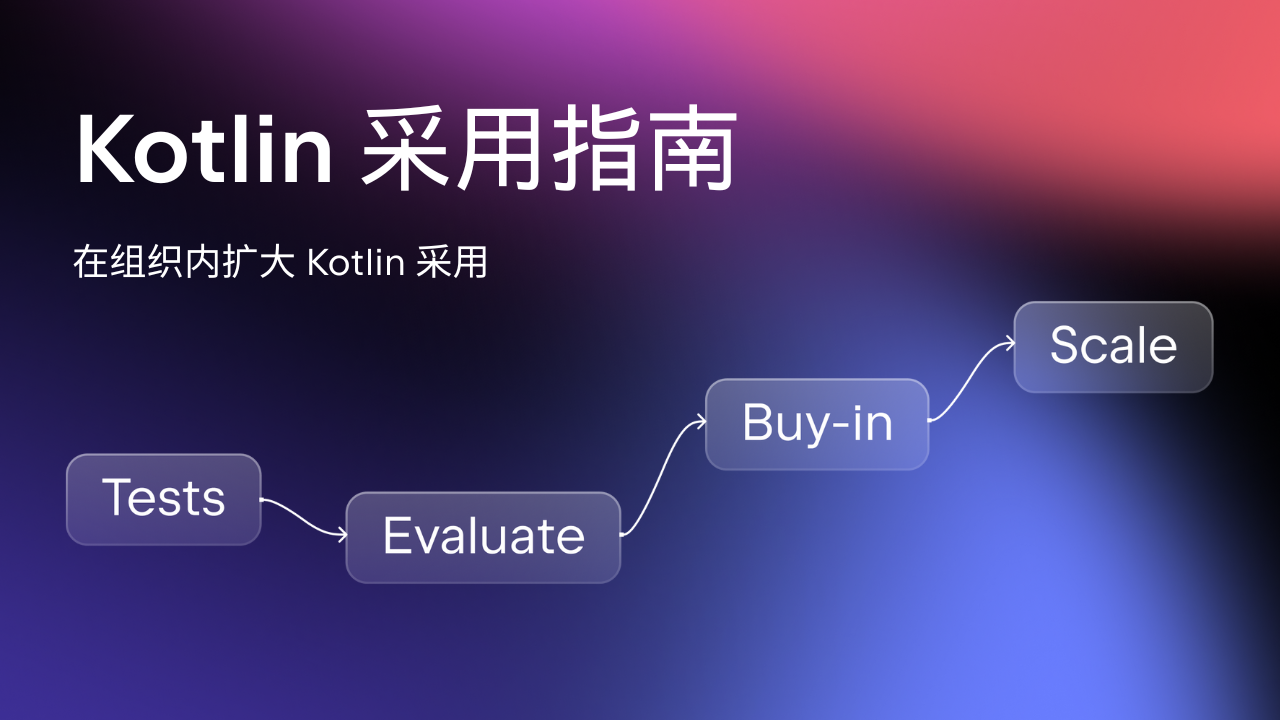
Kotlin
A concise multiplatform language developed by JetBrains
AI 友好型编程语言:Kotlin 的故事


编程语言只有在机器学习社区和语言模型中具有良好的代表性,才能在当今全球 AI 变革之中跟上时代的步伐。 语言的代表性越差,生成的代码的质量就越低,进而导致语言使用率下降,代表性也会更差。 您可能想知道我们所说的“代表性”是什么意思。 继续阅读!
为了支持 Kotlin 未来受欢迎程度的增长,并确保语言在新一代开发者工具中具有良好的代表性,我们推出了 ?Kotlin ML Pack:一套必备工具、数据和模型,可以促进 Kotlin 语言的代码建模任务。 它基于 JetBrains 研究团队的广泛研究,并为机器学习研究者提供了更多可以应用于其他编程语言的工具和想法。
Kotlin 数据/数据集
好数据是包括编程语言在内所有领域的机器学习的基石。 虽然已经存在用于教授和衡量 Python 语言建模各个方面的热门高质量数据集,但对于 Kotlin 来说,这样的数据集几乎不存在。 我们通过收集和开源 Kotlin 语言语料库和 Kotlin 生成指令数据集这两大主要数据集弥补了这一差距。
语言语料库数据集
下面两个数据集是我们语言语料库相关研究的成果:
- KStack – Kotlin 大型语言语料库。 最完整、许可最宽松且最新的开源 Kotlin 代码集合。
- KStack-clean – 用于提升模型训练的精选数据集。 KStack 的高度筛选版本,包含 25,000 个高质量样本。
下表比较了这两个新数据集和 The Stack v2 的 Kotlin 子集的描述性统计。
| 文件 | 仓库 | 行数 | 词例数 | |
| The Stack v2 | 200 万 | 109547 | 1.62 亿 | 17 亿 |
| KStack | 400 万 | 163310 | 2.93 亿 | 31 亿 |
| KStack-clean | 25000 | 3366 | 200 万 | 2200 万 |
KExercises:Kotlin 指令数据集
我们的数据集开发的另一个重点是创建用于指令调整的 Kotlin 数据集。 通常,此类数据集由指令或任务集及其解决方案组成。 在这种数据上训练有助于模型更好地理解自然语言与编程语言之间的关系。
此类数据集很多,一些适用于 Python 编程语言,另一些具有多语言表示。 不过,在这些数据集中,Kotlin 仅具有适量的代表性,或者根本不存在。
我们的决定是将一个现有数据集从 Python 转换到 Kotlin,而不是从头开始创建整个数据集。 为此,我们选择了一个 Python 练习数据集来展示其功能和有效性。 然后,我们使用 GPT-3.5-turbo 将数据从 Python 转换为 Kotlin。 转换完成后,我们手动审查了数据的子样本,确保转换的准确性。 最后,我们编译了一个包含 15,000 个 Kotlin 任务(约 350 万个词例和 33.5 万行代码)的指令数据集。
评估
机器学习的另一个重要方面是准确、有效的评估程序。 好在 HumanEval 已经成为代码 LLM 领域此类评估的标准。 虽然 HumanEval 最初是为 Python 设计,但它已被翻译成多种编程语言。 它也被改编用于编译语言,并已扩展到新任务。
适用于 Kotlin 的 HumanEval
不过,现有适用于 Kotlin 的 HumanEval 需要重大改进才能使用。 因此,我们采用不同的方式让人类专家参与,从头重做 HumanEval。
所有 JetBrains HumanEval 解决方案和测试均由具有六年 Kotlin 经验的专业程序员编写,并由具有四年 Kotlin 经验的程序员独立检查。 我们实现的测试相当于 Python 的原始 HumanEval 测试,我们还修正了提示签名以解决上述泛型变量签名。
新的 HumanEval 基准位于 Hugging Face 上,同时提供了适用于不同语言模型的使用说明和基准评估结果。
适用于 Kotlin 的训练模型
为了展示我们的数据集,我们在不同的环境中训练了多个模型。
- Code Llama 7B 是使用优化型 Transformer 架构的自回归语言模型。 它支持填充文本生成,使用多达 16,000 个词例进行了微调,并在推理时支持最多 100,000 个词例。
- DeepSeek 实现的 DeepSeek-coder-6.7B 基础模型是拥有 67 亿参数的 Multi-Head Attention 模型,基于 2 万亿个英语和中文自然语言文本训练。 它还使用 16,000 的窗口大小和额外的填空任务支持项目级代码补全和填充,在项目级代码语料库上进行预训练。
- DeepSeek-coder-1.3B 具有相同的架构和训练程序,但参数更少。
我们使用上面的三个数据集作为训练环境的一部分。 使用 AdamW 优化器在 NVIDIA A100 GPU 上以 bf16 精度微调。 此外,为了稳定训练过程,我们使用了多种种术,例如 Z-loss、权重衰减、梯度范数裁剪等。
最后,我们观察到使用的所有方式都有所改进。 结合 DeepSeek-coder-6.7B 与 KExercises 数据集上的微调,我们取得了最显著的提升,通过率达到 55.28%。 指令微调在另外两个基础模型也取得了很好的效果。 同时,对完整数据集的微调显示出较弱的结果,CodeLlama 的通过率仅提高了 3 个百分点。 KStack 的干净版本在微调期间显示出更好的结果,但通过率仍然低于我们使用 KExercises 数据集实现的通过率。

我们不会止步于此。 我们的目标不仅仅是提高 Kotlin 代码生成的质量。 我们还将为研究人员提供更多工具和想法,确保开发者工具在代码生成和软件开发的机器学习应用方面取得进一步发展。
这项工作和我们发布的 Kotlin ML Pack 涵盖了 Kotlin 学习管道的基本要素,例如数据和评估。 不过,Kotlin 和 JetBrains 生态系统可以为语言建模和机器学习社区提供更多好处,例如通过编译器或 linter 等工具学习、数据集的额外代码,以及与日常生产开发任务更相关的新基准。
如需深入了解 JetBrains 研究团队的研究,请阅读 Kotlin ML Pack:技术报告。
或者,观看 KotlinConf’24 主题演讲的相关部分(51 分 12 秒开始)。
本博文英文原作者: