

Big Data Tools
A data engineering plugin
Big Data Tools 2023.1 Is Out!

Our latest release includes several new features and improvements based on feedback from our users. In this release, we’ve added integration with Kafka Schema Registry, Kerberos authentication, and extended support for all cloud storages in Big Data Tools. Read on to learn about the most important changes in the Big Data Tools plugin or try it right now by installing it to IntelliJ IDEA Ultimate, PyCharm Professional, DataSpell, or DataGrip 2023.1.
New: Kafka Schema Registry connection
In response to numerous requests, we have integrated the Kafka Schema Registry connection into the Big Data Tools plugin 2023.1. The Schema Registry defines the data structure and helps keep your Kafka applications synchronized with data changes. With this latest update, you can explore Kafka topics serialized in Avro or Protobuf directly from the IDE.
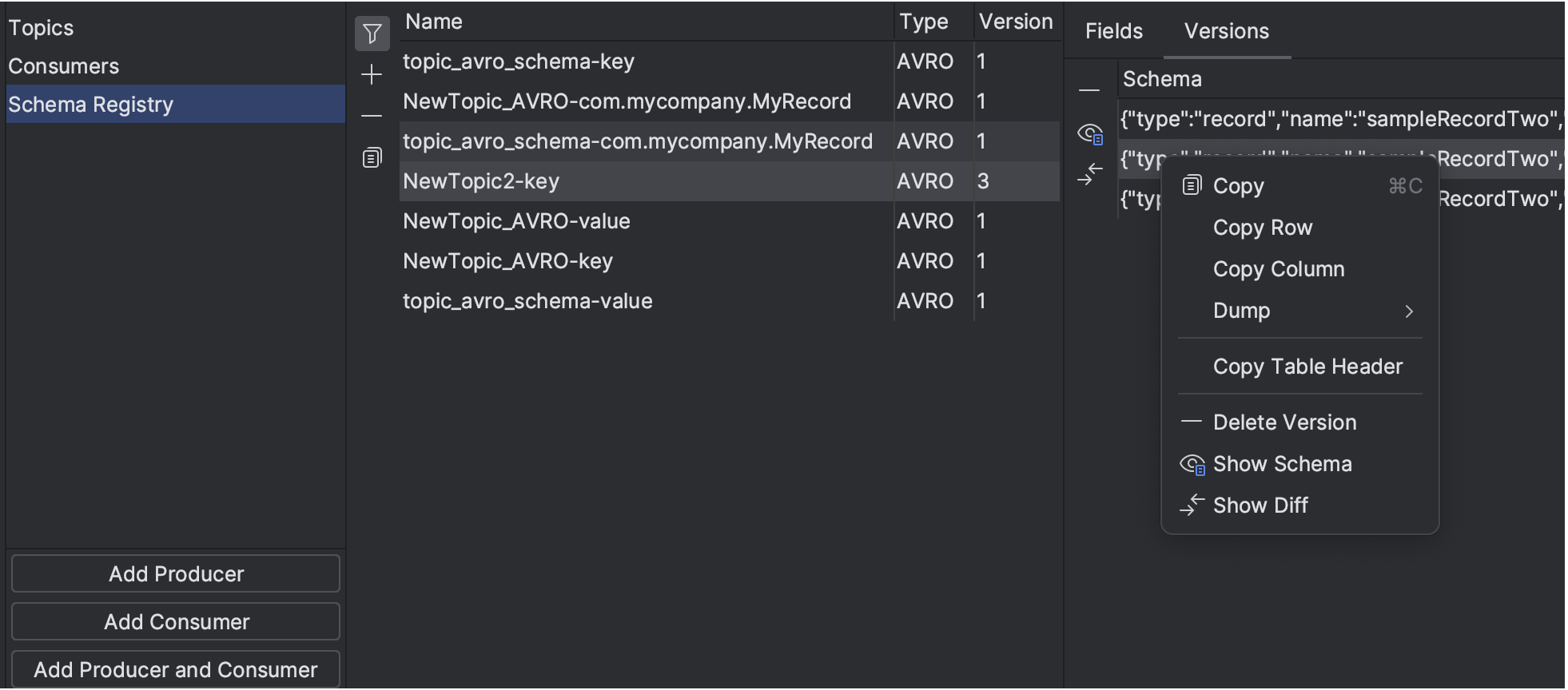
We also enabled a connection to Schema Registry via a secure SSH tunnel to help you consume and produce messages from your local machine.
More convenient work with cloud storages
We have aligned our feature set between all supported remote file storages (such as Amazon S3, Google Cloud Storage, and Microsoft Azure Blob Storage). Here are the most notable improvements:
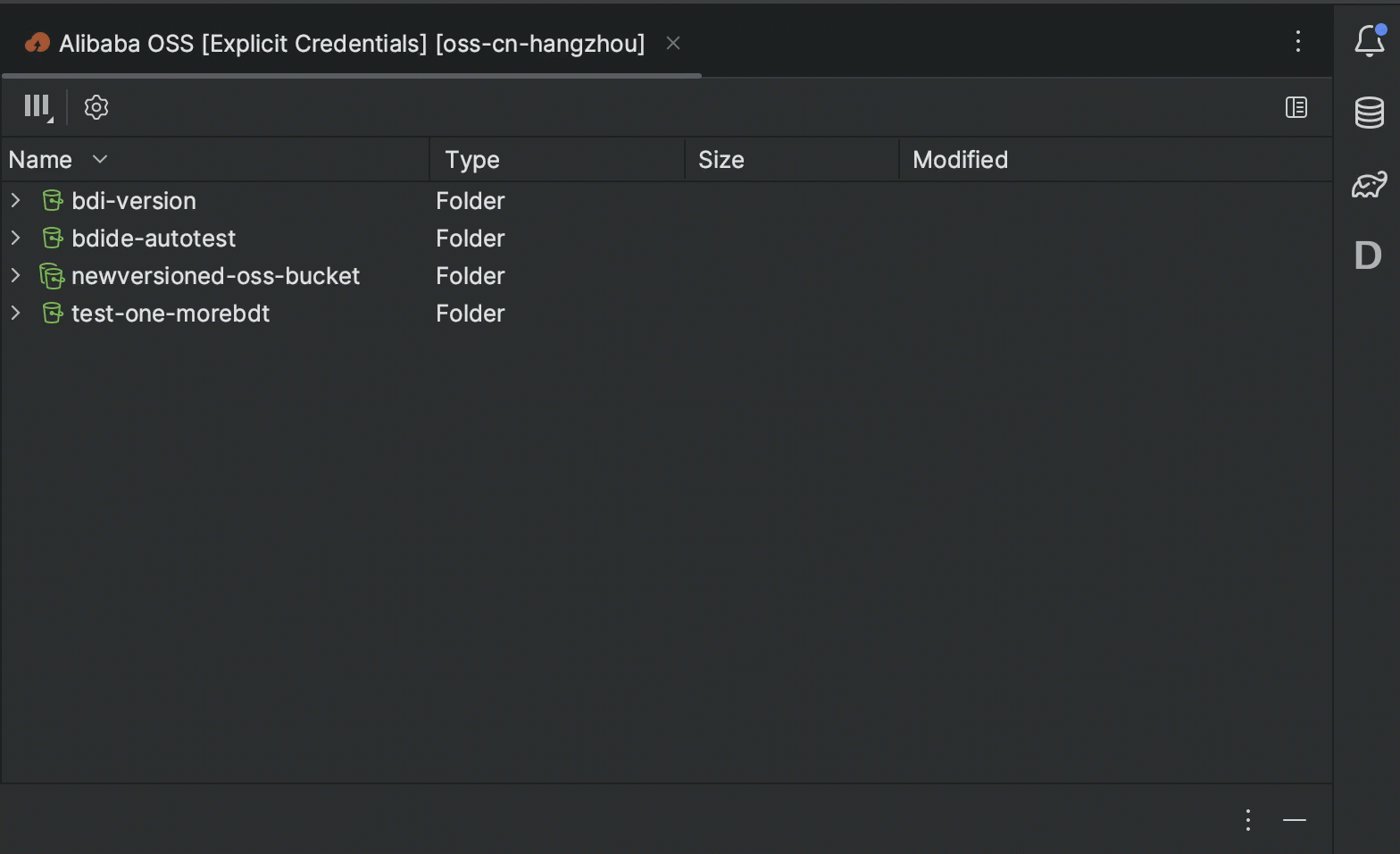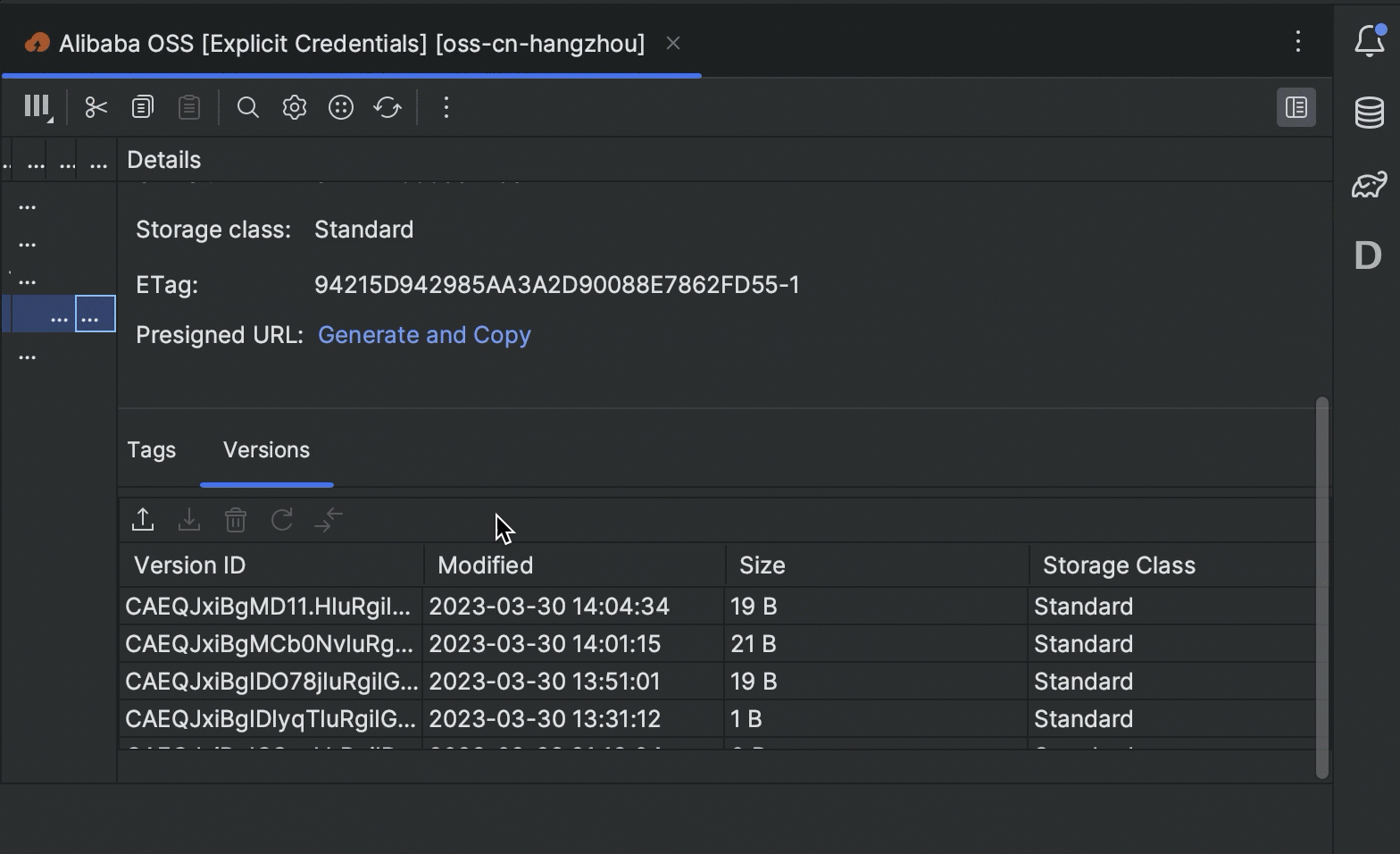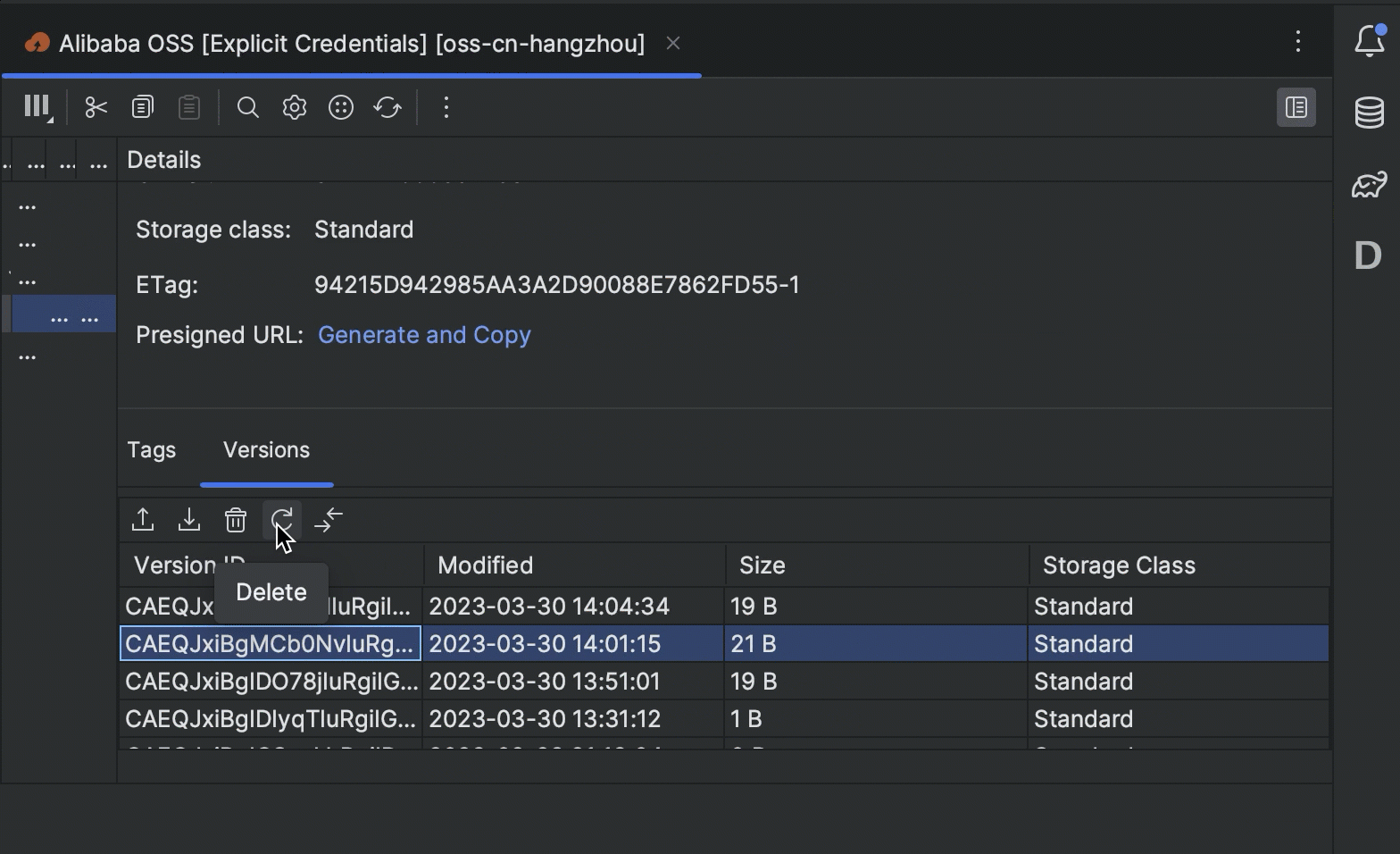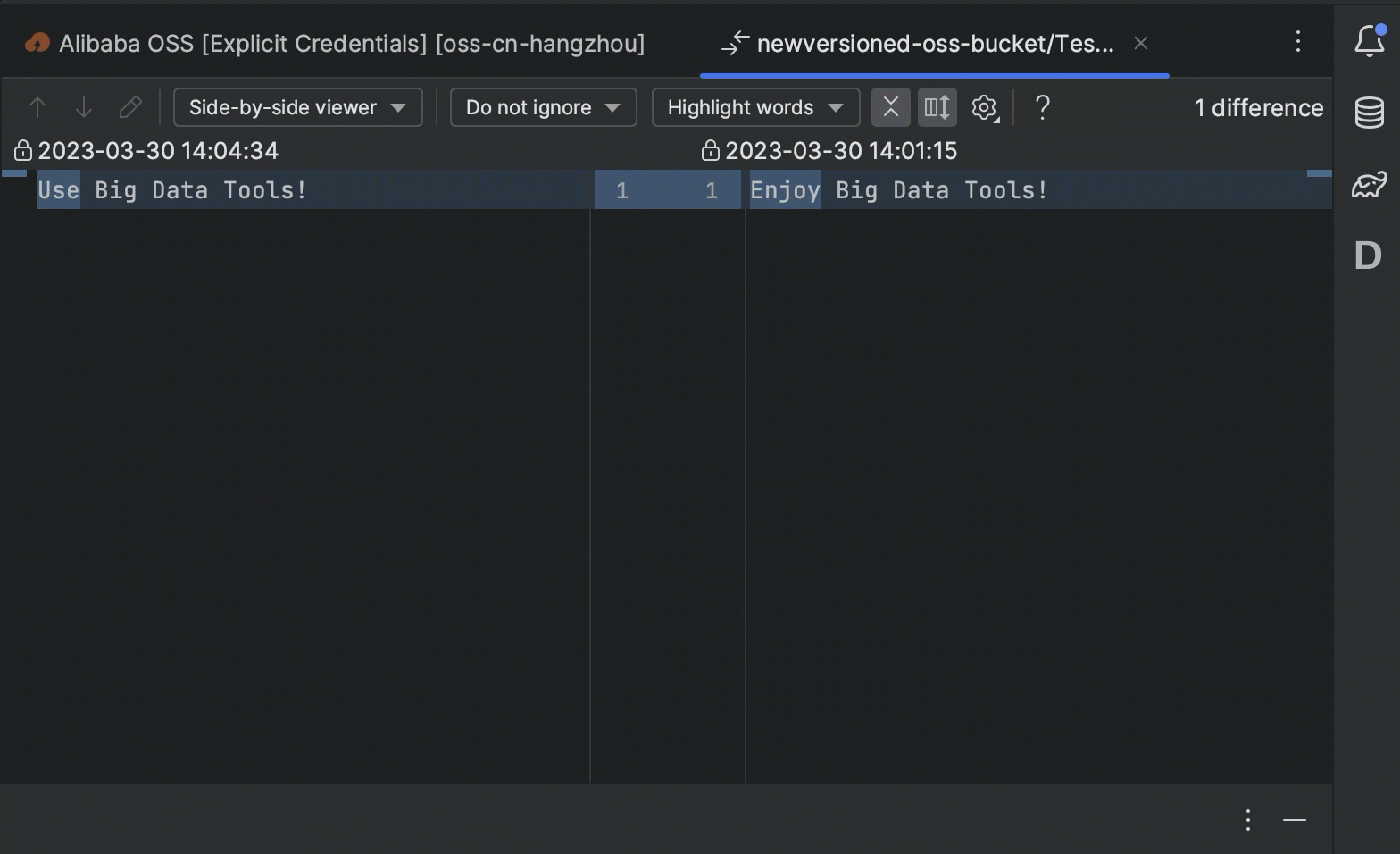
- You can now view and manage versions of the bucket objects right in your IDE.
- If you use object or bucket tagging to categorize storage, you can now modify and view them without leaving your editor window.
- The new contextual search feature lets you quickly locate a specific bucket in your cloud storage by typing relevant keywords.
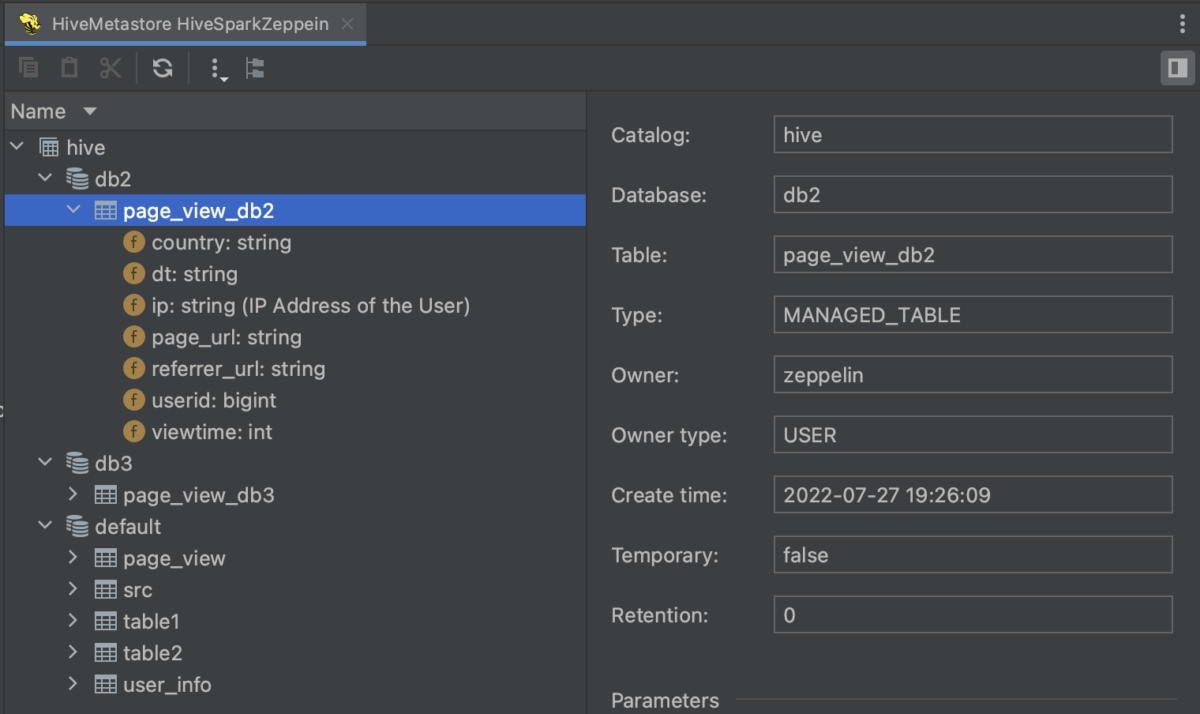
Extended Hive Metastore integration
Now the plugin supports both Hive 3 and Hive 2, allowing users to preview and understand their data within their IDE. You can open the Hive Metastore or its particular catalogs, databases, and tables in a separate tab of the editor.
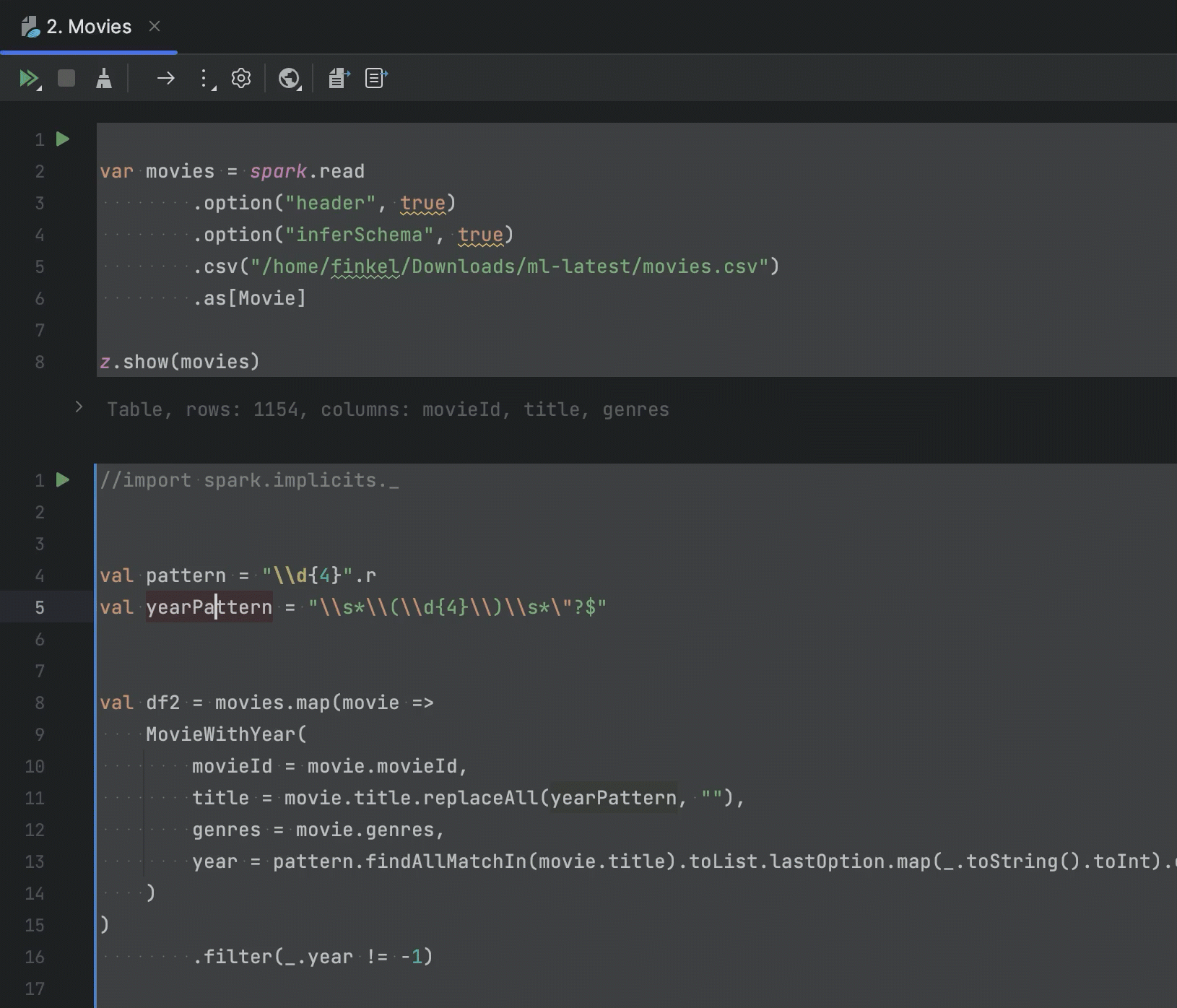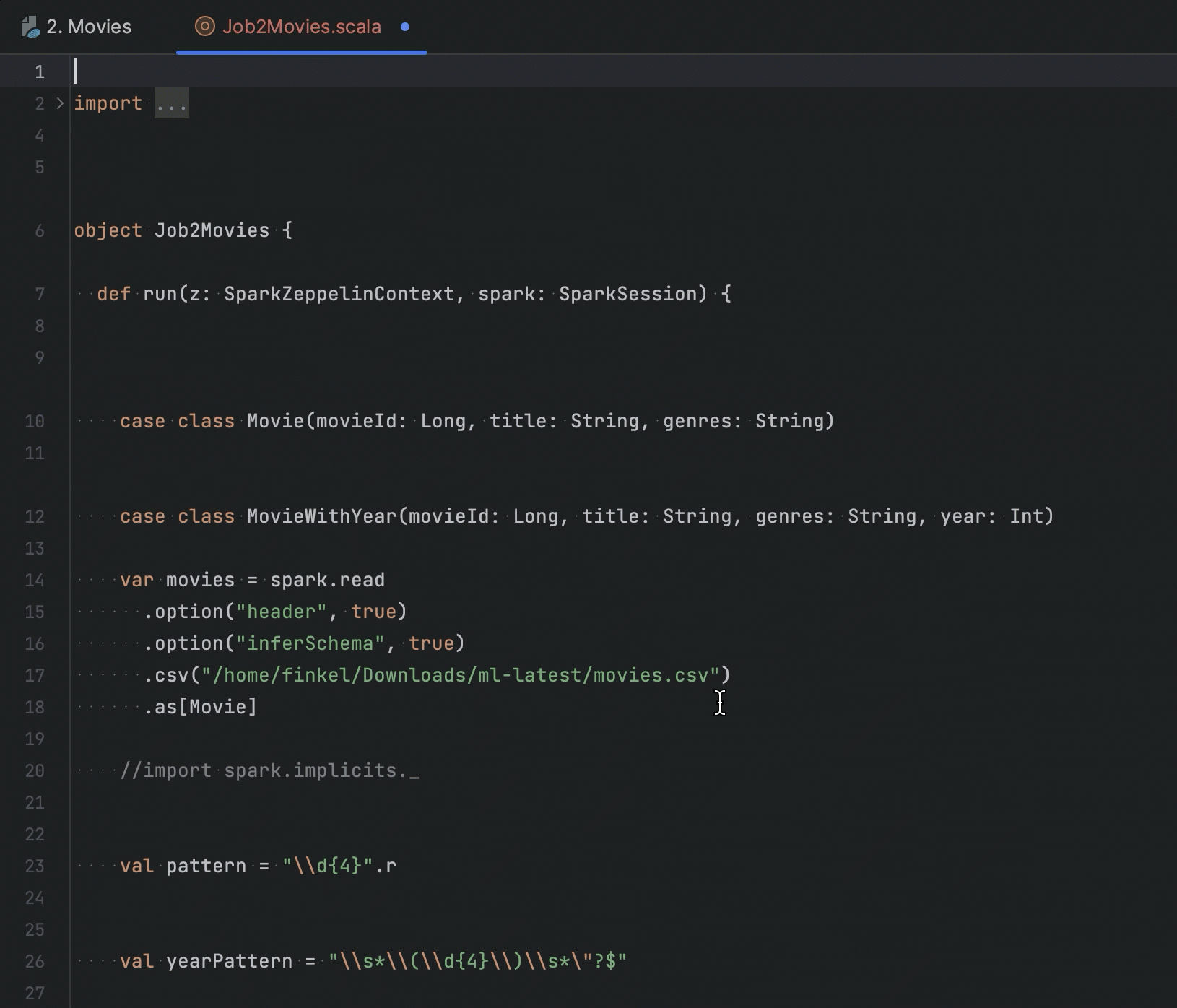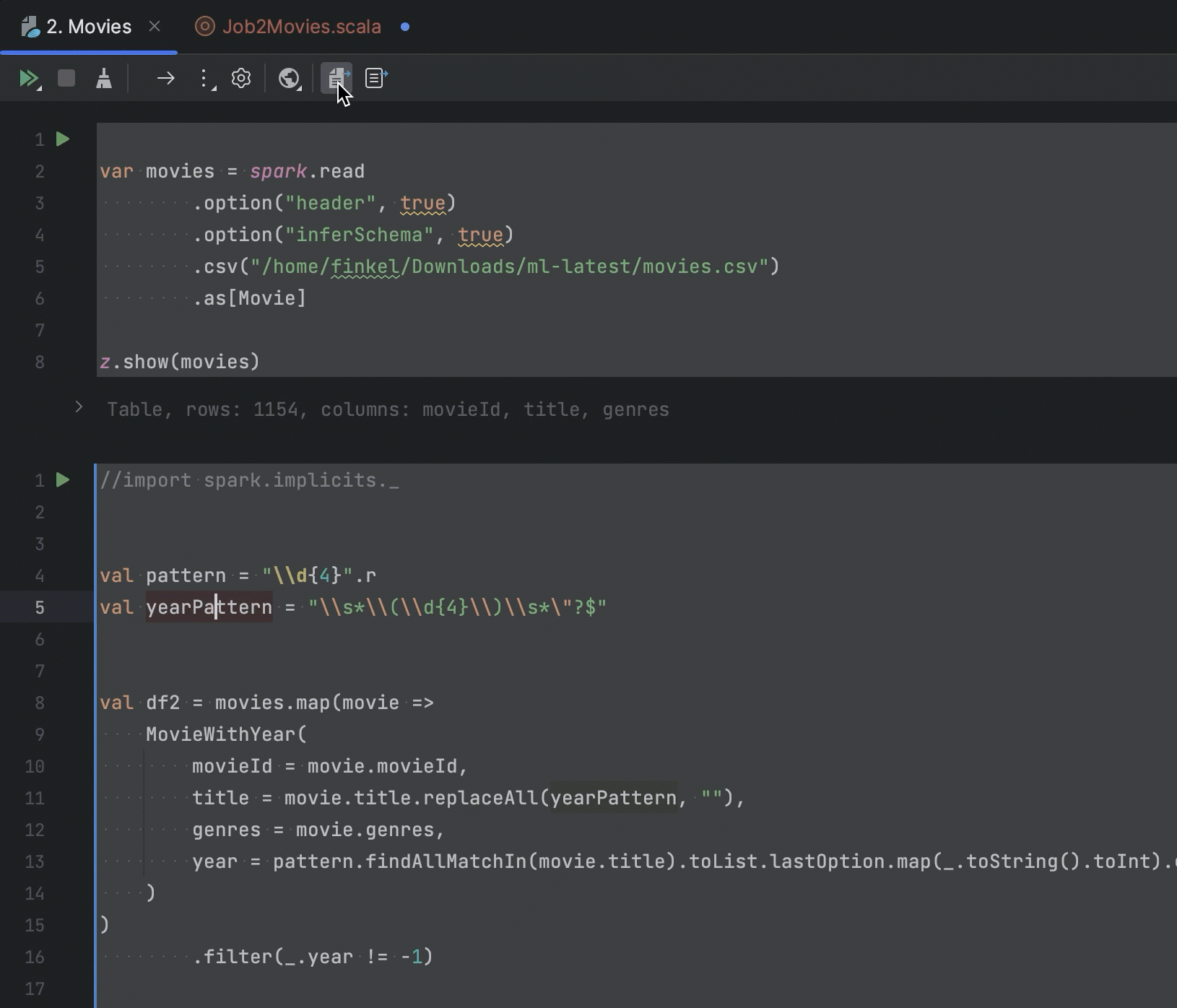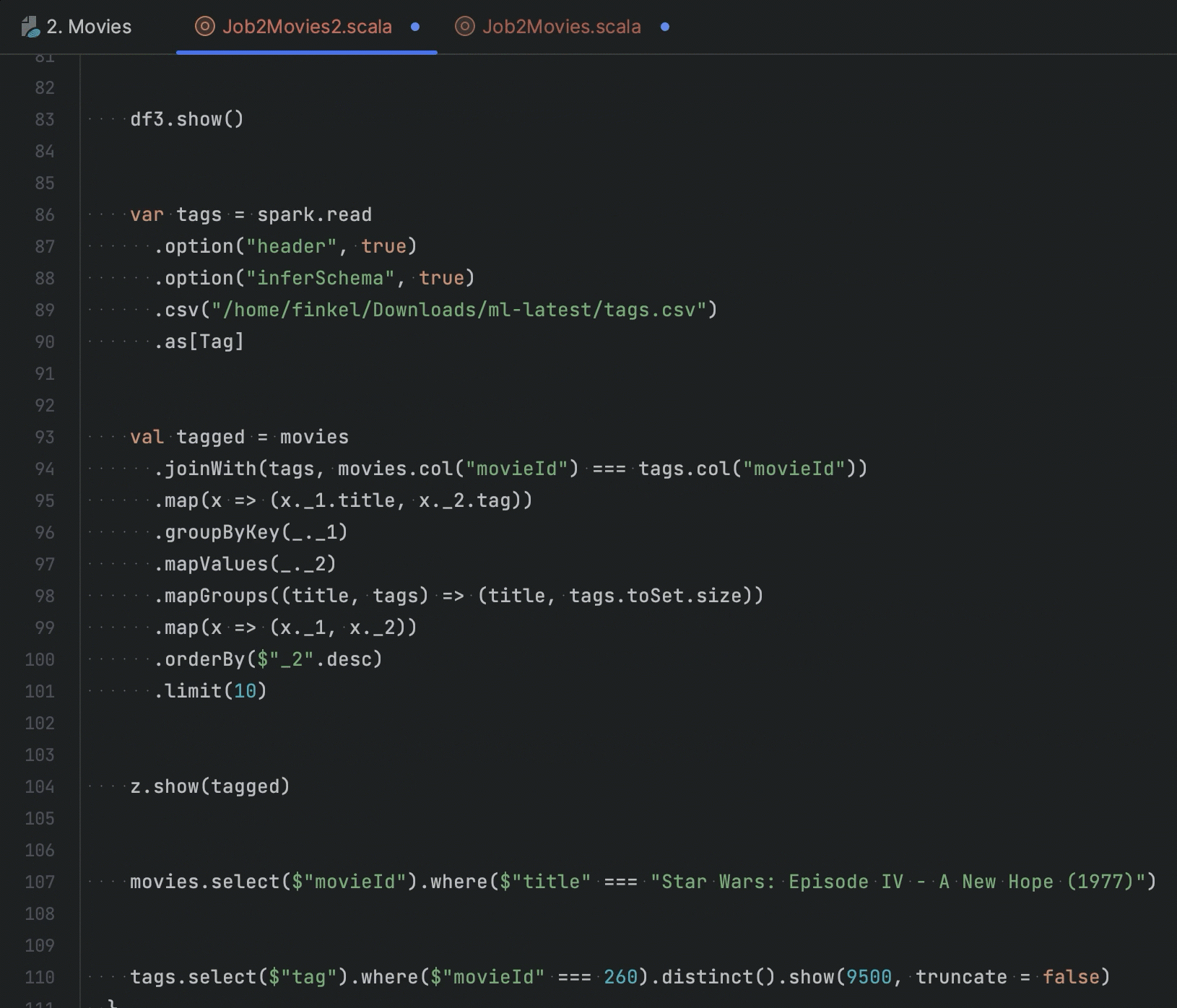
Improvements to Apache Zeppelin integration
If you are working with a Zeppelin notebook in your IDE, you can extract Spark job code into a Scala file to continue working on it in an IDE project. In this release, we have added options to extract both selected Scala code and code from paragraphs.
We’ve added code completion for PySpark paragraphs in Zeppelin, which completes column names by providing a list of the inferred columns from the DataFrame.
We’ve also consolidated Dependencies and Interpreter Settings into a single window, making it easier to find the necessary settings.
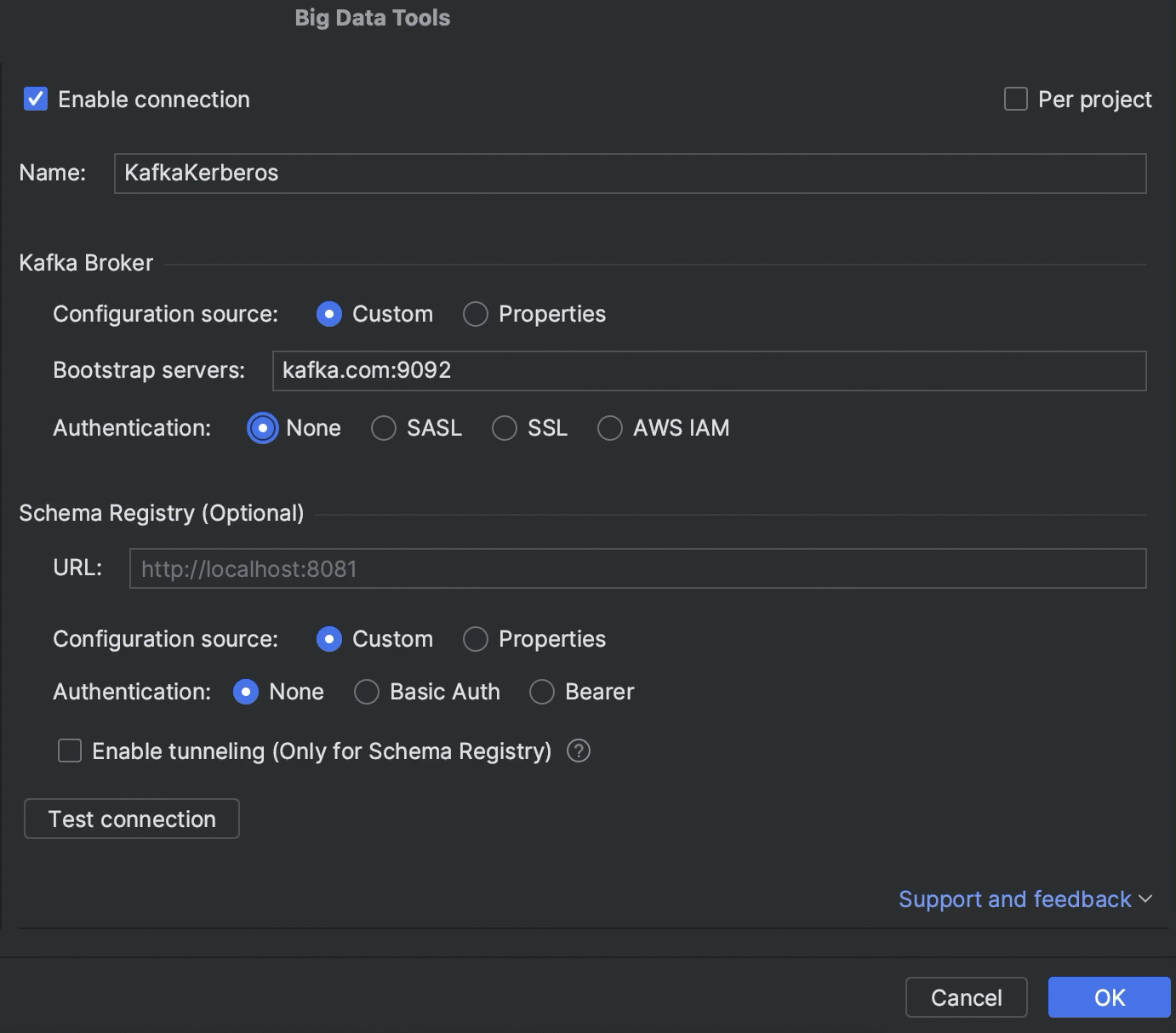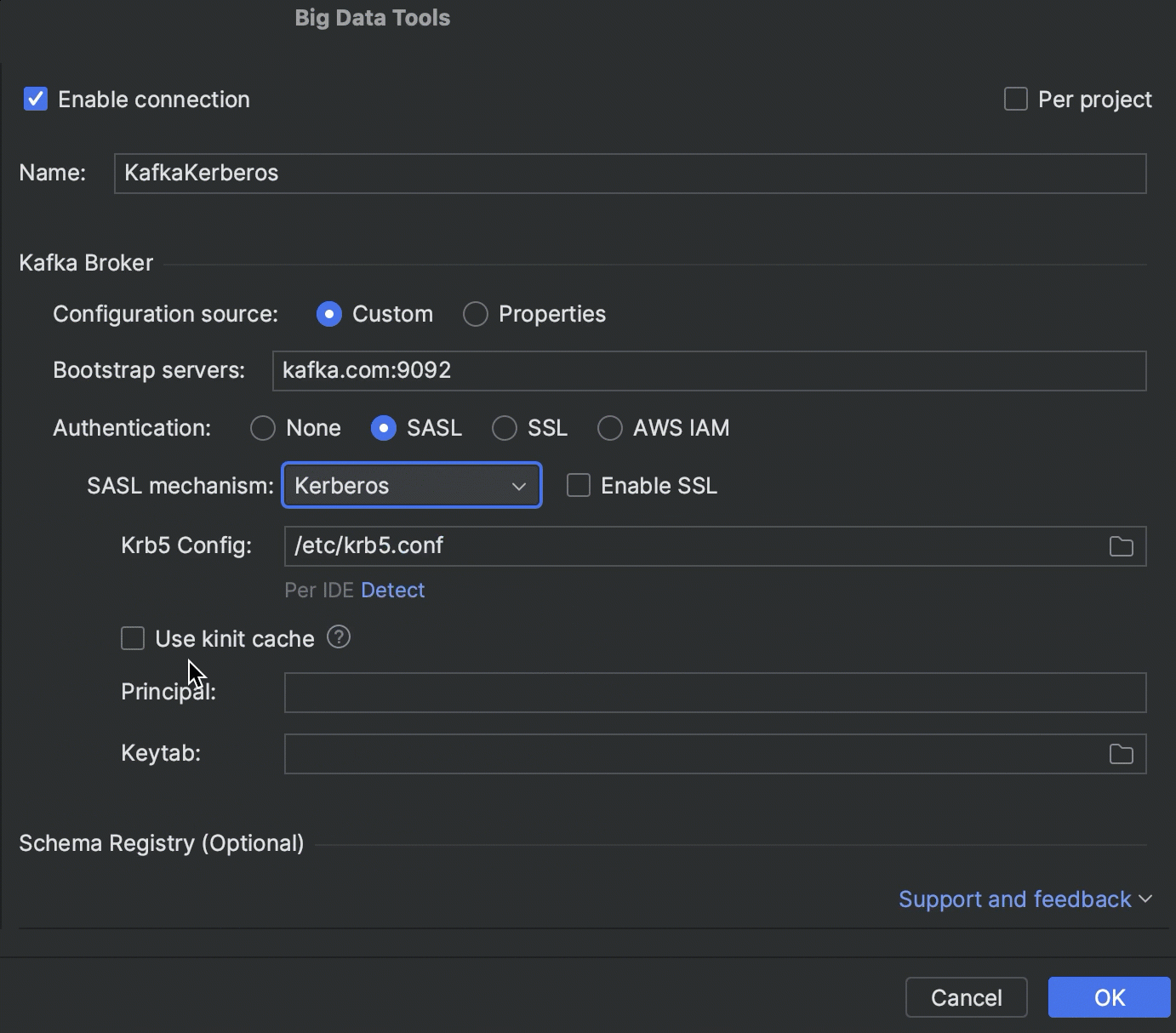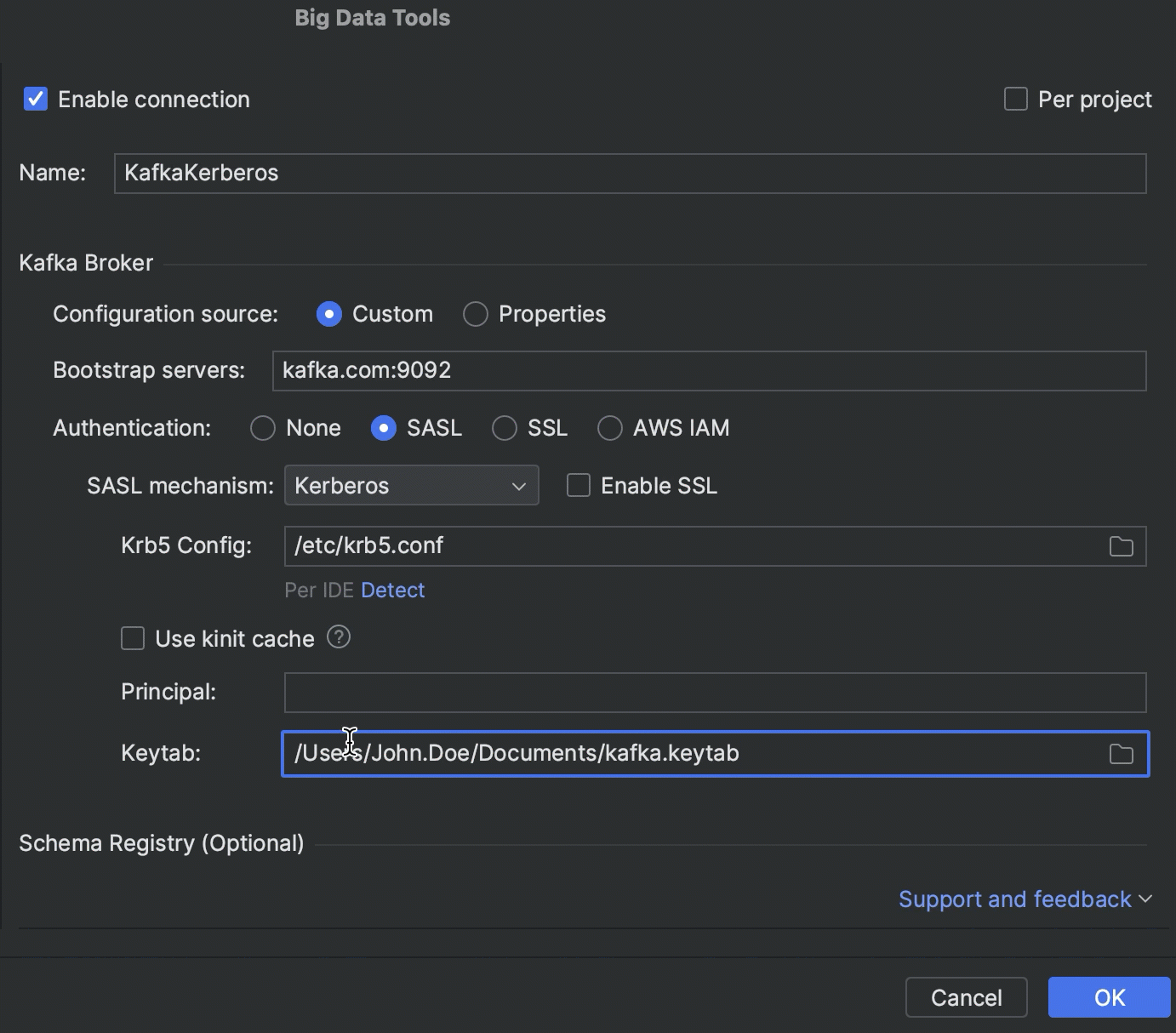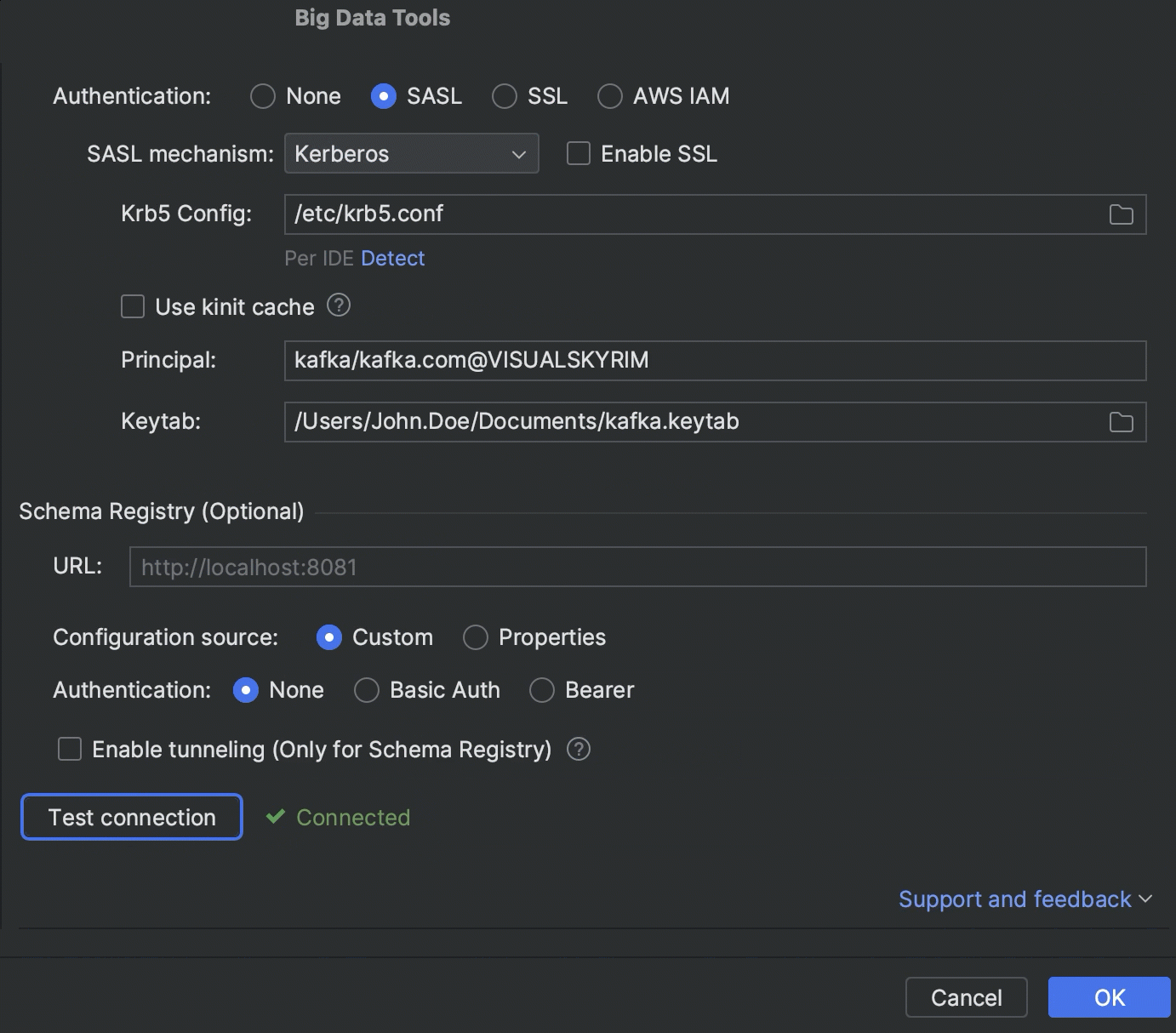
Kerberos authentication
It is now possible to connect to Kafka, HDFS, and Hive Metastore by using Kerberos authentication.
Single authorization in AWS services
We’ve added the ability to share AWS authorizations across AWS S3, AWS Glue, and AWS EMR connections. This eliminates the need to repeatedly enter keys or perform MFA authentication for each connection.
Viewing big data binary files
With the Big Data Tools plugin, you can conveniently preview the content of big data file formats without leaving your IDE. The latest release enables the opening of Parquet files that use compression methods such as zstd, Brotli, and LZ4.
For the full list of new features and enhancements, see the changelog on the Big Data Tools plugin page. Please share your feedback with us and report any issues you encounter to our issue tracker.
The Big Data Tools team




