

DataGrip 2020.2 EAP Has Started!

Hello, everybody! You may be keen to know what we are planning to include in this summer’s release. We’ve got a description here of what you can already try.
A new UI for boolean values
Well, this is quite a welcome development! There’s a new way to observe and edit boolean values that is more user-friendly.
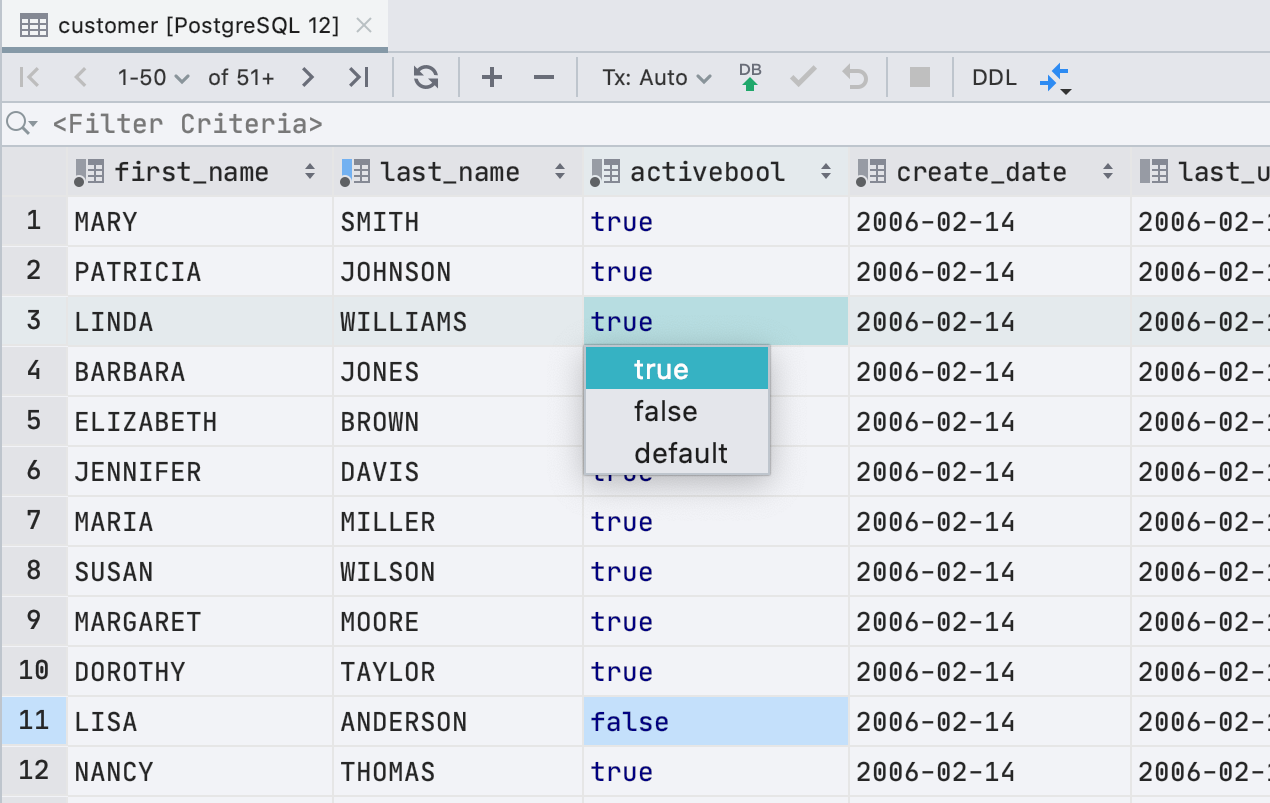
Editing:
– The space key toggles values like it used to.
– Typing f, t, d, n, g, or c will input the corresponding values: false, true, default, null, generated, and computed. We’re all lucky that all these words begin with different letters!
– Typing anything else will open the drop-down with possible values.
A new UI for cropped data
Sometimes DataGrip cannot load all the data for a given cell. This happens if the size of the data in the cell is larger than allowed by the Database | Data views | Max LOB length setting. In these cases, we used to add a small piece of text, like “10 KB of 50 KB loaded”, to the value. Now instead of altering the value, we just show a hint.

Long tabs: no more!
Another usability issue that won’t annoy you in 2020.2: long tabs.
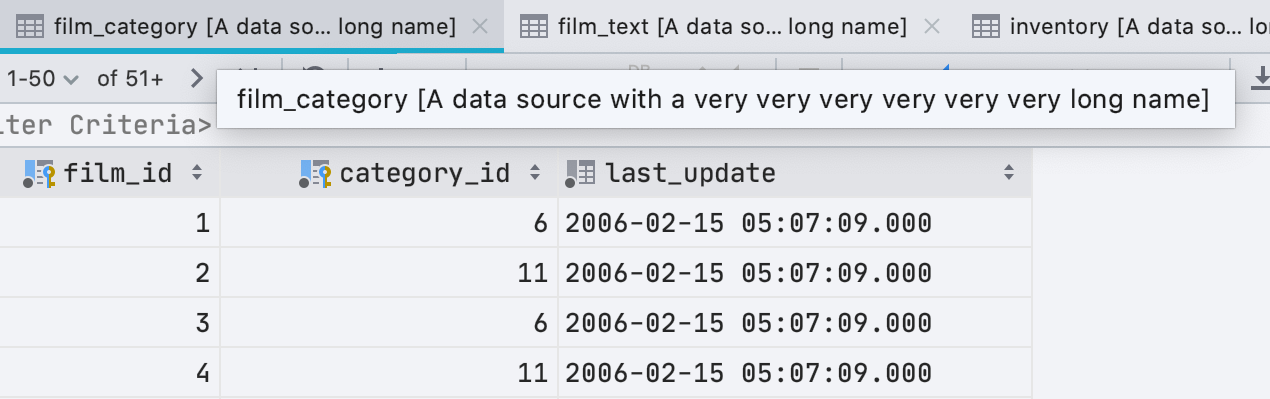
How it works now:
– The Database | General | Always show qualified names for database objects option is now turned off by default. Objects will be qualified in the tab names only if there are two objects with the same name open. For example, if you open two actor tables from different schemas, the schema name will be displayed in the tab name. Otherwise, it won’t be.
– If the data source has a name that is longer than 20 symbols, it will be truncated.
– If you have only one data source, DataGrip won’t display it in the tab name.
– If a qualified object name has more than 36 symbols, it will be cut off.
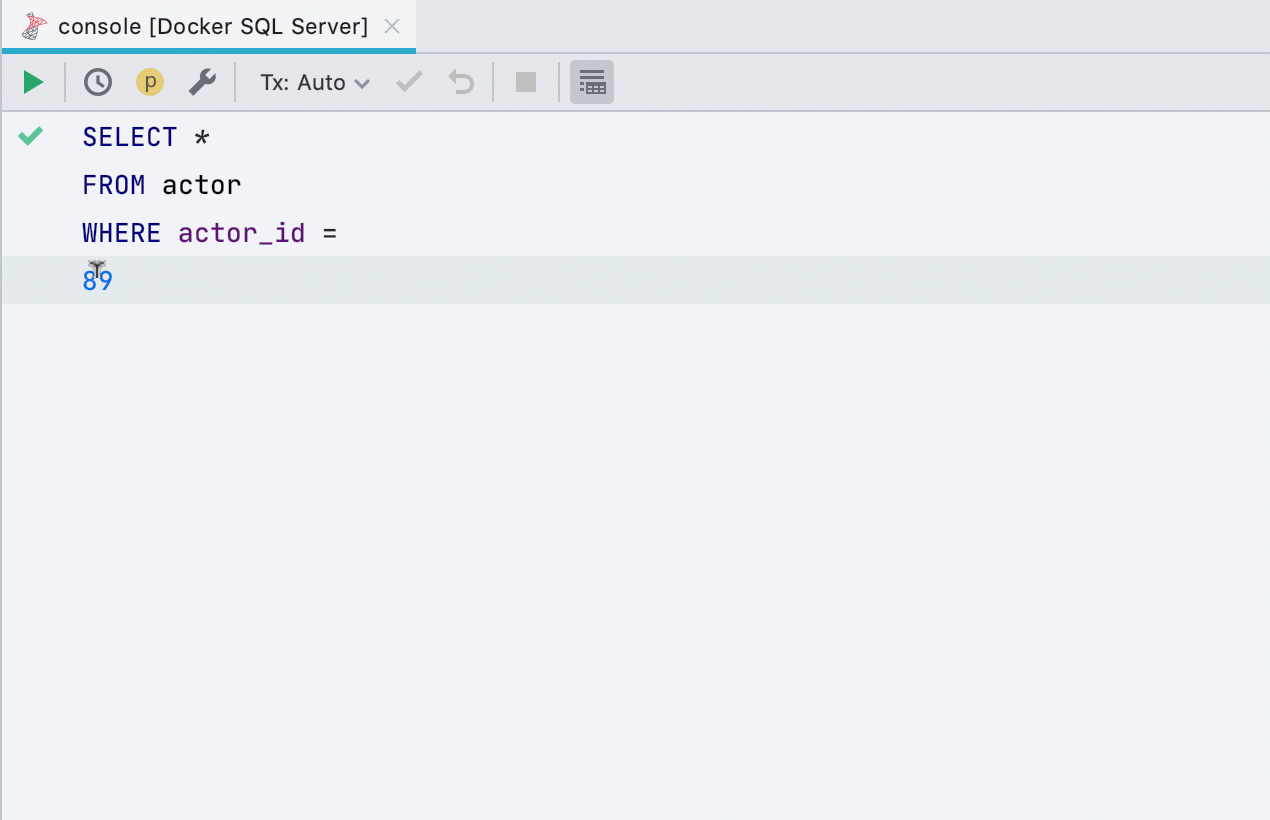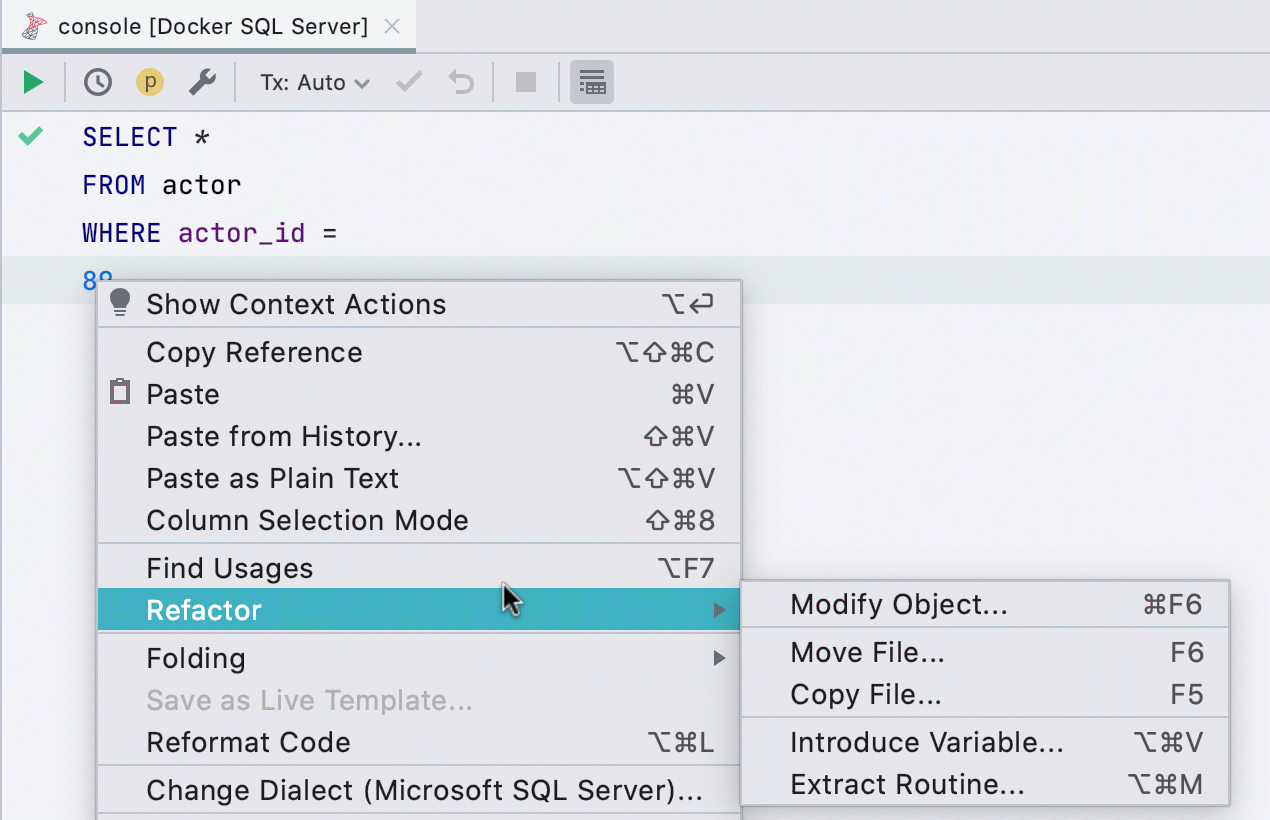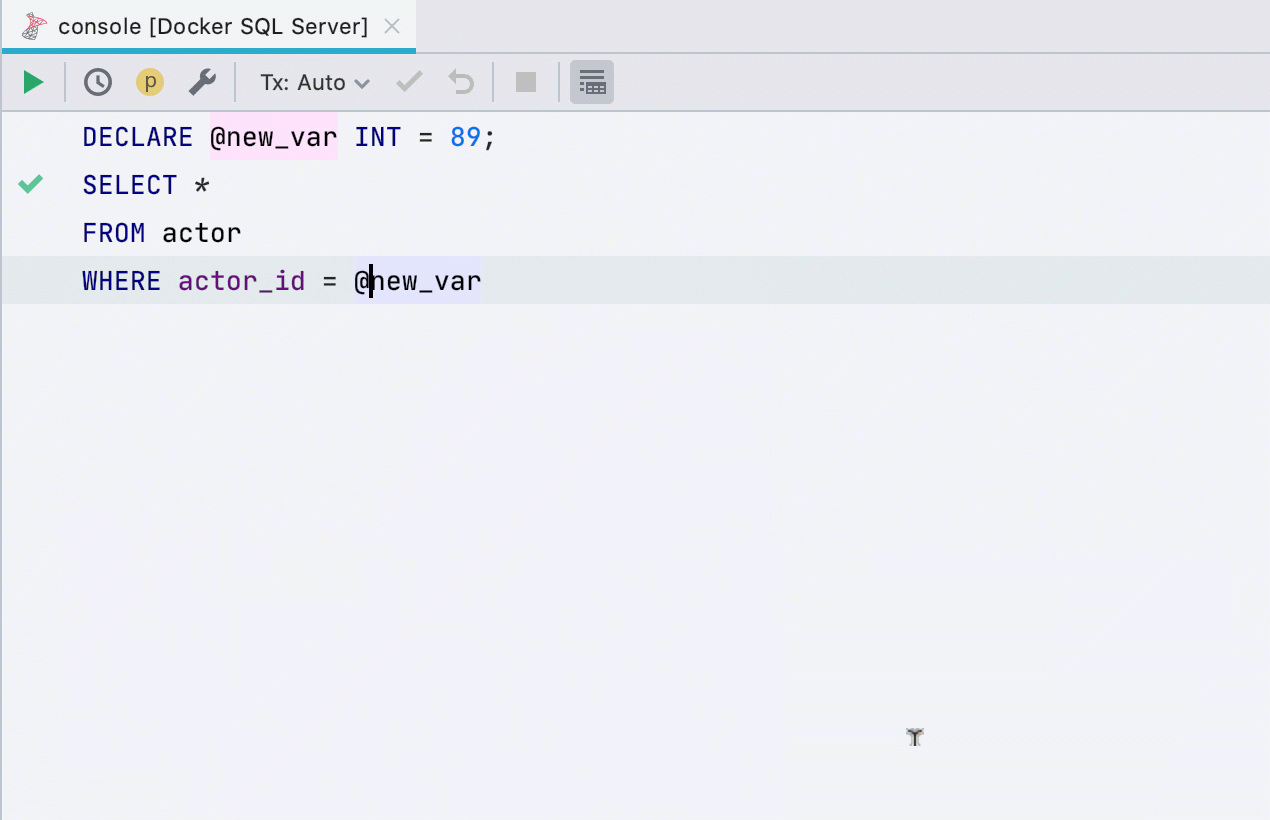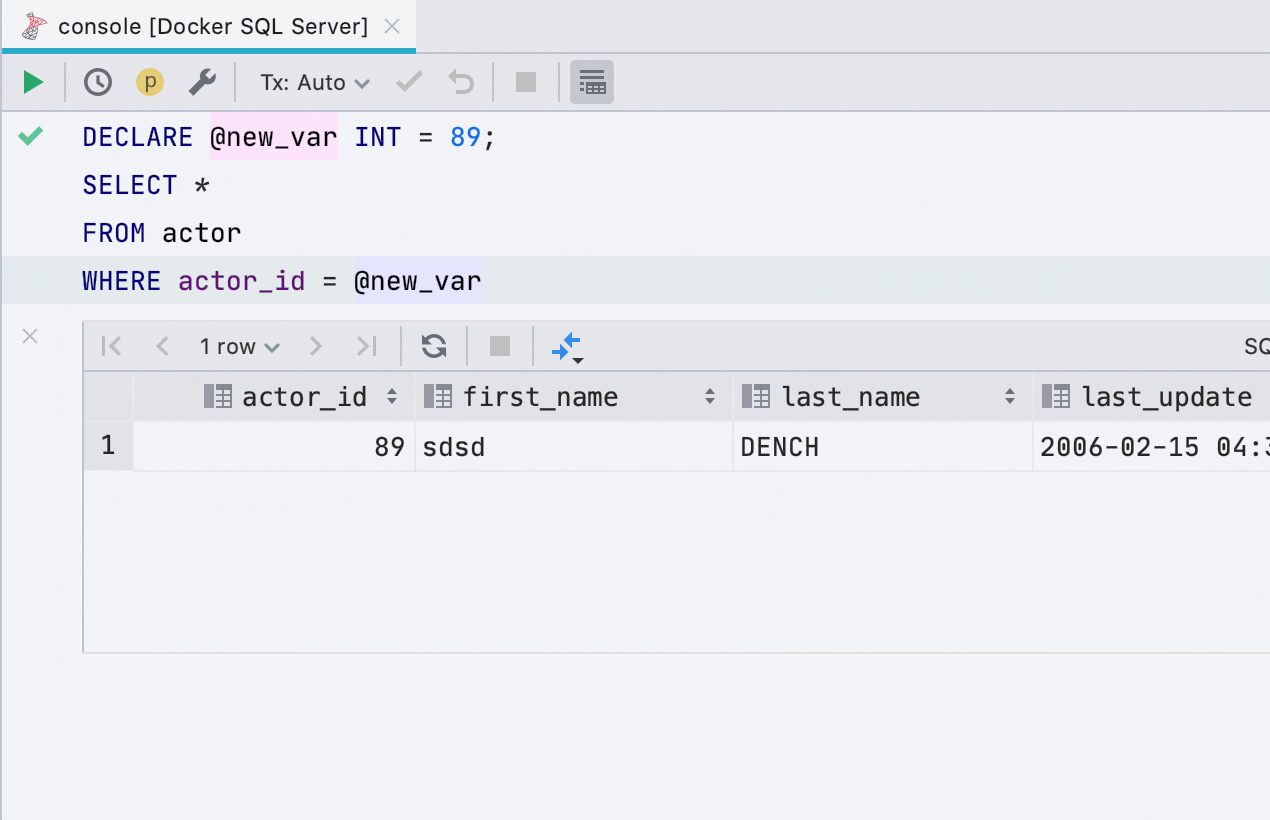
Introduce variable
This refactoring is now supported in more dialects: SQL Server, Db2, Exasol, HSQL, Redshift, and Sybase. You can introduce variables from any expression that has the simple type.
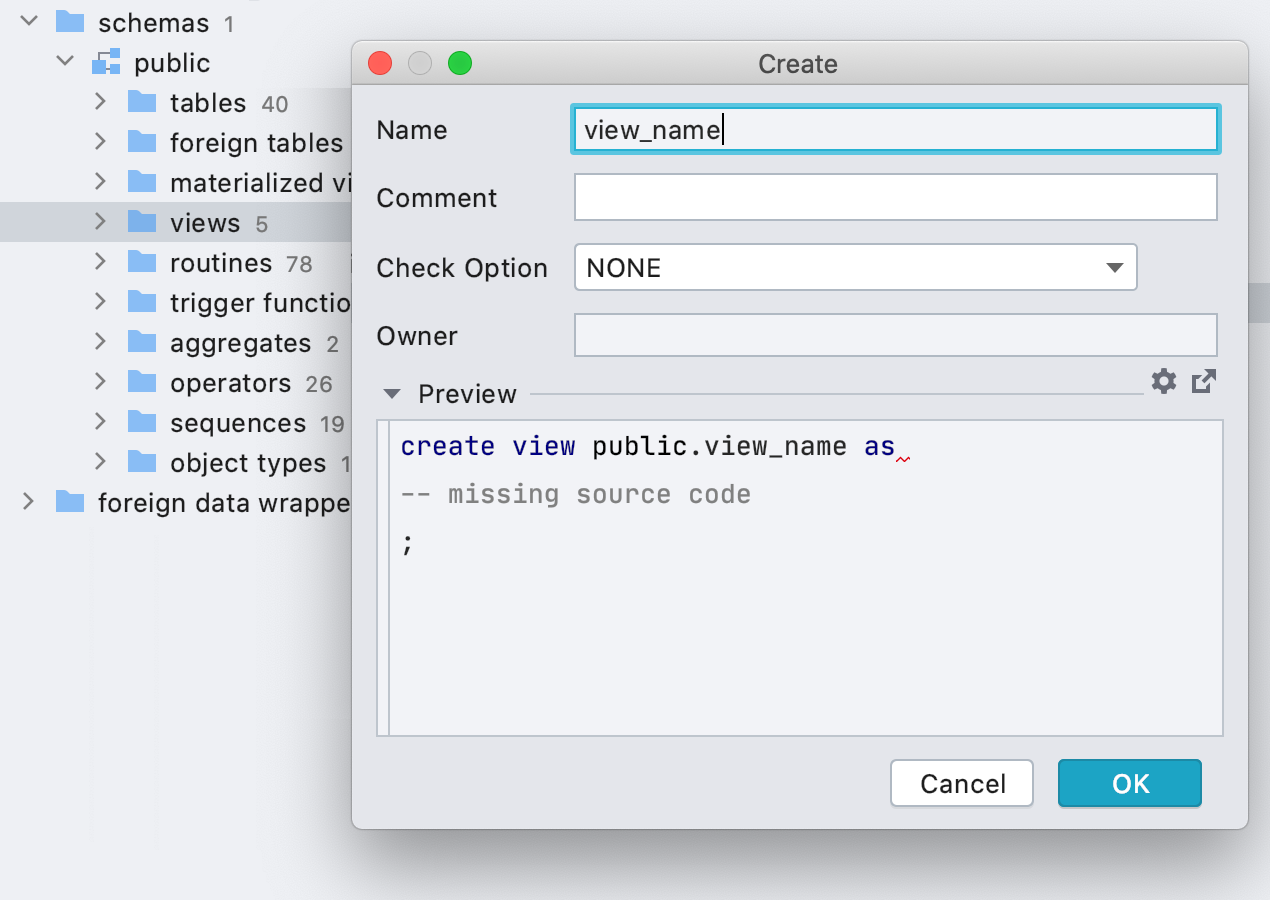
UI for creating views
While we are always advocating for people to use the Generate functionality (Alt+Ins or Cmd+N in the SQL editor) if they want to create a view, many are more comfortable using the UI. We heard you, and we’ve added a UI option for that.
Refresh database quick-fix
Sometimes you have unresolved objects in your script. When you do, DataGrip doesn’t understand where these objects are located and suspects that they don’t exist at all. While in many cases this is true, sometimes the objects are unresolved because you just need to tweak the context you are working on.
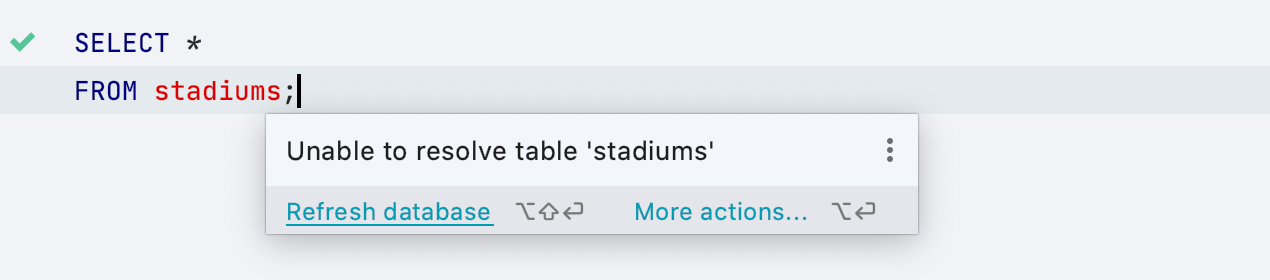
We’ve added the Refresh database quick-fix, which will help you if an object has been added to the database from somewhere else since the last time you refreshed your database.
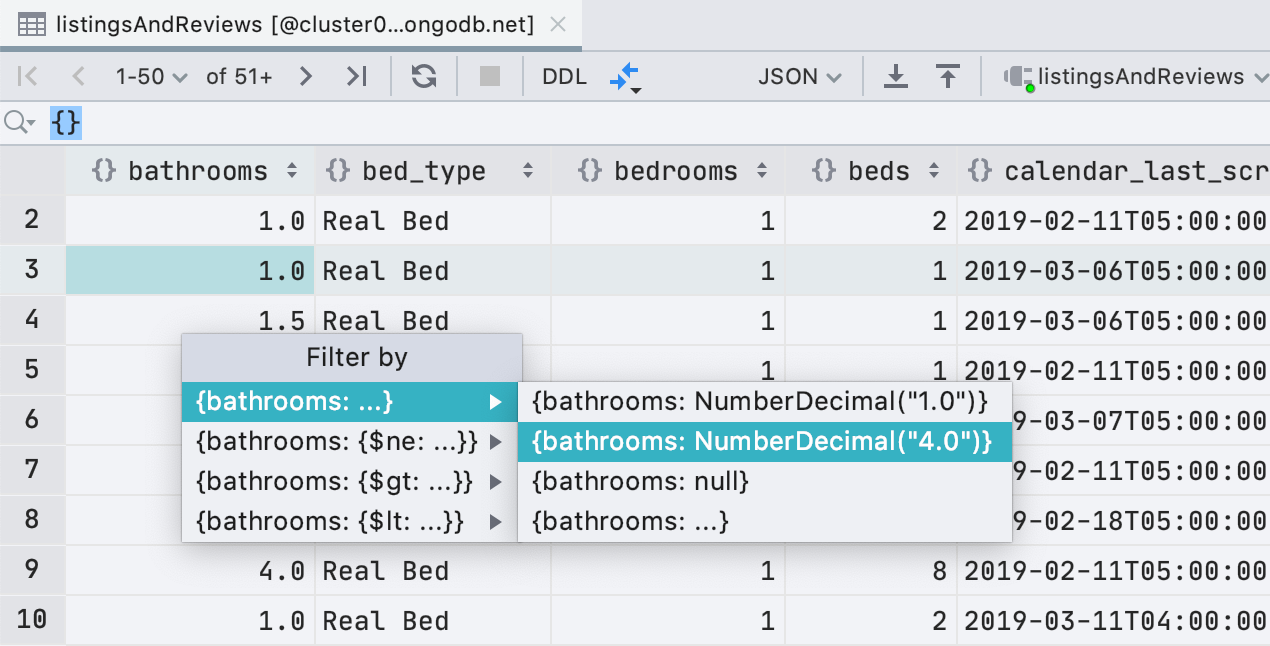
Better filtering for MongoDB
In addition to ObjectId and ISODate, filtering now supports UUID, NumberDecimal, NumberLong, and BinData. Also, if you have a valid UUID/ObjectId/ISODate in your clipboard, you will see this value in the offered filters.
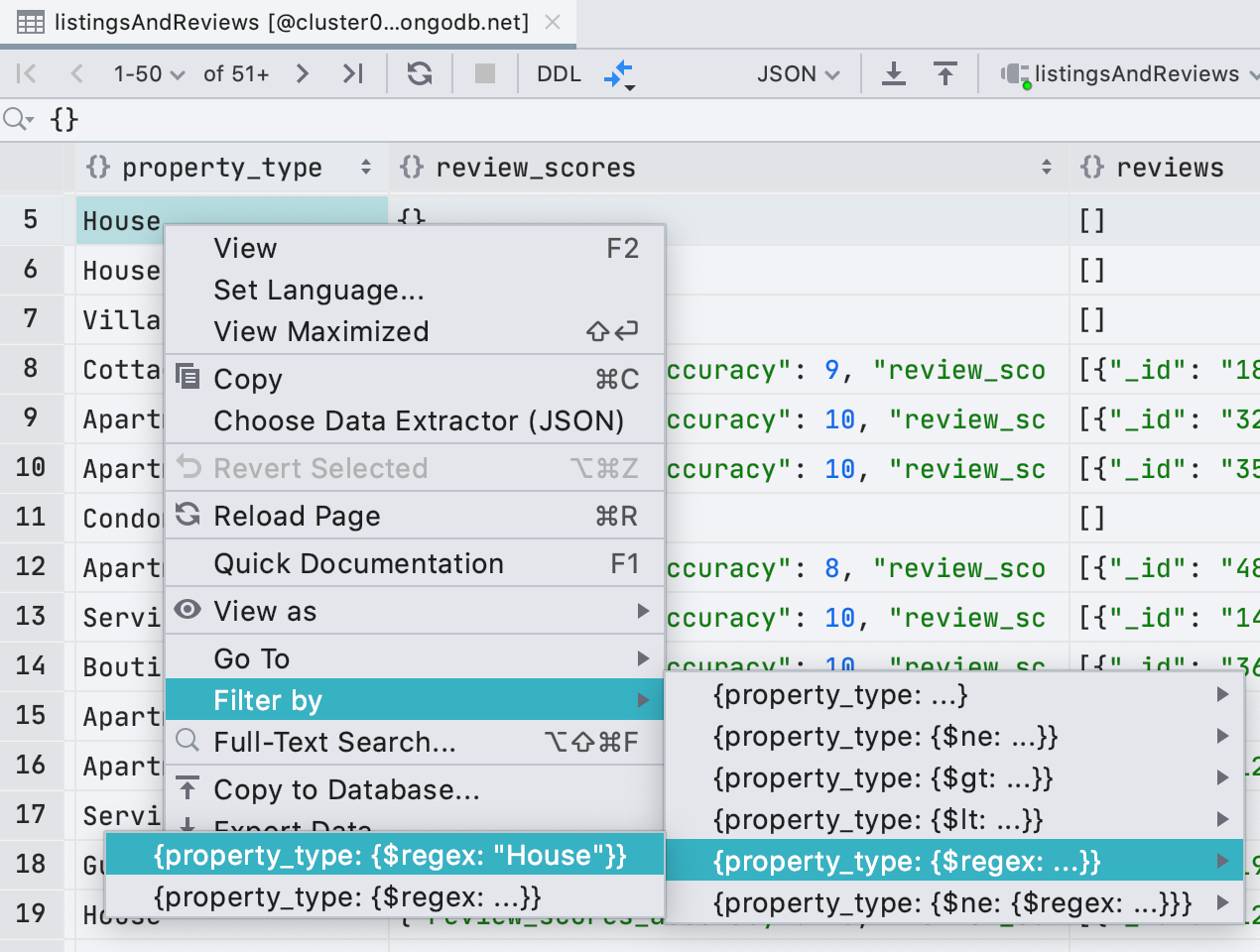
We’ve also added regular expressions to filtering, in case you are missing the LIKE filter from MongoDB.
Other improvements
– In the data editor, if you edit a one-line string value, the down/up keys will finish editing it for you.
– In the event you are experiencing network issues, introspection in Oracle databases is now faster than it was before.
– The XML extractor is now a little bit better: If the original value is already XML, the extractor will not wrap it again in the extracted XML. If the value is not already XML, then special characters ‘<‘ and ‘>’ will be converted to xml entities: < and >
That’s all for today! Please try our new EAP build. Your feedback is welcome in our twitter or forum.
The DataGrip team




