

Big Data Tools
A data engineering plugin
Big Data Tools 2021.3.1 Is Now Available

We’ve just released a new build of the Big Data Tools plugin that is compatible with the 2021.3 versions of IntelliJ IDEA Ultimate, PyCharm Professional Edition, and DataGrip. The plugin also supports our new data science IDE, DataSpell.
In this release, we’ve introduced a number of changes to the user interface, added several features, and fixed a long list of bugs. Let’s take a closer look.
Kafka support
- Producer and consumer management in the Kafka connection tool window
This allows you to quickly test apps by providing test data or checking the contents of existing topics.
You’ll notice two additional buttons in the Kafka connection tool window: Add producer and Add consumer.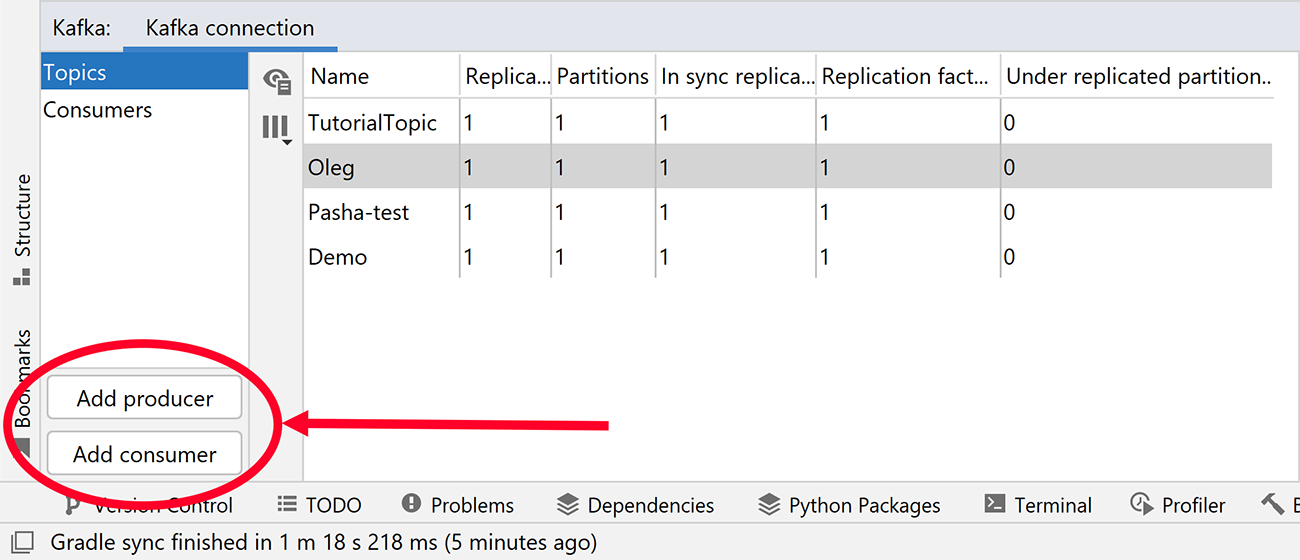
To produce test data, click the Add producer button, which opens a new editor tab. Simply fill in all the parameters (like the type of key and value) and click the Produce button.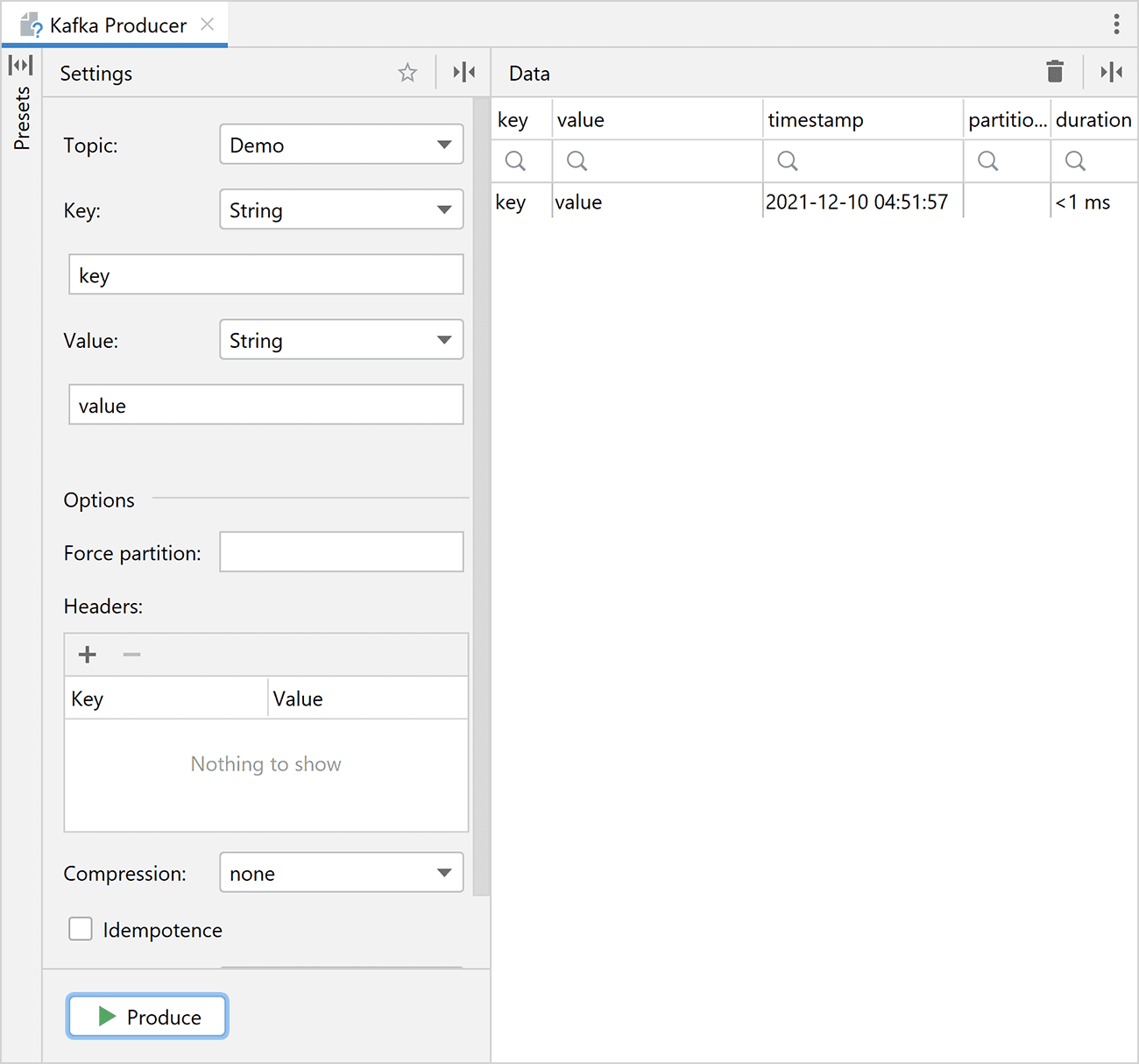
To collect the data, click the Add consumer button, pick your topic, format, and date range, and press Start Consuming. The consumer will run until you click Stop Consuming.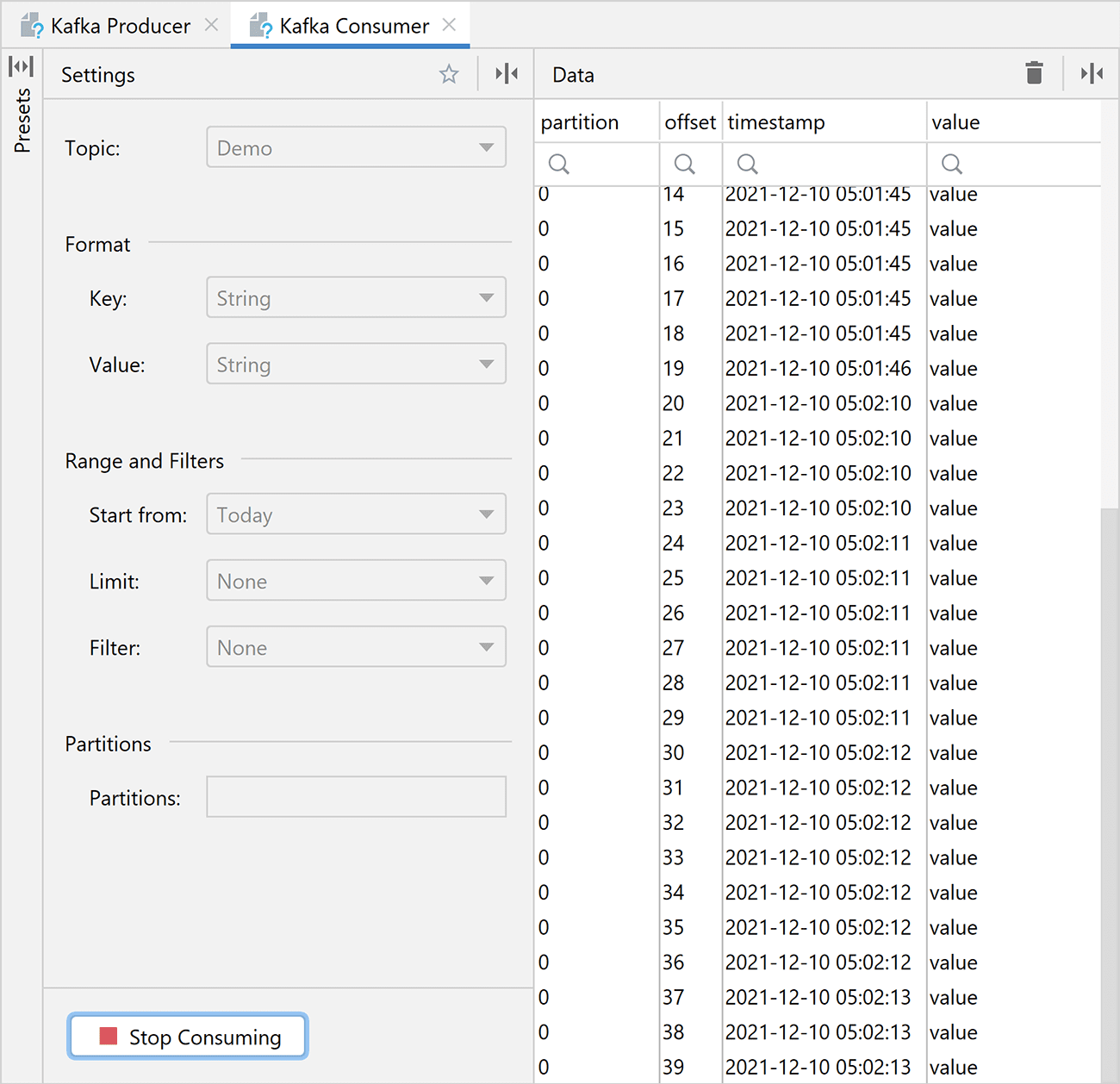
- Advanced Kafka properties configuration
The new Properties from dropdown allows you to select whether to write all the properties right in the connection settings or load them from an existing file: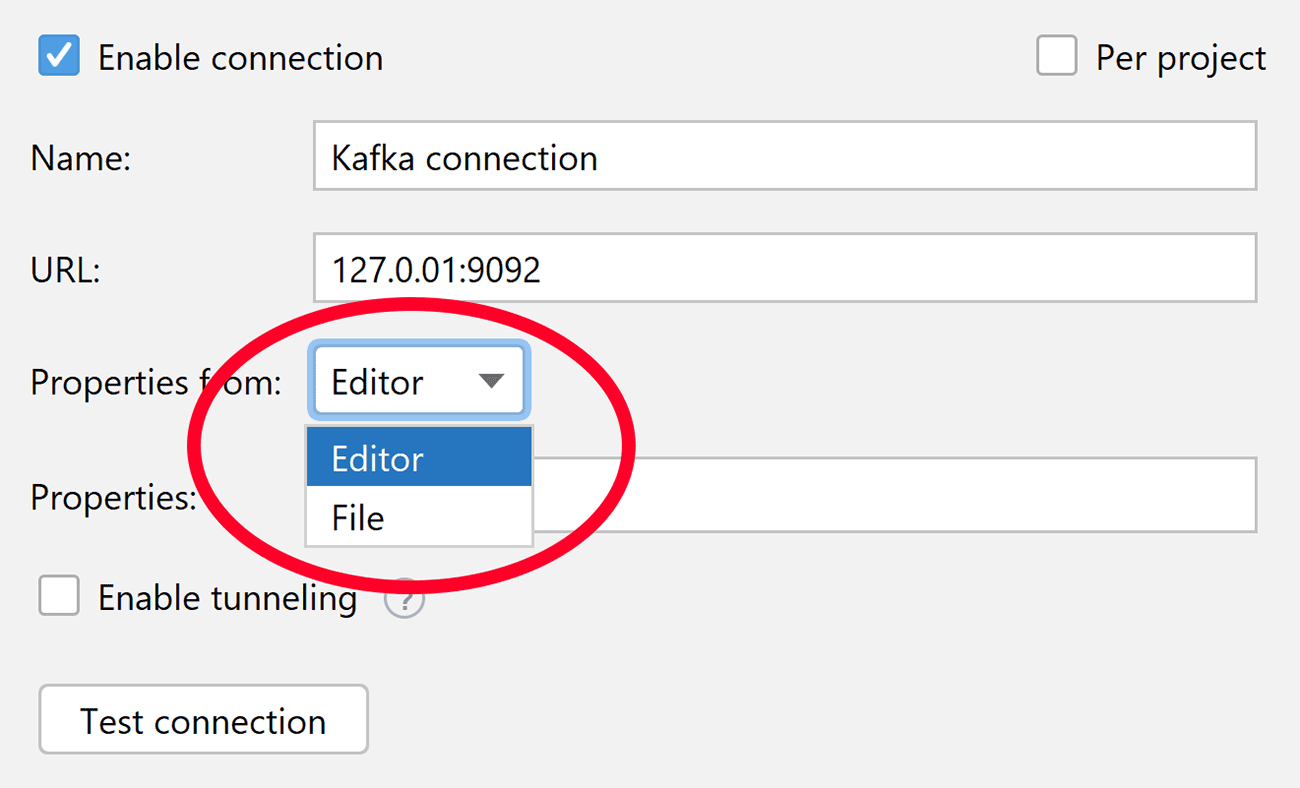
When Editor is selected, the window will provide automatic completion for the properties as you type them. Automatic completion is also provided for types and documentation: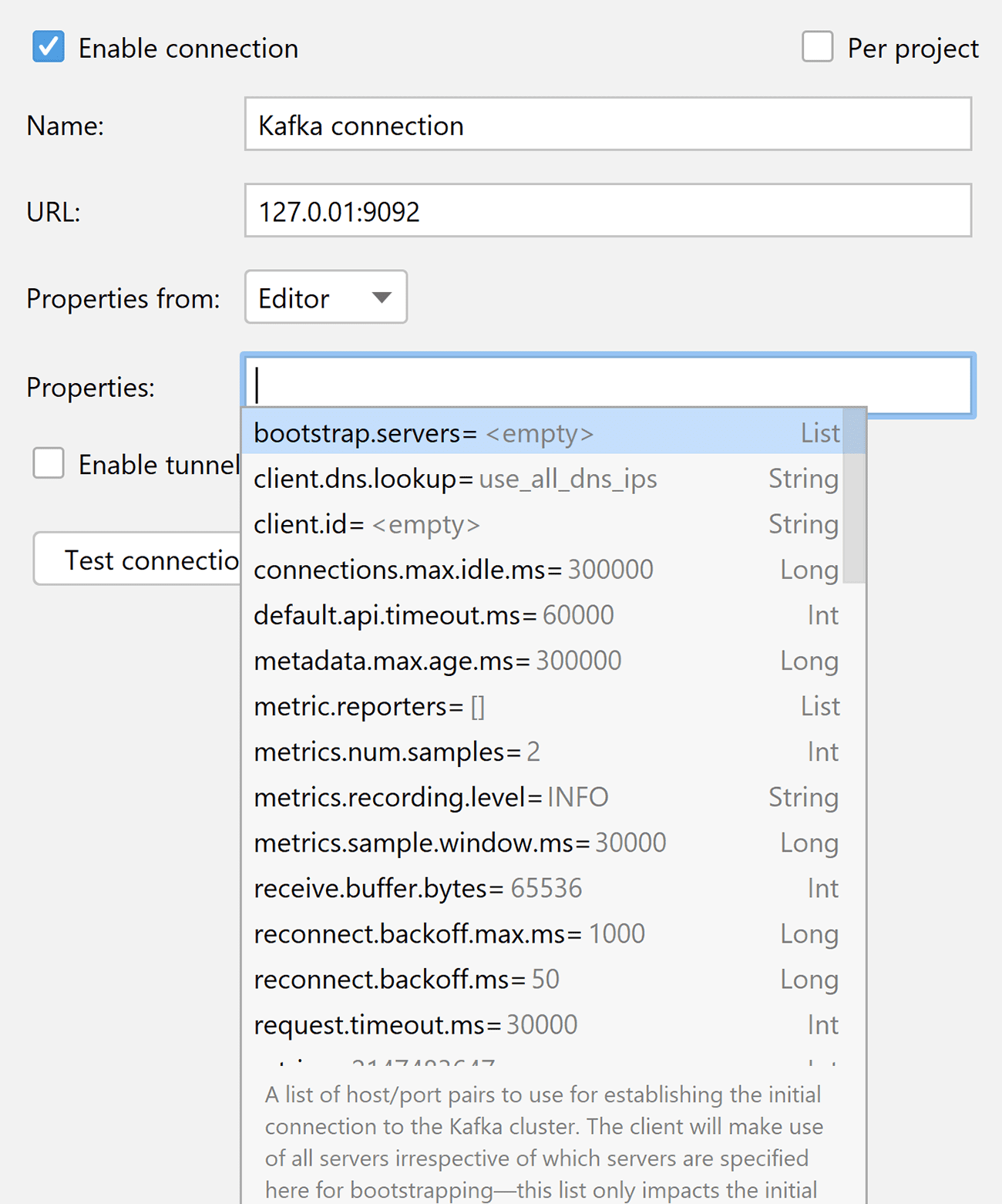
Remote file systems
- Multi-bucket support for S3-like connections (AWS S3, Linode, Digital Ocean Spaces, MinIO, and Yandex Object Storage).
This feature allows you to limit your preview to only the buckets that you actually use. In big production systems, you may have dozens of buckets, and now you can filter the list instead of creating different S3 connections to each one or scrolling through a long list.
In the new Connection Settings tab, you can now specify a bucket filter instead of a single bucket name. Multiple filter types are available: Contains, Match, Starts with, and Regex. If you leave the field blank, all buckets will be listed.
For example, let’s find all the buckets whose names start with “big-data-”: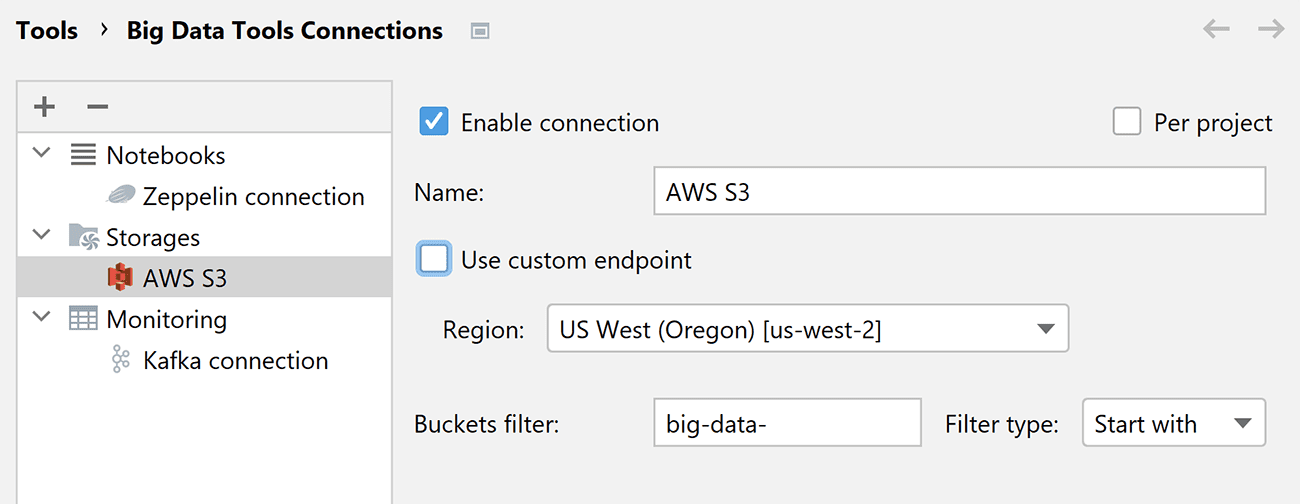
The result in the Big Data Tools tool window looks like this: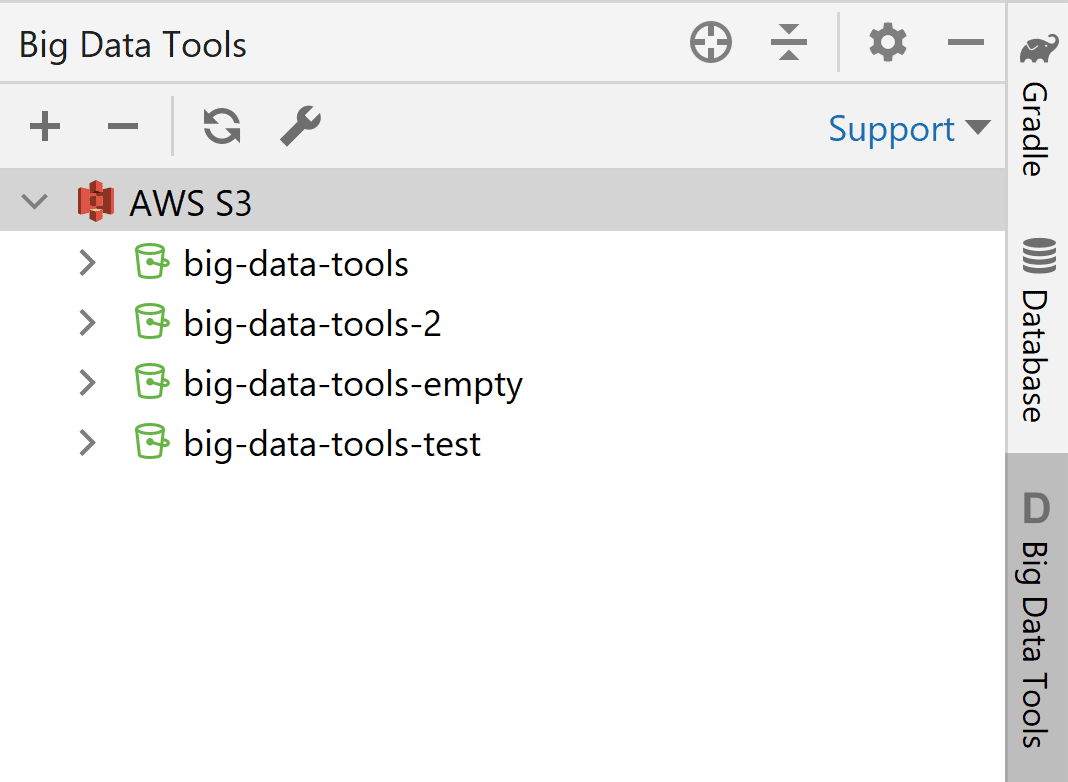
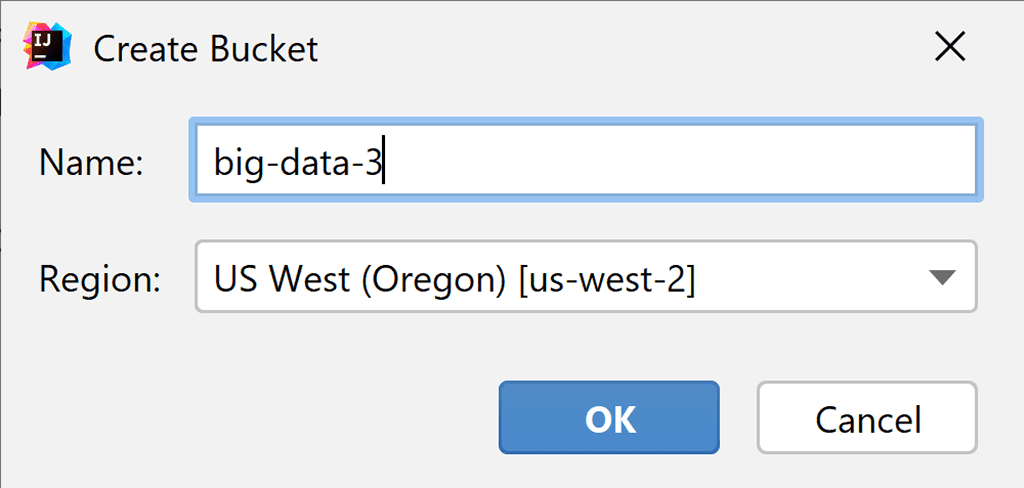
You can also create new buckets. Just right-click on the target server to open the context menu and type a name for the new bucket in the dialog window: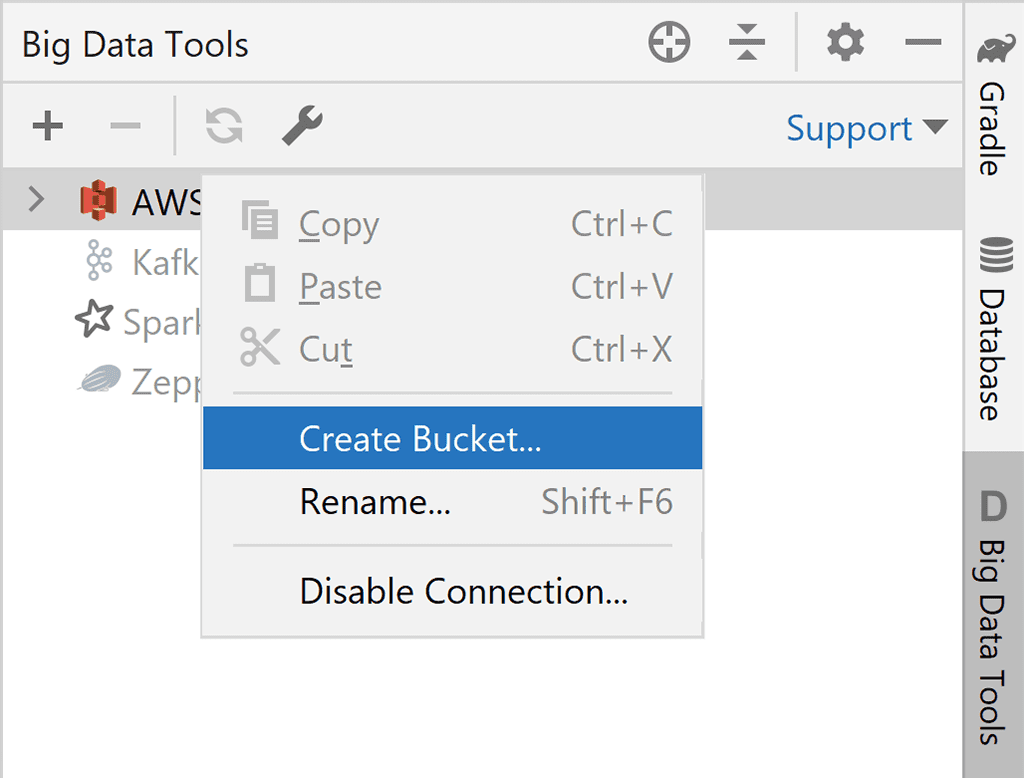
- Support for Yandex Object Storage, part of Yandex.Cloud
Yandex Object Storage is a universal scalable cloud object storage solution that provides a variety of benefits, including compatibility with the Amazon S3 API, replication across multiple availability zones, autoscaling, and advanced security. - New file system: SFTP
SFTP is the de facto standard for working with remote files.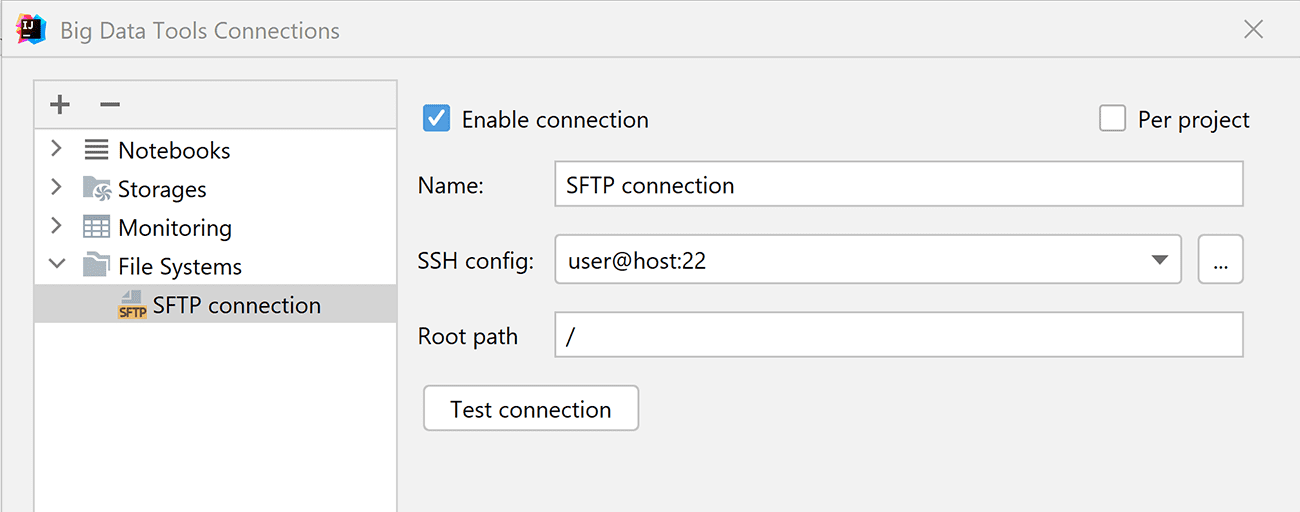
You can establish a new SSH connection to this server from the Connections context menu: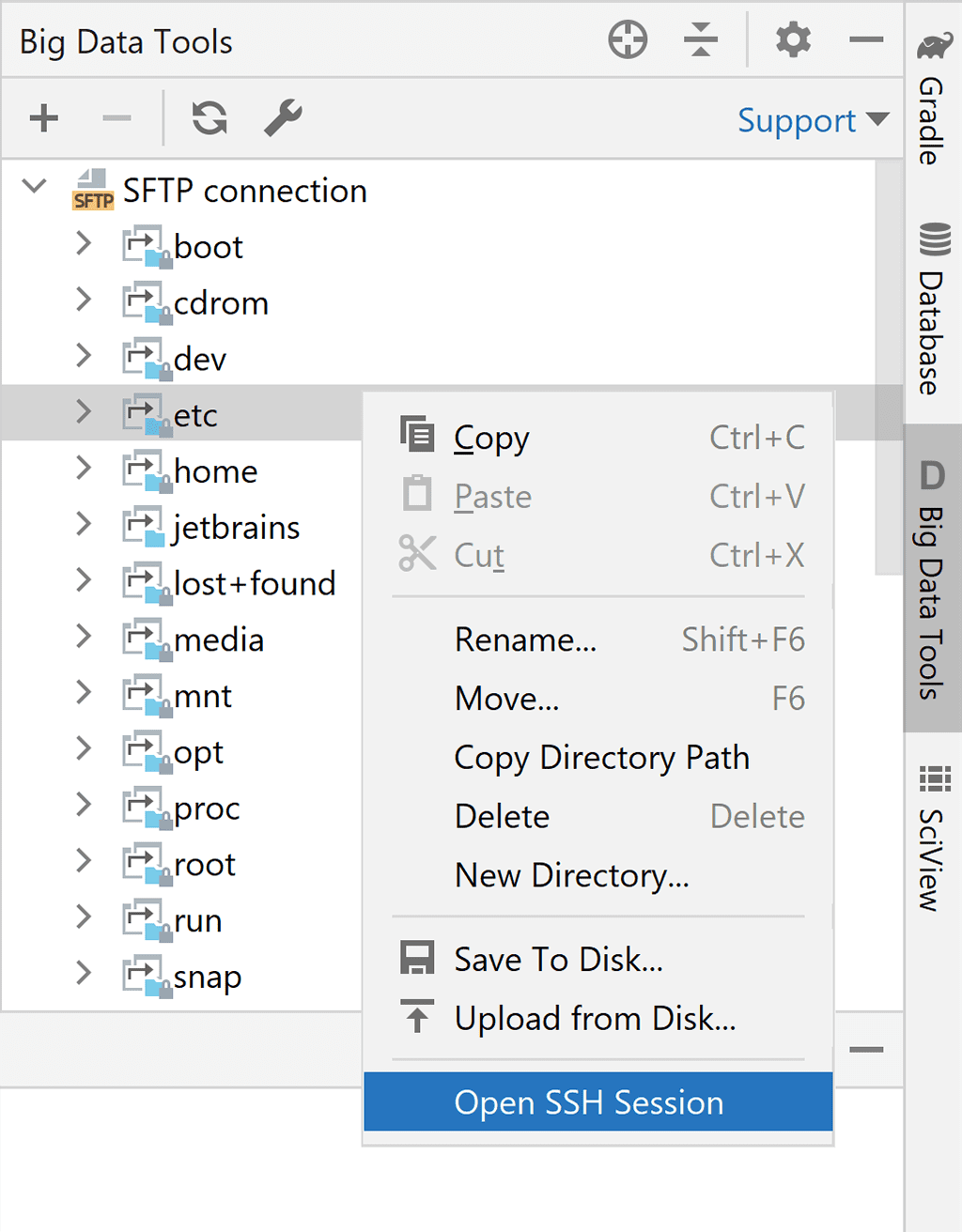
The terminal will automatically change the current directory.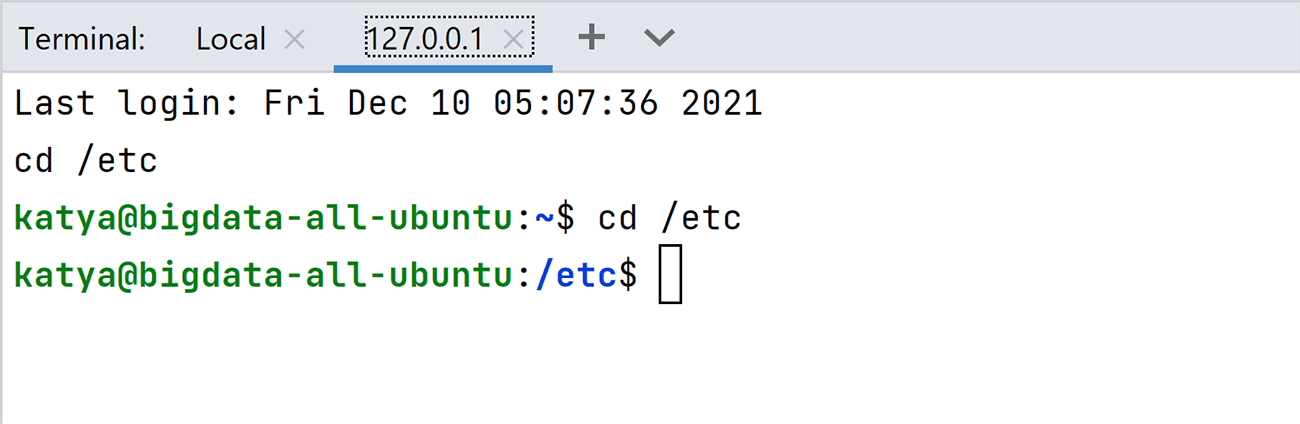
- Proxy support for Google Cloud Storage
A proxy server acts as an intermediary between your client computer and Google storage servers. You can use proxies to access Google Cloud from a secure corporate network or any other network without direct internet access. You have always been able to connect to AWS via proxy, and now you can do the same for Google Cloud Storage connections.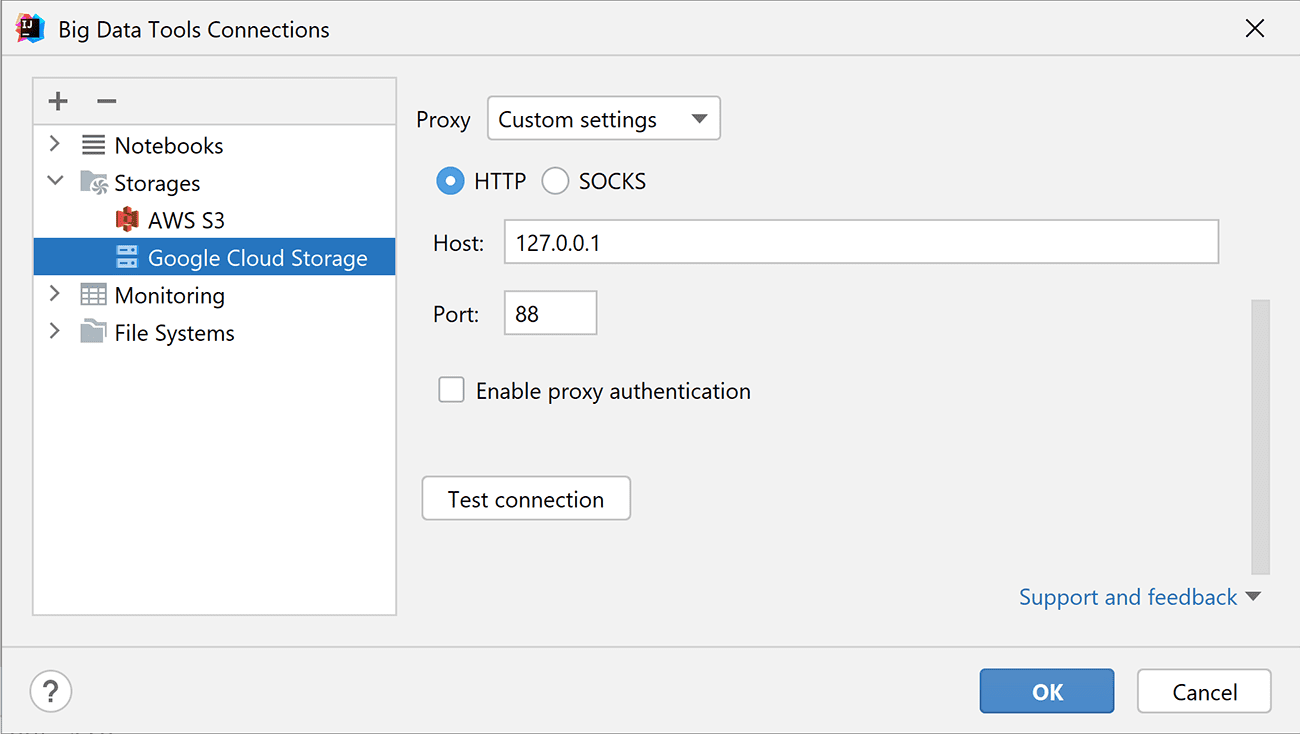
- You can now edit text files
At the top of the editor window, you’ll see a panel where you can compare the selected file with the remote copy of it and sync changes: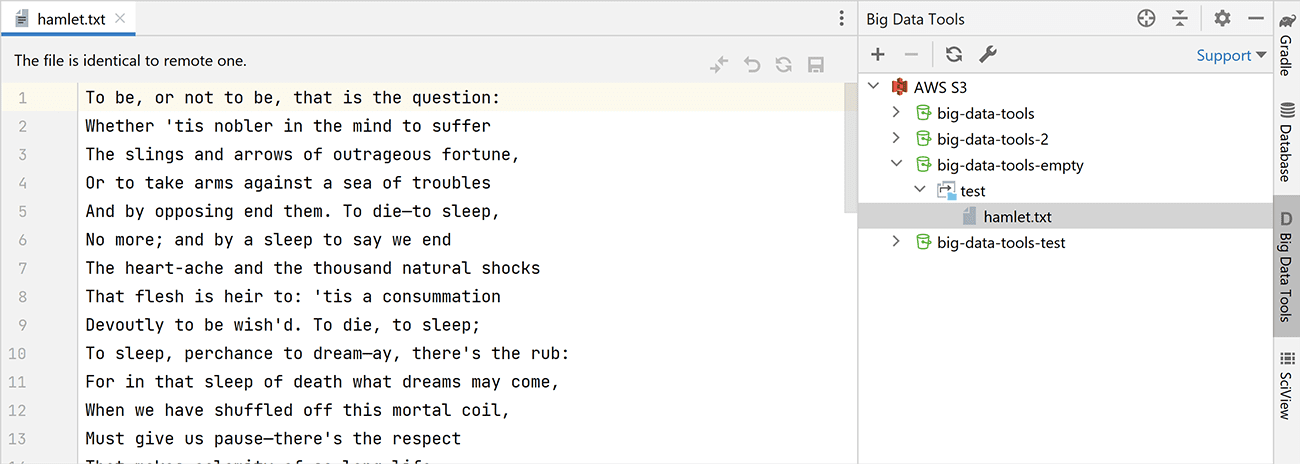
This feature is available for all file systems and cloud storage solutions, but it’s not available for Zeppelin notebooks. - Extended file info for CSV, ORC, Parquet, and text files
When you check the file schema for files in a tabular format, including CSV files,
you will now have access to additional metainformation provided by cloud storage solutions (like e-tag for S3). Azure, S3, and GCS connections are supported, as well.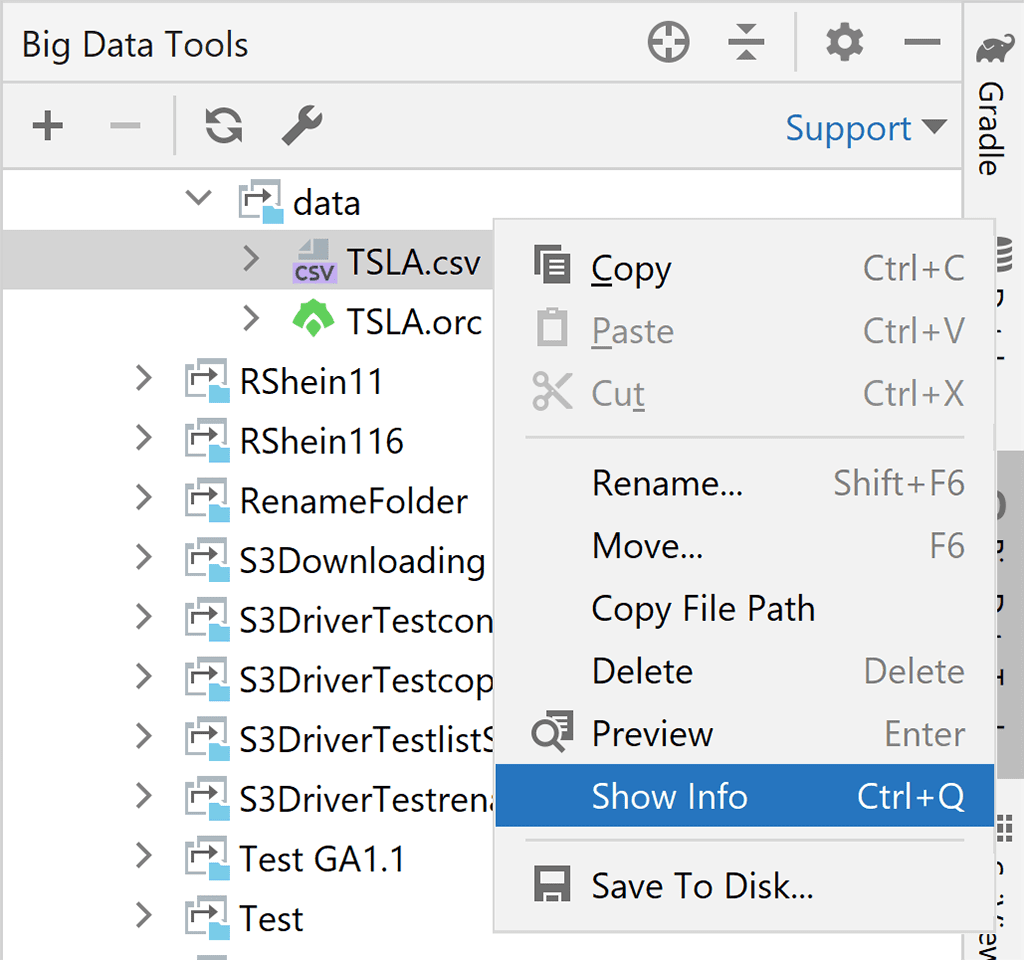

Zeppelin support
- Major changes to the ZTools implementation (“ZTools Light”)
We’ve completely redesigned our approach for communicating with Zeppelin servers, which has allowed us to implement additional features and stop using dependencies. The new implementation is called “ZTools Light”, and it works for Spark and PySpark. - Use ZTools without installing additional dependencies on your server
Production Zeppelin instances used to pose real problems because users had to persuade their server administrators or corporate security personnel to install custom dependencies on their servers. Now, however, this is no longer necessary, which is a significant step towards being able to use ZTools in banking, healthcare, and other major industries. - Only DataFrames and Datasets in the ZTools tool window
Because we found that users needed to look at local variables only rarely, if ever, we removed this feature altogether.
In previous versions, local variables were collected by a custom dependency installed on your Zeppelin server. But the no-dependency approach is the clear winner over the use of local variables. - New options for ZToolssettings
- You can disable automatic refreshing so variables will be updated only when you click the Refresh button.
- You can filter dataset schemas and SQL metadata, allowing you to see only what’s relevant to the current Zeppelin note.
These options are located under the Zeppelin Connection Settings tab.
- Search Zeppelin notebooks by ID and URL
While working in a browser, you may occasionally want to return to the notebook inside the IDE. You can now copy the URL or ID (which is included in the URL) and paste it into the IDE’s global Search window.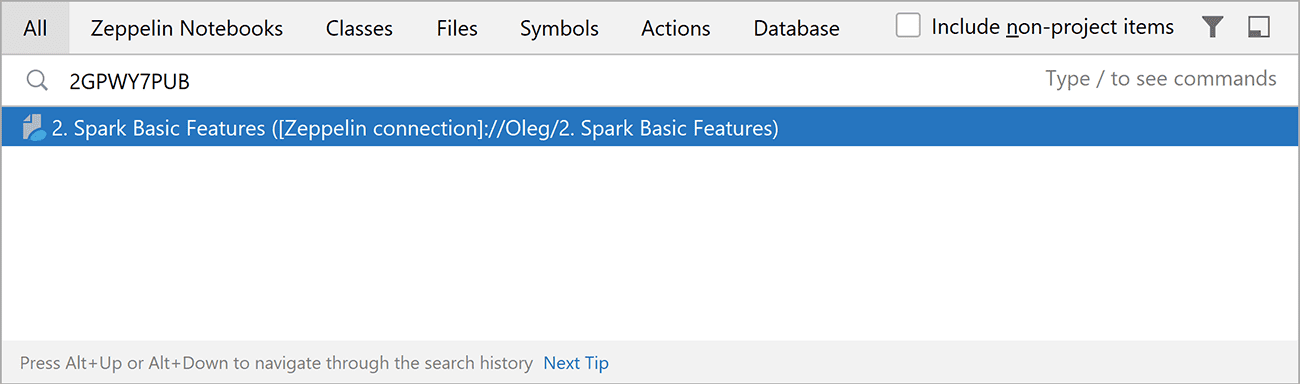
Spark support
- Parsing existing Spark commands
If you have a spark-shell command and don’t want to fill in dozens of fields in Spark Submit configurations, here’s a trick. You can click this button: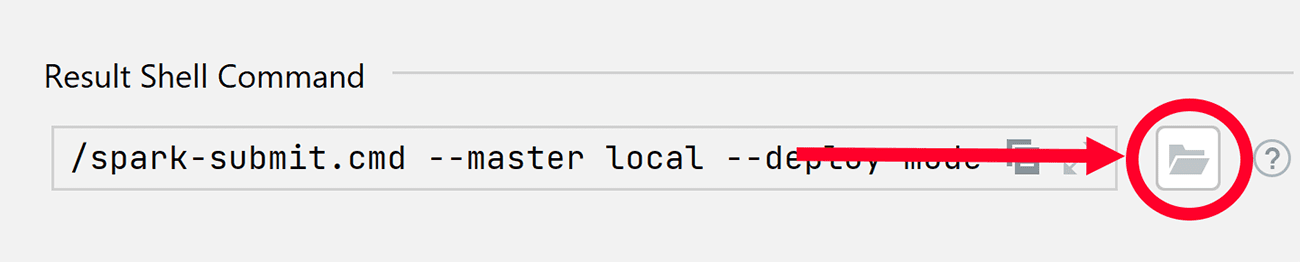
And paste your command into the dialog window that appears: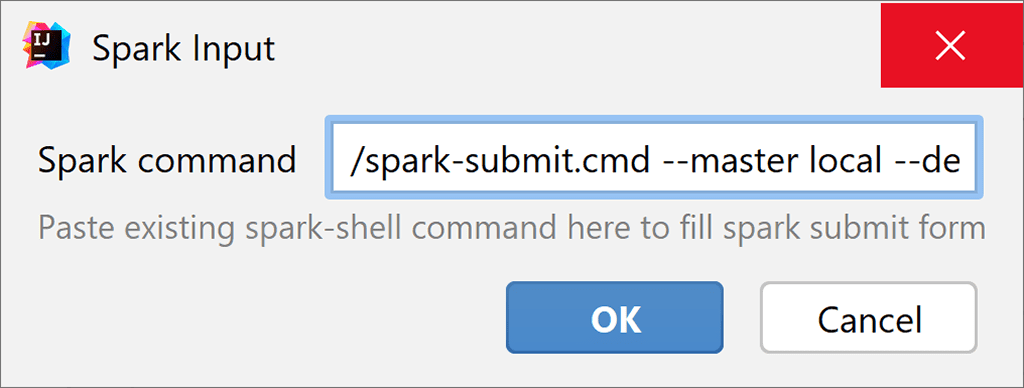
Now your Spark Submit run configuration uses the same settings as your original command. - Rearranged fields in Spark Submit run configurations
The fields in the Spark Submit run configuration window have been rearranged so the most important information appears at the top of the list. Some options were moved into the Advanced Submit Options section. Additionally, you can now see short hints for the fields.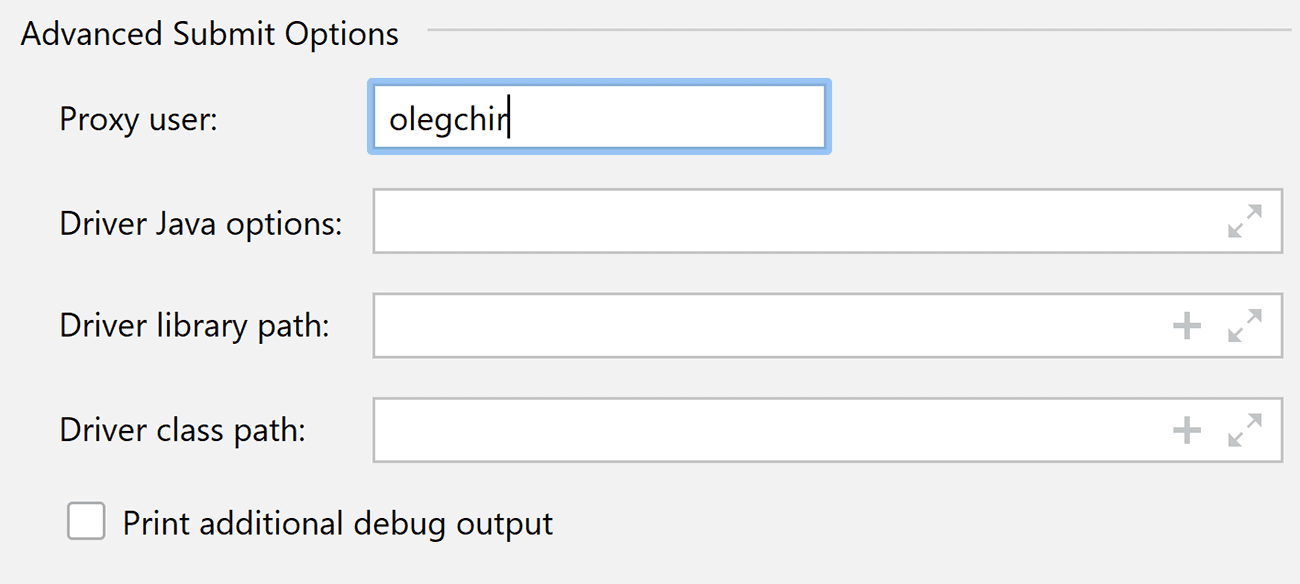
- Executor metrics in the Spark Monitoring tool window
The Executors tab in the Spark Monitoring tool window has been upgraded. It now looks similar to the Web UI and displays extended information about active and dead executors (e.g. their maximum memory, failed tasks, and so on).
Other
- Changelog inside the plugin update popup
The changelog will now only display the most important new features in a release, rather than all of the changes.
Documentation and social networks
For an overview of the key recent improvements, please visit the What’s New section of the plugin page. You can also review the full report on YouTrack, which includes just about all of the release notes.
Don’t forget to check out our Tips of the Day when you load up the IDE. They now include a few tips that are specific to Big Data Tools.
You can upgrade to the latest version of the Big Data Tools plugin from your browser, from the plugin page, or right in your IDE. If you’re looking for more information about how to use any of the plugin’s features, check out the IntelliJ IDEA, PyCharm, DataGrip, or DataSpell documentation. Need more help? Leave us a message on Slack or a comment on Twitter.
We’re actively developing and enhancing the Big Data Tools plugin, and we’re doing our best to process your feedback and fix as many bugs as possible. We encourage you to leave your thoughts and suggestions on the plugin page, and we will work to address them in future releases.
We hope that these improvements will help you tackle bigger and better challenges – and have more fun in the process! Thank you for using the Big Data Tools plugin!
The Big Data Tools team




