JetBrains AI
Supercharge your tools with AI-powered features inside many JetBrains products
Mellum2 开放源代码:适用于 AI 工作流的快速模型

Mellum2 从零开始训练,专为实际部署而设计,旨在用于软件工程系统中的路由、问答、子智能体和私有 AI。
今天,我们将开放 Mellum2 的源代码,它是一个 120 亿参数的模型,专为解决生产 AI 中的延迟、吞吐量和成本这三大最棘手的挑战而设计。Mellum2 从零开始构建,基于 Apache 2.0 许可证发布,为您的基础架构提供高性能、高性价比的替代方案。
Mellum 最初用于代码补全;如今已演进为可以同时处理自然语言和代码。它现在是一款多功能工具,能够为现代 AI 工作流中的路由、总结和中间推理步骤提供支持。
无论您想要试验、微调还是大规模部署,Mellum2 都可以随时在您自己的系统中运行。
架构与性能
Mellum2 通过自身架构和侧重于效率的设计,专为解决生产级系统的瓶颈而打造。
- 混合专家 (MoE) 设计: 模型共有 120 亿参数,但由于其采用 MoE 设计,每个 token 仅有 25 亿参数处于激活状态。此设计在降低计算成本的同时,可以对实时工作负载进行高吞吐量、低延迟推理。
- 专属侧重点:与很多现代模型不同,Mellum2 并非多模态模型, 它专门针对自然语言与代码数据进行训练。这种专门化可以确保模型在软件工程环境中表现出色,同时保持轻量和高速。
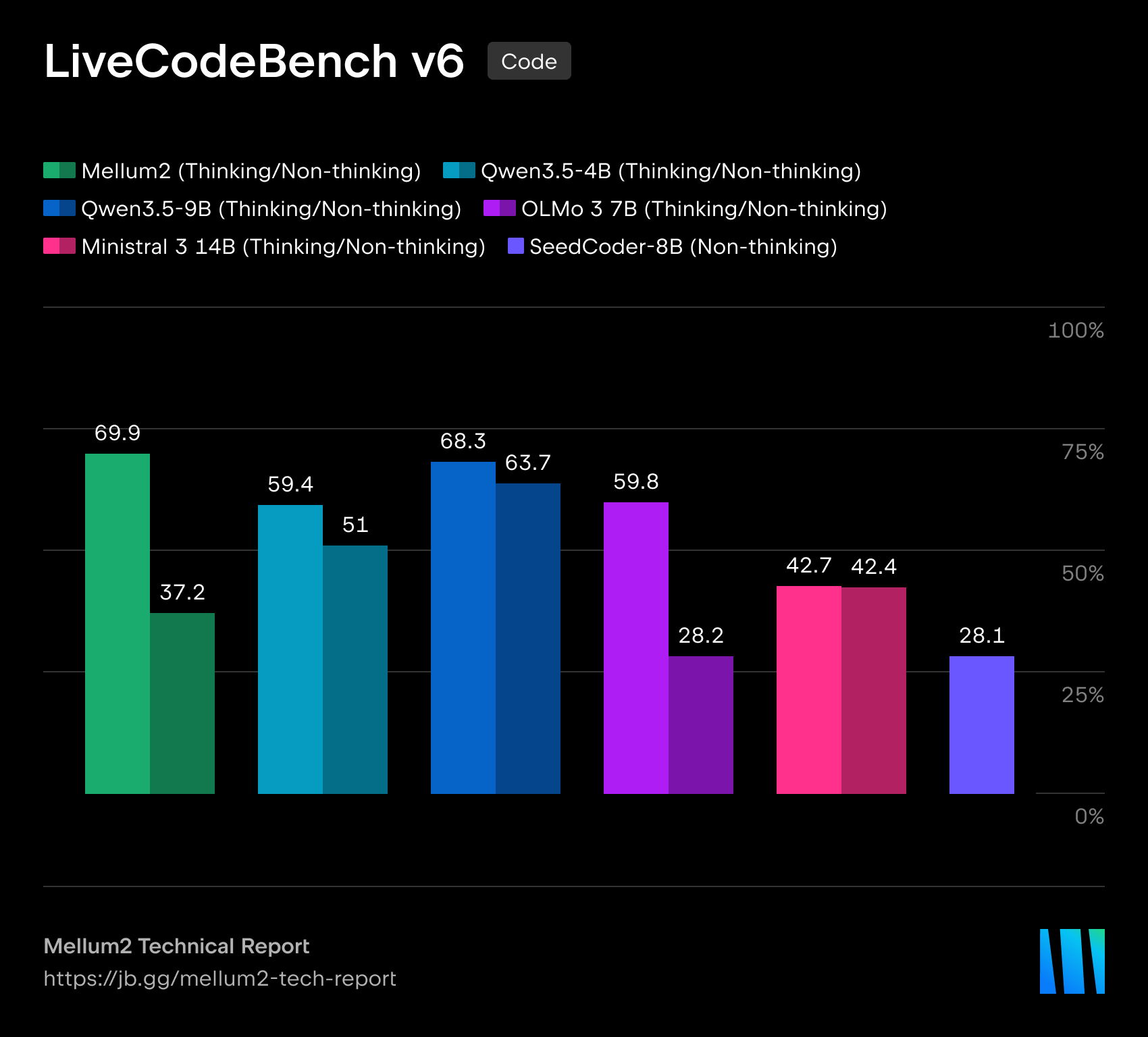
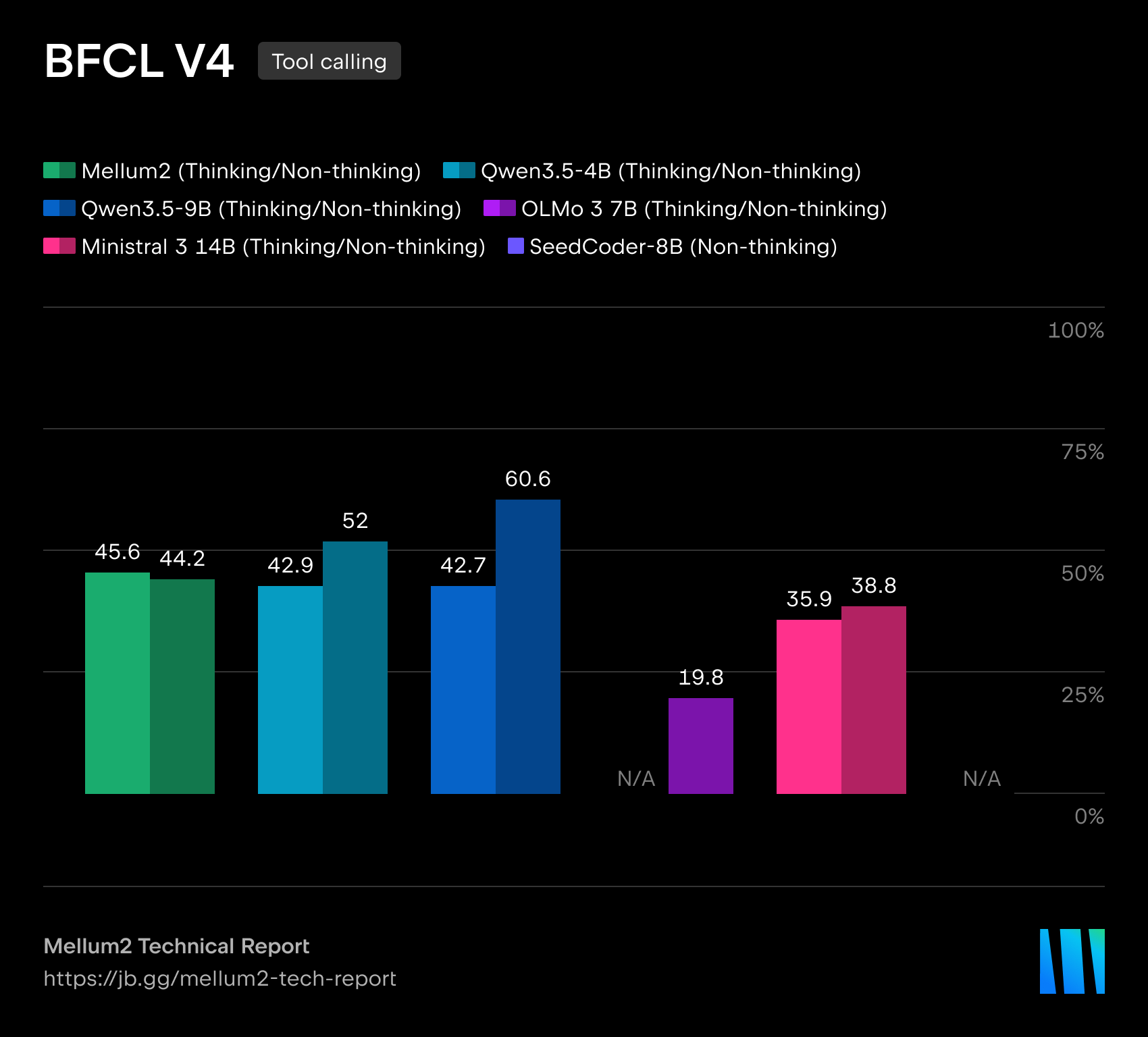
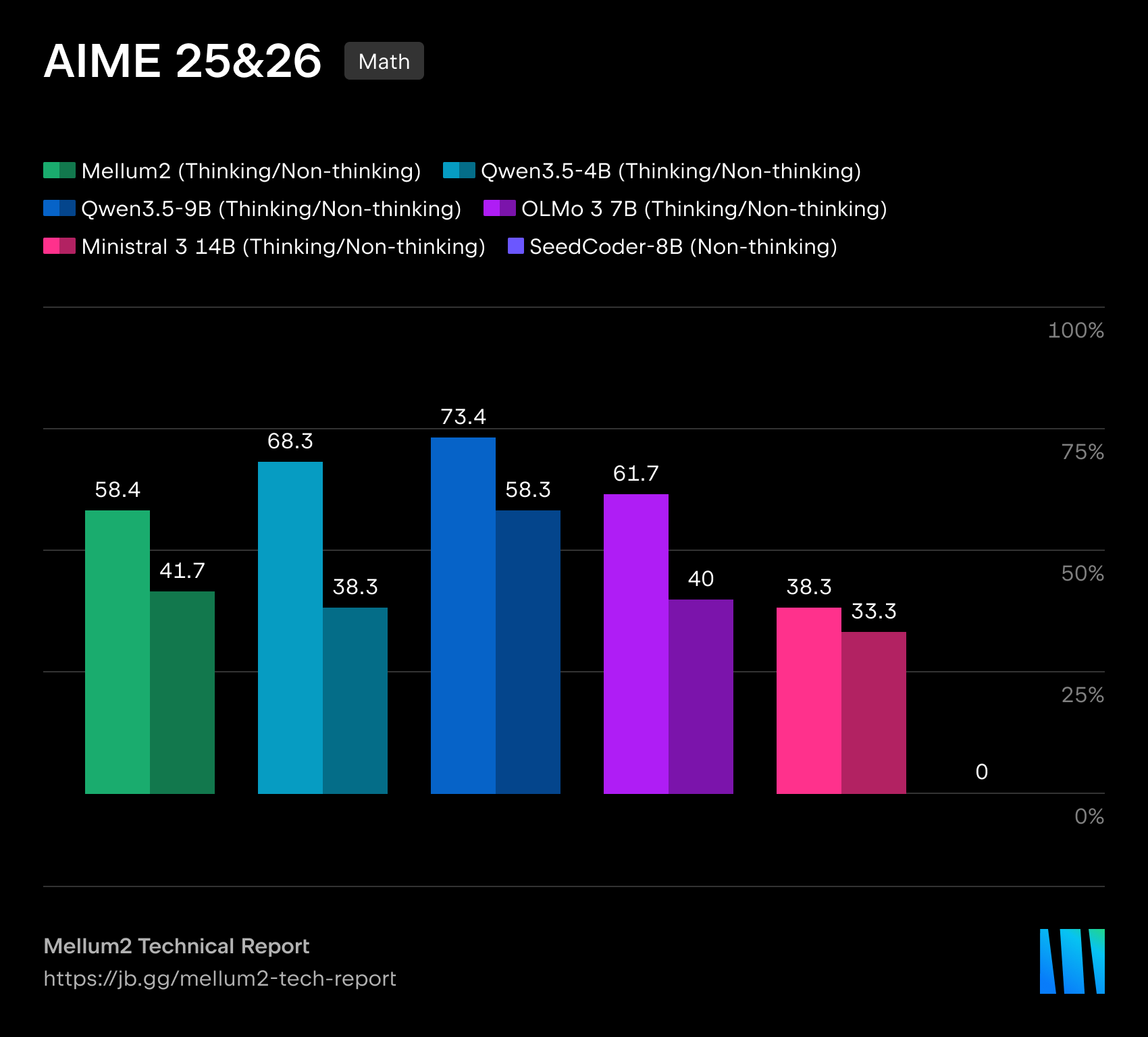
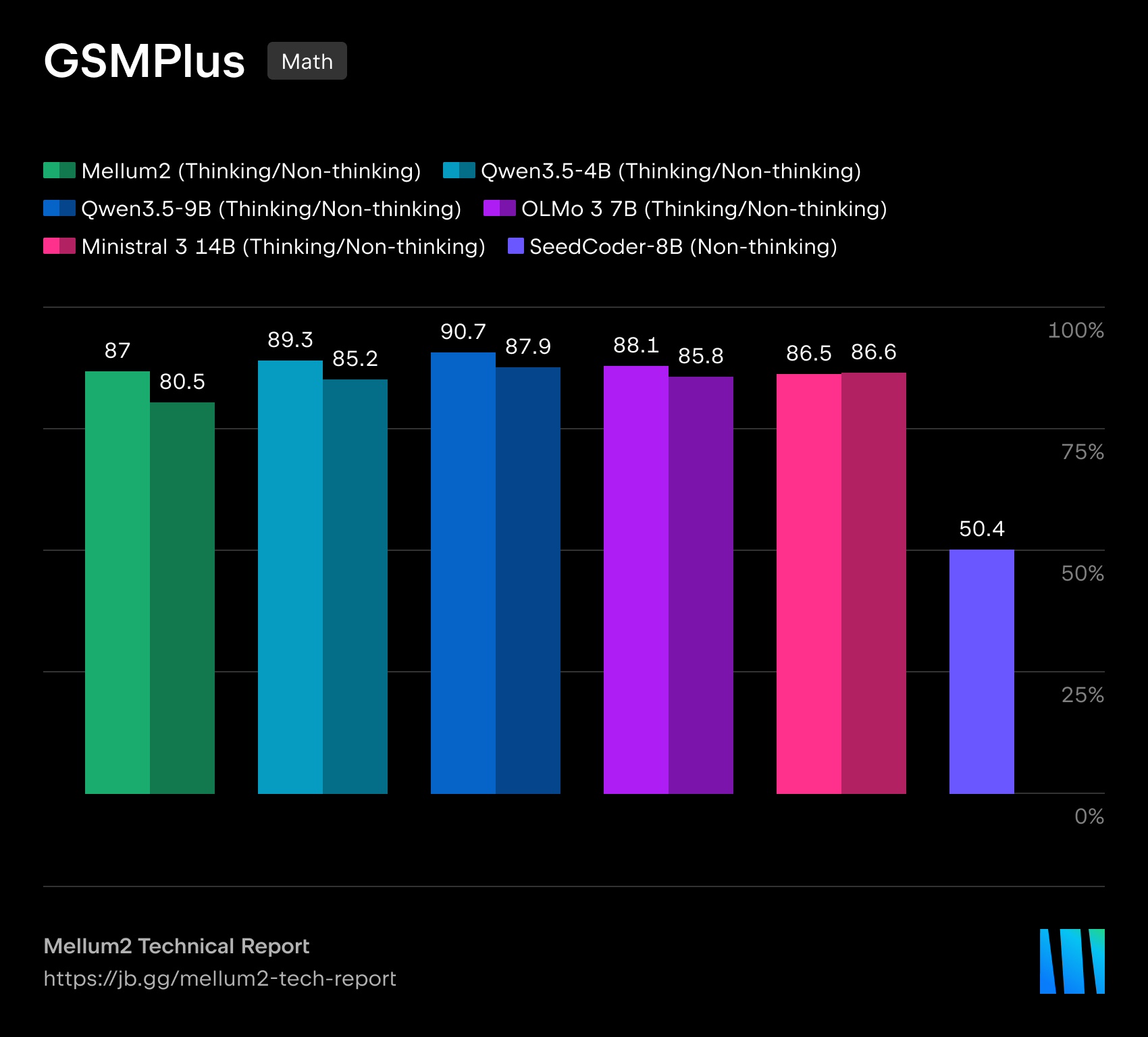
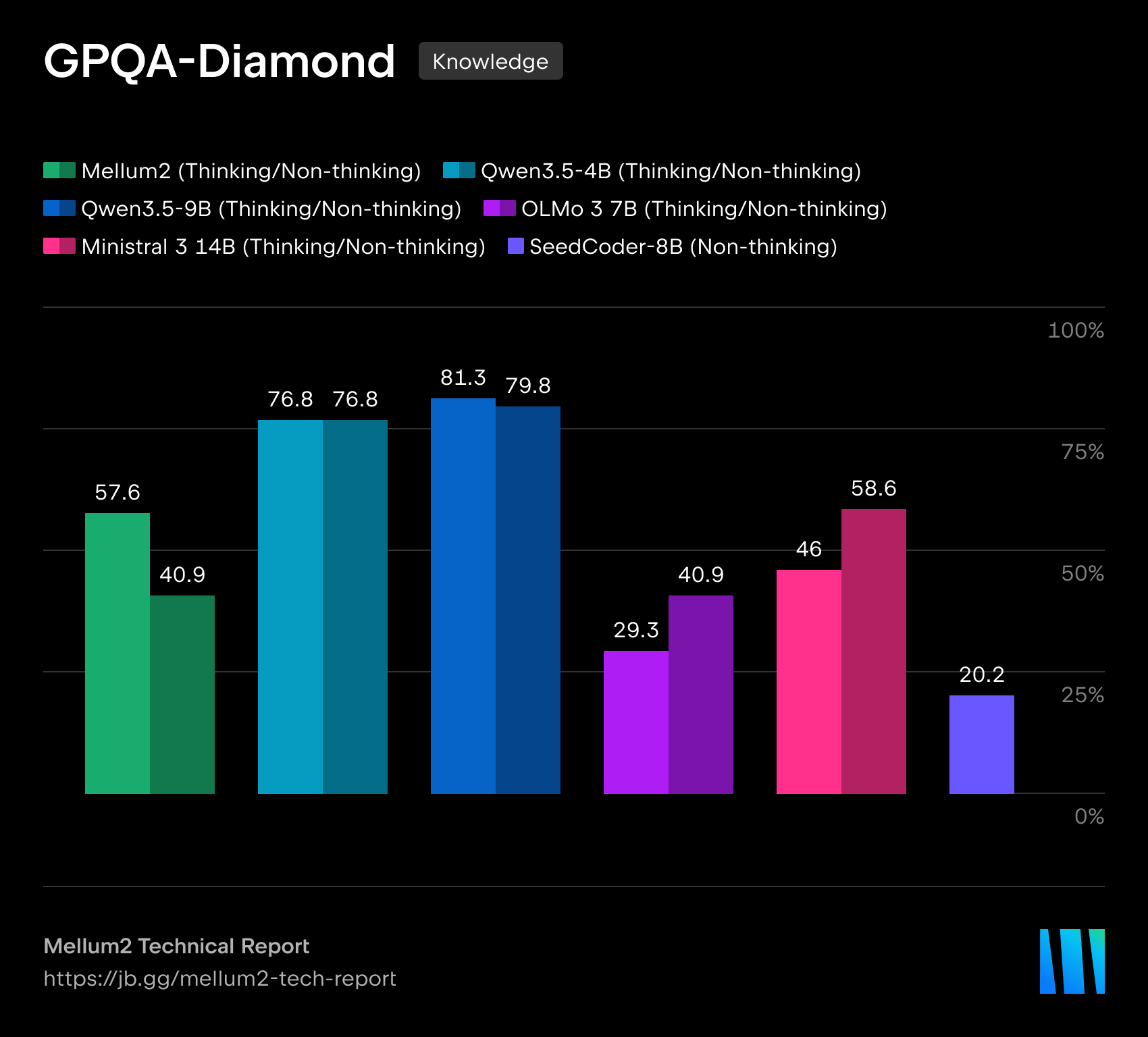
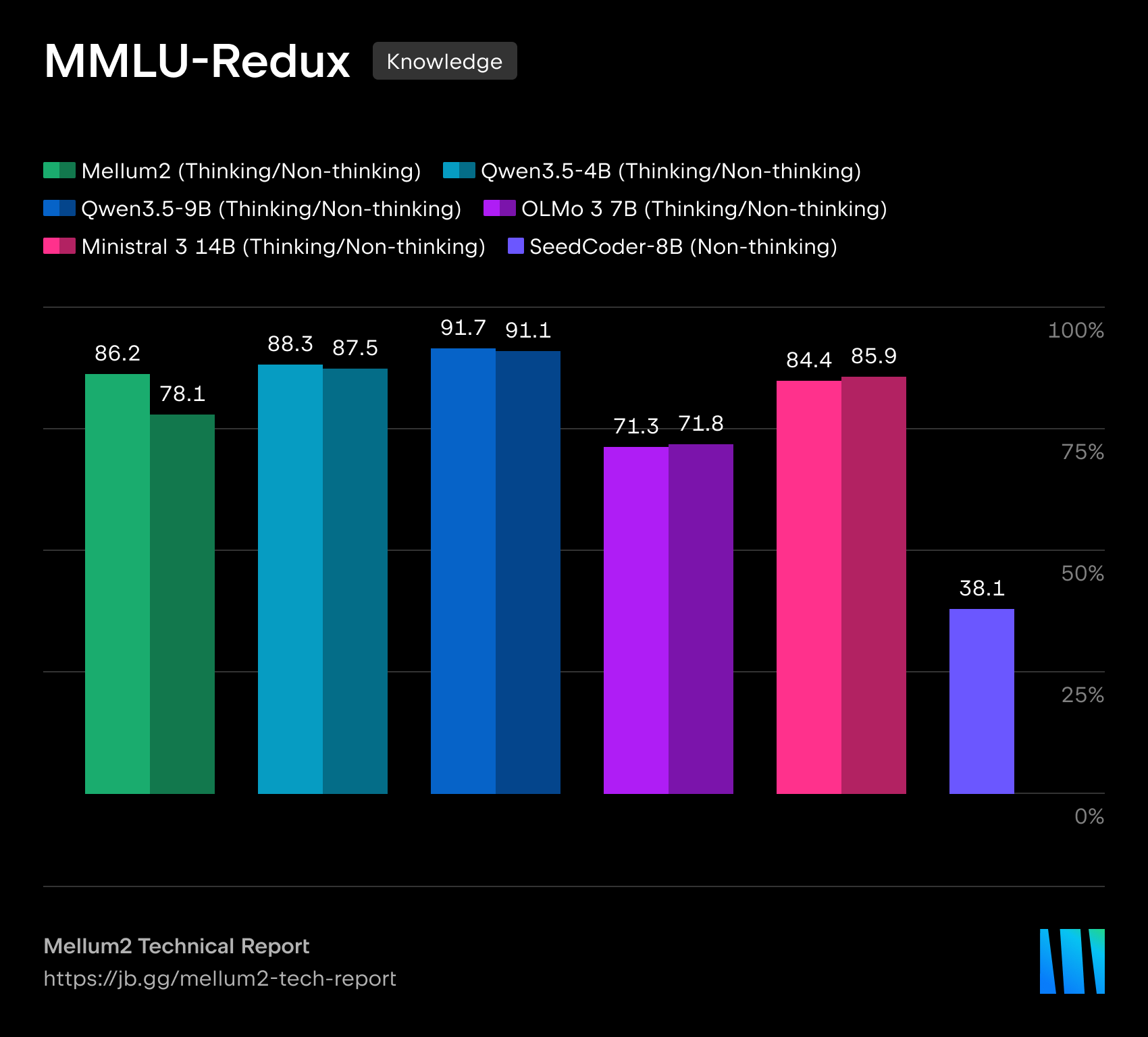
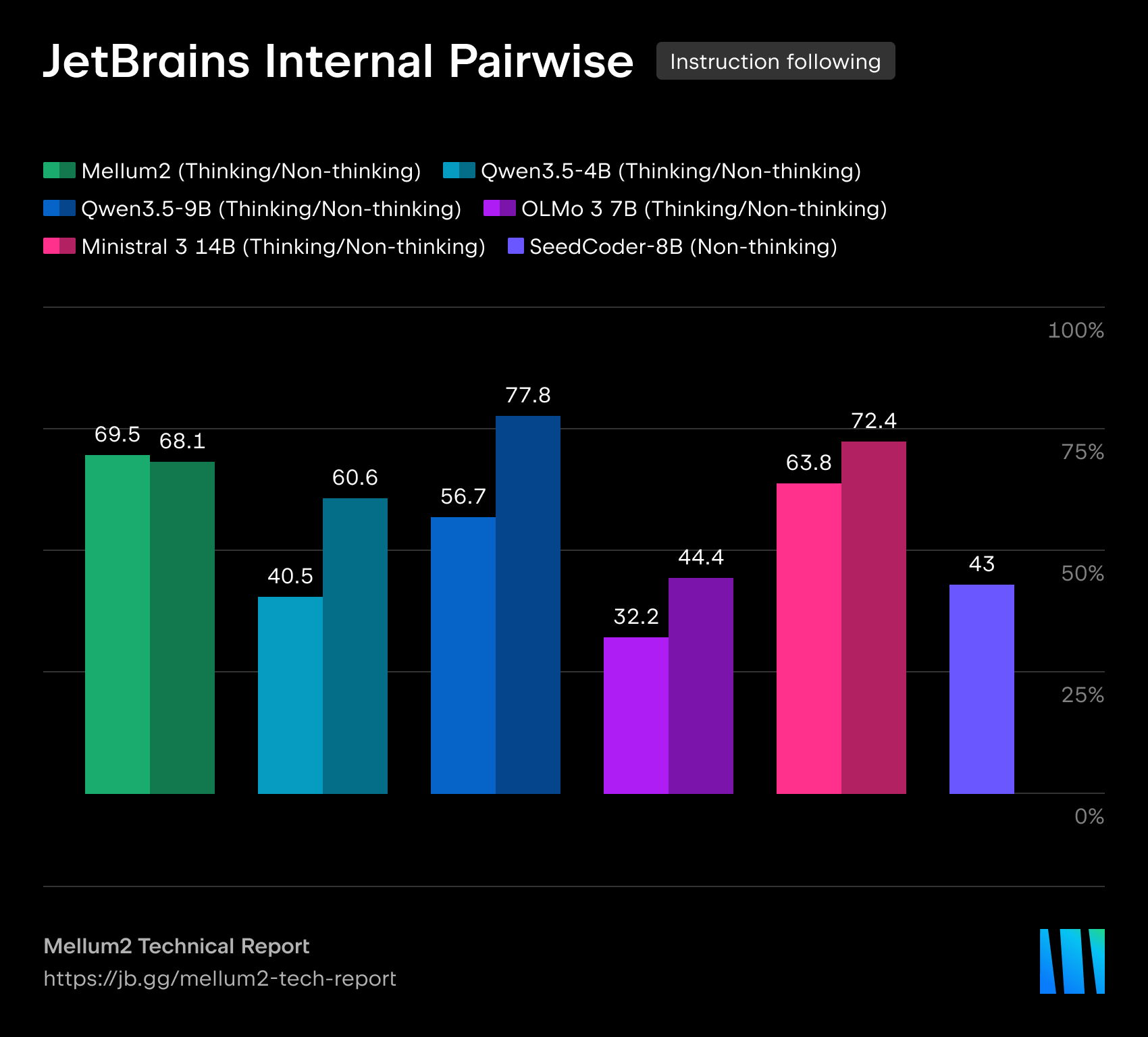
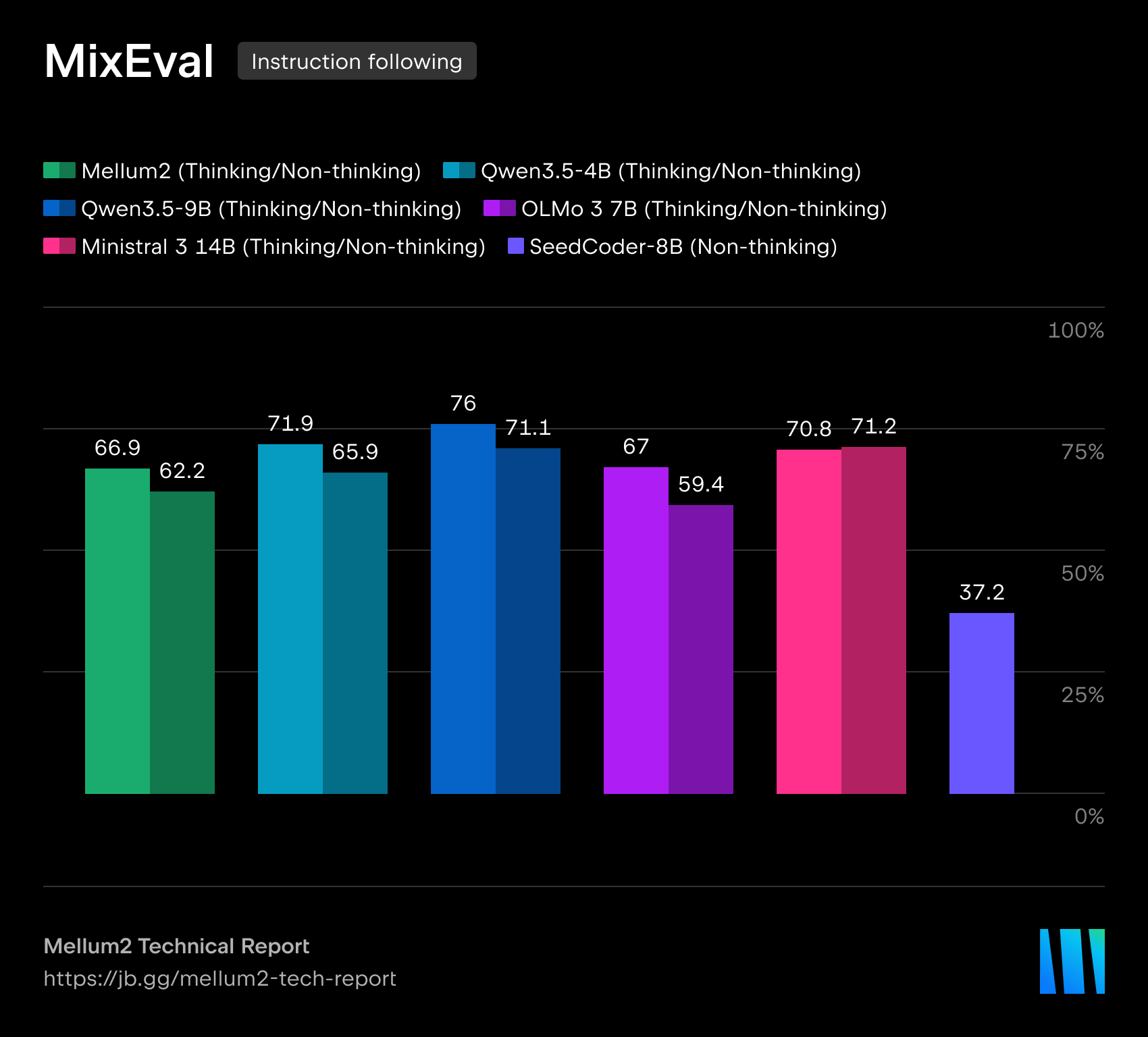
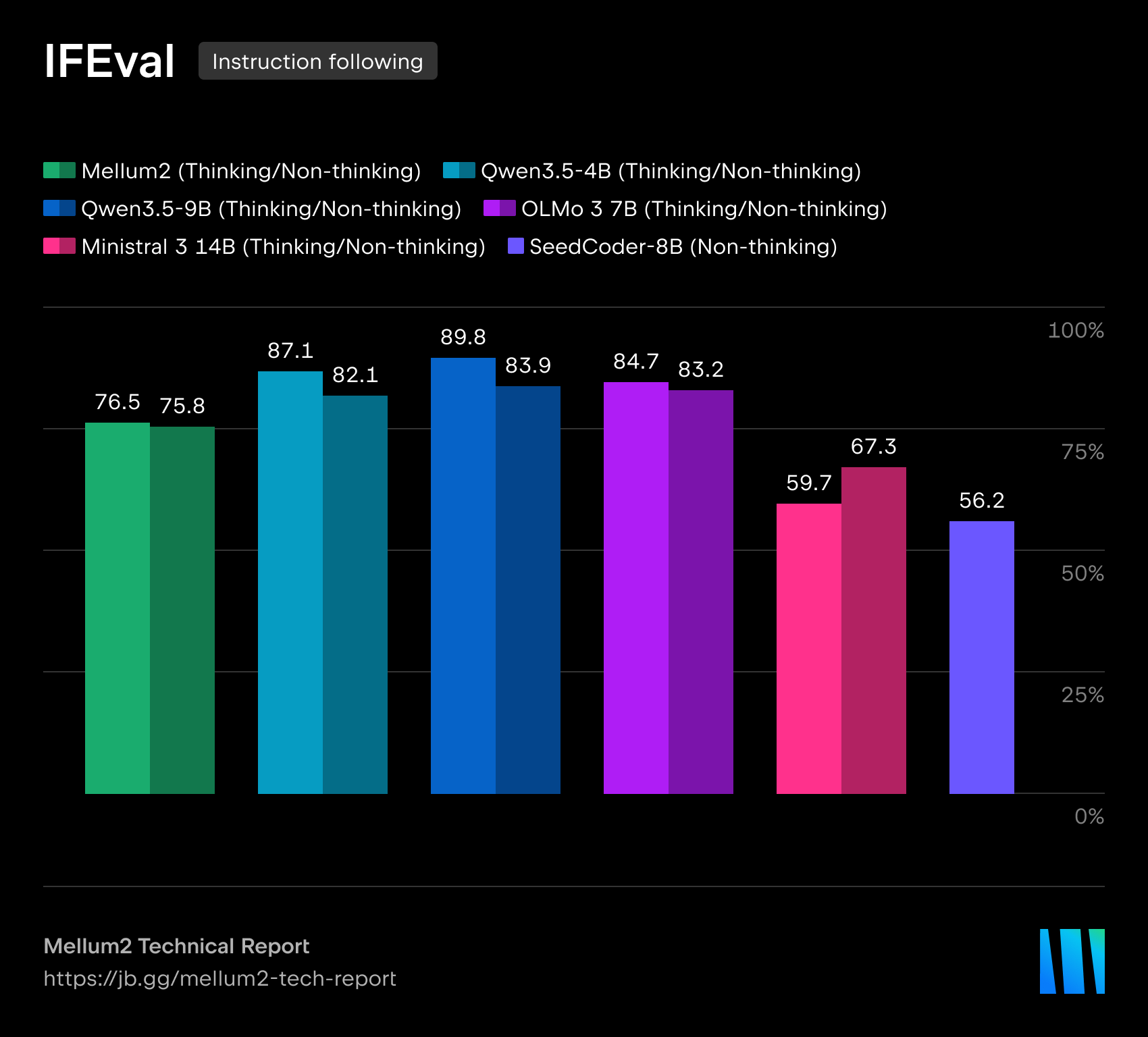
在我们的技术报告中,我们详细介绍了模型在代码生成、科学、数学和推理基准测试中的表现。Mellum2 在与同规模模型的竞争中不落下风,同时将推理时间缩短至不到一半 — 这对生产级部署来说是一项决定性优势。
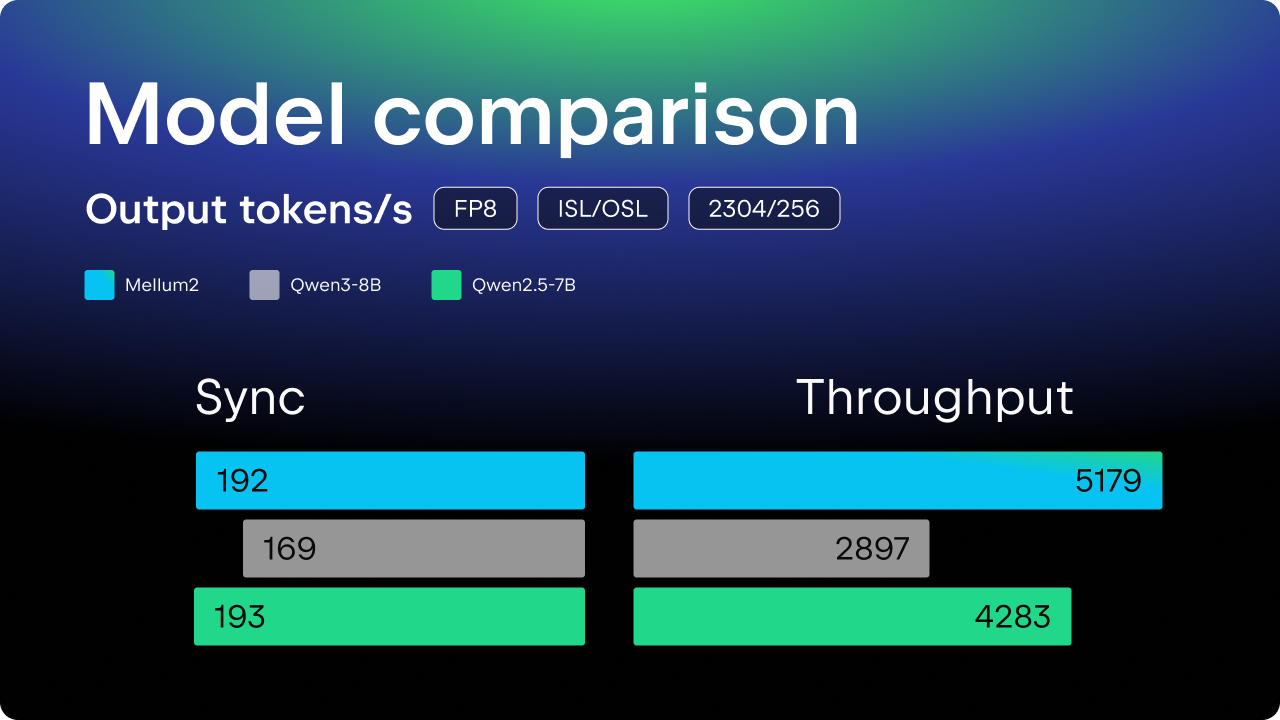
Mellum2 的主要用例
- 路由和编排 AI 工作负载:使用 Mellum2 分析传入提示,帮助为每项任务选择合适的模型或工具。
- 构建低延迟 RAG 流水线:检索相关上下文、使用 Mellum2 进行总结,并即时生成回答。
- 为复杂工作流中的快速子智能体提供支持:将智能体流水线拆分为多个步骤,例如上下文收集、规划和验证。使用 Mellum2 执行快速、专门的任务,而不依赖于单个大模型。
- 实现私有、本地 AI 部署:在本地运行 Mellum2 或进行自托管,以确保代码和数据完全在您的掌控之中。
“焦点模型”理念:为什么专注式模型的可扩缩性更好
随着 AI 系统日益复杂,性能瓶颈已从原始能力转向大规模部署时的延迟、吞吐量和成本。并非每项任务都需要规模最大的模型。现代 AI 系统中的许多步骤都是重复的、对延迟敏感且高频。这些步骤更适合通过可以高效实现路由、托管和控制的快速可靠的模型来处理。
JetBrains 相信未来属于协同系统,而非单一模型。前沿模型将继续突破极限,但实用的 AI 产品同样需要焦点模型:能够高效处理高频任务的快速、专用组件。
这就是我们对 Mellum2 在下一代 AI 软件工具中所扮演角色的看法。
开始使用 Mellum2
如果您正在为软件工程构建 AI 系统 — 无论是在 IDE 内部、RAG 流水线中、作为智能体工作流的一部分,还是完全在您自己的基础架构上 — 我们都非常希望您尝试 Mellum2。
开源是打造更出色工具的方式。
本博文英文原作者: