

Kotlin
A concise multiplatform language developed by JetBrains
使用 Kotlin DataFrame 执行数据分析的分步指南

简介
我们将利用一个教程系列介绍如何使用 Kotlin DataFrame 和 Kandy 库轻松操作和直观呈现数据,这是系列的第一部分。 教程面向普通 Kotlin 开发者,因此您不需要具备数据分析或类似框架(如 pandas 或 Apache Spark)的经验。 不过,您应该熟悉 Kotlin 语言,并且已经在 IntelliJ IDEA 中创建过基于 Kotlin 的项目。
在本教程中,您将学习:
-
-
- 如何从 CSV 文件创建 DataFrame。
- 如何执行常见操作。
- 如何显示或导出结果。
-
您将在 Kotlin Notebook 中工作,既方便又能访问 Kandy 绘图库。 您将看到的核心 DataFrame 功能在基于 Gradle 的项目中可用。
您可以直接跳转到示例项目,其中包含本系列所有教程的数据文件和 Notebook。 不过,刚接触 DataFrame 的开发者最好从头开始,一步一步自己动手构建。 然后,您可以将您的项目与示例项目进行比较,确保构建正确。
所有教程都使用真实世界数据,在本例中,包含 Stack Overflow 上排名最靠前回答者的信息。 请注意,下面显示的结果对于撰写本文时下载的数据以及示例项目中包含的数据是正确的。 如果您获取的是新鲜数据,那么其中自然可能包含更新的值。
示例数据
您可以通过 StackExchange Data Explorer 获取示例数据。 这样一来,您可以针对一系列问答网站(包括 Stack Overflow)运行示例查询。 查询的结果可以作为 CSV 文件下载。
这个示例查询基于问题回答计算出的平均分数选择 Stack Overflow 上排名前 500 的用户。 使用 Run Query(运行查询)按钮执行查询,然后通过 Download CSV(下载 CSV)链接保存结果:
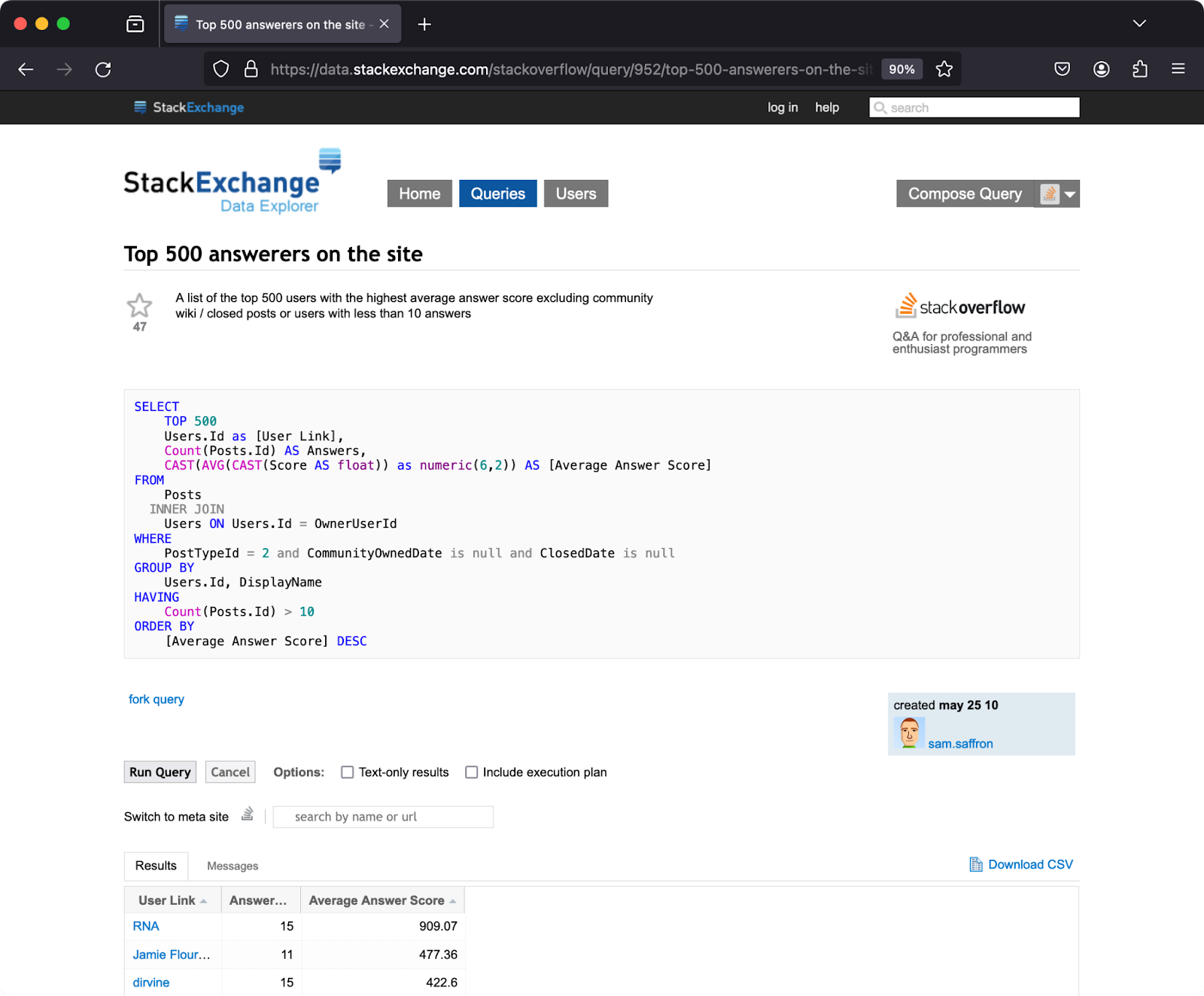
下载文件后,将其保存为 Top500Answerers.csv。
创建您的项目
打开 IntelliJ IDEA 并安装 Kotlin Notebook 插件,如这篇博文所述。 然后,使用 New Project(新建项目)向导创建一个新的 Kotlin 项目,并使用 Gradle 作为构建工具。
将您在上一节中创建的 CSV 文件复制到 src/main/resources 中。 您应该能够在文本或数据视图中打开该文件,如下所示:
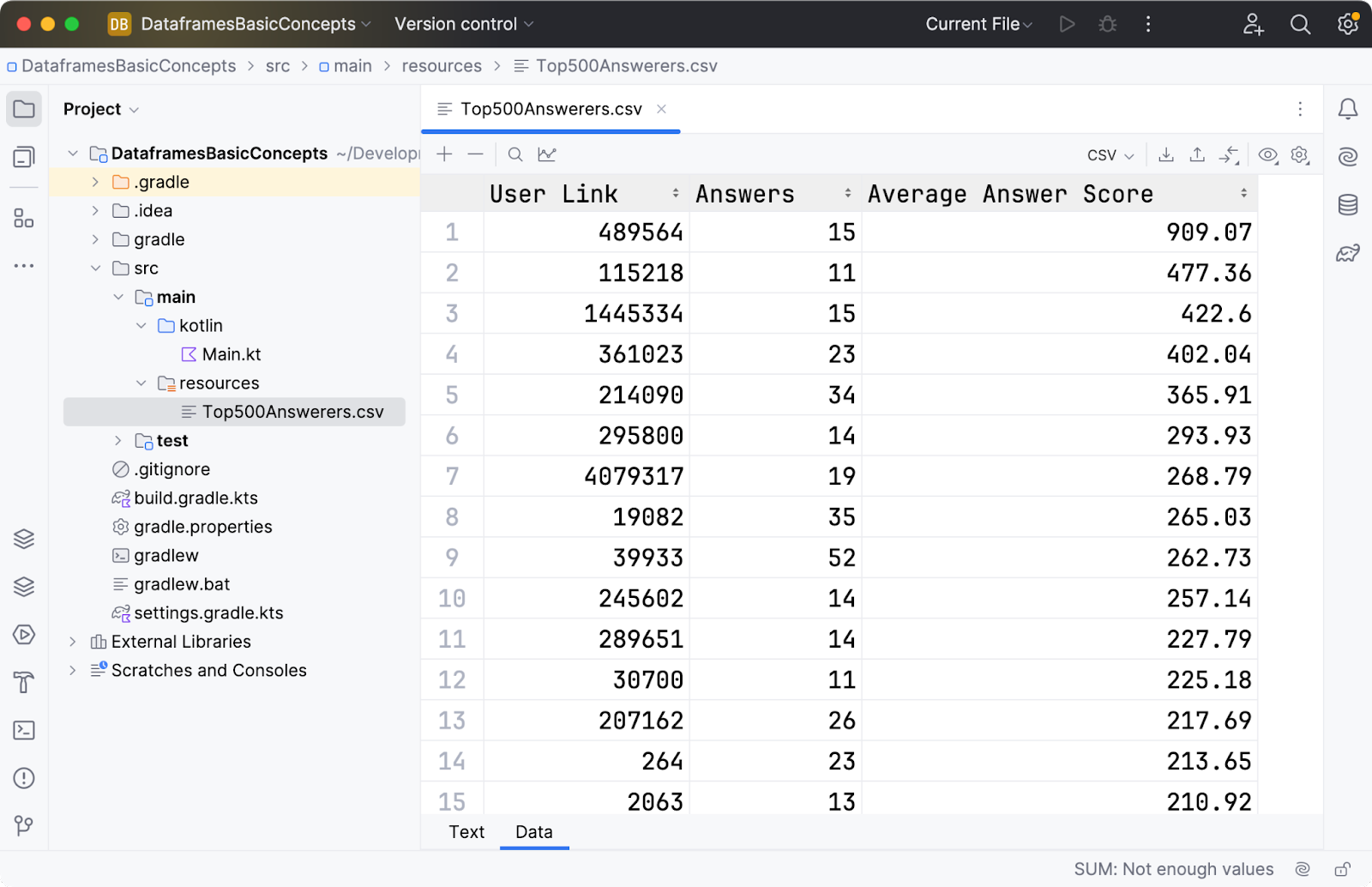
你好,DataFrame!
右键点击项目名称并选择 New | Kotlin Notebook(新建 | Kotlin Notebook)。 您可以随意命名并保存文件。 然后,添加并运行以下两行:
%useLatestDescriptors %use dataframe
use 命令将为您加载并初始化 Kotlin DataFrame 库。 许多热门库可以仅使用名称加载,其他库可以根据其 Maven 坐标加载。 加载库时可能会发生很多事情,因此最好在单独的单元中执行此操作。
现在,您可以创建一个新单元并添加以下三行:
val path = "./src/main/resources/Top500Answerers.csv" val topFolks = DataFrame.read(path) topFolks.head()
运行后,输出应类似于以下示例:
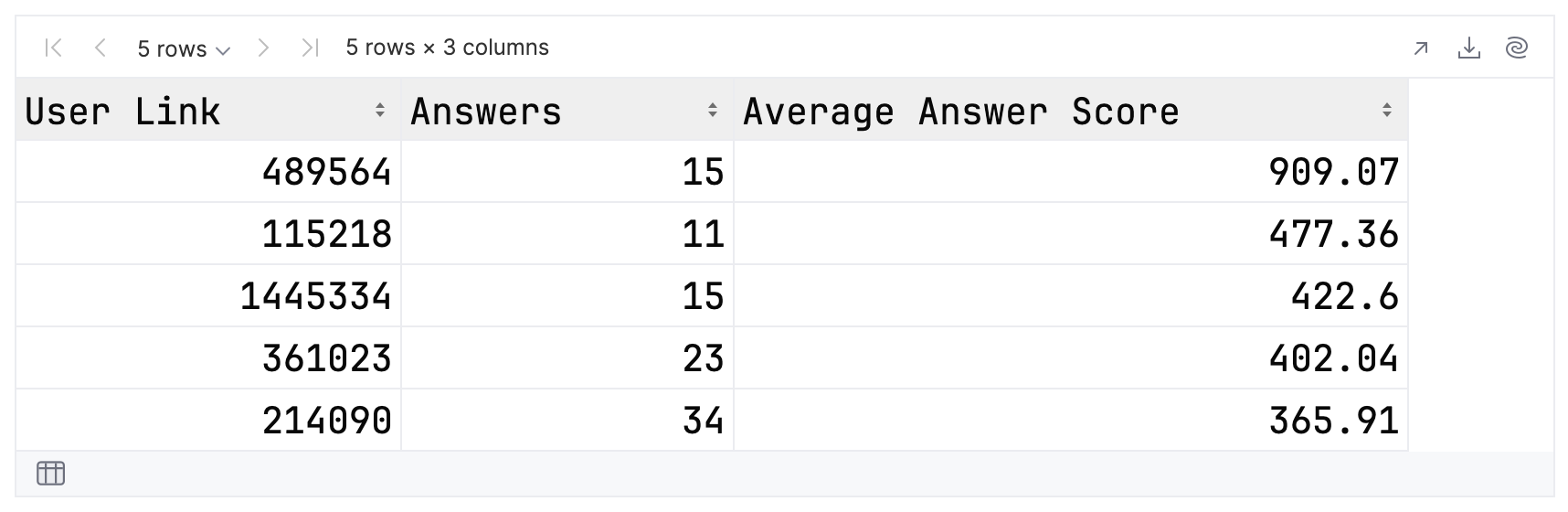
恭喜! 您已经成功从 CSV 文件构建了一个 DataFrame 并打印出前 5 条记录。
在 Kotlin Notebook 中显示数据
有了数据,我们来考虑如何在 Kotlin Notebook 中显示。
您可以通过 DISPLAY 和 HTML 函数将内容作为标记呈现。 以下示例会对用户进行排序,取前五位,并以 HTML 列表的形式打印其详细信息:
fun htmlLink(text: String, url: String) = "<a href=\"$url\">$text</a>"
fun soUrl(userID: String) = "https://stackoverflow.com/users/$userID"
val topFive = topFolks
.sortBy { `Average Answer Score` }
.tail()
.reverse()
val content = buildString {
append("<ul>")
topFive.forEach {
val userID = `User Link`.toString()
val average = `Average Answer Score`
val linkMarkup = htmlLink(userID, soUrl(userID))
append("<li>User $linkMarkup with an average of $average</li>")
}
append("</ul>")
}
DISPLAY(HTML(content))
结果应该显示为:

您应该能够点击链接并在浏览器中打开特定贡献者的页面。
以 HTML 形式显示数据虽然实用,但不太容易产生美观的结果。 更简单的方法是利用 Kandy 库直观呈现数据。 我们使用条形图展示排名前五位的贡献者。
首先,在单独的单元中加载 Kandy 库(出于上面讨论的原因):
%use kandy
然后,绘出贡献者,x 轴为用户 ID,y 轴为平均回答:
plot {
bars {
x(topFive.map { "ID: $`User Link`" })
y(topFive.map { `Average Answer Score` })
}
}
结果应该显示为:
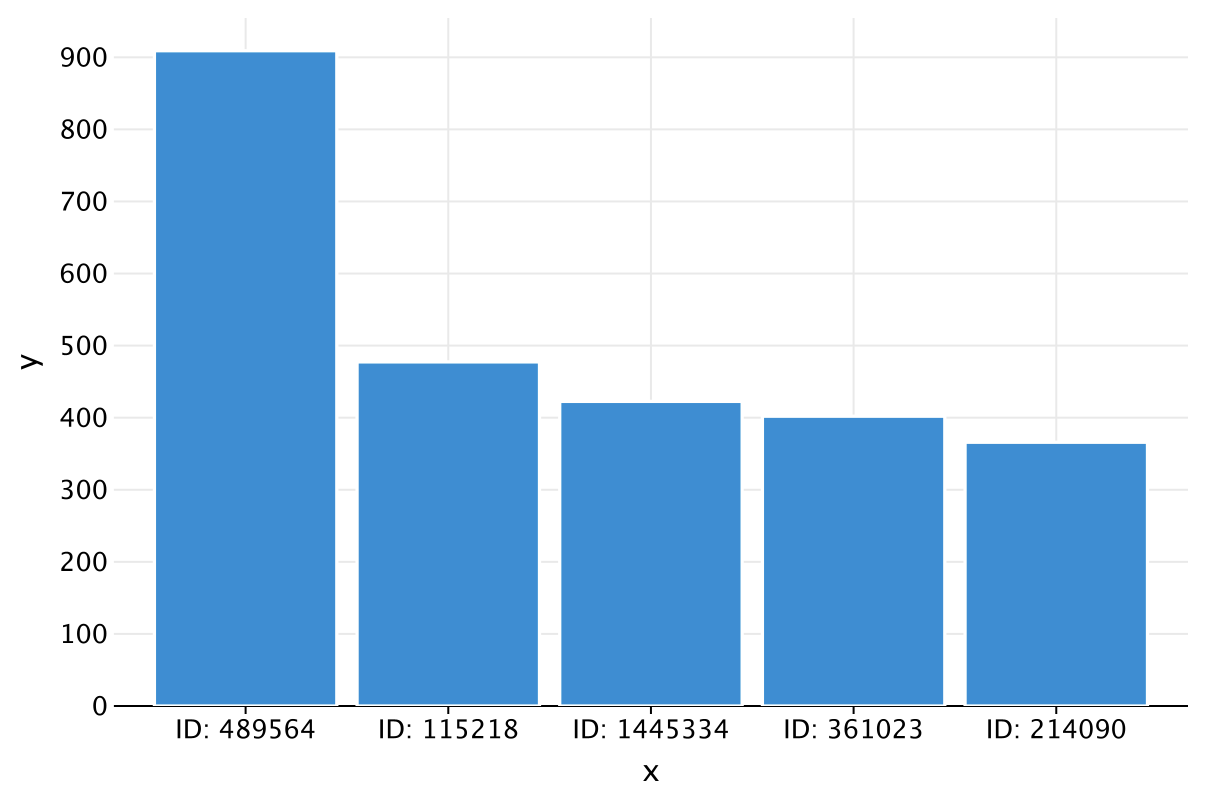
结果很好,过程也相对轻松。 现在,您已经了解了 DataFrame 库的强大功能,我们退一步回顾一些核心概念。
什么是 DataFrame?
DataFrame 是用于处理结构化数据的抽象。 它是从 CSV 文件、JSON 文档或数据库等源读取后创建的表。 DataFrame 包含一个或多个命名列,其内容可以是不同的类型。
列的内容可以是任何 Kotlin 对象,包括另一个 DataFrame。 这项特性让您可以存储和操作分层数据。
DataFrame API 能够实现函数式程序员或数据库管理员可能需要的所有操作。 API 不可变,因此任何有可能更改 DataFrame 的操作都会生成一个新实例。 底层数据尽可能得到重用,由此提高效率和性能。
Kotlin DataFrame 库的最大优势之一是其类型安全性。 您可以生成与 DataFrame 中的列对应的强类型扩展属性。 我们将在下一节中详细探讨。
请注意,在 Kotlin Notebook 中工作时,这些属性是动态创建的。
在 DataFrame 中访问值
DataFrame 的好处是,如果您以前使用过 Kotlin 集合或其他现代数据结构库,您就可以立即上手。 函数式编程的所有标准运算符都会按预期工作,开箱即用。
我们将所有贡献者的回答总数相加。 添加并运行包含以下表达式的新代码单元:
topFolks.map { Answers }.sum()
您可以使用熟悉的 map 和 sum 运算计算总数。 出于演示目的,您可以使用通用的归约运算符:
topFolks.map { Answers }.reduce { a, b -> a + b }
这应该会得到与之前相同的结果。 如前所述,CSV 文件中每个字段的属性都已添加到 DataFrame 中。 这些扩展属性简化了以类型安全方式对数据的访问和操作。
根据需要,您可以在没有这些扩展属性的情况下进行管理,例如创建列访问器函数:
val Answers by column()
topFolks.map { Answers() }.sum()
DataFrame 的标准操作
探索其他内置操作之前,我们应该先清理一下数据。 为了清晰和方便,您可以重命名最后两列:
val topFolksClean = topFolks
.rename { `Average Answer Score` }.into("AverageScore")
.rename { `User Link` }.into("UserID")
topFolksClean
您应该可以看到列名称已经更改:
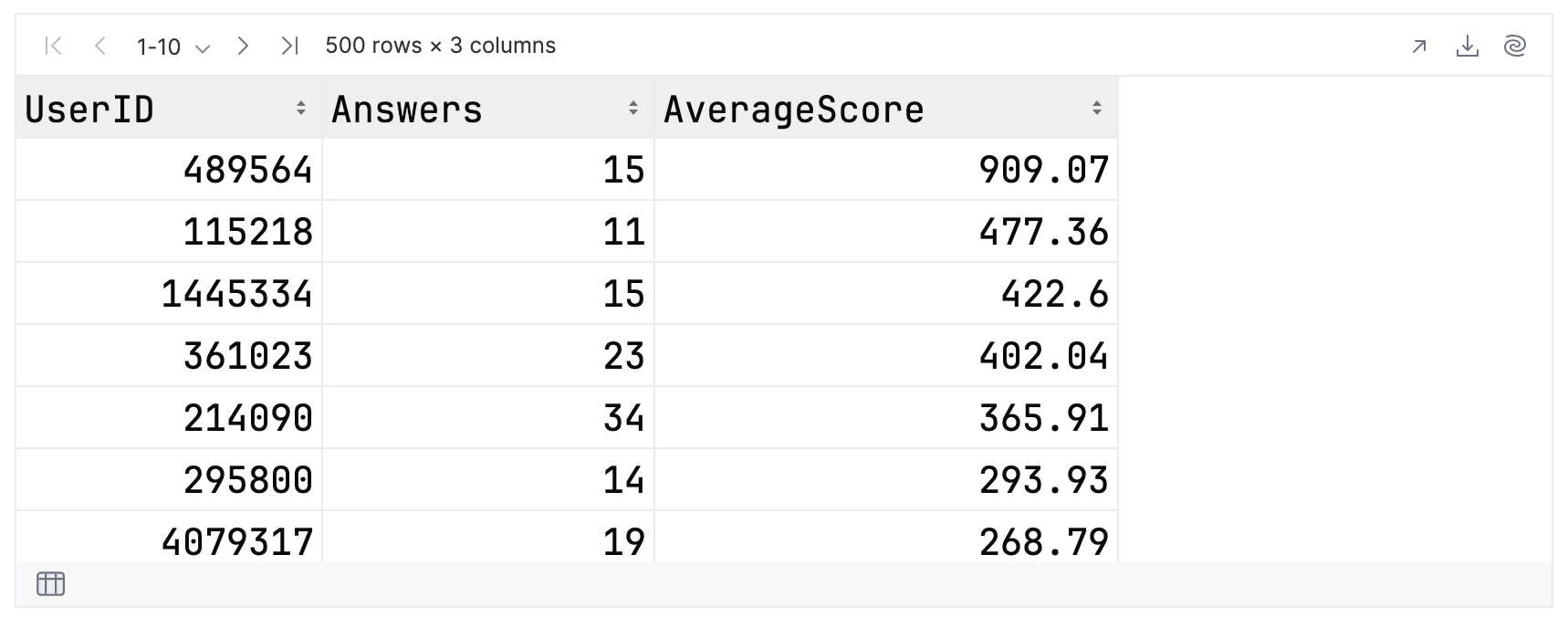
现在,输入并运行以下表达式:
topFolksClean
.filter { Answers >= 20 }
.sortBy { AverageScore }
.tail(3)
.select { UserID }
正如您所看到的,您获得一个操作链,包含以下操作:
-
-
- 筛选记录以仅包含回答了 20 个或更多问题的贡献者。
- 使用 sortBy 将剩余记录按平均分升序排序。
- 取前三个结果,这些结果将位于排序后的 DataFrame 的末尾。
- 将贡献者的 ID 提取到最终 DataFrame 中。
-
您的输出应类似于:
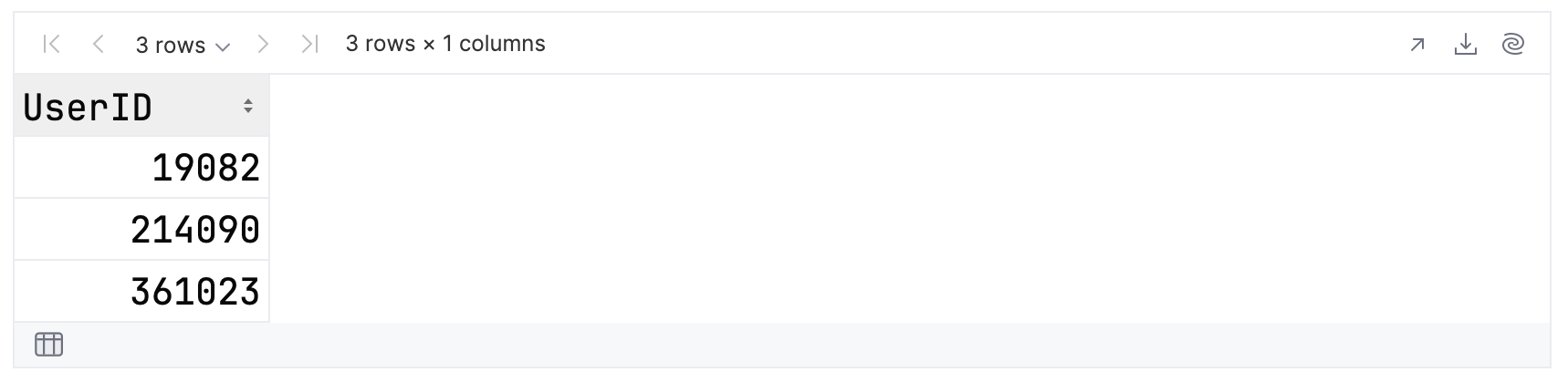
如果您熟悉 SQL,那么您应该会理解 select 操作,虽然它现在出现在语句末尾。 您可以将 filter 操作视为相当于 WHERE 子句,将 sortBy 操作视为相当于 ORDER BY。
以 PostgreSQL 中的数据库表为例,您可以在 DataGrip 中创建并运行以下查询:
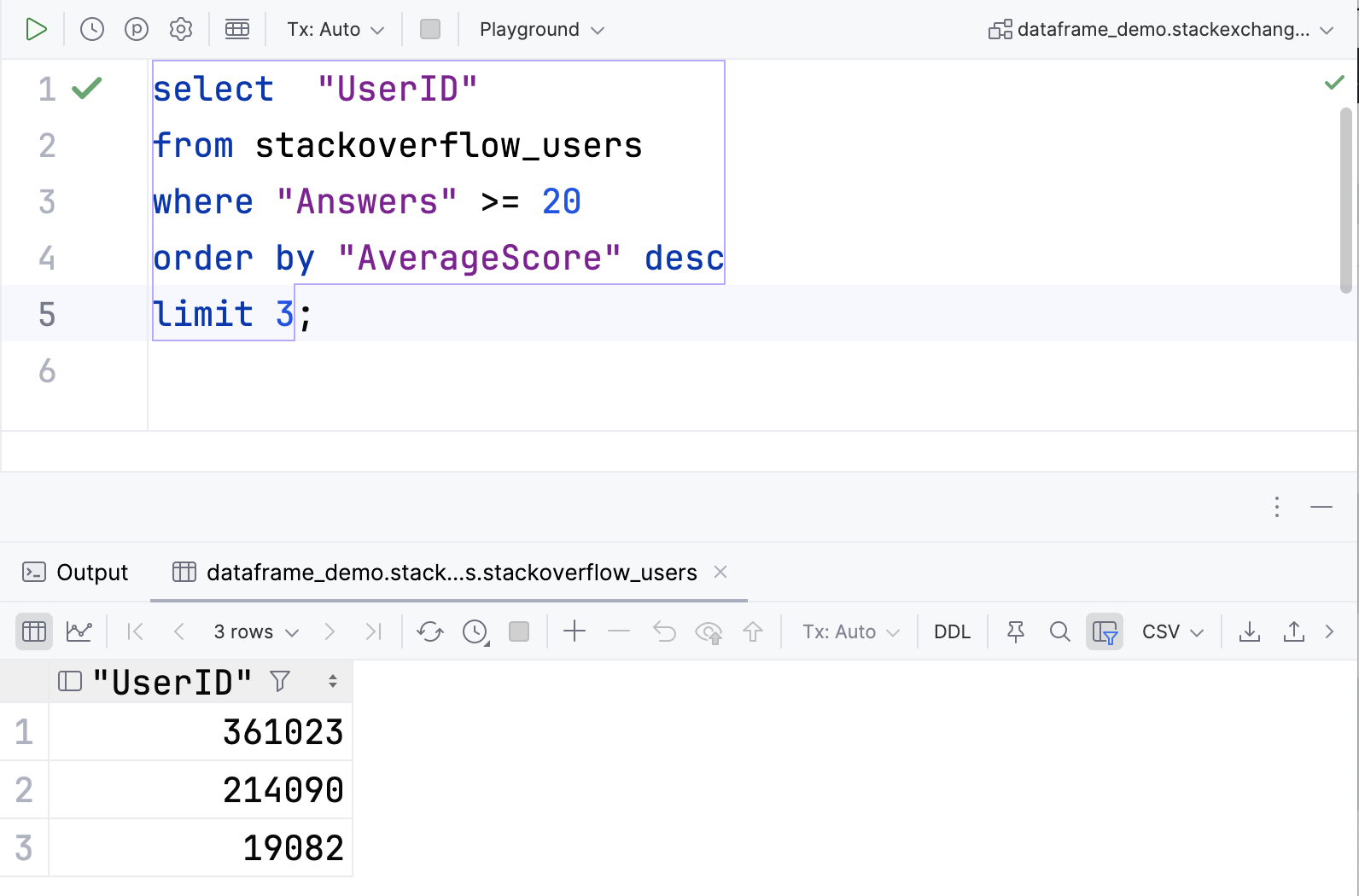
请注意,API 包含用于执行转换的 select 和 map 运算符。
distinct
查看数据,您可以发现贡献者回答的问题数量并不唯一。 例如,不止一位贡献者回答了 15 个问题。 您可以通过以下方式找出有多少重复项:
topFolksClean
.distinctBy { Answers }
.count()
对于撰写本文时的数据,结果为 93,这意味着 500 位贡献者可以根据其回答的问题数量分为 93 个组。 distinctBy 操作不执行此分组,只是从每个组中选择第一行。
如果要按平均回答得分降序排列贡献者,那么 distinctBy 操作应仅选择每个组中得分最高的贡献者。 我们使用内置操作来验证。
您可以首先检查原始 CSV 文件,然后从 Answers 列选择一个出现多次的值。 在此示例中,重复值为 15:
topFolksClean
.filter { Answers == 15 }
这是关联的输出。 有 22 行,Notebook 将以 10 行为一组显示。
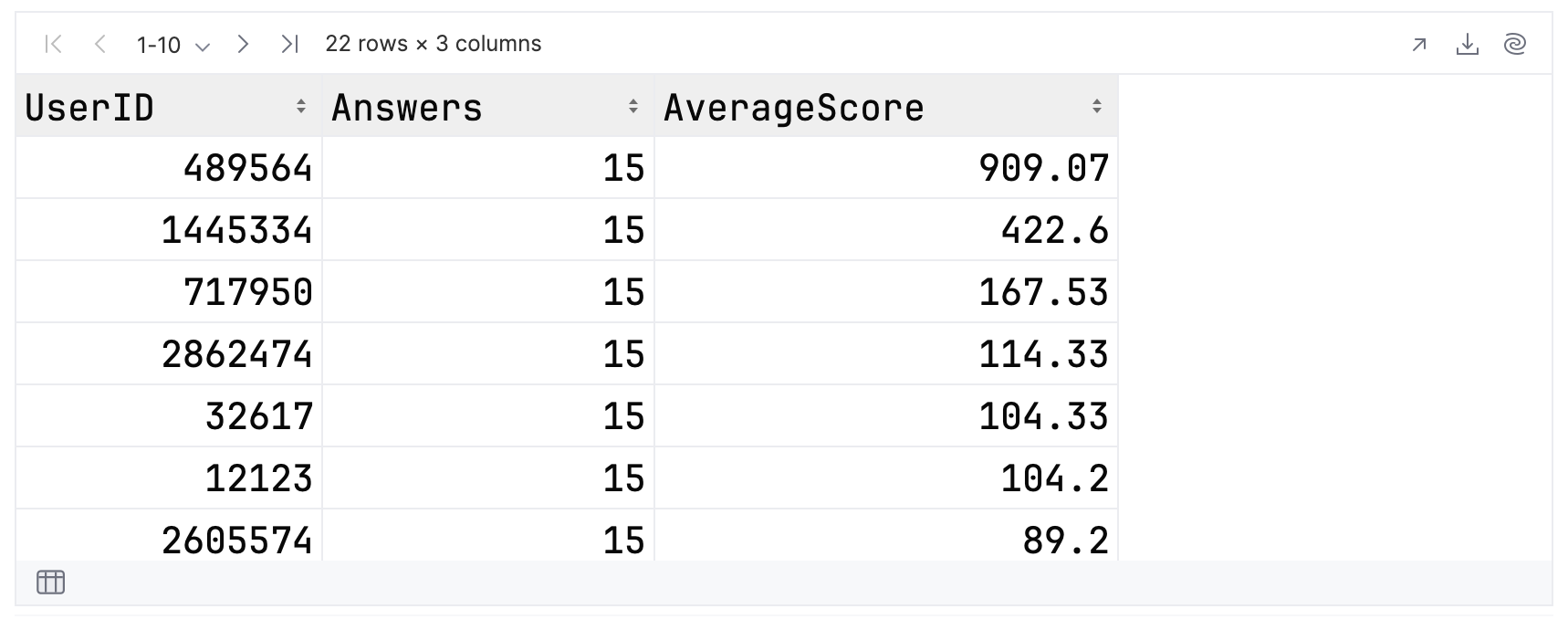
在我们的结果中,此组的最高分为 909.07,最低分为 58.33。 检查您自己的结果时,记得翻阅整个数据集!
如果以升序排列并使用 distinctBy,将有一个 Answers 值为 15 的贡献者:
topFolksClean
.sortBy { AverageScore }
.distinctBy { Answers }
.sortBy { Answers }
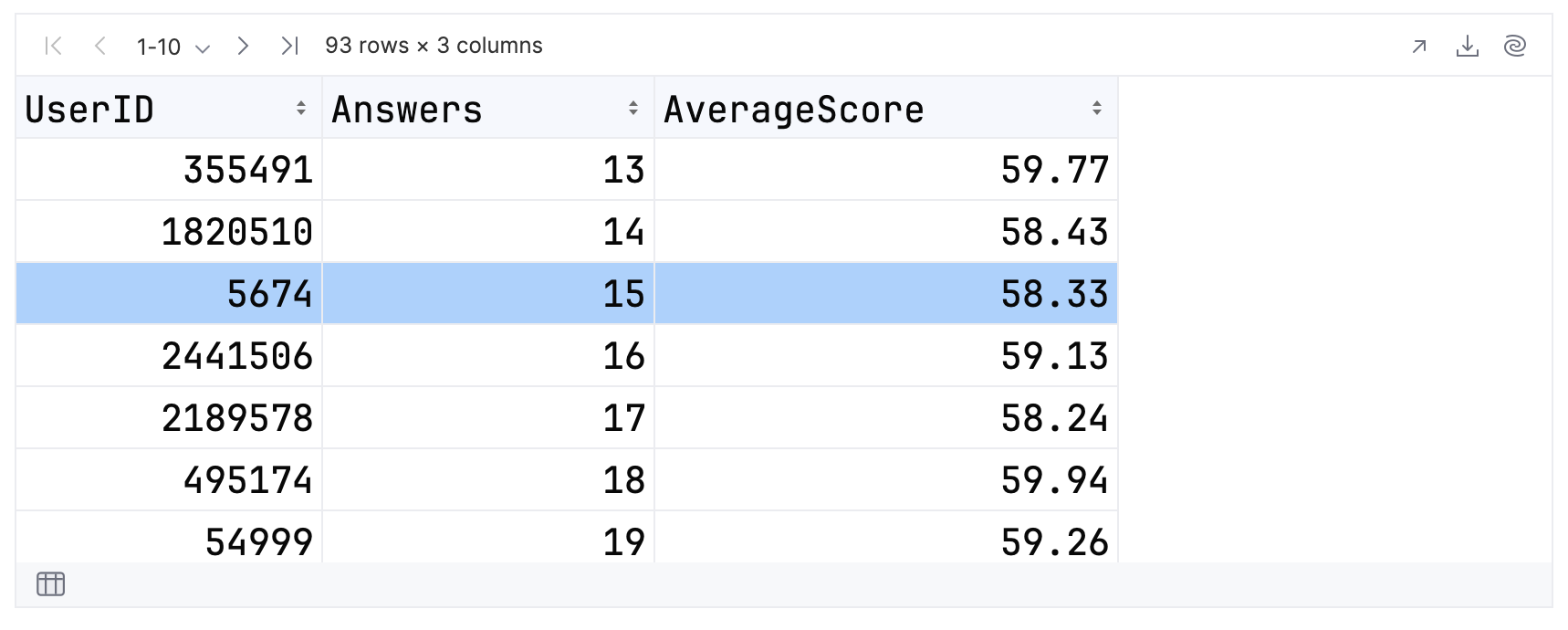
由于是升序排列,单个贡献者的得分将为 58.33。 如高亮显示的行所示。
如果以降序排列,则结果中显示的贡献者的分数应为 909.07。 我们来确认一下:
topFolksClean
.sortByDesc { AverageScore }
.distinctBy { Answers }
.sortBy { Answers }
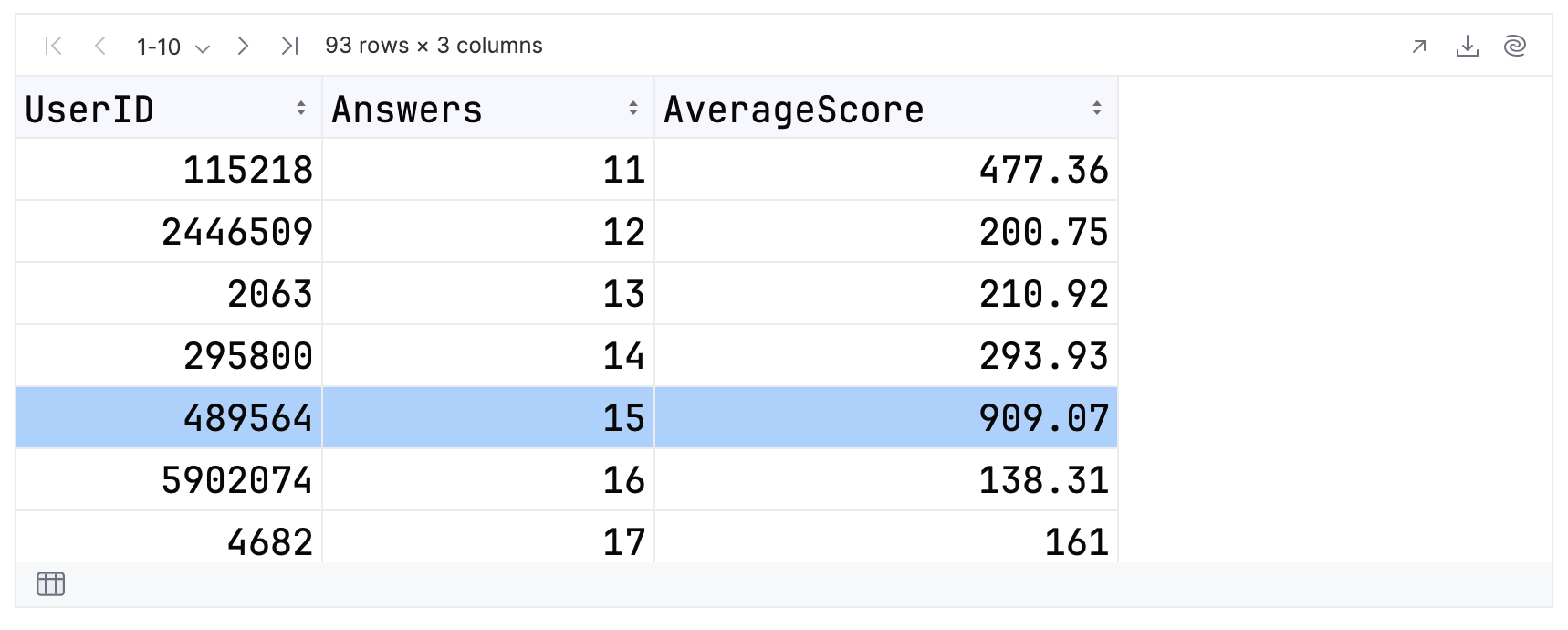
再次获得预期分数。
组
您对数据已经有了更好的理解,接下来,我们使用 groupBy 执行分组。 为简单起见,仅对前 10 个结果分组:
topFolksClean
.sortBy { AverageScore }
.tail(10)
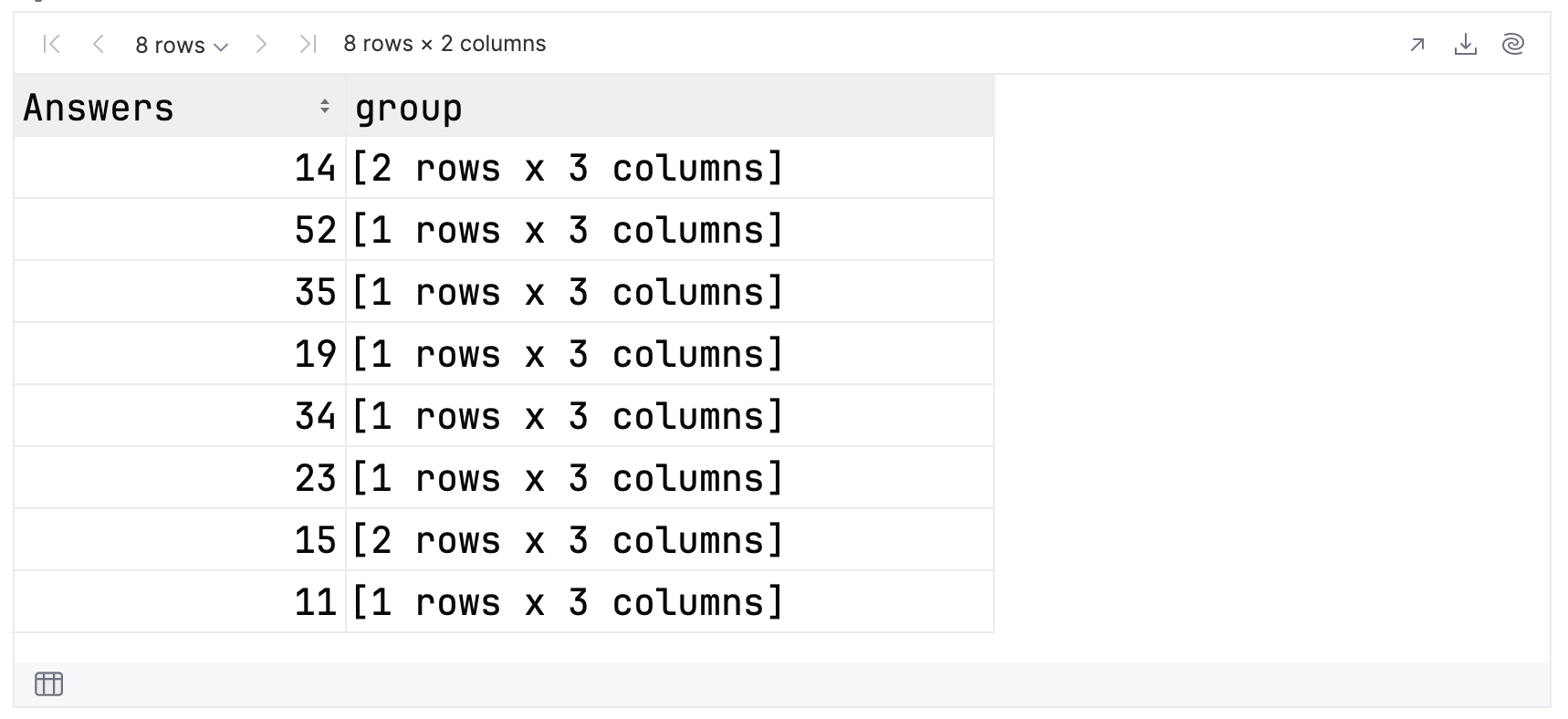
.groupBy { Answers }
此结果返回的数据稍微复杂一些。 您应该看到一列包含组的键,在本例中为回答的数量。 然后,是一个包含数据本身的列,作为嵌套 DataFrame。
下面是结果在 Notebook 中的表示方式。 请注意,您可以点击组来显示其内容:
如果您在 SQL SELECT 语句中使用过 GROUP BY 子句,应该会熟悉此操作。 这是 PostgreSQL 和 DataGrip 的另一个示例:
您可以从查看键开始逐渐探索分组数据:
val groupedData = topFolksClean
.sortBy { AverageScore }
.tail(10)
.groupBy { Answers }
groupedData.keys
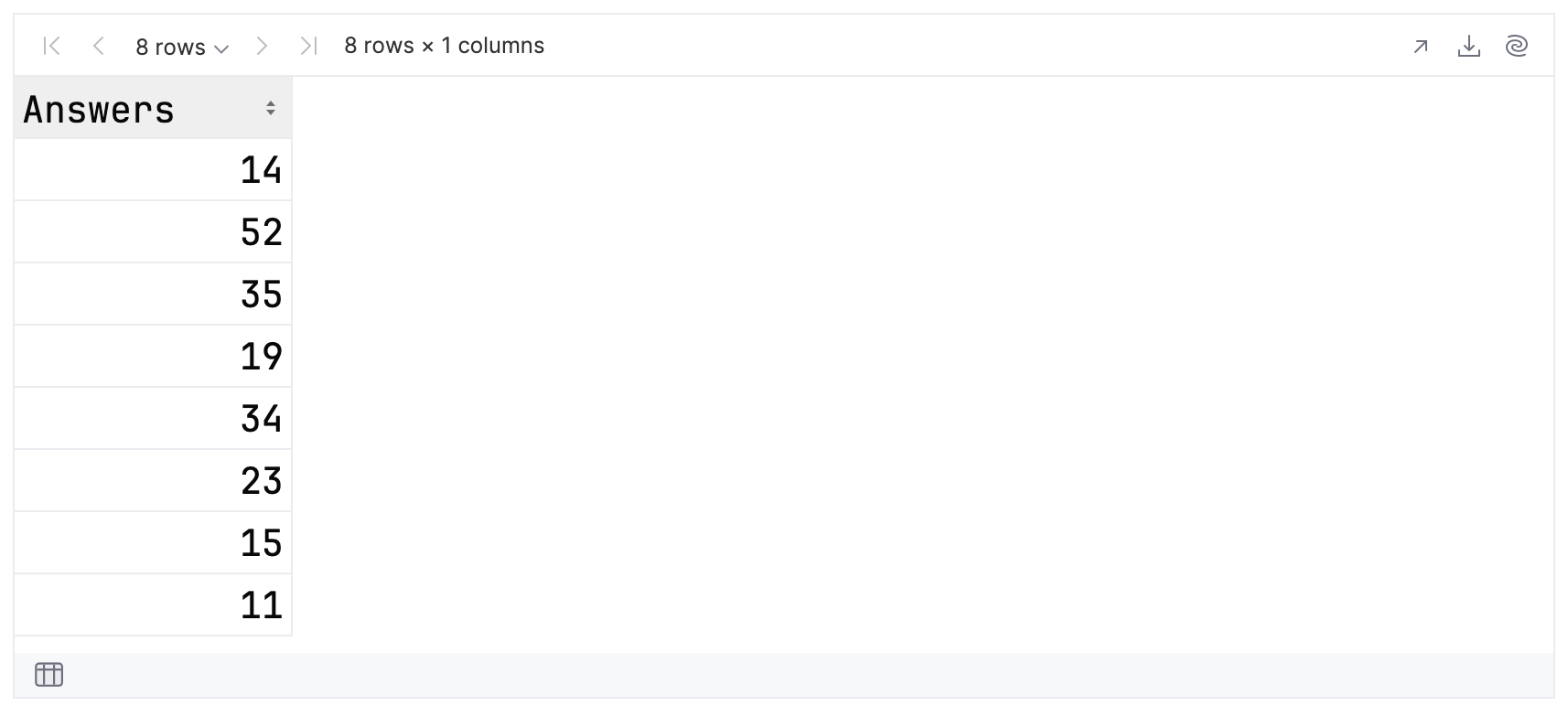
然后,打印组:
groupedData.groups
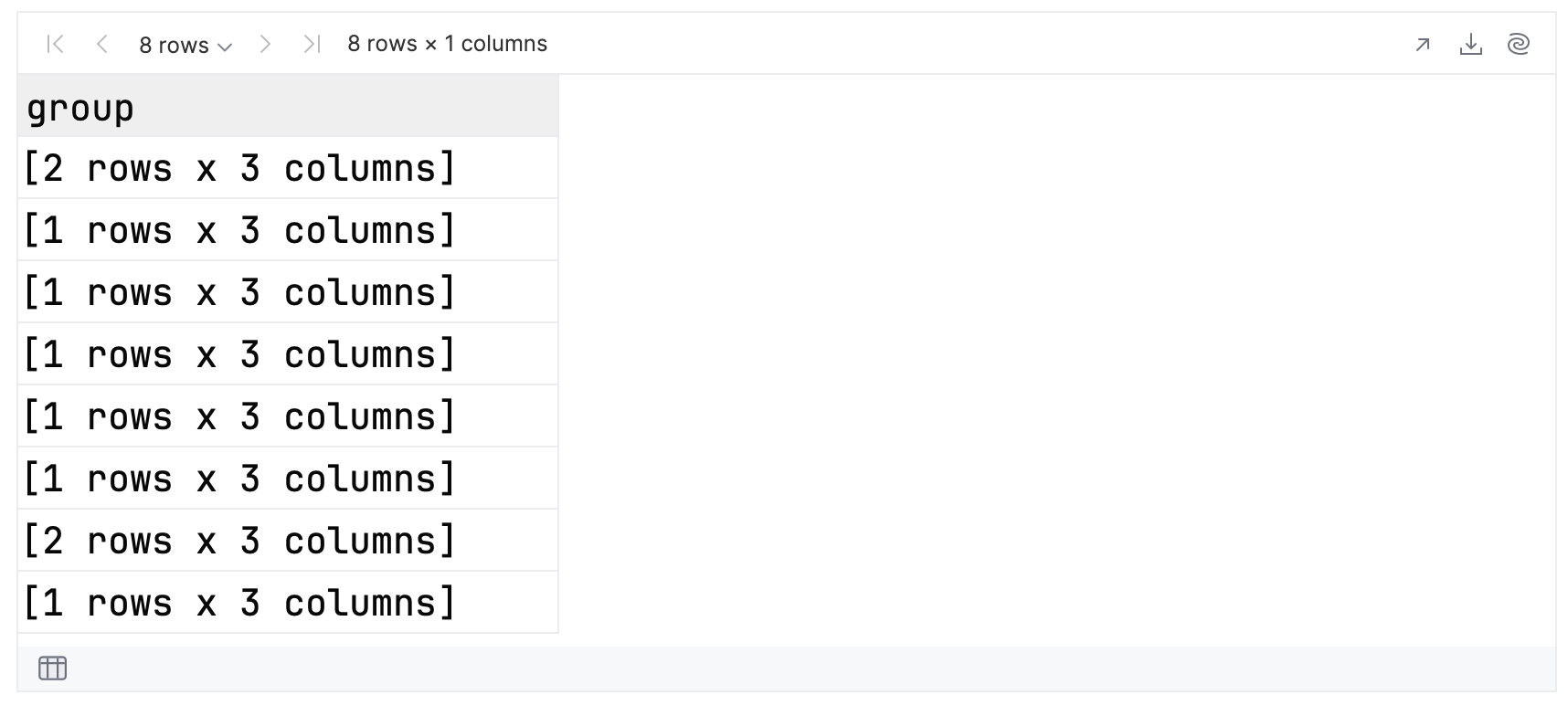
如果展开每个组查看其内容,您可以看到具有 14 和 15 个回答的组有两位成员,其他组都有一位成员。 因此,对于前 10 个结果,总共有 8 个组。
filter
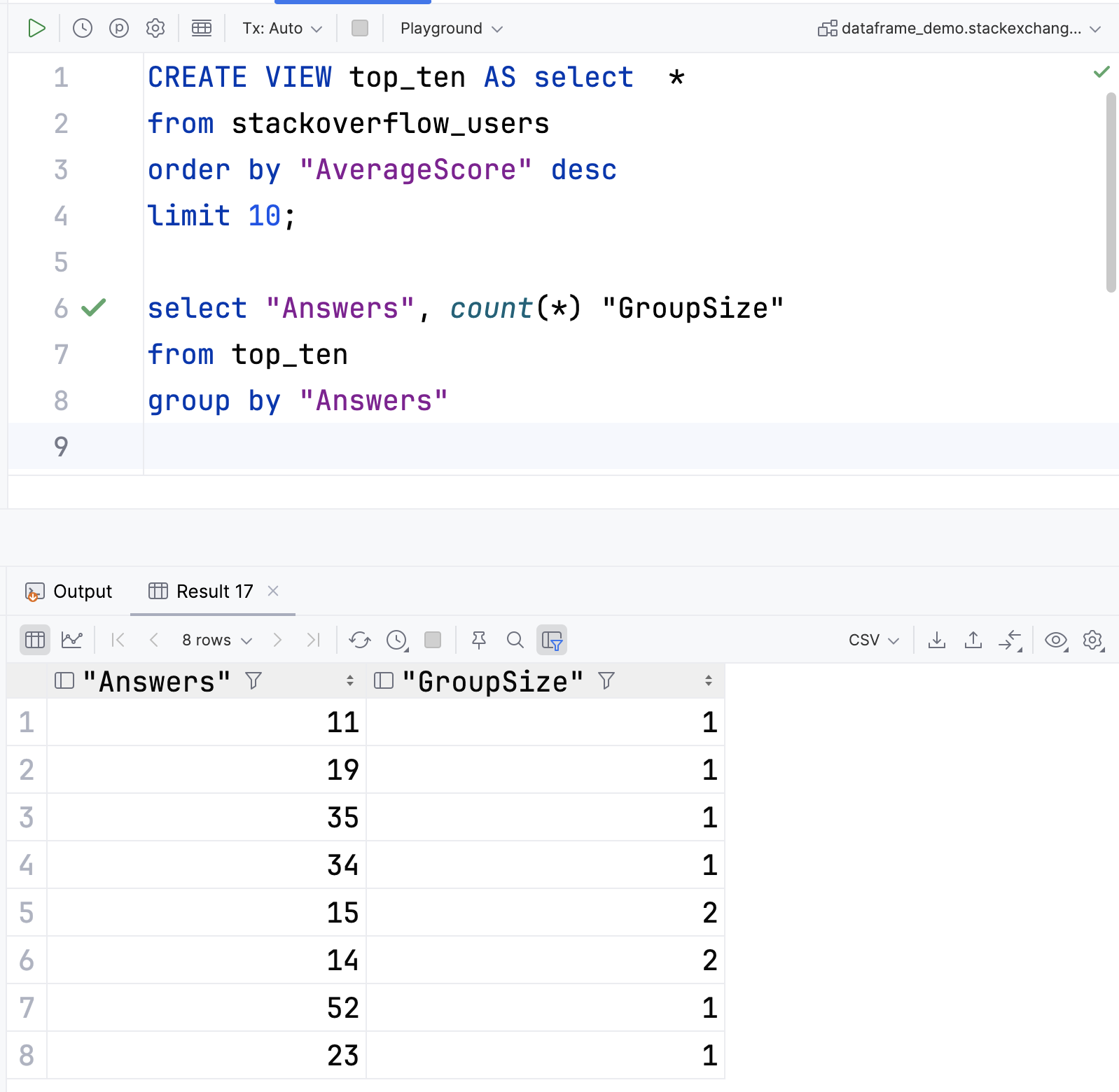
来看一看是否可以使用核心操作查找并显示具有多个结果的组:
groupedData
.groups
.filter { df ->
df.rowsCount() > 1
}.forEach { df ->
println(df.first().Answers)
}
这段代码将筛选并查找具有多行的组。 然后,它会遍历每个组,打印回答的数量。 组中的每一行都有相同数量的回答,因此您可以选择您喜欢的任意行。 在本例中,我们选择第一个。
筛选器返回两个数字:
14
15
由于 groups 返回一列 DataFrame,筛选器和 forEach 方法的签名略有不同。 每次调用 lambda 时,都会有一个值为当前 DataFrame 的形参。
更改 DataFrame 架构
使用 DataFrame 时,您不会受限于创建 DataFrame 时推断的架构。 您可以添加列、移除列,甚至更改现有列的数据类型。 考虑以下示例:
val ratedFolks = topFolksClean
.sortBy { AverageScore }
.remove("Answers")
.add("Rating") {
when (AverageScore) {
in 0.0 .. "Low"
in 100.0 .. "Medium"
else -> "High"
}
}
在这里获取排序后的数据,移除 Answers 列,添加一个新的 Rating 列(派生自 AverageScore)。 这会生成一个新的 DataFrame,称为 ratedFolks。
例如,您可以在将前三行和最后三行串联到一个新的 DataFrame 中后查看:
val topAndBottom = listOf(ratedFolks.head(3), ratedFolks.tail(3)).concat() topAndBottom
结果应该显示为:
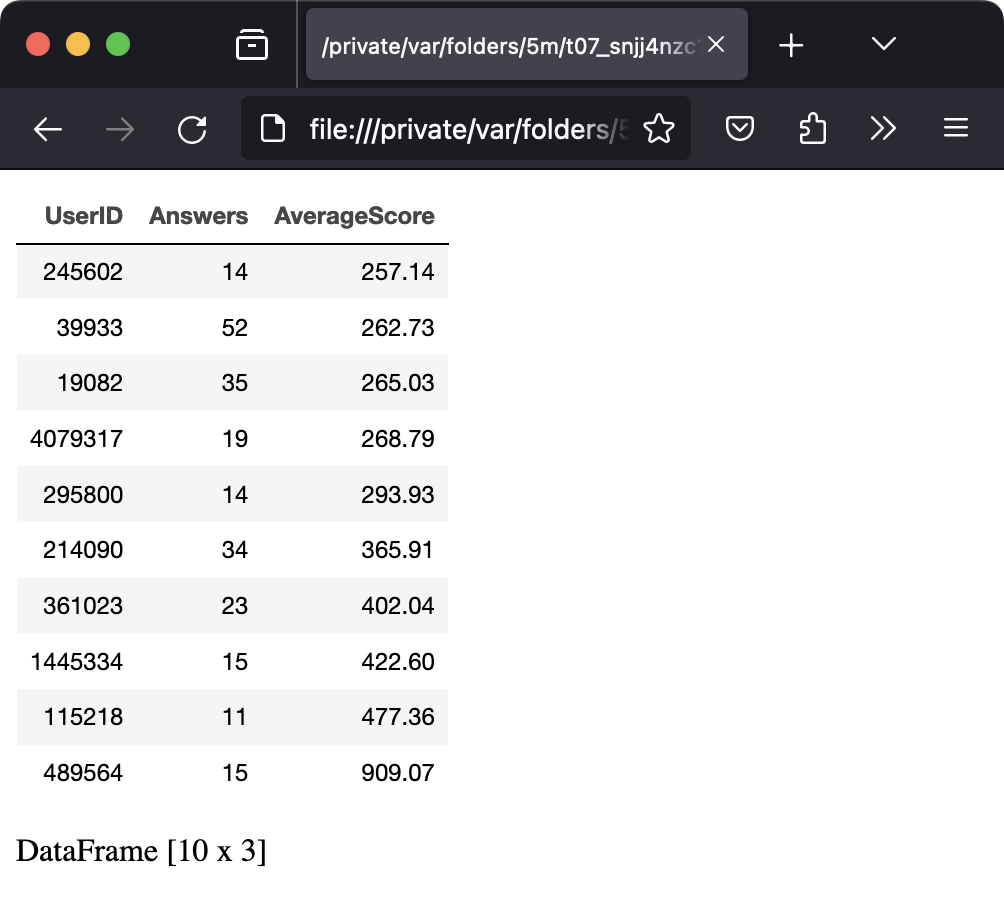
请注意,这通过添加到标准 Iterable 类型的扩展函数实现。 扩展是 Kotlin 中的一项关键功能,它使库简单易用。
直观呈现数据
正如您已经看到的,您可以利用 Kandy 库绘制数据。 我们来尝试直观呈现数据中出现频率最高的 Answers 值。
输入并运行:
val answersPairedWithCounts = topFolksClean
.groupBy { Answers }
.count()
.filter { column("count") >= 20 }
这段代码将根据回答的数量对记录分组,然后用其大小替换每个组。 为简单起见,我们仅查看具有 20 位或更多成员的组:
answersPairedWithCounts
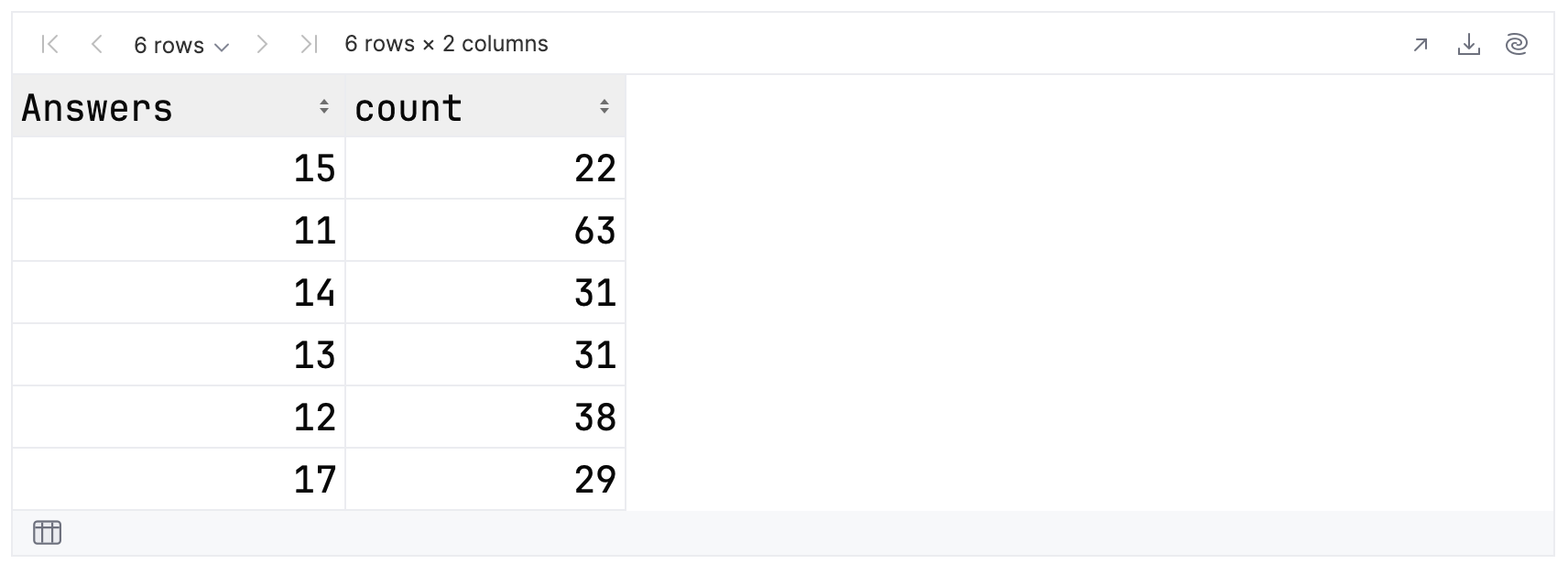
现在,让 Kandy 将此 DataFrame 绘制为条形图:
answersPairedWithCounts.plot {
bars {
x(Answers)
y(count)
}
}
这是得到的图表:
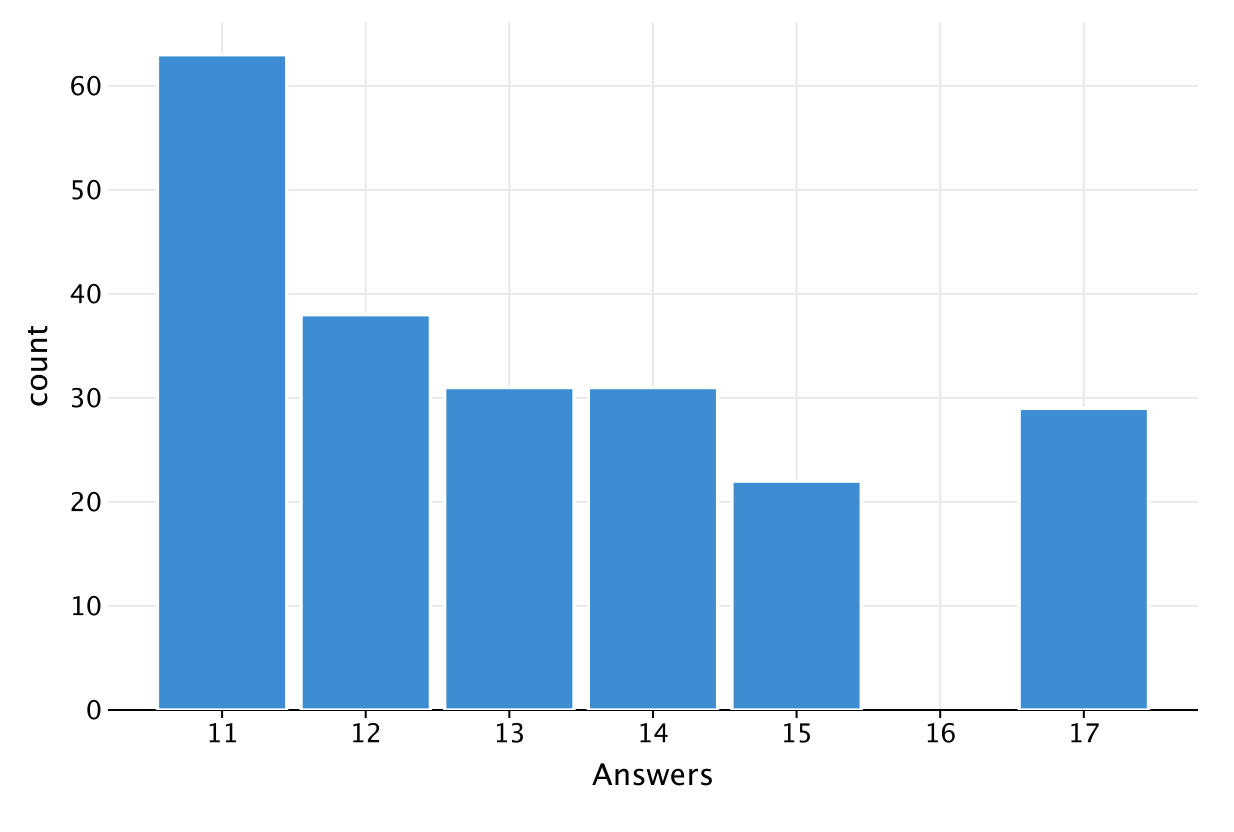
您可以看到,最常见的回答问题数为 11,在数据中出现了 63 次。
请注意,您已经在前面的示例中加载了 Kandy 库:
%use kandy
如果您跳过了前面的示例,那么您现在需要加载库。 如前所述,最好在单独的单元中执行此操作。
导出您的结果
到目前为止,您只是查看了结果,还没有保存。 我们来看看如何从 Kotlin Notebook 导出数据。 在下面的两个表达式中,创建一个新的 DataFrame,然后将其导出为 CSV 文件和 JSON 文档:
topFolksClean
.sortBy { AverageScore }
.tail(10)
.toCsv()
topFolksClean
.sortBy { AverageScore }
.tail(10)
.toJson()
将 DataFrame 导出到 HTML 的运作方式相同。 toStandaloneHTML 方法可以生成包含表的 HTML 文档,以及关联的 CSS 样式和 JavaScript 事件处理程序。 此文档可以直接在默认浏览器中打开:
topFolksClean
.sortBy { AverageScore }
.tail(10)
.toStandaloneHTML()
.openInBrowser()
结论
希望本教程能够展示 Kotlin DataFrame 库的强大功能和实用性。 请记住,示例项目包含本系列所有教程的数据文件和 Notebook。 您可以克隆此项目并轻松修改示例,也可以用您自己的数据文件替换示例数据文件。
在下一个教程中,我们将展示如何使用 Stack Exchange REST API 获取 JSON 数据。 下一篇文章中的信息将更加复杂和层次化,让您能够深入了解 DataFrame API 的强大功能。
本博文英文原作者:





