

时间序列中的异常检测


如何识别数据中可能揭示关键问题或隐藏机遇的异常模式? 异常检测有助于识别严重偏离常规的数据。 时间序列数据由一段时间内收集的数据组成,通常包括趋势和季节性模式。 当模式被打乱时,时间序列数据中就会出现异常,异常检测也因此成为销售、金融、制造和医疗等行业的重要工具。
由于时间序列数据具有季节性和趋势等特征,需要专门的方法来有效检测异常。 在这篇博文中,我们将探讨一些流行的时间序列异常检测方法,包括 STL 分解和 LSTM 预测,并提供详细的代码示例帮助您入门。
企业中的时间序列异常检测
时间序列数据对许多企业和服务至关重要。 许多企业使用时间戳记录一段时间内的数据,由此分析变化和比较一段时间内的数据。 时间序列在比较一定时段内的一定数量时很有用,例如,在数据表现出季节性特征的同比比较中。
销售监测
销售数据是带有季节性特征的时间序列数据的最常见示例之一。 许多销售额会受到年度假期和年中时间的影响,因此如果不考虑季节性因素,就很难得出有关销售数据的结论。 分析和查找销售数据异常的常用方法是 STL 分解,我们将在这篇博文的后续部分详细介绍。
金融
交易和股票价格等金融数据是时间序列数据的典型示例。 在金融行业,分析和检测这些数据中的异常是一种常见做法。 例如,时间序列预测模型可用于自动交易。 在这篇博文的后续部分,我们将使用时间序列预测识别股票数据中的异常。
制造业
时间序列异常检测的另一个用例是监测生产线中的缺陷。 机器通常受到监控,提供时间序列数据。 将潜在故障告知管理层至关重要,而异常检测发挥着关键作用。
医学和医疗
在医学和医疗领域,人体生命体征受到监测,异常会被检出。 这在医学研究中已经相当重要,但对诊断来说则是必不可少。 如果医院中的患者生命体征出现异常但没有得到及时治疗,后果可能是致命的。
为什么应该使用特殊方法进行时间序列异常检测?
时间序列数据的特殊之处在于,它有时不能像其他类型的数据那样处理。 例如,当我们将训练测试分割应用于时间序列数据时,数据的顺序相关性质意味着我们无法对其进行重排。 将时间序列数据应用于深度学习模型时也是这样。 通常使用循环神经网络 (RNN) 考虑顺序关系,将训练数据作为时间窗口输入,保留其中事件的顺序。
时间序列数据的特殊性还在于,它通常具有我们无法忽视的季节性和趋势。 常见的季节性可以表现为 24 小时周期、7 天周期或 12 个月周期等。 只有考虑到季节性和趋势之后才能确定异常,如以下示例所示。
用于时间序列异常检测的方法
由于时间序列数据的特殊性,可以通过特殊方法检测其中的异常。 根据数据类型,我们在上一篇关于异常检测的博文中提到的一些方法和算法也可用于时间序列数据。 不过,使用这些方法,异常检测的稳健性可能不如专为时间序列数据设计的方法。 在某些情况下,可以结合采用多种检测方法重新确认检测结果,避免误报或漏报。
STL 分解
处理具有季节性的时间序列数据的最流行方式之一是 STL 分解 – 使用 LOESS(局部估计散点图平滑)进行季节性趋势分解。 这种方法使用季节性估计(提供或使用算法确定时段)、趋势(估计)和残差(数据中的噪声)分解时间序列。 提供 STL 分解工具的 Python 库是 statsmodels 库。
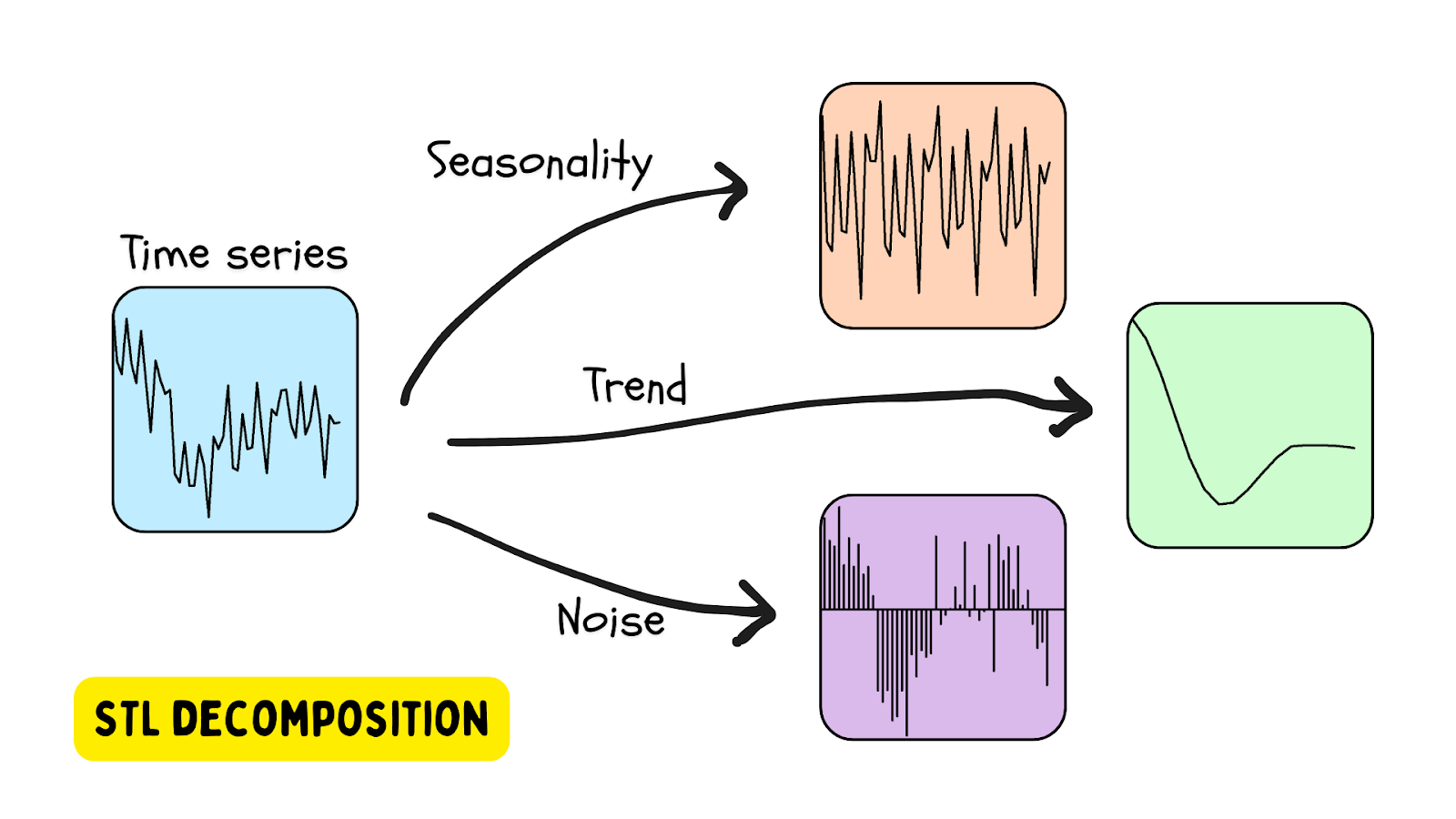
当残差超过某个阈值时,就会检测到异常。
在蜂巢数据上使用 STL 分解
在之前的博文中,我们使用 OneClassSVM 和 IsolationForest 方法探究了蜂巢中的异常检测。
在本教程中,我们将使用 statsmodels 库提供的 STL 类将蜂巢数据作为时间序列进行分析。 首先,使用此文件设置环境:requirements.txt。
1. 安装库
由于我们只使用 Scikit-learn 提供的模型,我们需要从 PyPI 安装 statsmodels。 在 PyCharm 中这很容易。
转到 Python Package(Python 软件包)窗口(选择 IDE 左侧底部的图标),在搜索框中输入 statsmodels。
您可以在右侧看到软件包的所有信息。 要安装,只需点击 Install package(安装软件包)。
2. 创建 Jupyter Notebook
为了进一步研究数据集,我们创建一个 Jupyter Notebook,利用 PyCharm 的 Jupyter Notebook 环境提供的工具。
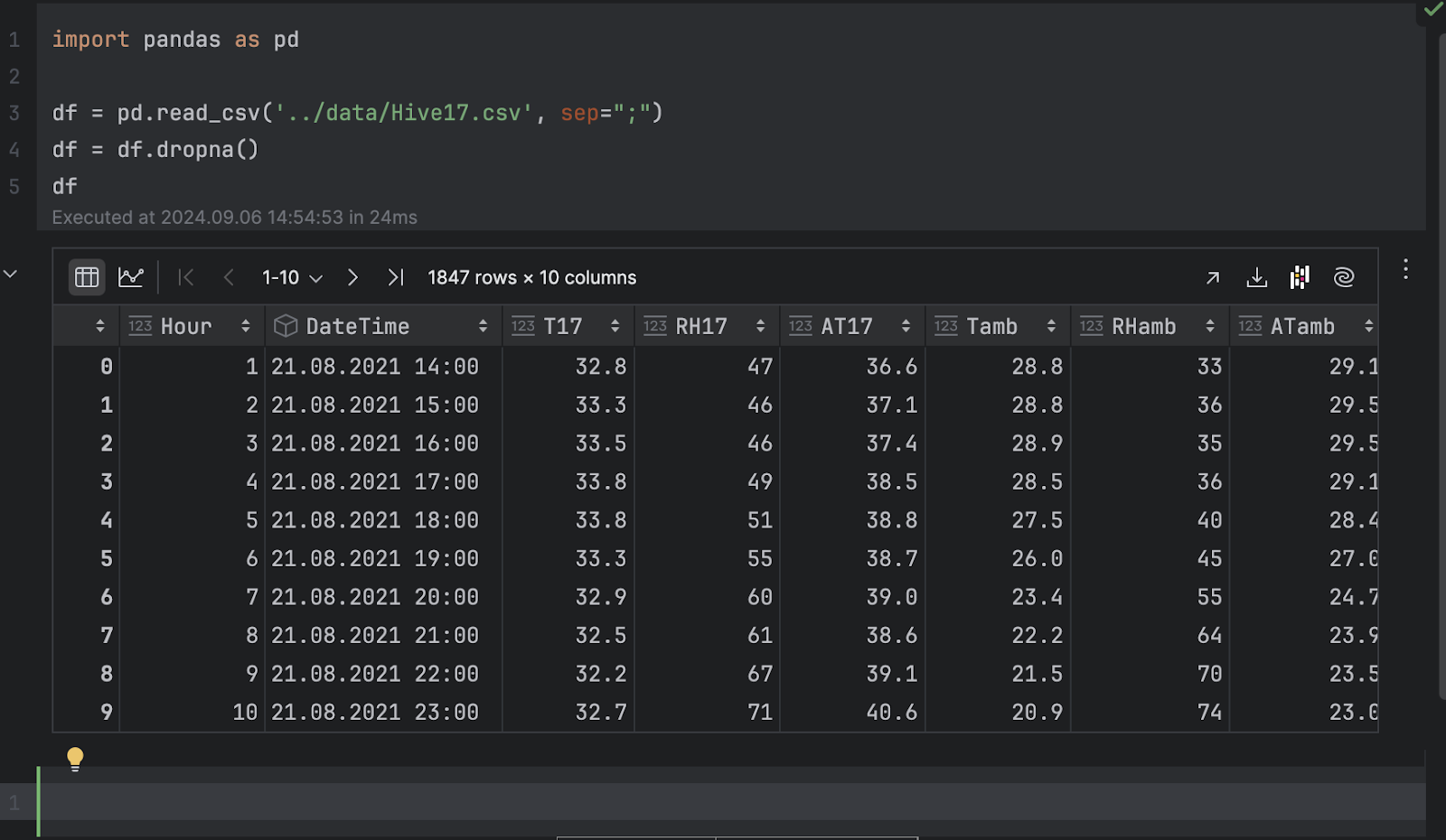
我们将导入 pandas 并加载 .csv 文件。
import pandas as pd
df = pd.read_csv('../data/Hive17.csv', sep=";")
df = df.dropna()
df
3. 以图形形式检查数据
现在,我们能够以图形形式检查数据。 在这里,我们想查看蜂巢 17 的温度在一段时间内的变化。 在 DataFrame 检查器中点击 Chart view(图表视图),然后在序列设置中选择 T17 作为 y 轴。
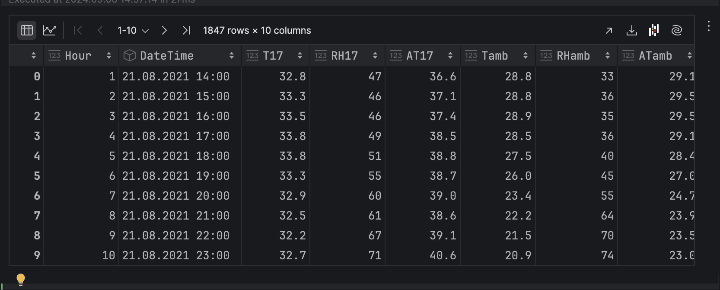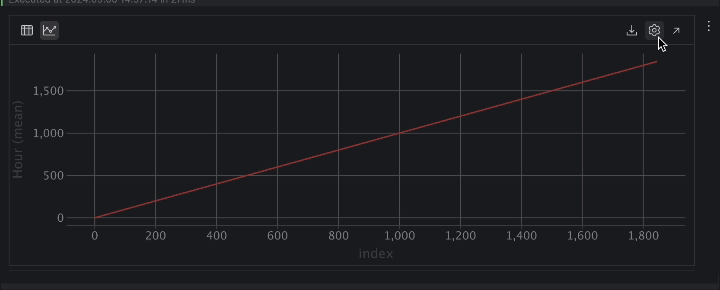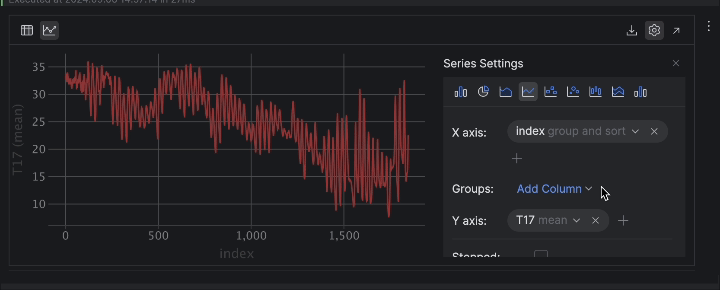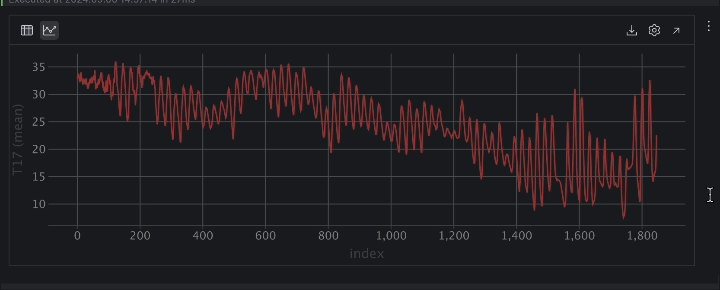
使用时间序列表示时,温度有很多起伏。 这表明行为具有周期性,很可能是由于昼夜循环,因此可以安全假设温度有一个 24 小时的周期。
其次,温度随时间推移呈下降趋势。 如果您检查 DateTime 列,可以看到从 8 月到 11 月的日期范围。 由于数据集的 Kaggle 页面表明数据是在土耳其收集,从夏季到秋季的过渡可以解释我们观察到的温度随时间下降的现象。
4. 时间序列分解
为了理解时间序列和检测异常,我们将执行 STL 分解,从 statsmodels 导入 STL 类并使用我们的温度数据进行拟合。
from statsmodels.tsa.seasonal import STL stl = STL(df["T17"], period=24, robust=True) result = stl.fit()
我们必须提供一个时段才能使分解发挥作用。 如前所述,可以安全假设一个 24 小时的周期。
根据文档,STL 将时间序列分解为三个部分:趋势、季节和残差。 为了更清楚地查看分解结果,我们可以使用内置的 plot 方法:
result.plot()
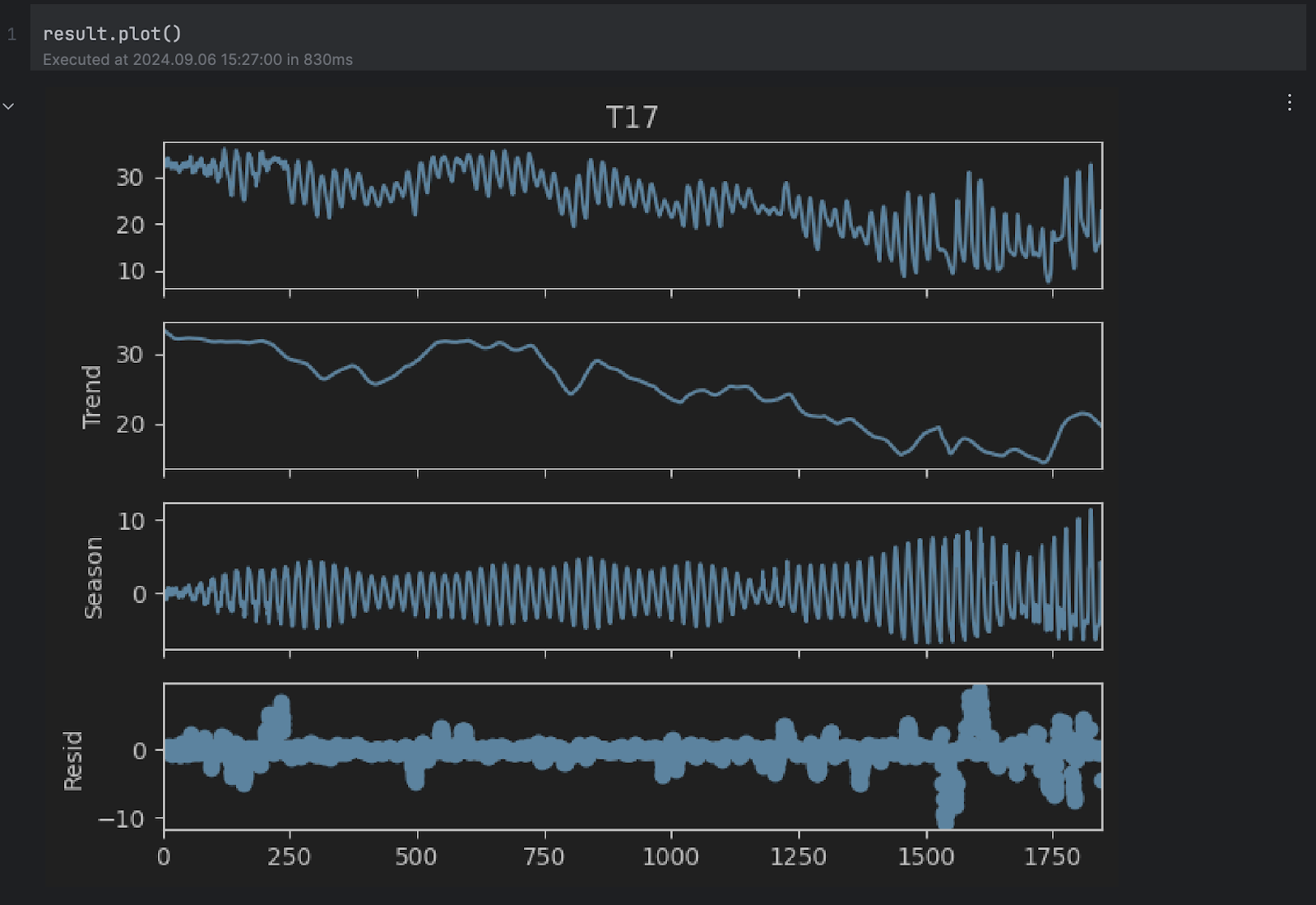
您可以看到 Trend(趋势)和 Season(季节)图似乎与上面的假设一致。 不过,我们感兴趣的是底部的残差图,即没有趋势和季节变化的原始序列。 残差中任何极高或极低的值都表示异常。
5. 异常阈值
接下来,我们要确定残差的哪些值是异常。 为此,我们可以看残差直方图。
result.resid.plot.hist()
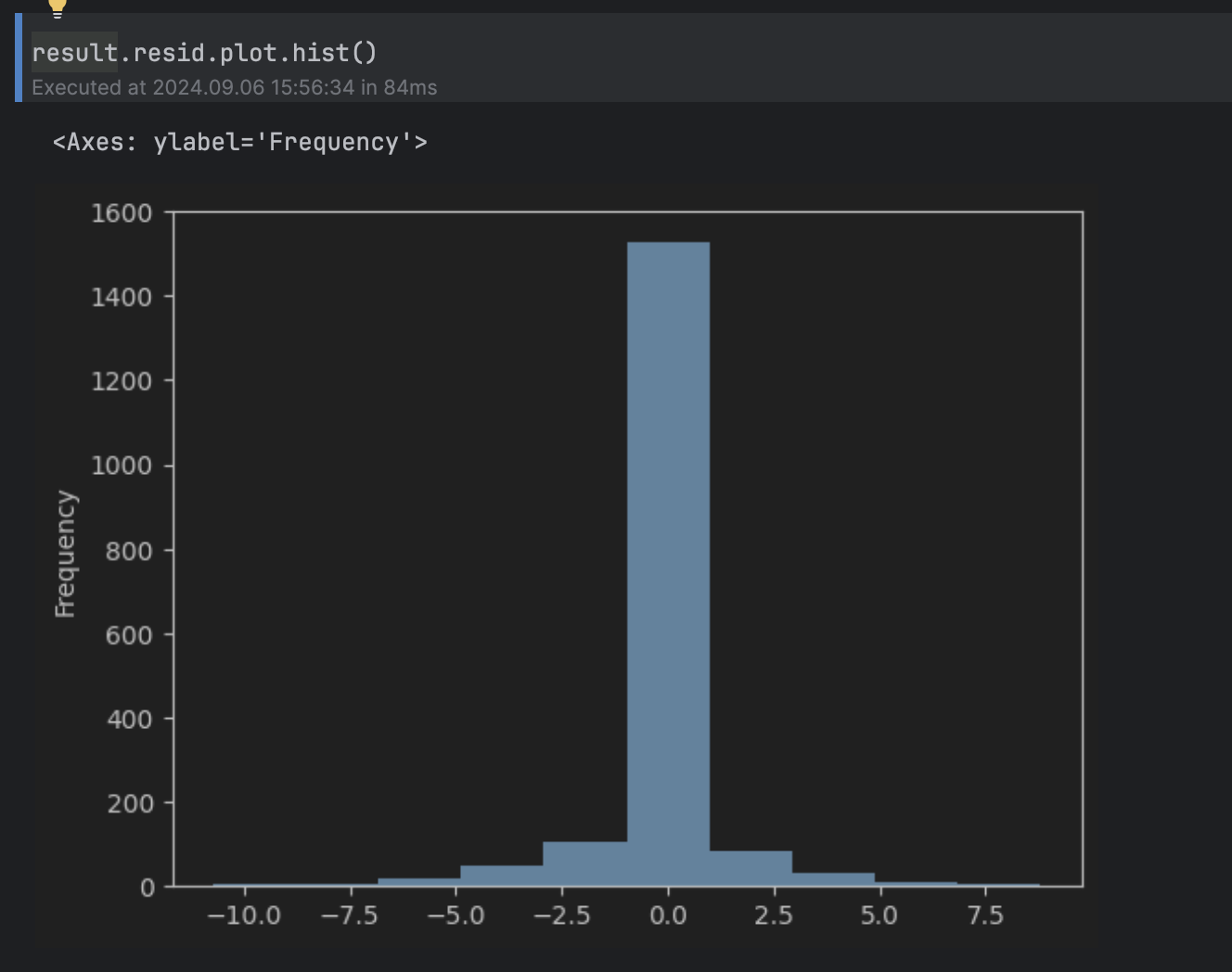
这可以被视为围绕 0 的正态分布,在 5 以上和 -5 以下有长尾,因此我们将阈值设为 5。
为了显示原始时间序列上的异常,我们可以在图形中将它们全部标成红色,如下所示:
import matplotlib.pyplot as plt
threshold = 5
anomalies_filter = result.resid.apply(lambda x: True if abs(x) > threshold else False)
anomalies = df["T17"][anomalies_filter]
plt.figure(figsize=(14, 8))
plt.scatter(x=anomalies.index, y=anomalies, color="red", label="anomalies")
plt.plot(df.index, df['T17'], color='blue')
plt.title('Temperatures in Hive 17')
plt.xlabel('Hours')
plt.ylabel('Temperature')
plt.legend()
plt.show()
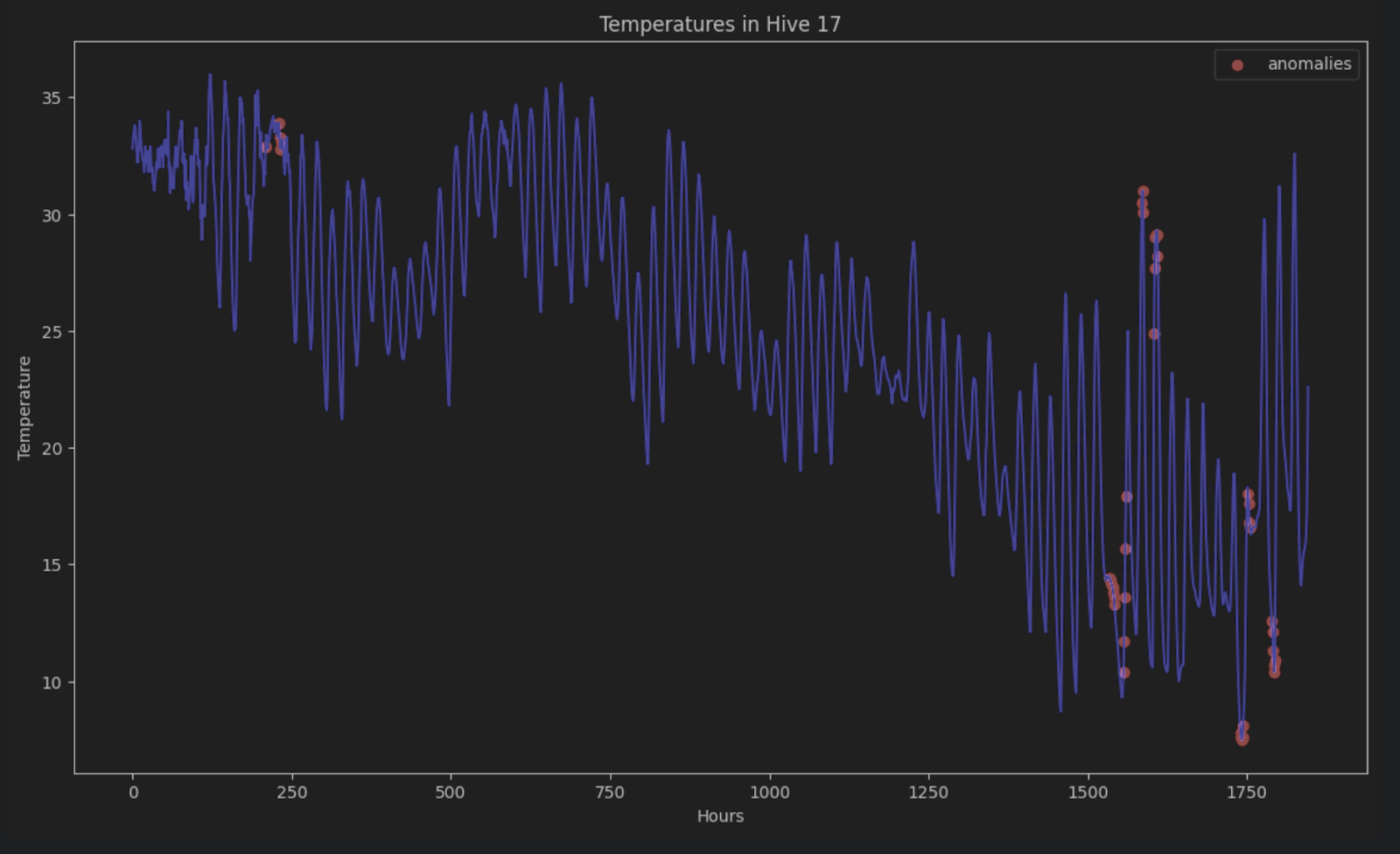
如果没有 STL 分解,就很难在由时段和趋势组成的时间序列中识别这些异常。
LSTM 预测
检测时间序列数据异常的另一种方式是使用深度学习方法对序列进行时间序列预测,估计数据点的结果。 如果估计值与实际数据点相差很大,那么这可能就是异常数据的迹象。
执行序列数据预测的流行深度学习算法之一是长短期记忆 (LSTM) 模型,它是一种循环神经网络 (RNN)。 LSTM 模型具有输入门、遗忘门和输出门,它们是数字矩阵。 这将确保重要信息在数据的下一次迭代中得到传递。
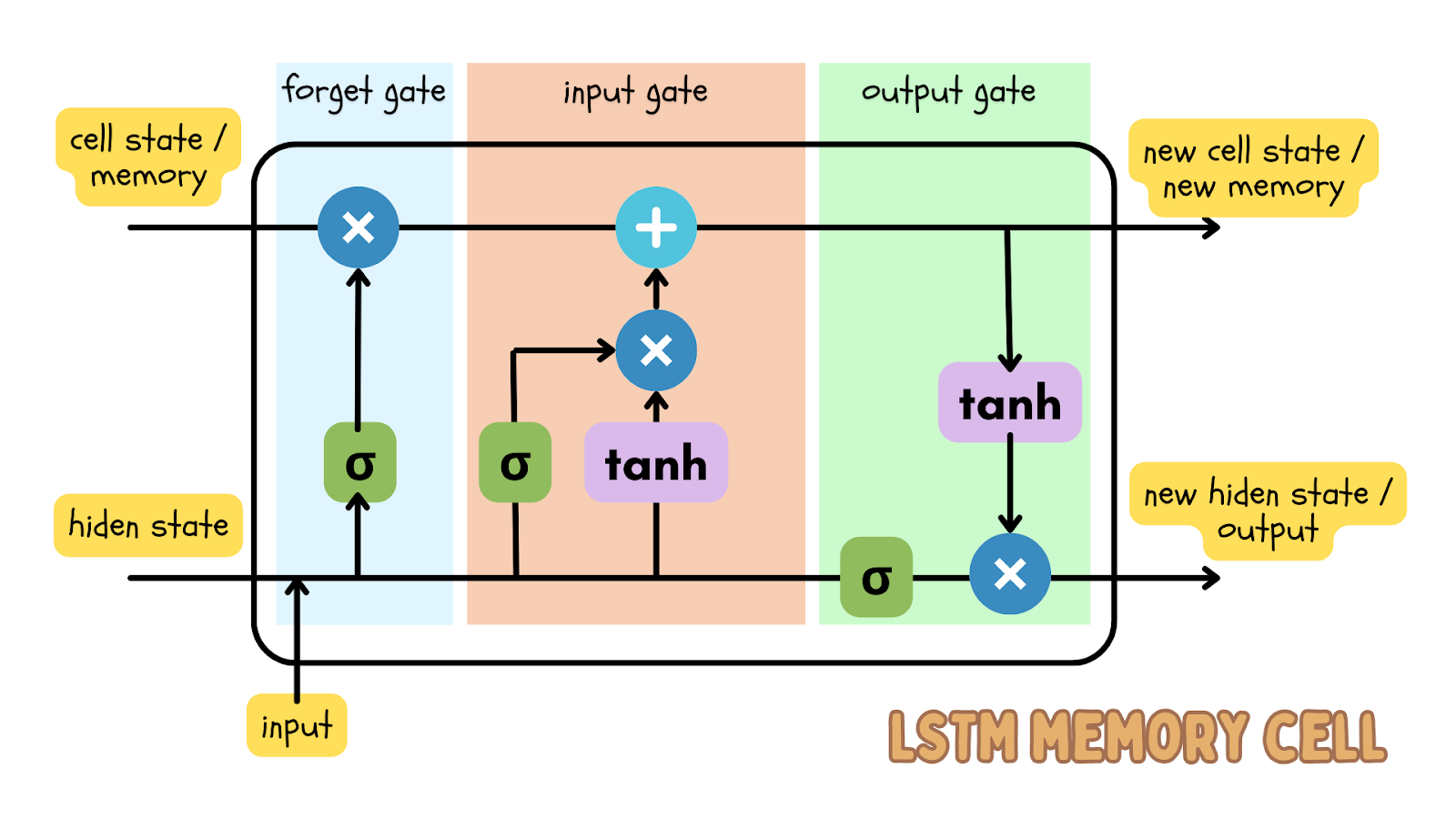
由于时间序列数据是顺序数据,即数据点的顺序是连续的且不应该被重排,LSTM 模型是预测特定时间的结果的有效深度学习模型。 这一预测可以与实际数据进行比较,由阈值确定实际数据是否异常。
对股票价格使用 LSTM 预测
现在,我们开始一个新的 Jupyter 项目,检测过去 5 年 Apple 股价的异常。 股票价格数据集显示的是最新数据。 如果您想跟随博文操作,可以下载我们使用的数据集。
1. 开始一个 Jupyter 项目
开始新项目时,您可以选择创建一个针对数据科学优化的 Jupyter 项目。 在 New Project(新建项目)窗口中,您可以创建一个 Git 仓库并确定使用哪个 conda 安装来管理环境。
开始项目后,您将看到一个示例 Notebook。 为本练习新建一个 Jupyter Notebook。
然后,设置 requirements.txt。 我们需要 pandas、matplotlib 和 PyTorch(在 PyPI 上名为 torch)。 由于 conda 环境中不包含 PyTorch,PyCharm 会告诉我们缺少软件包。 要安装软件包,点击灯泡并选择 Install all missing packages(安装所有缺失的软件包)。
2. 加载和检查数据
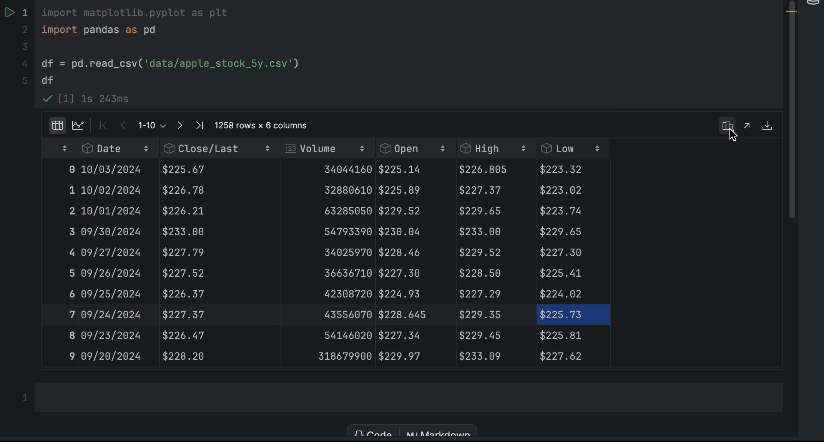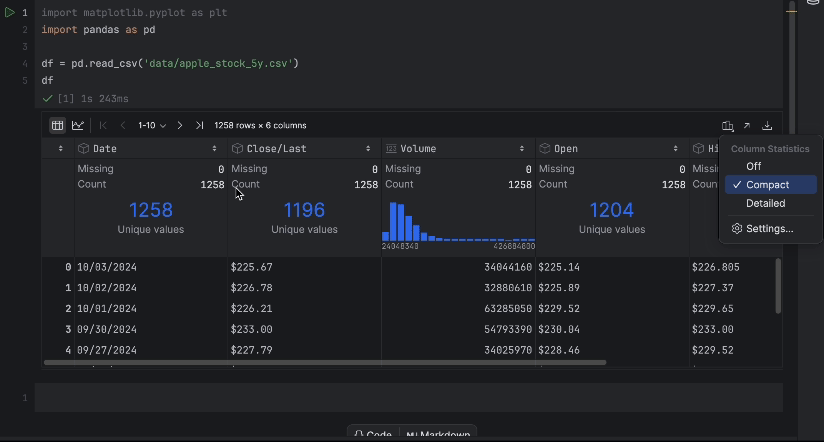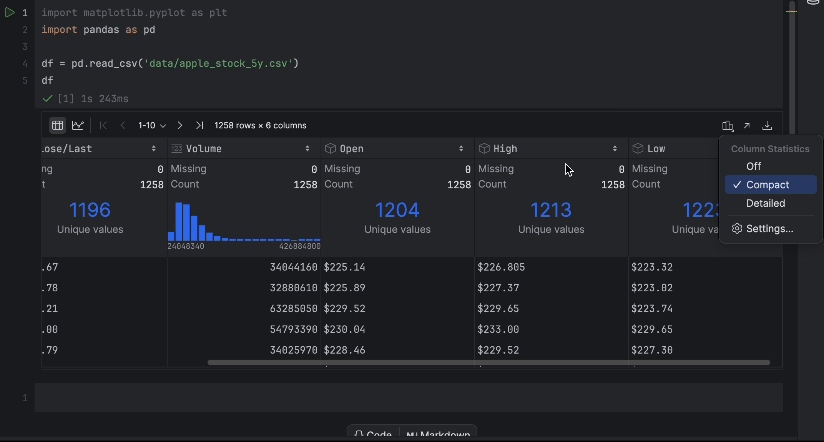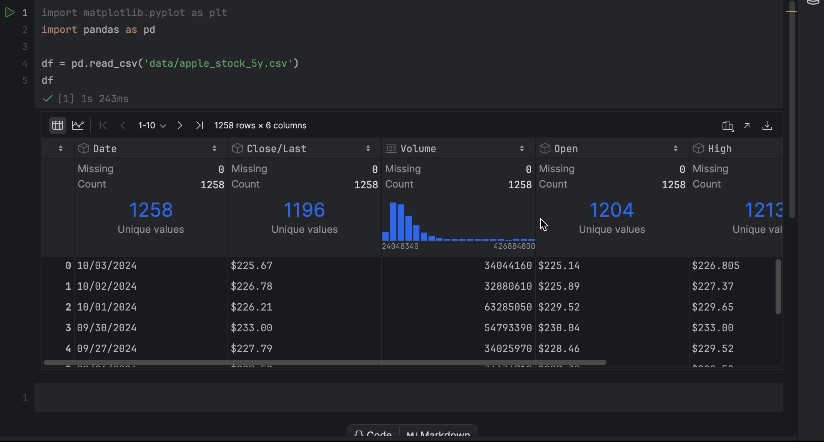
接下来,我们将数据集 apple_stock_5y.csv 放入 data 文件夹,并将其加载为 pandas DataFrame 进行检查。
import pandas as pd
df = pd.read_csv('data/apple_stock_5y.csv')
df
通过交互式表,我们可以轻松查看是否有数据缺失。
没有缺失数据,但有一个问题 – 我们想使用 Close/Last 价格,但它不是数字数据类型。 我们进行转换并再次检查数据:
df["Close/Last"] = df["Close/Last"].apply(lambda x: float(x[1:])) df
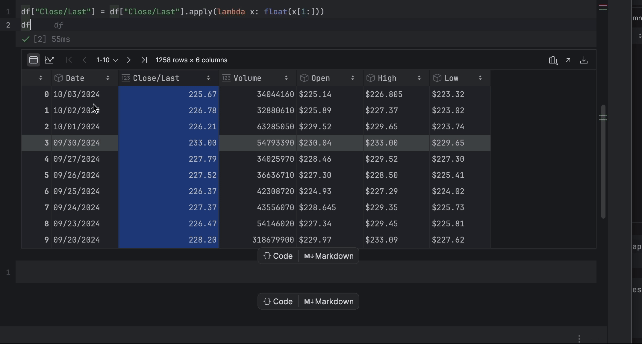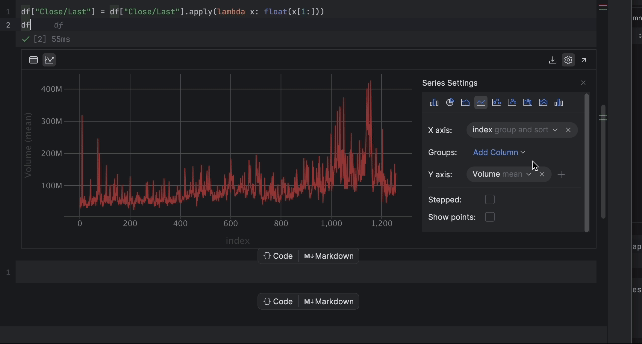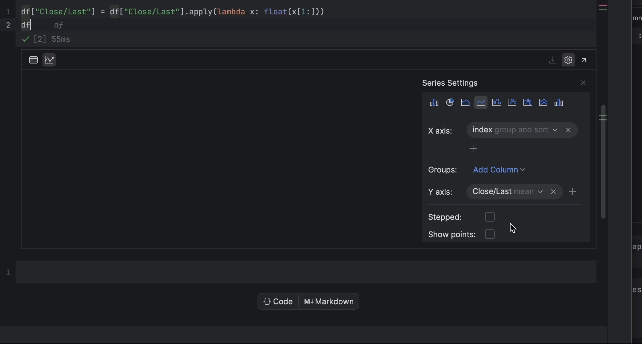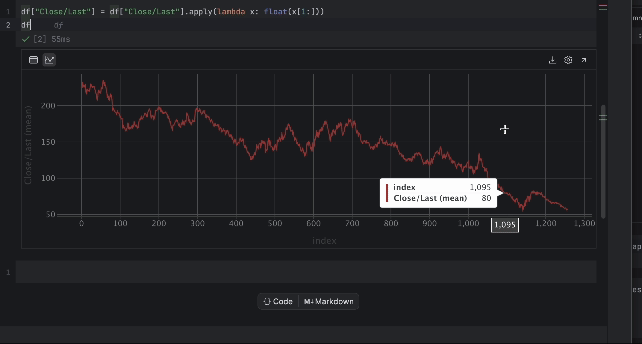
现在,我们可以通过交互式表检查价格。 点击左侧的绘图图标,将创建一个绘图。 它默认使用 Date 作为 x 轴,使用 Volume 作为 y 轴。 由于我们想查看 Close/Last 价格,点击右侧的齿轮图标进入设置,然后选择 Close/Last 作为 y 轴。
3. 为 LSTM 准备训练数据
接下来,我们准备在 LSTM 模型中使用的训练数据。 我们需要准备一个向量(特征 X)序列(每个向量代表一个时间窗口)来预测下一个价格。 下一个价格将形成另一个序列(目标 y)。 我们可以使用 lookback 变量选择此时间窗口的大小。 以下代码将创建序列 X 和 y,随后它们将被转换为 PyTorch 张量:
import torch
lookback = 5
timeseries = df[["Close/Last"]].values.astype('float32')
X, y = [], []
for i in range(len(timeseries)-lookback):
feature = timeseries[i:i+lookback]
target = timeseries[i+1:i+lookback+1]
X.append(feature)
y.append(target)
X = torch.tensor(X)
y = torch.tensor(y)
print(X.shape, y.shape)
一般来说,窗口越大,我们的模型就越大,因为输入向量更大。 不过,窗口越大,输入序列就越短,因此确定回顾窗口是一个平衡的操作。 我们将从 5 开始,但也可以尝试不同的数值,看看有什么不同。
4. 构建和训练模型
在训练之前,我们可以使用 PyTorch 中的 nn 模块创建一个类来构建模型。 nn 模块提组成要素,例如不同的神经网络层。 在本练习中,我们将构建一个简单的 LSTM 层,然后构建一个线性层:
import torch.nn as nn
class StockModel(nn.Module):
def __init__(self):
super().__init__()
self.lstm = nn.LSTM(input_size=1, hidden_size=50, num_layers=1, batch_first=True)
self.linear = nn.Linear(50, 1)
def forward(self, x):
x, _ = self.lstm(x)
x = self.linear(x)
return x
接下来,我们将训练模型。 在训练之前,我们需要创建一个优化器、一个用于计算预测值和实际 y 值之间损失的损失函数,以及一个用于馈入训练数据的数据加载器:
import numpy as np import torch.optim as optim import torch.utils.data as data model = StockModel() optimizer = optim.Adam(model.parameters()) loss_fn = nn.MSELoss() loader = data.DataLoader(data.TensorDataset(X, y), shuffle=True, batch_size=8)
我们已经创建了时间窗口,数据加载器可以将输入重排。 这保留了每个窗口中的顺序关系。
训练使用在每个周期循环的 for 循环完成。 每 100 个周期,我们将打印出损失并观察模型收敛情况:
n_epochs = 1000
for epoch in range(n_epochs):
model.train()
for X_batch, y_batch in loader:
y_pred = model(X_batch)
loss = loss_fn(y_pred, y_batch)
optimizer.zero_grad()
loss.backward()
optimizer.step()
if epoch % 100 != 0:
continue
model.eval()
with torch.no_grad():
y_pred = model(X)
rmse = np.sqrt(loss_fn(y_pred, y))
print(f"Epoch {epoch}: RMSE {rmse:.4f}")
我们从 1000 个周期开始,但模型收敛得相当快。 任意尝试训练周期次数,获得最佳结果。
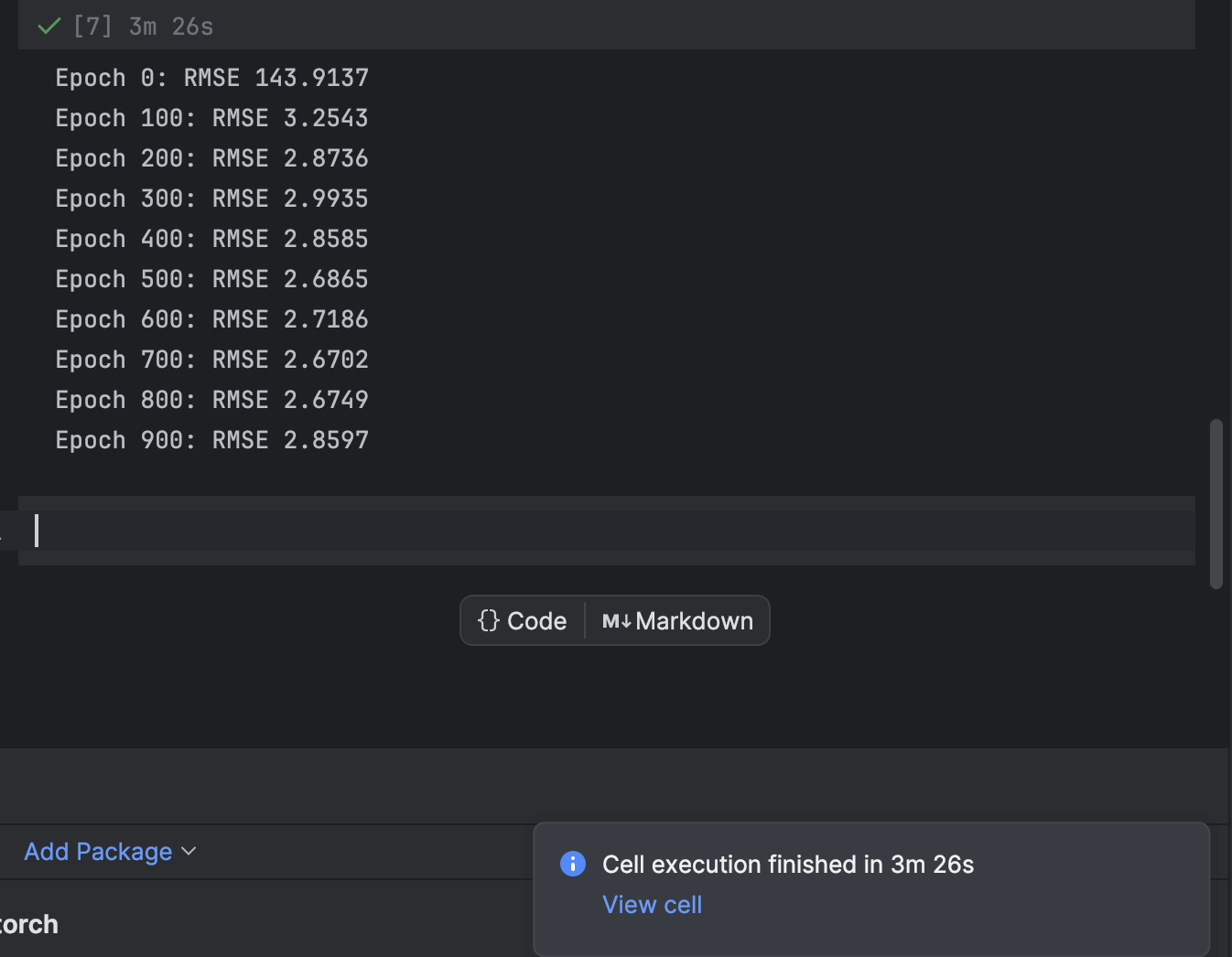
在 PyCharm 中,需要一些时间才能执行的单元将提供剩余时间的通知以及到该单元的快捷方式。 在 Jupyter Notebook 中训练机器学习模型,尤其是深度学习模型时,这非常方便。
5. 绘制预测并找出误差
接下来,我们将创建预测并将其与实际时间序列一起绘制。 注意,我们必须创建一个 2D np 序列,以便与实际时间序列匹配。 实际时间序列将为蓝色,预测时间序列将为红色。
import matplotlib.pyplot as plt
with torch.no_grad():
pred_series = np.ones_like(timeseries) * np.nan
pred_series[lookback:] = model(X)[:, -1, :]
plt.plot(timeseries, c='b')
plt.plot(pred_series, c='r')
plt.show()
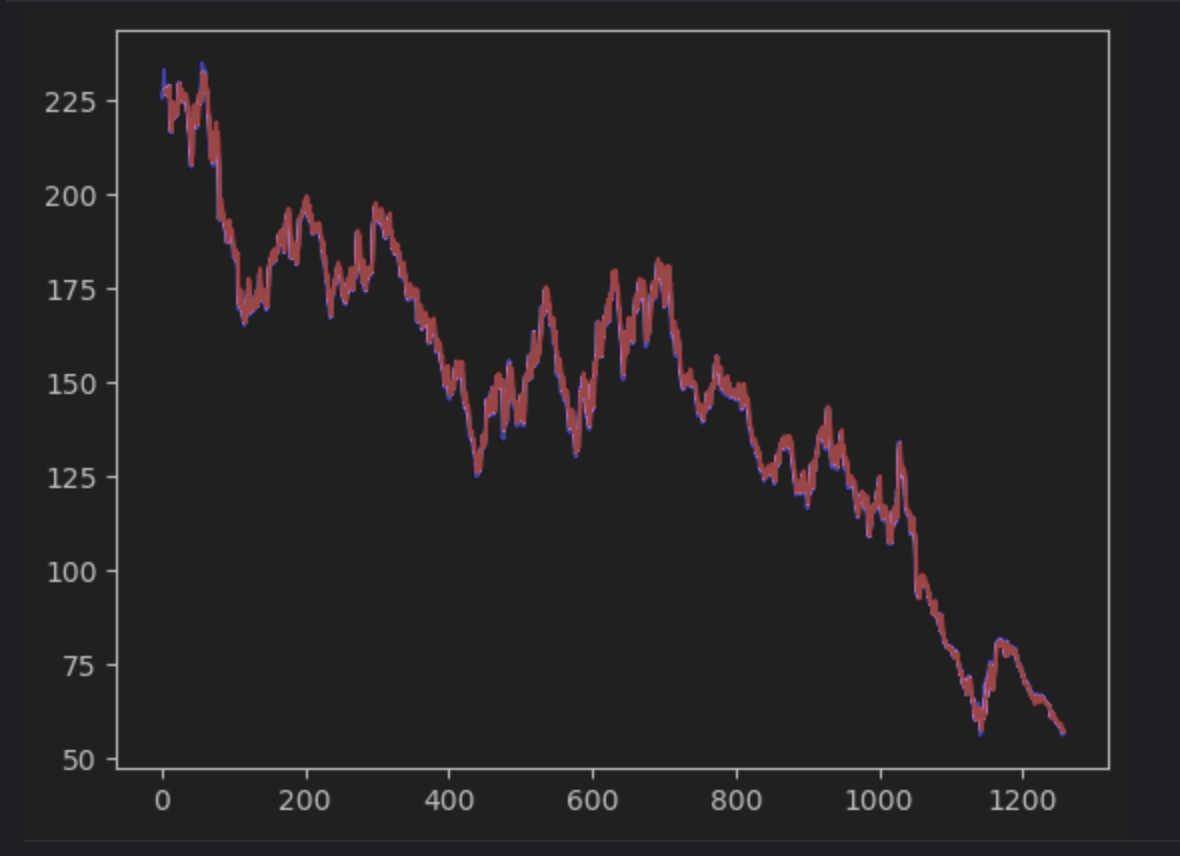
如果仔细观察,您会发现预测值和实际值并不完全一致。 不过,大多数预测都很好。
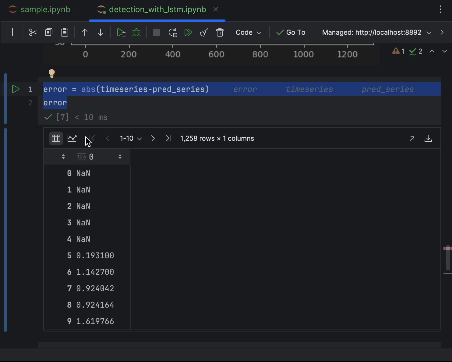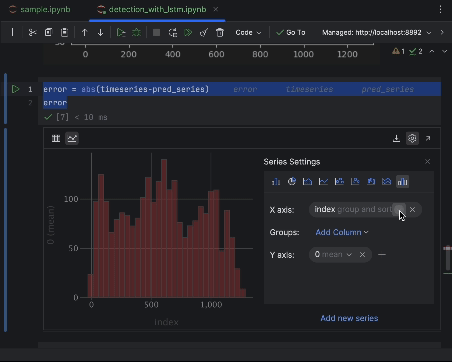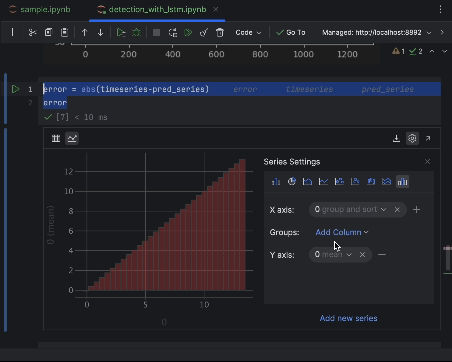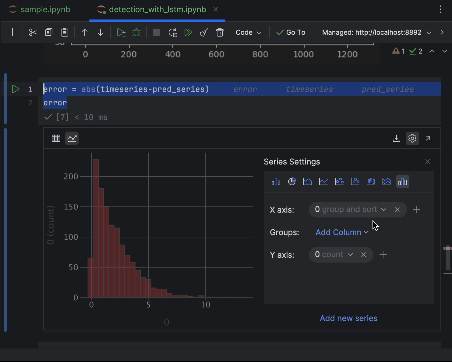
为了仔细检查误差,我们可以创建一个误差序列并使用交互式表对其进行观察。 这次我们使用绝对误差。
error = abs(timeseries-pred_series) error
使用设置创建直方图,以绝对误差的值作为 x 轴,以值的计数作为 y 轴。
6. 确定异常阈值并直观呈现
大多数点的绝对误差都会小于 6,因此我们可以将其设为异常阈值。 与处理蜂巢异常的做法类似,我们可以在图形中绘制异常数据点。
threshold = 6
error_series = pd.Series(error.flatten())
price_series = pd.Series(timeseries.flatten())
anomalies_filter = error_series.apply(lambda x: True if x > threshold else False)
anomalies = price_series[anomalies_filter]
plt.figure(figsize=(14, 8))
plt.scatter(x=anomalies.index, y=anomalies, color="red", label="anomalies")
plt.plot(df.index, timeseries, color='blue')
plt.title('Closing price')
plt.xlabel('Days')
plt.ylabel('Price')
plt.legend()
plt.show()
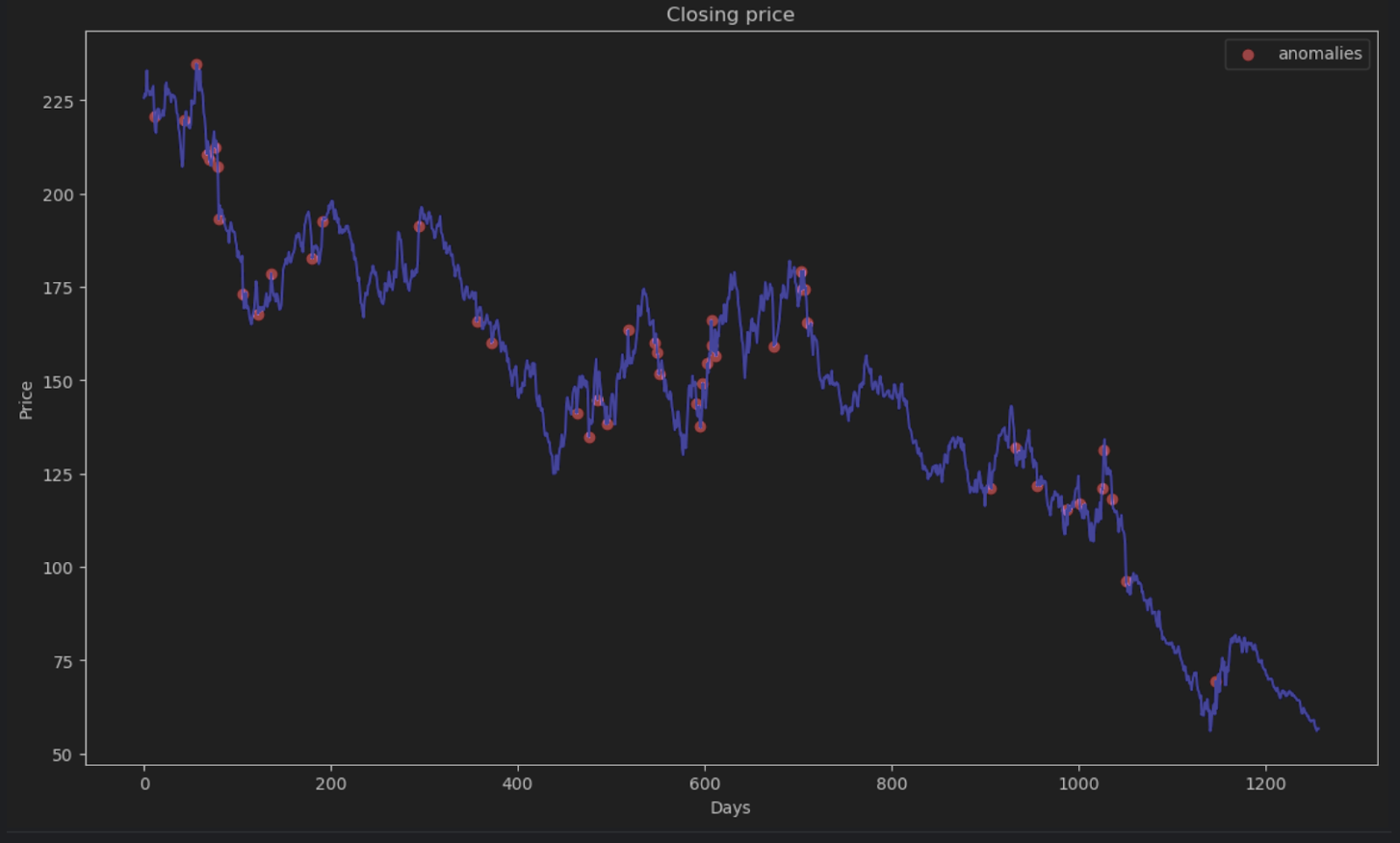
总结
时间序列数据是商业和科学研究等许多应用中使用的常见数据形式。 由于时间序列数据的顺序性,需要使用特殊的方法和算法来帮助确定其中的异常。 在这篇博文中,我们演示了如何使用 STL 分解识别异常以消除季节性和趋势。 我们还演示了如何使用深度学习和 LSTM 模型比较预测估计值和实际数据以确定异常。
使用 PyCharm 检测异常
使用 PyCharm Professional 中的 Jupyter 项目,您可以轻松组织包含大量数据文件和 Notebook 的异常检测项目。 在 PyCharm 中,可以生成图形输出以检查异常,并非常方便地查看绘图。 其他功能,例如自动补全建议,使浏览 Scikit-learn 模型和 Matplotlib 绘图设置变得非常容易。
使用 PyCharm 增强数据科学项目,查看为简化数据科学工作流提供的数据科学功能。
本博文英文原作者:





