C++ Annotated January 2022: C++20 to Eliminate Runtime Bugs and Achieve Better Design, Full Test Coverage, and a New QML Compiler

We have all of the January news for you in our latest monthly C++ Annotated digest and its companion, the No Diagnostic Required show.
If you have already subscribed, feel free to skip straight to the news. If this is your first time here, let us quickly take you through all the formats we offer. You can read, listen, or watch our essential digest of last month’s C++ news:
- Read the monthly digest on our blog (use the form on the right to subscribe to the blog).
- Subscribe to C++ Annotated emails by filling out this form.
- Watch the No Diagnostic Required show on YouTube. To make sure you hear about new episodes, follow us on Twitter.
- Listen to our podcast – just search for “No Diagnostic Required” in your favorite podcast player (see the list of supported players).
Watch our January episode or read the digest below:
January news
- Language news
- Learning
- Tooling
- And finally
Language news
This month was the WG21 plenary call. These are the events that usually happen on the last day of a physical gathering of the committee, and are where the official votes for what is adopted into the working draft for the next standard take place. This time the event was especially significant as it was deemed the cutoff deadline for new designs for C++23.
There were 17 papers approved for adoption in this session. 14 of them were library papers, of which 6 related to ranges – an indication of how important ranges are in the C++23 priority list. In fact there is an overarching paper, P2214, “A Plan for C++ Ranges”, that spells out what we were aiming to get in for C++23, and at this point a significant chunk has made it.
Let’s have a look at a couple of the ranges papers that were just adopted.
P2441R1 – “views::join_with”
Many higher-level languages, Python for example, give you an easy way to take a collection of items and join them up into a single item, usually a string. For strings, in particular, this is usually accompanied by the ability to specify a delimiter, such as a comma.
In C++20 we got the first part with the views::join range adapter, but this lacked the delimiter feature. views::join_with fixes that, and it works for any range, not just collections of strings.
P2387R3 – “Pipe support for user-defined range adaptors”
Talking of ranges, the built-in range adapters can be composed using the pipe operator. For example (from cppreference):
auto const ints = {0,1,2,3,4,5};
auto even = [](int i) { return 0 == i % 2; };
auto square = [](int i) { return i * i; };
for (int i :
ints |
std::views::filter(even) |
std::views::transform(square)) {
// …
}
In general, this allows a transformation where a call to a range adapter f(x) can be written as x | f. Functional programmers will be familiar with this type of transformation, usually as a general language feature.
But if you supply your own range adapters, this didn’t work out of the box in C++ … until C++23.
Now, with a little support code to hook up to some customization points, your own range adapters can take part in this functional lifestyle.
P0323R11 – “std::expected”
We mentioned this just last month, so it’s not unexpected, but std::expected has now been officially voted into the working draft for C++23.
We won’t go over it again this month – refer back to last April’s coverage for more details – but it’s noteworthy because this was the only library feature accepted in this time that was labeled a “large” feature.
P0627R6 – “Function to mark unreachable code”
This proposal solves the halting problem. Well, it’s more of a workaround, really. There are times when the compiler can’t predict with certainty that a particular line will never be reached, but the programmer does know (at least in the absence of bugs). That may have consequences – from noisy compiler or static analysis warnings, to suboptimal code as the compiler has to generate redundant checks and other unnecessary code. A common example might be a switch statement over an enum which is either exhaustive or which the programmer knows will only ever be reached with certain values.
Many compilers have had implementation specific intrinsics to allow the programmer to annotate this for some time. For example, __builtin_unreachable() is provided by GCC, Clang, and Intel C++. In Visual Studio you can write __assume(false).
As a valuable, widely provided-by-extension feature, it makes sense to provide a standard (and therefore portable) version. That’s what this paper specifies: std::unreachable().
But there are some extra considerations. As hinted at by the Visual Studio workaround, there is an interplay between reachability and assumptions. In fact it turns out you can implement either in terms of the other! Whether you spell it __assume(false), __builtin_assume(false), [[assert axiom: false]], or [[assume(false)]], it’s easy to see how “unreachable” can be implemented in terms of assumptions. But the other way around works, too:
if( !condition ) std::unreachable();
This, effectively, has the same meaning. So was it a race between this paper and P1774 (Portable Assumptions) as to which one would make it in first (a race that P0627 appears to have won)? Not necessarily. There is still a lot of value in more accurately expressing your intention. This applies to human readability, of course, but also to the compiler! Section 2.1 of P1774 cites an example where using __builtin_unreachable() pessimizes a certain case with GCC, whereas compilers that have something like __builtin_assume() are more optimal.
But until P0627, or a similar proposal, is adopted into the standard, std::unreachable may form the basis for a portable assumptions workaround.
C++20 to eliminate an entire class of runtime bugs
Cameron DaCamara wrote a great story about eliminating runtime bugs caused by format specifiers. This problem was occurring in MSVC code when printing compiler error messages that are enhanced with extra information passed via format specifiers.
The problem with format specifiers is that they are not type-checked in the call to error. Users might get into trouble with the runtime error if the compiler’s developers mistakenly pass the wrong argument or don’t pass one at all.
The compiler team looked into this problem, initially armed with C++14/17. The solution was to check the format specifiers at compile time. This approach fell short, however, because it was impossible to make an error call constexpr and pass template parameters to it. It required updating the whole codebase, which was unacceptable.
With C++20, MSVC developers acquired new language tools to protect themselves from these runtime issues. They took a similar approach to the one taken in the fmt library, which didn’t require touching any call sites. Consteval is used for the constructor of the user-defined type to evaluate strings at compile time. As a result, the compile team managed to identify about 120 problematic calls. Sounds like a great number covered!
Interestingly, in the comments there was a discussion about why we shouldn’t restrict types by using a concept. As the blog post author noted, concepts help you make better guesses about the semantics of the types being passed into a function. In this case, the semantic is stored in the format string itself, so compile-time constraints work better. What about you? Do you also have any similar stories?
100% test coverage
Let’s dig into a discussion about testing and test coverage. According to the JetBrains Developer Ecosystem Survey from 2021, 30% of developers don’t write unit tests for C++. The rest are doing some unit testing, but are they reaching full coverage? This article is not a technical overview of lcov, gcov, or any other coverage tools; it’s more like an invitation to a discussion. It raises questions about what full coverage actually means. Does it mean 100% of code lines? There are various reasons why you might want to exclude parts of the codebases from such reports, and tools often include the option to do so. Is it a report from one specific run? When collecting coverage reports, you’re not limited to just one test loop. Reporting can cover an entire testing pipeline, where unit and integration test reports are merged.
Who benefits from this? Participants in the code reviews and QA engineers. They see which parts are more vulnerable and require a deeper dive in manual testing or a more careful review process. Full coverage doesn’t replace manual testing, but rather directs it.
Do you aim for full coverage in your projects? Share your thoughts in the comments.
How to iterate through std::tuple
A new article from Bartlomiej Filipek on the C++ stories blog talks about the techniques used to run through all of a tuple’s entries. The example used to demonstrate the approaches is a simple printTuple function.
A tuple has a variable number of elements, which you can access via std::get by index or by type as a template parameter for the function call. Values and types are set at compile time. We also want to build a compile-time loop to solve our printing task.
The first approach presented in the article saves some typing by passing decltype to deduce the type of tuple itself, but the indices are still passed manually. To automate the latter, the author suggests using std::index_sequence (built over std::integer_sequence) and std::tuple_size. Based on that, a nice stream output function is written.
In the next chapters, the author promises more complicated examples allowing value transformations. A paper on a compile-time loop is mentioned, which could make life much easier, but it’s unlikely to appear in C++23.
Migrating to a safer API with {fmt} 8.x
A new blog post from Victor Zverovich discusses a few interesting examples of when migration to {fmt} 8.x eliminated several classes of bugs and made the code safer. The main drivers are the compile-time format string checks, which are now enabled by default, and stricter pointer diagnostics and [[nodiscard]], which are used to annotate formatting functions.
[[nodiscard]] annotations help with a family of cases where the format string is created but not used by mistake. Compile-time format string checks help in many cases, like when the format specifier is not implemented. This is now detected at compile time, which
is much better than throwing a format_error upon running. Check out more interesting cases in the original article!
Finding the second largest element in a range
This article might sound like the type of test task assigned during a job interview process. At the same time, it’s a typical problem that many programmers have to solve in the course of their everyday lives. There could be various requirements, and it’s also interesting to discuss how they affect the solution.
If you can’t modify the range, the two obvious solutions are as follows: (1) Iterate through the range while updating two variables to store the 1st and 2nd largest values, or (2) Iterate twice via std::max_element function call (the first iteration finds the maximum element and the second one looks for the maximum element that is smaller than the element found during the first iteration, with the first call using a lambda as a third argument to the function).
If you are allowed to modify the range, you can make the code a lot shorter by partially sorting the range. (3) The std::nth_element function guarantees that the element placed in the n-th position is exactly the same element that would occur in this position if the range was fully sorted. For us, n is equal to 2 and the sorting should go from biggest to smallest. Alternatively, (4) you can use std::partial_sort, which sorts the range from first to middle arguments while leaving the latter half of the arguments in an unspecified order. We only need to sort the two largest elements in the range. The partial sorting approaches, however, fail if the maximum element appears multiple times.
The article also includes the performance measurements for the described solutions.
The evolution of std::equal_range
The evolution of std::equal_range described by Jonathan Boccara in his blog post shows how a good design can be achieved. The main issue with the good old C++98 equal_range is that it returns a pair of iterators. This pair is a “range” only because of the specific implementation. The semantic of the range is missing.
A few improvements can be made to the code with auto from C++11 and structured bindings from C++17. The solution looks much better but the abstraction is still wrong.
It wasn’t until we started using C++20 where equal_range was finally able to return an object that is a range. The Ranges library, finally living up to its name in this version of C++, provides the necessary function.
Compile time code generation and optimization
There are situations where you want to specify something in a different language at compile time, and have it executed at compile time, such as a DSL. In his blog, Jonathan Müller shows how you can achieve that. The sample case is a compiler that can parse a Brainfuck program given as a string literal, and the execution also happens at compile-time. The goal is to show the power of constexpr.
The solution starts with a VM operating on an array of instructions. The program is known at compile time so the array size is fixed. The first implementation has parsing happening entirely at compile -time, but execution at runtime. The execute function is then converted from the switch-case operator to tail recursion. Then the author made an observation that the arguments of the recursive call can be computed at compile time, so the recursive execute function calls are turned into template instantiations with the program passed as a template parameter. Now everything happens at runtime and the generated assembly (the links to Compiler Explorer are provided in the blog post) confirms that everything works as expected.
The new Qt Quick Compiler
In January, the Qt blog introduced a series of articles on one of their new projects – the Qt Quick Compiler for QML. The goal is to increase the compilation speed so that QML runs at a speed close to native. It’s important to remind the readers that QML is an interpreted language, so there is a performance cost. The technology preview has started for Qt commercial customers, targeting not only the compiler but also tools that will help transform the code to achieve better performance.
Among other blog posts on the new compiler, the one about the technology is especially interesting. The path to a new Qt Quick Compiler started from compiling QML scripts into C++ and using QML engine’s private API. The next step was targeted at specifically optimizing the run-time aspect. For this, a caching approach was used and the byte code representation for each function and expression was stored and bundled into the binary. Interestingly, this worked better than C++ code generated by the old Qt Quick Compiler. The reason is that, compared to the extremely generic code generated, the interpreter comes with the run-time knowledge of the Qt metatype system, so it can reduce the type checking overhead.
The third step was obvious, following the logic and the problem described earlier of code being too generic. A way to declare the QML types together with the C++ types backing them was suggested, as well as the possibility of providing type information in function signatures. Later, the CMake API for building QML modules was introduced to sort out the QML file locations.
All of these ideas were later joined in the new Qt Quick Compiler, which consists of two parts:
- The QML Script Compiler to compile functions and expressions in QML files of an application into C++ code.
- The QML Type Compiler to compile QML object structures into C++ classes.
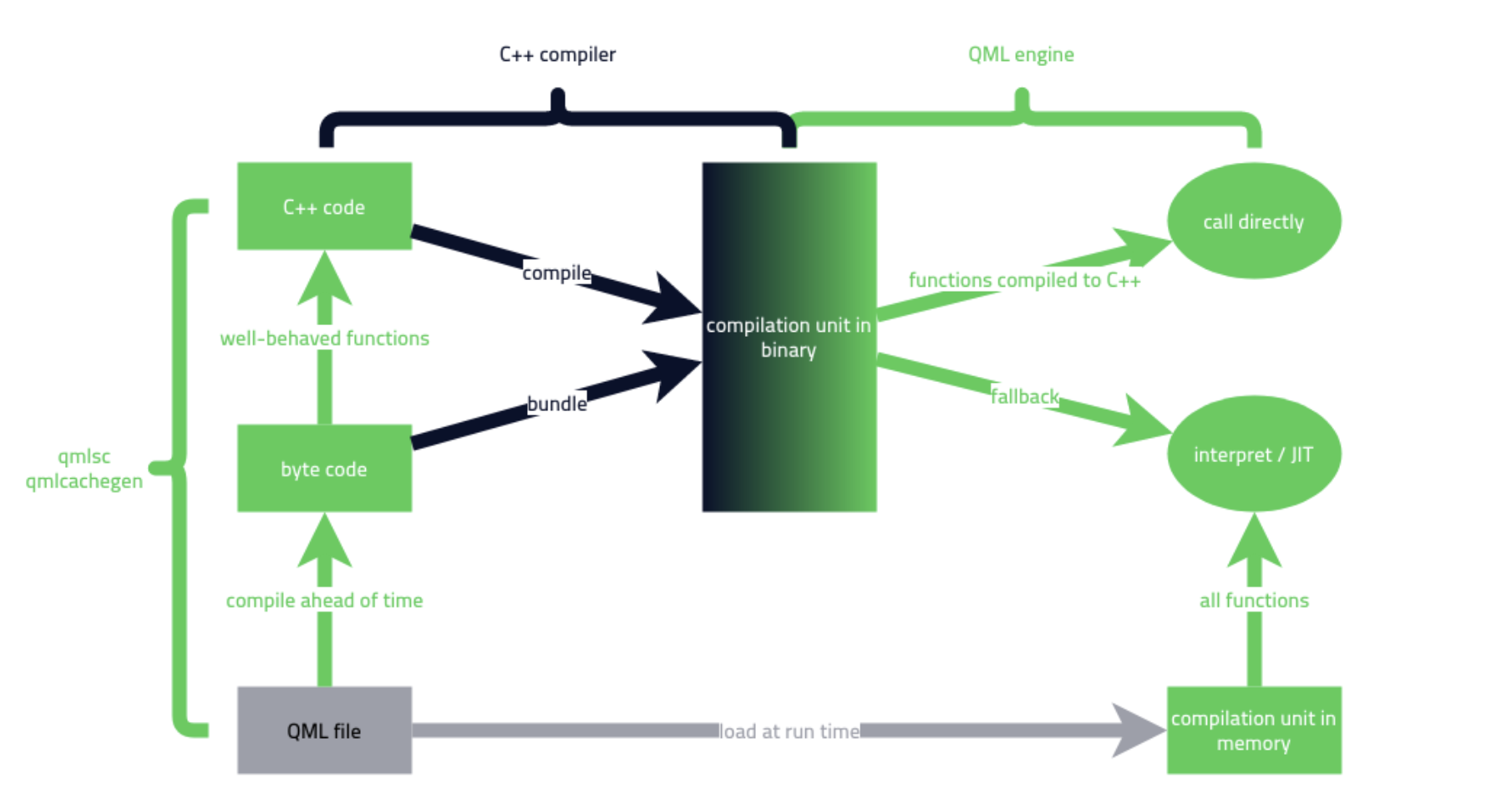
The performance benefits of the new approach have been measured and the results were published in the Qt blog. Even if you are not a Qt user, the general approach of speeding up the compilation and run time of the interpreted language is interesting.
JetBrains C++ tools start the 2022.1 EAP
We decided our first CLion and ReShaper C++ releases this year will be focused on quality improvements and bug-fixing. The first EAPs with many fixes are already published and you can try them for free. Here’s a brief summary of the major things delivered in the preview builds:
- CLion: The team is polishing the new remote development functions, has enabled support for Space dev environments, made toolchains and CMake profile settings more flexible, added a built-in preview for intention actions (DeMorgan laws, invert if condition, merge if-else, merge nested if, Clang-Tidy, MISRA, Clazy, and some others), introduced a new UI for Clang-Tidy settings, and added an option to provide additional container settings, such as port and volume bindings, for the Docker toolchain.The only new tool integrated into the CLion 2022.1 EAP is CMake profiling. If you’ve ever wondered why it takes so long to reload your CMake project, you can now try and find the answer with CLion’s help.
- ReSharper C++: Development is currently being taken in two main directions – sorting out and addressing the most annoying issues found in the product, and polishing the Unreal Engine support. To help you develop your Unreal Engine code faster, ReSharper C++ 2022.1 now adapts its features to the currently used version of Unreal Engine. For example, it now offers only the applicable reflection specifiers in code completion.
- Rider: If you are developing with Unreal Engine, this is an important piece of news! Unreal Engine support has been added to Rider 2022.1 EAP and will be released within the first major update of this year. C++ and Blueprints support, hundreds of code analysis checks, instant navigation actions, refactorings, code hints, native support for the uproject model, and more are all now available in the Rider EAP on all three major platforms. The blog post also comes with a short FAQ on why CLion isn’t used for UE, and how the Unreal Engine support in Rider relates to the Unreal Engine support in ReSharper C++.
And finally, what would you remove from C++, if not for ABI stability?
This reddit thread received lots of comments recently as it raised a popular question: Pretend for a moment that you don’t have ABI stability in C++. In that situation, what would you remove from C++ or fix in the language? The question probably arose in response to many ABI-related talks and discussions, where speakers proved just how much we care about ABI stability by listing the changes that were rejected because of it.
Several long threads in comments suggest an integer conversion to bool and even implicit conversions of any kind. It seems that many developers recognize a need for this but prefer to have more manual control over it. In the case of literals, where the need for implicit conversions is recognized by many, there is still a suggestion to improve things – make literals have unique types implicitly convertible to suitable integer types. A related idea shared in the comments was to cancel the old C-style cast.
Another popular idea is making variables const by default, or at least having that for function parameters. Another suggestion mentioned many times in the comments is to reject fallthrough by default in switch-case operator.
I personally love the “list of denials”:

I was surprised that undefined behavior was only mentioned after several hours of discussion in the comments.
What would be your answer to this question? Share in the comments.