

JetBrains AI
Supercharge your tools with AI-powered features inside many JetBrains products
在 Kotlin 中构建 AI 智能体 – 第 4 部分:委托和子智能体

本系列的前几篇文章:
- 使用 Kotlin 构建 AI 智能体 – 第 1 部分:极简编码智能体
- 使用 Kotlin 构建 AI 智能体 – 第 2 部分:深入探讨工具
- 使用 Kotlin 构建 AI 智能体 – 第 3 部分:密切观察
在上一篇文章中,我们了解了如何设置跟踪,这给我们提出了两个新问题:根据此工具提供的信息,我们应该进行哪些尝试? 我们可以利用智能体的观察结果改进智能体的哪些部分?
我们最初的想法是试验子智能体,或者更具体地说,使用 find 子智能体。这将让我们有机会了解,Koog 如何使实现子智能体等常见模式变得更加容易。我们的假设是,find 子智能体可以在保持甚至提升性能的同时降低总体成本。
我们为什么会这样想呢? 导致成本上升的主要因素是上下文增长。每个 LLM 请求都包含从头到尾的完整上下文,这意味着每个后续请求都比前一个请求更昂贵(至少在输入 token 方面)。如果我们能限制上下文增长,尤其是在智能体运行的早期,我们或许可以显著降低成本。不必要的过大上下文也可能会分散智能体的注意力,使其无法专注于核心任务。因此,通过缩小上下文范围,我们甚至可能会看到性能的提升,尽管这很难预测。
find 功能特别适用于摆脱长期积累的上下文。在搜索某些内容时,你通常会打开许多不含目标内容的文件。纠结于那些死胡同毫无意义。记得你真正要找的是什么。可以把这看作是压缩智能体历史记录的一种自然方式(我们将在后续文章中探讨实际的压缩)。
这项任务也非常适合由子智能体来完成,因为它相对简单。这种简便性意味着我们还可以利用子智能体的能力使用不同的 LLM 模型。这种情况下,可以选择速度更快、价格更低的模型。这提供了常规压缩所不具备的灵活性。
当然,我们本可以构建传统的程序化工具来实现这一点。事实上,我们确实构建了一个名为 RegexSearchTool 的工具,但为了本次试验,我们将其放在了 find 智能体中,而不是直接放在 main 智能体中。这种方式在模型选择方面为我们提供了灵活性,同时也增添了一层额外的智能。
find 智能体
为了能够拥有子智能体模式,我们首先需要另一个智能体。我们已经在本系列文章的第 1 部分深入探讨了智能体创建,所以现在不会在这上面花费太多时间。不过,仍有一些细节值得注意。
首先,有一个小问题:我们为此子智能体使用的是 GPT4.1 Mini,因为它的任务要比 main 智能体简单得多,不需要使用功能同样强大的模型。
其次,了解此智能体可以访问哪些工具也很有用。与 main 智能体一样,它可以访问 ListDirectoryTool 和 ReadFileTool,但不能访问 EditFileTool 或 ExecuteShellCommandTool。我们还允许其访问前面提到的新程序化搜索工具 RegexSearchTool,这样,我们可以使用正则表达式模式来搜索文件夹及其子文件夹中的各种文件。
ToolRegistry {
tool(ListDirectoryTool(JVMFileSystemProvider.ReadOnly))
tool(ReadFileTool(JVMFileSystemProvider.ReadOnly))
tool(RegexSearchTool(JVMFileSystemProvider.ReadOnly))
}
有关详情,请查看此处的完整实现。
构建 find 子智能体
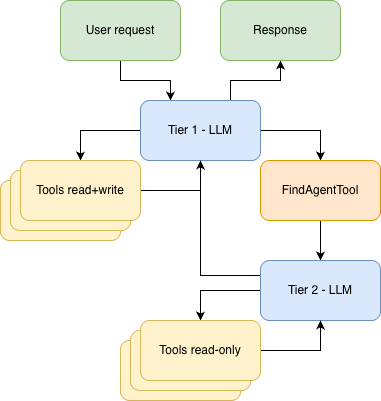
首先,什么是子智能体? 子智能体实际上非常简单;它是由另一个智能体控制的智能体。在这个具体的例子中,我们使用的是智能体即工具子智能体模式,其中子智能体在提供给 main 智能体的工具中运行。
事实证明,创建子智能体非常简单。我们知道工具本质上是一个与描述符配对的函数,智能体可以读取这些描述符来了解何时以及如何调用它。我们可以简单地定义一个工具,其 .execute() 函数会调用我们的子智能体。但 Koog 提供了一些工具,你甚至不必使用这些样板代码:
fun createFindAgentTool(): Tool {
return AIAgentService
.fromAgent(findAgent as GraphAIAgent)
.createAgentTool(
agentName = "__find_in_codebase_agent__",
agentDescription = """
""".trimIndent(),
inputDescription = """
""".trimIndent()
)
}
你可以认为它大致相当于:
public class FindAgentTool(): Tool() {
override val name: String = "__find_in_codebase_agent__"
override val description: String = """
"""
@Serializable
public data class Args(
@property: LLMDescription(
"""
"""
)
val input: String
)
@Serializable
public data class Result(
val output: String
)
override suspend fun execute(args: Args): Result = when {
output = findAgent.run(args.input)
Result(output)
}
}
无论哪种情况,我们唯一要做的就是:
- 创建子智能体。
- 给它起个名称 (
agentName)。 - 通过
agentDescription提示指定何时调用该智能体。 - 通过
inputDescription提示指定如何调用该智能体。
提示或许是最棘手的部分。有很大的空间可以微调。但有迹象表明,较新的 LLM 不太需要精确的提示,因此可能不值得我们花费时间对提示进行完美的调整。我们自己仍在探索这个课题,还需要进行更多尝试才能得出强有力的结论。
我们注意到的一点是,如果我们不谨慎地对待提示,main 智能体有时会将 find 智能体与简单的 Ctrl+F / ⌘F 功能搞错,仅发送它要查找的 token。这显然不是理想之选。由于上下文信息太少,find 智能体无法推断它实际应该查找什么。为了解决这个问题,我们加入了一些指令,要求 main 智能体指定它为什么要找这个内容。这样,find 智能体就可以充分利用其智力来查找 main 智能体要找的实际内容。
""" 此工具由智能微智能体提供支持,可以分析和理解代码上下文,从而查找代码库中的特定元素。不同于简单的文本搜索 (Ctrl+F / ⌘F),它可以智能地解释你的查询,找到最符合你的意图的类、函数、变量或文件。它需要一个详细的查询,描述要搜索什么、为什么需要这些信息,以及定义搜索范围的绝对路径。... """
| 带高亮显示的查询(不是 Ctrl+F /⌘F) | 不带高亮显示的查询(不是 Ctrl+F /⌘F) |
|---|---|
在 get_Search_results 中搜索关于不必要的 joins 操作的更改,查看是否有关于不必要的 joins 操作的注释或逻辑。 |
get_search_results |
在仓库中使用 SKLEARN_ALLOW 或类似查询搜索环境变量的用法,以查找绕过 check_build 的潜在方法。 |
SKLEARN_ALLOW |
我们还注意到,main 智能体有时仍会选择使用 grep 命令而不是 find 智能体来调用 shell 工具,这完全违背了我们设立专门的子智能体的初衷。为了避免出现这种情况,我们在主系统提示中添加了以下部分:
""" ... 你还可以使用智能的 find 微智能体,它可以帮你找到代码组件和其他构造,而且比你自行查找更加便宜。可以将其用于任何搜索操作。不要为查找任务执行 shell 命令。... """
这就是我们在文章开头提到的“自然压缩”。find 智能体会打开许多文件,陷入死胡同,并探索代码库。但 main 智能体只查看结果:相关的文件路径、代码段和解释。所有这些探索都保留在 find 智能体的上下文中,并在其返回后消失。只有真正重要的内容才会被添加到 main 智能体的上下文中。
取舍
使用子智能体有其优点,但也有缺点。这无疑是一种值得尝试的改变,以证明它能否在不付出太多代价的情况下提供我们所期望的好处。
第一个缺点是成本和时间。虽然缩短主线程中的上下文有助于降低成本和缩短时间,但我们现在也不得不为子智能体中的许多 LLM 调用支付费用并等待其完成。我们希望总成本和时间更少,但这取决于 main 智能体如何使用子智能体。如果它最终执行了大量小型查询,这个优点可能无法实现。我们将在后续章节中再次运行基准测试时查看成本,而且我们假设成本与时间相关。
我们确实注意到在某些运行中发生了这种情况,因此我们在该工具的 agentDescription 中添加了一个部分,用于向 main 智能体解释这一问题,并试图限制大量小型查询的执行频率:
""" ... 虽然此智能体在执行搜索方面比使用 shell 命令更加经济高效,但它在不同的搜索之间会丢失上下文信息。因此,最好将类似的搜索合并为一个调用,而不是多次调用此工具。... """
第二个缺点是,这种方式对上下文保留的处理方式比人类要“非黑即白”得多。我们可能无法将过去发生的所有事情都存储在我们的记忆中,但我们会对所发生的事情留有模糊的印象,并在需要时检索更多背景信息。可以通过多种方式模拟这种行为,但它们远远超出了我们当前版本的智能体的范围,并且与智能体记忆这一深刻而复杂的主题更相关。
另一项挑战是它增加了跟踪的复杂性。在 Langfuse 中,我们不再只需要查看一个智能体的跟踪记录。事实上,我们甚至可能需要从多个角度来看待该行为 – 即包括完整视图,也包括每个智能体。
拓宽思维:工程团队比照
这种使用子智能体的技术并不局限于像 find 智能体这样的简单情况。例如,你可以通过将分析、实现、测试和规划指定给不同的子智能体,复制团队结构中的关注点分离。
拥有所有这些能力的智能体比将这些能力指定给子智能体的系统表现得更好还是更差,仍然是一个悬而未决的问题,但其潜在的好处并不难想象。想想康威定律:“设计系统的架构受制于产生这些设计的组织的沟通结构。” 一种解释是,这些沟通结构会不断演变,直至发现值得保留的高效模式。反向的康威策略甚至表明这是可取的。
角色分配是否也是如此? 或许,软件团队中不同专业人员之间的任务分工也在不断演变,以探索高效的工作方式。或许 LLM 也能从中受益。
但也不一定。效率的提高可能很大程度上源于人类学习过程的传播,但这可能并不适用于 LLM。但在 Clean Code 这本书中,我们了解到不同角色的概念:编写者角色(创建者)、阅读者角色(维护者)和测试者角色(测试者)。其中的理念是专注于一个角色,不受他人观点的干扰。这表明任务划分不仅仅是学习效率的问题,这意味着它可能与 LLM 密切相关。
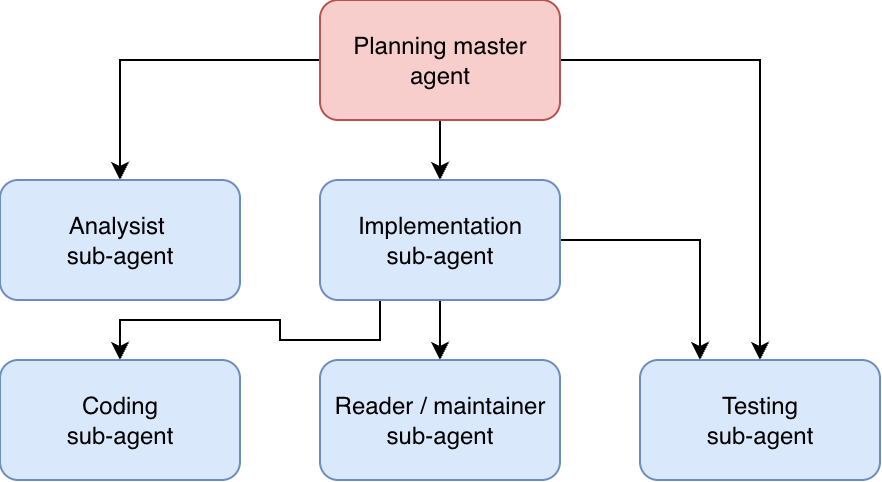
这一切都表明,你可以更进一步发挥子智能体的作用,但这是否是一种有益的方式仍有待证明。目前,它仍然是一种艺术形式,而不是纯粹的科学。
基准测试结果:测试假设
我们很高兴地报告,没有使用 find 子智能体的版本成本约为 814 美元,即每个实例 1.63 美元;而使用此子智能体的版本成本约为 733 美元,即每个实例 1.47 美元。成本节省了 10%,这绝对值得注意。
我们观察到一件有趣的事情,这个结果很大程度上取决于为子智能体选择的 LLM。在一个小规模的尝试中,我们尝试让子智能体与 GPT-5 Codex 保持连接,这使得 50 个样本的平均成本大幅增加到每个示例 3.30 美元。
| 试验 | 成功率 | 每个实例的成本 |
| 第 3 部分 (Langfuse) | 56% (278/500) | 1.63 美元(814 美元/500) |
| 第 4 部分(子智能体 GPT4.1 mini) | 58% (290/500) | 1.47 美元(733 美元/500) |
| 第 4 部分(子智能体 GPT-5 Codex) | 58% (29/50) | 3.30 美元(165 美元/50) |
不过,有趣的是,我们假设了两种降低成本的方式。第一种方式是通过任务交接实现的自然压缩来缩减上下文大小,第二种方式是将工作转移给更便宜的模型。数据表明,简单地拆分一个子智能体(并保留 GPT-5 Codex 模型)实际上会显著增加成本,因此,我们的第一种方式似乎行不通,而第二种方式(更便宜的模型)似乎确实有效 – 尽管这可能不是严格的证据。
在性能提升方面,我们看到了从 56% 到 58% 的小幅提升。这或许在容许的统计误差范围内,但令人鼓舞的是,在我们降低成本的同时,性能至少保持了稳定。
结论
我们看到,创建子智能体既操作简单,功能也可能很强大。Koog 提供了便捷的工具来进一步简化流程,你只需定义智能体即工具的提示即可。
显然,这项技术可以显著降低成本。我们实现了将近 10% 的降低 – 改进很明显,而且可衡量。对性能的影响尚不完全清楚,但似乎在这方面也可能会有所提升。
同时,这种评估费用高昂。即使成本降低,这项基准测试的总成本依然高达 730 美元。因此,在下一篇文章中,我们将更深入地探讨另一种降低成本的策略:一种更通用的压缩方式。届时,我们将回答以下问题:“如何防止你的上下文无限增长,以及与之相关的成本增长?”
本博文英文原作者:




