

TeamCity
Powerful CI/CD for DevOps-centric teams
Solving Build Server Scalability Issues
Over the last few months, the TeamCity team has been busy boosting the performance and stability of our build server. In this post, I’ll explain what steps we took and share the issues we’ve faced.
First, some numbers
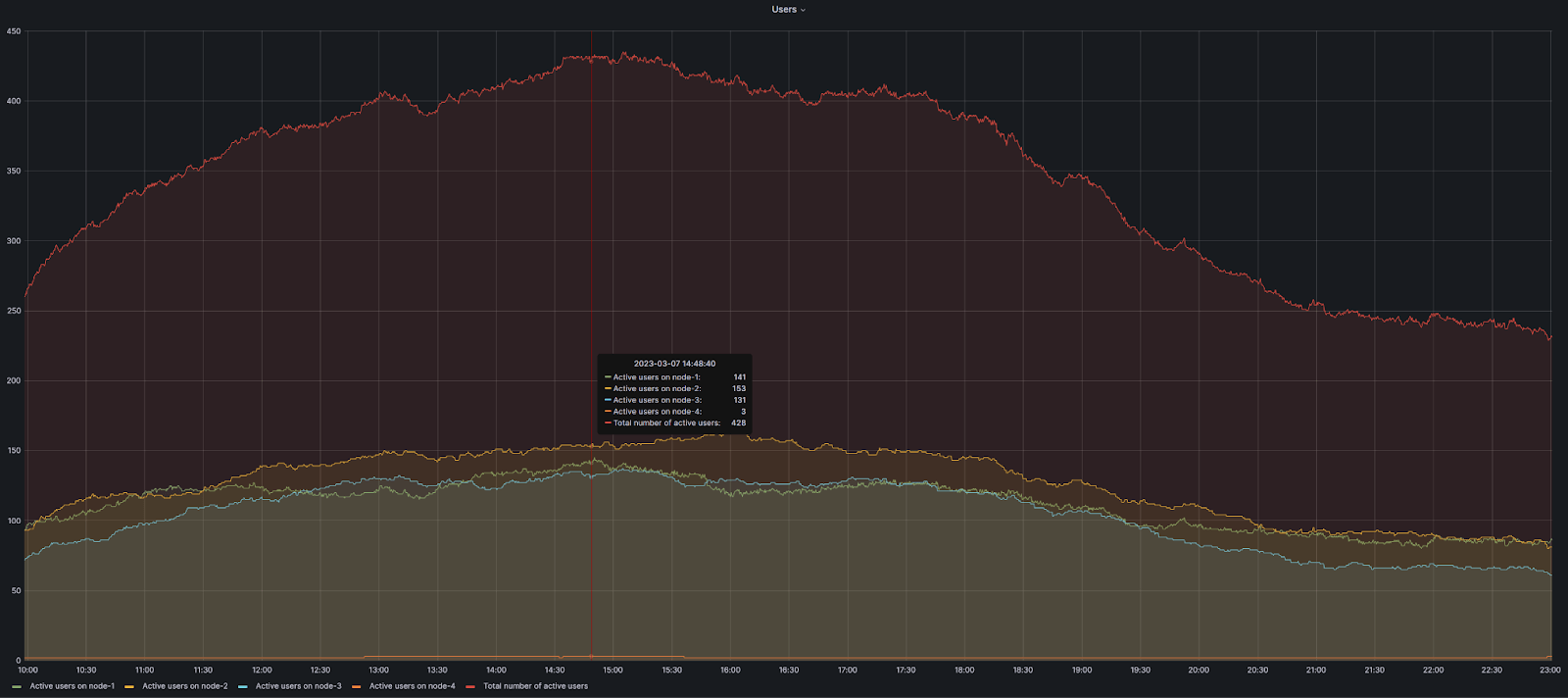
On a typical working day, the load on the build server increases after 14:00 CET and starts to drop after 20:00. This is the rush hour, when the number of queued builds is constantly high. For example, take a look at the statistics from February 22 to March 3:

The steps below played a significant role in making the server stable under this load.
Database hardware upgrade
The cheapest and the most straightforward step was probably upgrading the MySQL database used by the build server. When we initially moved the build server to AWS, we used a MySQL server instance with 16 cores and 64 GB of memory. However, it wasn’t enough to sustain the load. The average CPU load was constantly around 75%, so we switched to a larger machine with 32 cores and 128 GB of memory.
The challenge was to perform this upgrade without server downtime and ideally not over the weekend. We found a way to switch all TeamCity nodes from one database to another at runtime without restarting any nodes. As a result, the migration on the morning of December 5th was smooth and non-disruptive. The average CPU usage dropped to 45%, which will do its part to enhance build server performance.
The 4th node
For almost all of 2022, the build server cluster consisted of 3 nodes. By the end of the year, we decided to add a 4th node. The main reason for this decision was to have extra resources to handle the load when we need to bring down nodes, like for maintenance.
This happens from time to time, and is usually because of bugs. For a critical bug, we restart nodes one by one and apply hotfixes. This means until all nodes are restarted (which can take quite a while), our cluster is down to only 2 nodes which may struggle to sustain the workload our build server is dealing with.
Before the end of 2022, we added the 4th node to the cluster. All 4 TeamCity nodes are identical: 64 cores and 500 GB of RAM for each.
Round robin
A round robin of user sessions across all TeamCity nodes was in development for quite some time. It was launched in 2021 and has progressed at different paces over the last couple years.
While all TeamCity nodes appeared and behaved as regular TeamCity servers, some functionality was still missing. For instance, if a user landed on a secondary node, they would not be able to see agent logs or build process thread dumps.
It took some time to find all of the limitations and eliminate most of them. By mid-2022, we felt confident that secondary nodes would act almost identically to the primary node. At this point, we launched an experiment where a group of volunteers from the TeamCity team started using the secondary node to carry out their daily work.
Several months later, in December 2022, we expanded this round robin for all build server users. This caused some confusion, as some UI features were still unavailable on the secondary nodes, but overall it went well. If you paid close attention, you’d notice this small selector in the footer:
This selector allows you to check your current node and switch to another one. If certain functionality does not work as expected on a secondary node, switch to the primary node-1.
Fixing the event lag
When something important happens with major TeamCity objects (such as builds or projects), the node where the object’s state was changed publishes something called a “multi-node event”. This event is transmitted to all of the other nodes in a cluster. Depending on the event type, these other nodes may update their own in-memory caches and objects.
As time went by, our build server ran more and more concurrent builds, processed bigger build queues, and handled more agents. This resulted in a significant increase in events and revealed bottlenecks and inefficiencies in the code that processes these events, which usually looked like the following:
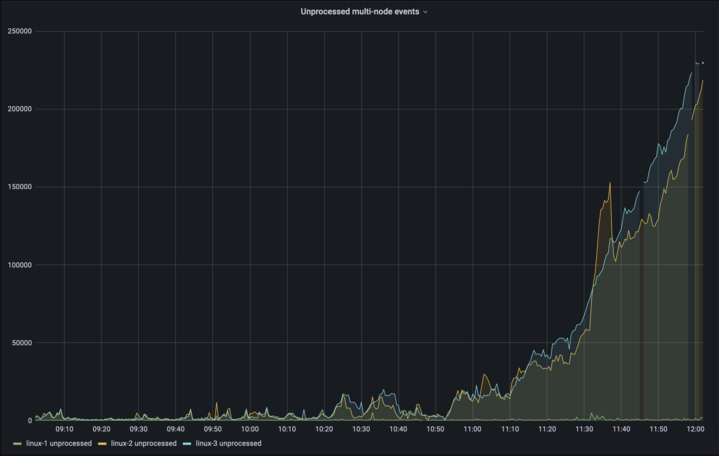
We called it the “event lag”. As you can see in the image above, linux-2 and linux-3 nodes cannot process all of the incoming events in time, and the backlog of unprocessed events grows rapidly. At a certain point, nodes are unable to recover and have to be restarted. The event lag was a critical issue that kept us from routing users to secondary nodes – the secondary nodes would simply miss the most recent data there.
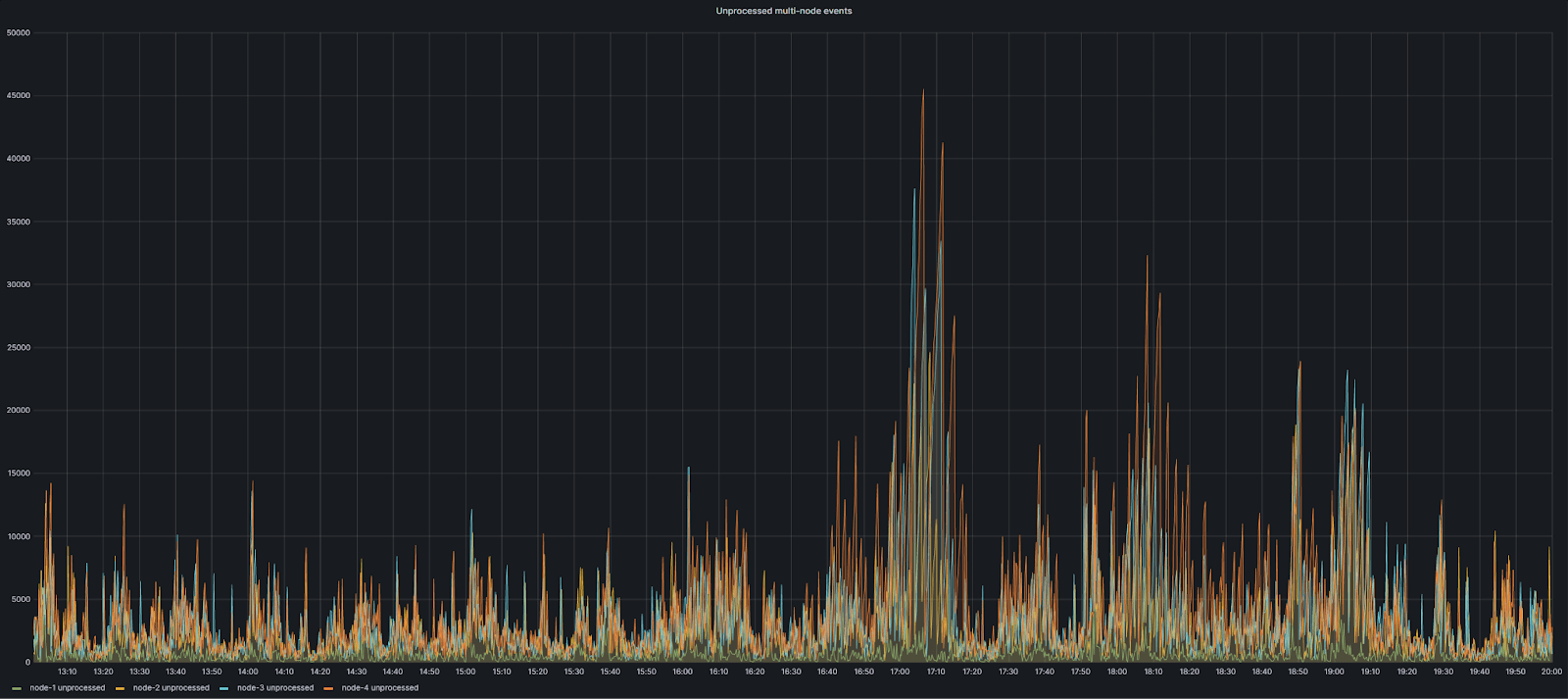
This major issue had no quick and easy fix. Instead, we had to rewrite our code to process most of the events in batches and modify the processing logic for other cases. In the end, we managed to resolve this problem. Now, even a hot day on a TeamCity build server looks like this:
Improving build queue processing performance
The TeamCity build queue bottleneck was previously described in this blog post.
We’ve managed to solve most of the issues mentioned there. Since then, the queue processing algorithm has become more parallel, and we’ve improved its performance even further. TeamCity can now process 20k builds in the queue without significant delays. The time required to process a queue this large is still 2-3 minutes, but the previous time was much higher than that.
Despite the progress that has been made, we’re not calling it a day yet. We will keep looking for a way to further speed up the queue processing.
Change collecting on multiple nodes
Previously, we had a dedicated node (node-3) to perform all “change collecting” operations whether they were caused by a commit hook, regular VCS polling, or the start of a build.
As a result, this node was sometimes overloaded with all of the requests to collect changes in different VCS roots, especially when many large build chains were triggered simultaneously.

In mid-February 2023, we enabled an experimental mode in which “change collecting” operations can be performed by any node in the cluster in parallel, as long as the single VCS root is being processed by one node only. This mode should improve throughput for such operations, reduce delays, and allow us to restart the nodes more easily if necessary.
What’s in the lab?
We’ve been cooking up a few more enhancements for quite some time now. Here they are at a glance:
Build log service
Occasionally, build logs get corrupted. We’re fairly certain that this happens when multiple nodes update the same build log. Despite our best efforts to set these updates aside across the running build lifetime, it still happens. To tackle this issue, we’re preparing a dedicated service. Instead of updating build logs directly, all nodes will send change requests to this service, eliminating the issue and ensuring there’s only one log writer.
Central repository for all configuration files
TeamCity keeps configuration files of all the projects on disk. This location is shared with all the nodes via a network file system. However, only one node can perform direct modifications of the files on disk. Other nodes need to send a request in order to perform any modifications.
When a project is modified and its configuration files are updated, a multi-node event fires to let other nodes know they should reload this project’s settings from the disk. While this approach works most of the time, it has obvious flaws. For instance, the project may be modified further while nodes are reloading it from the disk.
As a result, the nodes may get an inconsistent view of the project settings. We perform re-tries to work around this issue, but it’s still a workaround rather than a solid solution. This issue is probably one of the reasons why you sometimes see messages in the header saying “Critical errors in configuration files”.
To fix this problem, we want to move all of the configuration files to a Git repository. Then multi-node events will be able to send hashes of the VCS commits, which should improve the atomicity and precision of the reload operations.
In the longer term, we’ll be able to remove configuration files from the shared disk, thus making us less dependent on network storage.
Happy building!




