DataGrip 2021.3 EAP Is Open

Hello! We have begun our DataGrip 2021.3 EAP and there is something really exciting inside.
Data editor
Aggregates
We’ve added the ability to display an Aggregate view for a range of cells. This is a long-awaited feature that will help you manage your data and that will spare you from having to write additional queries! This brings our data editor step closer to Excel and Google Spreadsheets!
Select the cell range you want to see the view for, then right click and select Show Aggregate View.

Quick facts:
- It shares the panel with Value view: now you have two tabs there. This panel can be moved to the bottom of the data editor.
- You can use the gear icon to display or hide any aggregate from this view.
- Like extractors, aggregates are scripts. You can create and share your own in addition to the nine scripts we’ve bundled by default.
- Moreover, aggregate scripts and extractors are interchangeable. If you’ve previously used an extractor to get just one value, you can now copy it to the Aggregates folder and use it for aggregates.
One aggregate value is displayed in the status bar, and you can choose which value you’d like it to be.

Independent split
If you split the editor and open the same table, the data editors will now be completely independent. You can set different filtering and ordering options for them. Previously, filtering and ordering were synchronized, which obviously was useless.

Custom font
You can choose the dedicated font for looking at data under Database | Data views | Use a custom font.

Setting for default sorting
You can define which sorting method will be used as the default for tables: via ORDER BY or client-side (which doesn’t run any new queries and sorts only the current page). The setting can be found under Database | Data views | Sorting | Sort via ORDER BY.

Display mode for binary data
16-byte data is now displayed as UUID by default. You can also customize how binary data is displayed in the column.

[MongoDB] Completion for filter {} and sort {}
Code completion now works when filtering data in MongoDB collections.

Database in the Version Control System
TLDR
This release is a logical continuation of the previous one, which introduced the ability to generate a DDL data source based on a real one. Now, this workflow is fully supported. You can:
- Generate a DDL data source from a real one
- Use the DDL data source to map the real one
- Compare and synchronize them in both directions
Just as a reminder, a DDL data source is a virtual data source whose schema is based on a bunch of sql scripts. Storing these files in the Version Control System is a way to keep your database under the VCS.
Database in the VCS: step-by-step workflow
Let’s take a look at the whole process. Imagine two developers, Alice and Bob, want their data source schemas to be synchronized via GitHub.
We advise users to store the project root folder in the VCS. Alice and Bob will sync their projects, which contain the DDL data sources for the sakila database. They both have their local data sources, but they want to synchronize them via VCS.
Alice enables version control integration on a project root folder, which is usually automatically displayed in the Files tool window.
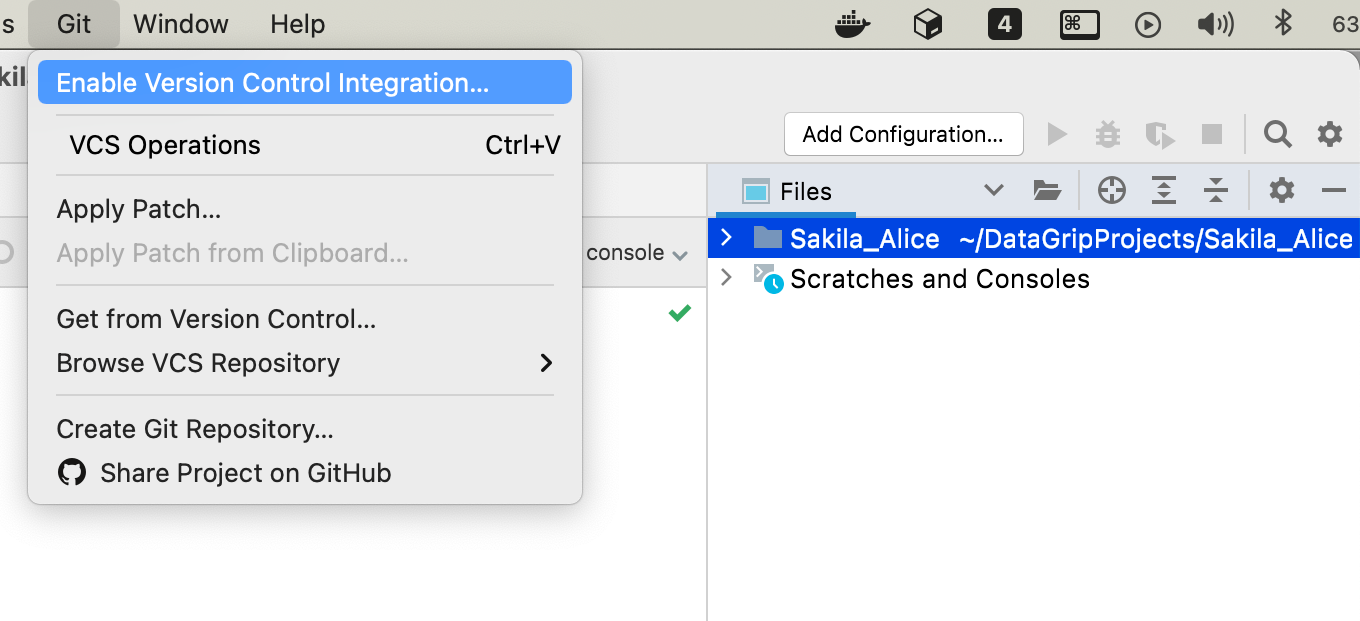
She then creates a sakila_repo folder, which she’ll use as a schema representation to be synced via VCS.

First, Alice needs to create the DDL data source with help of the Dump to DDL data source action. This will be a file-based schema mirror of the real data source. It’s name is Sakila Alice DDL.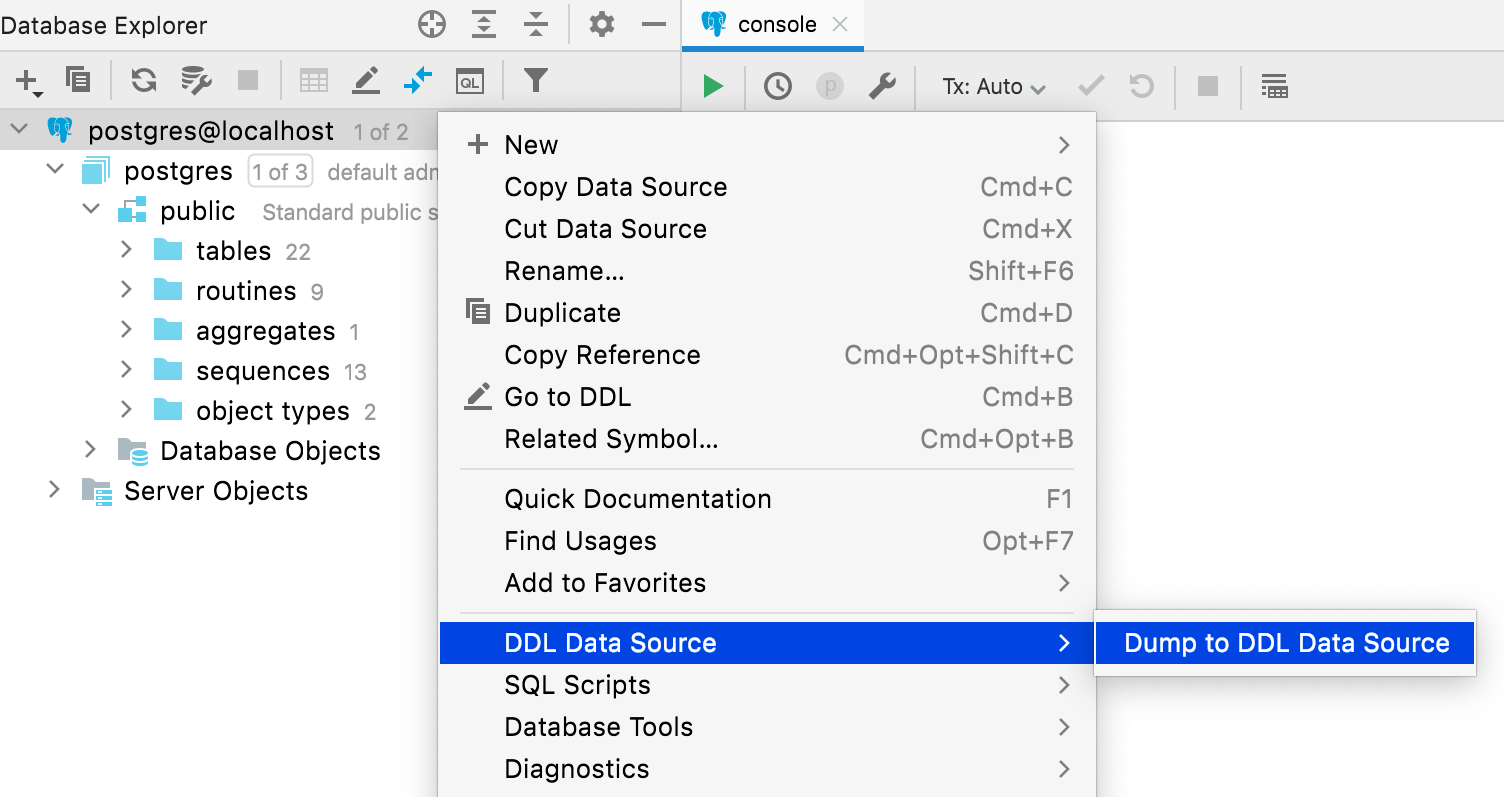
When creating a DDL data source, it’s necessary to specify that the files will be placed in the sakila_repo folder.

DataGrip asks whether Alice wants to add new files to Git, and indeed she does.

Now the project, along with the sakila_repo folder, can be committed and pushed to the GitHub repo. Alice hasn’t defined the remote repo yet. This can either be done in advance or when the project is pushed.

Done!
Bob clones the project from GitHub, and now he has the same local connection and DDL data source, which can be synced via VCS. All he needs to do is map his local data source using the DDL one. This should be done in the DDL mapping tab of the data source properties.
Now, the DDL data source represents the repository version, and the local data source is still local. Thus, to synchronize them, Bob needs to go to the context menu of the data source and select DDL data source | Apply from postgres@localhost (DDL)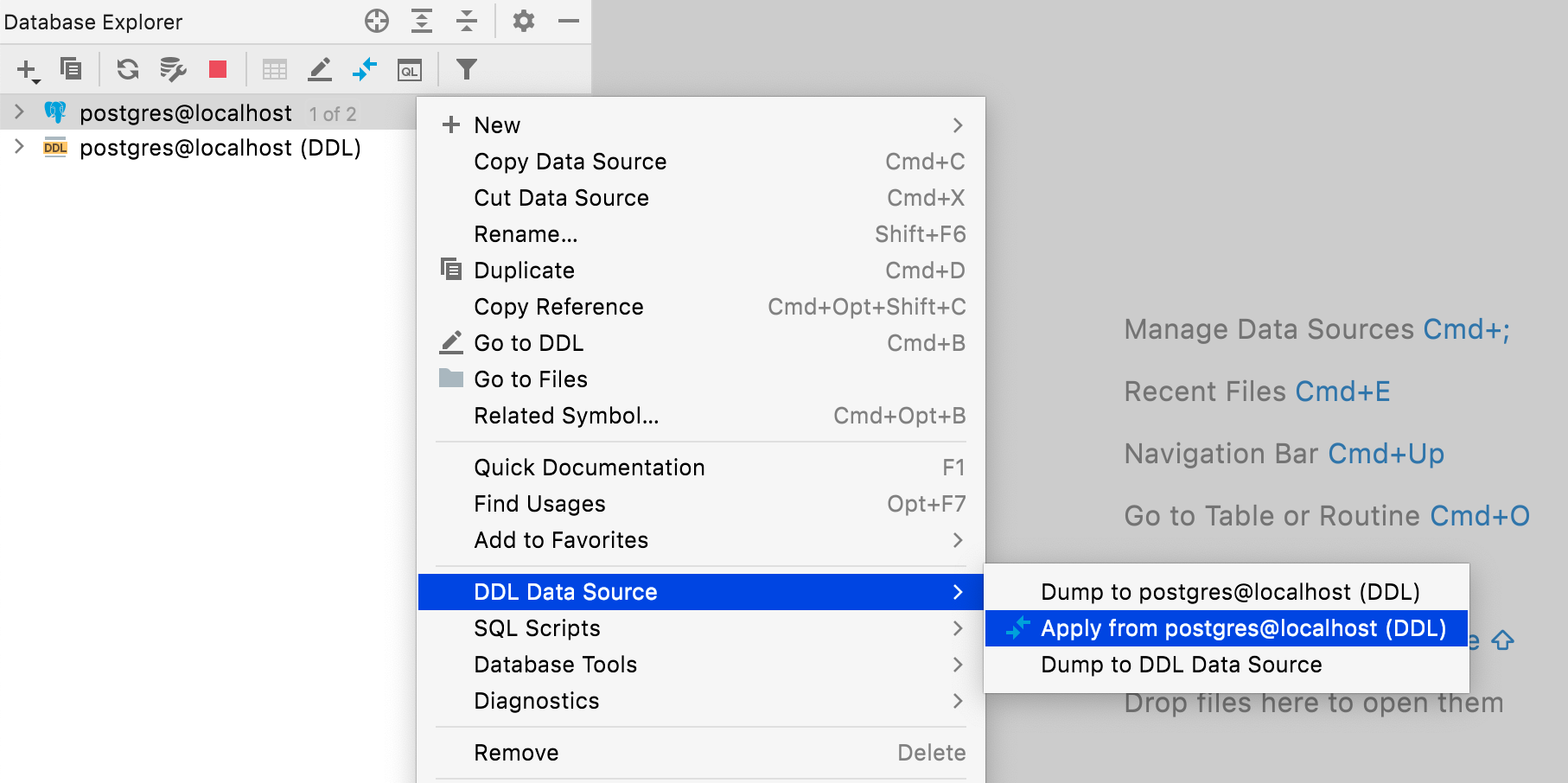
The migration dialog opens, and Bob needs to click Apply Right to Left. Viola! The data sources are synced.

Soon this migration dialog will be completely reworked, so in the stable release there will be a more convenient and powerful way to migrate from one data source to another.
File-related actions
All actions for files are available on DDL data source elements as well. For example, you can delete, copy, or commit files related to the schema elements just from the database explorer.

Auto-sync
If this option is turned on, the DDL data source will be automatically refreshed with changes to the corresponding files. This was already the default behavior, but now you have the option to disable it.

Initial search path
In this UI you can define names for your database and schemas, which will be displayed in the DDL data source. DDL scripts don’t usually contain names, and in these cases there will be dummy names for databases and schemas by default.

Connectivity
Accidental spaces warning
If any value except User or Password has leading or trailing spaces, DataGrip will warn you about them when you click Test Connection.

[Oracle, SQL Server] Kerberos authentication
It’s now possible to use Kerberos authentication in Oracle and SQL Server.

[Oracle, DB2] Enable DBMS_OUTPUT
This new option in the Options tab lets you enable DBMS_OUTPUT by default for new sessions.

More options button
We’ve introduced a More Options button for cases when something unusual has to be configured for the connection but there’s no need to clutter up the UI. These options currently include the ability to add Schema and Role fields for Snowflake connections and buttons for configuring SSH and SSL to increase their discoverability.

Expert options
The Advanced tab now includes an Expert Options list. In addition to a common option to turn on the JDBC introspector (please contact our support before using it), there are some database-specific options:
Oracle: Disable incremental introspection, Fetch LONG values, Introspect server objects.
SQL Server: Disable incremental introspection.
PostgreSQL (and similar) : Disable incremental introspection, Do not use xmin in queries to pgdatabase.
SQLite: Register REGEXP function.
MYSQL: Use SHOW/CREATE for source code.
Clickhouse: Automatically assign sessionid

Database explorer
Table view for tree nodes
Pressing F4 on any schema node allows you to see the table view of the node’s contents. For example, you can get a view of all tables:
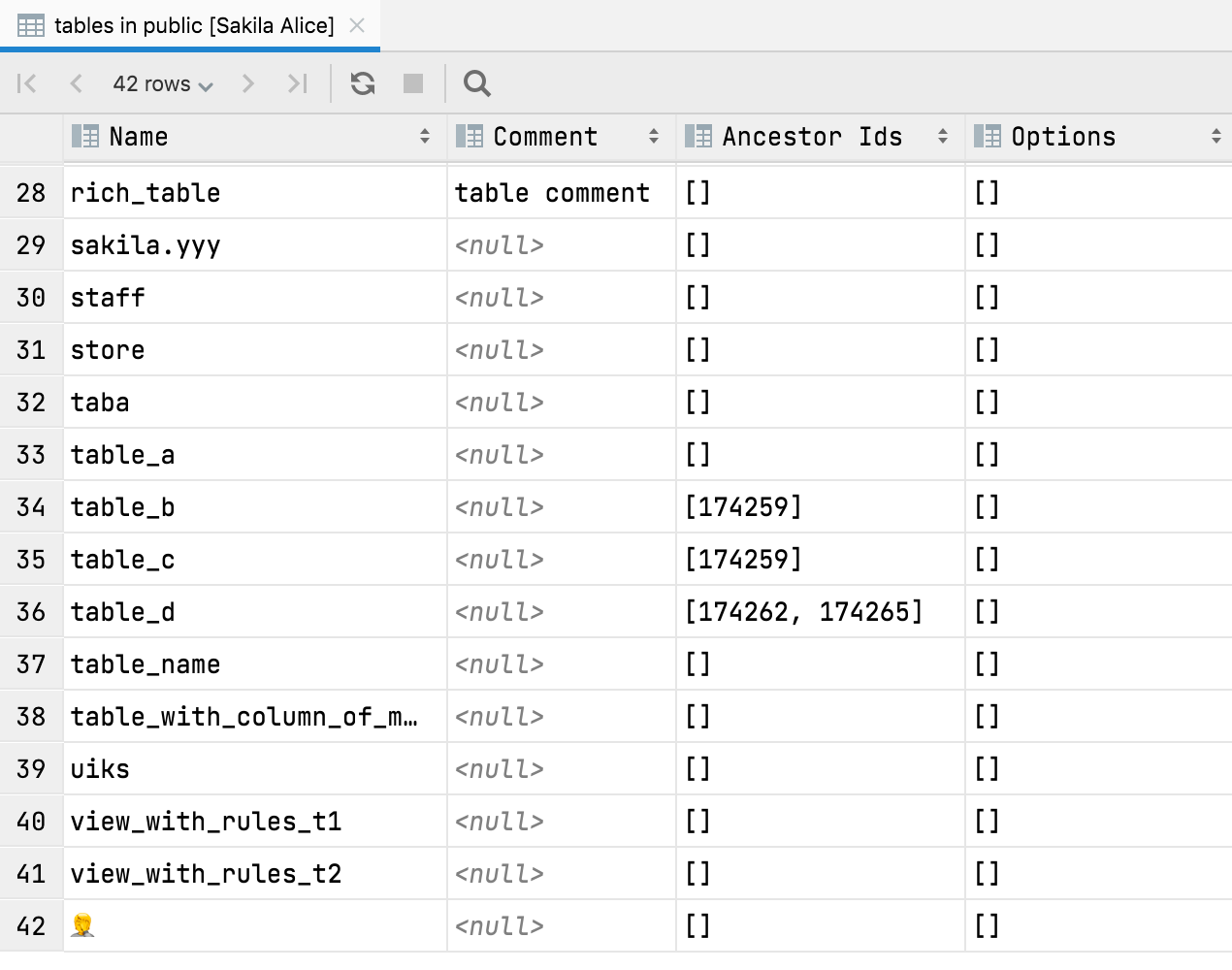
Or a table’s columns: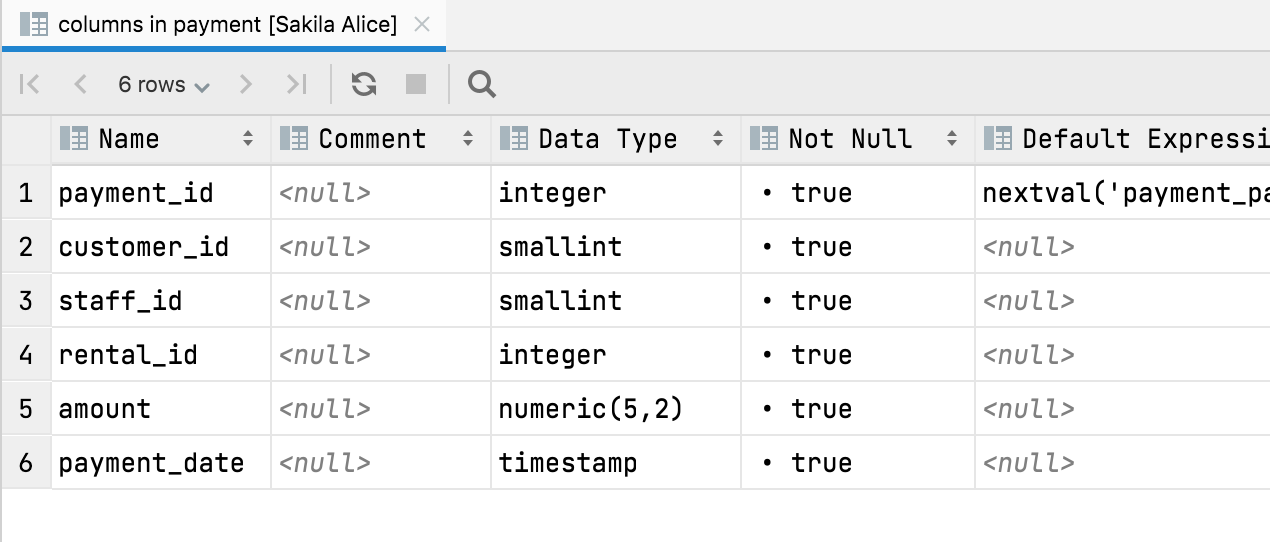
All data viewer capabilities are available here: you can hide/show columns, export to many formats, and use text search.
[Clickhouse] Distributed tables
Distributed tables are now placed under a dedicated node in the database explorer

Query Console
Timestamps in output hidden by default
In line with this request, timestamps are no longer shown for query output by default. If you want to return to the previous behavior, you can adjust the setting in Database | General | Show timestamp for query output.

[MongoDB] Code completion for database names
Database names are completed when using getSiblingDB, and collection names are completed when using getCollection.
Additionally, field names are completed and resolved if used from a collection that was defined through code completion.

Import/Export
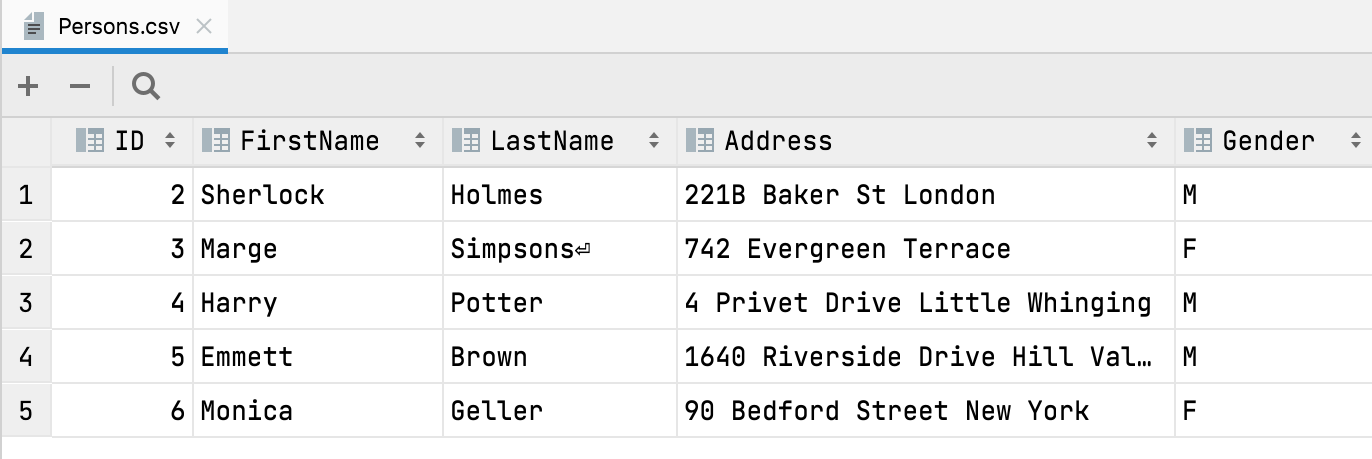
‘First row is header’ auto-detection
Starting from this version, when you open or import a CSV file, DataGrip automatically detects that the first row is the header and contains the names of the columns.