

DataGrip 2017.1 Released!

Hello! From this post you’ll find out what’s new in DataGrip 2017.1.

It is a long read, so let’s begin with the table of contents.
Database tree: New schema management, SQL resolution scopes; Create database/schema UI; Color settings affects editor and grid.
Import/export data: Column mappings and DDL preview; Drag-n-drop tables; Export result-set to a database.
Query Console: Respecting the default search path in PostgreSQL; Trigger generation pattern; Insert string concatenation on Enter option; Settings for Qualifying objects and more.
Database objects: Double-cliсk opening of column details in Modify table; Warning if object has been changed in another place.
Miscellaneous: Query time and column/row numbers in data editor status bar; Including/excluding text occurrences in Find Usages; Windows authentication for SQL Server in jTDS driver and more.
Below come the details.
Database tree
New schema management
Now the schema selection UI is a tree with the ability to choose if you want to introspect the current schema/database or, all schemas/databases. The ‘Schemas…’ node in the database view will also show this tree.

The Schemas tab comes back to the data source properties dialog. We added the Pattern field, where you can describe what you want to be introspected. The Ctrl+Q (Ctrl+J for OSX) shortcut will give you information about the syntax.

SQL resolution scopes
As you know, DataGrip resolves objects from SQL code to your database. It means that the IDE understands which particular object you use in your script and provides navigation, code completion, and everything else that we are proud of. But previously this process incurred some difficulties if objects in code were unqualified. For instance, if your script contained just table names without schemas or databases, and there were two identical data sources, test and production, then the situation would become confusing.

Now, you can simply map any file or folder to any datasource in Settings → Database → SQL resolution scopes. This means that all unqualified objects will be resolved to the selected datasource/database/schema. The project level mappings are the same as Options → Resolved unqualified references in previous versions.
Create database/schema UI
Many of you asked us to implement some simple UI for creating schemas and databases. Voila!

Decide if you want these new schemas and databases to be introspected immediately. This also applies to creating and deleting schemas/databases from the query console.

NB! As we still do not support several databases for PostgreSQL, any database created in this UI will not appear in the database tree, even if this option is enabled. Please create another data source to manage your new database.
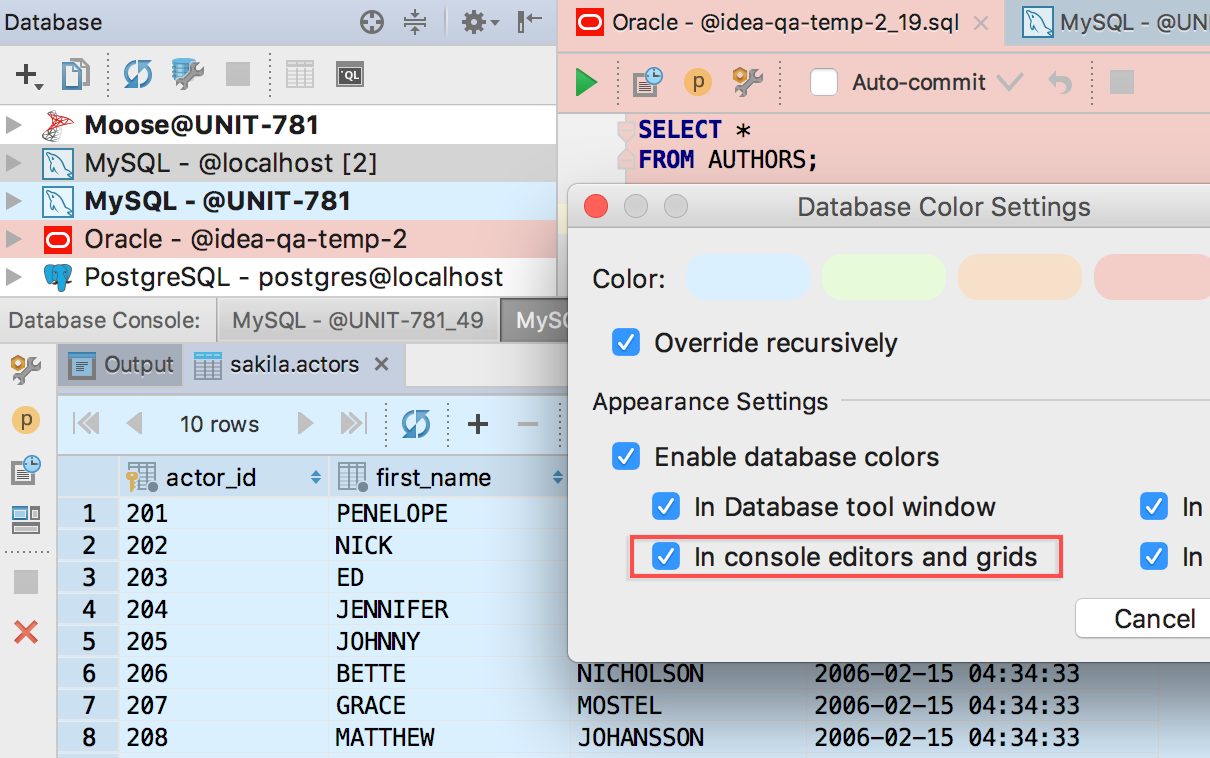
New options in color settings
Data Source color (Context menu→ Color settings) now affects the console and result tab toolbars. It can even be applied to the editor and grid as well. We hope this will help you avoid running test scripts on your production databases.
SQLite better introspection
We introduced a small database tree improvement for SQLite users. In earlier versions, we used the introspection provided by JDBC-driver for SQLite. As a result, many objects were absent in the database tree and some source codes were incorrect. Now we show triggers, expression indexes, partial indexes and check constraints.

Import/export data
Import dialog enhancements
We’ve been asked to make the import process more flexible. It frequently happens that the number of columns in a .csv file is not the same as in the target table. Or you just want to import several columns from a file, but not all of them. Now it’s possible to map every column of the file being imported to a table column in your database, which can be either an existing table or a new one created during the import process. Of course, completion works for column names.

Another new thing in this window is a DDL preview tab, showing you the code to be executed for creating or changing the table.

Export/import tables
Now there is an easy way to export tables and their data from one database/schema to another. It works even if the tables are in different databases from different vendors. For example, if you need to copy a table from a PostgreSQL database to a SQL Server database, just drag-n-drop it. Check if all is OK in the Import table window and go ahead!

The same for the result-set! We added the Export to database button. Choose any schema in the list and go ahead: the new table is created, the data is inserted.

Query console
Respect the default search path
Here is the most important point for PostgreSQL users: now DataGrip respects the default search path. Before, we set the search path according to the context of the console opening. At some point we discovered it wasn’t very convenient for many of you. Now the default search path is set for any console. Change it in any moment or go back to the default one.

Better triggers support
A trigger template has been added to the Generate menu, which is invoked with Ctrl+N (Cmd+O for OSX).

The IDE supports NEW/OLD and INSERTED/UPDATED tables when creating or editing triggers. This means you can use completion for these tables’ columns as well.

Code assistance
Try enabling Settings → Editor → Appearance → Show parameter name hints: DataGrip will prompt you about column names in INSERT statements.
![]()
We’ve added an SQL section to Settings → Editor → Smart Keys.

The Insert string concatenation on Enter option lets you choose if you actually need this. It was the default option before, and it works like this:
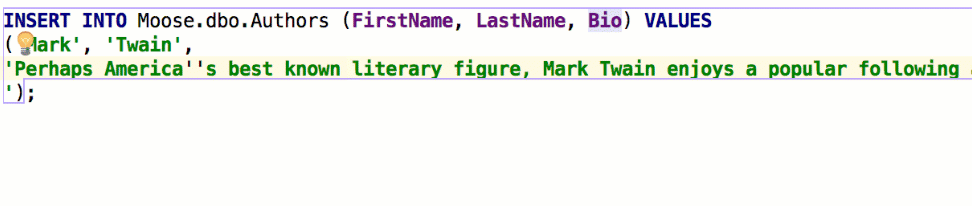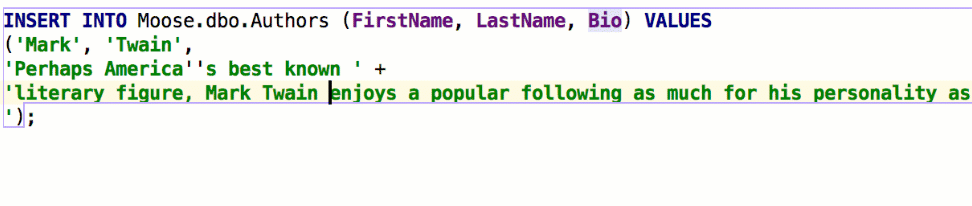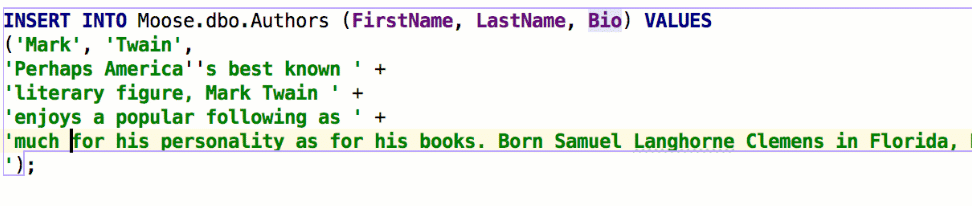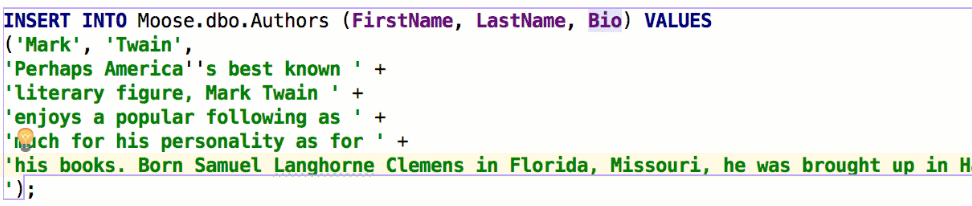
But the majority of database management systems support multiline string literals, so this IDE behavior may be annoying. Uncheck the option if you use multiline literals.
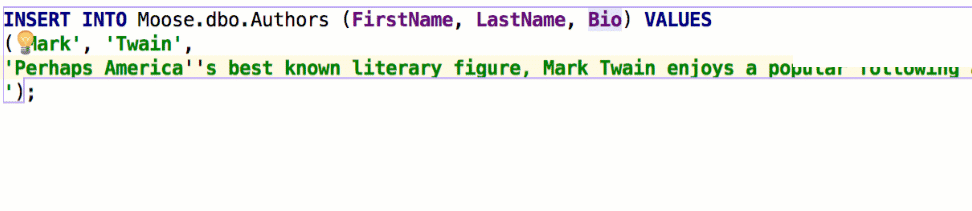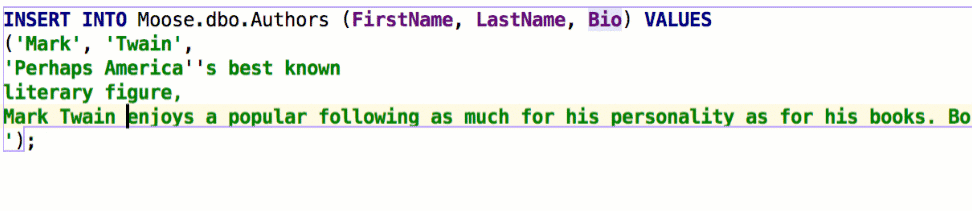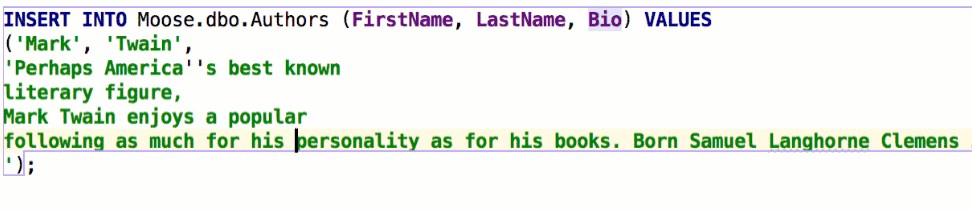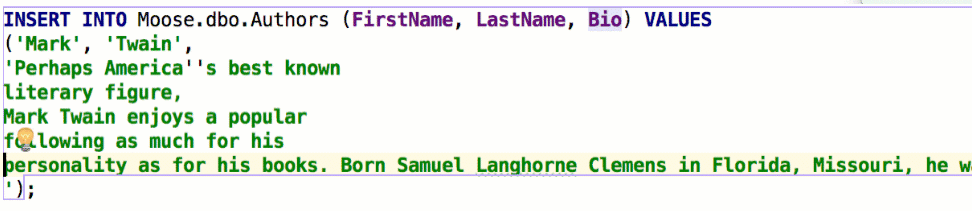
Qualify object in completion is also a thing we’ve been asked to implement. There are three options and here’s how they work. Suppose we have two schemas, max and public:

The table persons is present in both schemas and the table cardvendors is only in max. Here is the example Qualify on collisions:

Named parameters of routines can be completed by using second completion (pressing Ctrl+Space twice):

Aliases casing can now be set in Settings → Editor → Code style → SQL. Aliases are offered in code completion.

The general platform setting in Settings → Editor → Appearance → Show method separator now draws a line between statements.

An amusing feature for MySQL: due to errors in the MySQL grammar, a database cannot run queries with some combinations of parenthesis and UNION’s. Now DataGrip can handle these situations.

Jump to colors and fonts
A small helpful action is available to those who don’t want to wade through colors and fonts settings to find a single thing they need. For now it is only present in the Find Action menu (Ctrl/Cmd+Shift+A), but as usual, you can assign any shortcut to it.

This action will navigate you to the settings which are relevant to the context under the caret. If there are several of them, just choose one.

Here you are!

Database objects
Modify table UI improvement
The column details in the Modify Table dialog are now opened by double-cliсk. We changed it based on your negative feedback on single-click opening.

Tracking source code changes
Sometimes you make changes to the source code of some object, but forget to apply them. As you may know, DataGrip will detect and indicate this with colored marks on the gutter. If you modify such an object in some other place in DataGrip, the source code editor will alert you.

Documentation link for system tables in PostgreSQL
The quick info pop-up (Ctrl+J) for PostgreSQL system tables now contains the link to the documentation page at postgresql.org.

SQLite views
Also, now DataGrip loads the correct source code for views in SQLite. Before it was the ‘CREATE table’ code.

Miscellaneous
More information in result-set status bar
Some information was added to the status bar of the data editor. It is query time and selected column/row numbers under the cursor.

Text occurrences in Find Usages
Also, we have the new option to include or exclude text occurrences in Find Usages.

If it’s selected, the results will include comments, occurrences in text files, and string literals.

Other
— Windows authentication for SQL Server in the jTDS driver.
— Correct line endings are sent to the database in SQL Server.
— Support of the CREATE/ALTER construction from SQL Server 2016.
— TNS names are correctly parsed from tnsnames.ora file in Oracle.
— It’s possible to use routine parameters in LIMIT in MySQL.
— Commit triggers synchronization in PostgreSQL.
— Single quotation mark is now escaped in DDL.
— Read-only preview is available for large files.
— Warnings are added on the Output tab as soon as they’re raised.
— Zero-latency typing is now enabled by default.
— Icons for synonyms are displayed in the structure view and completion.
— Customized colors are used for syntax highlighting of regular expressions.
If it’s not the first post you read in this blog, you already know all the information below, but still:
— Get your 30-day trial of DataGrip here.
— Tweet at us!
— Discuss anything in forum.
— Report bugs to our issue tracker.
Thank you for your attention!
Your DataGrip Team
_
JetBrains
The Drive to Develop




