

IntelliJ IDEA
IntelliJ IDEA – the Leading IDE for Professional Development in Java and Kotlin
The Inspection Connection – Issue #4, Duplication Detection

One of the core principles of computer programming is eliminating manual repetition. Not only is repeated code time-consuming to read and review, it is disproportionately complex to maintain and provides a ready source of bugs when one copy changes. Yet in spite of this, duplicating some code in a large project may be inevitable. IntelliJ IDEA offers a powerful inspection for detecting and deduplicating repetitive code. You can activate this inspection by navigating to the menu entry Analyze|Locate Duplicates, or by pressing Ctrl/⌘+Alt/⌥+Shift+I then typing, “Duplicated Code.”
As it turns out, “Don’t Repeat Yourself” has some notable exceptions, especially when writing unit tests, and occasionally in some rare cases when attempting to outsmart the compiler. IntelliJ IDEA gives you the opportunity to exclude test sources, since many prefer a little duplication in their tests to improve overall readability. Nevertheless, the choice is yours.
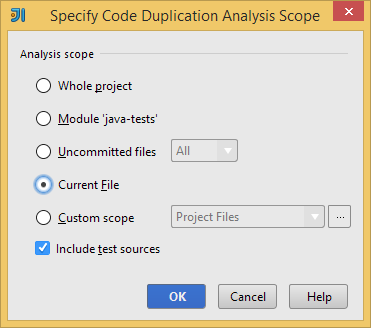 When analyzing a large set of files, you should carefully consider the scope of the inspection you are going to apply. There are a number of algorithms for detecting duplicate code – this one will scan for duplicates by comparing AST fragments. On an Intel i7-2640M with 8GB of RAM, scanning a codebase with 53,000 LOC will take about 3 minutes, or ~300 LOC/second. However your mileage may vary depending on the minimum duplicates length, line density and other factors. When searching for exact matches, the time complexity is effectively linear w.r.t. the number of nodes in your AST.
When analyzing a large set of files, you should carefully consider the scope of the inspection you are going to apply. There are a number of algorithms for detecting duplicate code – this one will scan for duplicates by comparing AST fragments. On an Intel i7-2640M with 8GB of RAM, scanning a codebase with 53,000 LOC will take about 3 minutes, or ~300 LOC/second. However your mileage may vary depending on the minimum duplicates length, line density and other factors. When searching for exact matches, the time complexity is effectively linear w.r.t. the number of nodes in your AST.
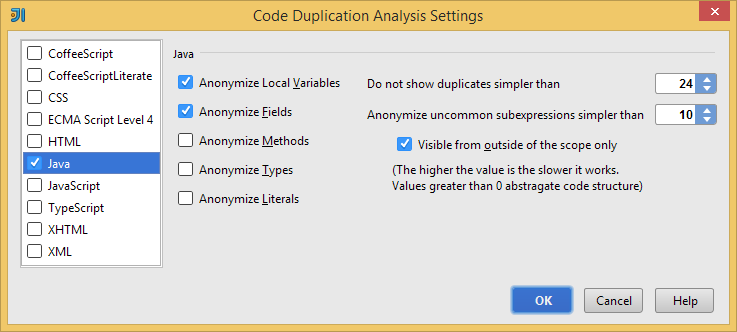 When searching for duplicate code, we may want to discard duplicates shorter than some minimum threshold or add a similarity metric in order to detect fuzzy-matches. IntelliJ IDEA lets us define these values, but keep in mind they do not correspond to characters or lines, but rather arbitrary weights. If “Visible from outside of the current scope only” is selected, only subexpressions which are valid outside of their parent construct are anonymized. If you would like to learn more how all of this works, head over to the source.
When searching for duplicate code, we may want to discard duplicates shorter than some minimum threshold or add a similarity metric in order to detect fuzzy-matches. IntelliJ IDEA lets us define these values, but keep in mind they do not correspond to characters or lines, but rather arbitrary weights. If “Visible from outside of the current scope only” is selected, only subexpressions which are valid outside of their parent construct are anonymized. If you would like to learn more how all of this works, head over to the source.
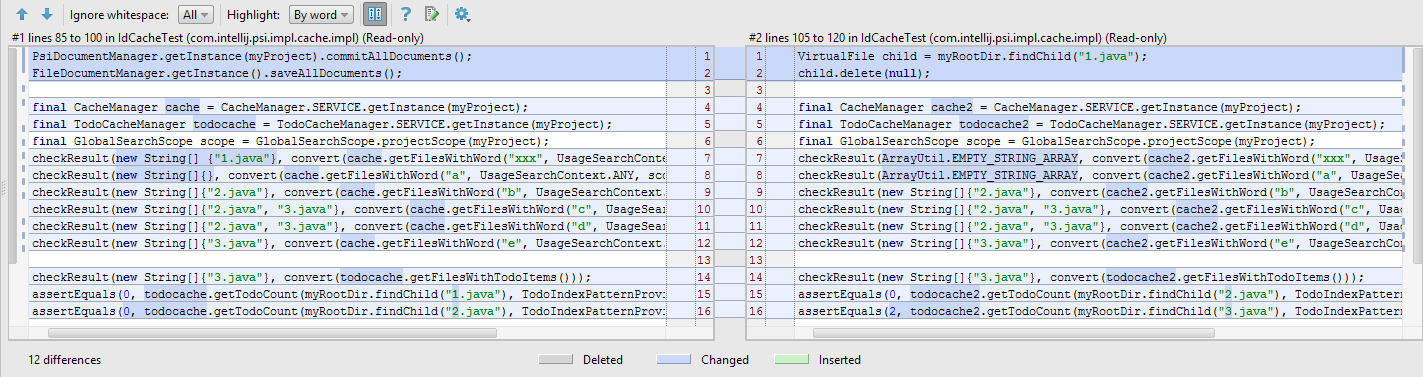
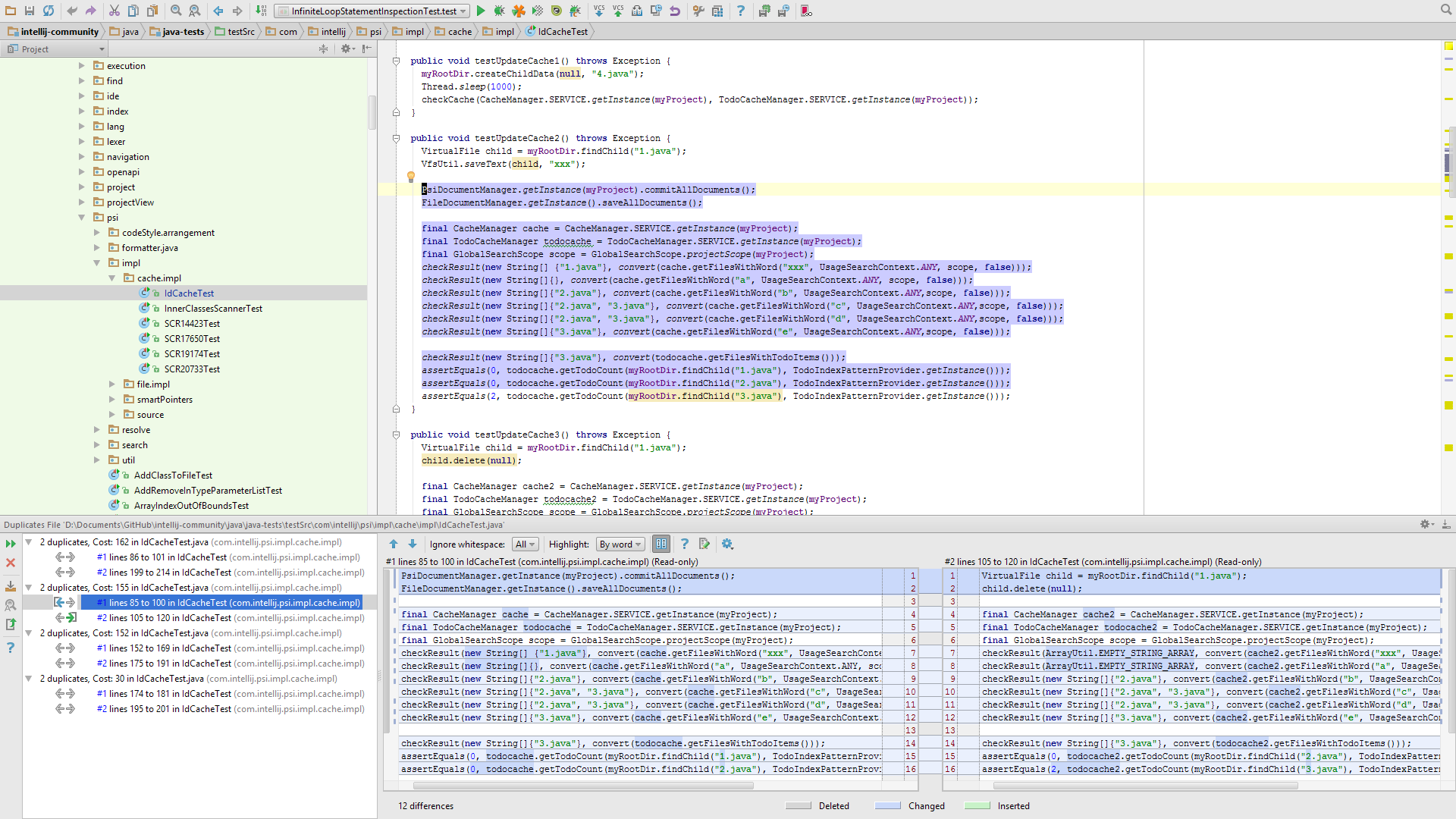 After scanning, the Duplicates Tool Window is a convenient area to browse through duplicate regions and view a side-by-side diff at each location. From here you can clearly see which sections are structurally similar and flag them for review or refactor them immediately. The highlighter will help you quickly identify which blocks are different.
After scanning, the Duplicates Tool Window is a convenient area to browse through duplicate regions and view a side-by-side diff at each location. From here you can clearly see which sections are structurally similar and flag them for review or refactor them immediately. The highlighter will help you quickly identify which blocks are different.
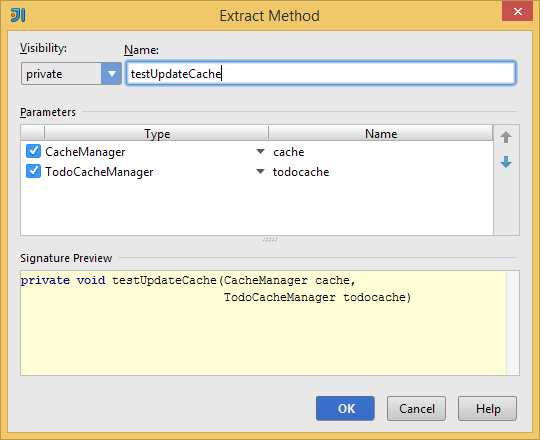
When you have found a duplicate block of code, it can be easily simplified by pressing Ctrl/⌘+Alt/⌥+M to apply the Extract → Method refactoring. IntelliJ IDEA will transform all inbound variables inside the selected region with parameters and provide a helpful dialog to extract the method, which you can use to replace any other duplicates inside the analysis scope.
 This inspection is also available in TeamCity, where you can assign a dedicated build runner to periodically scan your project for duplicate code. This may be an even better option if your organization needs regular assurance audits for clean-room engineering. Plagiarism detection is another important use case for the academic community, and if you are a student or teacher, IntelliJ IDEA is now completely free.
This inspection is also available in TeamCity, where you can assign a dedicated build runner to periodically scan your project for duplicate code. This may be an even better option if your organization needs regular assurance audits for clean-room engineering. Plagiarism detection is another important use case for the academic community, and if you are a student or teacher, IntelliJ IDEA is now completely free.






