

IntelliJ IDEA
IntelliJ IDEA – the Leading IDE for Professional Development in Java and Kotlin
将 Spring Data JPA 与 Kotlin 搭配使用

这篇博文由我与 Thorben Janssen 共同撰写,Thorben 拥有 20 余年的 JPA 和 Hibernate 经验,并且是“Hibernate Tips: More than 70 Solutions to Common Hibernate Problems”和 JPA 简报的作者。
Spring Data JPA 基于 Jakarta Persistence 规范,最初是为 Java 设计的。这常常会引出一个问题:Spring Data JPA 是否也适用于 Kotlin 项目?
简短的回答是肯定的!
您可以将 Spring Data JPA 与 Kotlin 搭配使用,不会出现任何问题,并且在编写业务代码时还能利用 Kotlin 简洁的语法以及 null 安全、扩展函数等语言功能。
实现这一切操作快速、简便,这篇简短的博文就能解释清楚。我们将 Spring Data JPA 与 Kotlin 搭配使用,定义并使用一个简单的持久性层。
需要的依赖项
最简单的入门方式是使用 IntelliJ 中的“New Project”(新建项目)向导。在您选择 Kotlin 和 Spring Data JPA 后,IDE 会自动完成基本设置, 包括配置 Kotlin no-arg 和 all-open 插件。这些插件可以确保您的 Kotlin 类满足 Jakarta Persistence 对非 final 类和无形参构造函数的要求。您还会获得 Spring 必需的 kotlin-reflect 依赖项。
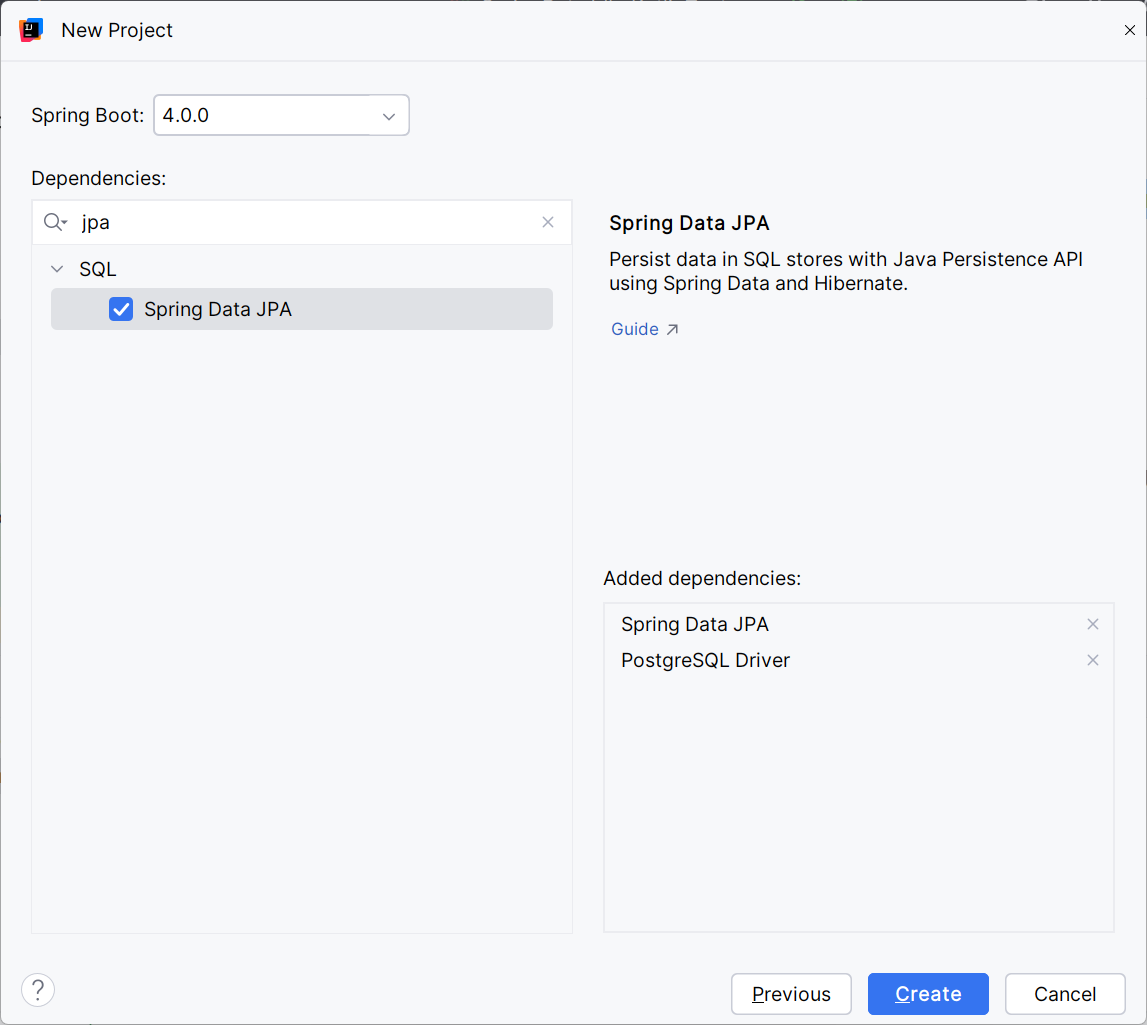
在下一个页面上,您可以选择要使用的 Spring Boot Starter 模块以及其他依赖项。在本例中,我们选择的是 Spring Data JPA 和 PostgreSQL 数据库驱动程序。
将 Kotlin 添加到现有项目
如果您已有一个基于 Java 且包含所需依赖项的 Spring Boot 项目,只需将 Kotlin 类添加到其中即可。从版本 2026.1 开始,IntelliJ IDEA 会自动将 plugin.spring 和 plugin.jpa 插件添加到您的构建配置中,并且会配置 all-open 插件。
如果您使用的 IDEA 版本较低,则需要自行添加以下配置。
plugins {
kotlin("plugin.spring") version "2.2.20"
kotlin("plugin.jpa") version "2.2.20"
}
allOpen {
annotation("jakarta.persistence.Entity")
annotation("jakarta.persistence.MappedSuperclass")
annotation("jakarta.persistence.Embeddable")
}
数据库和日志记录配置
定义项目的依赖项后,您需要在 application.properties 文件中设置数据库连接,并且您可以设置您偏好的日志记录配置。
以下设置可以连接到本地 PostgreSQL 数据库,并激活详细的 Hibernate 日志记录。日志记录配置会指示 Hibernate 记录已执行的 SQL 语句以及所有绑定形参值。这些信息在开发和调试过程中非常有用,但会生成大量输出。因此,在生产环境中务必使用其他日志记录配置。
spring.datasource.url=jdbc:postgresql://localhost:5432/postgres spring.datasource.username=postgres spring.datasource.password=postgres logging.level.root=INFO logging.level.org.hibernate.SQL=DEBUG logging.level.org.hibernate.orm.jdbc.bind=TRACE
实体建模
接下来,您可以开始用 Kotlin 为实体建模。Jakarta Persistence 规范为实体类定义了一些要求。正如我们在最近一篇关于通用最佳做法的文章中所介绍的,其中一些要求并不完全符合 Kotlin 的数据类规范。不过,如果您将实体类定义为普通 Kotlin 类,并为想要持久化的字段添加注解,就不会遇到任何问题,还能利用 Kotlin 简洁的语法。
常用的最佳做法是避免在 API 中暴露实体类及其技术依赖项。为此,大多数团队会引入其数据的另一种非实体表示。使用 Kotlin 时,您可以轻松将这些类建模为数据类。这种做法需要编写额外的映射代码,以在不同格式之间转换数据。当然,您也可以在业务代码中完成此操作。但更方便的做法是向实体类添加一组转换函数,或者直接从数据库中选择数据类。本文后面的部分会给出第二种方式的示例。现在,我们重点介绍实体类。
这是一个简单的 Person 实体, 它映射了人员的名字和姓氏,以及与其就职公司的多对一关系。
PersonData 类表示相同信息。您可以在 API 中使用此类,无需暴露持久性层的任何技术细节。为了尽可能方便地使用这个类,Person 实体类提供了 2 个包含所需映射代码的函数。
@Entity
class Person(
@Id
@GeneratedValue
var id: Long? = null,
var firstName: String? = null,
var lastName: String? = null,
@ManyToOne(fetch = FetchType.LAZY)
var company: Company? = null,
@Version
var version: Integer? = null
) {
fun createPersonData(): PersonData {
return PersonData(
id = id!!,
firstName = firstName ?: "",
lastName = lastName ?: "",
version = version
)
}
companion object {
fun createPersonFromData(data: PersonData): Person {
return Person(
id = data.id,
firstName = data.firstName,
lastName = data.lastName,
version = data.version
)
}
}
}
data class PersonData(
val id: Long,
val firstName: String,
val lastName: String,
val version: Int
)
函数
Company 实体采用相同的方式:
@Entity
class Company(
@Id
@GeneratedValue
var id: Long? = null,
var name: String = "default",
@Version
var version: Integer? = null
)
为实体类建模后,您可以开始定义仓库。
设计和使用仓库
Spring Data JPA 的仓库抽象在 Kotlin 中的使用方式与在 Java 中一致。您只需扩展提供的仓库接口(如 JpaRepository 或 CrudRepository)之一,Spring Data 就会自动为您提供实现。
这些仓库定义了一组标准方法,用于通过主键获取实体、持久化新实体以及移除现有实体。它们还与 Spring 的事务处理集成,这样,您可以在业务层或 API 层使用 @Transactional 注解定义事务处理。
下面是一个简单的 PersonRepository 定义示例。它会继承 JpaRepository 定义的所有标准方法。我们将通过下列示例之一介绍如何添加您自己的查询方法。
interface PersonRepository : JpaRepository<Person, Long> {}
为了进一步简化操作,IntelliJ IDEA 可以自动为您创建仓库。只需开始在服务中输入仓库名称,IDEA 就会建议创建此仓库:

此仓库创建完毕后,您便可专注于业务逻辑。这在 Kotlin 中尤为便捷,因为借助构造函数注入和简洁的函数定义,您的类能够保持简短且专注于特定功能。
@Component
@Transactional
class PersonController (
private val personRepository: PersonRepository) {
fun createNewPerson(person : Person): Person {
// add additional validations and/or logic ...
return personRepository.save(person)
}
}
在本例中,Spring 会在进入 createNewPerson 方法之前注入 PersonRepository 实例,并连接有效事务或启动新事务。如果它启动了新事务,还会在完成此方法调用后提交该事务。PersonRepository 和 Jakarta Persistence 实现会共同提供所需代码,以创建并执行用于将提供的 Person 对象存储到数据库中的 SQL INSERT 语句。
2025-11-16T16:02:53.988+01:00 DEBUG 10104 --- [SDJWithKotlin] [ main] org.hibernate.SQL : select next value for person_seq 2025-11-16T16:02:54.012+01:00 DEBUG 10104 --- [SDJWithKotlin] [ main] org.hibernate.SQL : insert into person (company_id,first_name,last_name,version,id) values (?,?,?,?,?) 2025-11-16T16:02:54.014+01:00 TRACE 10104 --- [SDJWithKotlin] [ main] org.hibernate.orm.jdbc.bind : binding parameter (1:BIGINT) <- [null] 2025-11-16T16:02:54.014+01:00 TRACE 10104 --- [SDJWithKotlin] [ main] org.hibernate.orm.jdbc.bind : binding parameter (2:VARCHAR) <- [John] 2025-11-16T16:02:54.014+01:00 TRACE 10104 --- [SDJWithKotlin] [ main] org.hibernate.orm.jdbc.bind : binding parameter (3:VARCHAR) <- [Doe] 2025-11-16T16:02:54.014+01:00 TRACE 10104 --- [SDJWithKotlin] [ main] org.hibernate.orm.jdbc.bind : binding parameter (4:INTEGER) <- [0] 2025-11-16T16:02:54.015+01:00 TRACE 10104 --- [SDJWithKotlin] [ main] org.hibernate.orm.jdbc.bind : binding parameter (5:BIGINT) <- [2]
您可能已经在将 Spring Data JPA 与 Java 搭配使用时了解了这些内容, 使用 Kotlin 并不会让此行为有任何改变,您在实现业务逻辑时也能享受到 Kotlin 带来的所有优势。
我们来看另一个示例。
获取和更新现有实体沿用相同的模式。updateLastName 函数通过主键加载实体,并更改 lastName 属性。您只需完成这些操作即可。Jakarta Persistence 实现会在下一次脏检查过程中发现这处修改,并自动更新数据库。
@Component
@Transactional
class PersonController (
private val personRepository: PersonRepository) {
fun updateLastName(id : Long, lastName : String): Person {
var person = personRepository.findById(id).orElseThrow()
person.lastName = lastName
return person
}
}
您会发现,Kotlin 简洁的语法帮助提高了业务逻辑的易读性,Spring 则为您处理了所有样板代码。因此,实现应用程序变得非常轻松。
添加您自己的查询
除了 Spring Data JPA 仓库提供的标准方法外,您还需要定义用于获取业务代码中所用数据的查询。您可以通过两种方式定义该查询,且这两种方式均适用于 Kotlin。
第一种也是最便捷的方式,是使用派生查询方法。Spring 会分析方法名称,派生相应的 JPQL 查询,并绑定方法形参值。如果查询比较简单,且只需要一个或两个绑定形参,这是不错的选择。
您可以直接向仓库添加派生查询方法。也可以开始在 IDEA 中开始输入所需方法名称,并利用自动补全功能将其自动添加到仓库中。
以下代码段给出了典型示例。findByLastName 方法会获取 lastName 等于所提供值的所有 Person 实体。
interface PersonRepository : JpaRepository<Person, Long> {
fun findByLastName(lastName: String): List<Person>
}
如果您的查询变得更加复杂,则应改为向仓库方法添加 @Query 注解。这样,您便可编写自己的 JPQL 查询,并完全控制执行的语句。您可以使用连接、分组或任何其他 JPQL 功能。
这里给出的查询语句与上例中相同, 但这次使用的是 @Query 注解,而不是 Spring Data 的派生查询功能。
interface PersonRepository : JpaRepository<Person, Long> {
@Query("select p from Person p where p.lastName = :lastName")
fun getByLastName(lastName: String): List<Person>
}
当您调用这些方法之一时,Spring Data JPA 会使用 Jakarta Persistence 的 EntityManager 来实例化查询、设置提供的绑定形参、执行查询,并将结果映射到受管理的 Person 实体对象。
2025-11-16T16:47:20.949+01:00 DEBUG 16193 --- [SDJWithKotlin] [ main] org.hibernate.SQL : select p1_0.id,p1_0.company_id,p1_0.first_name,p1_0.last_name,p1_0.version from person p1_0 where p1_0.last_name=? 2025-11-16T16:47:20.952+01:00 TRACE 16193 --- [SDJWithKotlin] [ main] org.hibernate.orm.jdbc.bind : binding parameter (1:VARCHAR) <- [Doe]
但实体并不是您可以使用的唯一投影。对于许多用例来说,仅获取所需信息的只读 DTO 投影更为高效。Kotlin 的数据类是为此类 DTO 建模的绝佳方式。
如果您只想显示多人的名字、姓氏及其任职公司名称,可以使用以下 PersonWithCompany 数据类:
data class PersonWithCompany(
val firstName: String,
val lastName: String,
val company: String
)
在下一步中,您可以定义返回这些对象 List 的仓库方法。如果您为该方法添加 @Query 注解,并提供返回包含匹配名称的 3 个字段的 JPQL 查询,Spring Data JPA 会自动将每条记录映射到 PersonWithCompany 对象。
interface PersonRepository : JpaRepository<Person, Long> {
@Query("select p.firstName, p.lastName, c.name as company from Person p join p.company c")
fun findPersonsWithCompany(): List<PersonWithCompany>
}
在日志输出中可以看到,使用数据类作为查询投影,既能在业务代码中享受 Kotlin 数据类的便利,又能获得仅从数据库中获取所需信息的性能优势。
2025-11-16T16:59:42.260+01:00 DEBUG 22541 --- [SDJWithKotlin] [ main] org.hibernate.SQL : select p1_0.first_name,p1_0.last_name,c1_0.name from person p1_0 join company c1_0 on c1_0.id=p1_0.company_id 2025-11-16T16:59:42.278+01:00 INFO 22541 --- [SDJWithKotlin] [ main] c.t.j.k.s.SDJWithKotlinApplicationTests : PersonWithCompany(firstName=Jane, lastName=Doe, company=Mighty Business Corp)
提供您自己的仓库方法实现
如果 Spring Data JPA 的 @Query 注解提供的灵活性无法满足您的需求,您还可以为仓库添加自己的方法实现。为此,请创建一个仅定义您要实现的方法的接口,让您的仓库扩展该接口,并提供该接口的实现, 这称为片段仓库。
在本例中,PersonFragmentRepository 定义了 searchPerson 方法,该方法接收 PersonSearchInput 形参。
interface PersonFragmentRepository {
fun searchPerson(searchBy : PersonSearchInput): List<Person?>?
}
data class PersonSearchInput(
val firstName : String?,
val lastName : String?,
val worksForCompany : String?
) {}
在下一步,您必须实现 PersonFragmentRepository。您的类名称应为接口名称加上 Impl 后缀。Spring Data 随后会自动检测此类,将其注入到您的仓库中,并将所有对 searchPerson 方法的调用委托给您的类来处理。
以下 searchPerson 实现的目标是:检查 PersonSearchInput 对象的哪些字段已设置,并在查询的 WHERE 子句中仅考虑这些字段。对于用户可以在其中选择要搜索的信息的复杂搜索对话框,这是典型的实现。
override fun searchPerson(searchBy: PersonSearchInput): List<Person?>? {
val cBuilder = em.criteriaBuilder
val cQuery = cBuilder.createQuery(Person::class.java)
val person = cQuery.from(Person::class.java)
val wherePredicates = mutableListOf<Predicate>()
searchBy.firstName?.let {
wherePredicates.add(cBuilder.equal(person.get<String>("firstName"), searchBy.firstName))
}
searchBy.lastName?.let {
wherePredicates.add(cBuilder.equal(person.get<String>("lastName"), searchBy.lastName))
}
searchBy.worksForCompany?.let {
val company = person.join<Person, Company>("company")
wherePredicates.add(cBuilder.equal(company.get<String>("name"), searchBy.worksForCompany))
}
cQuery.where(*wherePredicates.toTypedArray())
return em.createQuery(cQuery).resultList
}
从代码段中可以看出,searchPerson 方法使用 Jakarta Persistence 的 Criteria API,根据所提供 PersonSearchInput 对象中设置的字段定义查询。
它先获取 CriteriaBuilder,并将其用于创建返回 Person 对象的 CriteriaQuery, 随后定义 FROM 子句,并创建 List of Predicates。对于 PersonSearchInput 对象的每个非 null 字段,会向 wherePredicates List 添加等值条件。
得益于 Kotlin 简洁的语法和 null 处理,定义这些 Predicates 简单易行。只有对公司名称的处理需要稍加注意。如果该字段已设置,则必须先添加对 Company 实体的连接,然后才能定义等值条件。
随后,您可以使用 wherePredicates List 来定义 WHERE 子句、执行查询并返回结果。
定义并实现 PersonFragmentRepository 后,即可在您的仓库定义中使用它。我们来将其添加到前面的示例中介绍过的 PersonRepository。它现在会扩展 Spring Data JPA 的 JpaRepository 和 PersonFragmentRepository。
interface PersonRepository : JpaRepository<Person, Long>, PersonFragmentRepository {
fun findByLastName(lastName: String): List<Person>
@Query("select p from Person p where p.lastName = :lastName")
fun getByLastName(lastName: String): List<Person>
@Query("select p.firstName, p.lastName, c.name as company from Person p join p.company c")
fun findPersonsWithCompany(): List<PersonWithCompany>
}
当您在业务代码中使用此 PersonRepository 时,Spring Data JPA 会提供由 JpaRepository 定义的所有方法的实现。它还会生成 3 个查询方法的实现。只有对 searchPerson 方法的调用会被委托给您的 PersonFragmentRepositoryImpl 类。
总结
正如您在本文中看到的,Kotlin 与 Spring Data JPA 配合得非常出色。您可以像在 Java 应用程序中一样为实体建模和定义仓库。Kotlin 简洁的语法通常可以提高这些代码部分的易读性和易维护性,同时无需改变任何持久性行为。如果遵循既有的针对 Kotlin 的 Jakarta Persistence 最佳做法,您将获得流畅的开发体验和高效的持久性层。
要详细了解 Kotlin 的持久性开发,可以阅读本系列的另外两篇文章:
作者简介






