

The Many Ways of Exporting Data in IntelliJ-based IDEs

In DataGrip, as well as all other JetBrains IDEs that feature database support, there is a powerful engine to export data in many formats. You can even create your own export format.

Let’s look closer at this engine.
Export directions
Any table/view or result-set can be exported to a file or copied to the clipboard.
To export to file:
— Context menu on a table/view and → Dump data to file.
— Context menu on a query and → Execute to file.
— In the toolbar of the result-set or data editor, select Dump data button → To File…
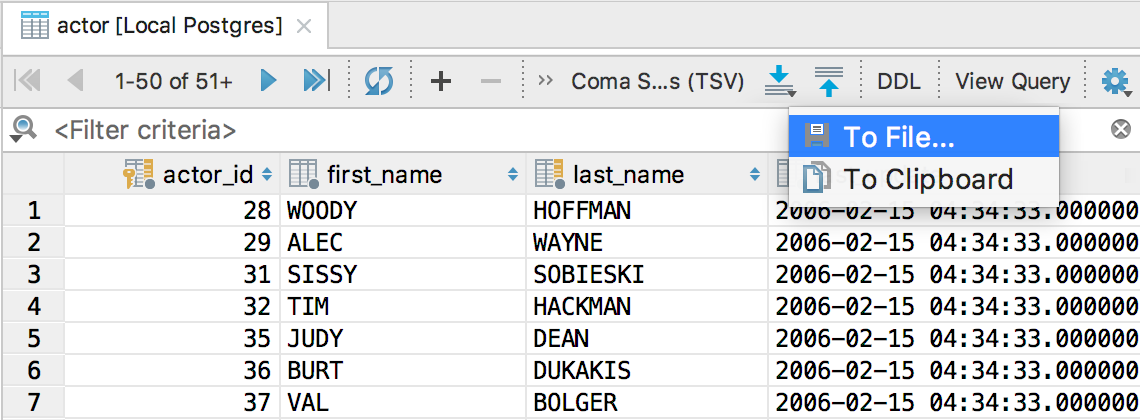
To export to the clipboard:
— Select the data you need within a result-set or data editor and click Copy or press Ctrl/Cmd+C.
— In the toolbar of a result-set or data editor, select Dump data button → To Clipboard
Default extractors
We’ll talk about copying data to the clipboard from the data editor, but the same applies to other described ways to export data.
Look to the left of the Dump data button for a drop-down where you can choose the extractor — the format to export data in.
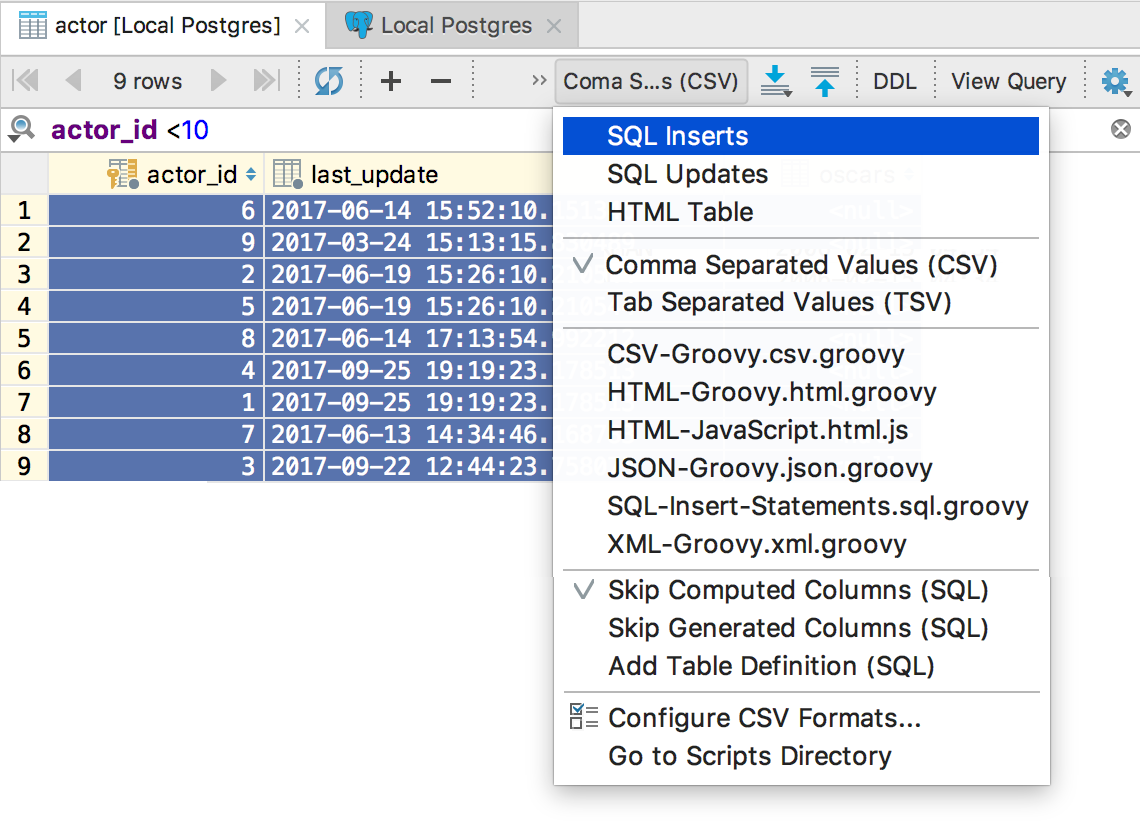
There are several built-in formats as you can see. Some of them let you export data as a set of INSERT/UPDATE statements, while others export data as text such as CSV, JSON, HTML, etc. For more details on how they work, please visit this page.
Still, users may need to extract data in many different ways.
Creating a DSV-based extractor
Let’s see how we can extend the default functionality.
To create your own format based on CSV (or any DSV format), select Configure CSV formats…
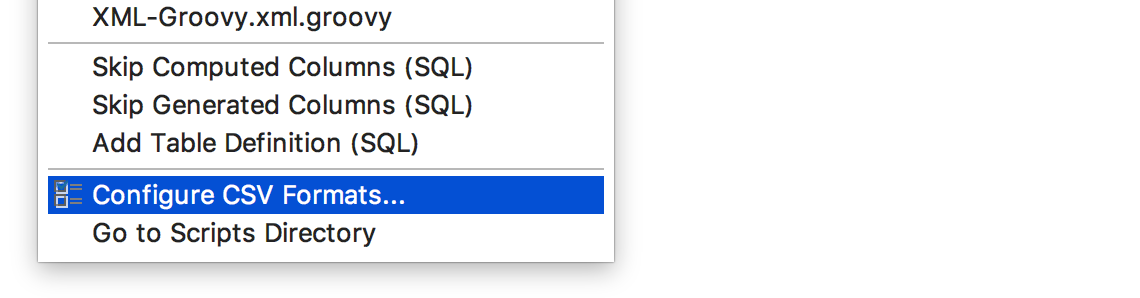
In this dialog, in addition to changing the existing CSV and TSV extractors, you can create your own. For example, Confluence Wiki Markup.
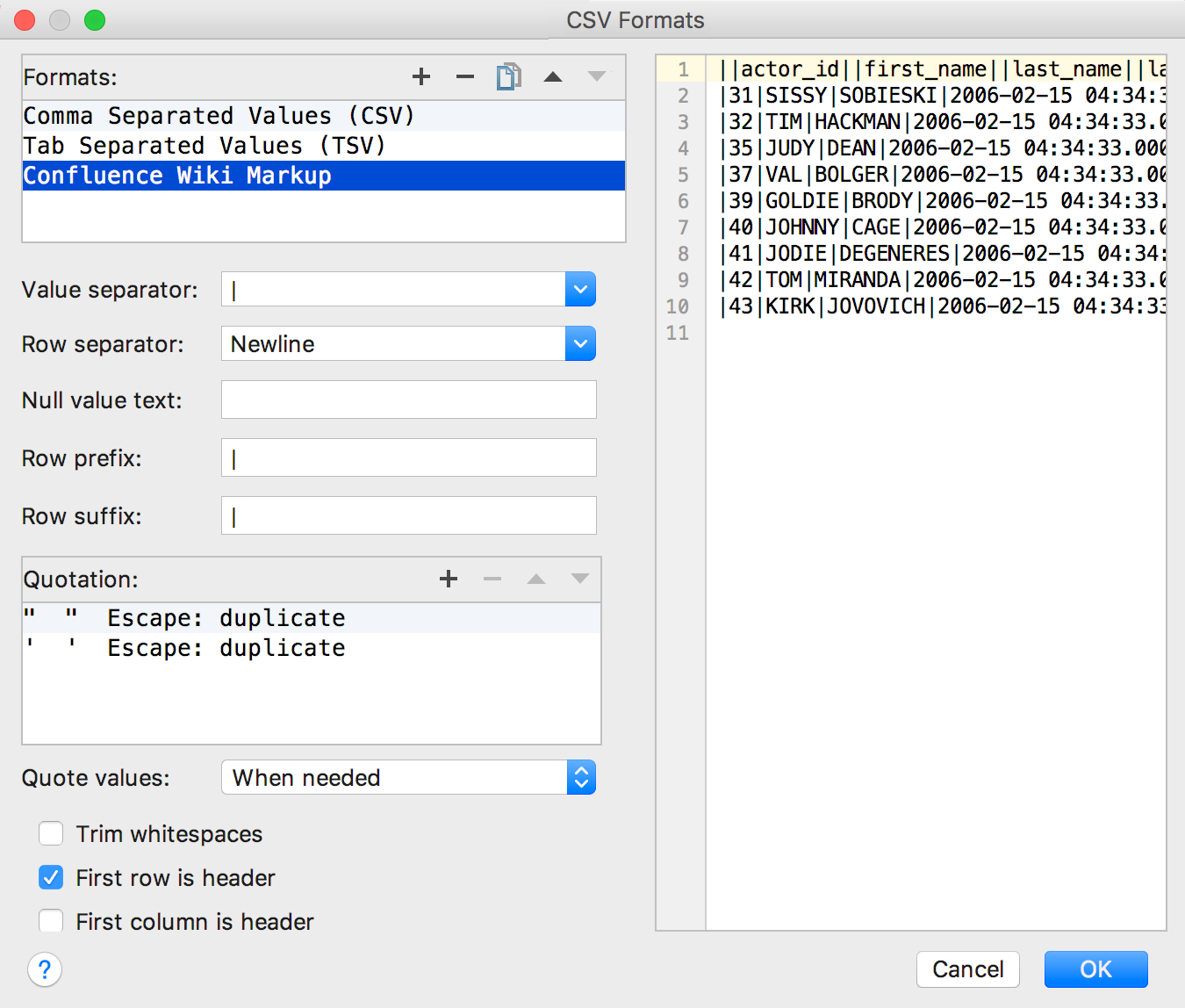
Once created, it appears among the other extractors.

Creating any text extractor with scripting
For the more complicated cases, consider using scripting extractors. Several of them are already there such as CSV-Groovy.csv.groovy, HTML-Groove.html.groovy, and others. These scripts are written in Groovy, but they can also be written in JavaScript. Our examples use Groovy.
Looking closely at the file name, CSV-Groovy.csv.groovy:
CSV-Groovy is just the name of the script;
csv is the extension of the result file if you extract to file;
groovy is the extension of the script itself. It helps IntelliJ IDEA highlight your code if that’s where you create/edit your scripts.
Scripts are usually located in `Scratches and Consoles/Extensions/Database Tools and SQL/data/extractors`. Or you can select Go to scripts directory in the extractor menu to navigate there.
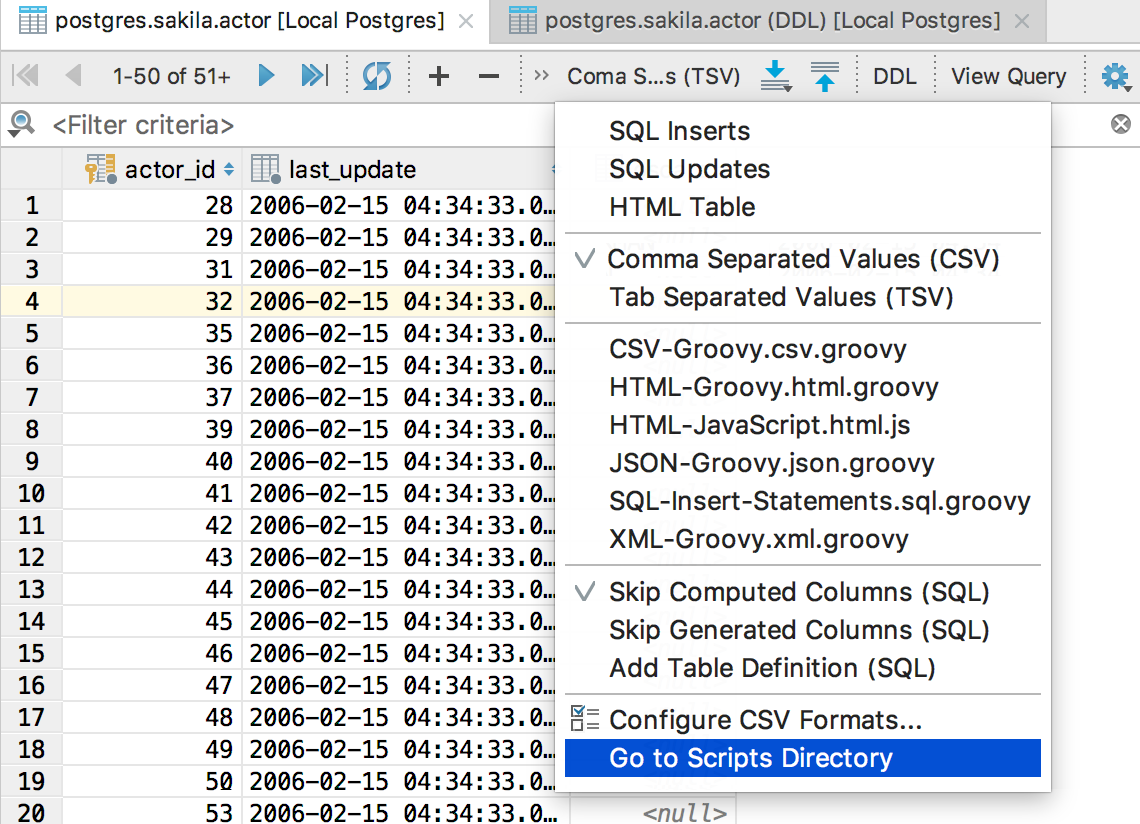
You should edit an existing extractor or just add your own to this folder.
Let’s create an extractor which will dump your data to CSV format, but to just one row. It can be useful if you are going to paste these values into an IN operator in a WHERE clause.
Here is the diff view of two scripts: the existing CSV-Groovy.csv.groovy and our new one which we’ll name CSV-ToOneRow-Groovy.csv.groovy.
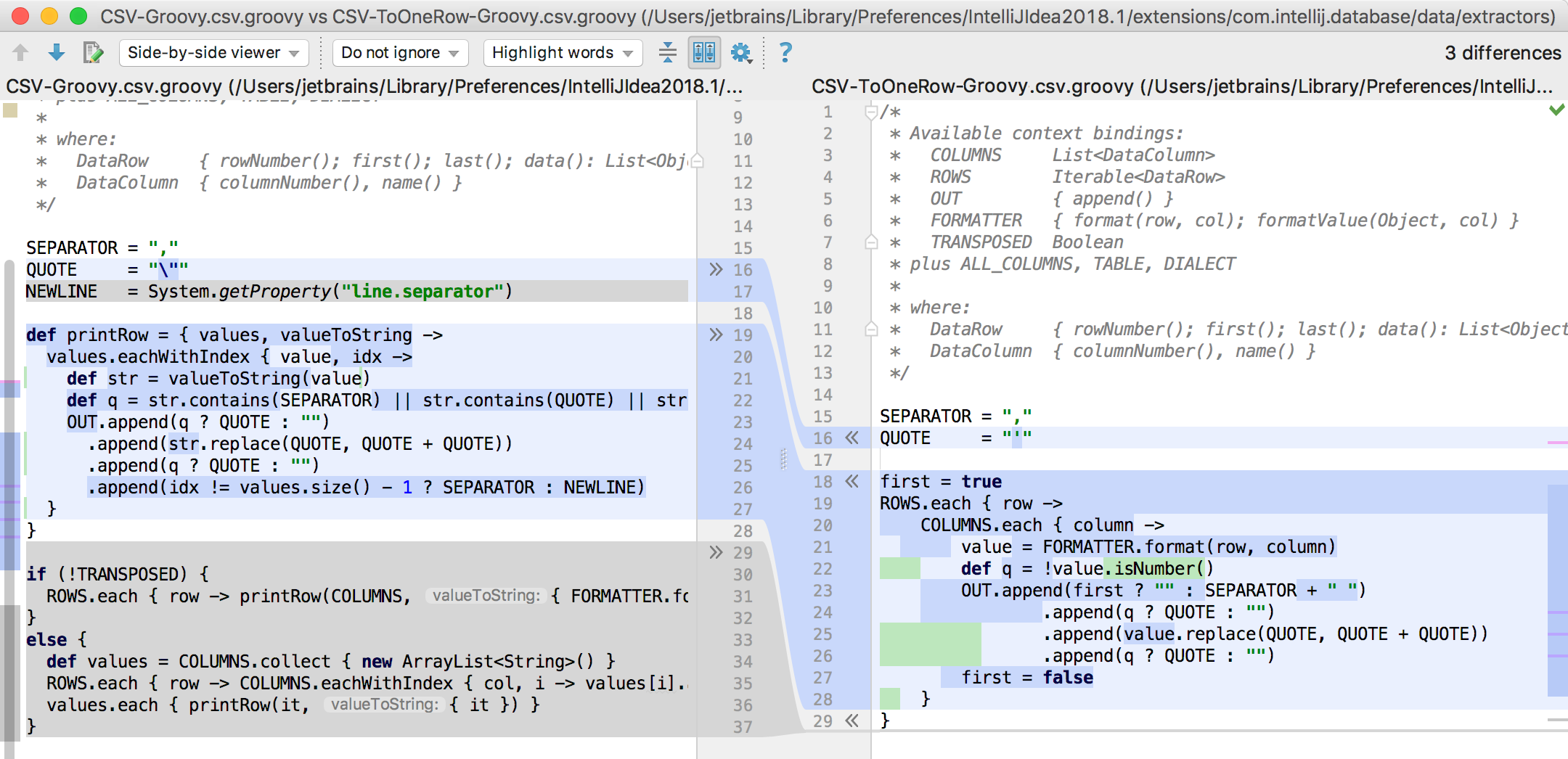
Note the available context bindings:
COLUMNS <DataColumn> //selected columns ALL_COLUMNS List<DataColumn> //all columns
These objects are equal when dumping the whole page to file.
ROWS Iterable<DataRow> //selected rows
Where:
DataRow { rowNumber(); first(); last(); data(): List<Object>; value(column): Object }
DataColumn { columnNumber(); name() }
OUT {append()} //object to output data
FORMATTER {format(row, col); formatValue(Object, col)} //converts data to String
TRANSPOSED Boolean //checks if data editor is transposed (Gear Icon → Transpose)
TABLE DasTable //object that represents the actual table you’re extracting data from
DasTable has two important methods:
Before v2017.3
DasObject getDbParent() JBIterable<DasObject> getDbChildren(Class, ObjectKind)
Since v2017.3
DasObject getDasParent() JBIterable<DasObject> getDasChildren(ObjectKind)
Additional information about the API can be found here.
When you create or edit Groovy scripts in IntelliJ IDEA, and have Groovy installed, coding assistance is available.
Once the new script file is in the folder, you can use the extractor!
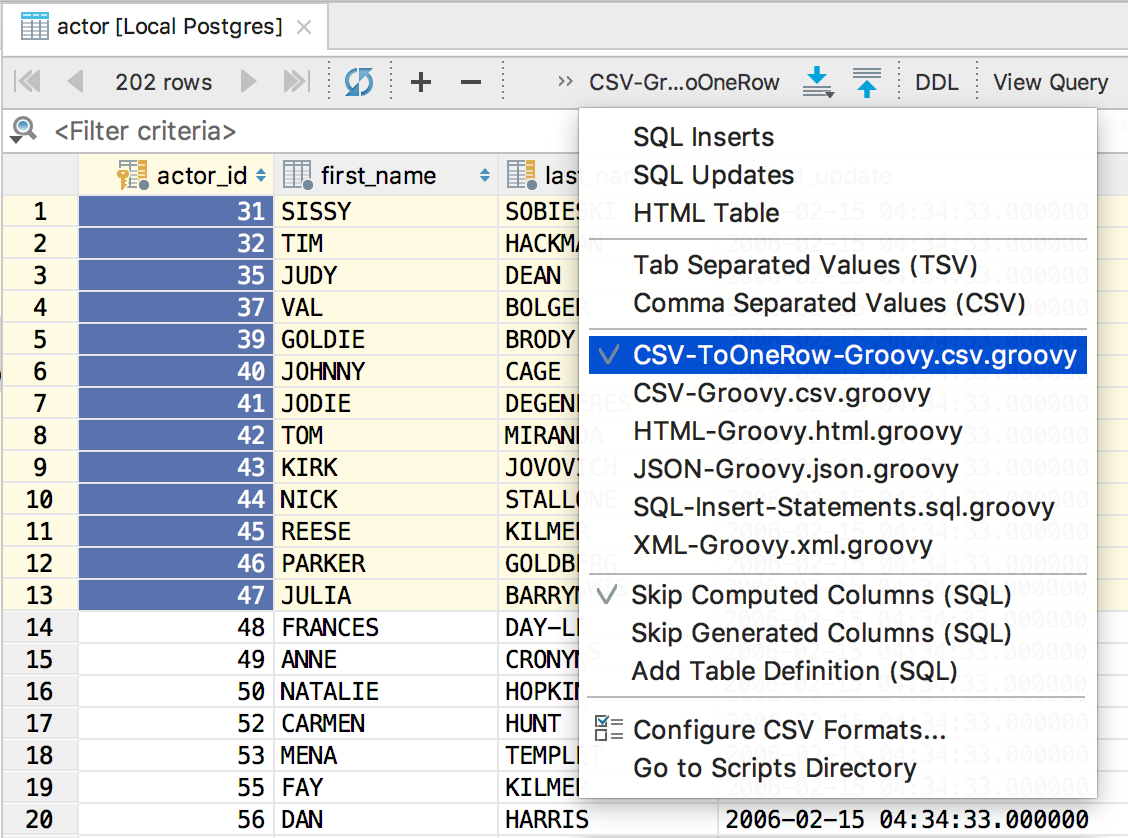
Copy these values and paste them into the query.

Here’s another example based on SQL-Insert-Statements.sql.groovy. MySQL and PostgreSQL allow using multi-row syntax. To use this type of extractor, create a new SQL-Inserts-MultirowSynthax.sql.groovy file in the scripting folder.
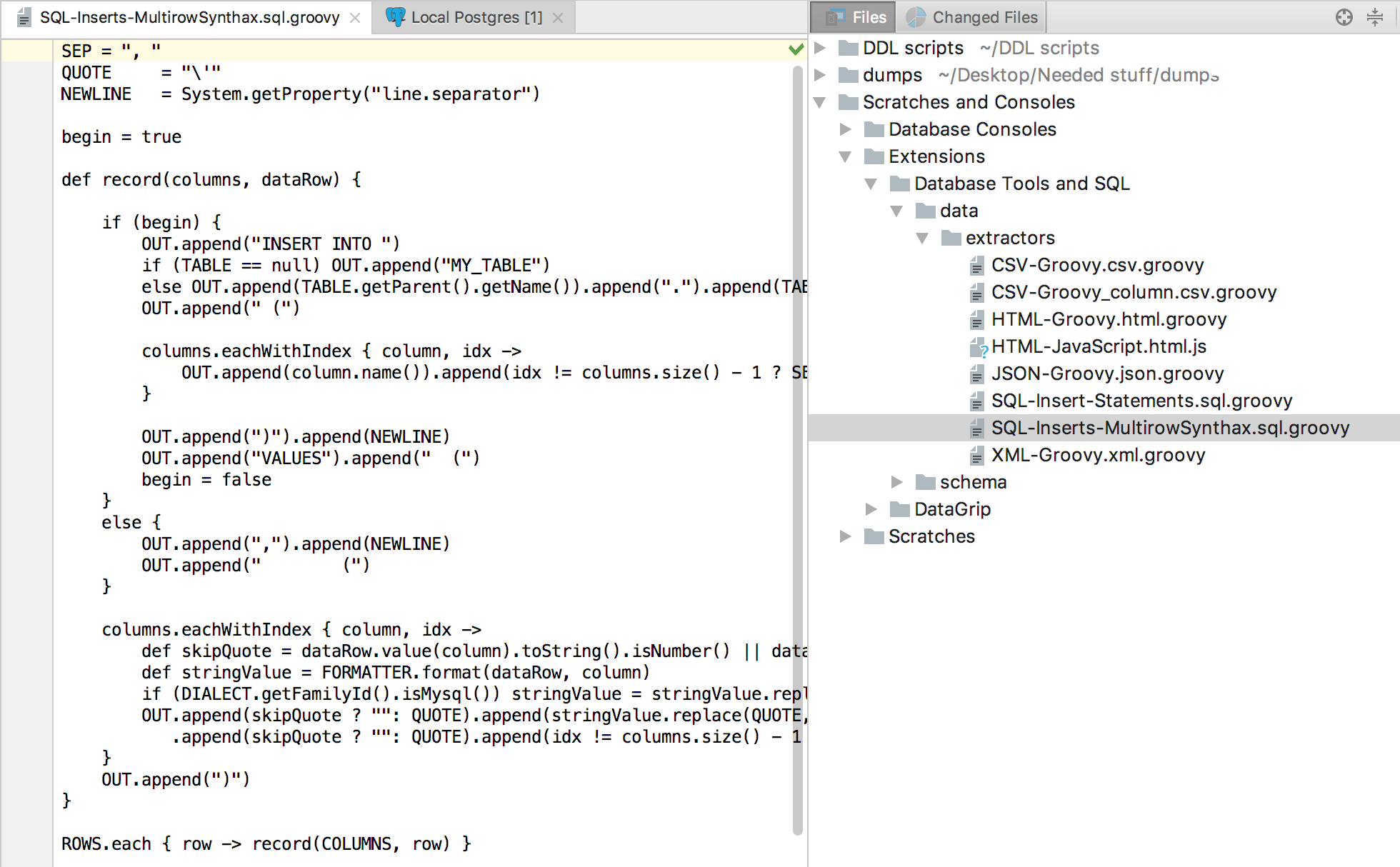
Again, simply select it in the menu.
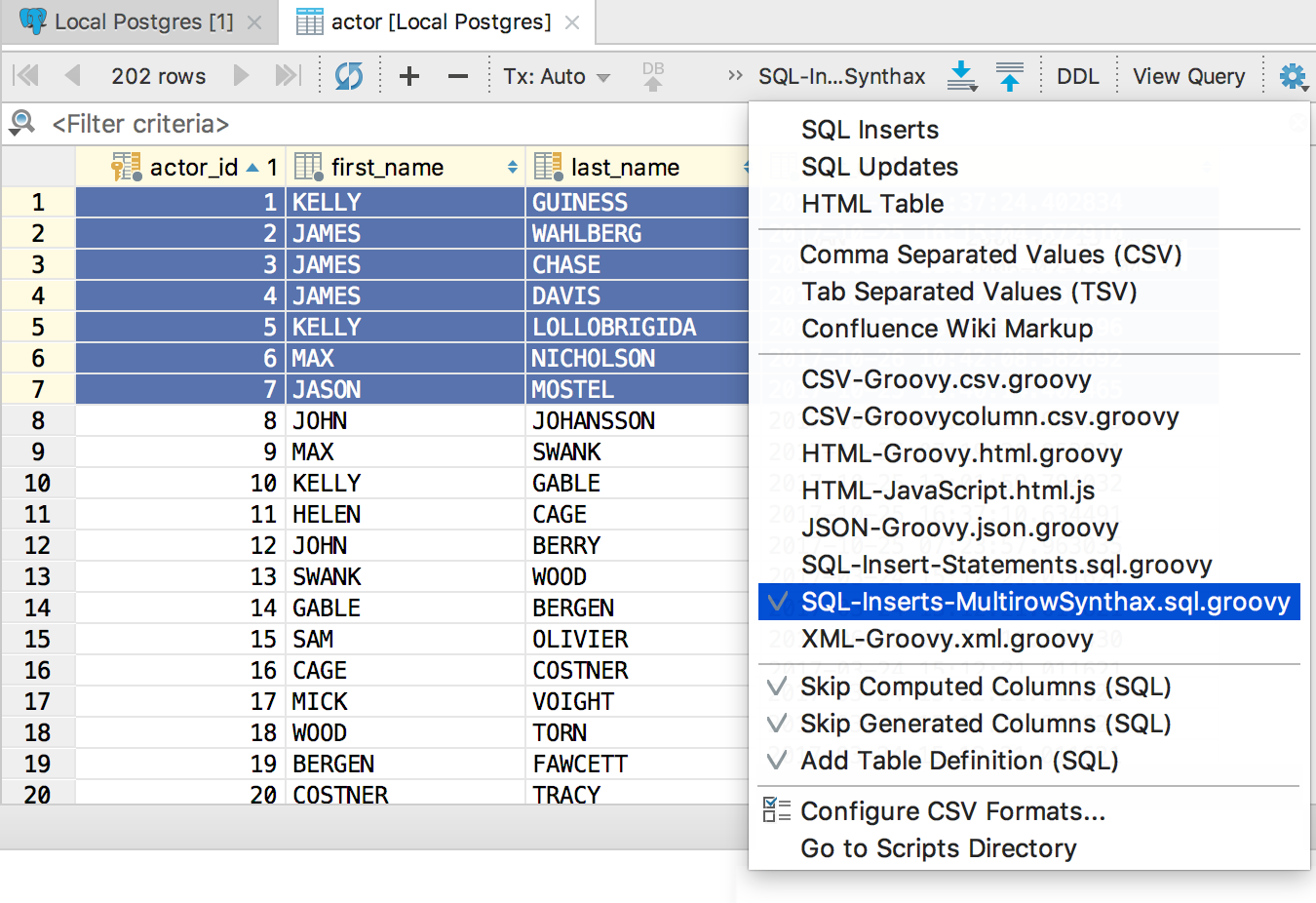
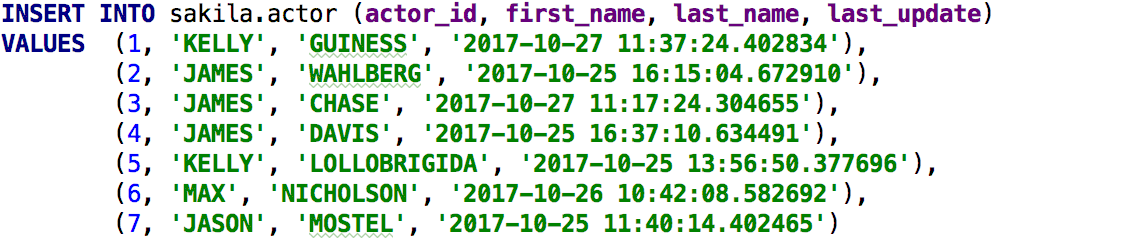
The result:
Another version of this extractor from our user is here: it also adds parentheses. It creates several lists if you’ve selected cells from several columns.
There are already some user-generated extractors on GitHub which everybody can use:
— Extractor to copy tab separated query results to paste into Excel with comma decimal separator.
— DBunit XML.
— Txt-file with fixed length columns. (Here’s a very similar one).
— Php array.
— Markdown.
— Jira.
We hope this tutorial will help you tweak DataGrip to your specific needs and encourage you to share extractors for all to use.
The DataGrip Team







