

DataGrip 2017.2 Released!

DataGrip 2017.2 Released!
Hello!
Please give a warm welcome to our new release, DataGrip 2017.2.

We thank all of the EAPers who have helped us by testing all the new features we added in this release. Let’s have a look at them.
– Amazon Redshift and Microsoft Azure support
– Several databases in one PostgreSQL data source
– Transaction Control
– Evaluate expression
– Table DDL
– Integration with restore tools for PostgreSQL and MySQL
– Executing queries
– Coding assistance
– Other
Amazon Redshift and Microsoft Azure support
Database сloud services are growing more popular with every day. We were asked to add support for these two, especially Redshift, and here they are.
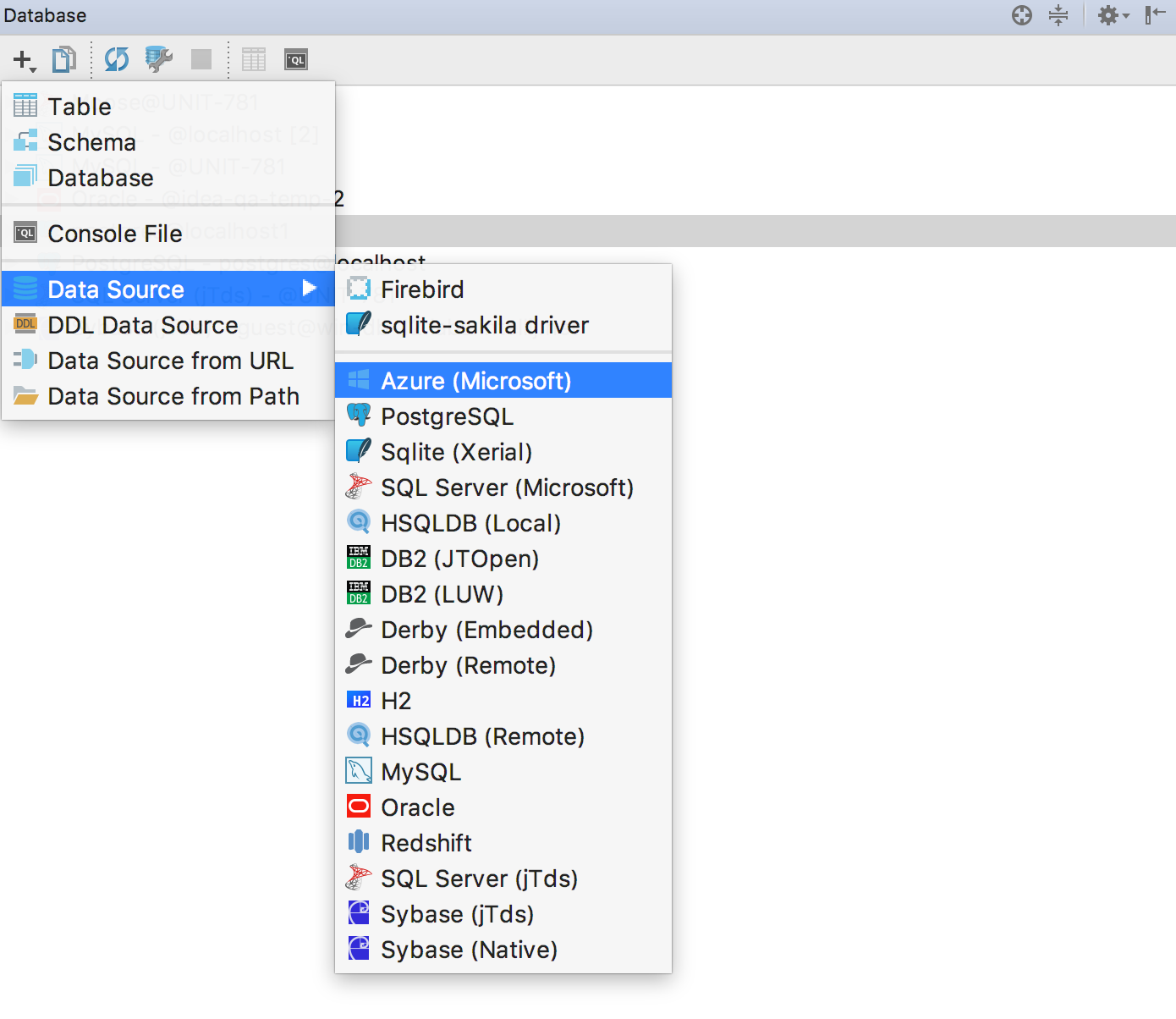
Microsoft Azure is similar to SQL Server, so we just added a dedicated driver, UI for adding the data source and some enhancements in the introspection.
But there are many things we did for Amazon Redshift. The introspection is now incremental. This means that only modified objects will be refreshed in a database tree after any operation instead of all objects.
Also, we started to support specific cases in SQL grammar which are different from PostgreSQL. For example, UNLOAD statement is not only highlighted correctly, but has an SQL-injection inside.
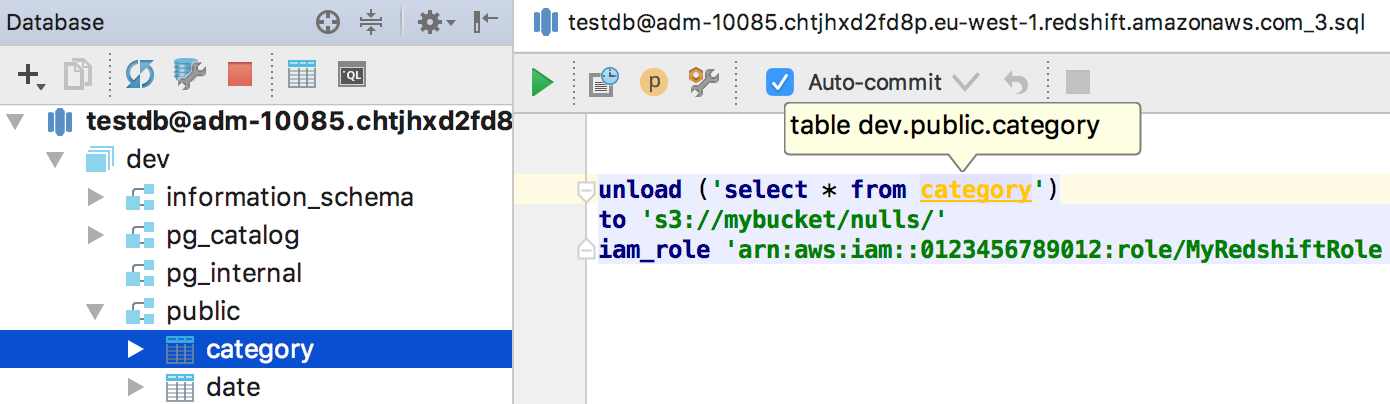
Another example: support for embedded Redshift functions that are absent in PostgreSQL.

Generation of the DDL scripts for tables and functions has been enhanced.
Now DDL for tables contains the following attribute:
[ BACKUP { YES | NO } ]
column_attributes:
[ IDENTITY ( seed, step ) ] [ ENCODE encoding ] [ DISTKEY ] [ SORTKEY ]
and table_attributes:
[ DISTSTYLE { EVEN | KEY | ALL } ]
[ DISTKEY ( column_name ) ]
[ [COMPOUND | INTERLEAVED ] SORTKEY ( column_name [, ...] ) ]
The source code of a function is now generated with the following section:
{VOLATILE | STABLE | IMMUTABLE }
In general, our support means, that if a part of your Redshift code is highlighted as an error but in fact it isn’t, we consider this a bug. Please report such cases to our issue tracker.
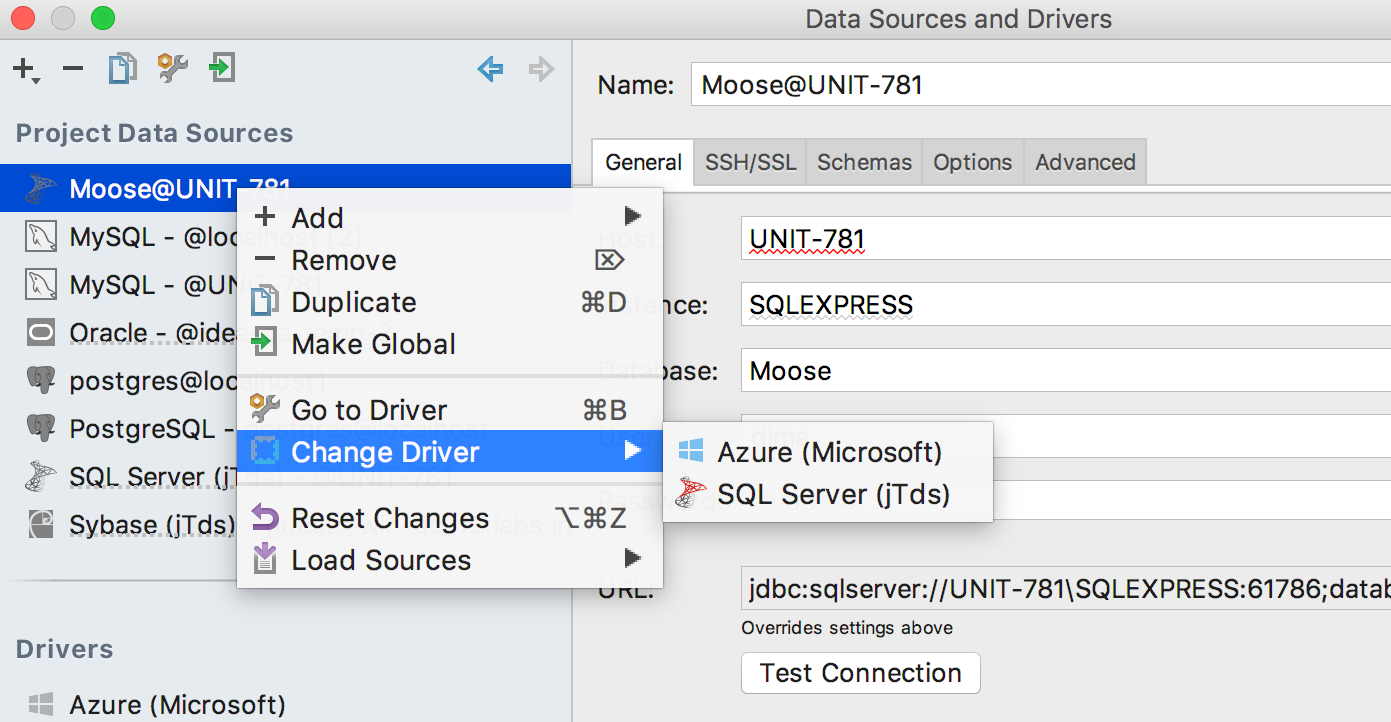
If you’re already using Azure and Redshift via SQL Server and PostgreSQL drivers, please re-select the driver in the data source properties window:
Several databases in one PostgreSQL data source
This was a really long-awaited feature, but the wait is finally over. Thanks for bearing with us! We refactored a lot of code to implement this functionality, so some things might still be missing. Please give us your feedback on your experience using data sources with multiple databases.

Data sources with several databases are also supported for Amazon Redshift, Microsoft Azure, and any unsupported databases whose drivers report several databases.
Transaction Control
Transaction Control feature replaced the Auto-commit option.
First, define what kind of transaction control you want to use when working with a particular data source. This option is available in data source properties. In the Auto mode you don’t need to commit any transactions executing the commit statement., while in the Manual mode, you, obviously need to do this.
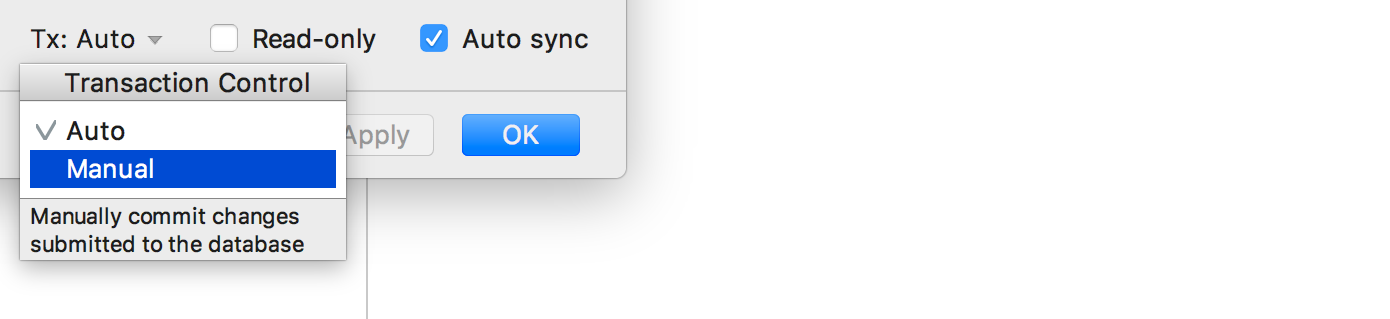
This also can be defined for each query console along with the isolation level.
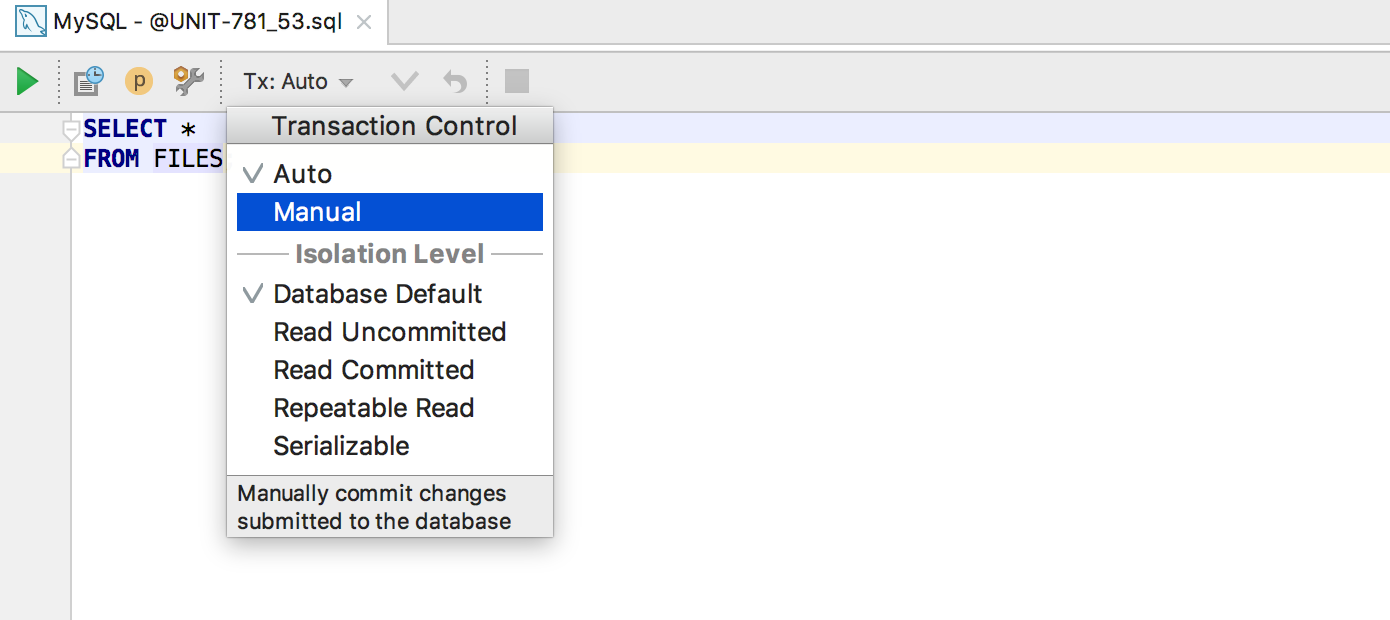
The data editor in the Manual mode also has Commit and Rollback buttons on toolbar. All actions are also available in the context menu.
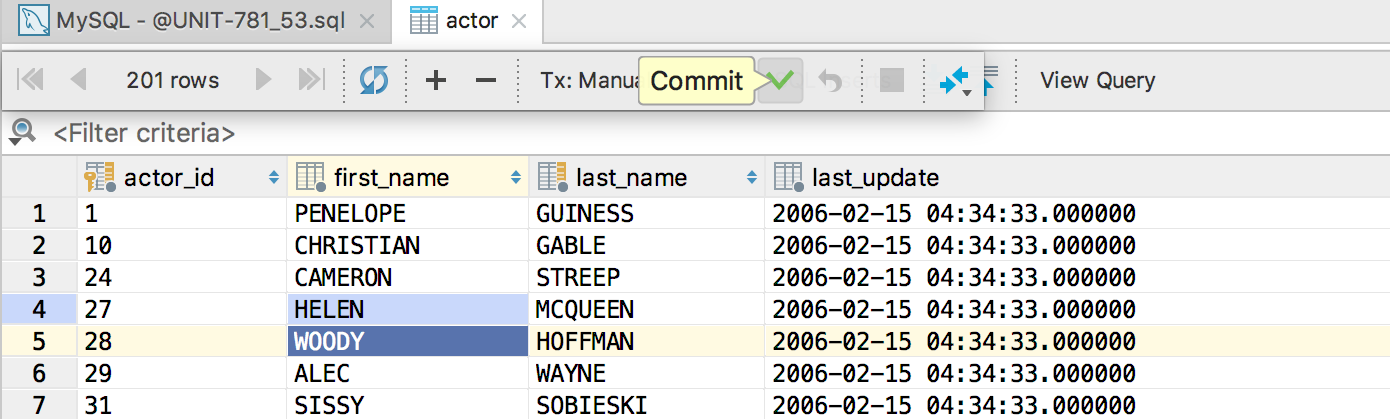
So, now it works like this:
Auto and Manual mode
Submit button or Ctrl/Cmd+Enter → submits your data, which means that your local changes(they are highlighted) are submitted to the database. If you are in the Manual mode this transaction is not committed.
Revert Selected from the context menu or Ctrl/Cmd+Alt+Z (it used to be Ctrl+Z, but Revert isn’t Undo, right?) on selected rows → reverts unsubmitted local changes of the selected rows.
Only in Manual mode
Commit button or Shift+Ctrl+Alt+Enter → commits the transaction. If you have unsubmitted local changes (again, they are highlighted) they will be automatically submitted before the commit.
Rollback button → rolls back transaction if it’s uncommitted.
Evaluate expression
This will help you see data without writing a query to the console.
In other IntelliJ-based IDEs, Ctrl+Alt+F8 on an object gives you quick evaluation. In DataGrip, invoke it on a table in a query to see the data of that table.
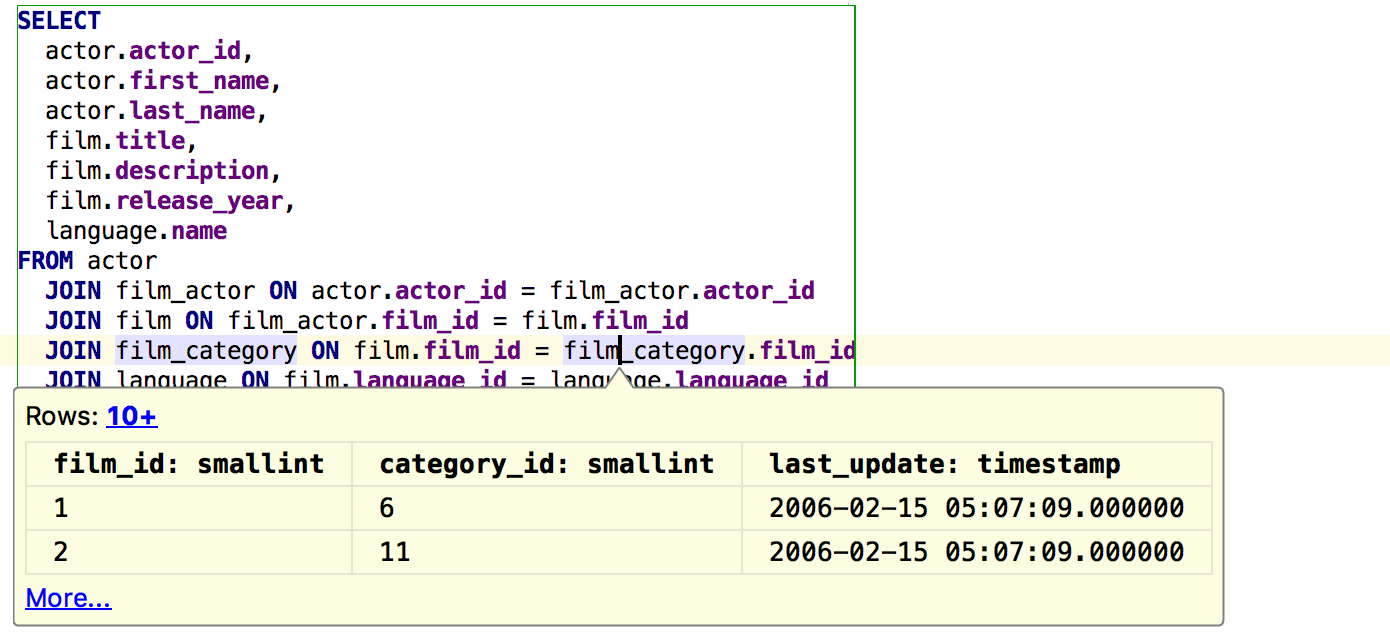
Ctrl+Alt+F8 on a column name will show the values of that column in the expected result-set.
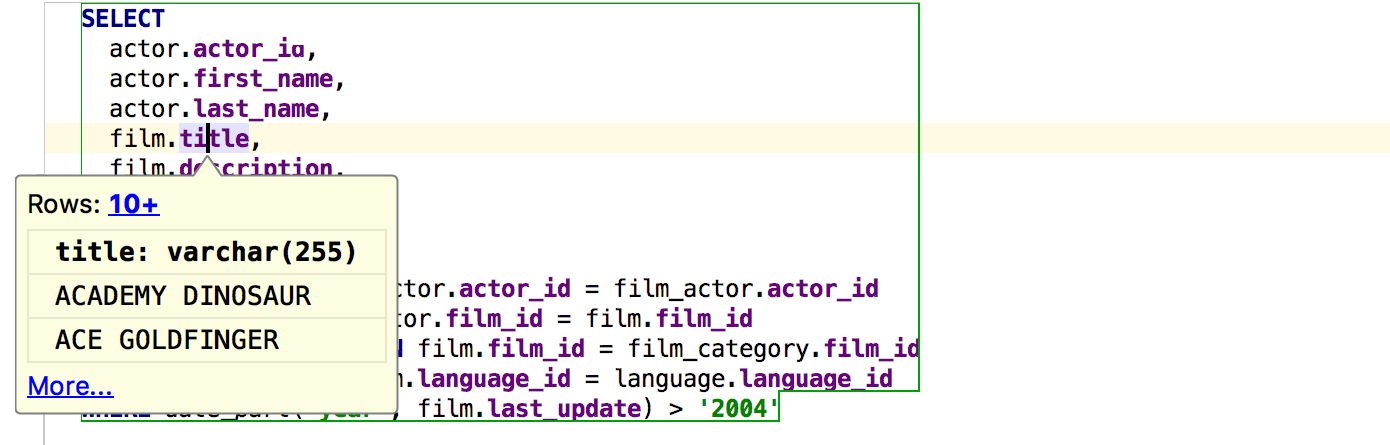
If you invoke the same quick evaluate on the keyword of a query (or subquery), the pop-up will show you the result. Note that Alt+Click also works for this.
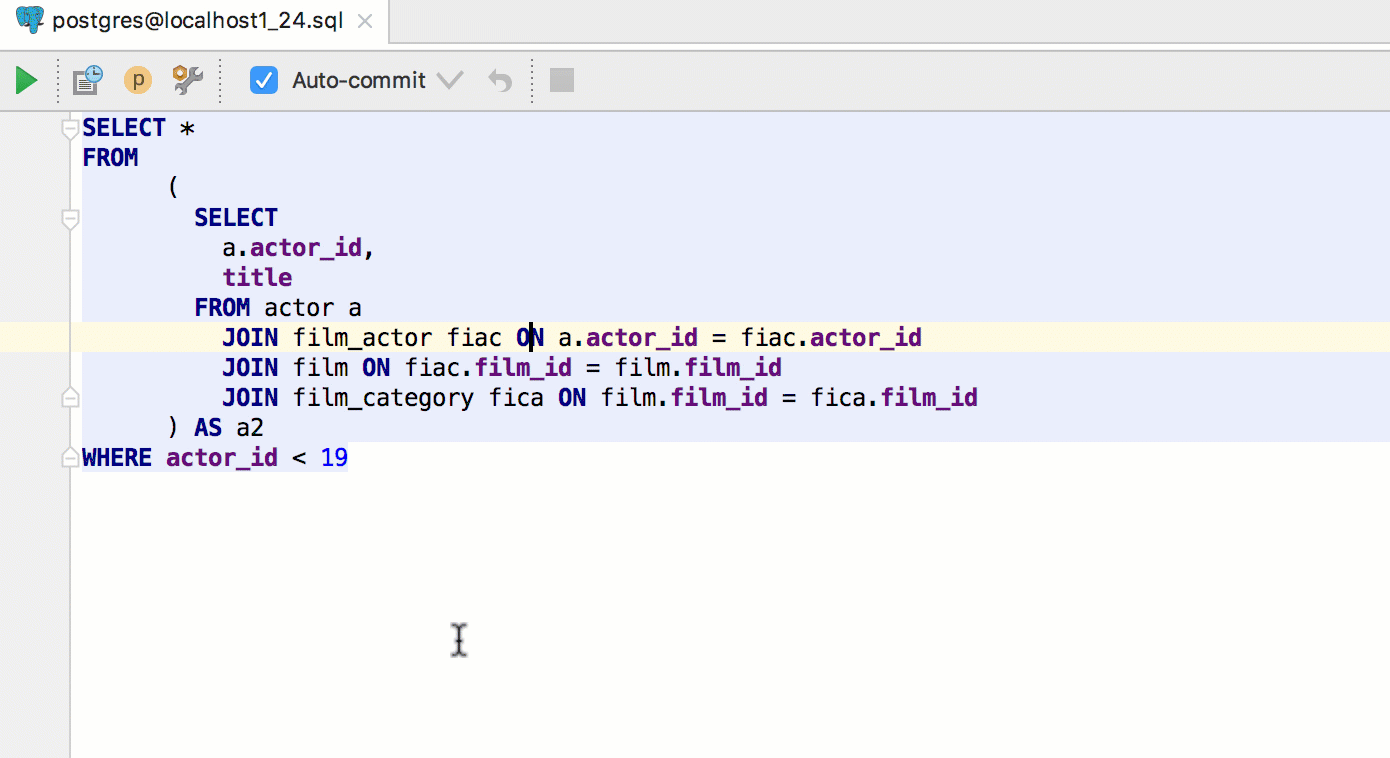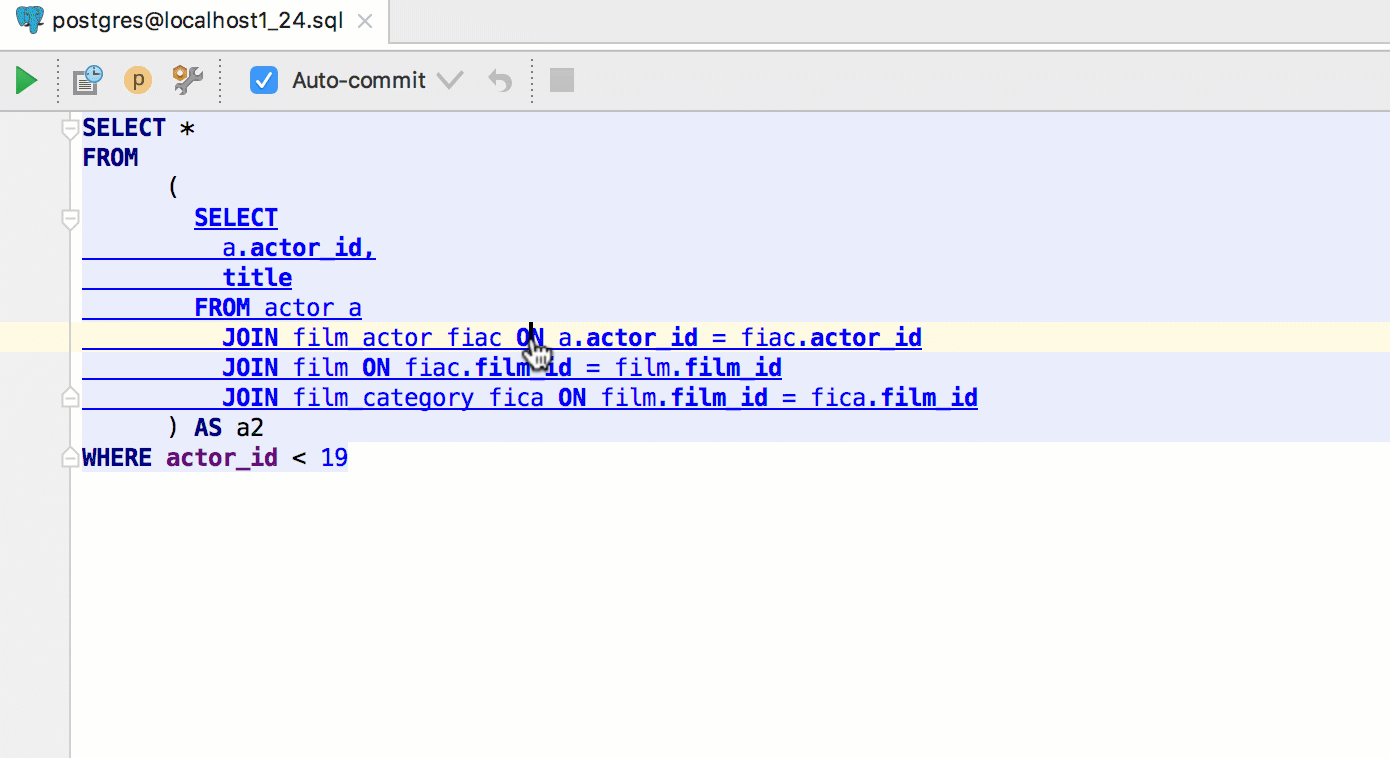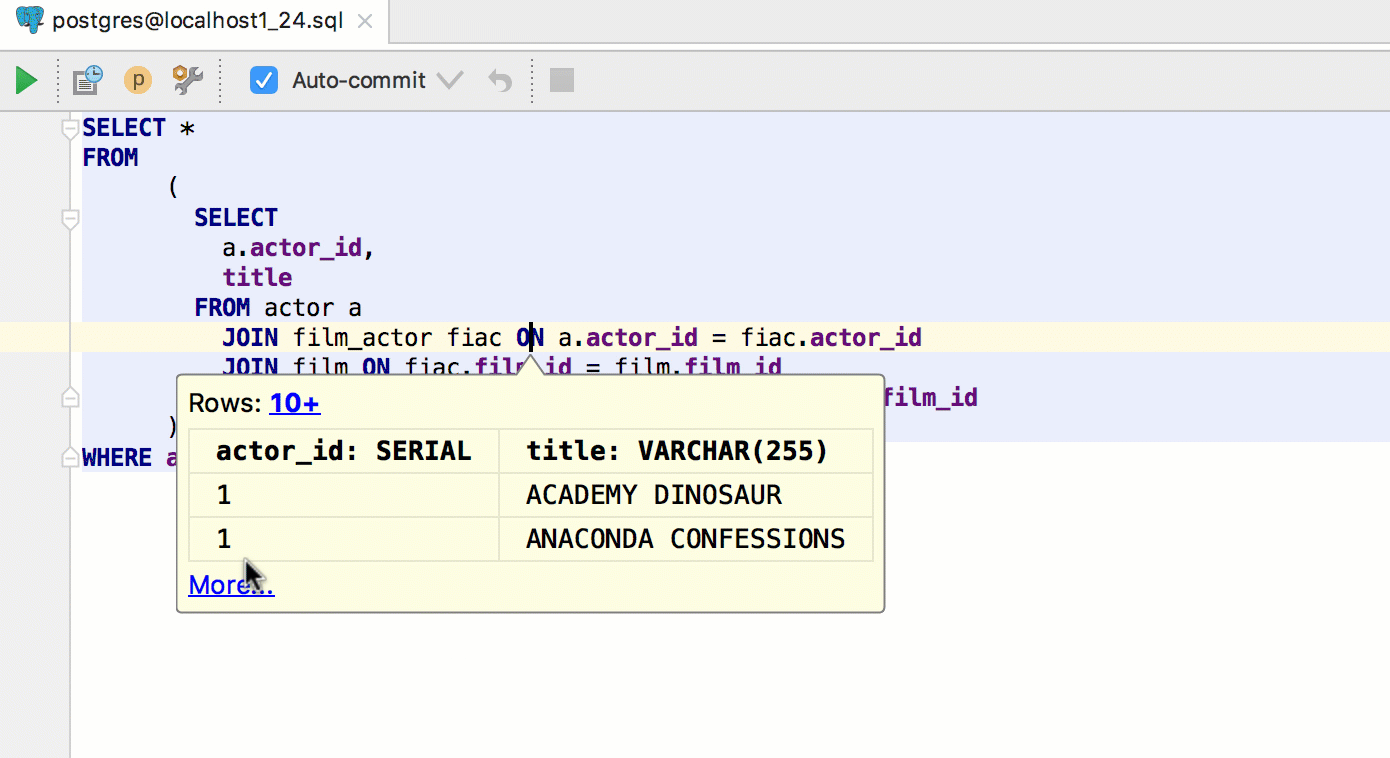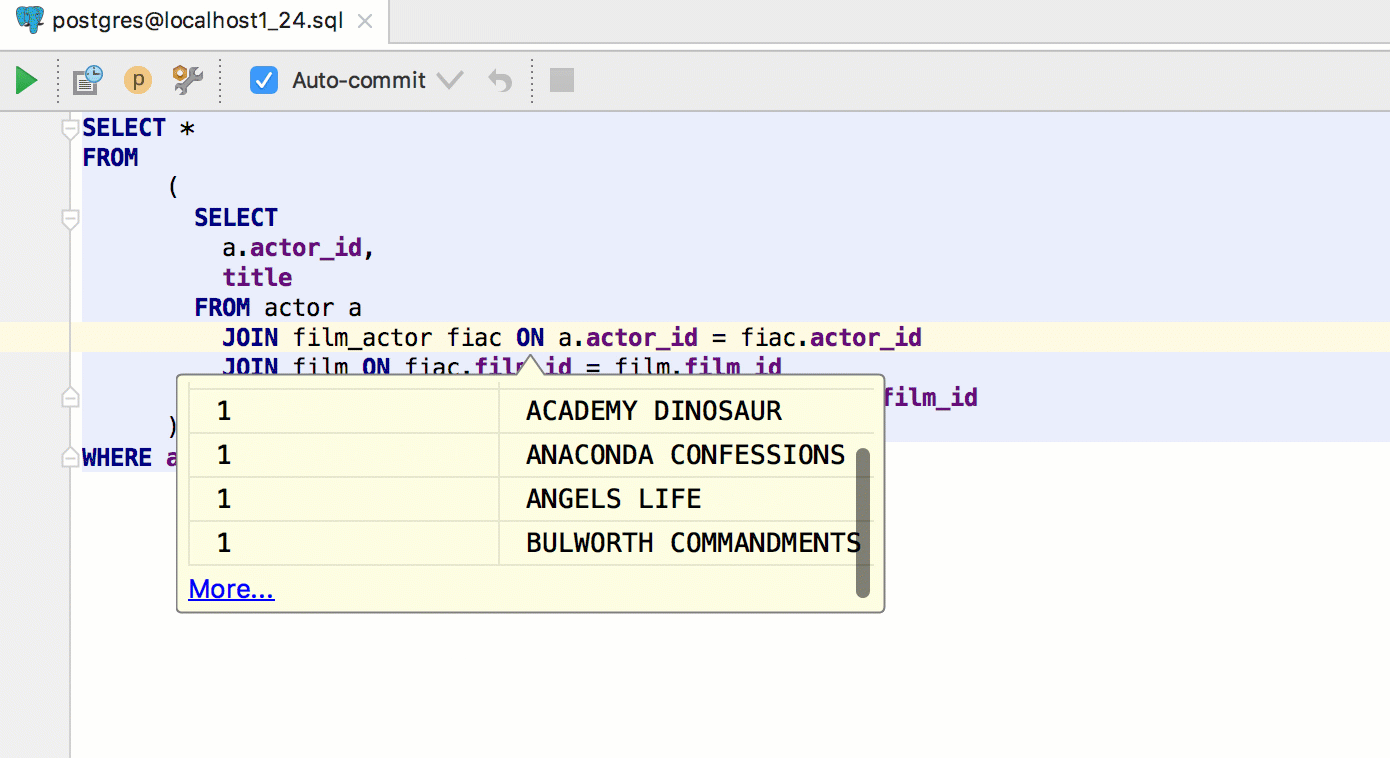
Press Alt+F8 to open an Evaluate pop-up, where any query can be run. If invoked on a table, it will show the data.
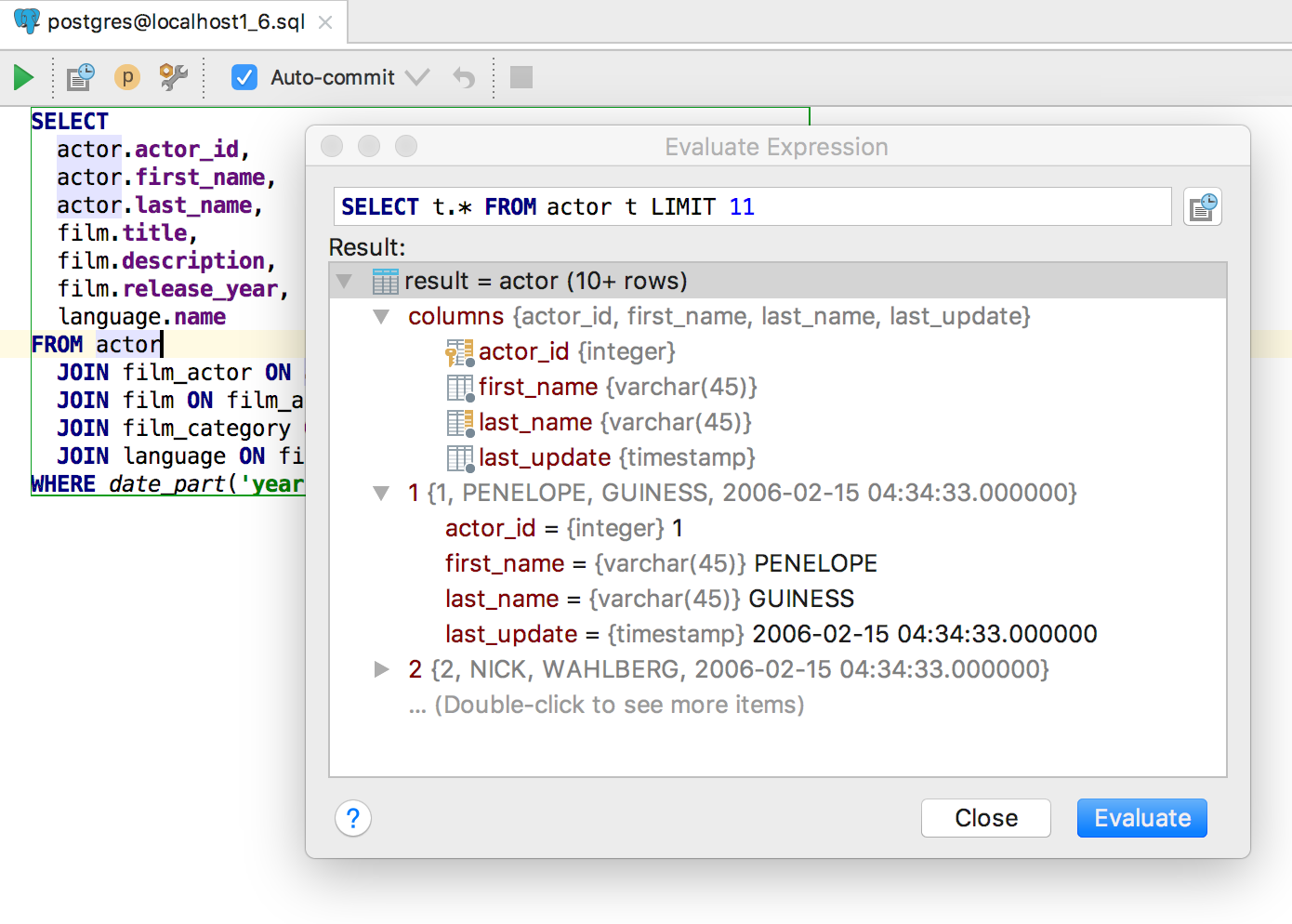
You can evaluate expressions here as well.
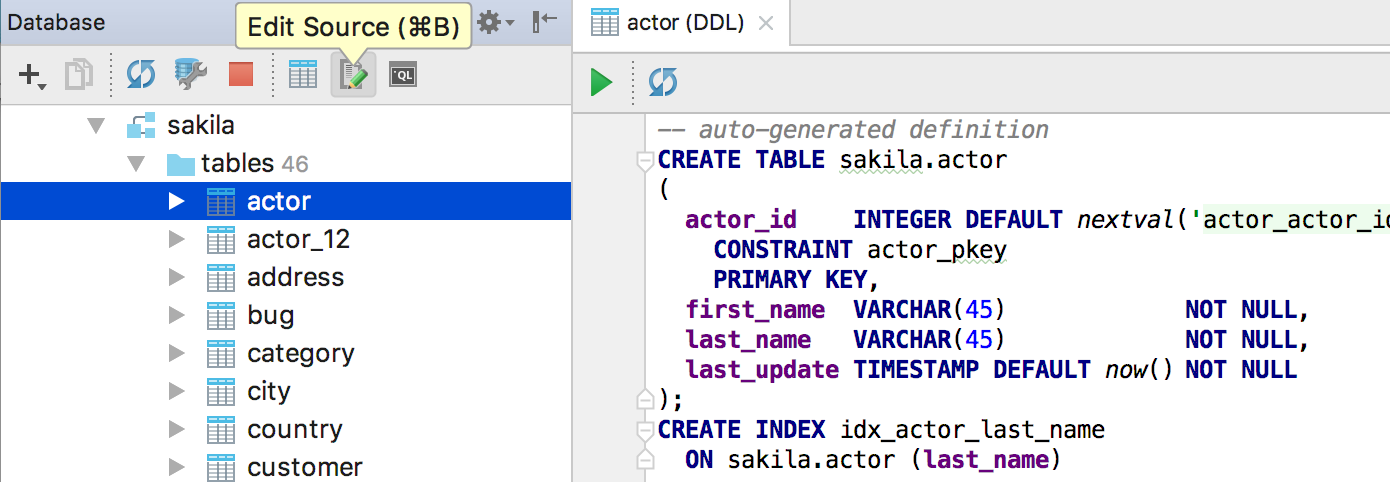
Table DDL
We have divided the Data and DDL tabs when viewing a table. Actually, there are no more tabs. Now, when you open a table with a double-click, you just see data. Where is the DDL? It can be opened by Edit Source on the toolbar or by Ctrl/Cmd+B.
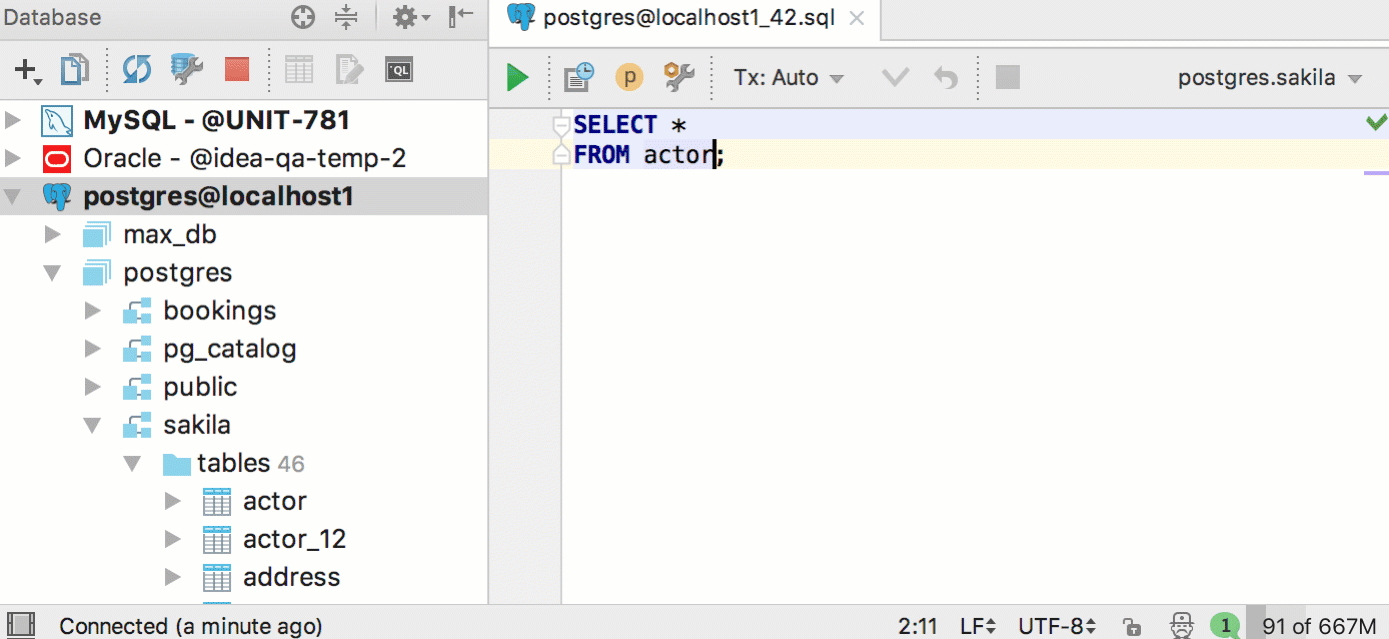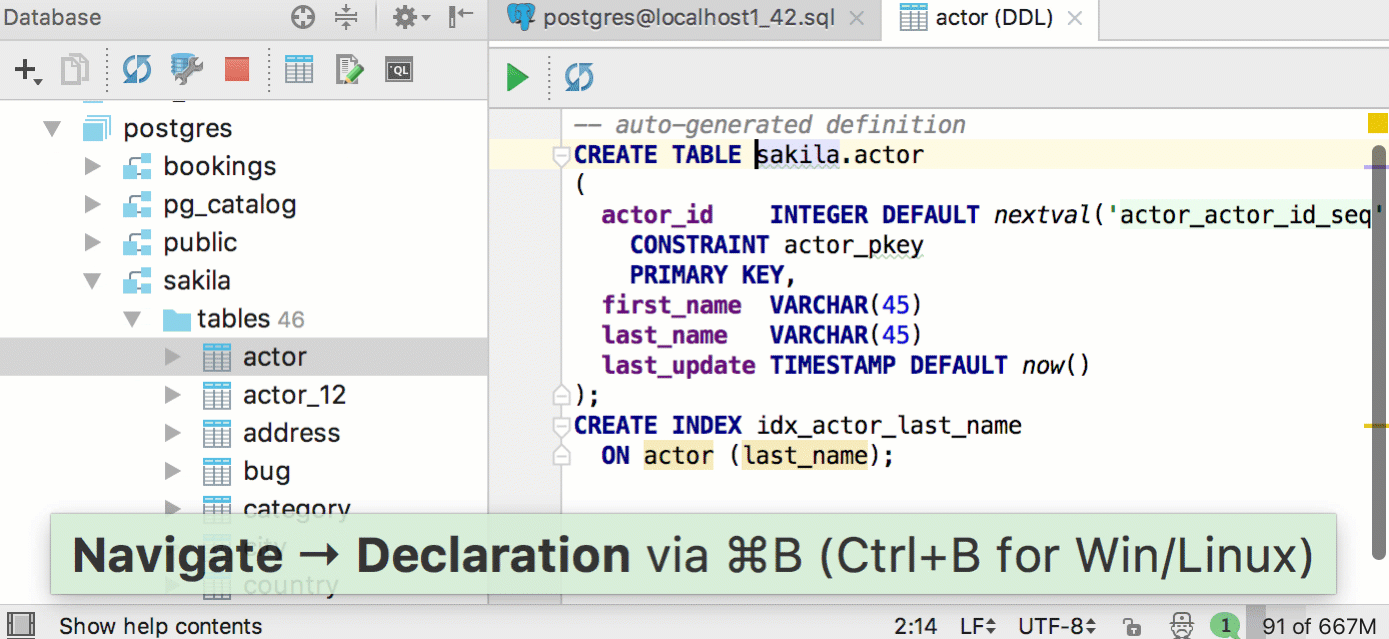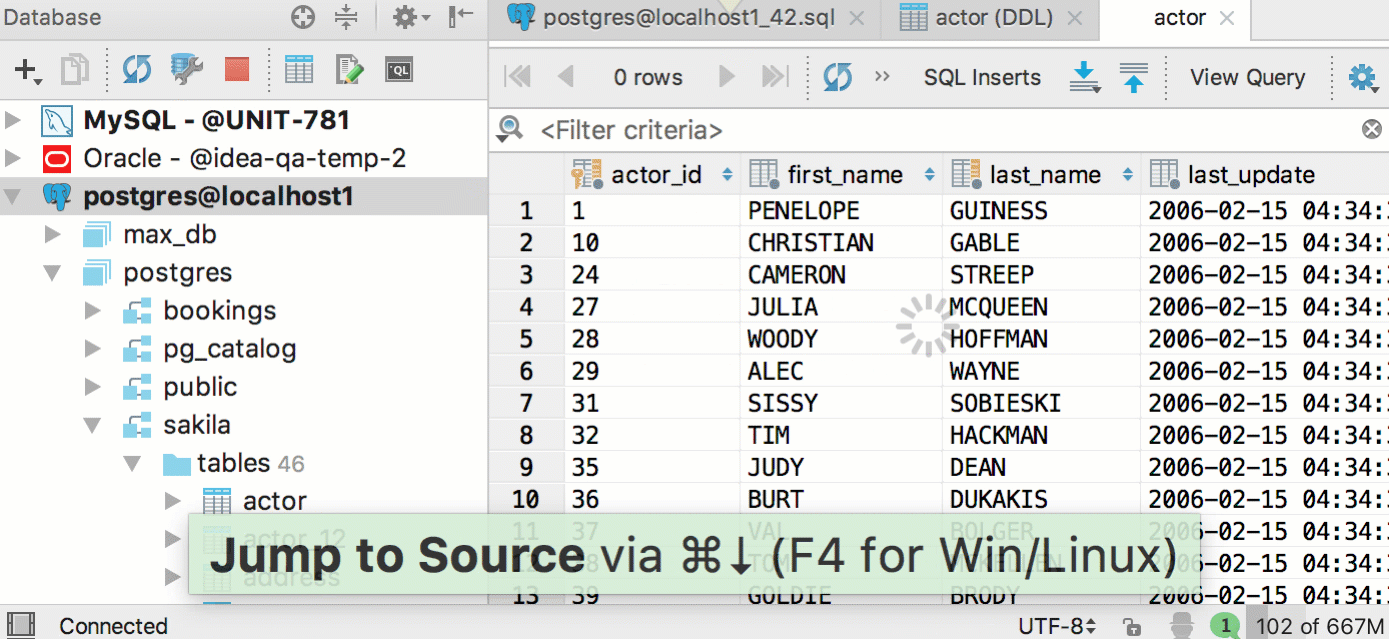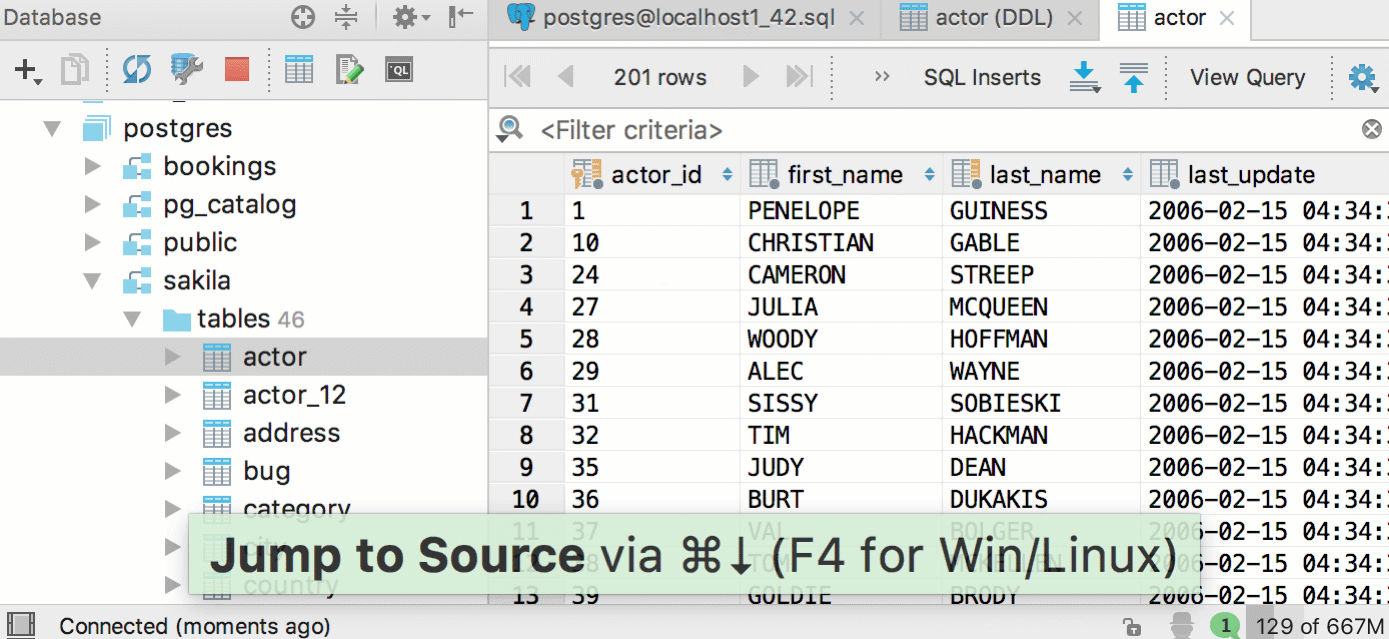
The same DDL editor will open when pressing Ctrl/Cmd+B on the table name in the SQL script. As you may remember, Ctrl/Cmd+click does the same. In the previous versions this action brought you to the database tree. If you still need this, press Alt+F1 on any object and choose Database view.
It became easier to open Data editor for a table. Just click F4 on the table name, either in the database tree or in SQL.
Integration with restore tools for PostgreSQL and MySQL
In 2016.3 we integrated DataGrip with mysqldump and pg_dump, so it’s logical to add integration with the restore tools of these databases as well. Now they can be accessed from the context menu. If there’s only one tool available, this option will look like ‘Restore with pg_restore’, etc.
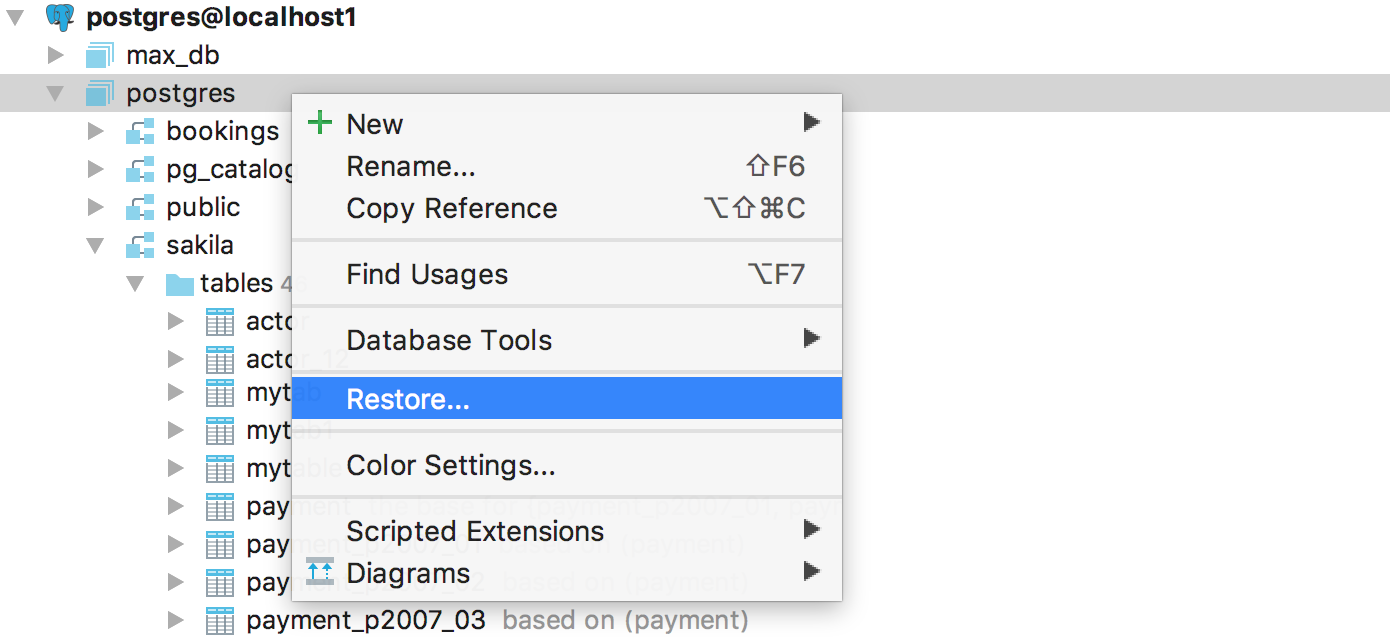
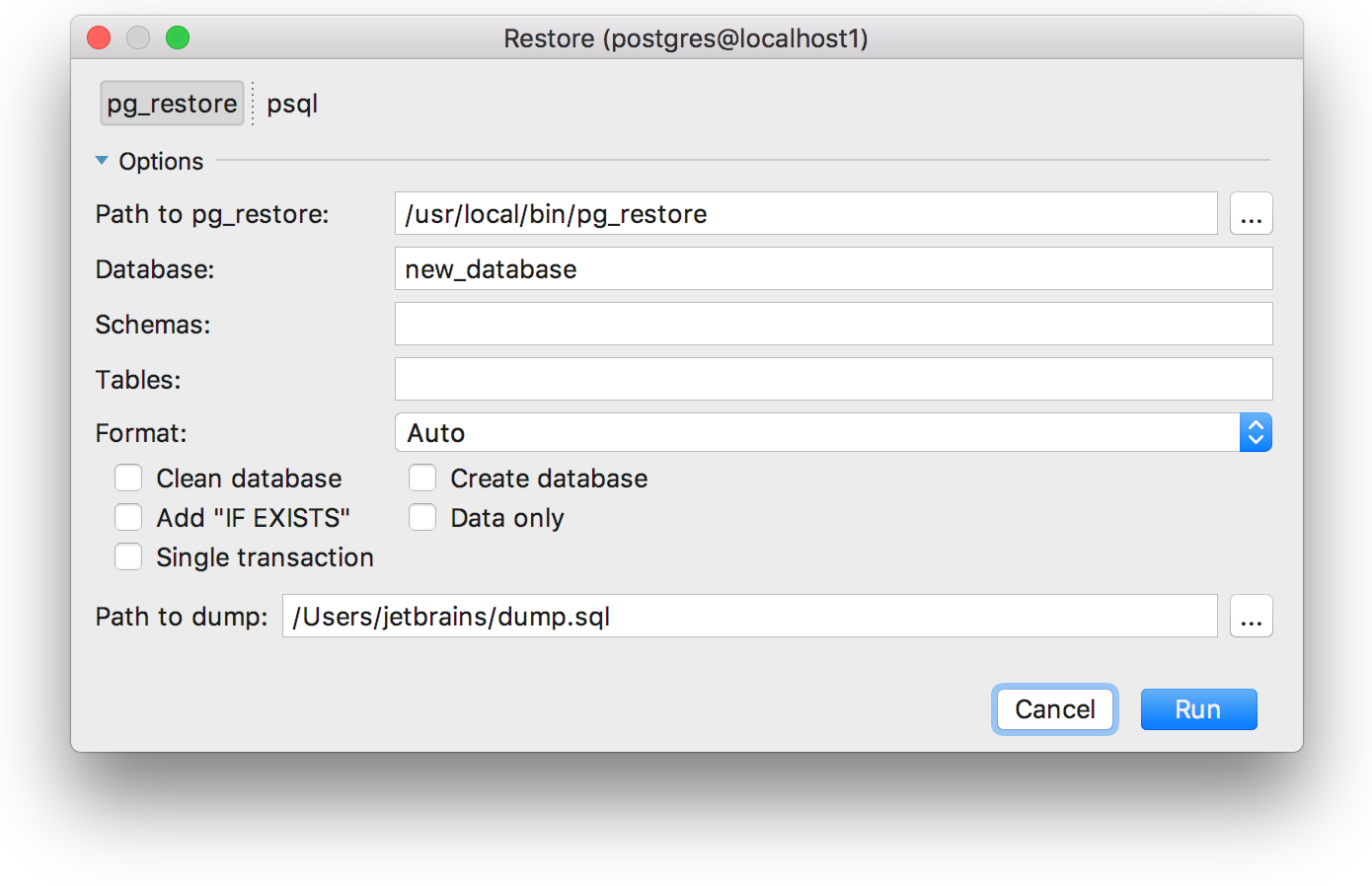
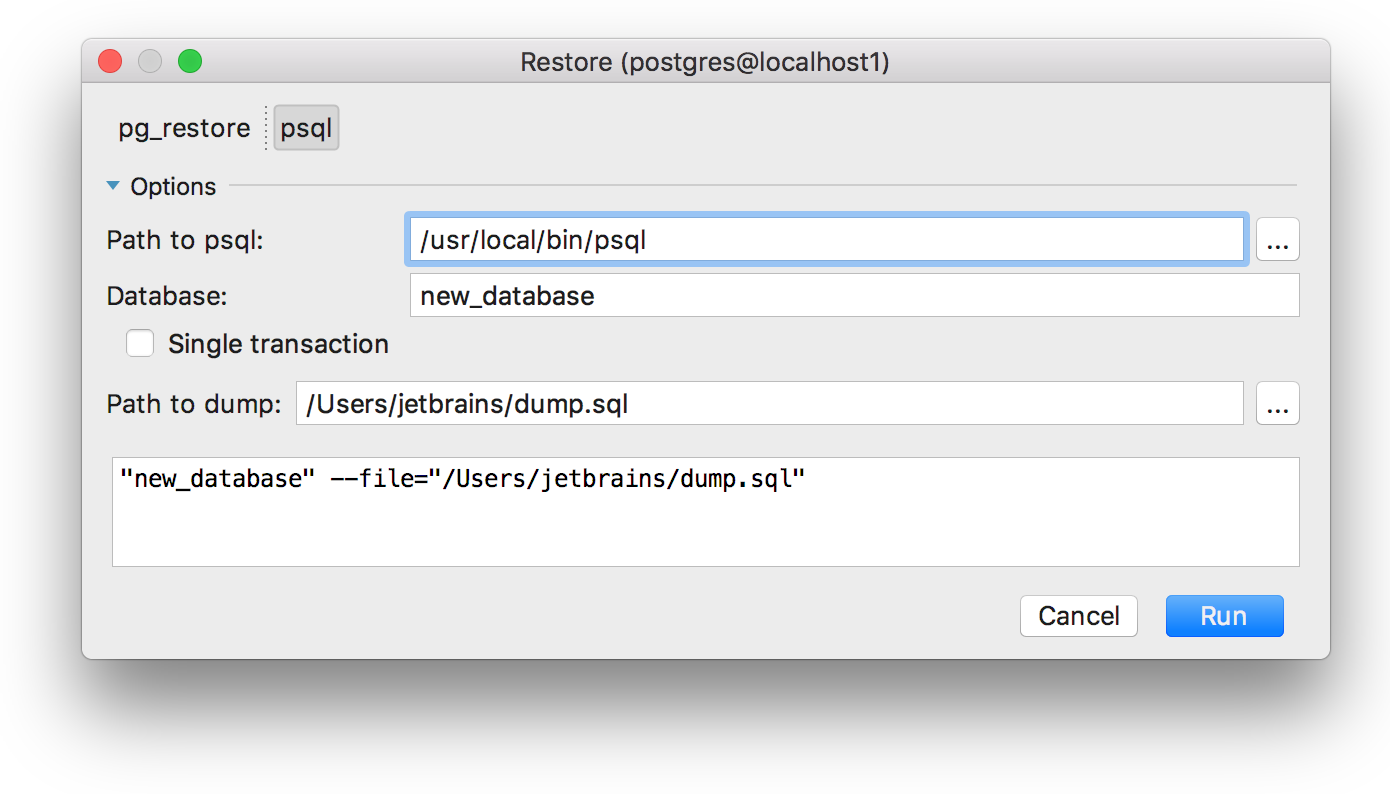
In the case of PostgreSQL, the restore operation can be done with pg_dump or psql: there is a chooser in the Restore dialog:
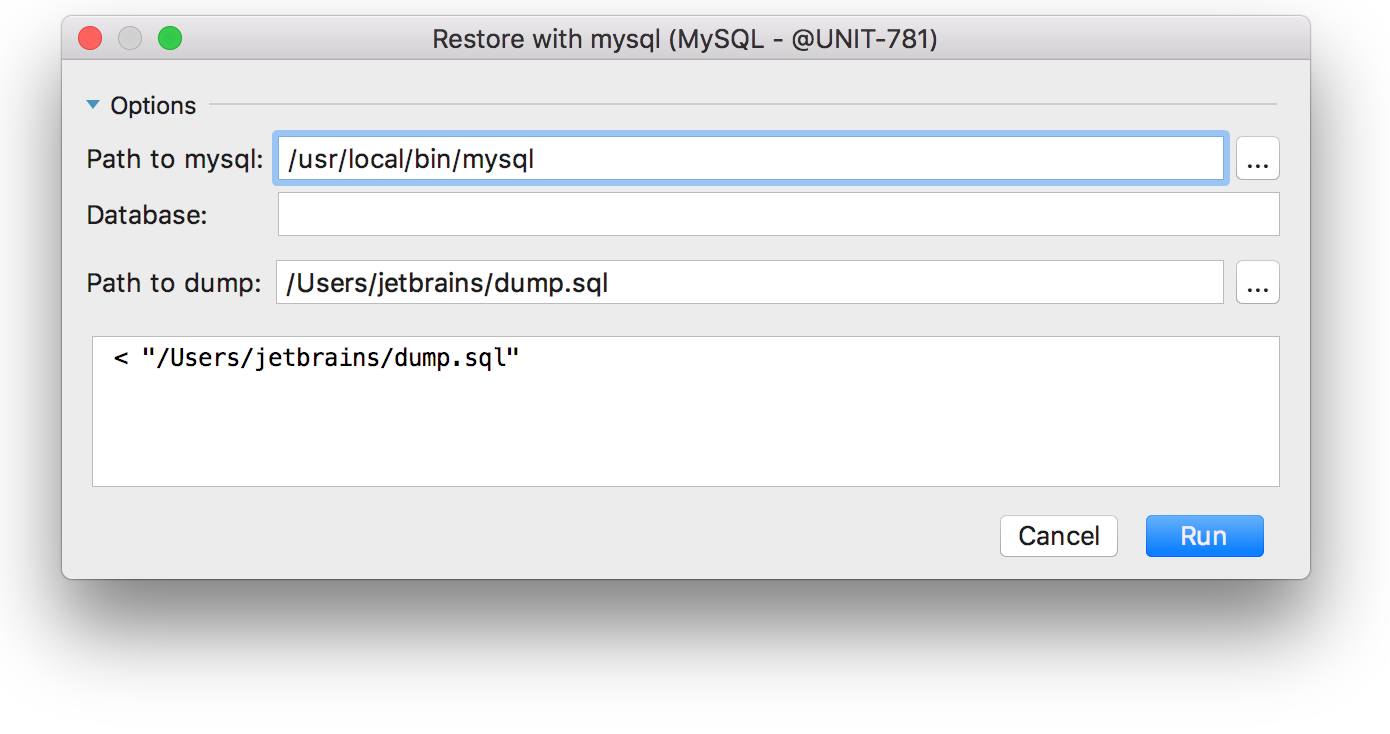
And it looks like this in MySQL:
Executing queries
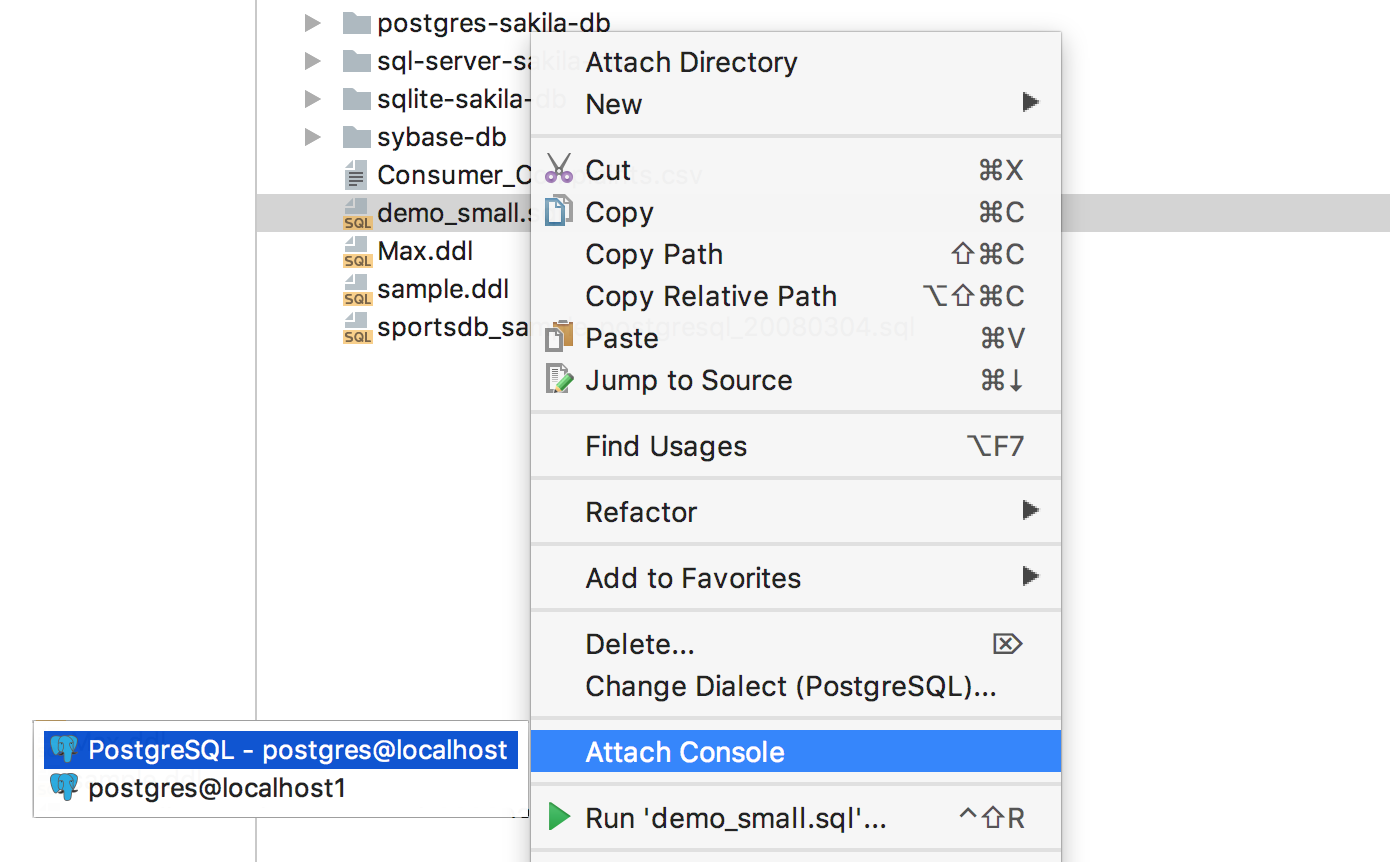
There is a new action for any file called Attach console. You can find via Ctrl+Shift+A or by opening the context menu for a file. After performing this action, this file can be run against the console. Switching consoles will be useful if you want to run the same script in several data sources.
Called-for feature: a notification is now displayed when a large query is finished. To disable it, in Settings look for the “Database queries that took much time” notification. It appears if it took more than 20 seconds to execute a statement.

Many of you have asked for result-sets to be switched along with the corresponding consoles. Done!
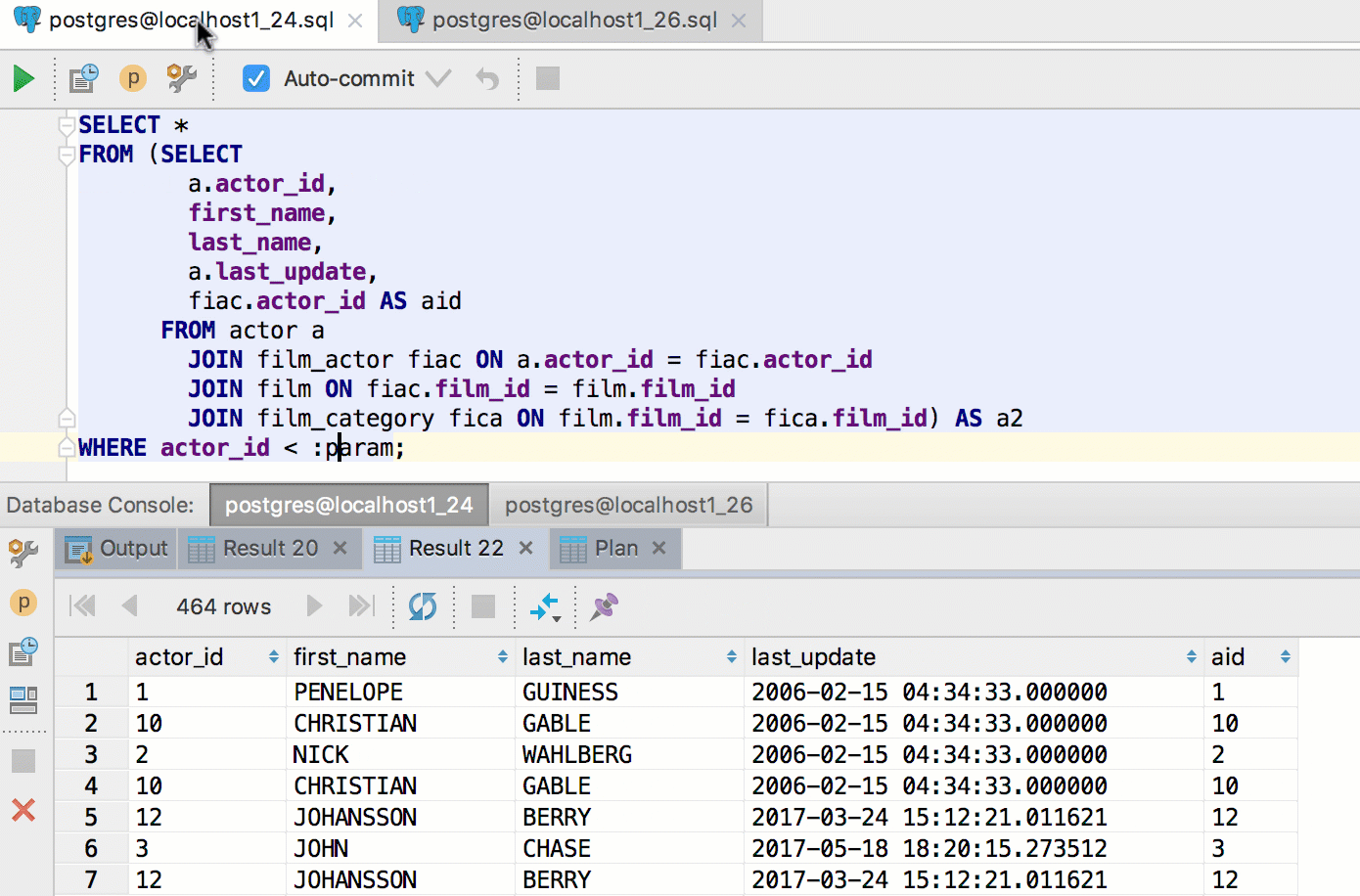
The same works in the opposite direction.
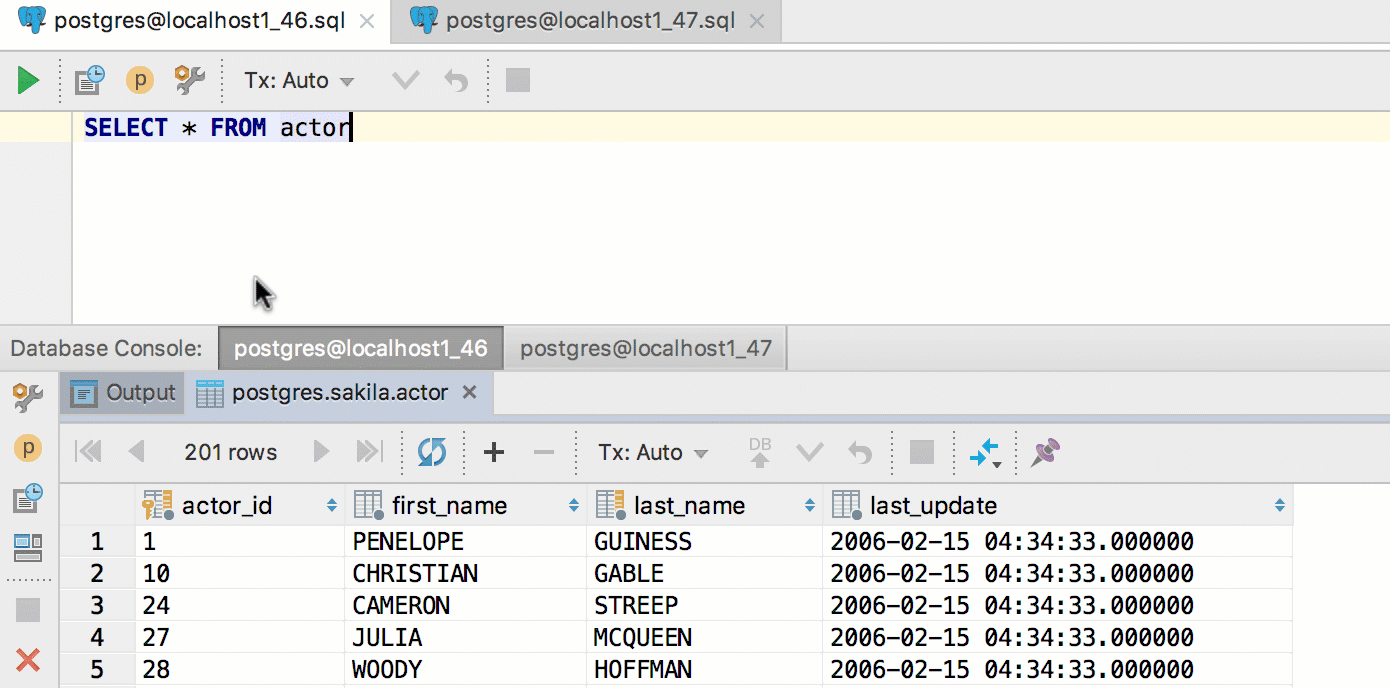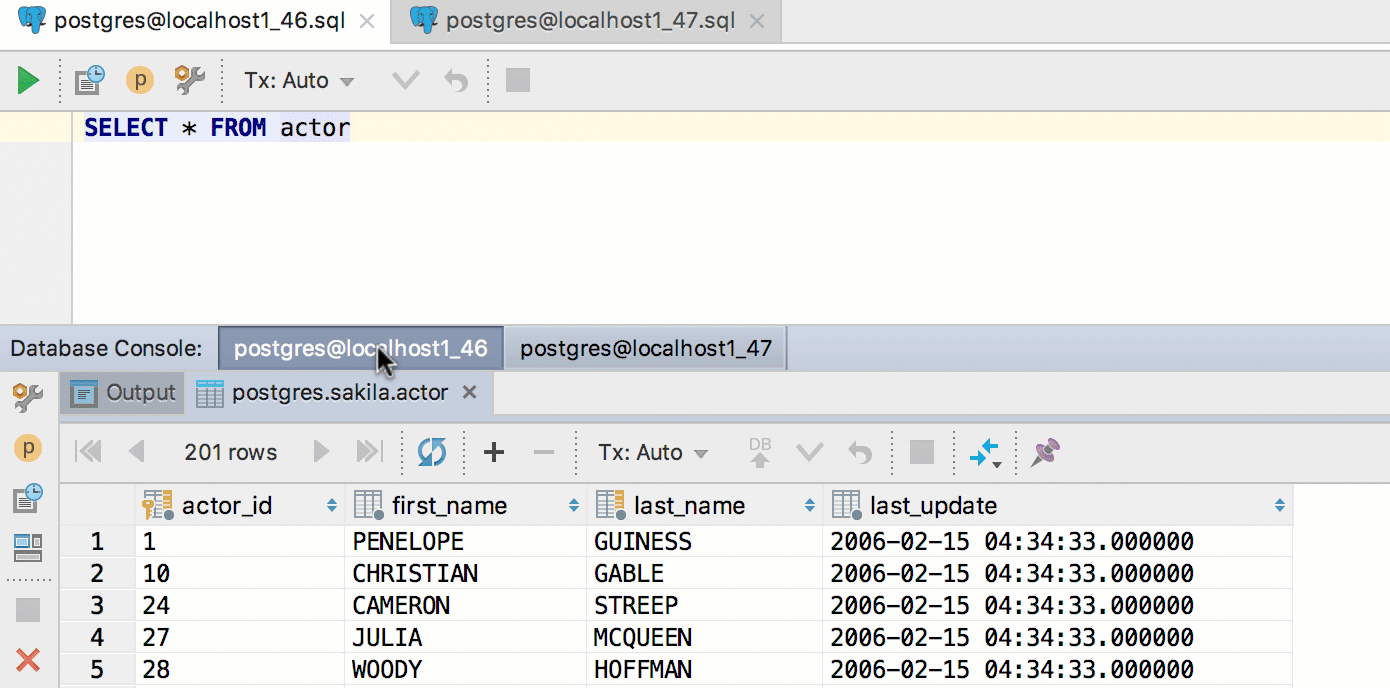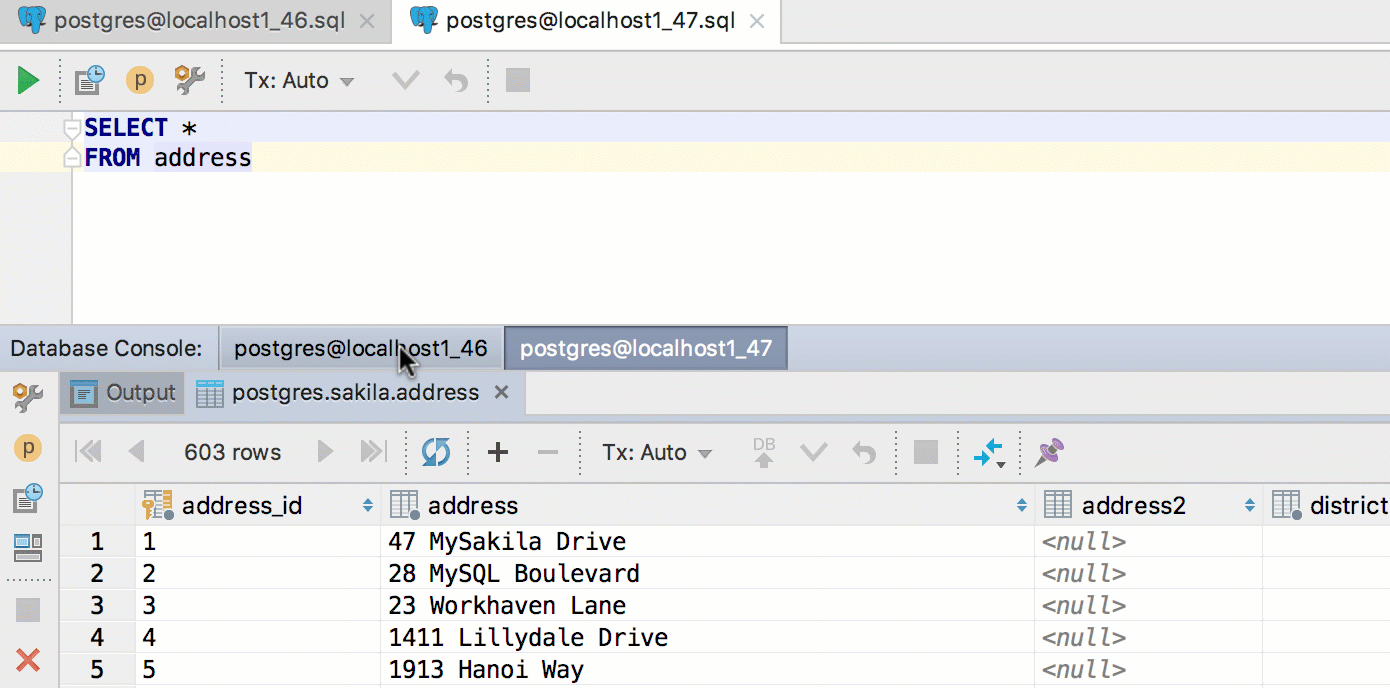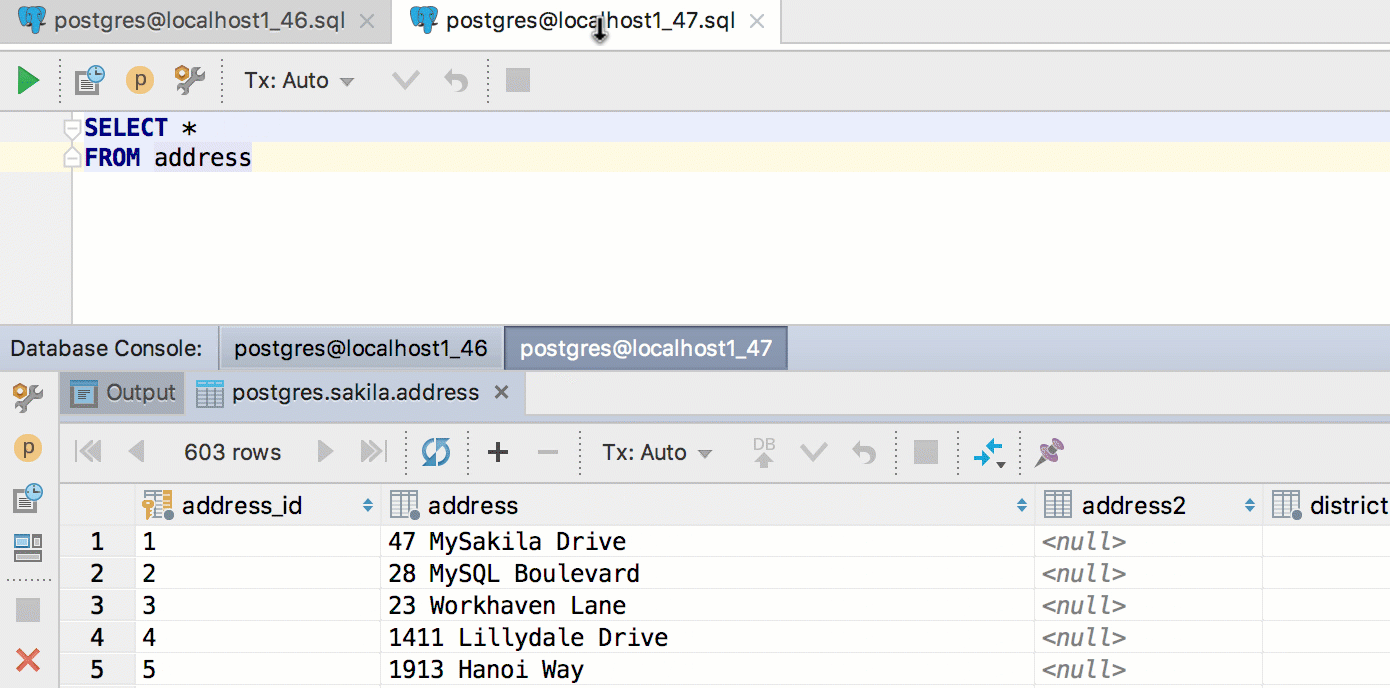
These behaviors are on by default, look for the “Autoscroll ..” toggles in the gear-icon menu of the Database Console tool window.
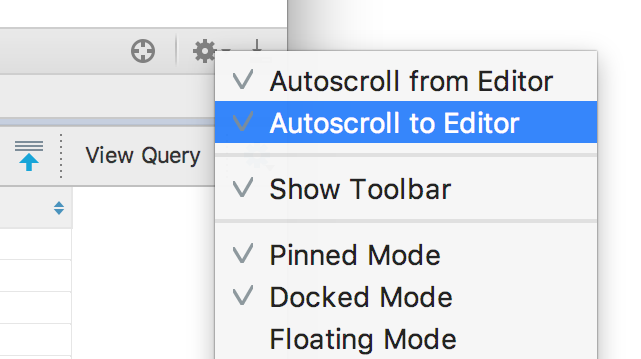
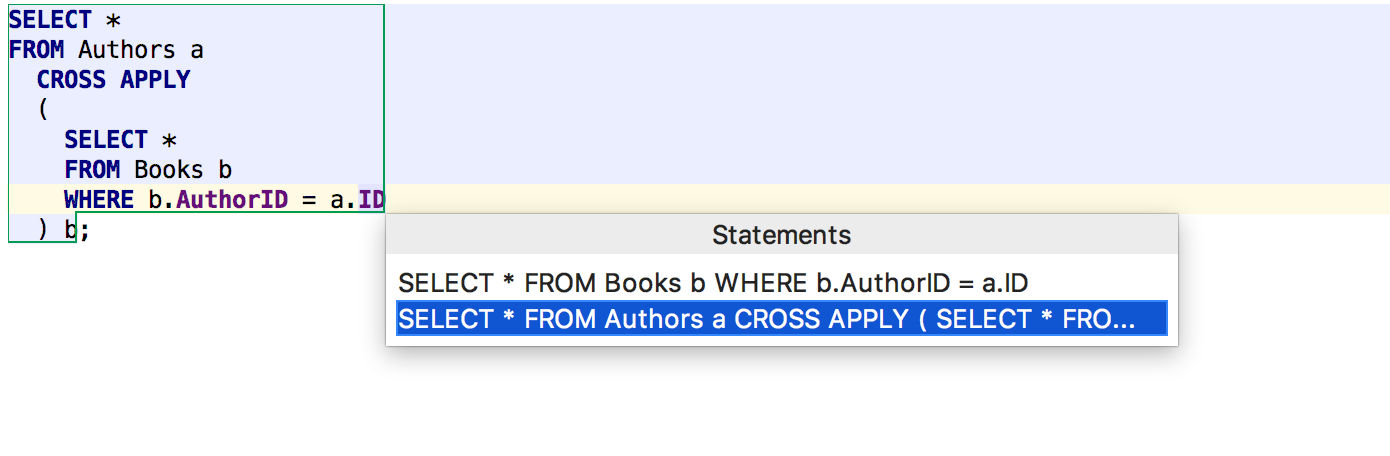
And another small enhancement: when you execute a query with subqueries, the outer statement is selected in the drop-down by default. Well, nested statements often just cannot be executed at all.
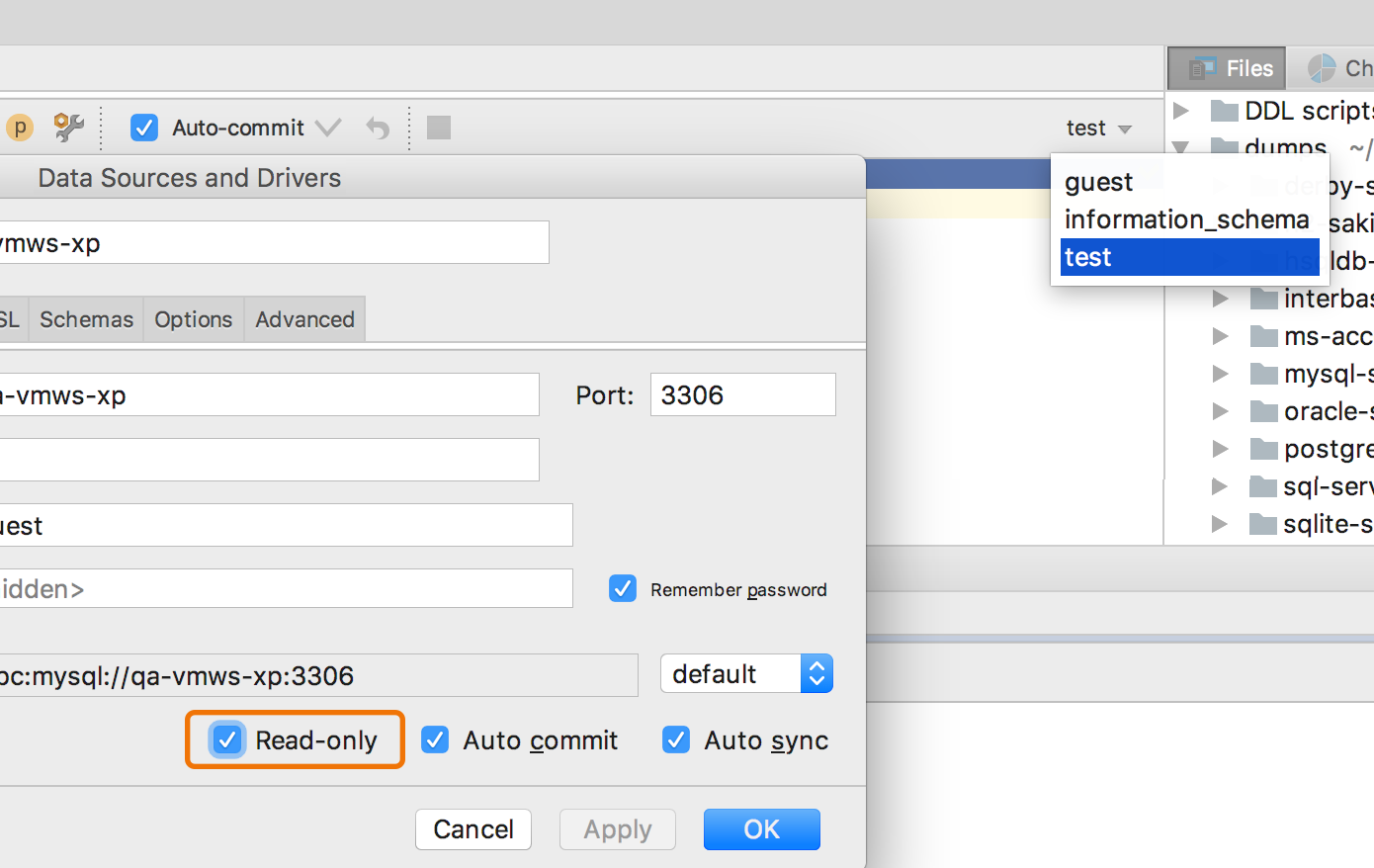
Schema switcher works in MySQL even with a read-only connection.
Coding assistance
Completion now works for columns in table-valued functions.
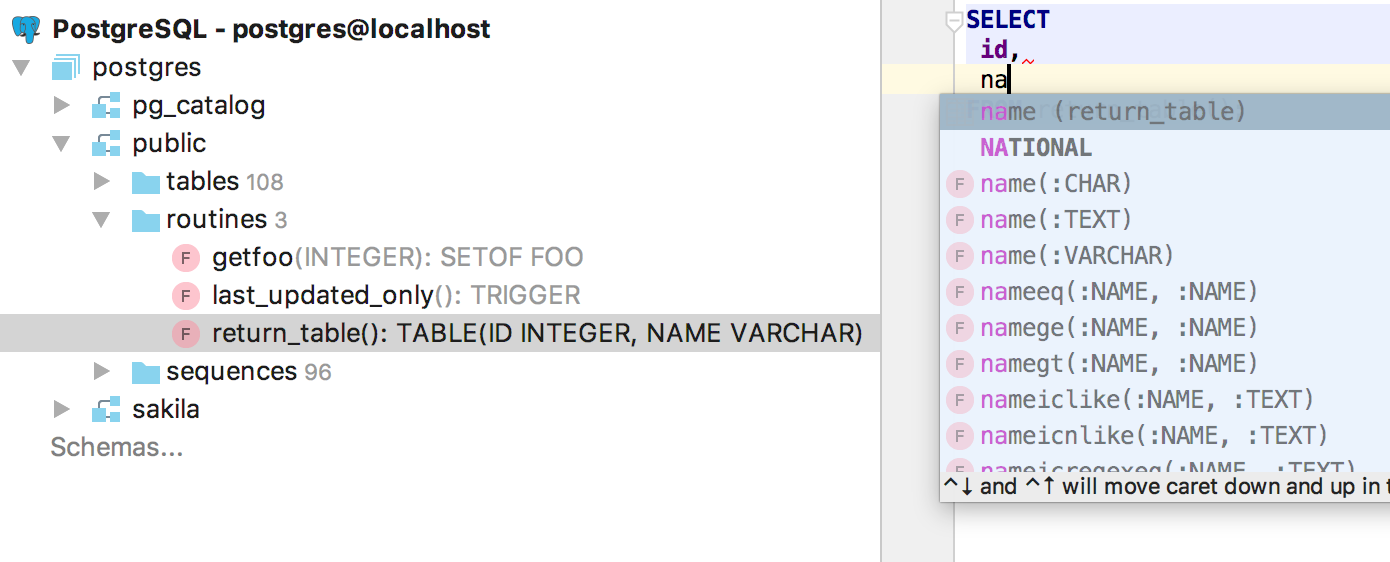
NEW and OLD references are resolved in PostgreSQL triggers.
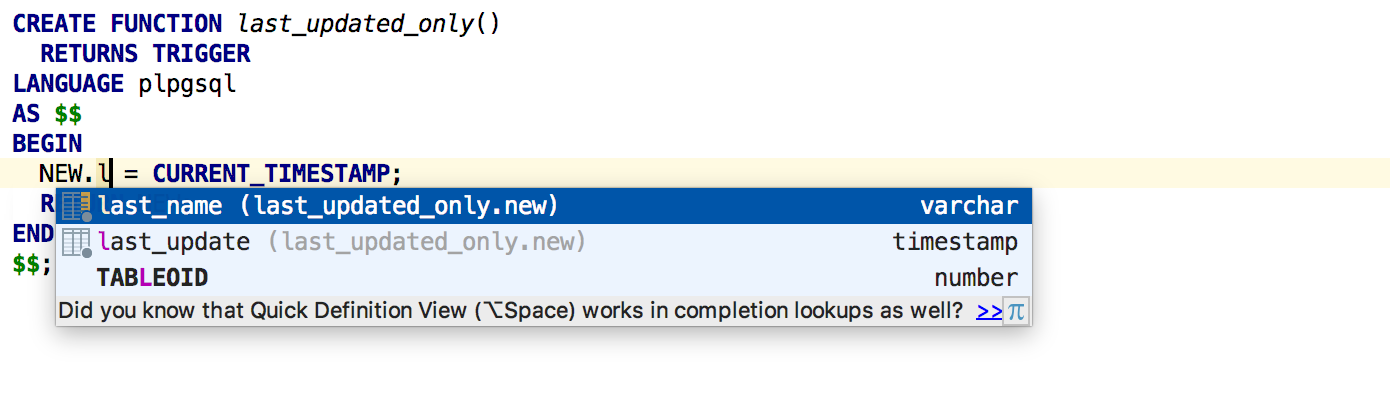
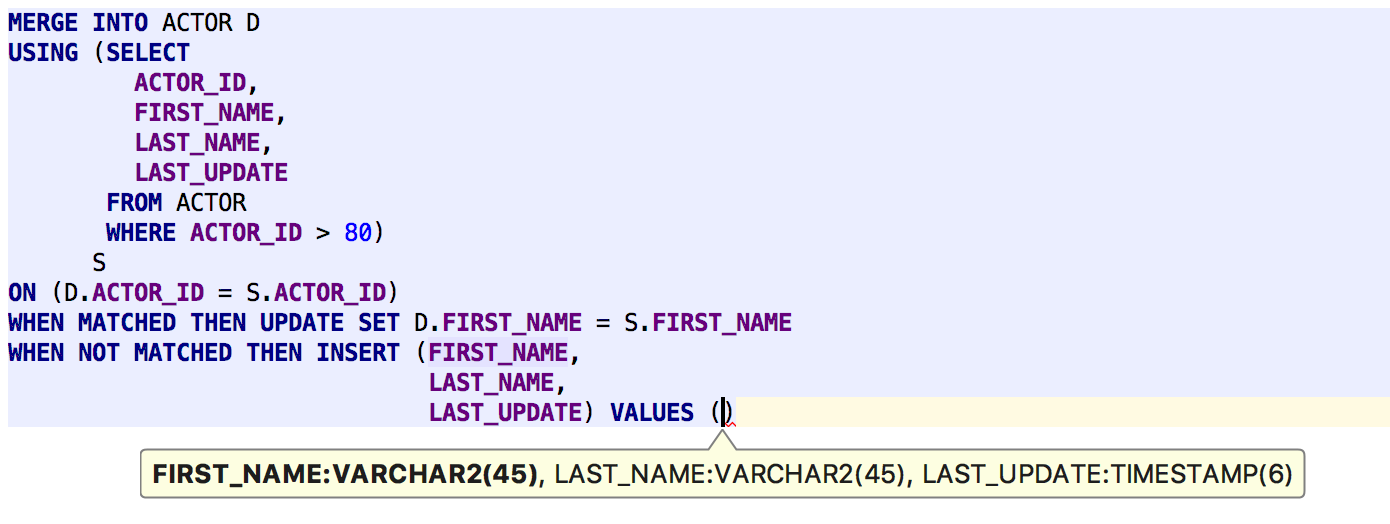
We’ve added support for MERGE statements for all databases where they are available.
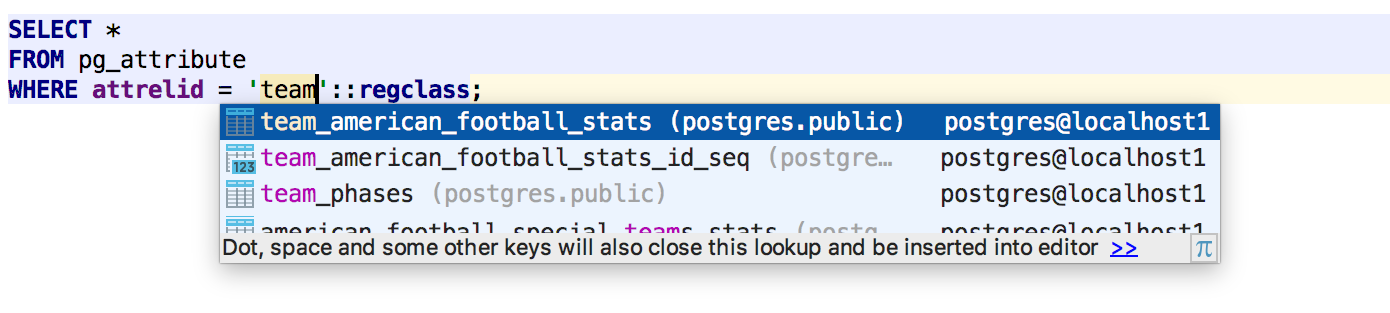
Objects are resolved by their OID values in PostgreSQL.
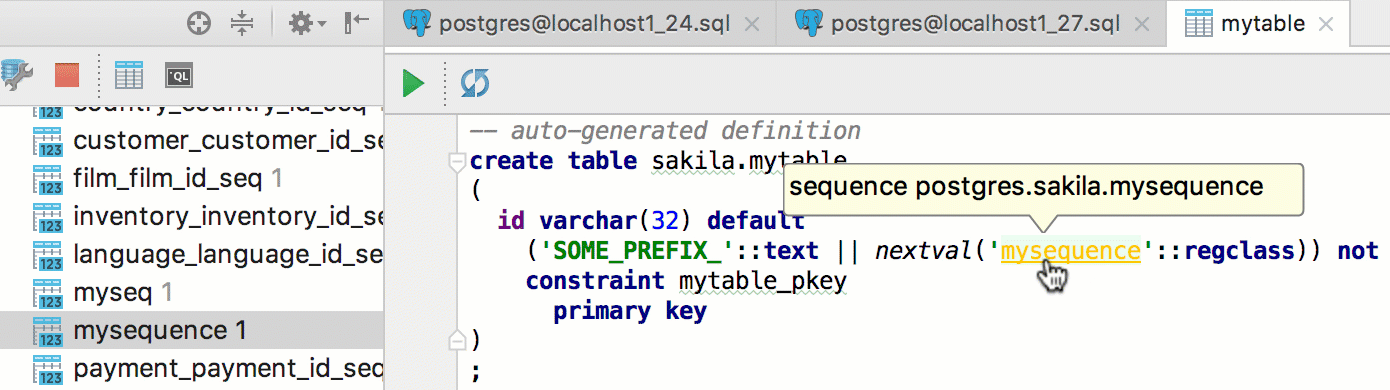
Sequences are resolved in scripts as well.
Other
New features:
— Database objects can be added to Bookmarks.
— You can now pause file indexing when you need to free the CPU for other tasks, and then resume it when appropriate.
— We added per-monitor DPI support for Windows. Font settings are automatically adjusted based on the display resolution.
— Lines with two identical results are merged in Find in Path.
— Support for non-int-literal expressions in TABLESAMPLE and ALTER FOREIGN TABLE in Postgres.
— Support for ‘json_table’ function in Oracle.
Important fixes:
— DBE-4600 with renaming schemas.
— DBE-1288 with renaming sequences in PostgreSQL.
— DBE-4507 in composite primary key editing.
— DBE-4637 about a wrong error message in queries with GROUP BY.
— Faster data editor scrolling
Get your 30-day trial of DataGrip here.
That’s it! Don’t forget about twitter, forum, and the issue tracker.
Your DataGrip Team
_
JetBrains
The Drive to Develop




