

在机器学习中使用 Python 进行异常值检测


近年来,我们的许多应用程序都由我们能够收集和处理的大量数据驱动。 有人可能会说我们正处于数据时代。 处理如此大量数据的一个重要方面是异常值检测 – 这个过程使我们能够识别离群值、超出预期范围的数据并展现反常的行为。 在科学研究中,异常值数据点可能是技术问题的原因,在得出结论时可能需要舍弃,或者,也可能带来新的发现。
在这篇博文中,我们将分析为什么使用机器学习进行异常值检测很有帮助,并探索使用 Python 检测异常值的关键技术。 您将学习如何实现 OneClassSVM 和孤立森林等流行方法,查看直观呈现这些结果的示例并了解如何将它们应用于实际问题。
异常值检测在哪里使用?
异常值检测也是现代商业智能的重要组成部分,因为它提供了可能出错的地方的洞察,也可能发现潜在问题。 以下是在现代商业中使用异常值检测的一些示例。
安全警报
某些网络安全攻击可以通过异常值检测发现,例如,请求量激增可能表示 DDoS 攻击,可疑登录行为(如多次尝试失败)可能表示未授权访问。 检测到可疑用户行为可能表示潜在网络安全威胁,公司可以采取相应措施防止或尽可能减少损失。
欺诈检测
例如,在金融组织中,银行可以使用异常值检测突出显示可疑账户活动,这可能是洗钱或身份盗窃等非法活动的迹象。 可疑交易也可能表示信用卡欺诈。
可观测性
Web 服务的常见做法之一是,在系统出现异常行为时收集服务的实时性能指标。 例如,内存使用量激增可能表明系统中的某些东西没有正常运行,工程师可能需要立即解决,以避免服务中断。
为什么要使用机器学习进行异常值检测?
虽然传统统计方法也可以帮助发现离群值,但使用机器学习进行异常值检测已经带来了颠覆性变化。 利用机器学习算法,可以一次性分析更复杂的数据(例如,具有多个参数的数据)。 机器学习技术还提供了一种分析分类数据的方式,使用传统统计方法不容易分析这些数据,因为传统统计方法更适合数值数据。
很多时候,这些异常值检测算法都经过编程,可以作为应用程序部署(请参阅我们的如何将 FastAPI 用于机器学习教程),并按要求或预定时间间隔运行以检测异常值。 这意味着它们可以促使公司内部的立即行动,也可以用作报告工具供商业智能团队审查和调整战略。
异常值检测技术和算法的类型
异常值检测通常有两种主要类型:离群值检测和新颖性检测。
离群值检测
离群值检测有时也被称为无监督异常值检测,因为它假设在训练数据中存在一些未检出的异常值(因此未标记),并且方式是使用无监督机器学习算法将异常值挑出。 算法包括一类支持向量机 (SVM)、孤立森林、局部离群因子和椭圆包络等。
新颖性检测
新颖性检测有时被称为半监督异常值检测。 由于我们假设所有训练数据并非完全由异常值组成,它们都被标记为正常。 目标是检测新数据是否为异常值,这有时也称为新颖性。 只要训练数据中没有异常值,用于离群值检测的算法也可以用于新颖性检测。
除了上述离群值检测和新颖性检测外,在时间序列数据中进行异常值检测也很常见。 不过,由于时间序列数据所用方式和技术通常与上述算法不同,我们将在以后详细讨论。
代码示例:查找蜂巢数据集中的异常值
在这篇博文中,我们将以蜂巢数据集为例,检测蜂巢中的异常值。 这个数据集提供了蜂巢在不同时间的各种测量数据(包括蜂巢的温度和相对湿度)。
接下来,我们将展示两种截然不同的异常值检测方法。 它们分别是基于支持向量机技术的 OneClassSVM(我们将使用它来绘制决策边界),以及孤立森林,这是一种类似于随机森林的集成方法。
示例:OneClassSVM
在第一个例子中,我们将使用蜂巢 17 的数据,假设蜜蜂会将蜂巢保持在一个对蜂群来说恒定舒适的环境中。我们可以看看这是否属实,以及蜂巢是否会经历异常的温度和相对湿度水平。 我们将使用 OneClassSVM 拟合数据并查看散点图上的决策边界。
OneClassSVM 中的 SVM 代表支持向量机,这是一种用于分类和回归的流行机器学习算法。 虽然支持向量机可用于对高维数据点分类,但通过选择一个内核与一个标量参数定义边界,我们可以创建一个包含大多数数据点(正常数据)的决策边界,同时保留边界外的少量异常值,表示发现新异常值的概率 (nu)。 Scholkopf 等作者在题为 Estimating the Support of a High-Dimensional Distribution 的论文中讲解了使用支持向量机进行异常值检测的方法。
1. 开始一个 Jupyter 项目
在 PyCharm (Professional 2024.2.2) 中开始新项目时,选择 Python 下的 Jupyter。
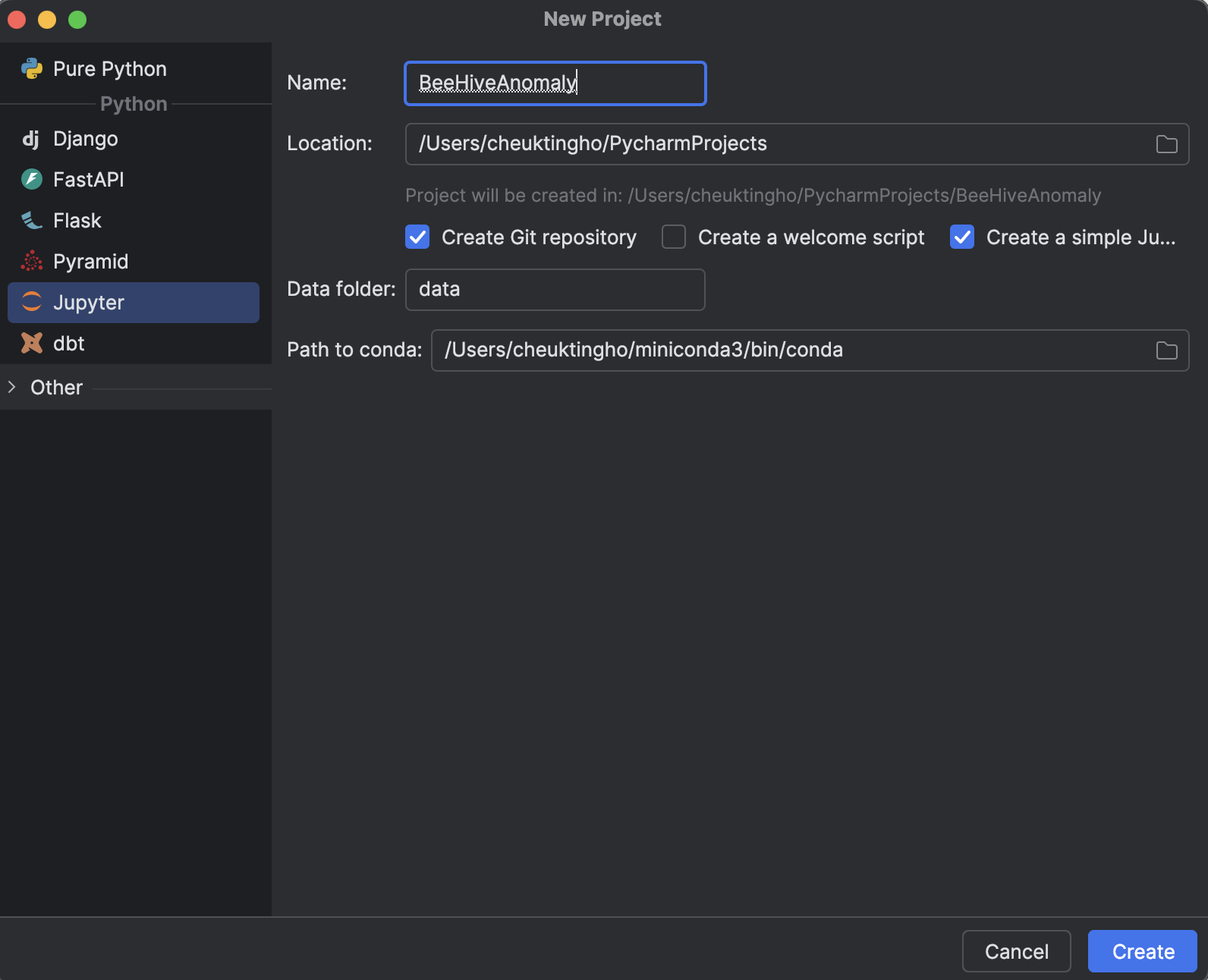
在 PyCharm 中使用 Jupyter 项目(以前也称为科学项目)的好处是,它会生成一个文件结构,包括一个用于存储数据的文件夹和一个用于存储所有 Jupyter Notebook 的文件夹,因此您可以将所有实验集中在一个地方。
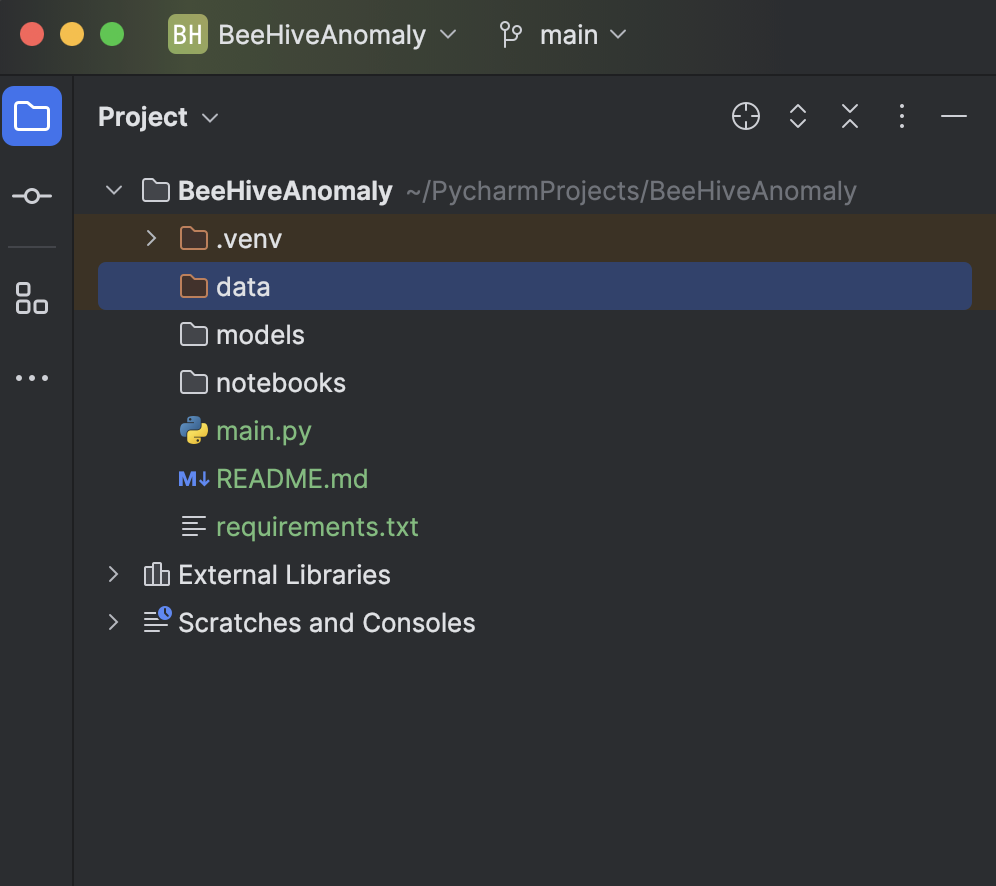
另一个巨大的好处是,我们可以使用 Matplotlib 非常轻松地呈现图形。 这将在下面的步骤中有所展现。
2. 安装依赖项
从相关 GitHub 仓库下载此 requirements.txt。 将其放入项目目录并在 PyCharm 中打开后,您将看到一条提示,要求安装缺失的库。
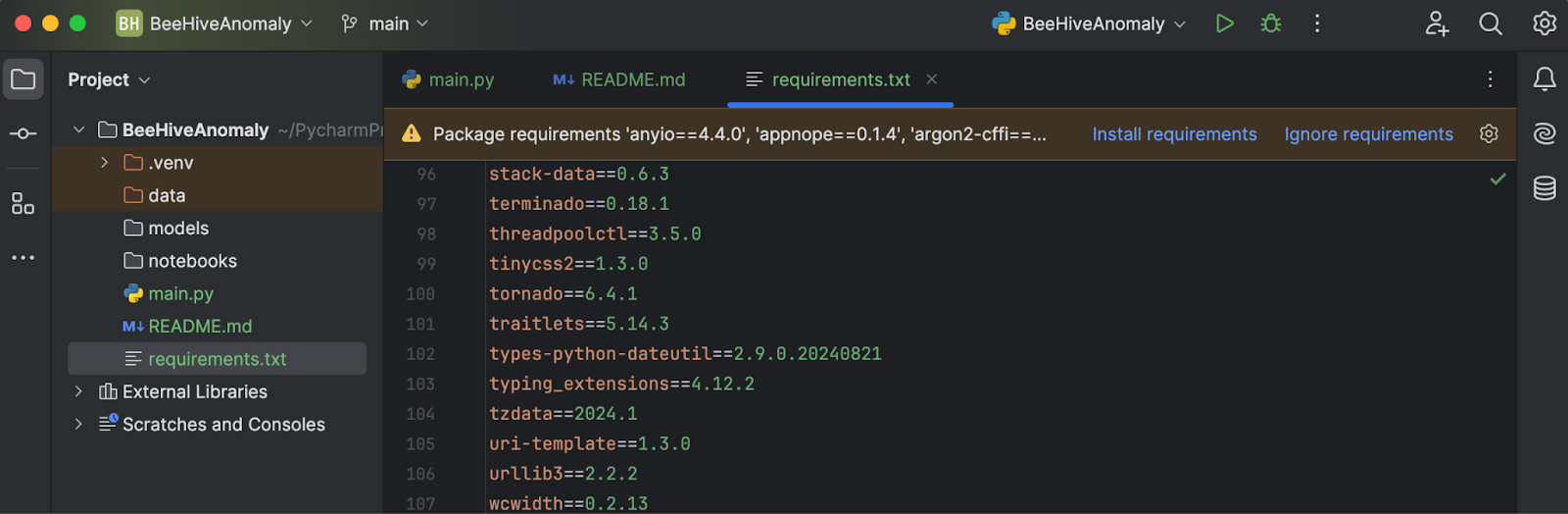
点击 Install requirements(安装 requirements),将安装所有 requirements。 在此项目中,我们使用 Python 3.11.1。
3. 导入并检查数据
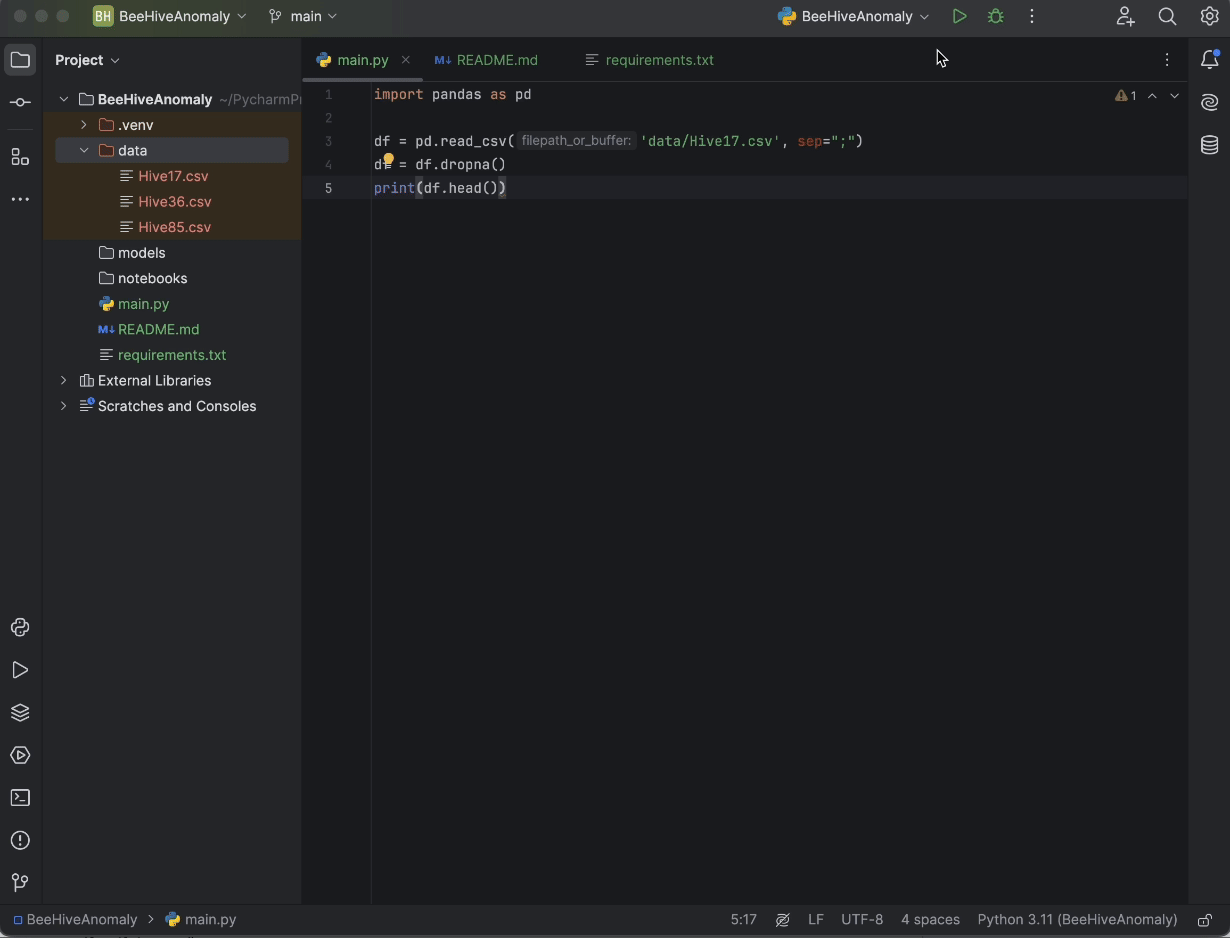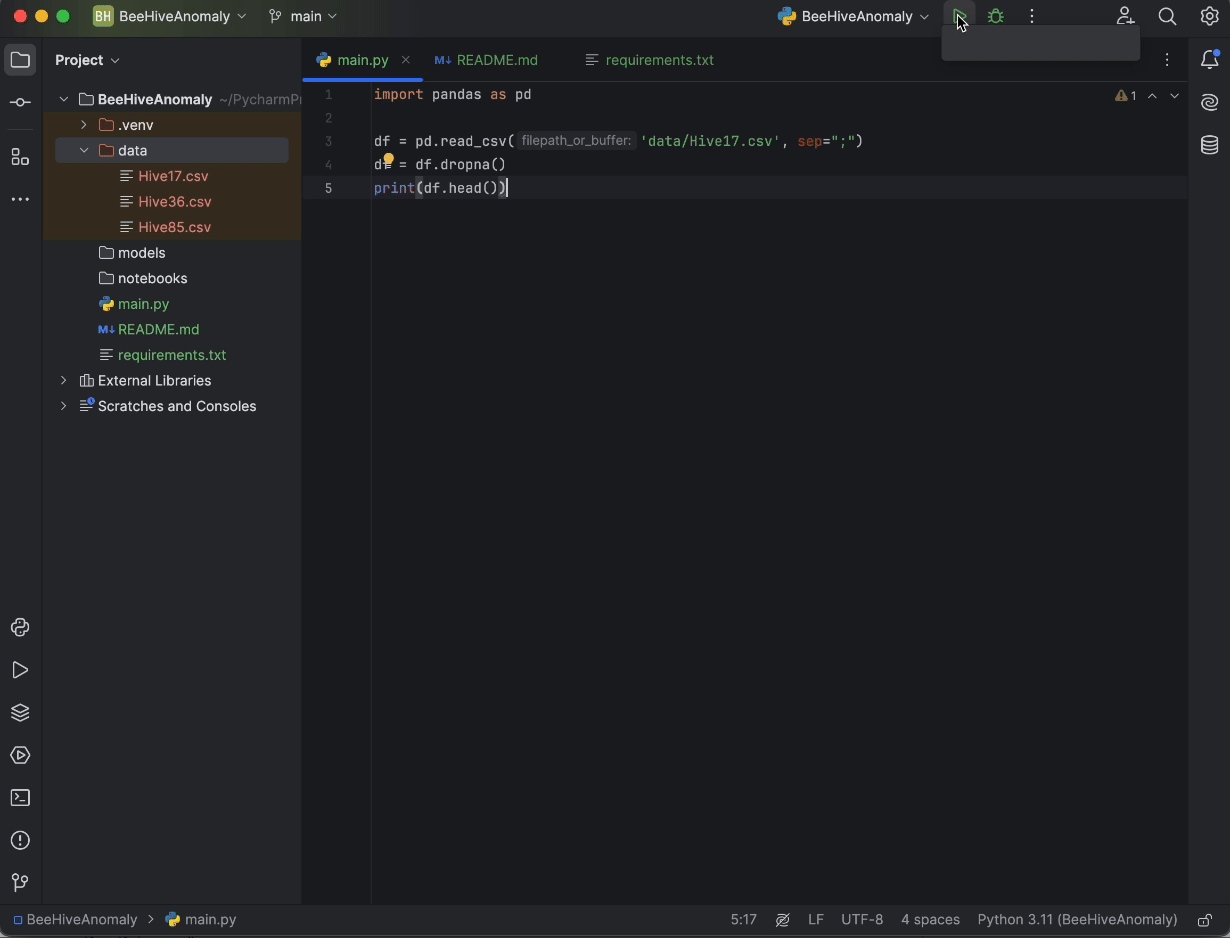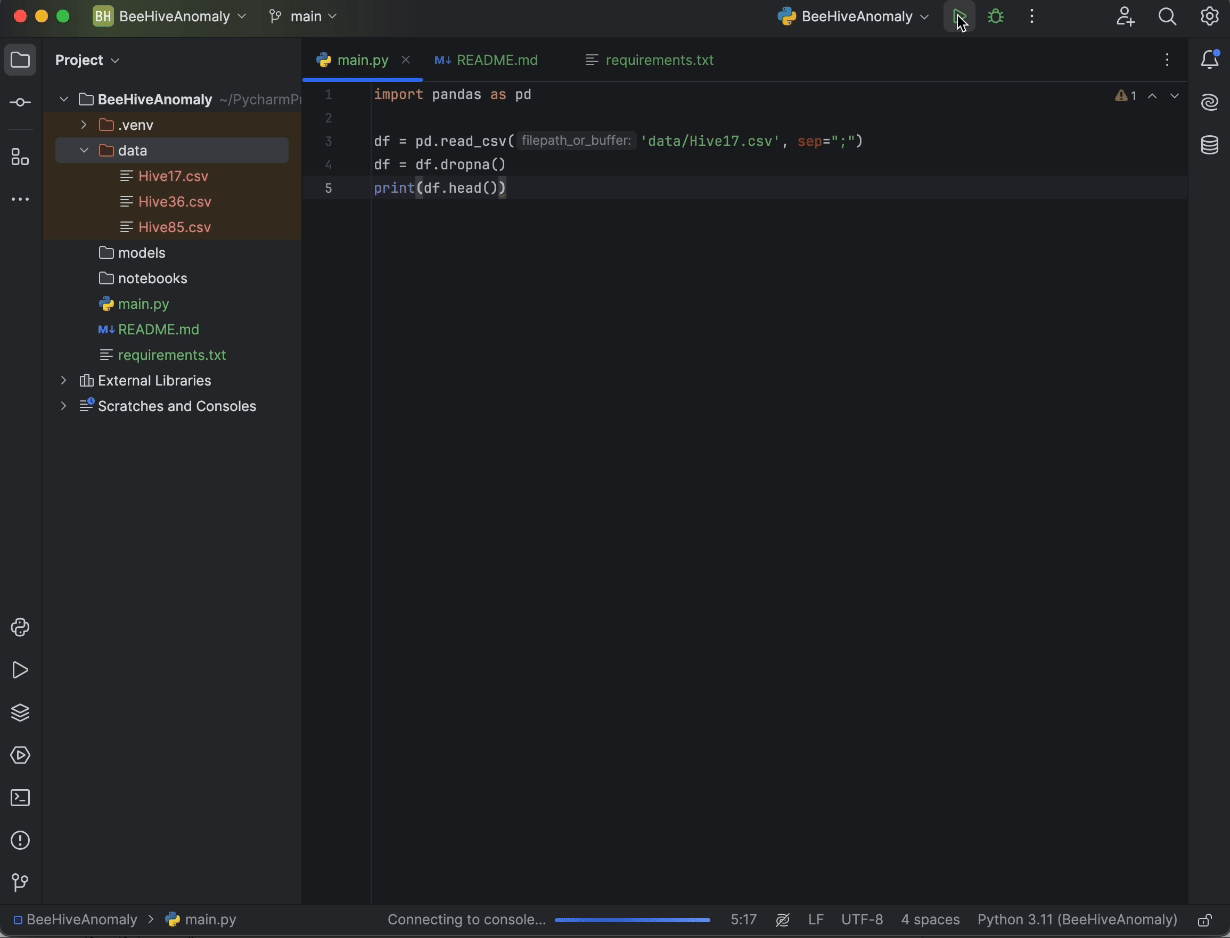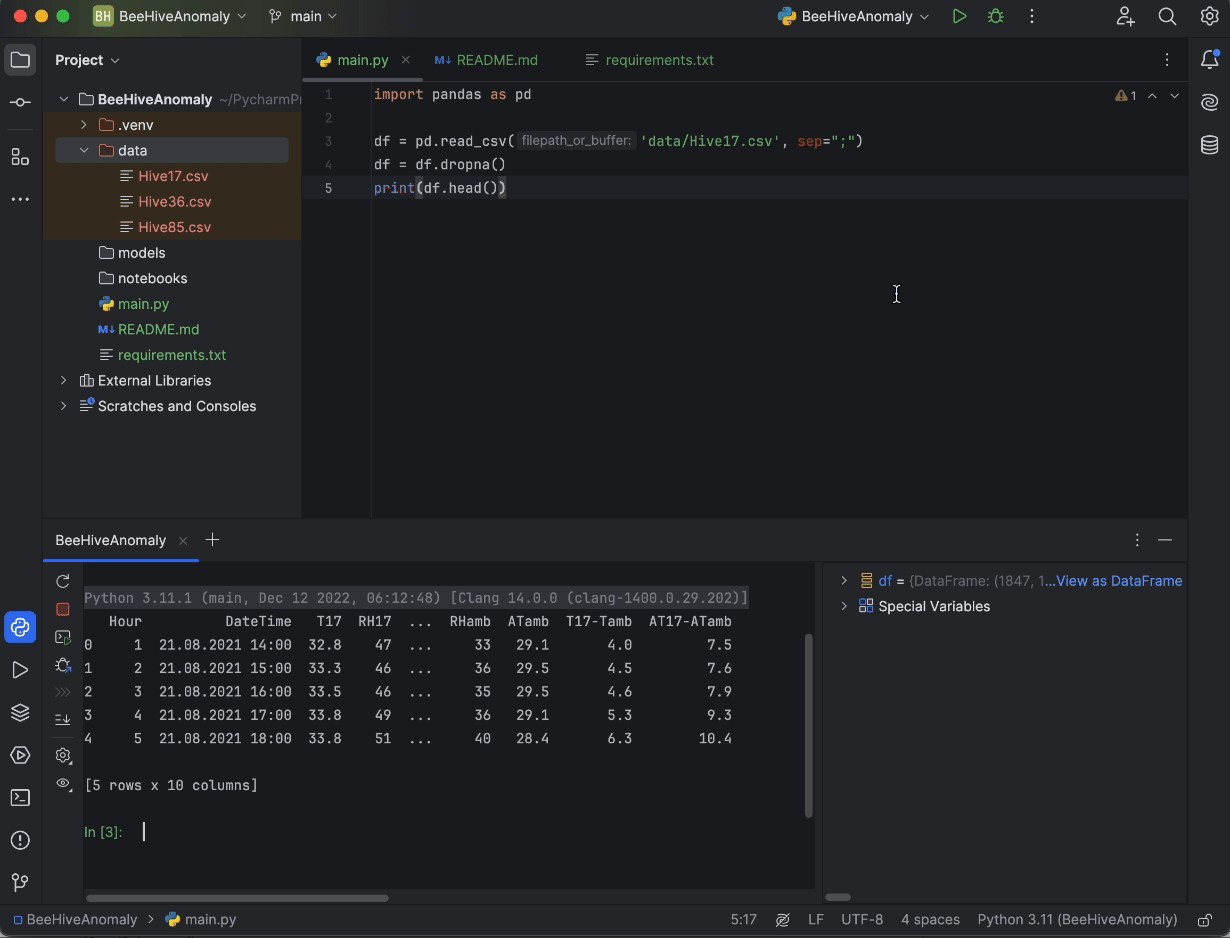
您可以从 Kaggle 或此 GitHub 仓库下载“Beehives”数据集。 将全部三个 CSV 放入 Data 文件夹。 然后,在 main.py 中输入以下代码:
import pandas as pd
df = pd.read_csv('data/Hive17.csv', sep=";")
df = df.dropna()
print(df.head())
最后,按屏幕右上角的 Run(运行)按钮,我们的代码将在 Python 控制台中运行,让我们了解数据会是什么样子。
4. 拟合数据点并在图表中检查
由于我们将使用 scikit-learn 中的 OneClassSVM,我们使用以下代码将其与 DecisionBoundaryDisplay 和 Matplotlib 一起导入:
from sklearn.svm import OneClassSVM from sklearn.inspection import DecisionBoundaryDisplay import matplotlib.pyplot as plt
根据数据描述,我们知道 T17 列代表蜂巢的温度,RH17 代表蜂巢的相对湿度。 我们将提取这两列的值作为输入:
X = df[["T17", "RH17"]].values
然后,创建并拟合模型。 注意,我们首先尝试默认设置:
estimator = OneClassSVM().fit(X)
接下来,我们将决策边界与数据点一起展示:
disp = DecisionBoundaryDisplay.from_estimator(
estimator,
X,
response_method="decision_function",
plot_method="contour",
xlabel="Temperature", ylabel="Humidity",
levels=[0],
)
disp.ax_.scatter(X[:, 0], X[:, 1])
plt.show()
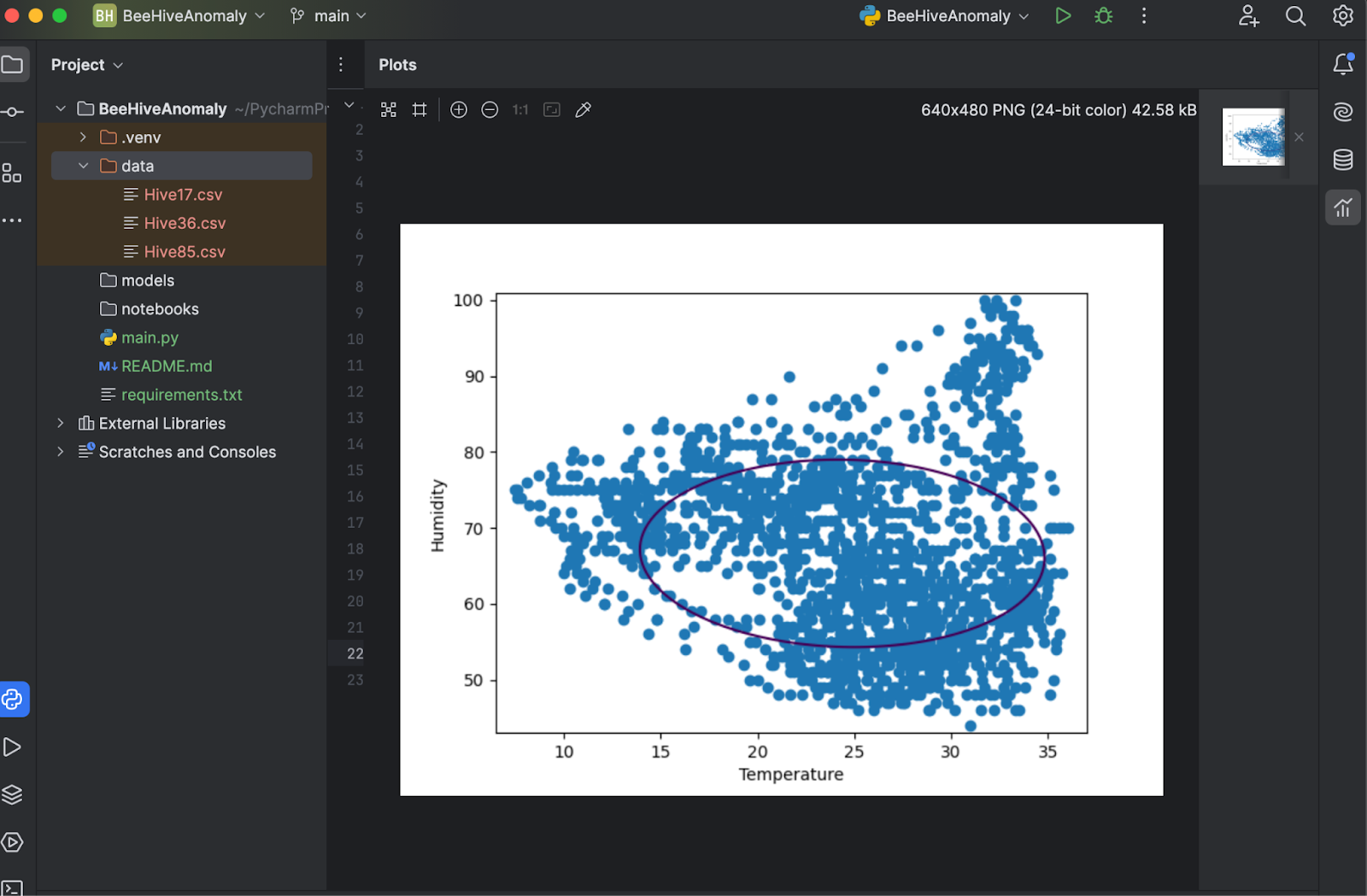
现在,保存并再次按 Run(运行),您可以看到绘图显示在单独的窗口中以供检查。
5. 微调超参数
如上图所示,决策边界与数据点并不十分拟合。 数据点由几个不规则形状(而不是椭圆形)组成。 为了微调我们的模型,我们必须为 OneClassSVM 模型提供“nu”和“gamma”的特定值。 您可以自己尝试一下,但经过几次测试后,似乎“nu=0.1, gamma=0.05”给出的结果最好。
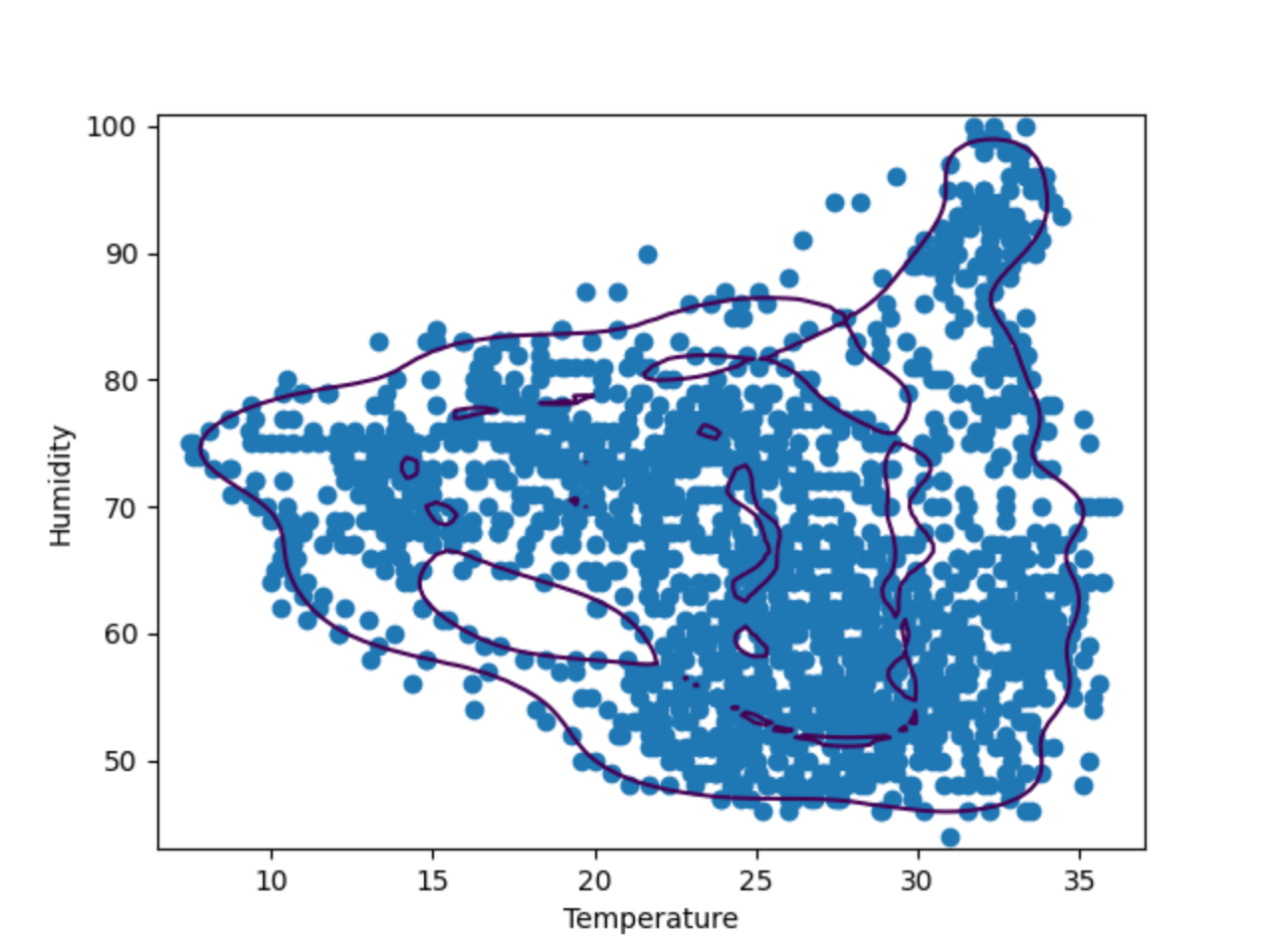
示例:孤立森林
孤立森林是一种基于集成的方法,类似于更流行的随机森林分类方法。 通过随机选择分离特征和值,它将创建许多决策树,然后从树的根到做出该决策的节点的路径长度将在所有树(因此称为“森林”)上取平均值。 较短的平均路径长度表示存在异常值。
现在,我们比较 OneClassSVM 和 IsolationForest 的结果。 为此,我们绘制两种算法做出的决策边界的图。 在后续步骤中,我们将使用相同的蜂巢 17 数据基于上述脚本构建。
1. 导入 IsolationForest
IsolationForest 可以从 Scikit-learn 中的集成类别中导入:
from sklearn.ensemble import IsolationForest
2. 重构并添加新的 estimator
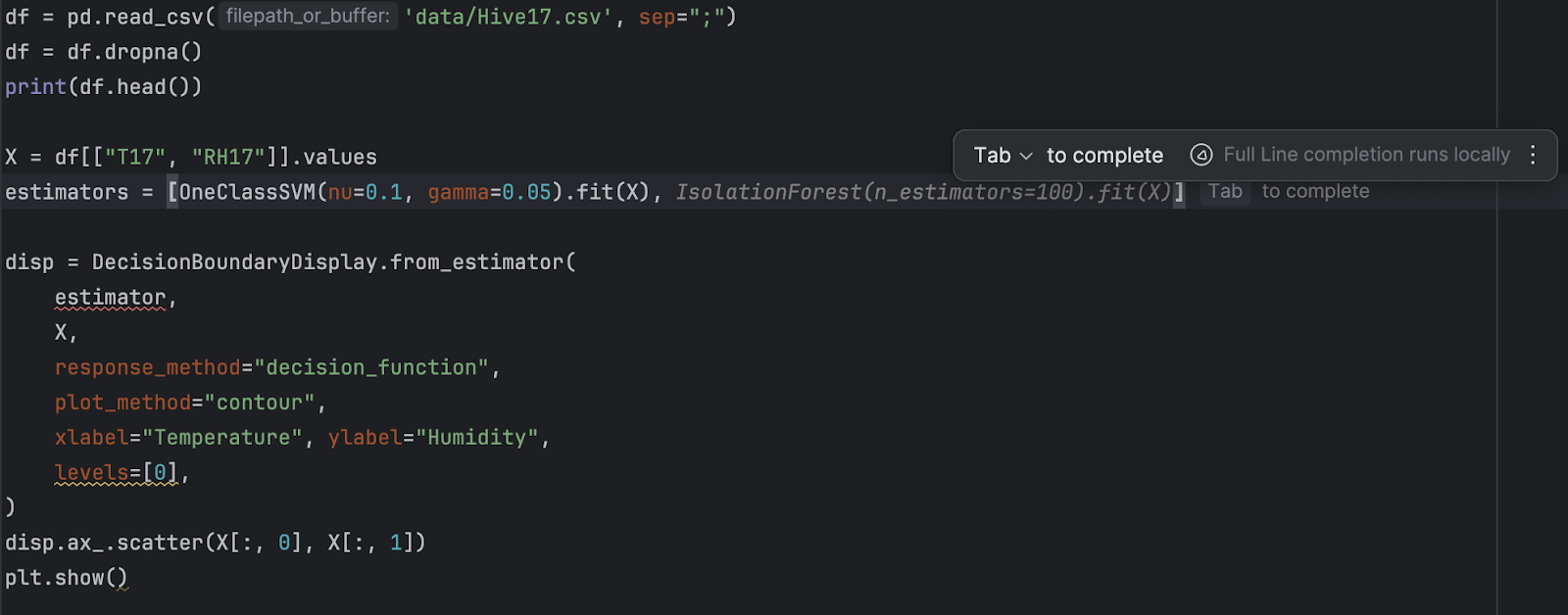
由于现在我们将有两个不同的 estimator,我们将它们放在一个列表中:
estimators = [
OneClassSVM(nu=0.1, gamma=0.05).fit(X),
IsolationForest(n_estimators=100).fit(X)
]
然后,我们使用 for 循环遍历所有 estimator。
for estimator in estimators:
disp = DecisionBoundaryDisplay.from_estimator(
estimator,
X,
response_method="decision_function",
plot_method="contour",
xlabel="Temperature", ylabel="Humidity",
levels=[0],
)
disp.ax_.scatter(X[:, 0], X[:, 1])
plt.show()
最后,我们为每个图表添加标题以方便检查。 为此,我们将在 disp.ax_.scatter 后添加以下内容:
disp.ax_.set_title(
f"Decision boundary using {estimator.__class__.__name__}"
)
您可能会发现,使用 PyCharm 的重构非常简单,因为它提供了自动补全建议。
3. 运行代码
和先前一样,按右上角的 Run(运行)按钮即可运行代码。 这次运行代码后,我们应该会得到两个图表。
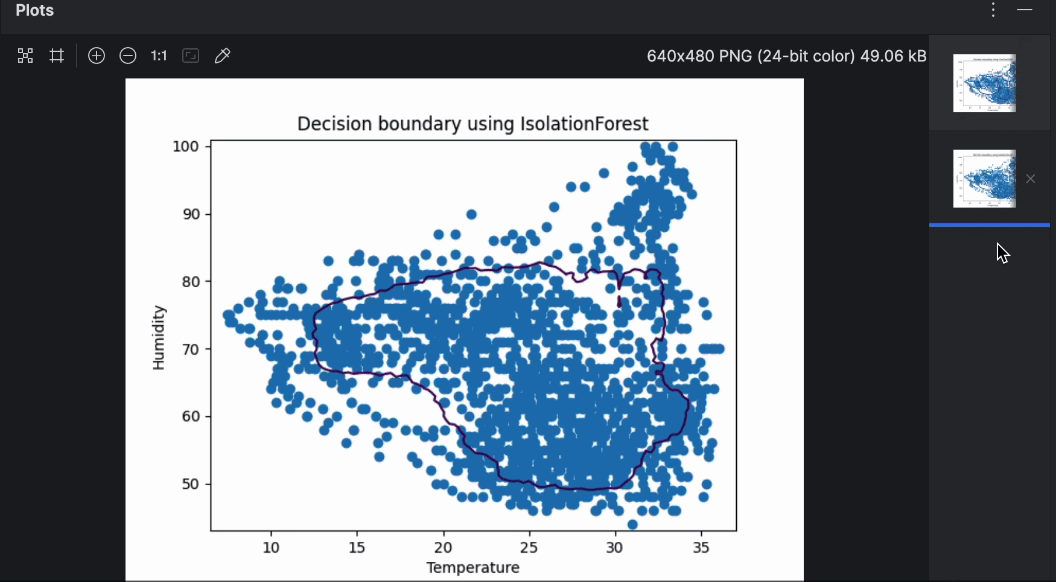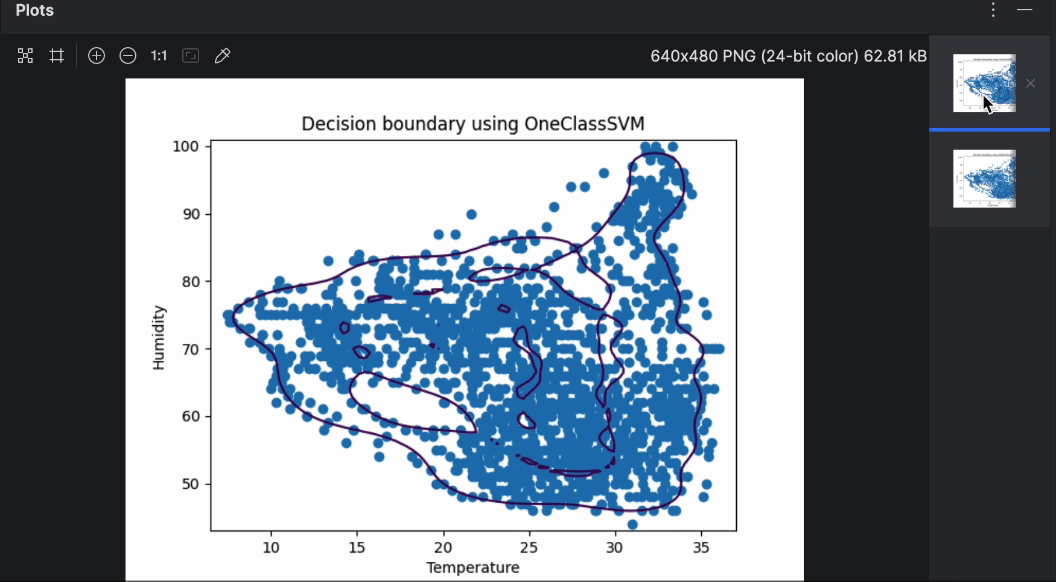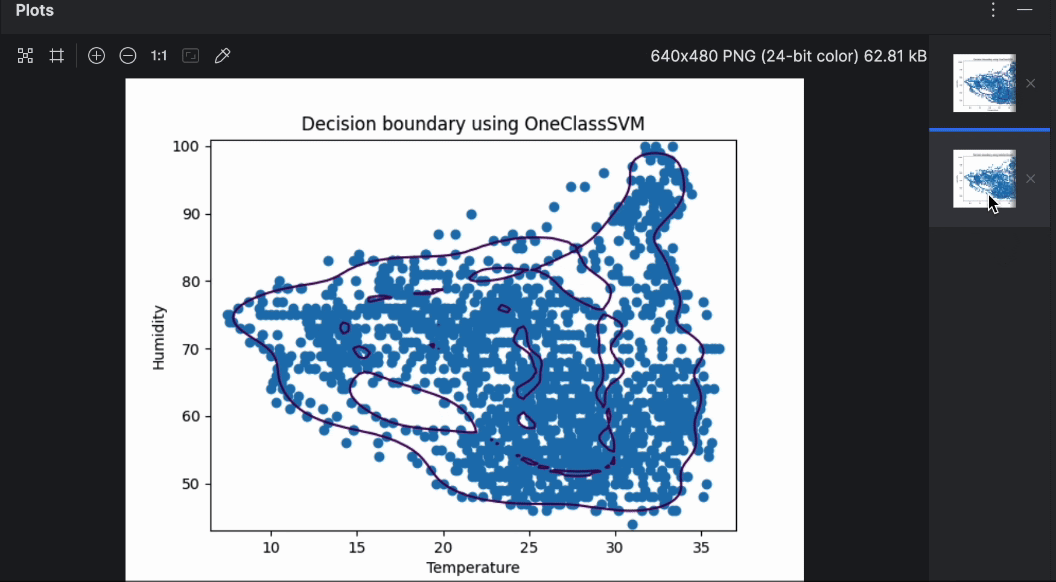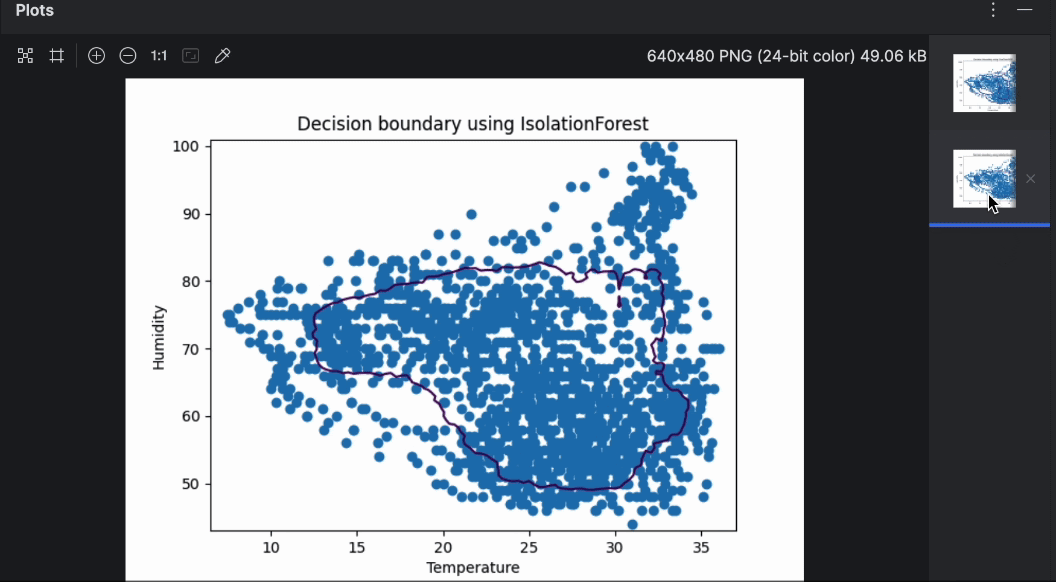
您可以通过右侧的预览轻松翻阅这两个图表。 可以看出,使用不同的算法时,决策边界有很大不同。 进行异常值检测时,值得尝试不同的算法和参数,寻找最适合用例的方案。
下一步:时间序列数据中的异常值检测
如果数据像我们的蜂巢数据一样是时间序列,那么还有其他方法可以找出异常值。 由于时间序列具有趋势和周期,任何不符合趋势和周期模式的值都可以被视为异常值。 检测时间序列异常值的流行方法包括 STL 分解和 LSTM 预测。
在这篇博文中,您可以了解如何使用这些方法检测时间序列中的异常值。
总结
异常值检测已被证明是商业智能的一个重要方面,在某些商业领域,识别异常值并立即采取行动至关重要。 使用合适的机器学习模型自动检测异常值有助于在短时间内分析复杂、大量的数据。 在这篇博文中,我们展示了如何使用 OneClassSVM 等统计模型识别异常值。
要详细了解如何将 PyCharm 用于机器学习,请参阅开始使用 PyCharm 学习机器学习和如何在 PyCharm 中使用 Jupyter Notebook。
使用 PyCharm 检测异常值
借助 PyCharm Professional 中的 Jupyter 项目,您可以轻松组织包含大量数据文件和 Notebook 的异常值检测项目。 在 PyCharm 中,可以生成图表输出检查异常值,并非常方便地查看绘图。 其他功能,例如自动补全建议,使浏览 Scikit-learn 模型和 Matplotlib 绘图设置变得非常容易。
使用 PyCharm 增强数据科学项目,查看为简化数据科学工作流而提供的数据科学功能。
本博文英文原作者:

Subscribe to PyCharm Blog updates





