

Big Data Tools
A data engineering plugin
Data Engineering Annotated Monthly – October 2022

Greetings from sunny Berlin! Yes, it’s still 20+ °C here – perfect conditions for sitting down on your balcony with the latest issue of your favorite Annotated! I’m Pasha Finkelshteyn, and I’ll be your guide through this month’s news. I’ll offer my impressions of recent developments in the data engineering space and highlight new ideas from the wider community. If you think I missed something worthwhile, hit me up on Twitter and suggest a topic, link, or anything else you want to see. By the way, if you would prefer to receive this information as an email, you can subscribe to the newsletter here.
News
A lot of engineering is about learning new things and keeping a finger on the pulse of new technologies. Here’s what’s happening in the world of data engineering right now.
Apache Doris 1.1.3 – Here’s another interesting database for you. We aren’t aware of many MPP databases, and none of them are under the motley umbrella of the Apache Software Foundation. It is built specifically for ad-hoc queries, report analysis, and other similar tasks. For example, take a look at this picture from Doris’ site:
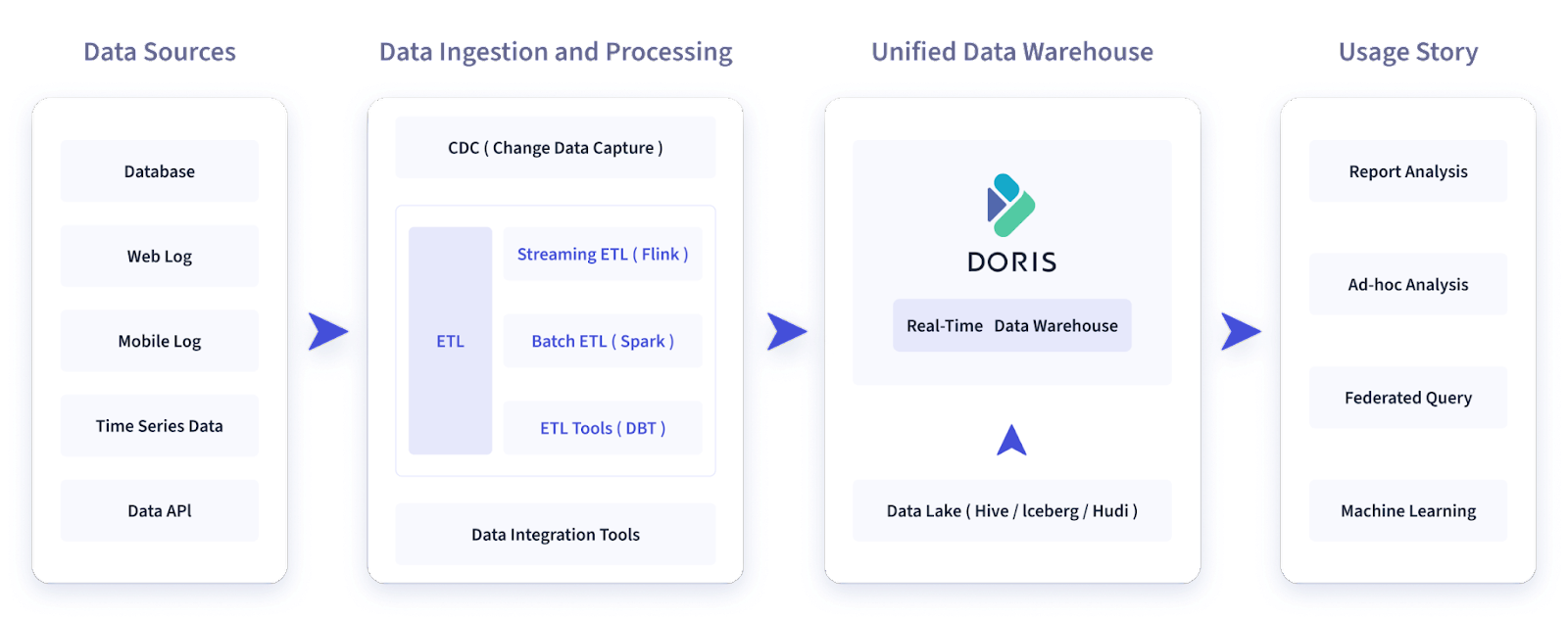
This looks like an excellent candidate for use as your next DWH, doesn’t it?
One of the great things about ASF projects is that they usually work nicely together, and this is no exception. For example, the current 1.1.3 release supports Apache Parquet as an output file format.
Apache Age 1.1.0 – Sometimes, we data engineers do work that doesn’t deal directly with big data. Sometimes our job is just to ensure things are designed correctly, which can require us to use tools we are familiar with in a non-typical manner. Take, for example, Postgres. It’s one of the most popular databases; it is extensible, has a good enough planner, and is tunable. Some extensions for it are fairly well-known. For example, `ltree` is a popular extension from postgres-contrib that facilitates the representation of tree structures in a friendly way with a special type. But today, I want to highlight Apache Age, an extension that makes it possible to use Postgres as a graph database. The query language is some kind of mix of traditional SQL and Cypher, which is, as far as I’m concerned, the most popular graph query language today.
RocketMQ 5.0.0 – I’ve already mentioned Apache RocketMQ, a high-performance queue based on ActiveMQ, in previous installments of this series. This new major release is notable, however, because it introduces a handy new concept: logic queues. Currently, MessageQueue is coupled to the broker name, and the broker name is coupled to the number of presently active brokers. When there’s a change, planned or unplanned, to the number of brokers, queue rebalancing begins. This rebalancing can take minutes, and the queue will not always be available during that time. That, in turn, can lead to significant degradation of the overall quality of service. Logic queues remove this relation between queues and the number of nodes, so now, when the number of nodes changes, the rebalance will take significantly less time, if any.
ScyllaDB 5.0.5 – I’ve had my eye on ScyllaDB for a long time now, but I still haven’t had a chance to share its progress. ScyllaDB is interesting because it’s a drop-in replacement for Apache Cassandra. Many years ago, when Java seemed slow, and its JIT compiler was not as cool as it is today, some of the people working on the OSv operating system recognized that they could make many more optimizations in user space than they could in kernel space. One example of an application they targeted for improvement was Apache Cassandra, as it was powerful but slow… Fast forward seven years, and it looks like they achieved their goal and built a sustainable business as well! Among the most notable changes in ScyllaDB 5.0 is the implementation of (experimental) support for the strongly consistent DDL, which is very important, especially when your data changes, as it is likely to do.
Future changes
Data engineering tools are evolving every day. This section is about updates that are in the works for technologies and that you may want to keep an eye on.
Docker Official Image for Spark – A proposal to make Spark a Docker Official Image was recently approved. The Docker Official Image status is a way to indicate that an image is top-level and very important for the community. This type of image will usually be located not in some directory in Docker Hub but rather in the root (in this case, it should be https://hub.docker.com/_/spark). But of course, making Spark a Docker Official Image would not just entail small cosmetic changes. Docker Official Images are rebuilt proactively, so if you find yourself vulnerable to a new security breach that’s already fixed in the master, you can just download the latest version of the DOI and get back to safety. Additionally, DOIs are maintained by the Docker community, which usually means best practices are adhered to. Of course, some work still needs to be done to achieve this goal, but the proposal has already been approved and is halfway implemented.
Flink: Support Customized Kubernetes Schedulers – This proposal is fascinating. On the one hand, the authors say that the current integration of Flink with k8s is already excellent. On the other hand, they say that resource scheduling is implemented only with a very narrow set of techniques, which is not enough. They postulate that different Flink workflows require different kinds of resource scheduling and describe four strategies for resource allocation and scheduling that could significantly improve the performance of Flink jobs.
Kafka: The Next Generation of the Consumer Rebalance Protocol – The current rebalance protocol in Kafka has existed for a long time. It’s superior to what was introduced at first with ZooKeeper, but nevertheless, it’s already a legacy protocol. It relies on intelligent clients that know everything about other consumers in their consumer group and can act accordingly when the number of consumers in the group changes. The authors of the proposal state that the majority of bugs they have encountered in the protocol this year required fixes on the client side, which is indeed bad because we don’t have control over a consumer’s code, for a variety of reasons. The coming change is absolutely massive and has lots of goals, but for me, the most crucial difference is that now the broker will decide how clients should be rebalanced, allowing it to dictate changes that are as small as possible. And for clients, the process should be completely transparent.
Articles
This section is all about inspiration. Here are some great articles and posts that can help inspire us all to learn from the experience of other people, teams, and companies who work in data engineering.
Data Engineers Aren’t Plumbers – When people ask me what a data engineer is, I usually use the metaphor of a plumber. We work with pipes. We make sure they work correctly, and that they aren’t clogged, and so on, right? Well, it looks like Luís Oliveira disagrees with me. He says that data engineering work is indeed related to pipes, but in a different way, and he uses a different pipe-related metaphor. Will I use it in my future explanations? Maybe. But I suspect his explanation will raise even more questions. Nevertheless, the analogy is beautiful.
How to create a dbt package – I like dbt and even wrote a couple of posts about it. But this post brought something to my attention that I hadn’t given a lot of thought to: dbt packages. Dbt packages allow one project to depend on others, making the usage of dbt much more manageable in the event your warehouses are massive. Different teams can, for example, reuse the “common” package that contains all the basic models from your anchor-organized Data Warehouse.
How to run your data team as a product team – Sometimes, it can be tempting to conceive of data engineering as purely a technical enterprise, like plumbing. But the truth is all the data engineers are (or should be) working on a data product – a product that will solve particular problems confronting management, customers, or another party. And that’s why we should think about our tasks as engineers and as part of a product team. This post offers insight into that dual mindset.
That wraps up October’s Data Engineering Annotated. Follow JetBrains Big Data Tools on Twitter and subscribe to our blog for more news! You can always reach me, Pasha Finkelshteyn, at asm0dey@jetbrains.com or send a DM to my personal Twitter account. You can also get in touch with our team at big-data-tools@jetbrains.com. We’d love to know about any other exciting data engineering articles you come across!





