

PyCharm을 사용해 MySQL 데이터베이스에서 pandas로 데이터를 읽어오는 방법

데이터 과학 작업을 하다 보면 데이터베이스에서 데이터를 가져와야 할 때가 있습니다. 그러나 로컬에 저장된 CSV 파일을 읽다가 pandas로 넘어가 데이터베이스에 연결하여 쿼리하는 작업은 진행하기 부담스러울 수 있습니다. 시리즈의 첫 번째인 이번 블로그 글에서는 MySQL 데이터베이스에 저장된 데이터를 pandas로 불러오는 방법을 알아보고 이 과정을 더 쉽게 처리할 수 있도록 도와주는 유용한 PyCharm 기능을 살펴봅니다.

데이터베이스 콘텐츠 조회
이번 튜토리얼에서는 MySQL 데이터베이스에 있는 항공편 지연 및 결항 데이터를 pandas DataFrame으로 읽어 보겠습니다. 이 데이터는 Priank Ravichandar가 제작한 “2003-2016 항공편 지연” 데이터세트의 한 버전이며 CC0 1.0 라이선스로 제공됩니다.
데이터베이스 작업을 할 때 짜증나는 점 중 하나는 모든 테이블이 원격 서버에 저장되어 있어 사용 가능한 데이터의 개요를 볼 수 없다는 점입니다. 따라서 여기서 사용할 첫 번째 PyCharm 기능은 Database(데이터베이스) 도구 창으로, 해당 창에서는 쿼리 작업을 하기 전에 데이터베이스에 연결해서 전체적으로 내부 검사를 할 수 있습니다.
MySQL 데이터베이스에 연결하기 위해 먼저 PyCharm의 오른쪽으로 이동하여 Database(데이터베이스) 도구 창을 클릭합니다.
창의 왼쪽 상단에 + 버튼이 있습니다. +를 누르면 다음의 드롭다운 대화상자 창이 나타납니다. 해당 창에서 Data Source(데이터 소스) | MySQL을 선택합니다.
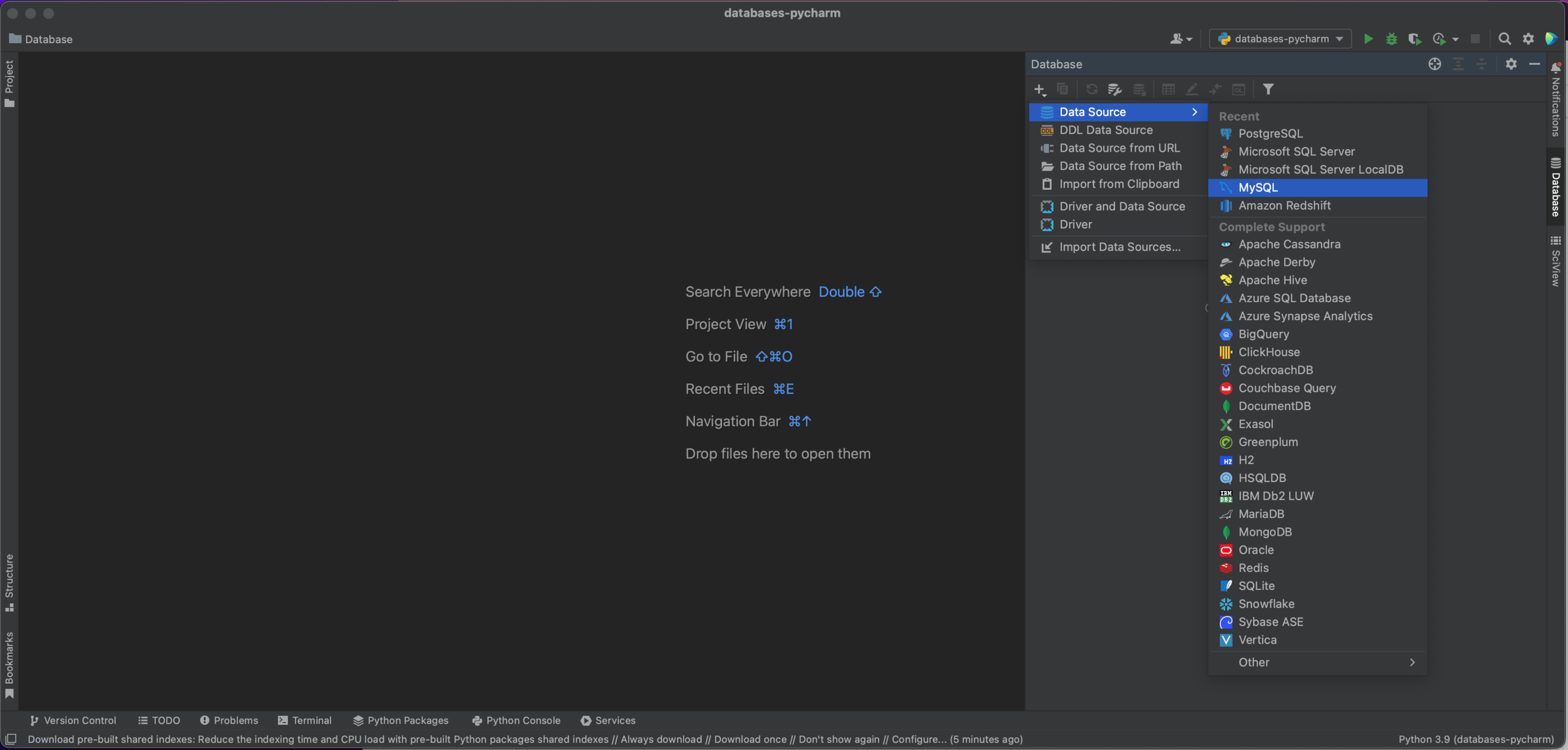
이제 MySQL 데이터베이스로 연결할 수 있는 팝업 창이 나타납니다. 로컬에 호스팅된 데이터베이스를 사용하므로 Host(호스트)를 ‘localhost’로 두고 Port(포트)는 기본 MySQL 포트인 ‘3306’으로 설정합니다. Authentication(인증) 옵션으로 ‘User & Password'(사용자 및 비밀번호)를 사용하고 User(사용자) 및 Password(비밀번호)에 모두 ‘pycharm’을 입력합니다. 마지막으로 Database(데이터베이스) 이름에 ‘demo’를 입력합니다. 물론 사용자의 MySQL 데이터베이스에 연결하려면 특정 호스트, 데이터베이스 이름 및 사용자 이름과 비밀번호를 입력해야 합니다. 연결에 대한 전체 옵션은 문서를 참조하세요.
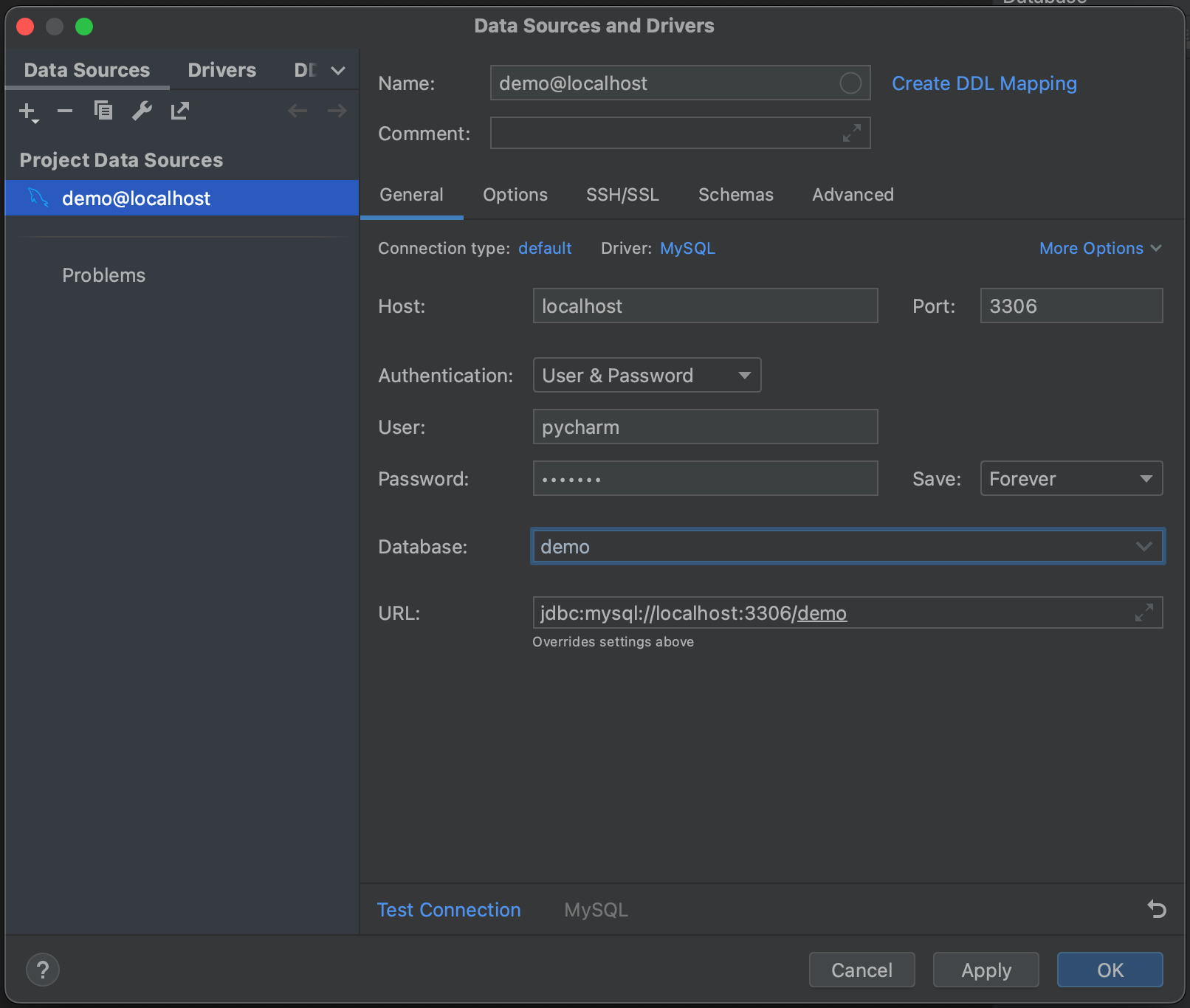
다음으로 Test Connection(연결 테스트)을 클릭하세요. 설치된 드라이버 파일이 없으면 PyCharm이 알려줍니다. Download Driver Files(드라이버 파일 다운로드)를 클릭하세요. Database(데이터베이스) 도구 창의 매우 유용한 기능 중 하나는 올바른 드라이버를 자동으로 찾고 설치해주는 것입니다.
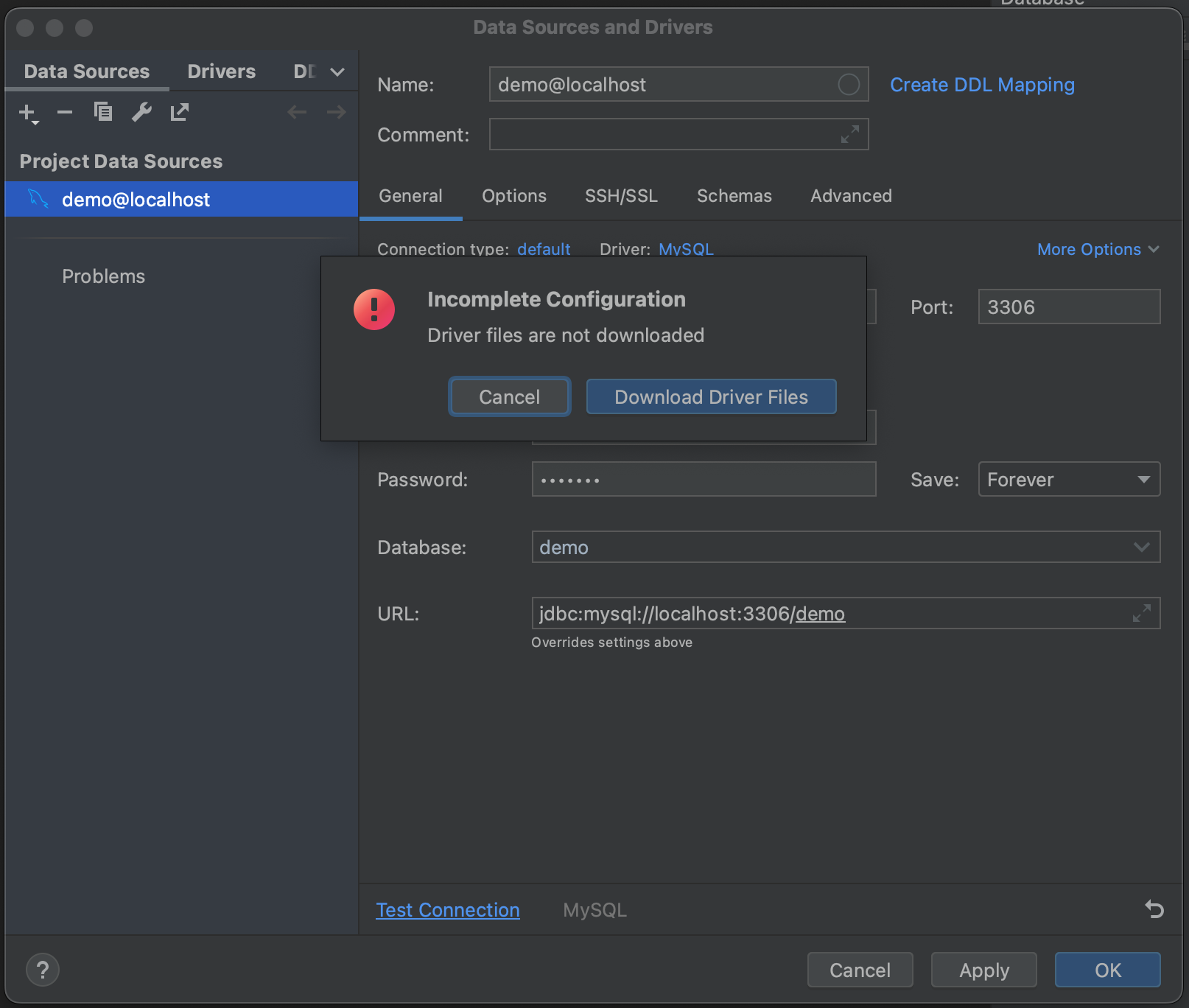
성공했습니다! 이제 데이터베이스에 연결되었습니다. 이제 Schemas(스키마) 탭으로 이동하고 내부 검사를 할 스키마를 선택합니다. 예시 데이터베이스에는 하나의 스키마(‘demo’) 밖에 없지만, 매우 큰 데이터베이스가 여러 개 있는 경우 필요한 데이터베이스에서만 내부 검사를 실행하여 시간을 절약할 수 있습니다.
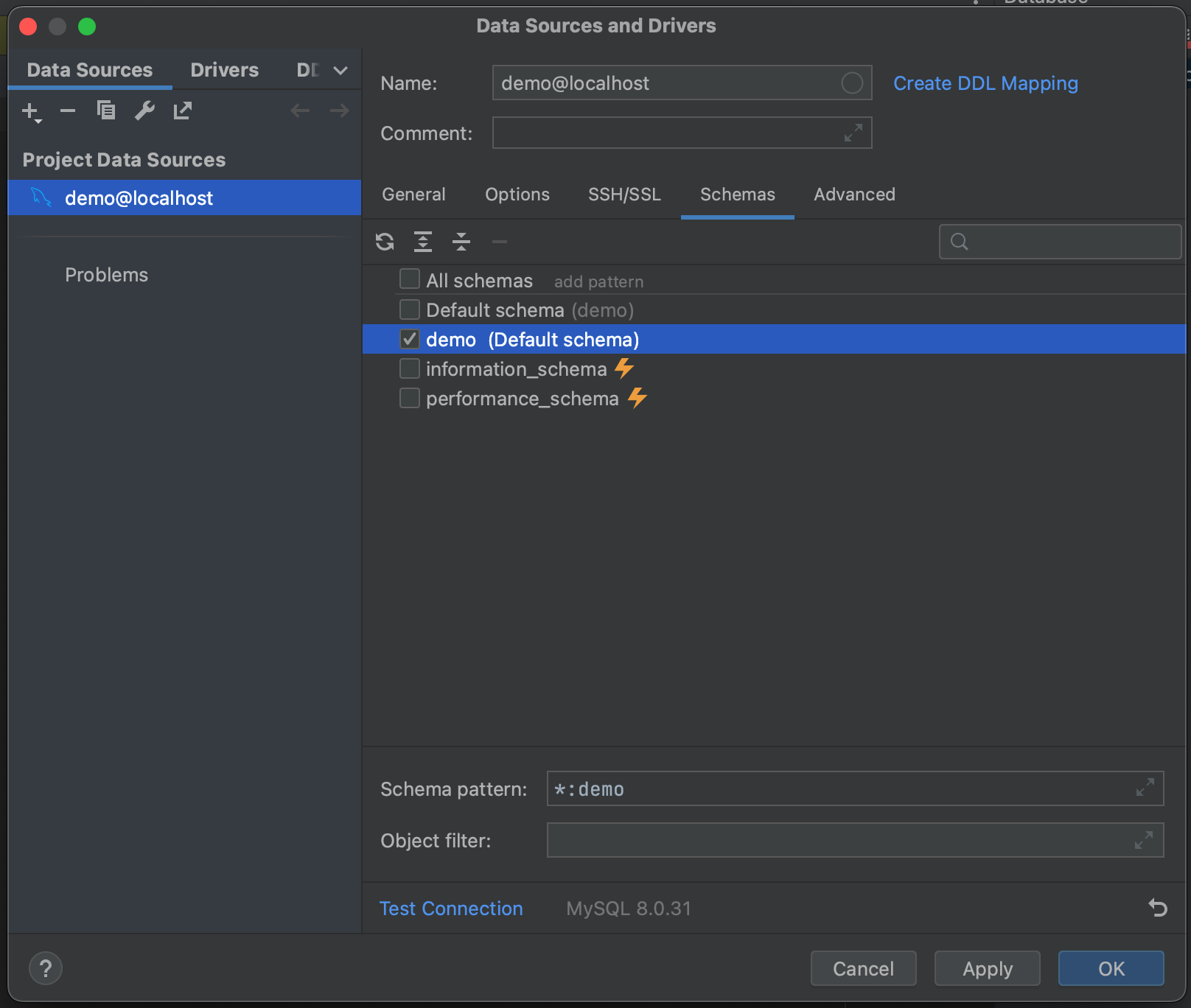
모두 완료되면 데이터베이스에 연결할 준비가 끝납니다. OK(확인)를 누르고 잠시 기다립니다. 이제 전체 데이터베이스에 대한 내부 검사가 테이블 필드 및 타입 수준까지 끝난 것을 확인할 수 있습니다. 이를 통해 쿼리를 실행하기 전에 데이터베이스 안에 무엇이 있는지 전체적으로 볼 수 있습니다.
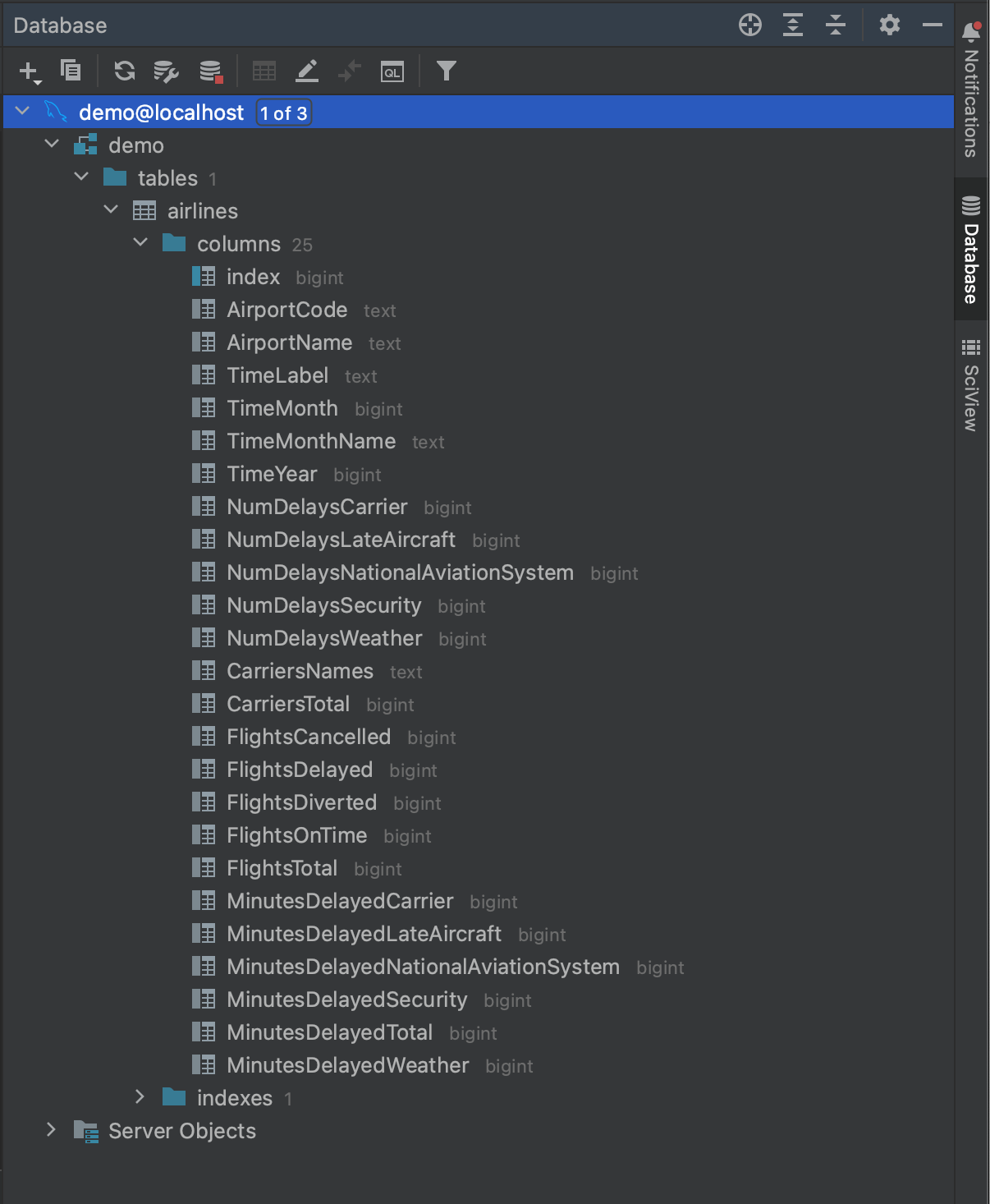
MySQL Connector를 사용하여 데이터 읽기
이제 데이터베이스에 무엇이 있는지 알게 되었으므로 쿼리를 작성할 수 있습니다. 2016년에 최소 500건의 지연이 발생한 공항을 찾는다고 가정해 보겠습니다. 내부 검사된 airlines 테이블의 필드를 보면 다음의 쿼리로 원하는 데이터를 얻을 수 있습니다.
SELECT AirportCode,
SUM(FlightsDelayed) AS TotalDelayed
FROM airlines
WHERE TimeYear = 2016
GROUP BY AirportCode
HAVING SUM(FlightsDelayed) > 500;
Python으로 이 쿼리를 실행하는 첫 번째 방법은 MySQL Connector라는 패키지를 사용하는 것입니다. 이 패키지는 PyPI 혹은 Anaconda에서 설치할 수 있습니다. pip 혹은 conda 환경을 설정하거나 종속성을 설치할 때 도움이 필요하면 링크된 문서를 참조하세요. 설치가 끝나면 새 Jupyter Notebook을 열어 MySQL Connector와 pandas를 모두 가져옵니다.
import mysql.connector import pandas as pd
데이터베이스에서 데이터를 읽으려면 connector를 생성해야 합니다. connect 메서드를 사용하여 생성할 수 있으며, 이를 위해 데이터베이스에 액세스할 때 필요한 자격 증명을 전달합니다(host, database 이름, user 및 password). 이전 섹션에서 Database(데이터베이스) 도구 창을 사용하여 데이터베이스에 액세스할 때 사용한 것과 동일한 자격 증명입니다.
mysql_db_connector = mysql.connector.connect( host="localhost", database="demo", user="pycharm", password="pycharm" )
이제 cursor를 생성해야 합니다. 데이터베이스를 대상으로 SQL 쿼리를 실행할 때 사용되며, connector에 지정된 자격 증명으로 액세스를 획득합니다.
mysql_db_cursor = mysql_db_connector.cursor()
이제 쿼리를 실행할 준비가 되었습니다. cursor의 execute 메서드를 사용하고 쿼리를 인수로 전달하여 실행합니다.
delays_query = """
SELECT AirportCode,
SUM(FlightsDelayed) AS TotalDelayed
FROM airlines
WHERE TimeYear = 2016
GROUP BY AirportCode
HAVING SUM(FlightsDelayed) > 500;
"""
mysql_db_cursor.execute(delays_query)
그런 다음 cursor의 fetchall 메서드를 사용하여 결과를 가져올 수 있습니다.
mysql_delays_list = mysql_db_cursor.fetchall()
그러나 fetchall은 데이터를 목록으로 반환한다는 문제가 있습니다. pandas에 전달하려면, DataFrame으로 전달할 수는 있지만 열 이름이 사라지며 DataFrame을 생성할 때 이름을 수동으로 지정해야 합니다.
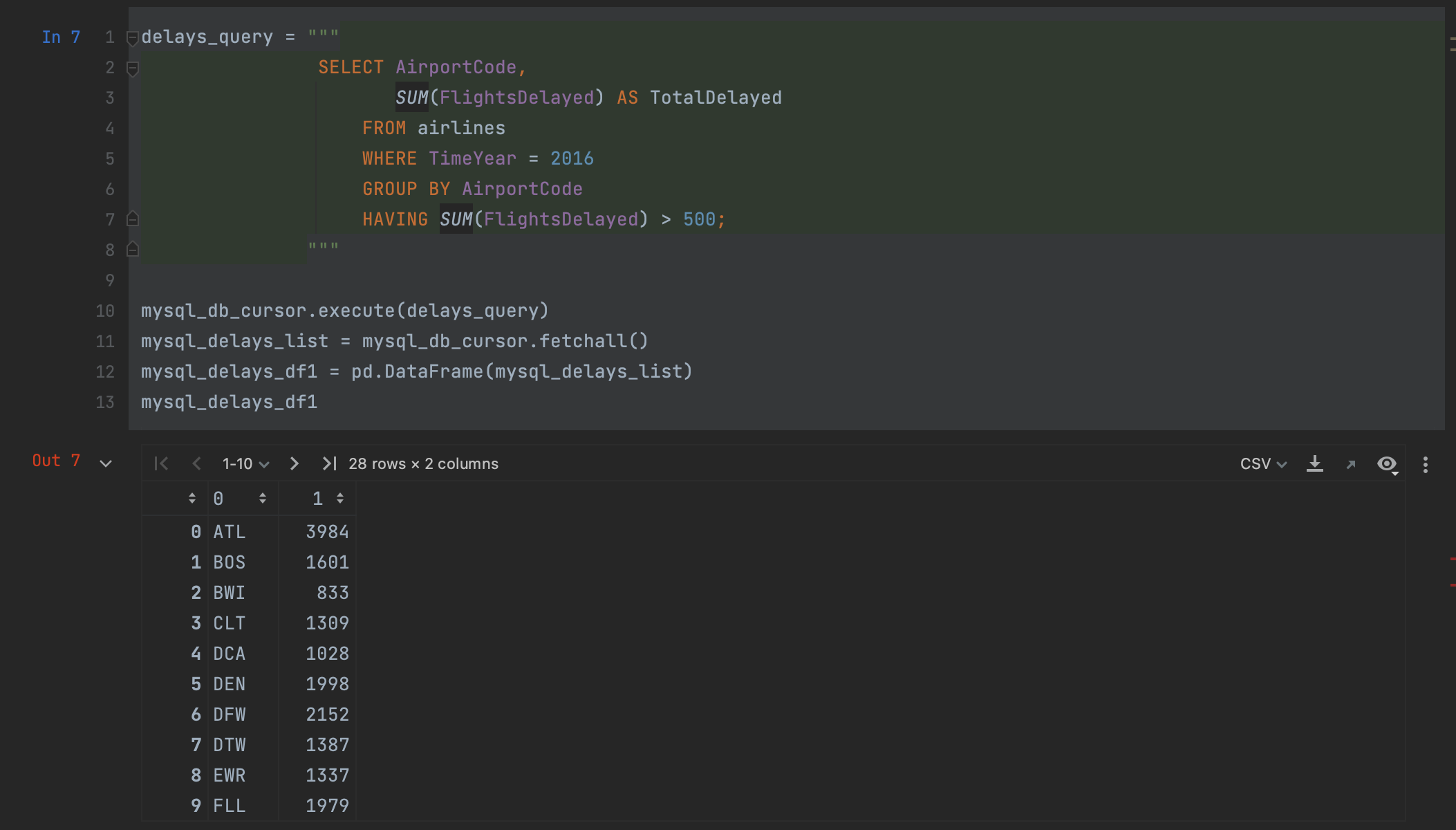
다행히도 pandas에 더 좋은 방법이 있습니다. cursor를 생성하는 대신 read_sql 메서드를 사용하면 한 번의 절차만으로 DataFrame을 대상으로 하는 쿼리를 읽을 수 있습니다.
mysql_delays_df2 = pd.read_sql(delays_query, con=mysql_db_connector)
MySQL 데이터베이스에서 데이터를 읽으려면 간단하게 쿼리와 connector를 인수로 전달하면 됩니다. dataframe을 보면 결과가 위와 완전히 동일하지만 열 이름은 보존된 것을 확인할 수 있습니다.
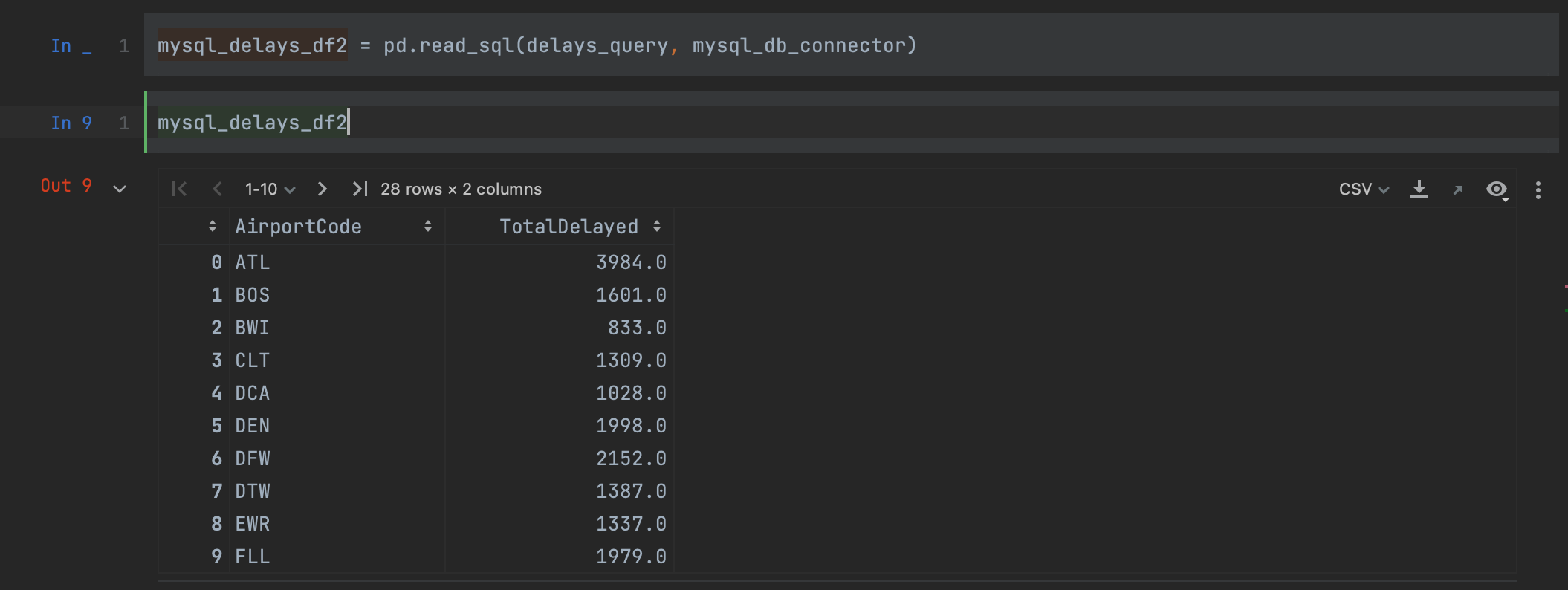
PyCharm의 유용한 기능인 구문 강조 표시가 Python 문자열 내에 포함된 SQL 쿼리에도 적용된 것을 확인할 수 있습니다. 이 블로그 글의 후반에서는 PyCharm으로 SQL 작업을 할 수 있는 다른 방법을 살펴보겠습니다.
SQLAlchemy를 사용하여 데이터 읽기
MySQL Connector의 대안은 SQLAlchemy라는 패키지를 사용하는 것입니다. 이 패키지는 MySQL을 포함한 여러 데이터베이스에 연결하는 만능 메서드를 제공합니다. SQLAlchemy를 사용하면 좋은 점 한 가지는 데이터 타입에 관계없이 쿼리 구문이 일관적이라는 것입니다. 따라서 여러 종류의 데이터베이스로 작업할 때 수많은 명령어를 기억할 필요가 없습니다.
시작하려면 PyPI나 Anaconda에서 SQLAlchemy를 설치해야 합니다. 그런 다음 create_engine 메서드와 pandas를 가져옵니다.
import pandas as pd from sqlalchemy import create_engine
이제 engine을 생성해야 합니다. engine을 이용하면 어떤 SQL 파생 언어를 사용하게 될지(이 경우 MySQL) pandas에 알려줄 수 있고 데이터베이스에 액세스할 때 필요한 자격 증명도 제공할 수 있습니다. 전부 [dialect]://[user]:[password]@[host]/[database]의 형태로 하나의 문자열로 전달됩니다. MySQL 데이터베이스에서는 어떤 모습인지 살펴보겠습니다.
mysql_engine = create_engine("mysql+mysqlconnector://pycharm:pycharm@localhost/demo")
생성되면 read_sql을 다시 사용하기만 하면 됩니다. 이번에는 engine을 con 인수로 전달합니다.
mysql_delays_df3 = pd.read_sql(delays_query, con=mysql_engine)
MySQL Connector로 read_sql을 사용할 때와 결과가 같은 것을 볼 수 있습니다.
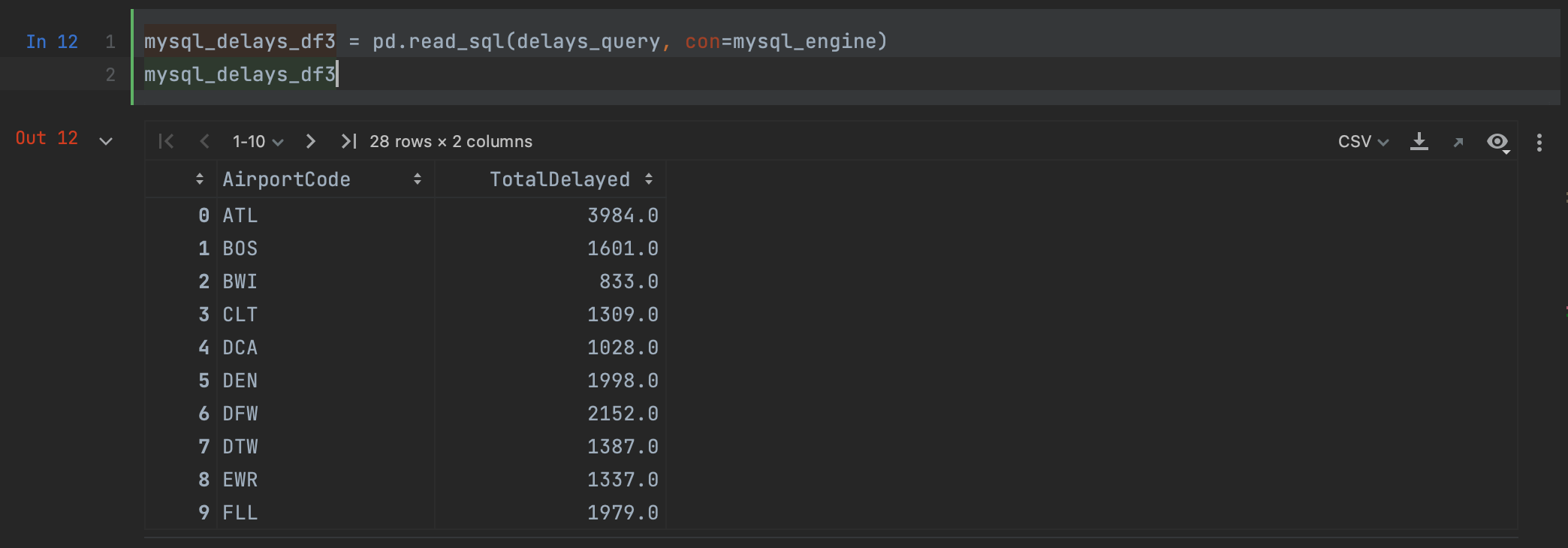
데이터베이스 작업을 위한 고급 옵션
connector 메서드는 명확하게 원하는 쿼리를 추출할 때는 매우 유용합니다. 그렇지만 전체 쿼리를 실행하기 전에 데이터가 어떤 모습일지 미리 보고 싶거나 전체 쿼리가 얼마나 걸릴지 궁금할 때는 어떻게 해야 할까요? PyCharm에는 데이터베이스 작업을 할 때 사용할 수 있는 고급 기능이 있습니다.
Database(데이터베이스) 도구 창으로 돌아가서 데이터베이스를 마우스 오른쪽 버튼으로 클릭하면 New(새로 만들기) 아래에 Query Console(쿼리 콘솔)을 생성할 수 있는 옵션이 보입니다.
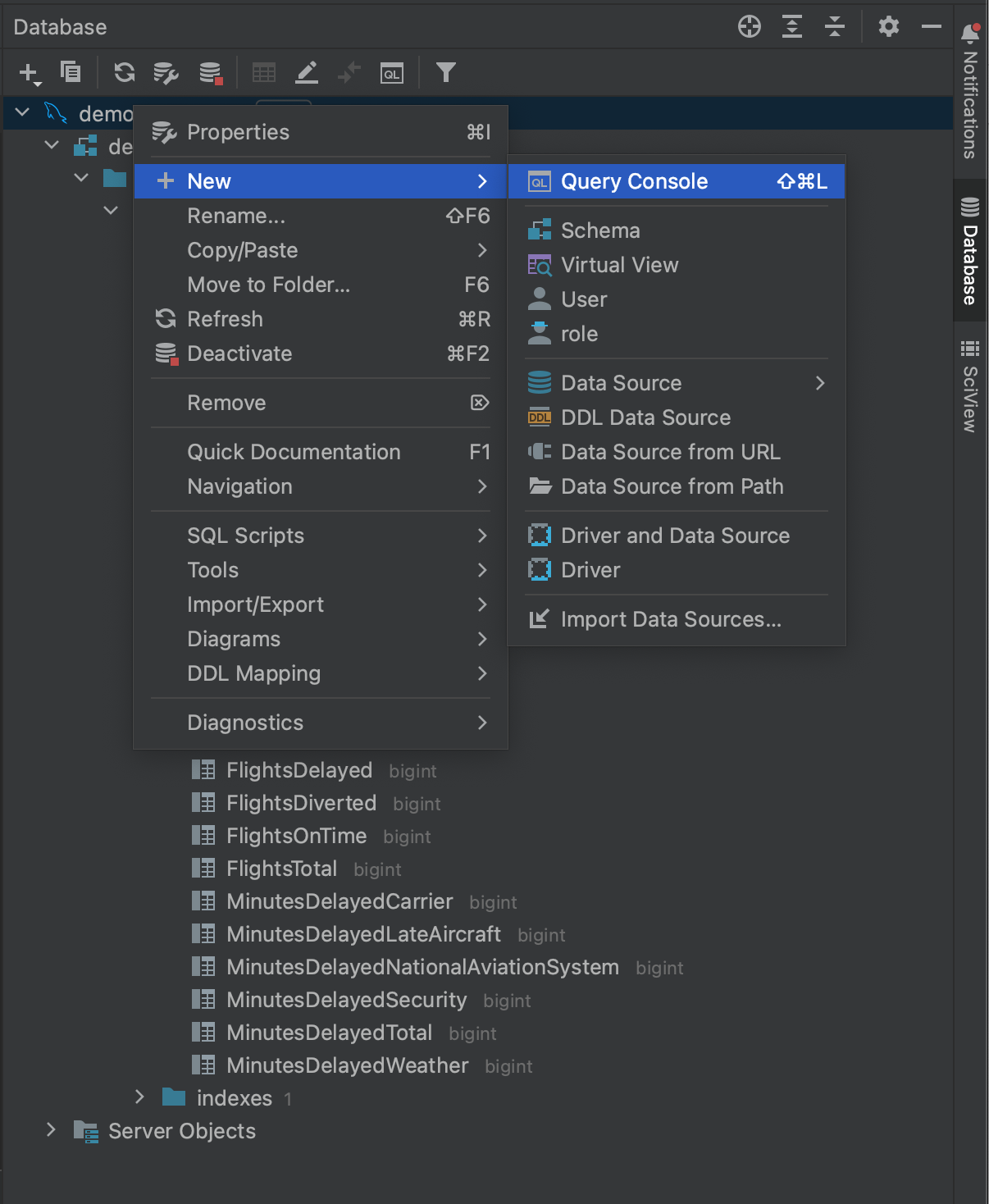
이 옵션을 사용하여 콘솔을 열고 네이티브 SQL로 데이터베이스를 대상으로 하는 쿼리를 사용할 수 있습니다. 콘솔 창에는 SQL 코드 완성 및 내부 검사가 포함되어 있으므로 손쉽게 쿼리를 작성하여 Python connector 패키지에 전달할 수 있습니다.
쿼리를 강조 표시하고 왼쪽 상단 모서리에서 Execute(실행) 버튼을 클릭합니다.
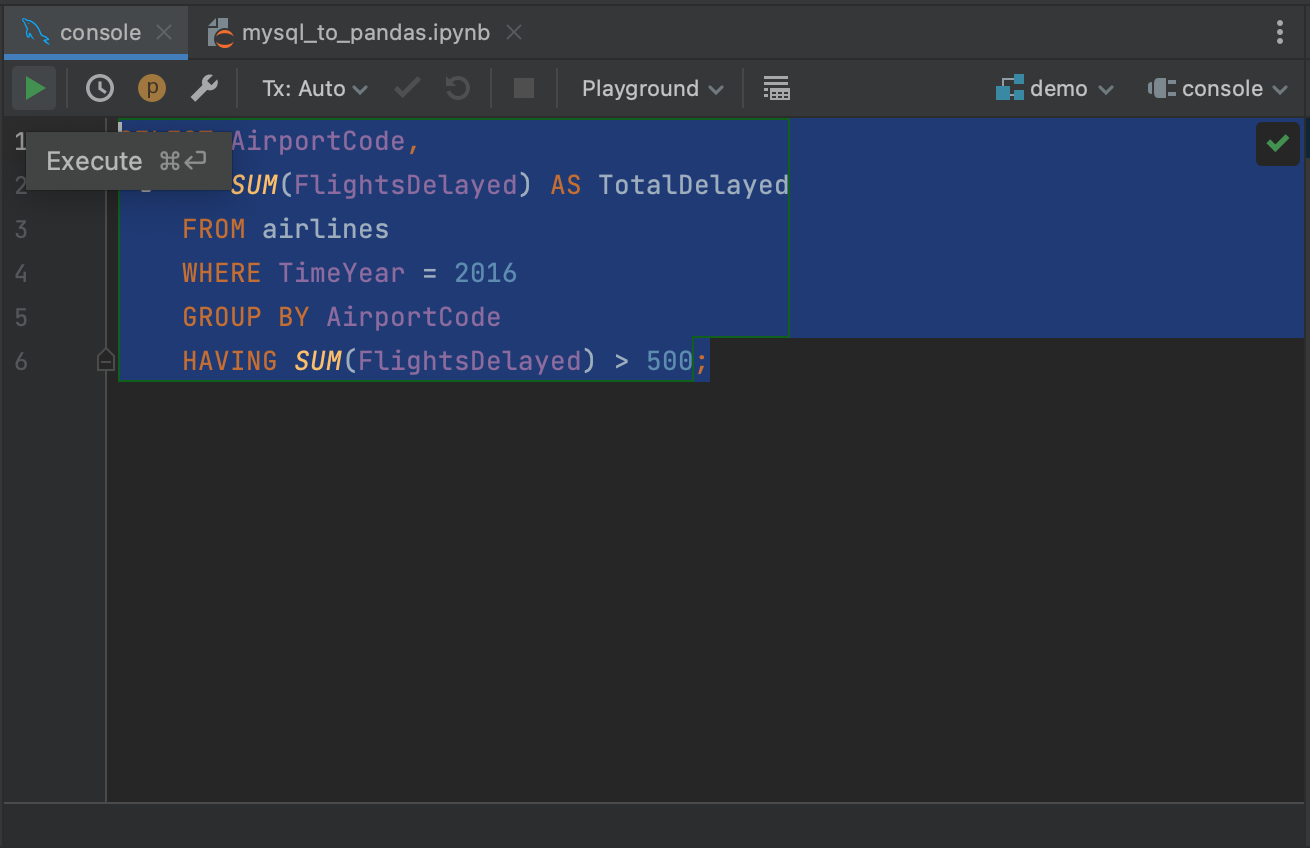
쿼리의 결과는 Services(서비스) 탭에서 확인할 수 있으며 해당 탭에서 결과를 검사하거나 내보낼 수 있습니다. 콘솔에서 쿼리를 실행할 때의 장점은 데이터베이스에서 처음에 첫 500개의 행만 가져온다는 점입니다. 따라서 전체 데이터를 가져오지 않고도 큰 쿼리의 결과가 어떨지 감을 잡을 수 있습니다. 가져오는 행의 수는 Settings/Preferences(설정) | Tools(도구) | Database(데이터베이스) | Data Editor and Viewer(데이터 에디터 및 뷰어)에서 Limit page size to(다음으로 페이지 크기 제한:):의 값을 변경하여 조정할 수 있습니다.
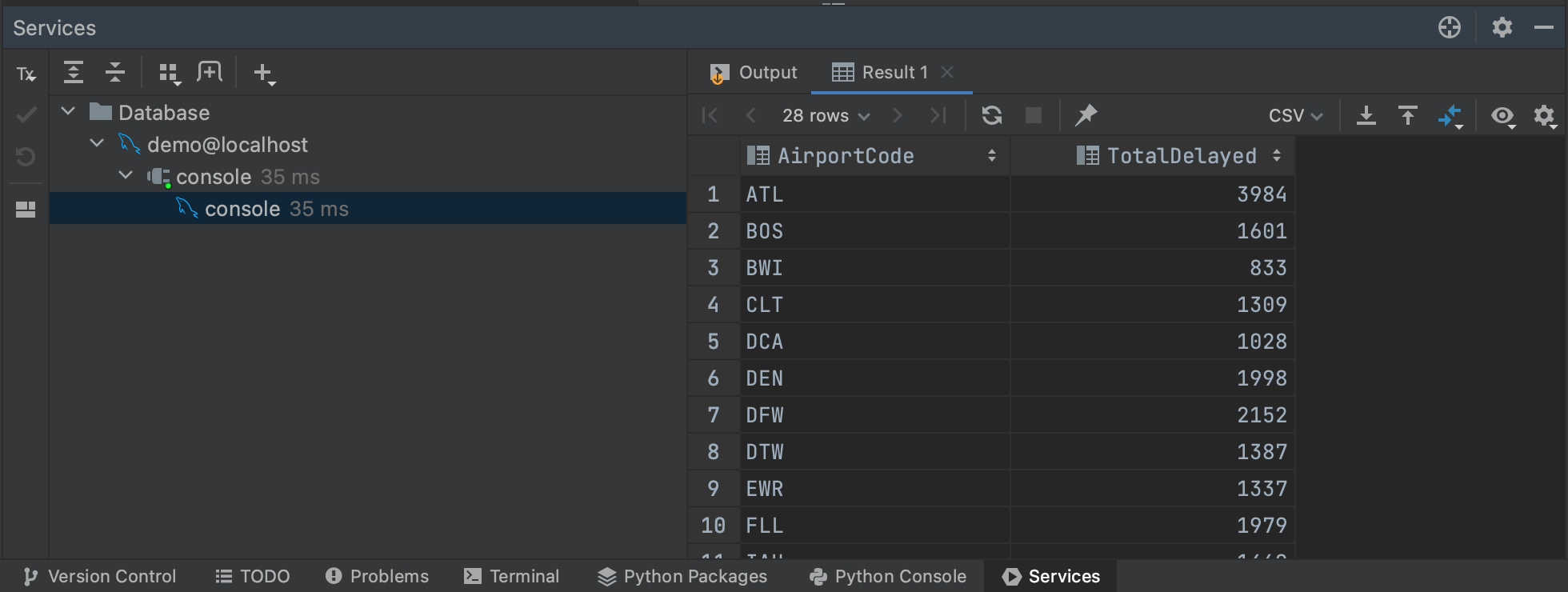
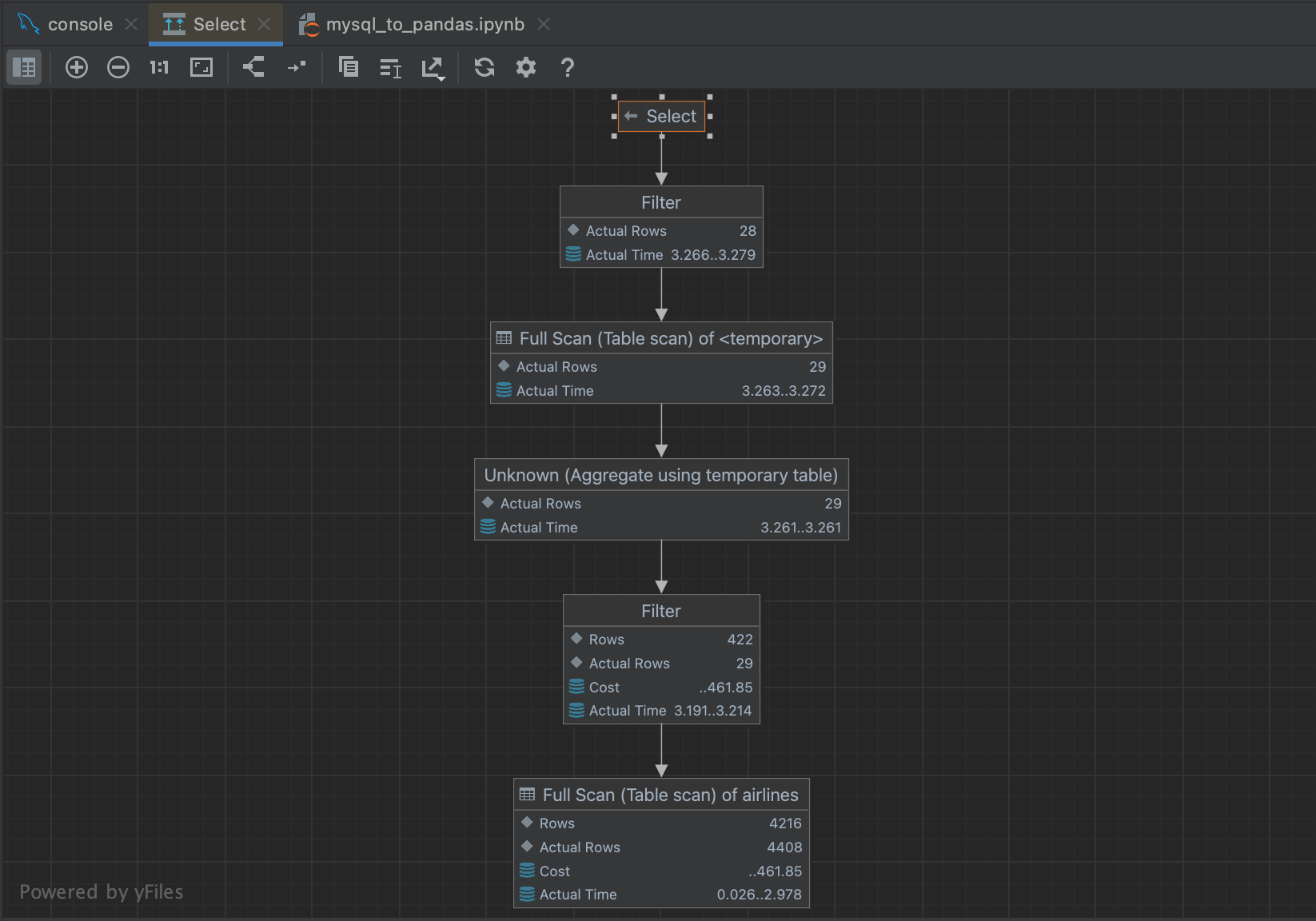
큰 쿼리의 경우 실행 계획을 생성하면 쿼리가 얼마나 걸릴지 대략적으로 알아볼 수 있습니다. 쿼리를 강조 표시하고 마우스 오른쪽 버튼으로 클릭하면 메뉴에서 Explain Plan(계획 설명) | Explain Analyse(분석 설명)를 고를 수 있습니다. 그러면 쿼리의 실행 계획이 생성되어 쿼리 플래너가 결과를 가져오기 위해 취하는 각 단계를 보여줍니다. 실행 플랜은 별개의 주제이므로 계획에 나와 있는 것을 모두 이해할 필요는 없습니다. 현재 목적에서 연관성 있는 열은 각 단계에서 모든 행을 반환하는 데 걸리는 시간을 보여주는 Actual Total Time(실제 총 시간) 열입니다. 이를 통해서 전체 쿼리 시간이 얼마나 걸릴지 예상할 수 있고 쿼리의 어느 부분에서 시간이 많이 걸리는지도 알 수 있습니다.
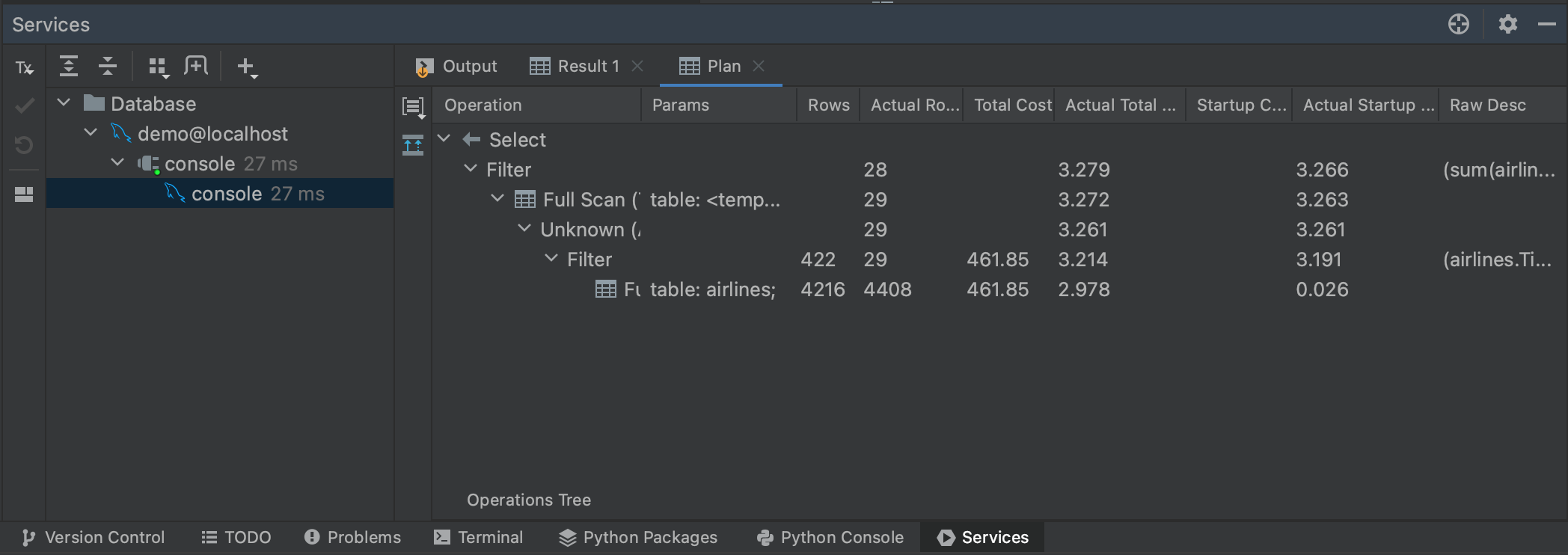
Plan(계획) 패널의 왼쪽에 있는 Show Visualization(시각화 표시)을 눌러 실행을 시각화할 수도 있습니다.
그러면 플로차트가 표시되어 쿼리 플래너가 취하고 있는 단계로 손쉽게 이동할 수 있습니다.
MySQL 데이터베이스에서 pandas DataFrames로 데이터를 가져오는 것은 어렵지 않습니다. 또한 PyCharm에는 MySQL 데이터베이스 작업을 수월하게 도와주는 강력한 도구가 많이 있습니다. 다음 블로그 글에서는 PyCharm을 사용하여 유명한 데이터베이스 타입 중 하나인 PostgreSQL 데이터베이스에서 pandas로 데이터를 읽어오는 방법을 살펴보겠습니다.
게시물 원문 작성자





