑战性。每个工具都会增加难度。DoD 循环增加了更多的调用和 token。可能需要几个小时才能完成评估,当评估失败时,通常不清楚失败原因或问题出在哪里。
现在,我们的智能体可以解决这个问题了。可惜我们看不到过程。
当你想要改进智能体、调试故障或估算成本时,这就成了一个问题。本文中,我们将解决这个可见性问题。我们先来看看众所周知的方案(虽然它们不太奏效),回顾一下 LLM 应用的常用可观测性工具,并将跟踪与 Langfuse 相集成。结果是我们能够看到智能体的分步操作,包括每个操作的成本。在此过程中,我们发现了行为模式,甚至发现了一个我们以前不知道的 bug。
我们先来了解一下我们缺少什么。
你的智能体故事
当你的智能体完成编码任务时,它会产生一个决策和行动链条:阅读此文件,分析该函数,修改此代码,运行这些测试。这个链条是智能体的轨迹,它讲述了智能体的运作方式。
轨迹很重要,因为它们会揭示智能体在哪里浪费了时间,在哪里偏离了轨道。它们会向你展示,智能体何时对同一个文件读取了 47 次,或者当你要求修正一个简单的 bug 时,它为什么重写了一半的代码库。简而言之,你无法改进观察不到的事务。
直到现在,我们依然都在使用这个简单的设置:
handleEvents {
onToolCallStarting { ctx ->
println("Tool '${ctx.tool.name}' called with args: ${ctx.toolArgs.toString().take(100)}")
}
}
在初期阶段,这没什么问题。它至少显示出了活动。但现在,它已经满足不了我们了。如果没有完整的形参和观察结果,我们就无法足够详细地了解智能体的行为。如果我们将所有内容都打印出来,控制台就会变得杂乱无章:对象转储、文件内容和错误消息全都混在一起。
我们需要更好的东西。
“仅仅开启日志记录”
我们先来试试显而易见的解决办法。Koog 具有内置的调试日志记录,因此我们将 Logback 从 ERROR 切换为 DEBUG 并再次运行:
三分钟后,几千行后:信息量很大吗? 是。方便吗? 否!
详细的日志有自己的用武之地。在生产中,它们可以协助进行事后剖析。当你想要在多次运行后获取见解和分析行为模式时,它们也很有帮助。但当你调试单次运行,试图了解你的智能体为什么陷入循环中时,你需要的是为人类构建的东西,而不是统计分析。
资金流向
虽然这些日志并不是理想的调试工具,但它们确实提醒了我们其他一些应该跟踪的事情:使用情况统计。OpenAI 的仪表板提供了每个键的 API 消耗明细。它能快速回答一个问题:我们的预算是否正在耗尽?
但它仍然没有回答开发过程中至关重要的问题:运行一次的成本是多少?
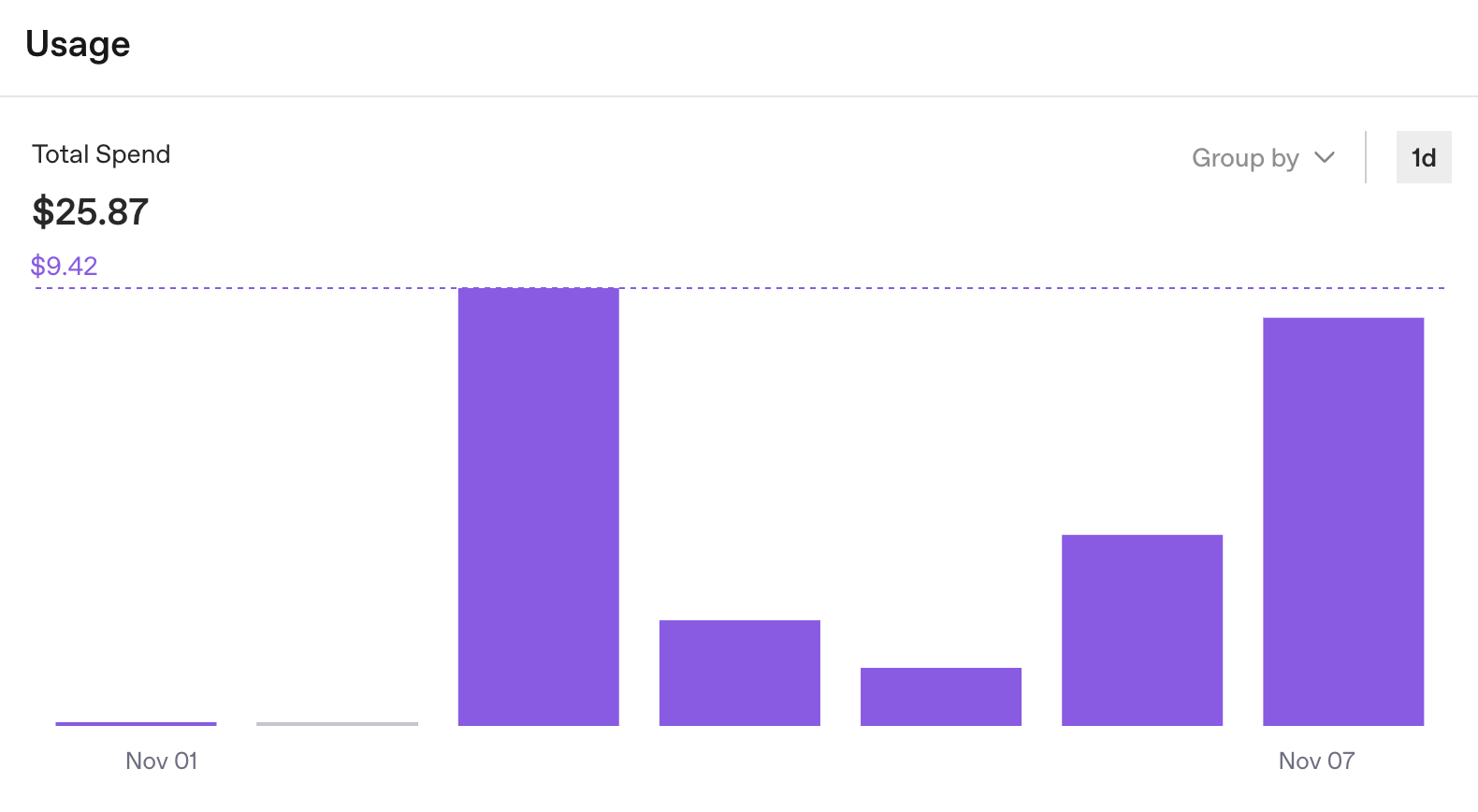
好的,一周 25 美元。有用,但并不全面。OpenAI 仪表板按照设计的方式运行:跟踪组织级别 API 的使用情况。但对于智能体开发而言,我们需要运行级别的见解。我们可以看到总计,但看不到哪些任务花费了 0.50 美元,哪些任务花费了 5.00 美元。
现在,增加更多移动部分。如果我们将工作分配给各个子智能体,并为特定步骤使用不同的提供程序(将在后续文章中讨论),我们最终会得到多个仪表板,而不是单一的一次运行真实成本视图。如果多个人共享相同的智能体设置,就会更难看出谁花了多少钱,花在了哪里。
API 密钥方法仅针对一个智能体、一个提供程序和次数有限的运行。这只是个开始,但它不能扩大规模。我们需要可观测性。
四行集成
我们不是第一个遇到这个问题的人。过去几年,围绕 LLM 应用和智能体形成了一个可观测性工具生态系统。有 Weights & Biases Weave 和 LangSmith 等专有工具,也有 Langfuse、Opik、Arize Phoenix、OpenLLMetry、Helicone、OpenLIT 和 Lunary 等开源选项。有些基于云端,有些支持自托管,还有一些两者兼备。每种都有自己的优点和缺点。
在评估了几个选项后,我们的团队选择了 Langfuse。做出这个决定要归因于以下实际因素:它是开源的,提供自托管选项(因此跟踪记录完全在你的掌控之中),它提供免费的云层级供你上手,用户界面使检查跟踪记录变得更加容易,而且当出现问题时,团队能够及时响应。
集成本身很简单。Koog 需要四行代码即可连接到 Langfuse:
) {
+ install(OpenTelemetry) {
+ setVerbose(true)
+ addLangfuseExporter()
+ }
handleEvents {
// existing handlers remain
}
}
就是这样。
关于 setVerbose(true) 的简短说明:Koog 默认仅发送遥测元数据。只有启用详细模式,才会发送完整的详细信息。提示和响应保持隐藏状态,这很有必要,因为跟踪记录可能包含客户数据。在智能体开发过程中,你往往需要完全的可见性,而详细模式可以实现这一点。
设置 Langfuse 大约需要五分钟。对于本文,我们使用的是他们的免费云实例,你也可以在 Docker 中本地运行整个堆栈。
- 在 cloud.langfuse.com 中创建帐户。
- 创建一个组织。
- 创建项目.
- 点击 Create API Key(创建 API 密钥)。
你将获得三个值:
export LANGFUSE_HOST="https://cloud.langfuse.com" export LANGFUSE_PUBLIC_KEY="" export LANGFUSE_SECRET_KEY=""
Koog 从执行环境中读取这些值。如果需要以代码形式传递它们,可以直接将其传递到 addLangfuseExporter。以下是我们启用了可观测性的完整智能体:
val executor = simpleOpenAIExecutor(System.getenv("OPENAI_API_KEY"))
val agent = AIAgent(
promptExecutor = executor,
llmModel = OpenAIModels.Chat.GPT5Codex,
toolRegistry = ToolRegistry {
tool(ListDirectoryTool(JVMFileSystemProvider.ReadOnly))
tool(ReadFileTool(JVMFileSystemProvider.ReadOnly))
tool(EditFileTool(JVMFileSystemProvider.ReadWrite))
tool(ExecuteShellCommandTool(JvmShellCommandExecutor(), PrintShellCommandConfirmationHandler()))
},
systemPrompt = """
You are a highly skilled programmer tasked with updating the provided codebase according to the given task.
Your goal is to deliver production-ready code changes that integrate seamlessly with the existing codebase and solve given task.
Ensure minimal possible changes done - that guarantees minimal impact on existing functionality.
You have shell access to execute commands and run tests.
After investigation, define expected behavior with test scripts, then iterate on your implementation until the tests pass.
Verify your changes don't break existing functionality through regression testing, but prefer running targeted tests over full test suites.
Note: the codebase may be fully configured or freshly cloned with no dependencies installed - handle any necessary setup steps.
""".trimIndent(),
strategy = singleRunStrategy(ToolCalls.SEQUENTIAL),
maxIterations = 400
) {
install(OpenTelemetry) {
setVerbose(true) // Send full strings instead of HIDDEN placeholders
addLangfuseExporter()
}
handleEvents {
onToolCallStarting { ctx ->
println("Tool '${ctx.tool.name}' called with args: ${ctx.toolArgs.toString().take(100)}")
}
}
}
第一条跟踪记录
我们从一个简单的任务开始:在你的项目中找到 main() 函数。运行该函数,等待其完成,然后在 Langfuse 项目中打开 Tracing(跟踪)标签页。
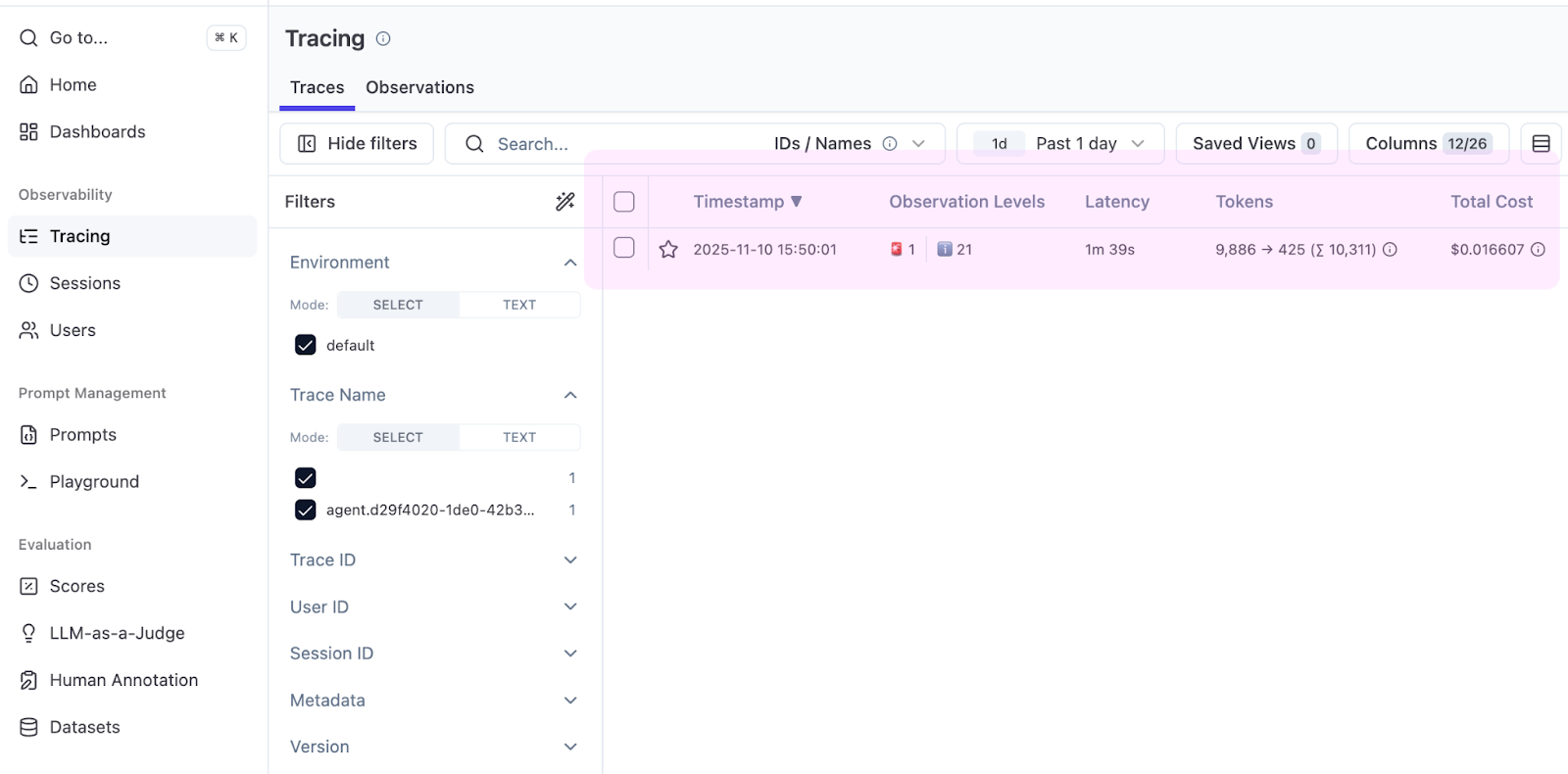
表格立即会显示一些有用的内容:Total Cost(总成本)列。Koog 会报告 token 计数,Langfuse 会应用定价,你可以看到查找 main() 需要 0.016 美元。
打开跟踪记录以查看完整运行。
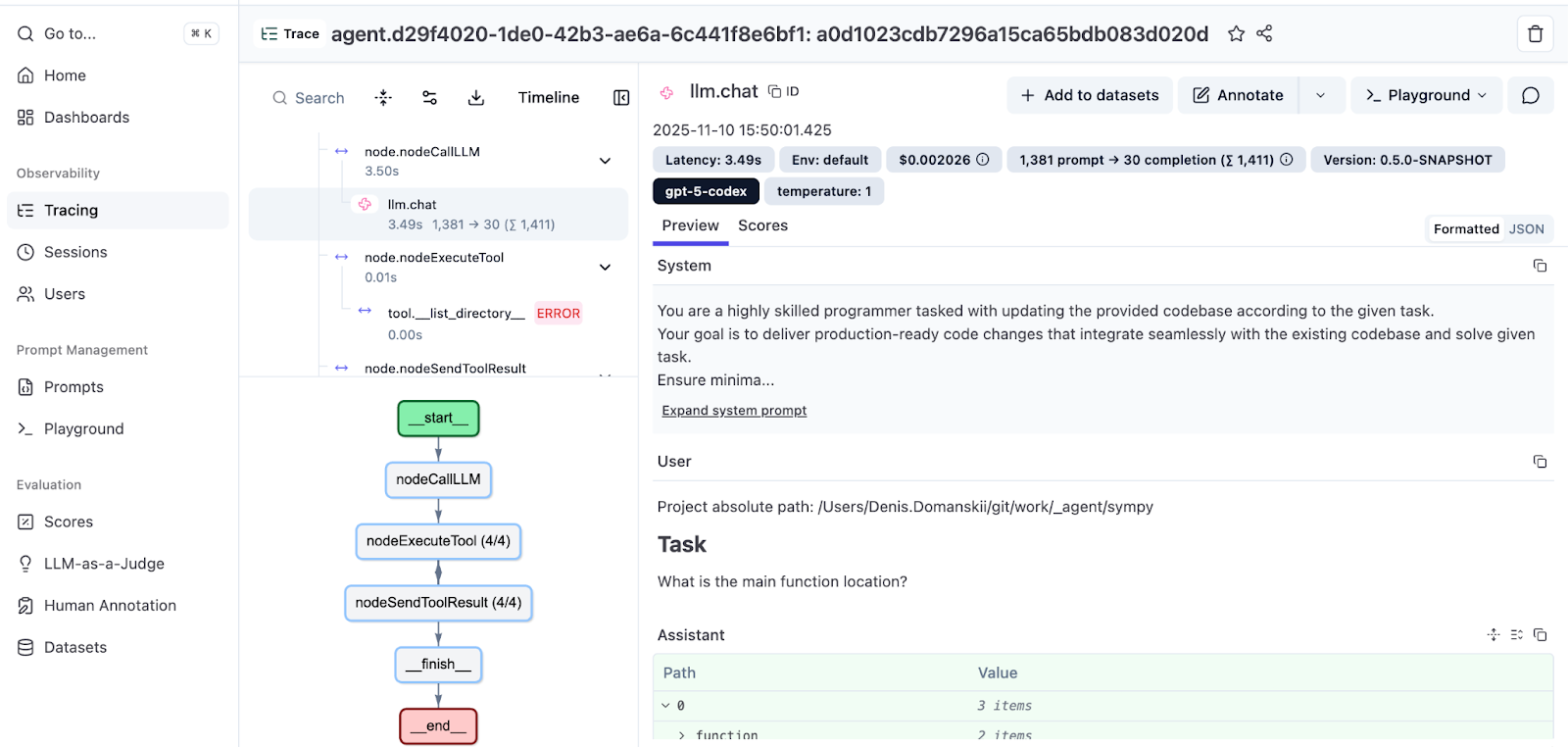
左侧面板按顺序显示智能体的轨迹:消息、工具调用和观察结果,缩进表示调用层次结构。右侧面板显示每个步骤的详细信息:提示、响应、工具形参和按 span 成本明细。
在底部,你还会看到一个执行图,后者直观地显示了这个流程。有关 Koog 基于图表的策略的更多信息,请参阅此文档。你也可以阅读 Koog 技术主管撰写的深入探究:Mixing the Secret AI Sauce: How to Design a Flexible, Graph-Based Strategy in Koog(混合秘制 AI 酱料:如何在 Koog 中设计灵活、基于图表的策略)。
通过可观测性发现问题
在为本文准备示例时,我们注意到一个失败的工具调用,它以红色高亮显示。
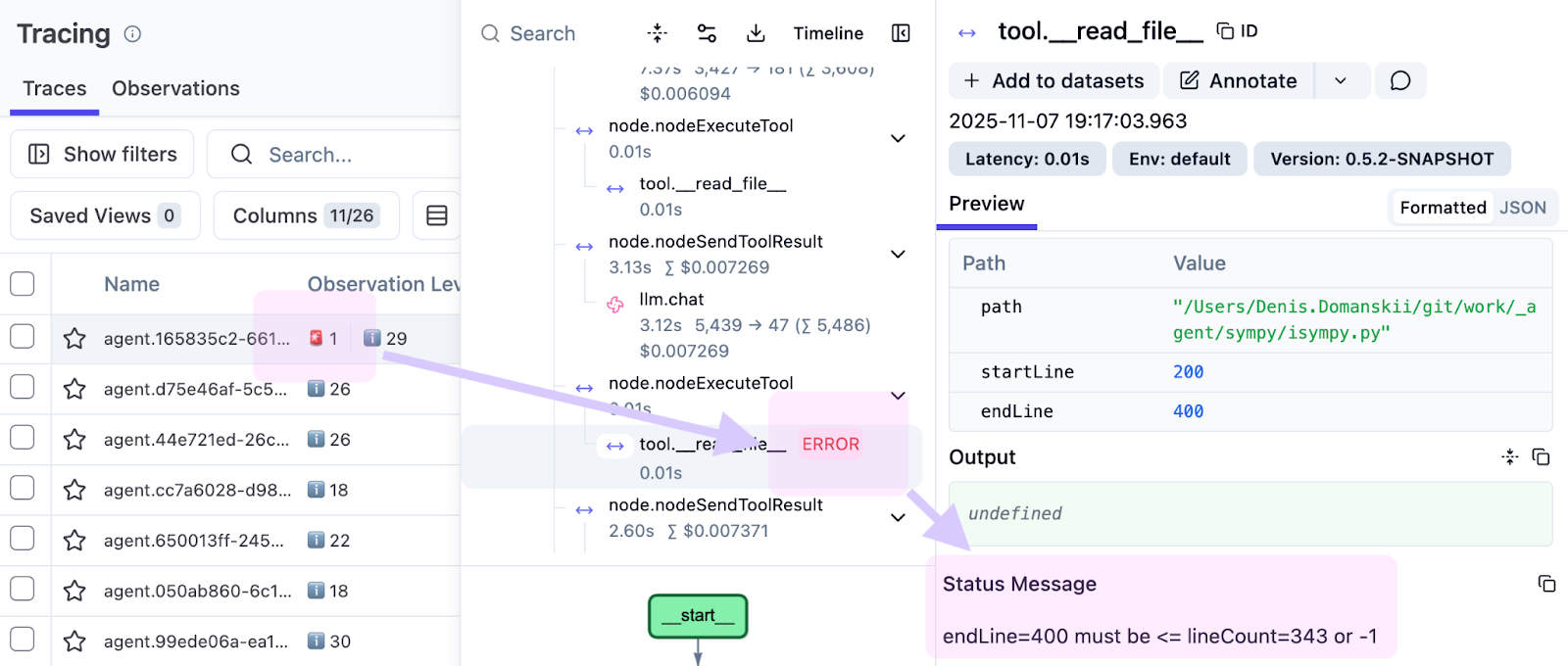
观察结果如下:
endLine=400 must be <= lineCount=394 or -1
智能体请求了 0–400 行,但该文件只有 394 行。这表明我们的工具实现存在局限性。它应该缩小范围并返回可用行 (0–394),而不是失败,从而允许智能体继续运行。如果没有跟踪记录,此类问题往往会被掩埋在日志中。有了跟踪记录,你可以在确切的运行、确切的步骤和确切的输入中看到它。
这就是可观测性很重要的原因。它不仅会显示哪里出了问题,还会显示怎么以及为什么会出现问题,使得修正变得更加容易。
处理评估运行
单个跟踪记录对调试来说已然足够,但评估运行需要批处理视图。
当你在多个 SWE-bench Verified 任务(编码智能体的标准基准)中运行智能体时,需要对跟踪记录和汇总成本进行分组。
Langfuse 通过会话支持这一点。添加会话 ID,作为跟踪记录特性:
install(OpenTelemetry) {
setVerbose(true)
addLangfuseExporter(
traceAttributes = listOf(
CustomAttribute("langfuse.session.id", "eval-run-1"),
)
)
}
使用此配置,通过该评估获得的跟踪记录会共享会话 ID。在 Langfuse 中,导航到 Sessions(会话)标签页,查看总持续时间和总成本。
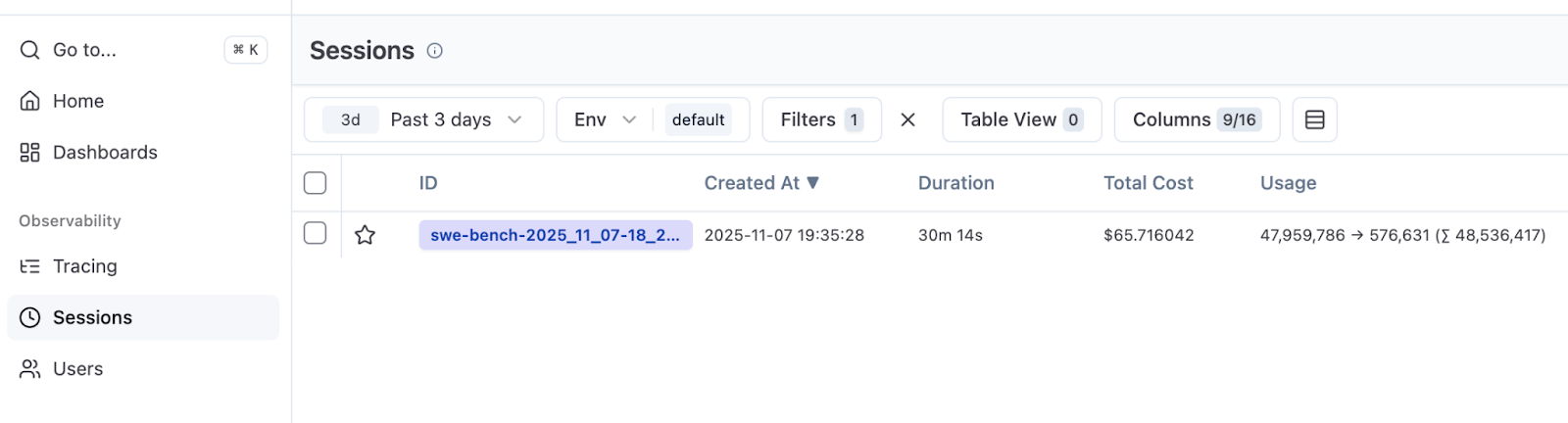
在我们的运行中,我们执行了 50 个 SWE-bench Verified 任务(共 500 个)。有 10 个并行实例,运行耗时 30 分钟,成本为 66 美元。这为未来的实验提供了基准:成功率、运行时间和成本。
Langfuse 默认情况下不显示成功分数。这在意料之中。跟踪会记录发生了什么,而不是运行是否通过。如果想要在 Langfuse 中获得成功指标,你的评估工具就需要对每次尝试进行评分并报告自定义分数。如果拥有配套的基础架构,就值得实现。
展望未来
可观测性不仅仅与调试有关。它也是你了解智能体行为的方式。
通过几行代码,我们就将智能体从一个黑盒子变成了可以检查的东西。我们发现了可能被忽视的行范围错误。我们了解到,我们的 50 次任务评估成本为 66 美元。现在,我们可以看到哪些任务消耗了 token,哪些任务高效运行。
在下一篇文章中,我们将介绍一个子智能体模式:将特定任务委托给更小、更便宜的模型。有了跟踪记录,你可以根据智能体在每次运行中执行的操作来决定委托哪些任务。不再胡乱猜测。
资源
感谢阅读! 我很乐意了解你自己的跟踪记录分析方法 – 你通过智能体的行为发现了什么模式? 有什么令你惊讶的事情吗? 欢迎在评论区分享你的经验!
本博文英文原作者:




