

Usando o PyCharm para ler dados de um banco de dados MySQL em pandas

Mais cedo ou mais tarde na sua jornada de ciência de dados, você chegará a um ponto em que precisará obter dados de um banco de dados. No entanto, o salto entre ler um arquivo CSV armazenado localmente para o pandas e conectar e consultar bancos de dados pode parecer uma tarefa assustadora. Na primeira de uma série de postagens de blog, exploraremos como ler dados armazenados em um banco de dados MySQL em pandas e veremos alguns recursos interessantes do PyCharm que facilitam essa tarefa.

Visualizando o conteúdo do banco de dados
Neste tutorial, vamos ler alguns dados sobre atrasos e cancelamentos de companhias aéreas de um banco de dados MySQL para um DataFrame do pandas. Esses dados são uma versão do conjunto de dados “Airline Delays from 2003-2016”, por Priank Ravichandar e licenciada sob a CC0 1.0.
Uma das primeiras coisas que podem ser frustrantes ao se trabalhar com bancos de dados é não ter uma visão geral dos dados disponíveis, já que todas as tabelas são armazenadas num servidor remoto. Portanto, o primeiro recurso do PyCharm que usaremos é a janela de ferramentas Database, que permite que você se conecte e introspeccione totalmente um banco de dados antes de fazer qualquer consulta.
Para se conectar ao nosso banco de dados MySQL, vamos primeiro navegar para o lado direito do PyCharm e clicar na janela de ferramentas Database.
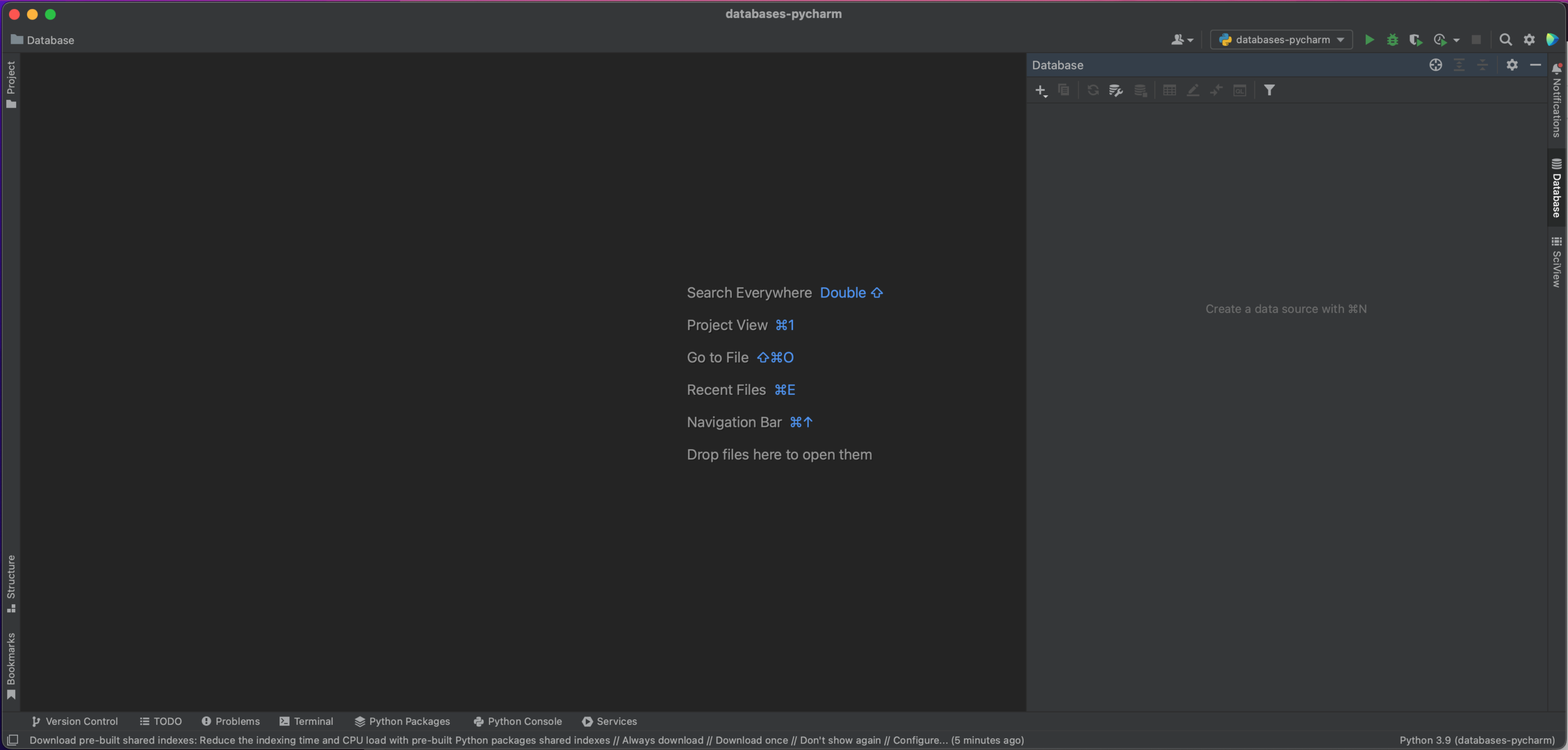
No canto superior esquerdo dessa janela, você verá um botão de adição. Clicar nele ativa a seguinte janela de diálogo suspensa, na qual selecionaremos Data Source | MySQL.
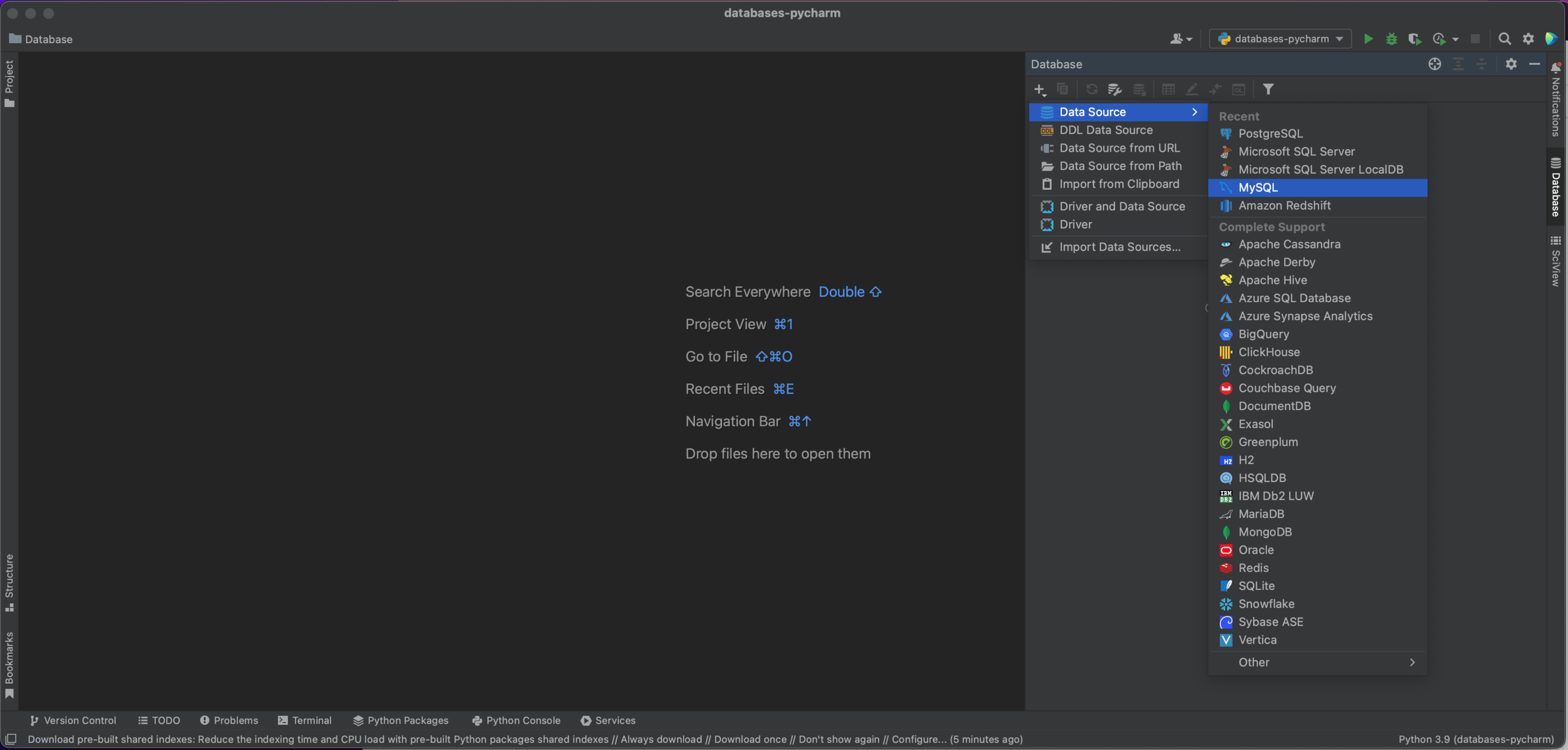
Agora, temos uma janela pop-up que nos permitirá abrir uma conexão ao nosso banco de dados MySQL. Neste caso, estamos usando um banco de dados hospedado localmente, então deixamos Host como “localhost” e Port como a porta MySQL padrão de “3306”. Usaremos a opção de Authentication “User & Password” e digitaremos o valor “pycharm” para User e para Password. Por fim, vamos inserir “demo” para como o nome do banco de dados em Database. Obviamente, para se conectar ao seu próprio banco de dados MySQL, você precisará do host específico, do nome do banco de dados e do seu nome de usuário e senha. Consulte a documentação para conhecer o conjunto completo de alternativas.
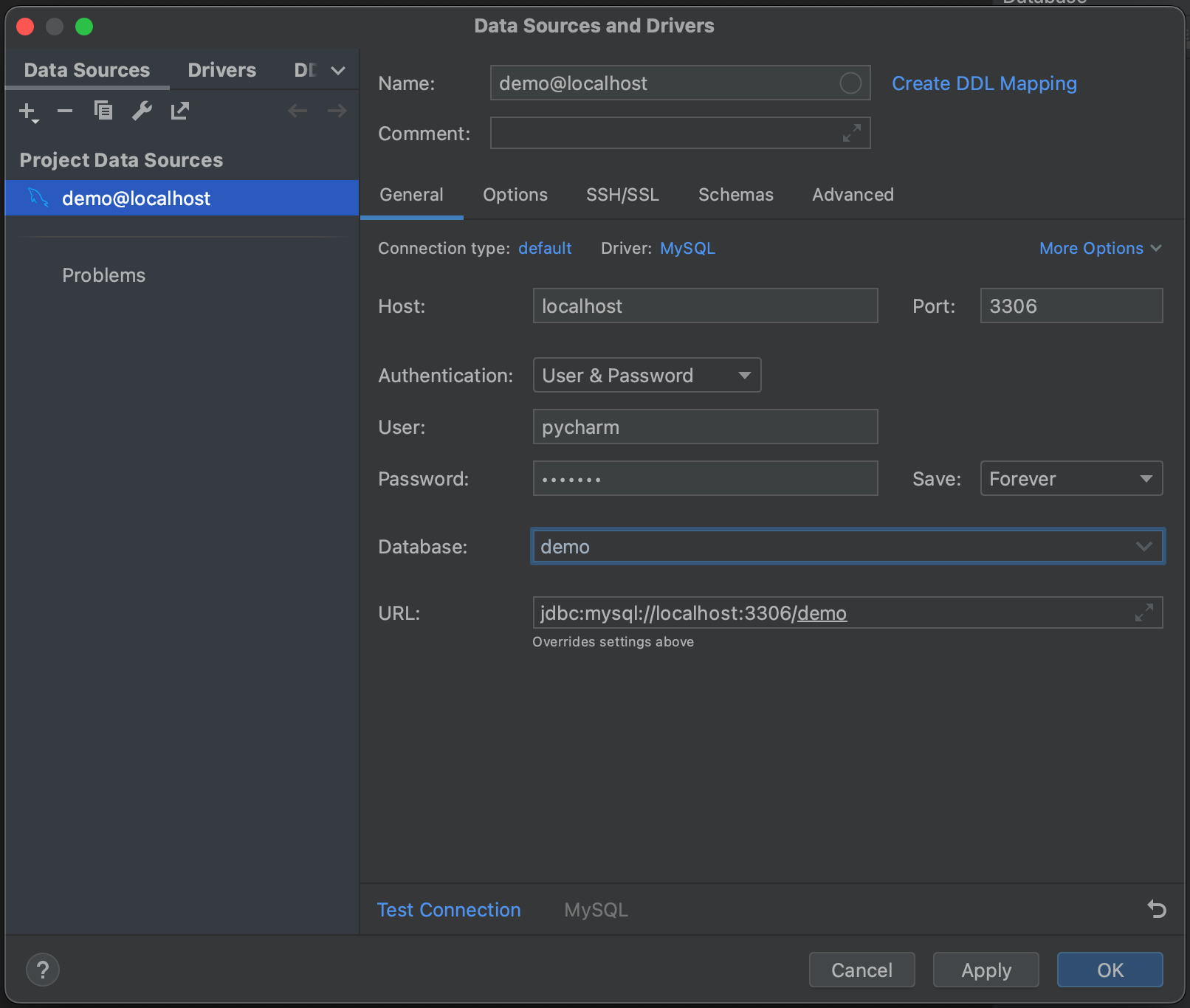
Em seguida, clique em Test Connection. O PyCharm nos informa que não temos os arquivos de driver instalados. Vá em frente e clique em Download Driver Files. Um dos recursos mais interessantes da janela de ferramentas Database é que ela localiza e instala automaticamente os drivers corretos.
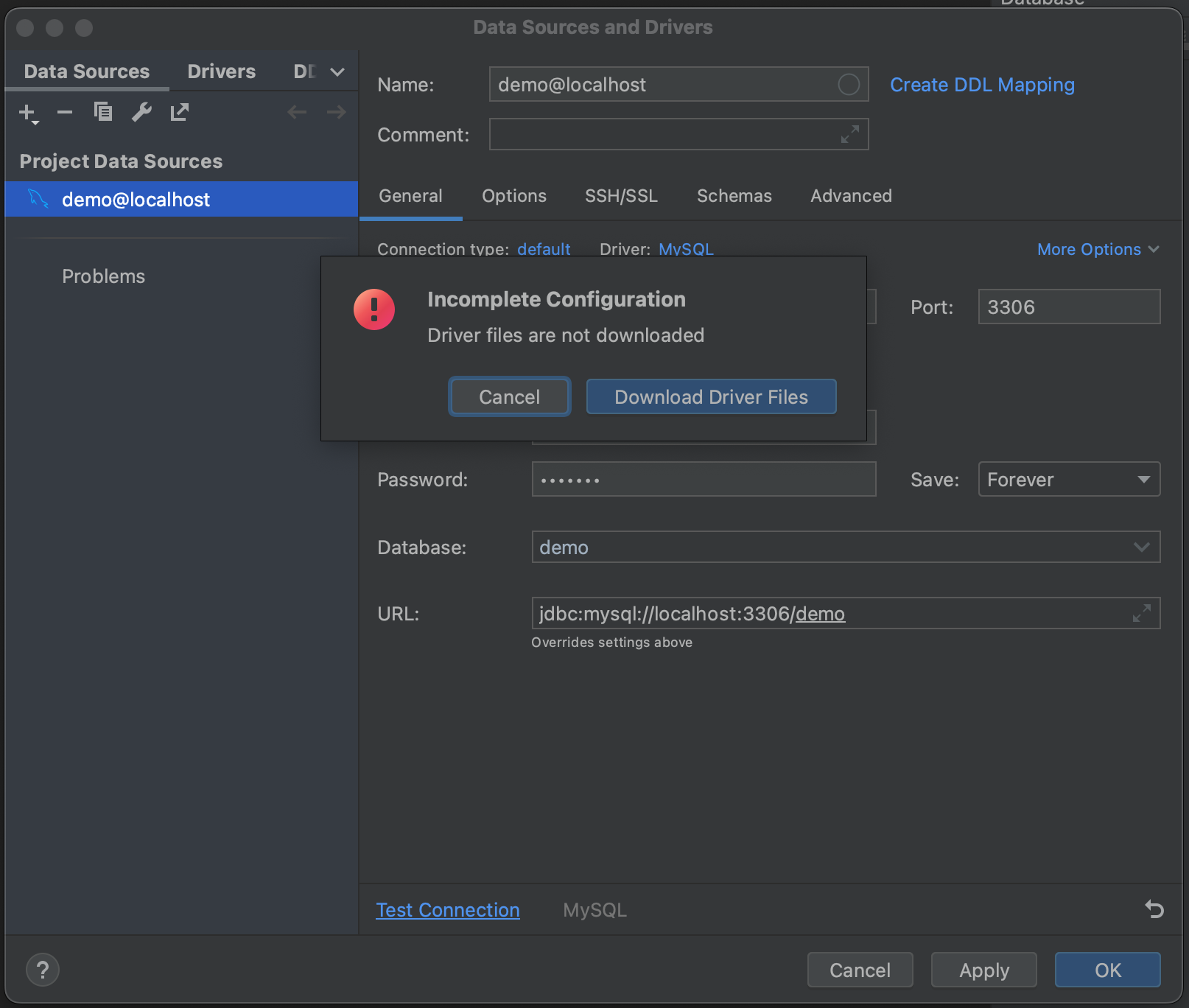
Sucesso! Nós nos conectamos ao nosso banco de dados. Agora, podemos navegar até a aba Schemas e selecionar quais esquemas queremos examinar. Em nosso banco de dados de exemplo, temos apenas uma (“demo”), mas, nos casos em que você possui bancos de dados muito grandes, pode economizar tempo analisando apenas os relevantes.
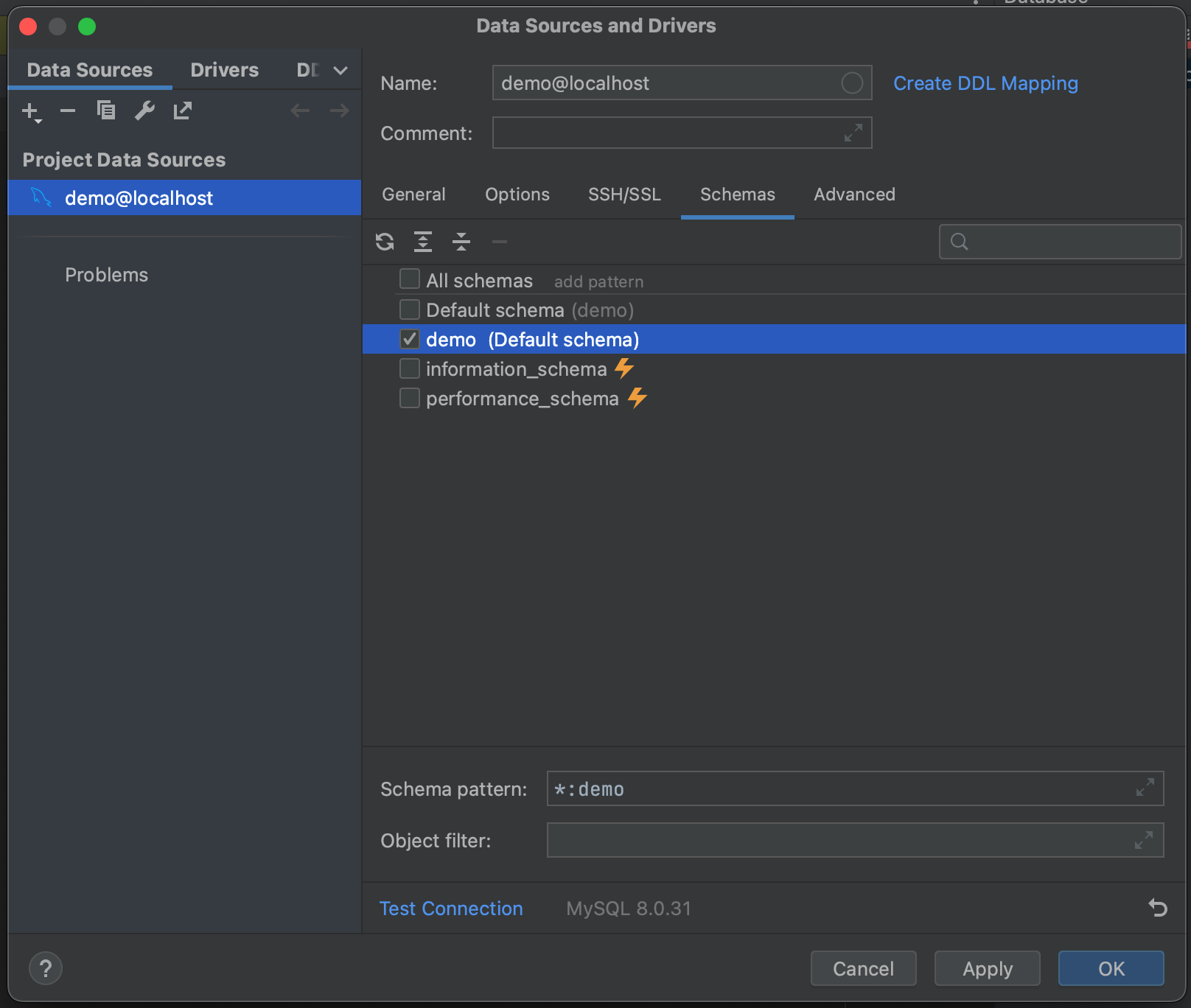
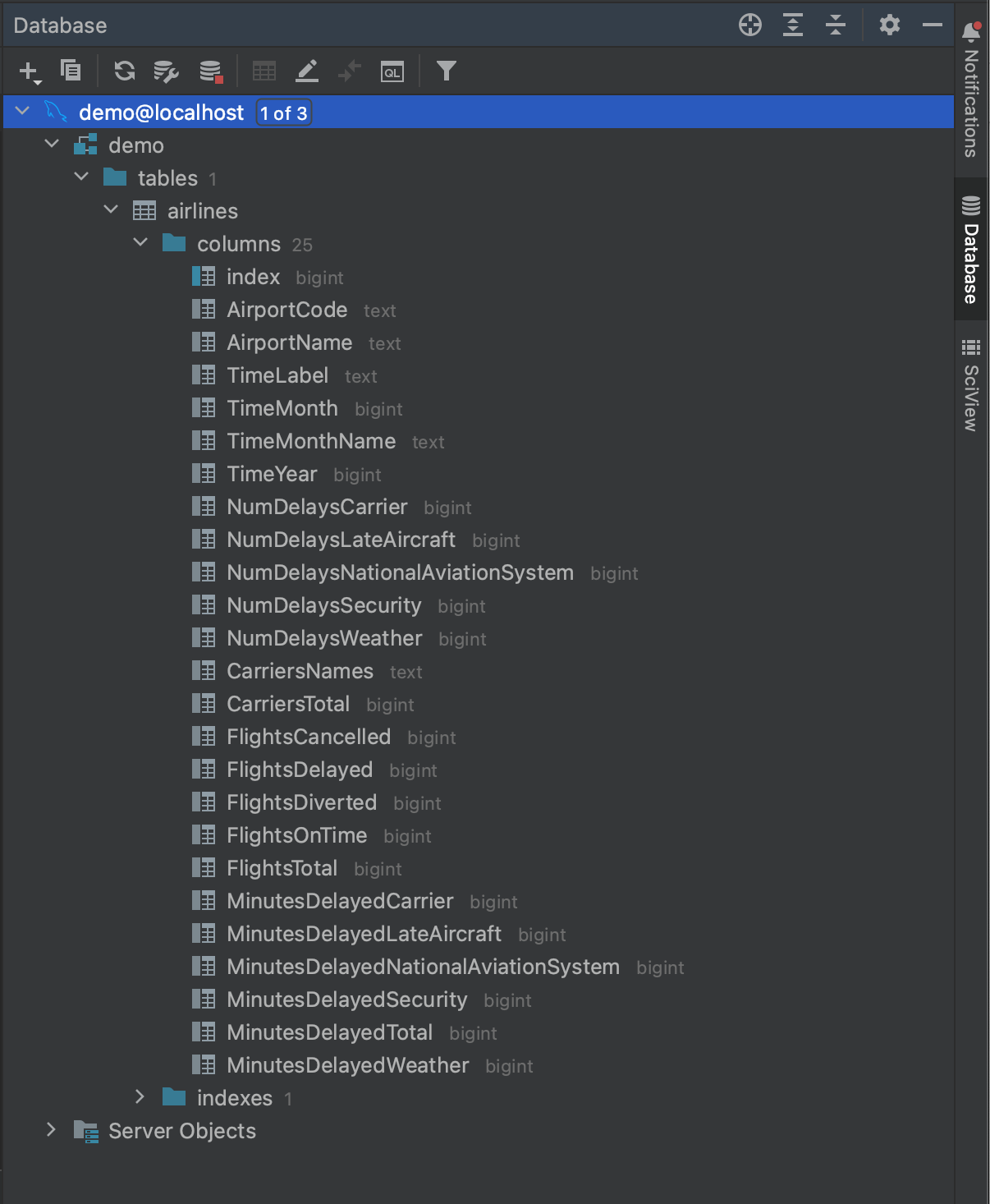
Com tudo isso feito, estamos prontos para nos conectar ao nosso banco de dados. Clique em OK e aguarde alguns segundos. Agora, você pode ver que todo o nosso banco de dados foi instrospeccionado, até o nível dos campos da tabela e seus tipos. Isso nos dá uma ótima visão geral do que está no banco de dados antes de executar qualquer consulta.
Lendo os dados com o MySQL Connector
Agora que sabemos o que está em nosso banco de dados, estamos prontos para montar uma consulta. Digamos que queremos ver os aeroportos que tiveram pelo menos 500 atrasos em 2016. Observando os campos na tabela introspectiva airlines, vemos que podemos obter esses dados com a seguinte consulta:
SELECT AirportCode,
SUM(FlightsDelayed) AS TotalDelayed
FROM airlines
WHERE TimeYear = 2016
GROUP BY AirportCode
HAVING SUM(FlightsDelayed) > 500;
A primeira maneira de executar essa consulta usando o Python é através de um pacote chamado MySQL Connector, que pode ser instalado a partir do PyPI ou Anaconda. Consulte a documentação vinculada se precisar de orientação sobre como configurar ambientes pip ou conda ou sobre como instalar dependências. Assim que a instalação for concluída, abriremos um novo notebook Jupyter e importaremos o MySQL Connector e o pandas.
import mysql.connector import pandas as pd
Para ler dados do nosso banco de dados, precisamos criar um conector. Isto é feito usando o método connect, para o qual passamos as credenciais necessárias para acessar o banco de dados: host, database, user e password. Estas são as mesmas credenciais que usamos para acessar o banco de dados usando a janela de ferramentas Database na seção anterior.
mysql_db_connector = mysql.connector.connect( host="localhost", database="demo", user="pycharm", password="pycharm" )
Agora, precisamos criar um cursor. Isto será usado para executar nossas consultas SQL no banco de dados e usará as credenciais ordenadas no nosso conector para obter acesso.
mysql_db_cursor = mysql_db_connector.cursor()
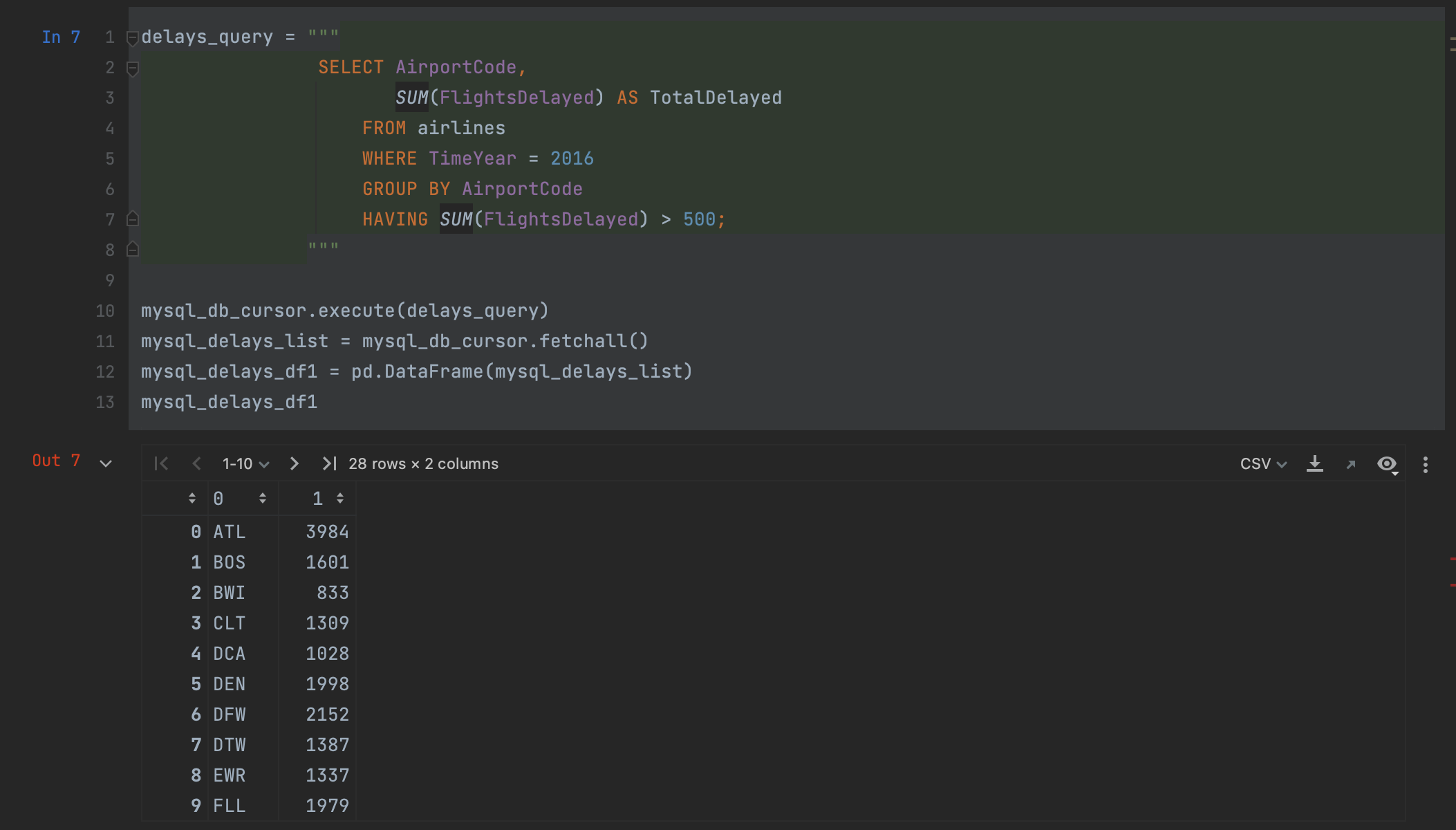
Agora, estamos prontos para executar nossa consulta. Fazemos isso usando o método execute do nosso cursor e passando a consulta como argumento.
delays_query = """
SELECT AirportCode,
SUM(FlightsDelayed) AS TotalDelayed
FROM airlines
WHERE TimeYear = 2016
GROUP BY AirportCode
HAVING SUM(FlightsDelayed) > 500;
"""
mysql_db_cursor.execute(delays_query)
Em seguida, recuperamos o resultado usando o método fetchall do cursor.
mysql_delays_list = mysql_db_cursor.fetchall()
No entanto, temos um problema nesse ponto: fetchall retorna os dados como uma lista. Para usá-la em pandas, podemos passá-la para um DataFrame, mas perderemos os nomes de coluna, que precisarão ser especificados manualmente quando quisermos criar o DataFrame.
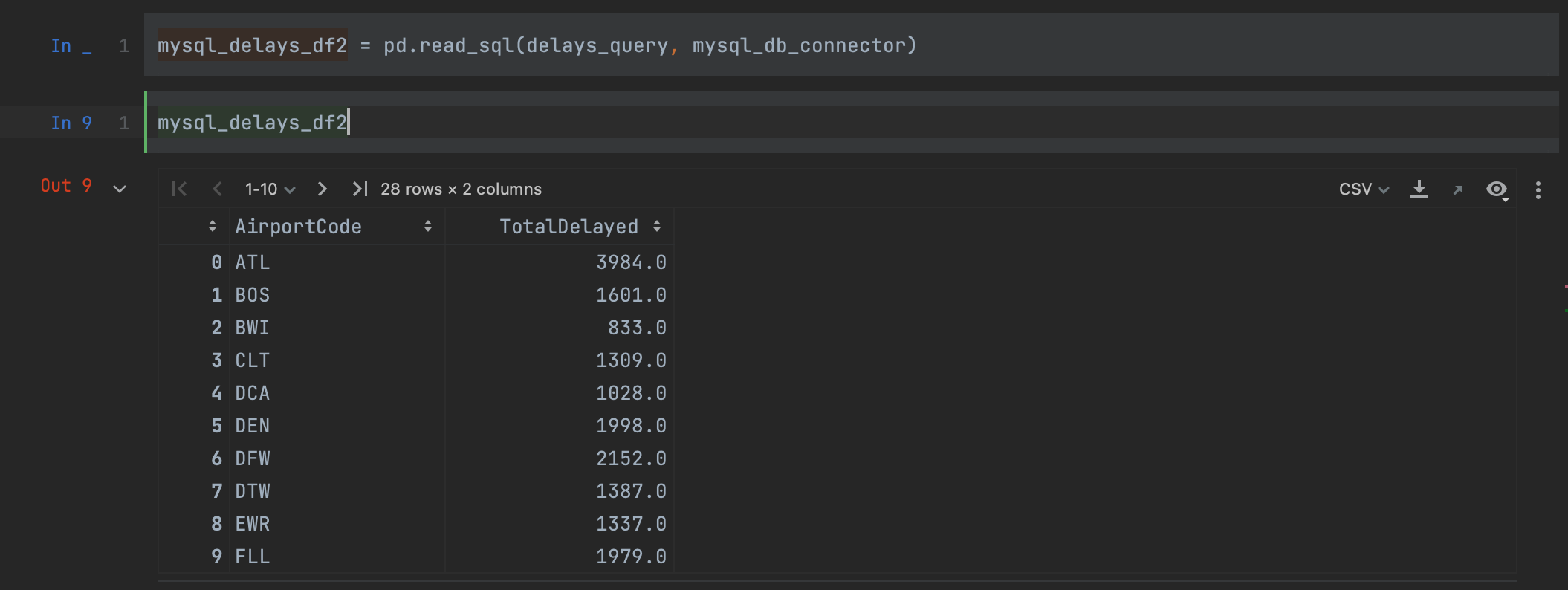
Felizmente, pandas oferece uma solução melhor. Em vez de criar um cursor, podemos ler nossa consulta em um DataFrame numa única etapa, usando o método method read_sql.
mysql_delays_df2 = pd.read_sql(delays_query, con=mysql_db_connector)
Precisamos simplesmente passar nossa consulta e conector como argumentos para ler os dados do banco de dados MySQL. Olhando para nosso dataframe, podemos ver que temos exatamente os mesmos resultados acima, mas, desta vez, nossos nomes de coluna foram preservados.
Um bom recurso que você deve ter percebido é que o PyCharm aplica realce de sintaxe à consulta SQL, mesmo quando ela está contida numa string Python. Abordaremos outra maneira pela qual o PyCharm permite que você trabalhe com o SQL mais adiante nesta postagem de blog.
Lendo os dados com o uso do SQLAlchemy
Uma alternativa para usar o MySQL Connector é usar um pacote chamado SQLAlchemy. Esse pacote oferece um método único para conectar-se a uma variedade de bancos de dados diferentes, incluindo o MySQL. Uma das coisas boas sobre o uso do SQLAlchemy é que a sintaxe para consultar diferentes tipos de banco de dados permanece consistente entre os tipos de banco de dados, evitando que você se tenha que se lembrar de vários comandos diferentes se estiver trabalhando com muitos bancos de dados diferentes.
Para começar, precisamos instalar o SQLAlchemy a partir do PyPI ou Anaconda. Em seguida, importamos o método create_engine e, é claro, pandas.
import pandas as pd from sqlalchemy import create_engine
Agora, precisamos criar nosso mecanismo. O mecanismo nos permite dizer ao pandas qual dialeto SQL estamos usando (no nosso caso, o MySQL) e fornecer as credenciais necessárias para acessar nosso banco de dados. Tudo isso é passado como uma string, na forma de [dialect]://[user]:[password]@[host]/[database]. Vejamos como fica usando nosso banco de dados MySQL:
mysql_engine = create_engine("mysql+mysqlconnector://pycharm:pycharm@localhost/demo")
Com isto criado, basta usar read_sql novamente, desta vez passando o mecanismo para o argumento con:
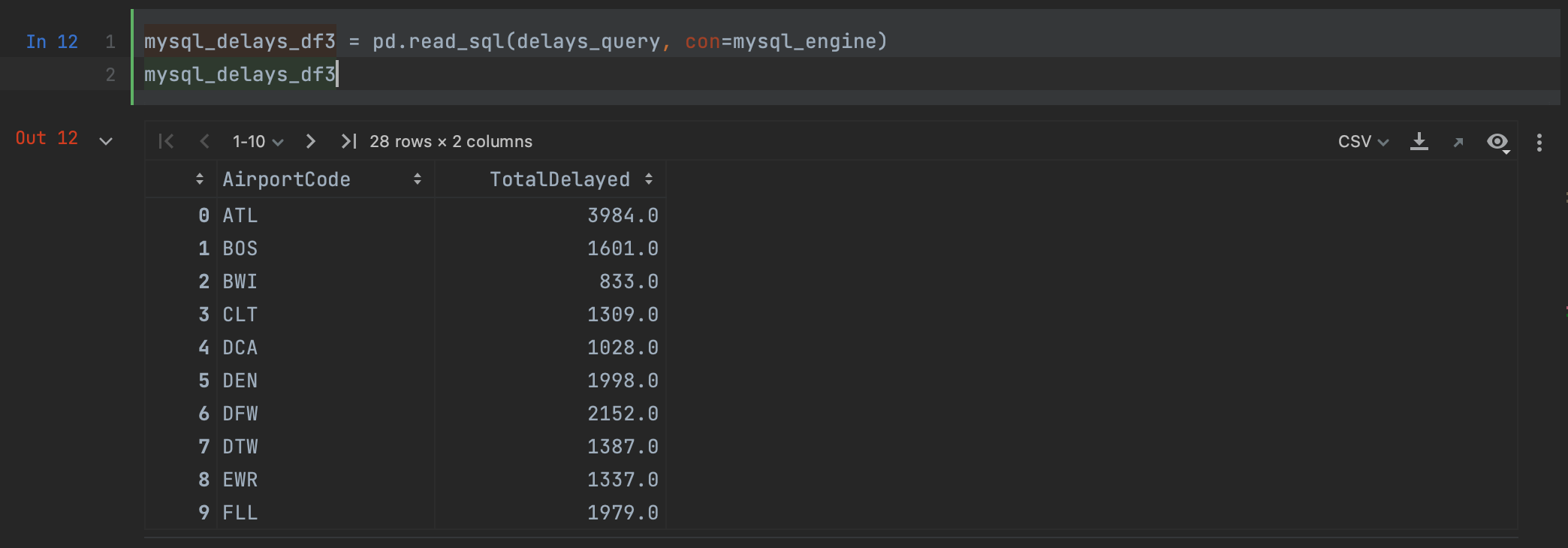
mysql_delays_df3 = pd.read_sql(delays_query, con=mysql_engine)
Como você pode ver, obtemos o mesmo resultado ao usar read_sql com o MySQL Connector.
Opções avançadas para trabalhar com bancos de dados
Esses métodos de conector são muito bons para extrair uma consulta que já sabemos que queremos. Mas, e se quisermos ter uma prévia de como serão nossos dados antes de executar a consulta completa ou ter uma ideia de quanto tempo toda a consulta levará? O PyCharm está de volta com alguns recursos avançados para trabalhar com bancos de dados.
Se navegarmos de volta para a janela de ferramentas Database e clicarmos com o botão direito do mouse em nosso banco de dados, veremos que, em New, temos a opção de criar um console de consulta em Query Console.
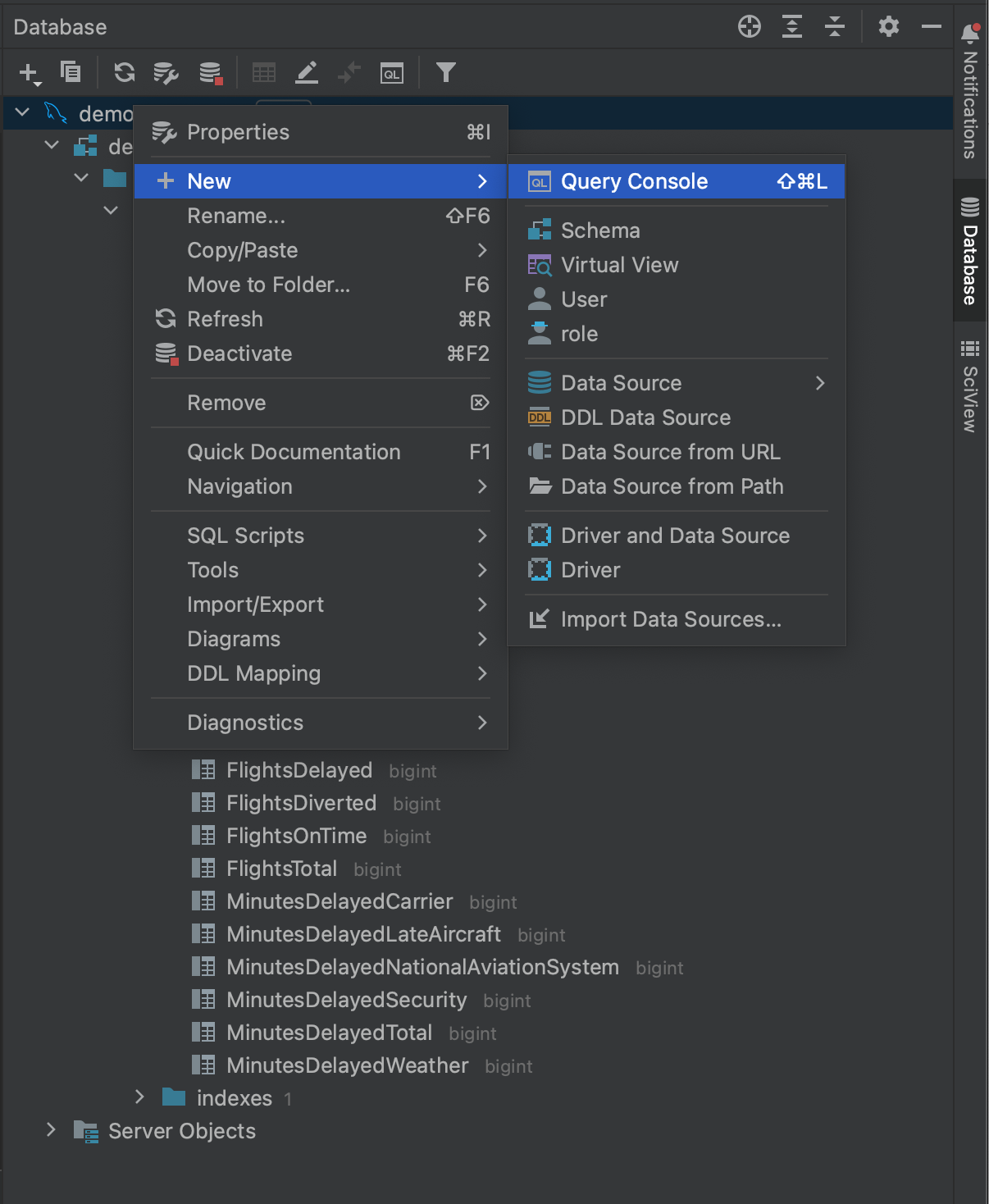
Isso nos permite abrir um console que podemos usar para consultar o banco de dados em SQL nativo. A janela do console inclui complementação e introspecção de código SQL, oferecendo uma maneira mais fácil de criar suas consultas antes de repassá-las para os pacotes de conectores em Python.
Realce sua consulta e clique no botão Execute no canto superior esquerdo.
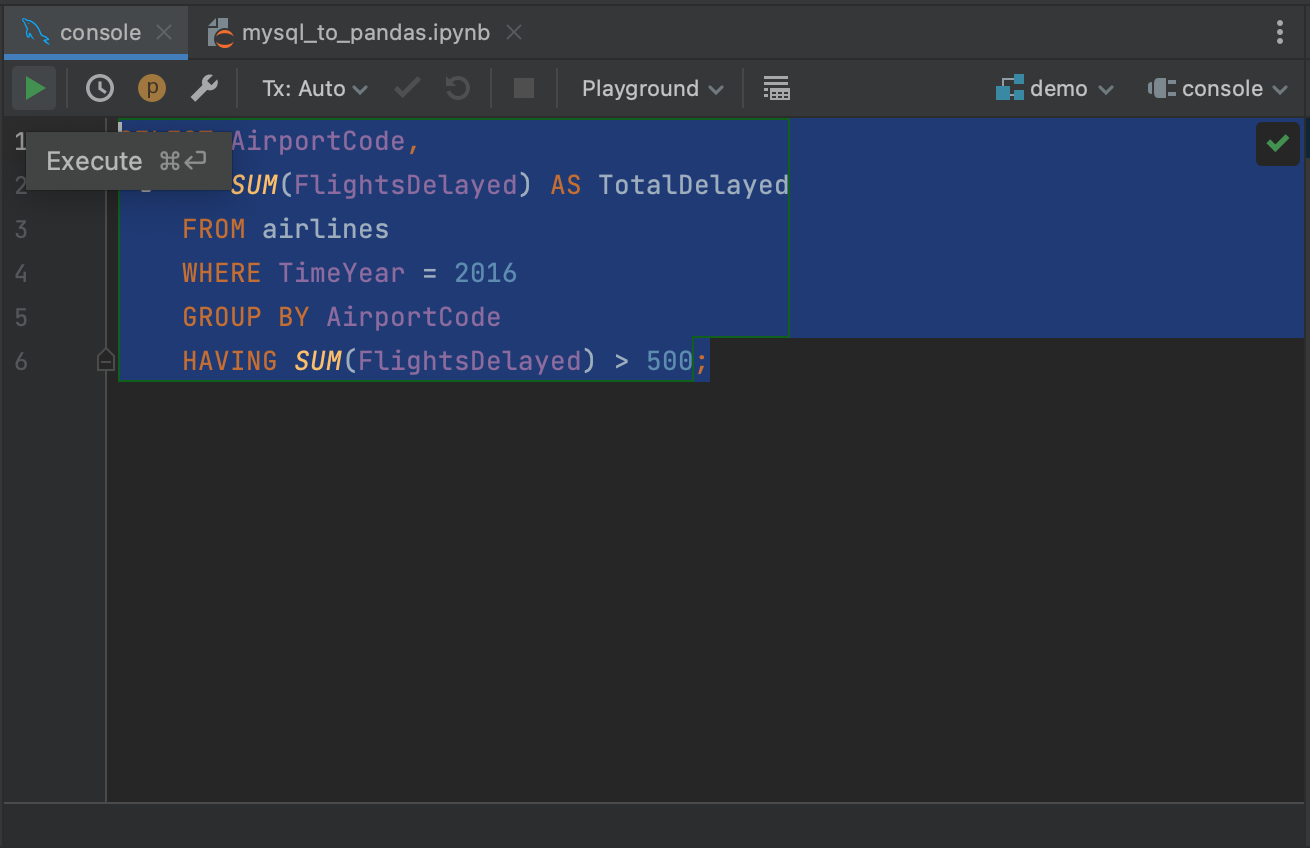
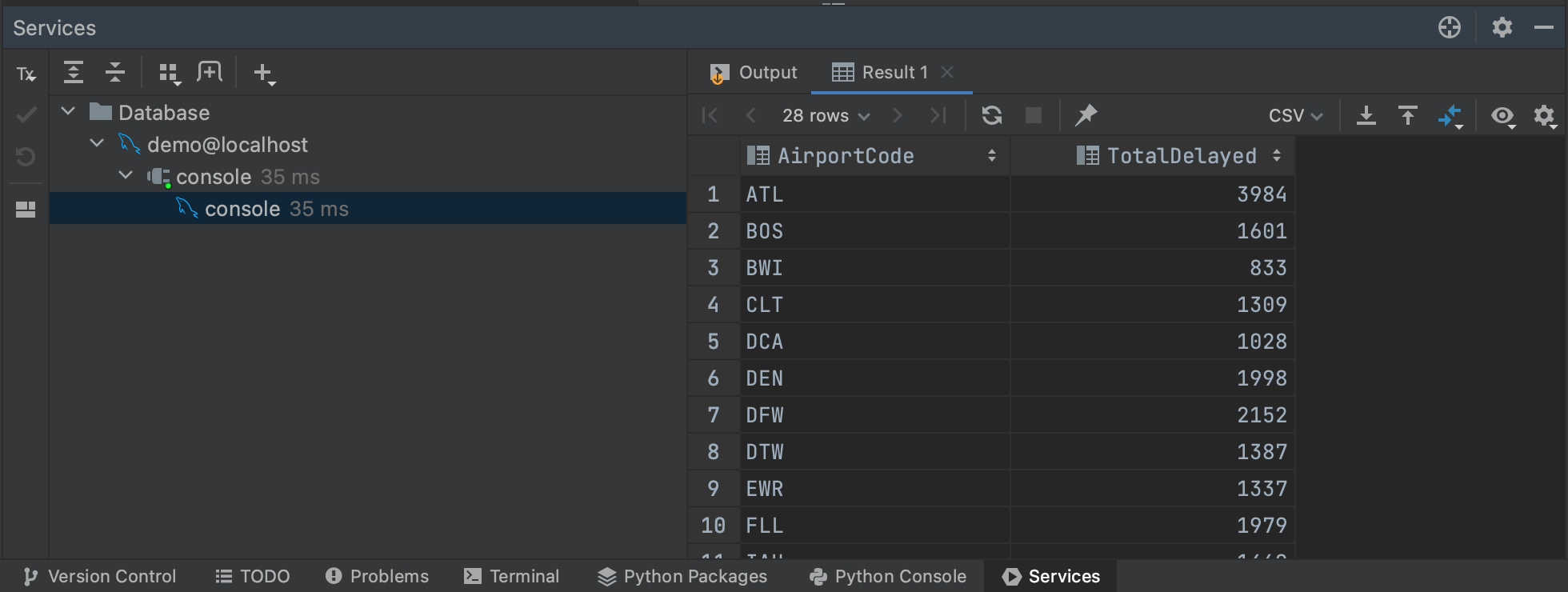
Isto recuperará os resultados da nossa consulta na aba Services, onde ela pode ser inspecionada ou exportada. Uma coisa boa sobre a execução de consultas no console é que apenas as primeiras 500 linhas são inicialmente recuperadas do banco de dados, o que significa que você pode ter uma noção dos resultados de consultas maiores sem o compromisso de extrair todos os dados. Você pode ajustar o número de linhas recuperadas acessando Settings/Preferences | Tools | Database | Data Editor and Viewer e alterando o valor em Limit page size to:.
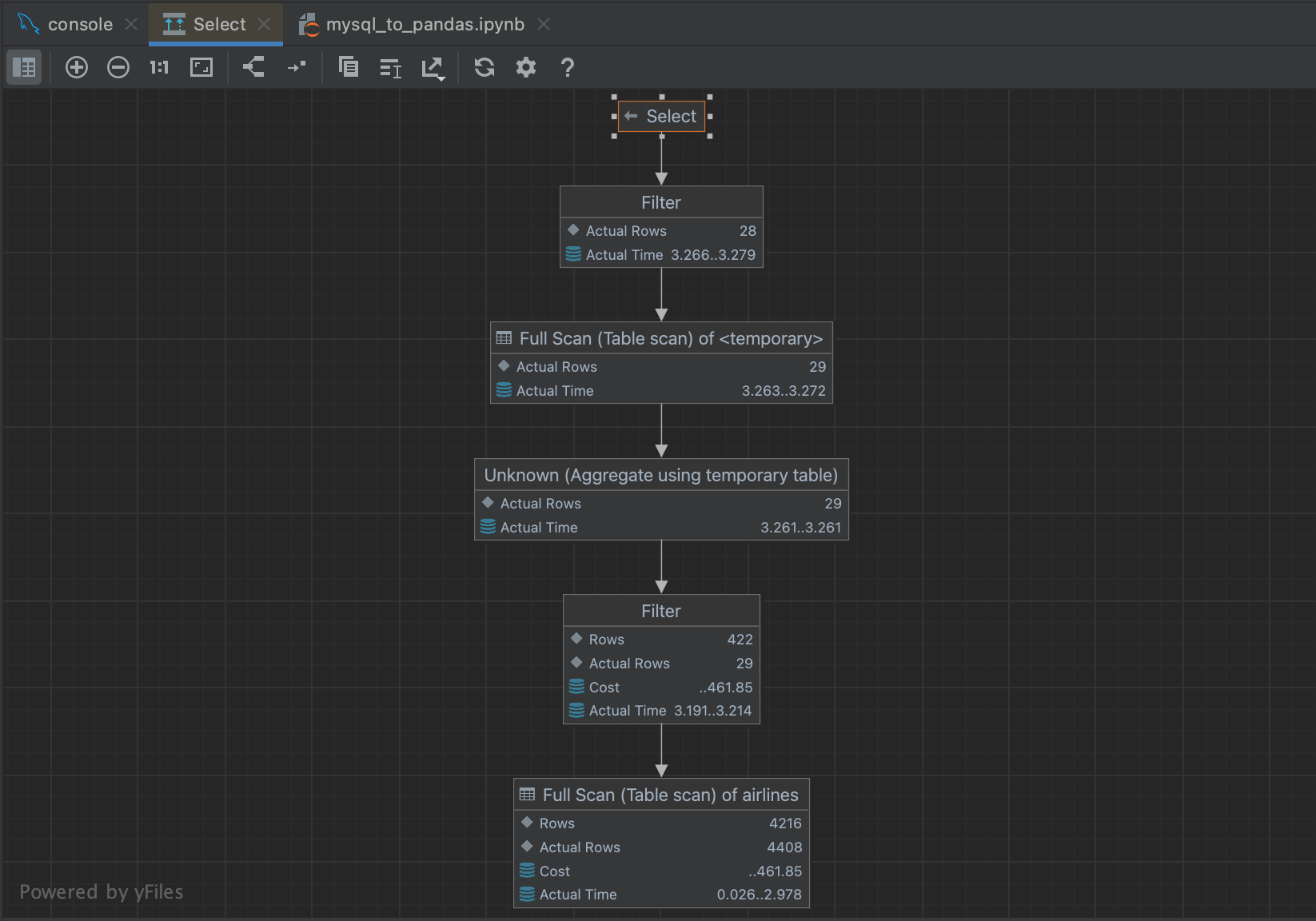
Falando em consultas grandes, também podemos ter uma noção de quanto tempo nossa consulta levará, gerando um plano de execução. Se realçarmos nossa consulta novamente e clicarmos com o botão direito do mouse, poderemos selecionar Explain Plan | Explain Analyse no menu. Isto gerará um plano de execução para a nossa consulta, mostrando cada etapa que o planejador de consulta está realizando para recuperar nossos resultados. Planos de execução são um tema por si só, e não precisamos realmente entender tudo o que nosso plano está nos dizendo. Mais relevante para nossos propósitos é a coluna Actual Total Time, onde podemos ver quanto tempo levará para retornar todas as linhas em cada etapa. Isto nos dá uma boa estimativa do tempo geral da consulta, bem como se alguma parte de nossa consulta provavelmente consumirá muito tempo.
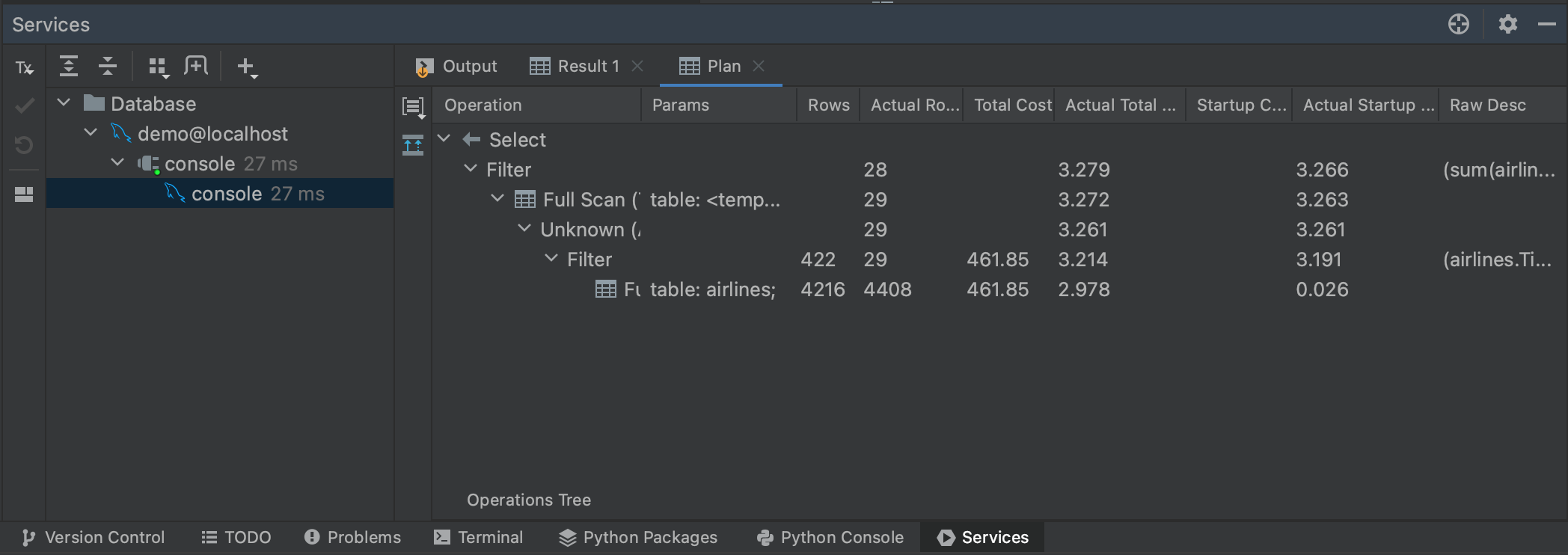
Você também pode visualizar a execução clicando no botão Show Visualization, à esquerda do painel Plan.
Isto exibirá um fluxograma que torna um pouco mais fácil navegar pelas etapas que o planejador de consulta está executando.
Obter dados de bancos de dados MySQL em DataFrames pandas é simples, e o PyCharm possui várias ferramentas poderosas para facilitar o trabalho com bancos de dados MySQL. Na próxima postagem do blog, veremos como usar o PyCharm para ler dados em pandas de outro tipo de banco de dados popular: bancos de dados PostgreSQL.
Artigo original em inglês por:





