

Fleet
More Than a Code Editor
Dans les coulisses de Fleet, Partie II – Présentation détaillée de l’éditeur

Sommaire
Cet article fait partie d’une série consacrée à la conception et au fonctionnement de Fleet, notre IDE nouvelle génération.
- Partie I – Vue d’ensemble de l’architecture
- Partie II – Présentation détaillée de l’éditeur
Le permier article de cette série était consacré à l’architecture de Fleet. Dans cette deuxième partie, nous allons parler des algorithmes et des structures de données utilisés au cœur de l’éditeur.
Un agrégat de structures de données
Regardez cette capture d’écran de la fenêtre de l’éditeur dans Fleet :

On y voit une ligne de texte dans laquelle les éléments de syntaxe sont mis en évidence et un widget fournissant des informations sur les utilisations de la variable. Il est possible d’afficher ces informations de différentes façons, mais le problème avec les éditeurs est qu’ils ne sont pas en lecture seule. Les données sont affichées, mais peuvent aussi être mises à jour. Une opération simple, telle que la modification d’un nom de fonction, peut avoir un impact en cascade, notamment sur la mise en évidence des éléments de syntaxe, les utilisations, et toute autre fonctionnalité accessible, telle que l’analyse statique ou la compilation à la volée.
Afin de pouvoir fournir la meilleure expérience possible, nous devons nous assurer que l’édition du texte et la visualisation qui en découle soient aussi fluides que possible. Pour ce faire, il faut stocker et manipuler les données de manière efficace. Ceci dit, il n’y a pas qu’une seule façon de stocker les données. En fait, dans image ci-dessus, les données sont stockées de plusieurs façons, en s’appuyant sur différentes structures de données, qui forment ensemble ce que nous appelons l’éditeur. En d’autres termes, l’éditeur peut être considéré comme un agrégateur de structures de données !
Regardons de plus près ses différents éléments !
Des cordes partout
Tous ceux d’entre vous qui ont l’habitude de manipuler de grandes quantités de texte savent que l’utilisation de chaînes (ou tableau de caractères) pour les stocker n’est pas très efficace. Généralement, toute opération sur un tableau implique de devoir créer un autre tableau, plus grand ou plus petit, et à copier le contenu de l’ancien tableau dans le nouveau. Cela n’a rien d’efficace.
Une meilleure approche, qui est aussi plus standardisée, consiste à utiliser des structures de corde. Ce type de données abstrait stocke les chaînes dans les nœuds feuilles d’un arbre.
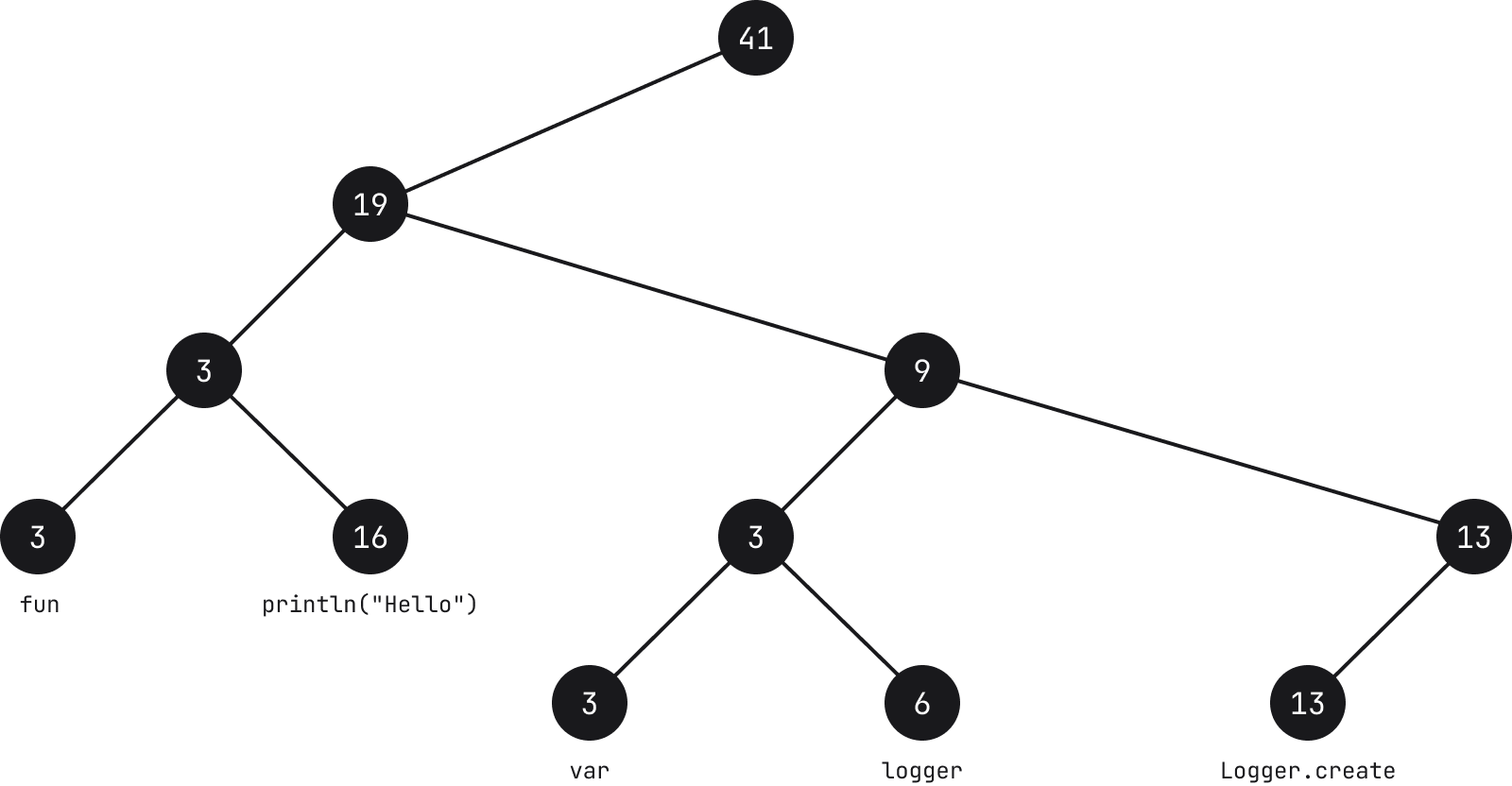
Chaque nœud feuille contient une chaîne (voir la remarque ci-dessous) et sa longueur, appelée poids. Chaque nœud intermédiaire contient également un poids qui correspond à la somme de toutes les feuilles de son sous-arbre gauche.
Remarque : le texte utilisé sur les feuilles est un simple exemple et n’est pas représentatif de la répartition réelle du texte dans Fleet.
Dans l’exemple ci-dessus, si nous prenons le nœud contenant les caractères fun, le décompte affiché par le nœud est 3 parce que la chaîne a 3 caractères. En remontant vers le nœud parent, la valeur reste 3, car la somme de tous les poids à sa gauche est égale à 3. En revanche, son parent affiche 19 car il s’agit de la somme des feuilles à sa gauche, 3 et 16.
Des actions courantes, telles que la recherche, l’ajout, le retrait ou la division de chaînes, peuvent être effectuées avec un niveau de complexité O(log N), où N correspond à la longueur de la chaîne. Les opérations commencent par traverser un arbre et, étant donné les informations des nœuds, cela est plus rapide. Par exemple, si nous devons trouver un caractère à la position i = 30, nous commençons par le nœud, et si 30 est inférieur au poids du nœud (nombre de caractères), nous passons à gauche pour soustraire la valeur du poids de i (voir la remarque ci-dessous). Par contre, si i est supérieur, nous passons à droite. Au fur et à mesure que nous descendons et que la valeur de i diminue, lorsque nous atteignons un nœud feuille, le caractère à la position i de la chaîne contenue par le nœud est le caractère recherché.
Remarque : selon la mesure utilisée, la soustraction peut ne pas être l’opération requise. L’important est d’accumuler les mesures en suivant l’arbre vers le bas jusqu’au nœud voulu et de les comparer à la clé que nous recherchons.
Lors de l’insertion ou de la suppression de nœuds dans la structure de corde de Fleet, nous utilisons un arbre B à équilibrage automatique. Nous commençons par lire des blocs de 64 caractères, et lorsque nous arrivons à des blocs de 32 caractères, nous créons un nœud et commençons à collecter des blocs pour un deuxième nœud. Chaque nœud a deux nombres : en plus du poids, nous stockons également le nombre de lignes (la combinaison des deux correspond à ce que nous appelons mesures).

En stockant le nombre de lignes, nous pouvons accéder plus rapidement à des positions spécifiques. Une autre caractéristique de l’arborescence dans Fleet est que nous privilégions la largeur à la profondeur.
Arbres d’intervalle pour les widgets et autres.
Comme nous l’avons vu plus haut, un fragment de code peut non seulement contenir du texte, mais aussi des éléments additionnels comme des utilisations.

Nous appelons cela des widgets, et il peut s’agir de widgets interlignes, tels que les widgets Find Usages ou Run, postlignes (par exemple, débogage des informations apparaissant après la ligne de code) ou incrustée (par exemple, suggestions de types pour les variables et les lambdas).
Un widget en soi est simplement un élément de balisage, et la structure de données qui le contient est une variante des arbres d’intervalle, dont la structure est comparable à celle d’une corde. Dans les arbres d’intervalle, les nœuds contiennent une plage et le poids correspond à la valeur maximale des plages du sous-arbre.
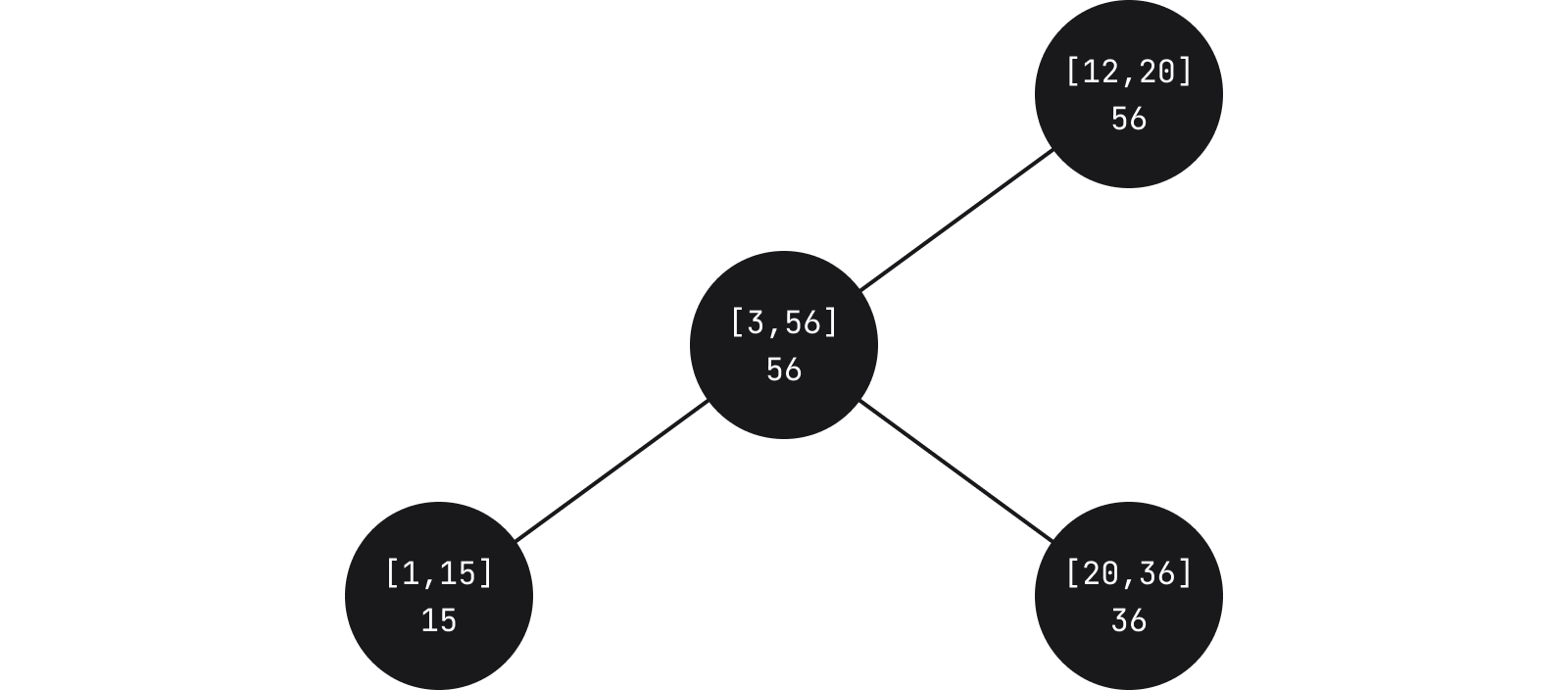
Dans Fleet, chaque nœud contient un début et une fin relatifs des nœuds enfants. Les feuilles, quant à elles, contiennent un widget. Lors de l’éxécution de requêtes pour voir si un widget donné doit s’afficher en fonction de coordonnées spécifiques, nous traversons l’arbre jusqu’à ce que la plage croise celle que nous recherchons.
Chose importante : les feuilles contiennent également l’ID du widget. Cela signifie qu’en supplément des requêtes portant sur les intersections d’une plage spécifique, il est également possible de déterminer son emplacement quel que soit le widget.
Une différence par rapport à un arbre d’intervalle standard est que Fleet permet aux nœuds de se superposer. Cela peut rendre les recherches un peu moins efficaces, mais a pour avantage de créer des arbres équilibrés et d’avoir la possibilité de les mettre à jour pendant la saisie.
En complément des widgets, les arbres d’intervalle de Fleet permettent également de suivre les carets, de mettre le texte en évidence, et de créer des emplacements épinglés dans le texte que nous appelons des ancres.
Cordes pour les jetons et Arbre de syntaxe abstrait
Lorsqu’on travaille sur du code source, on utilise normalement un arbre de syntaxe abstrait (AST), qu’il s’agisse d’un compilateur ou d’un éditeur. Un module analyse le code source et crée une série de jetons. Ces jetons servent ensuite à construire l’AST.
Prenons le code suivant :
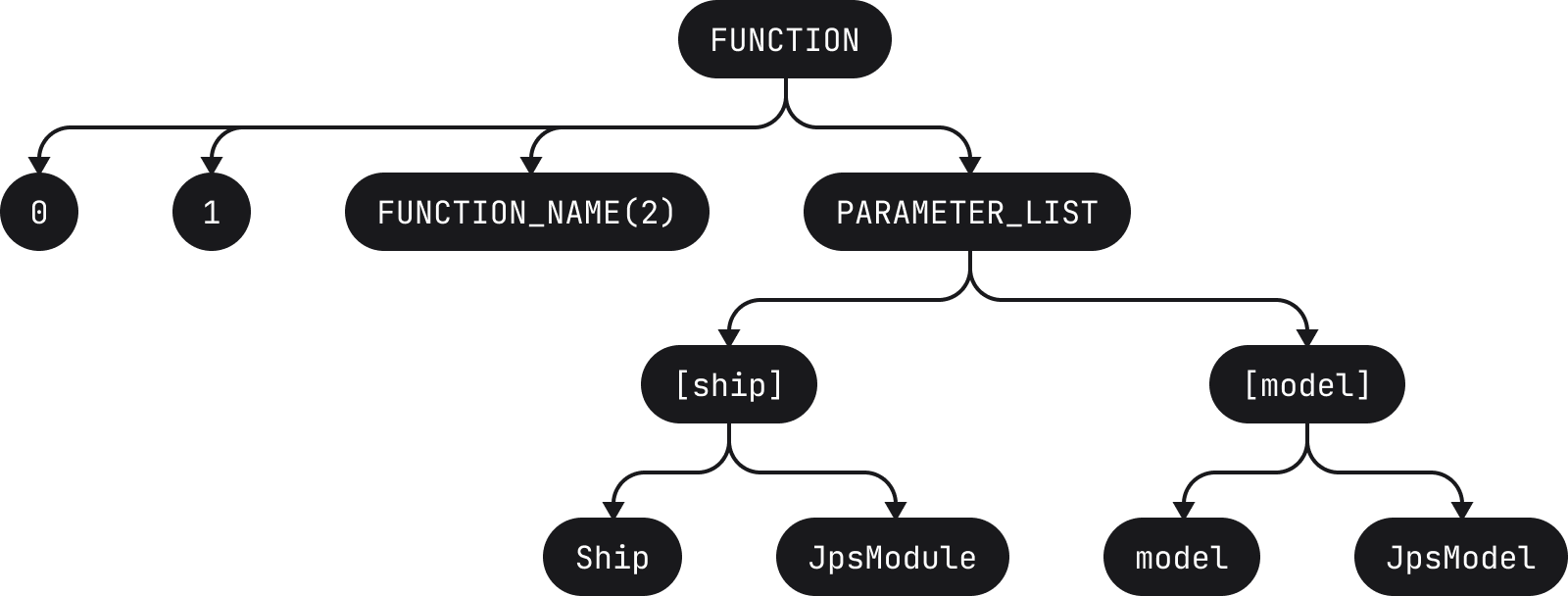
fun compileBundles(ship: JpsModule, model: JpsModel, src: SrcBundles): DstBundles
Il serait divisé pour obtenir les jetons suivants :
[fun][ ][compileBundles][(][ship][:][ ][JpsModule][,][ ][model][:][ ][JpsModel][,][ ][src][:][ ][SrcBundles][)][:][ ][DstBundles]
où chaque jeton est représenté par des crochets (il est à noter que les espaces vides sont également des jetons). Ces jetons servent ensuite à créer l’AST correspondant.
L’AST est ensuite utilisé dans différents types d’opérations, comme la mise en évidence des éléments de syntaxe, l’analyse statique, etc. C’est une partie importante de l’IDE.
À ce sujet, si vous souhaitez voir comment du code peut être converti en AST, essayez cet explorateur d’AST en ligne (qui est utilisable avec différents langages).
Au fur et à mesure de la saisie dans l’éditeur, le texte change, ce qui signifie que les jetons changent aussi, et un nouvel AST doit être créé pour fournir les fonctionnalités ci-dessus.
Dans Fleet, pour éviter de mettre à jour l’AST directement, nous utilisons une structure de corde pour stocker les jetons dans des feuilles (en fait, seules les longueurs sont stockées). Pour donner un exemple, la liste de jetons ci-dessus pourrait être représentée par l’arborescence suivante :

Lorsque l’utilisateur saisit quelque chose, par exemple un espace, l’arbre est mis à jour (la longueur 1 est ajoutée sur la feuille la plus à gauche, ce qui augmente d’autant le total sur ce chemin).
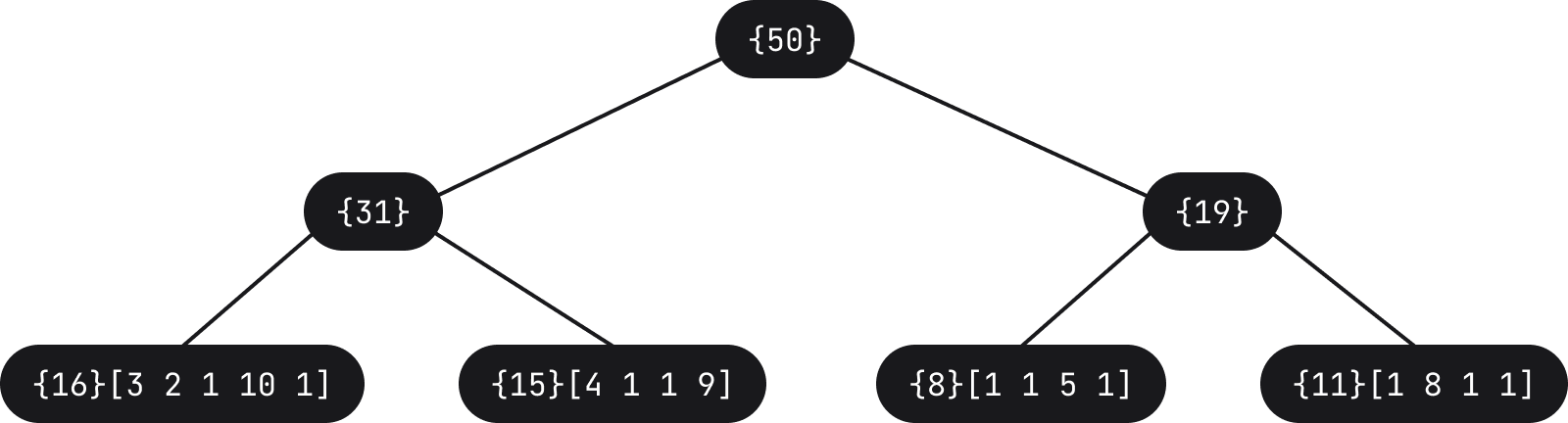
La longueur du nouveau jeton s’ajoute sur la feuille concernée, ce qui en retour met à jour certains nœuds de l’arbre pour ajuster le poids. L’analyseur reçoit ensuite une notification qui le force à se mettre à jour et à analyser de nouveau l’AST. Ainsi, l’AST risque de ne pas être entièrement correct pendant une fraction de seconde, mais l’expérience utilisateur en termes d’édition est bien meilleure car il y a très peu de choses à mettre à jour.
Cordes pour le rendu
L’image ci-dessous est un autre exemple tiré de l’éditeur, mais cette fois avec quelques éléments supplémentaires, notamment le widget des utilisations étendu pour afficher les utilisations, les retours à la ligne, et d’autres éléments comme les lignes verticales colorées dans la barre de défilement.
Le rendu ci-dessus nécessite non seulement de savoir quelle ligne sera affichée pour une coordonnée Y donnée, mais aussi de prendre en compte tous les widgets et retours à la ligne.
Anecdote : l’éditeur rendu dans le widget des utilisations utilise les mêmes structures de données sous-jacentes que celles que nous présentons dans cet article. Pour les utilisations dans le même fichier, les mêmes cordes sont utilisées pour créer et restituer cet éditeur.
Les informations sur le widget et les retours à la ligne sont également stockées dans une structure de type corde. Alors qu’avant les feuilles de l’arborescence contenaient la chaîne et sa longueur, dans ce cas, les feuilles contiennent des objets SoftLine. Il s’agit de blocs de texte accompagnés par les hauteurs qui sont considérées comme des lignes visuelles. Dans ce cas, le poids des nœuds (que nous appelons mesures) correspond à la hauteur et la longueur des SoftLine. La hauteur est stockée de façon à pouvoir prendre en charge les requêtes de la fenêtre d’affichage. Cette hauteur est affectée par les interlignes qu’elle contient. De plus, lorsque les retours à la ligne sont activés, SoftLines n’établit pas une correspondance exacte ligne à ligne et peut correspondre à une plage de lignes.
Remarque sur l’immutabilité
Il est important de signaler que Fleet a adopté l’immutabilité. L’utilisation de fonctions pures et d’objets immuables offre de nombreux avantages. Les fonctions pures nous permettent non seulement de mieux raisonner sur le code, mais également de savoir que l’appel d’une fonction ne générera pas de modification imprévue ou d’effet secondaire dans le reste du système. En termes de données, savoir qu’un objet est immuable signifie qu’il ne posera pas de problème au niveau des threads et qu’il n’y aura pas de situation de compétition en cas de tentative de mise à jour. Pour les environnements multi-thread, cela présente des avantages considérables.
Ce principe d’immutabilité est également central pour les opérations qui utilisent des structures de corde. Plus haut, nous avons vu comment mettre à jour les nœuds et les feuilles de l’arbre. Tout cela se fait de façon immuable : toute opération sur l’arbre produit une copie de l’arbre qui partage sa structure avec le précédent, à l’exception de la racine du nœud qui doit être modifiée. Dans la mesure où les arbres sont généralement larges et peu profonds, les chemins sont très courts. Si l’opération mène à des nœuds non référencés, ces derniers sont nettoyés de la mémoire.
Cette approche est assez différente de celle de la plateforme IntelliJ, pour laquelle nous utilisons des mécanismes de verrouillage de lecture-écriture pour la réalisation de modifications.
En résumé
Comme nous l’avons vu dans ce deuxième volet sur la conception de Fleet, un outil aussi simple qu’un éditeur servant à saisir et à lire du code peut s’avérer être une agrégation complexe de différentes structures de données sous-jacentes, dont la plupart sont des cordes. Si vous souhaitez en apprendre plus sur les cordes, nous vous recommandons de lire la série d’articles Rope Science, qui a fortement influencé notre travail pour la conception de Fleet.
Auteur de l’article original en anglais :




