C++ Annotated October 2021: CppCon-dedicated Podcast Episode, Combining String and Templates, Move vs. Copy, and UDL Basics

We have all the October news for you in our latest monthly C++ Annotated digest and its companion, the No Diagnostic Required show.
If you have already subscribed, feel free to skip ahead straight to the news. If this is your first time here, let us quickly take you through all the formats we offer. You can choose to read, listen, or watch our essential digest of the month’s C++ news:
- Read the monthly digest on our blog (use the form on the right to subscribe to the blog).
- Subscribe to C++ Annotated emails by filling out this form.
- Watch the No Diagnostic Required show on YouTube. To make sure you hear about new episodes, follow us on Twitter.
- Listen to our podcast – just search for “No Diagnostic Required” in your favorite podcast player (see the list of supported players).
CppCon-dedicated NDR podcast episode
This month, our edition of No Diagnostic Required is a little bit different from our regular episodes. There are two reasons for that. First, our colleagues from the CppCast podcast (a highly recommended podcast for any C++ developer with great hosts, Rob Irving and Jason Turner) recently noticed that there are other C++ podcasts, but not many of them are regular. CppCast and NDR are, but Cpp.Chat, hosted by Phil Nash and Jon Kalb, hasn’t been released for a while. So I suggested to Phil, who is the host for both Cpp.Chat and NDR, to record a joint episode to breathe some fresh life into Cpp.Chat. Second, CppCon was held live just a week ago. Being the biggest C++ event in the world, it brought lots of new C++ insights, inspiration, and knowledge. There were a lot of new things to discuss at this hybrid event after our year-and-a-half lockdown! It’s a great occasion to have a chat with the organizer, coincidentally Cpp.Chat host Jon Kalb, about this year’s edition and its highlights.
Please welcome the special October edition of No Diagnostic Required show paired with Cpp.Chat:
October news
- Easy Way To Make Your Interface Expressive
- Don’t reopen namespace
std - Moves in Returns
- C++ Smart Pointers and Arrays
- A Recap on User Defined Literals
- Combining String and Templates. What could go wrong?
- JetBrains shares CppCon Keynotes Recordings
- C++ tools evolution: static code analyzers
- Language news
Easy Way To Make Your Interface Expressive
The article addresses the case of code readability, specifically the case when two parameters of the same type (bool in the example) are passed to the function or as template parameters. How often have you written code like this? How often have you accidentally passed arguments in the wrong order, and broken the code? The article talks about several approaches to avoid the issue, specifically:
- Expressing the meaning of the parameters in the code itself.
- Preventing the wrong usage at compile-time.
The list of suggestions starts from a native suggestion to always add comments to the code, then goes through type aliases, and finally, strong types.
Don’t reopen namespace std
Arthur O’Dwyer wrote a blog post proving that users should define template specializations using their qualified names instead of reopening the namespace std. Readability and clean code is one reason for this. A less obvious reason is that names can collide with something in the standard library if the code is placed inside the namespace, meaning you might need to qualify names inside curly braces.
An interesting case is covered at the end of the article. The sample looks pretty typical, but it produces undefined behavior. It reopens the namespace std and inserts an overload of the standard function that works specifically with some user’s type. However, users are not allowed to add new overloads of functions in the std namespace, so the bad practice leads to undefined behavior in this case.
Moves in Returns
Is the return value moved or copied? The classic C++ question was raised and discussed through different samples in this article, written by Philip Trettner. The author doesn’t just discuss where the return values are copied, moved, or directly constructed in memory, but also shows the assembly to analyze the call graph.
The cases discussed are:
- Directly constructing objects in memory provided by the caller function (“unmaterialized value passing”).
- Returning a local variable and a named return value optimization. Again, if all the paths through the function end in returning the object, the compiler could use the caller-provided space for the return value, avoiding any copying or moving.
- Returning a function parameter that behaves differently.
- Moving from a local variable.
- Two types with implicit conversion used in the
returnstatement (which, interestingly, is a copy in pre-C++14, and move in newer standards). - There are some cases that trigger copy, not move.
C++ Smart Pointers and Arrays
Bartlomiej Filipek posted a couple of new articles about smart pointers on C++ Stories in October. One of them is dedicated to smart pointers and arrays. In this blog post, he looks at ways to create and initialize smart pointers for arrays. Using an interesting addition coming from C++20, he uses a set of functions to skip value initialization to achieve better performance (function with _for_overwrite suffix).
The article also presents a nice summary of the Stack Overflow discussion on whether you need unique_ptr with an array when you have std::array and std::vector. A table comparing the techniques can be used as a practical guide:
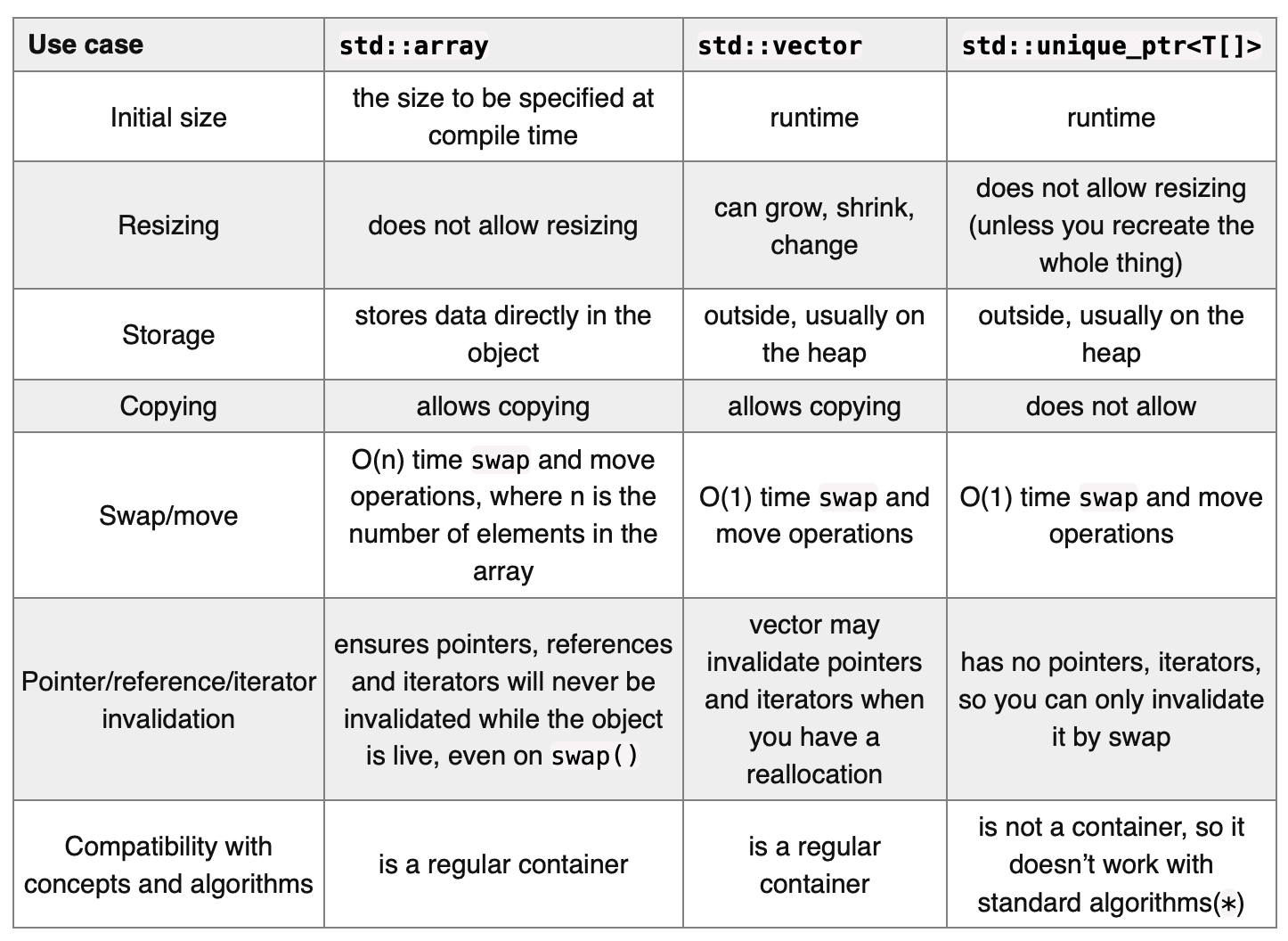
You can look through it and select the conditions that are important or applicable to your case to get a solution.
A Recap on User Defined Literals
There is another article on more expressive and readable code. In his new blog post, Jonathan Boccara provides a refresher on the basics of user defined literals and how to work with them in C++11/14/17. He discusses various useful aspects, like the types allowed for UDL, and some interesting rules to remember (e.g. for suffixes starting with capital letters there should be no space in the prototype between operator"", and the starting underscore of the user-defined suffix should be present).
C++14 and C++17 brough UDLs to the standard library. String literals (C++14) with the s suffix, chrono literals (C++14) with all the time and date related suffixes, and string view literals (C++17) with the sv suffix are discussed in the article.
Combining String and Templates. What could go wrong?
“Stringy Templates” is a nice article discussing the newest language ability to pass strings as non-type template parameters. Non-type template parameters have a very important characteristic – when used with the same template argument, they then define equal specializations. The equality of the template argument might be a compile-time calculation, rather than just using exactly the same entity. C++20 builds on this by allowing class-type non-type template parameters when several conditions are fulfilled, finally making using strings as template arguments possible. The article presents the implementation via the fixed_string type. It also gives an interesting practical example at the end, when given strings should name a valid/registered type.
JetBrains shares CppCon Keynote Recordings
CppCon is a great annual gathering for C++ specialists and those interested in the C++ ecosystem. It brings new proposal announcements, talks about the implementation details of various C++ features, and presents new tools and techniques to the public. After a 2-year break, CppCon’21 is back to the regular in-person format, while also running a Hybrid format. If you were unable to attend the conference in person or online, JetBrains provides you an opportunity to keep up with the hottest news from the world of C++. This year we became an official CppCon YouTube channel sponsor and compiled a special page with the CppCon’21 keynote session recordings.
Timur Doumler, who recently joined the JetBrains C++ team as a Developer Advocate, was among those lucky in-person visitors and shares his impressions of the event in his trip report.
C++ tools evolution: static code analyzers
If you are not yet convinced that static analysis is that helpful and you need more real-world samples to help you decide, check out this article by the PVS-Studio team. It starts with a few interesting examples from CovidSim, StarEngine, and LLVM projects. There are some basic errors that could hurt in some unlucky conditions.
Static code analysis can help prevent such errors, along with code reviews, testing, and techniques like sanitizers. The article is focused around a specific analyzer created by the authors and available both as plugins to various IDEs and as a stand-alone tool. The author shows the various errors it catches in Poco and other projects. The spectrum of issues discussed are memory safety issues, cases of undefined behavior, and always-true code branches.
Finally, the article discusses various static code analyzers and how to choose from the existing selection. It also brings to light the topic of false positives and an analysis baseline.
Language News
As usual, there are some highlights from the world of C++ standardization.
P2465r0 – Standard Library Modules std and std.all
Modules are here – they’re just not evenly distributed (that’s a reference)! While we wait for the tools to catch up and give us an opportunity to see if they live up to their promise, you might feel disappointed that the standard library itself is not available as a module. This paper proposes to fix that with not one, but two standard library modules. Importing std gives you all of the standard library within the std namespace, including all the types and functions inherited from C. Notably it does not export any of the C identifiers in the global namespace, even if the corresponding #include <cheader> might have done. If you have existing code that depended on those identifiers being in the global namespace then importing std.compat is for you. It imports the identifiers exactly as the <cheader> #includes would have done. Note, though, that neither of these modules export any macros. If you depend on any standard library macros, like assert, or the feature test macros, then you still need to #include the appropriate header. With so few macros necessary now, this is probably the best approach, especially if we eventually get contracts (to, among other things, replace the assert macro). Speaking of which …
P2461r0 – Closure-Based Syntax for Contracts
Last month I mentioned that there was a new paper, not yet published, that proposes an alternative syntax for contracts that is based on the lambda capture syntax. That paper has now landed, so we can talk more about it.
P2388 proposes a syntax that looks like attributes, but is not strictly attributes syntax due to the presence of a colon character and other possible future extensions along the lines of C++20 contracts. This paper proposes (almost) exactly the same semantics, but with a different syntax. Instead of looking like attributes, this one looks like lambdas! The three keywords: pre, assert, and post, are preserved, but now they are outside of square brackets and are followed by a(n optional) captures list and a body in curly brackets that contains the checking code. For postconditions the “lambda” may also take an (optional) argument – the return value.
At first it may seem like the “looks-like-attributes-but-not-quite-attributes” problem has been perpetuated, but with lambdas. It’s true, there is some divergence from lambdas as we have today:
- The captures list is optional. In fact, for this first MVP step it must be omitted! For “real” lambdas the captures list also functions as the “lambda introducer”, so it is syntactically required to be present, even if empty. In this case, the context sensitive keywords
pre,post, orassert, take care of this role, so it makes sense that it can be omitted (in which case it is as if[&]was specified). - Only the postcondition can take an argument, it can only take one argument, and it must correspond to the return type. This is an extra restriction, which we could relax in the future if there was a good reason, so it’s not really a divergence.
- There is no return statement (or, rather, it is optional). The conditional code in the body is evaluated and “returned” implicitly. This is actually abbreviated lambdas – which are still in flight – so this syntax is subject to change. However, this is a perfect candidate for abbreviated lambdas.
- No type is specified for the return value argument to a postcondition. As in point 3, this is abbreviated lambda syntax (albeit one of the extensions). It is implicitly
auto&&.
There are a number of advantages to this syntax that, for me at least, suggest this is a particularly promising direction:
- When you look at the code, your intuition and prior knowledge of lambda syntax makes it easy to understand, even with the abbreviated syntax. If and when the captures syntax is allowed, it should also be obvious what it means, especially when reasoning about the value of mutating parameters by the end of the function (although this raises some questions of its own).
- There is also an intuitive mental model for what gets executed and when. Captures are evaluated up front. Bodies may be executed at any time or not at all (we don’t see their invocations, so we shouldn’t depend on them), but even if not executed, they must compile.
- Some parts of the syntax are overly restricted for the MVP, but it is easy to see how things would be handled in the syntax in the future, like stateful post-conditions.
- We will get the benefit of any evolution of lambdas themselves, like abbreviated lambdas and destructuring for return values.
- No new “mini language” to learn.
- We can use attributes against contracts.
- Evolving the semantics is unlikely to have ABI implications for currently foreseeable evolutions.
On the positive side, this proposal has generated a lot of interest and discussion, with many very much in favor of it. On the other hand, if there was any chance we might be able to get minimal contracts support in C++23, this new discussion has probably put an end to that.
P2445r1 – std::forward_like
C++11 introduced move semantics with rvalue references, and std::move and std::forward along with them, to help us achieve “perfect forwarding”. For many developers these can still seem like a bit of a black art, even a decade later, but for library implementers they are essential tools to achieve optimum performance with a clean interface (even if the internals get a bit messy). While std::move turns an lvalue into an rvalue, std::forward aims to preserve the value category of what it is passed, but requires the unqualified type as a template argument to do so. However there are some cases where you need to also consider the value category of another type. This gets quite esoteric in the abstract, but the motivating use-case here is Deducing This. If this is an explicit, templated, parameter then the value category of the owning object becomes generic – which is the main point of Deducing This – but that influences the value category of members that you may need to forward. Unfortunately just taking the decltype of the member is not enough, and there are several models for how these value categories interact with subtle differences that are important in different situations. Understanding the implications of these models and getting them right can be tricky, so having such a facility in the library would be a useful tool to use alongside explicit this parameters when we get them in C++23.
P2012r2 – Fix the range-based for loop, Rev 2
Usually we discuss proposals that are in flight, or have been adopted into the working draft. This one, for now at least, has been rejected! However, there is a strong consensus that the issue it attempts to solve is worth addressing, so it’s likely to come back. Whether it’s in a similar form or with a different approach is yet to be seen. So what’s the problem with range-based for loops?
On the face of it, the problem is just a special case of dangling references. But there is a tight interplay between lifetime extension of temporaries, and the generative nature of range-based for loops, which makes this case particularly pernicious. Take the following example:
for (auto elem : createPerson().getValues()) {
std::cout << "value: " << elem << "\n";
}
Now if createPerson() returns a temporary, and getValues() returns a reference into that temporary, we end up with a dangling reference. This may not seem intuitive, since the similar looking:
if(auto elem = createPerson().getValues()[0]) {
std::cout << "value: " << elem << "\n";
}
works due to lifetime extension! The lifetime of the temporary is extended to the end of the statement it was created in, by which time we have copied the element into another variable. It looks like the same should be true of the for loop. But, in fact, the for-loop is specified to be as-if the expression had been written as multiple statements. So the statement that creates the temporary has finished before the loop begins and therefore has already been destroyed! It’s primarily that (effectively) code-generation step that causes the problem. We don’t see the separation of the statement introducing the temporary from the part that assigned an element to the loop variable.
The paper proposes to fix the issue by changing how the range-based-for is specified, so that the lifetimes of all temporaries created in the range initializer are extended. This seems reasonable but was rejected in the committee vote. Why was it rejected? It’s difficult to say too much without quoting individuals, but two objections seemed to be the main causes:
- It’s a breaking change. The paper argues that this is a technicality that we shouldn’t meet in practice – except with code that was already broken. Some reviewers disagreed.
- There is a separate effort to specify ways that temporary lifetimes could be extended in similar ways. The outcome of that work could supersede what the paper proposes or conflict with it.
Hopefully this will come around again in a way that addresses these concerns. In the meantime, a better option may be to use for_each, which already has the intuitive behavior, and in its ranges form (ranges::for_each) is almost as succinct as the language construct anyway.