Datalore
Collaborative data science platform for teams
New in Datalore: S3 Buckets Support, Workspace Files, Two Inspiring Research Posts and Other Updates
Though this is our final blog post of 2020, we have a bunch of new Datalore updates we’d like to share, including the results of two major studies we recently conducted.

S3 buckets support
Here’s some more detail on how to benefit from the S3 bucket support, which we announced in this Pro plan updates blog post earlier this month.
Connecting and mounting an external S3 bucket will help you:
- Extend the storage in Datalore.
- Avoid uploading files to Datalore notebooks if you already store them in an S3 bucket.
- Read and write files to a directory you can share with your team.
In Datalore, you can connect Amazon AWS S3 buckets or use the endpoint_url parameter to connect to other bucket providers from this list.
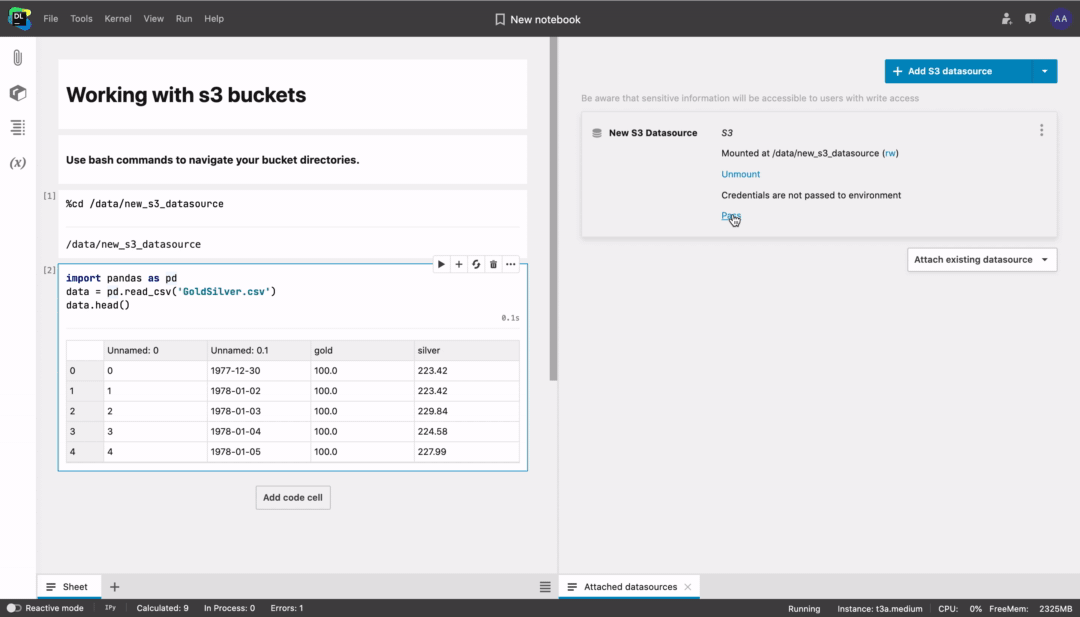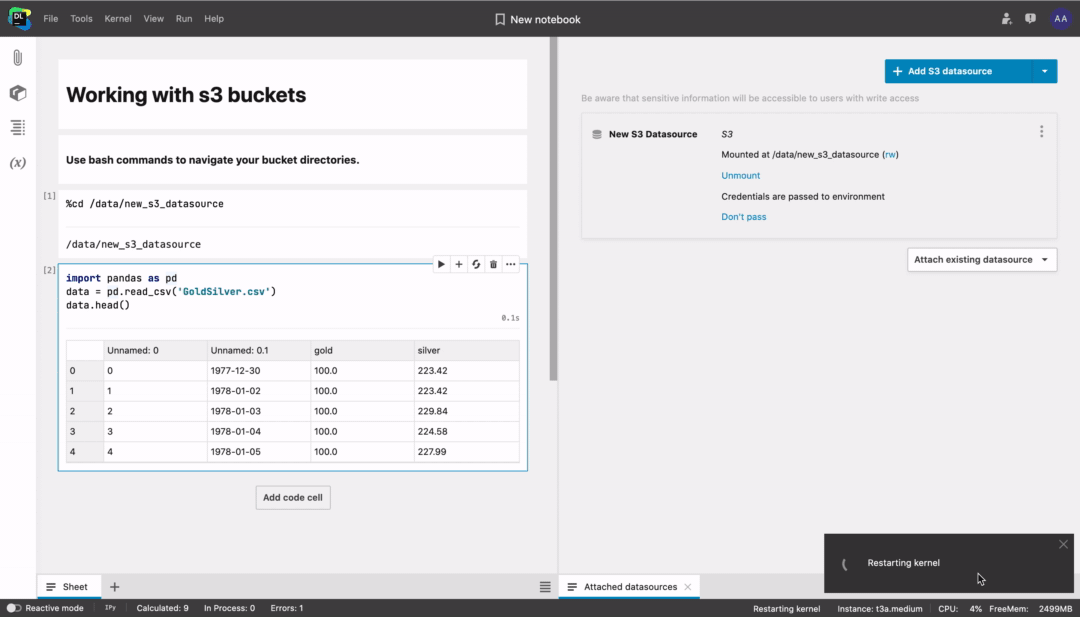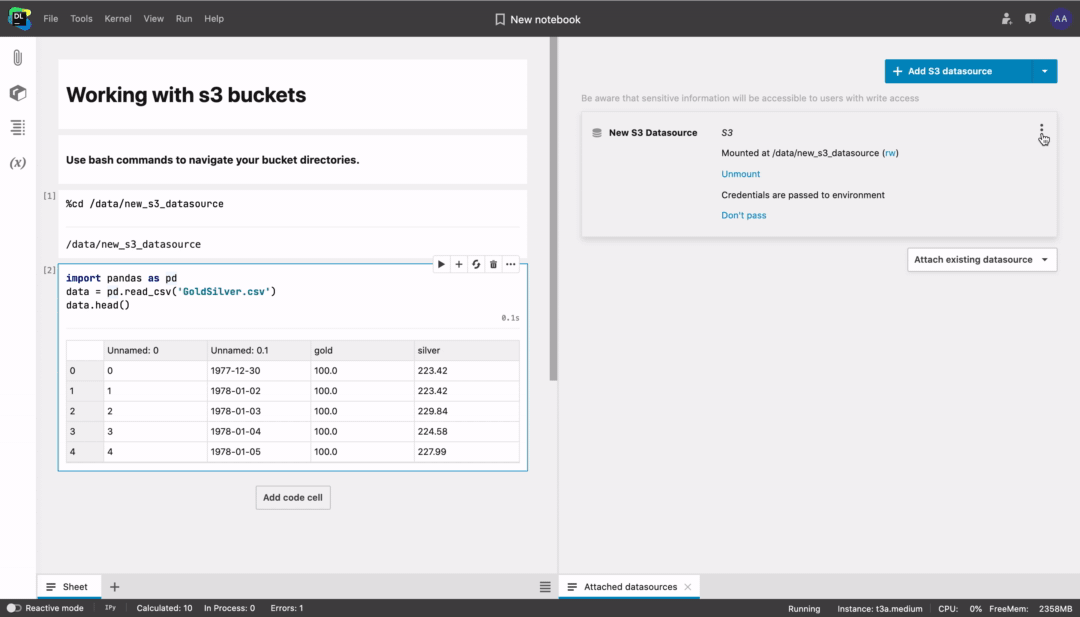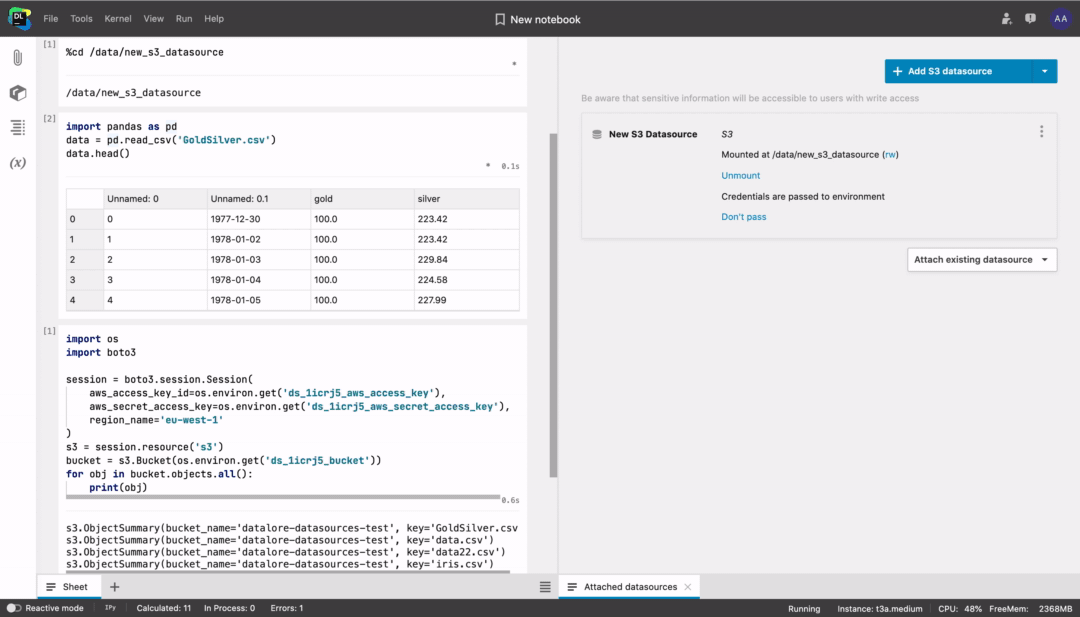
How to connect an S3 bucket in Datalore
Connect a private S3 bucket in Tools → Attached datasources. You will need to provide access keys, a bucket region, and a bucket name. You can find these parameters inside your bucket provider account.
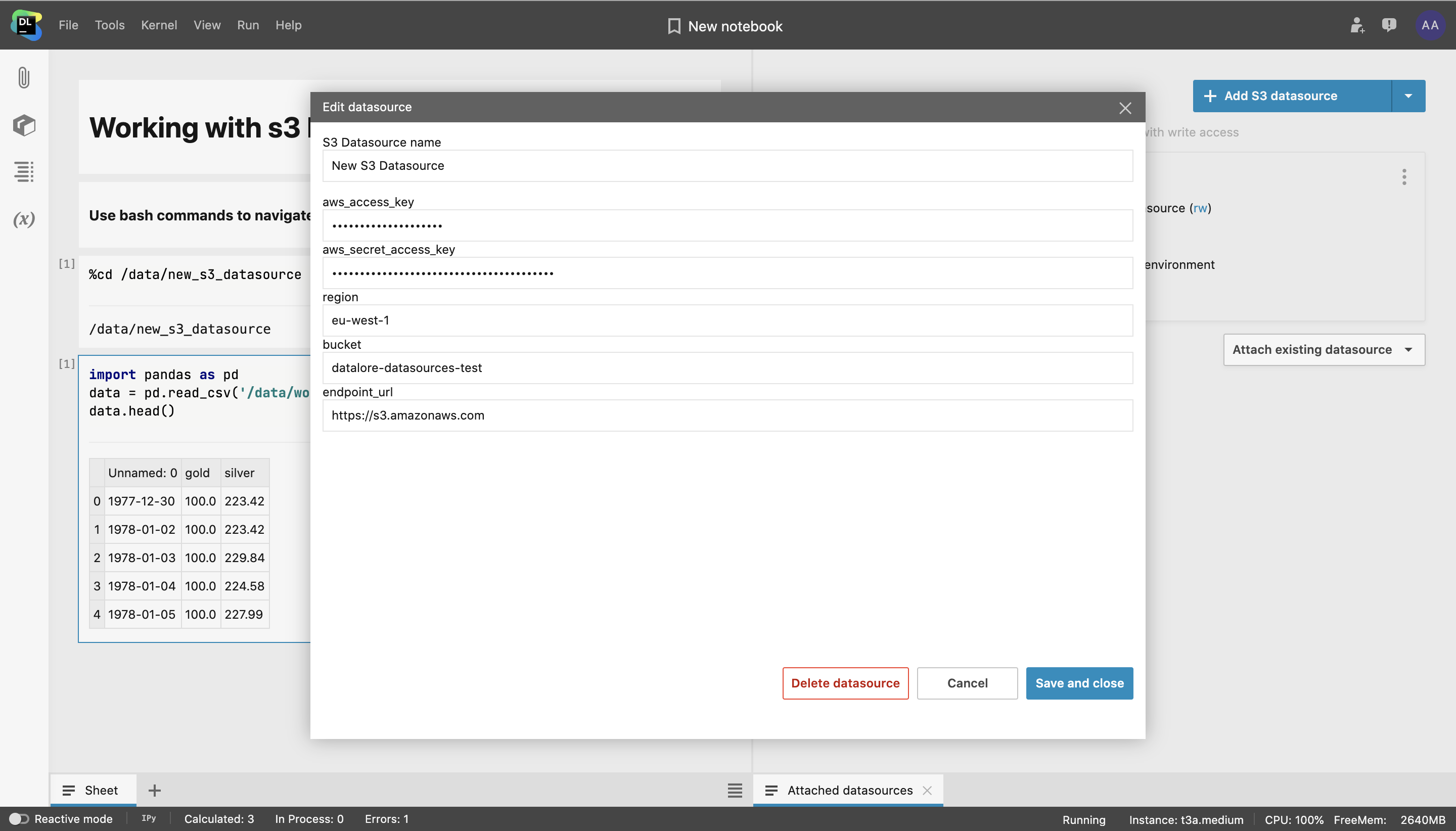
By default the bucket will be mounted with read/write access (rw) and your credentials will not be passed to the environment. You can change these parameters later.
Once attached to a notebook, the bucket will be available for other notebooks in the same workspace.
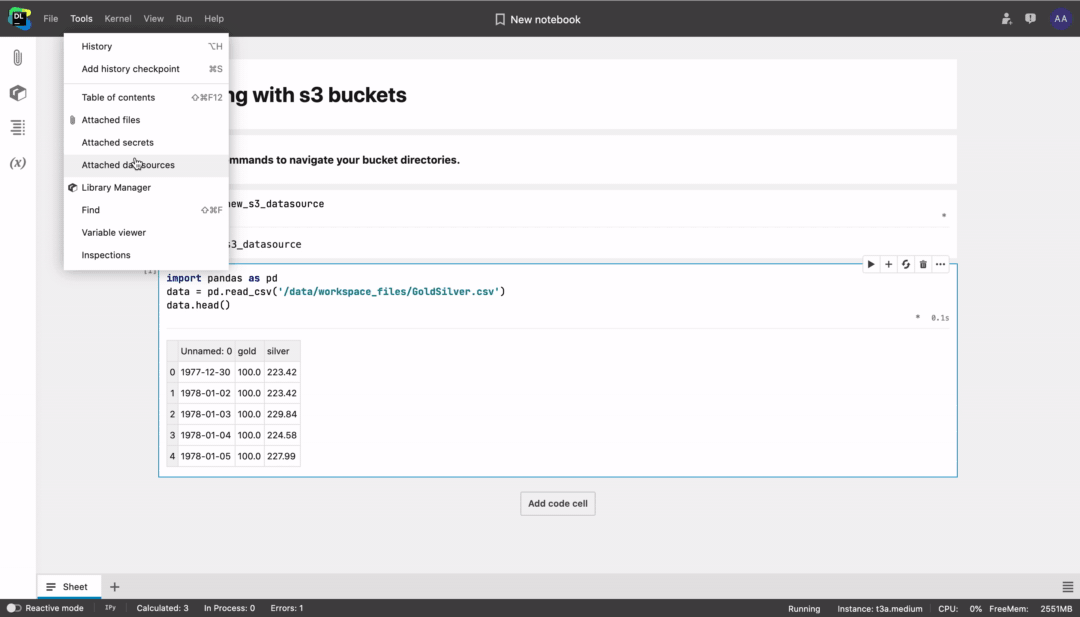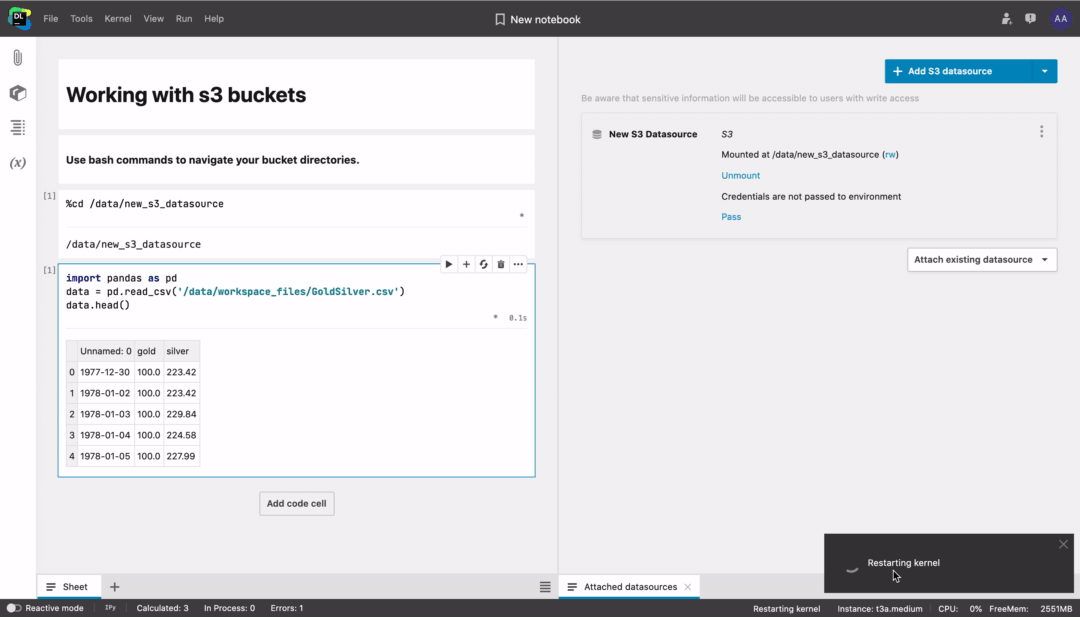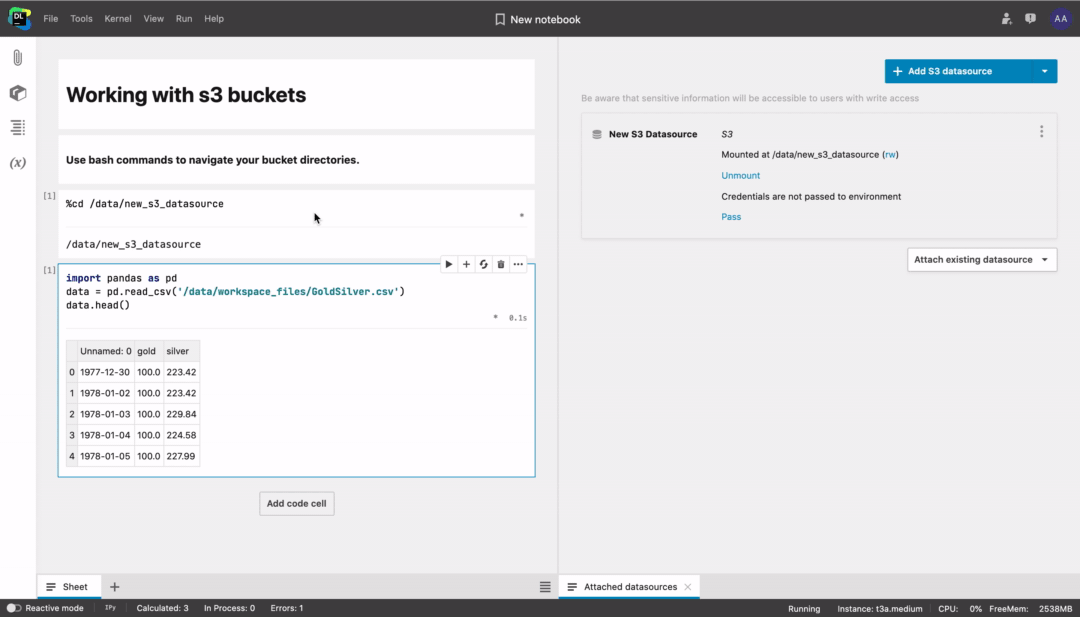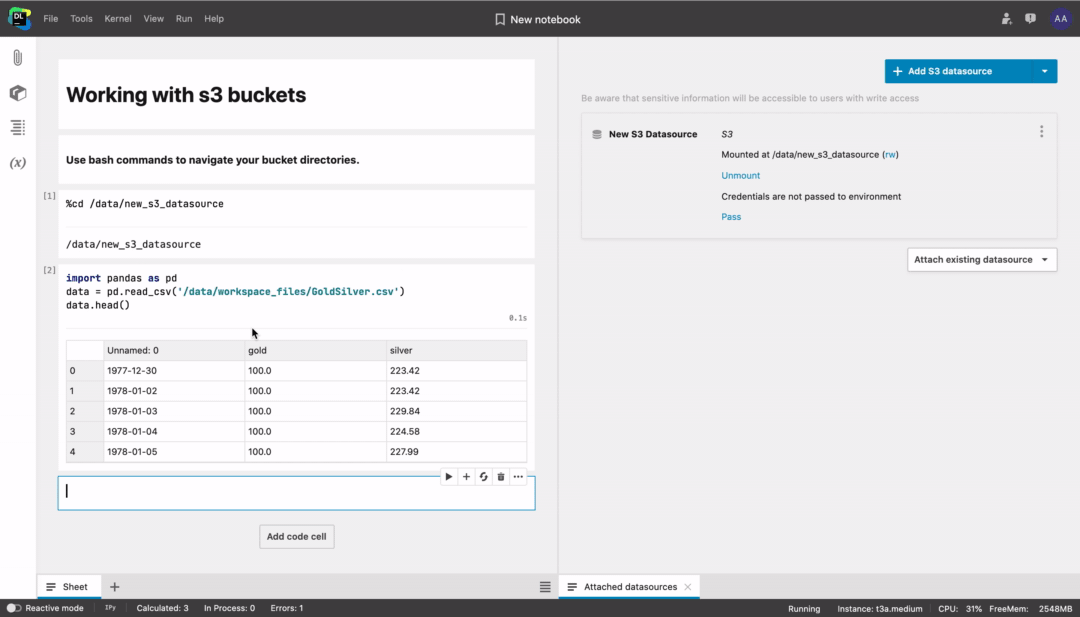
Don’t forget to follow the prompt to restart the kernel.
After mounting the bucket, you can use bash commands to navigate and work with the file system, or directly type code like df = pd.read_csv("/data/my_datasource/my_file.csv”).
💡 Note that some buckets may take a while to mount. Please let us know if you encounter any problems.
To connect using boto3, follow these steps:
- Choose to pass credentials to the environment.
- Restart the kernel.
- In the datasource context menu choose Connect using boto3.
- Run the simple generated template code from the notebook that connects your S3 bucket using boto3.
Connecting using boto3 might make it easier to work with large S3 buckets. Learn more from the boto3 documentation.
Workspace files
This month we implemented support for attaching data to workspaces. This will help you work with the same data files across several different notebooks without uploading the files multiple times.
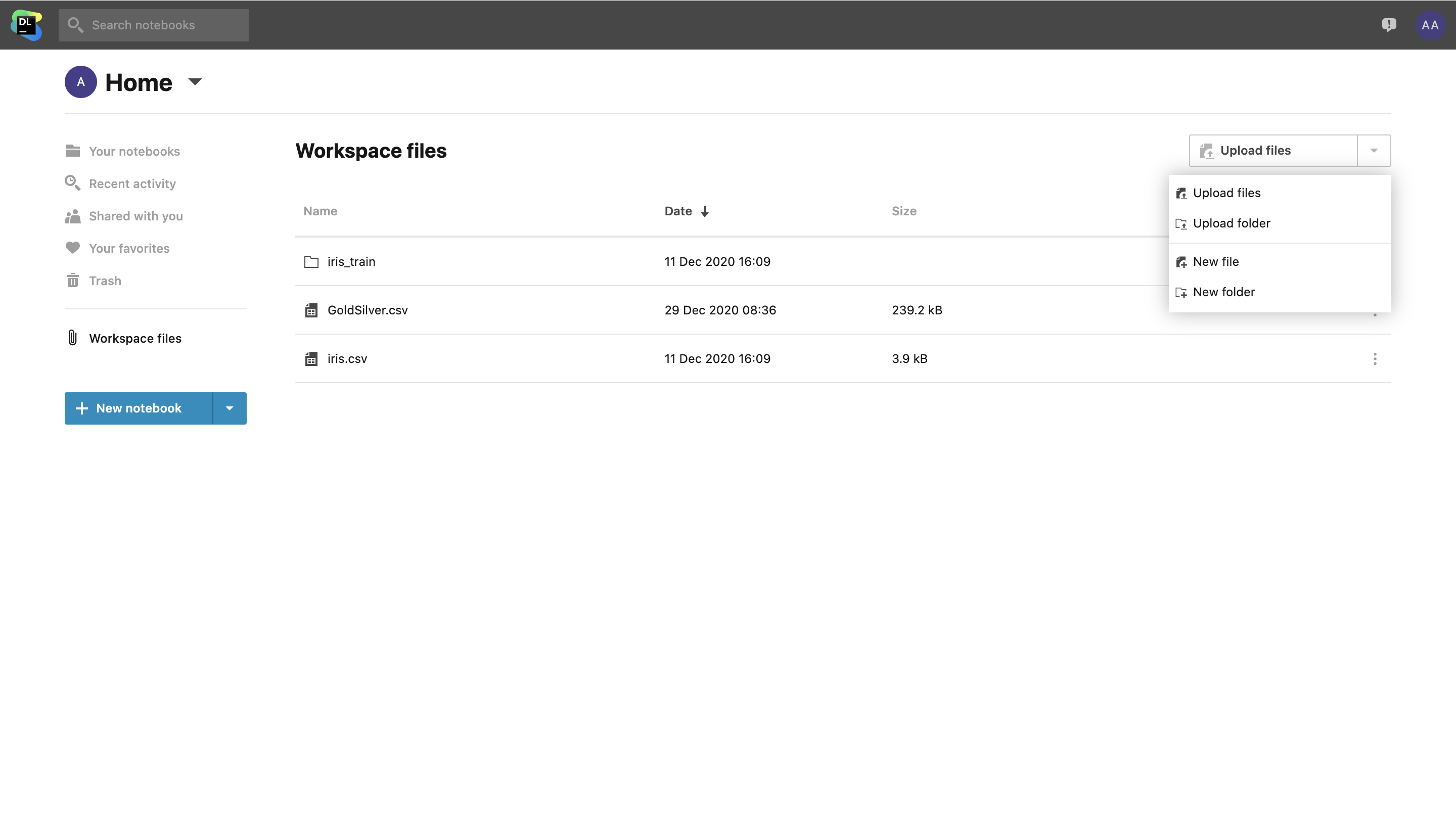
To start working with Workspace, follow these steps:
- Upload files to the whole workspace from the Workspace files tab in the File system.
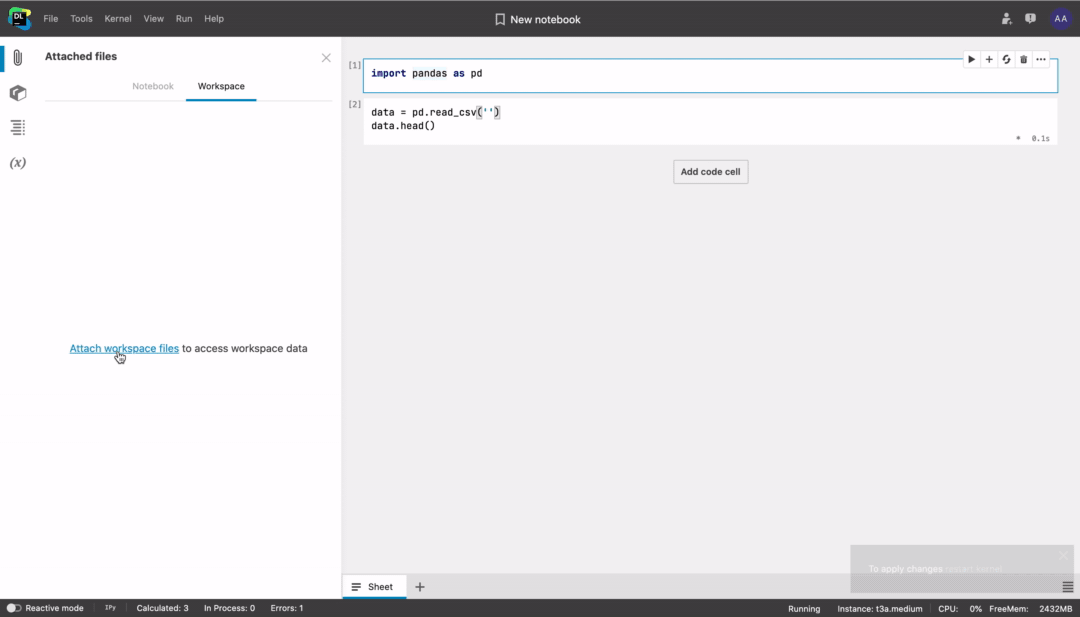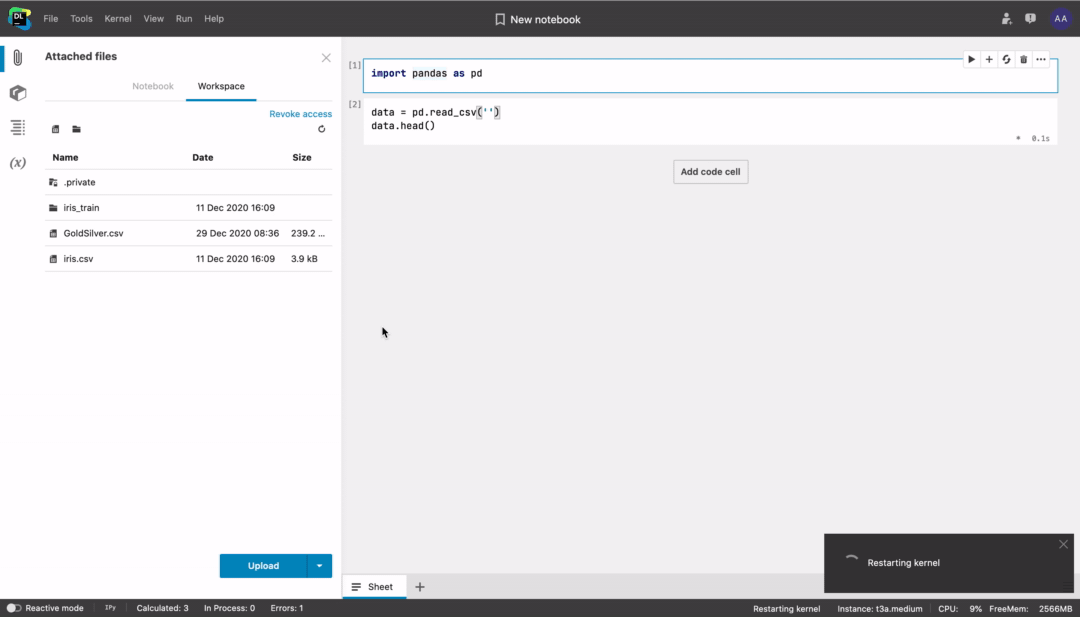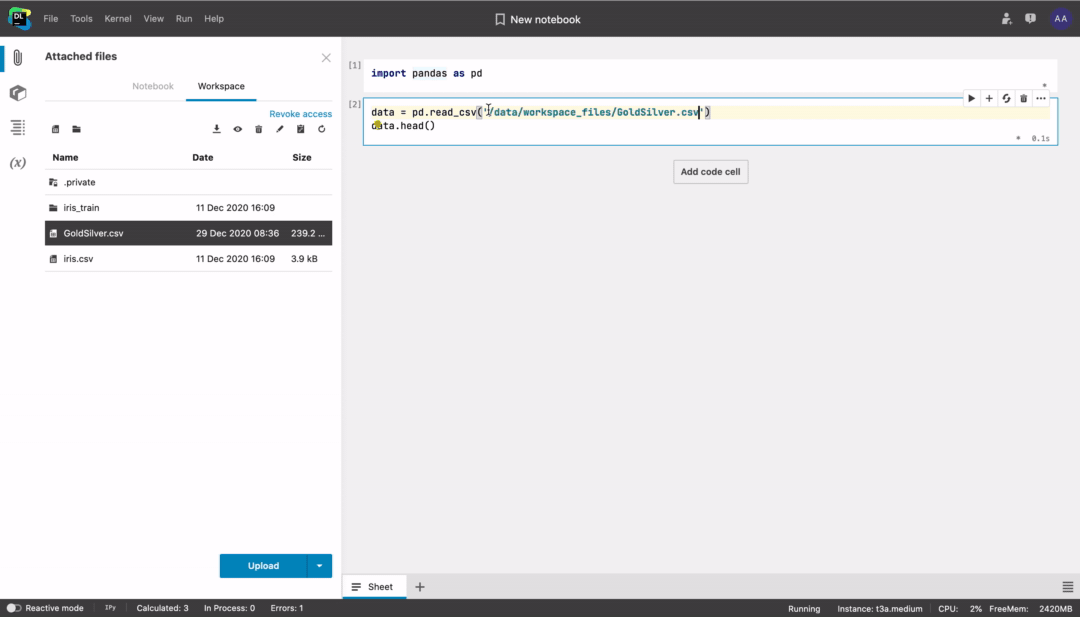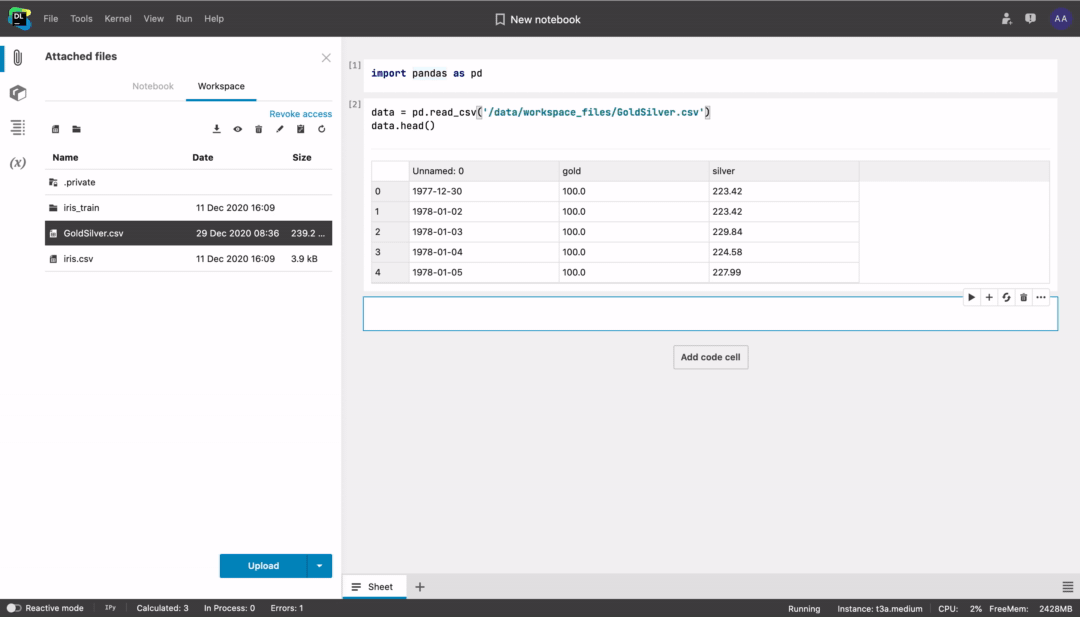
- Go to the Workspace tab inside the Attached files sidebar menu and click Attach workspace files.
- Don’t forget to follow the prompt to restart the kernel.
- Access files in the notebook code from the
/data/workspace_files/directory or select the file you need and click Copy file path to clipboard.
There are now four ways to work with data files inside Datalore:
- Attach data files directly to your notebook.
- Attach data files to the whole workspace.
- Mount your external S3 buckets.
- Download or generate data from the code.
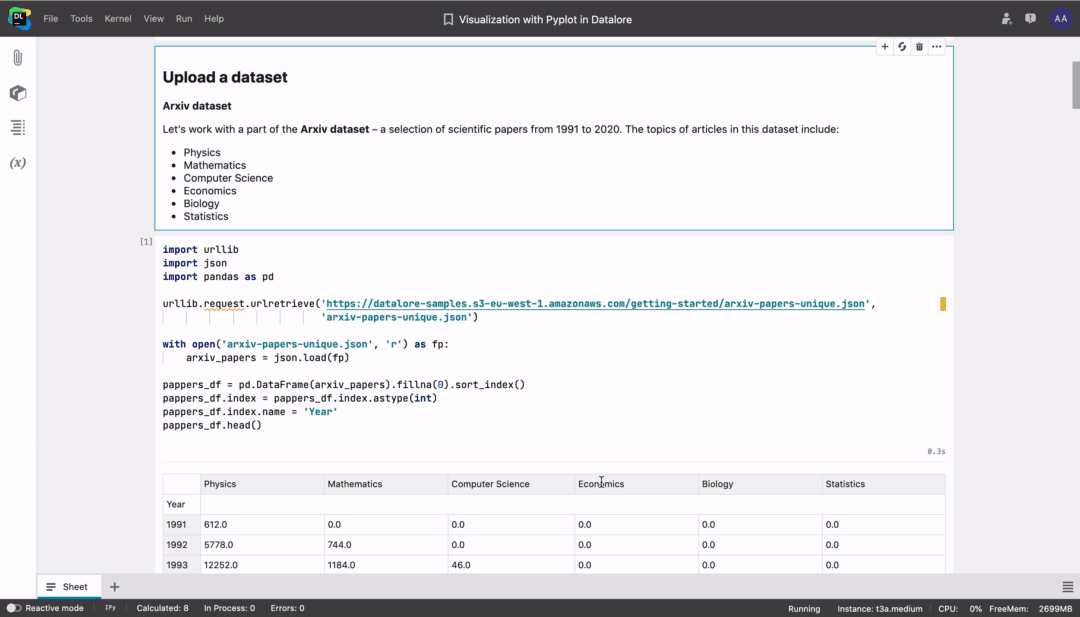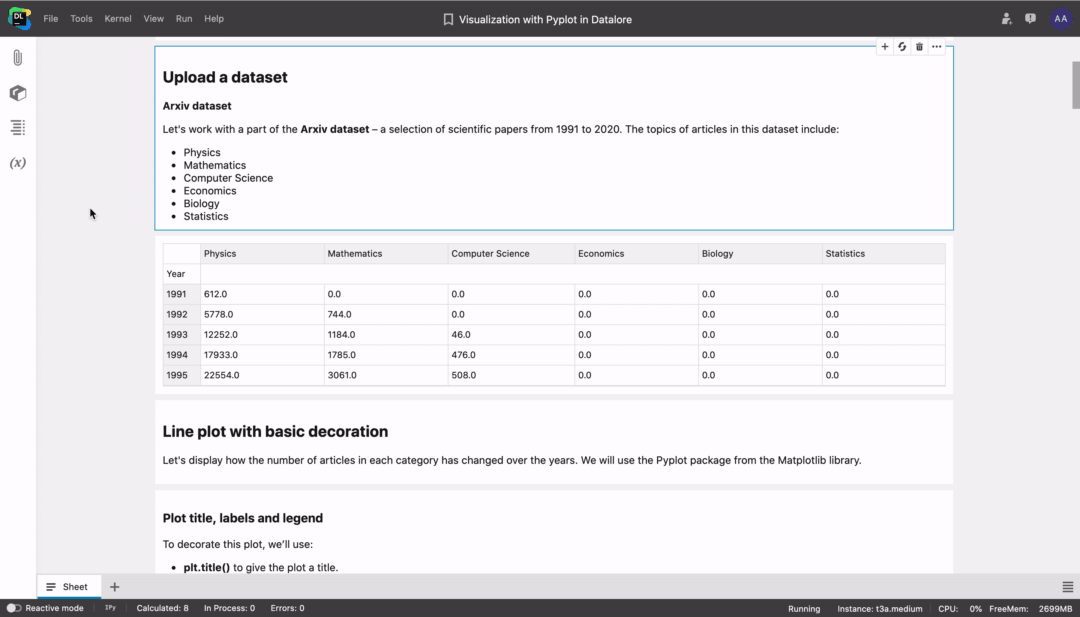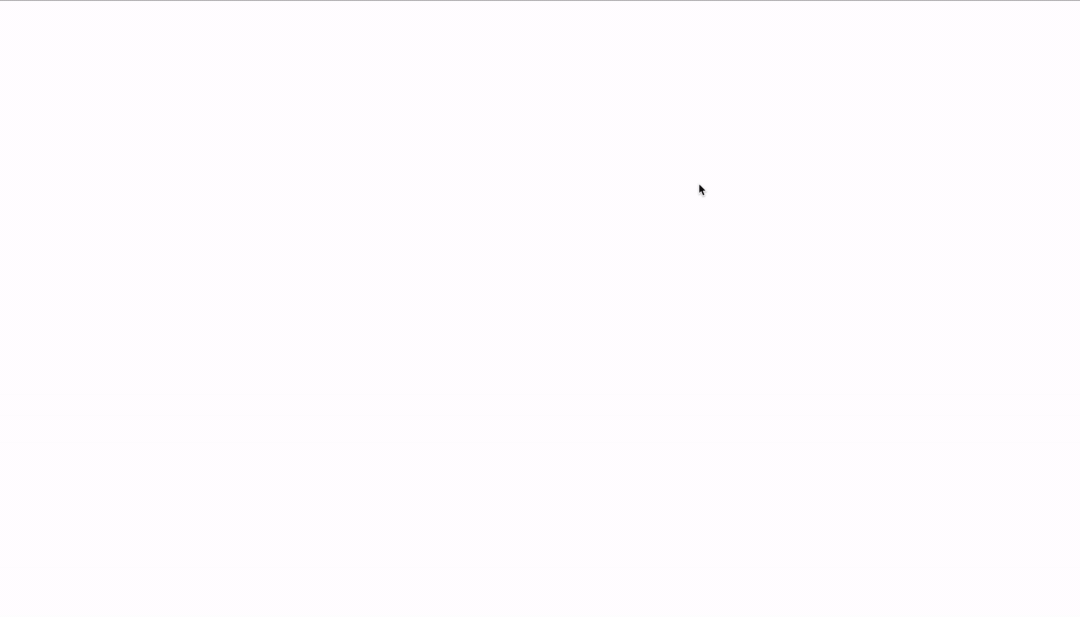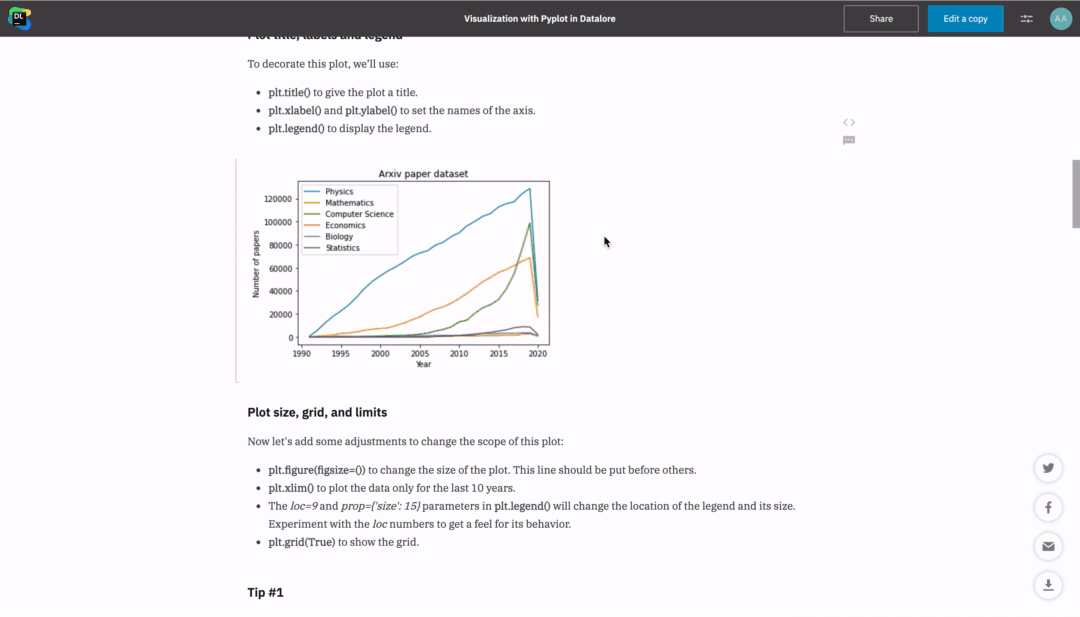
Sharing notebooks with collapsed inputs
Try collapsing cell inputs if you want to share your notebook with your non-tech colleagues or show the results without displaying the code. We hope this feature will help you deliver cleaner reports.
To collapse cell inputs go to the View menu tab.
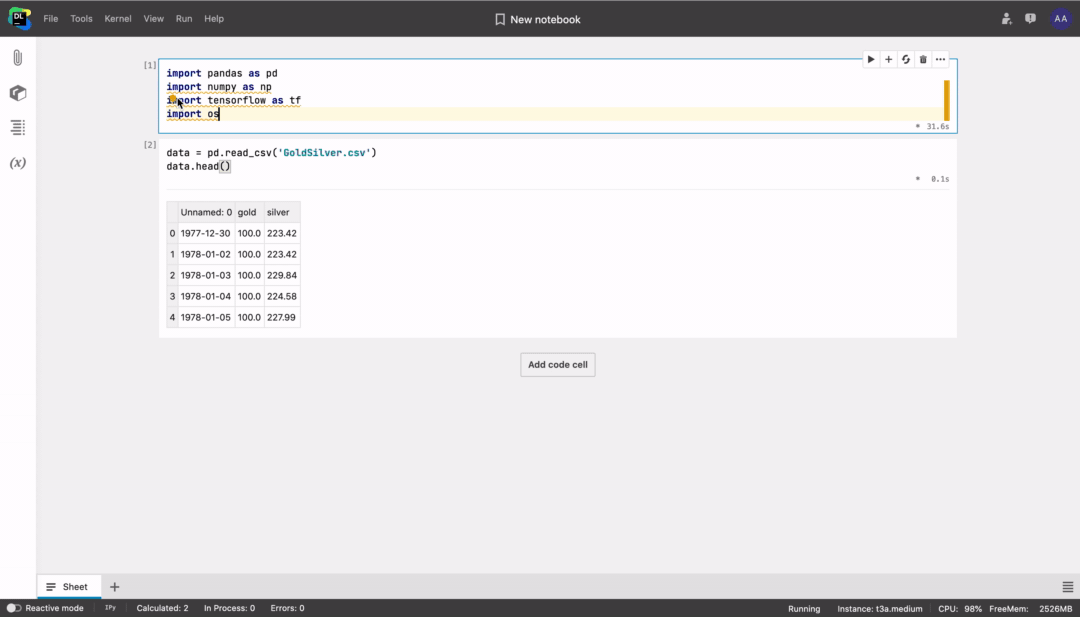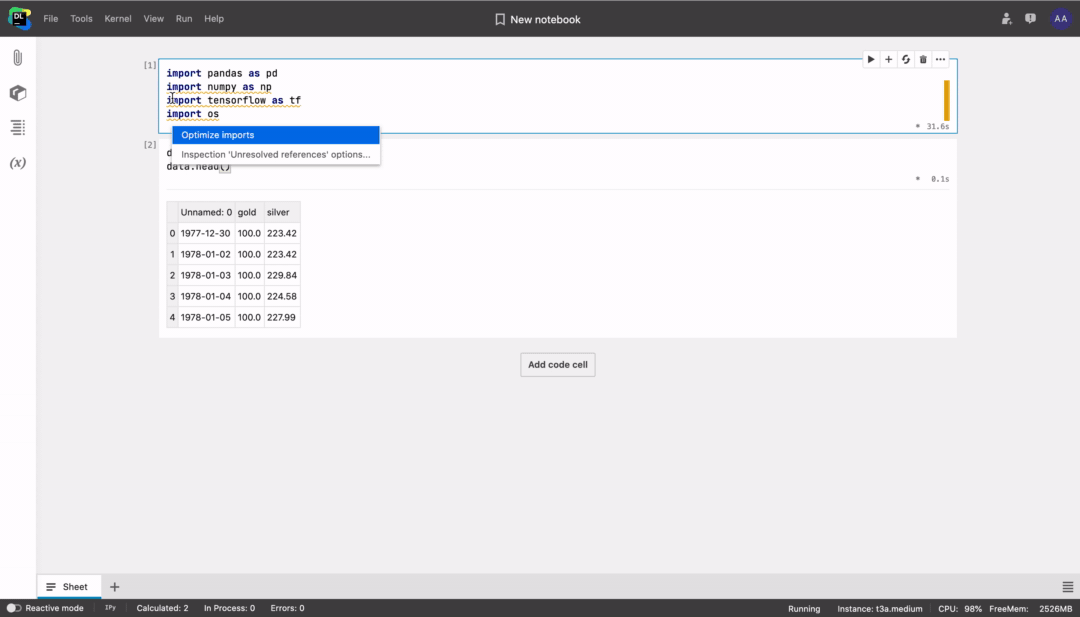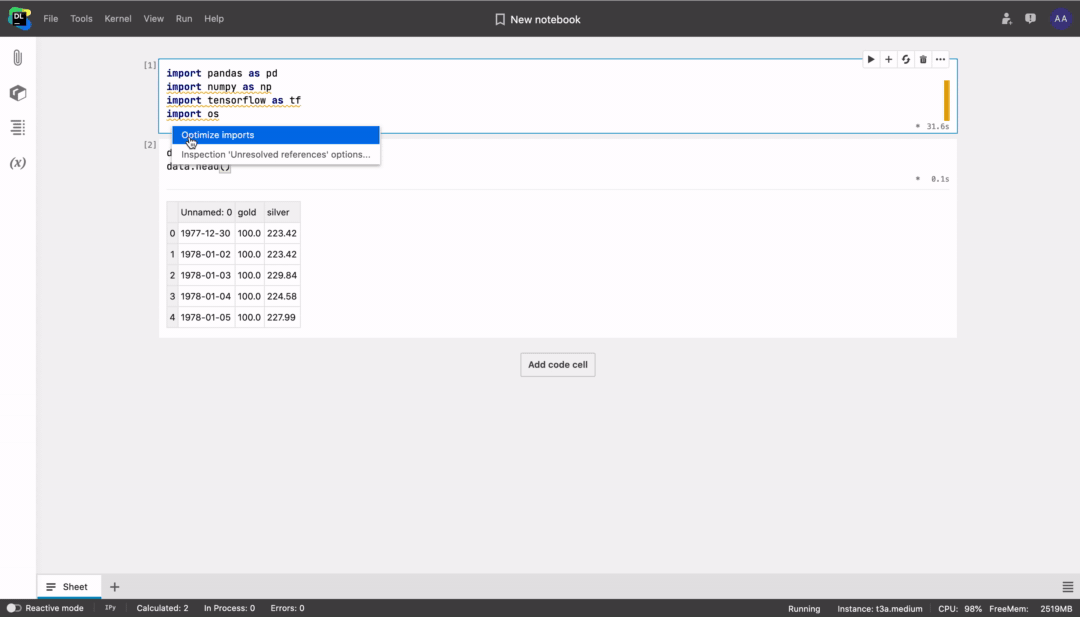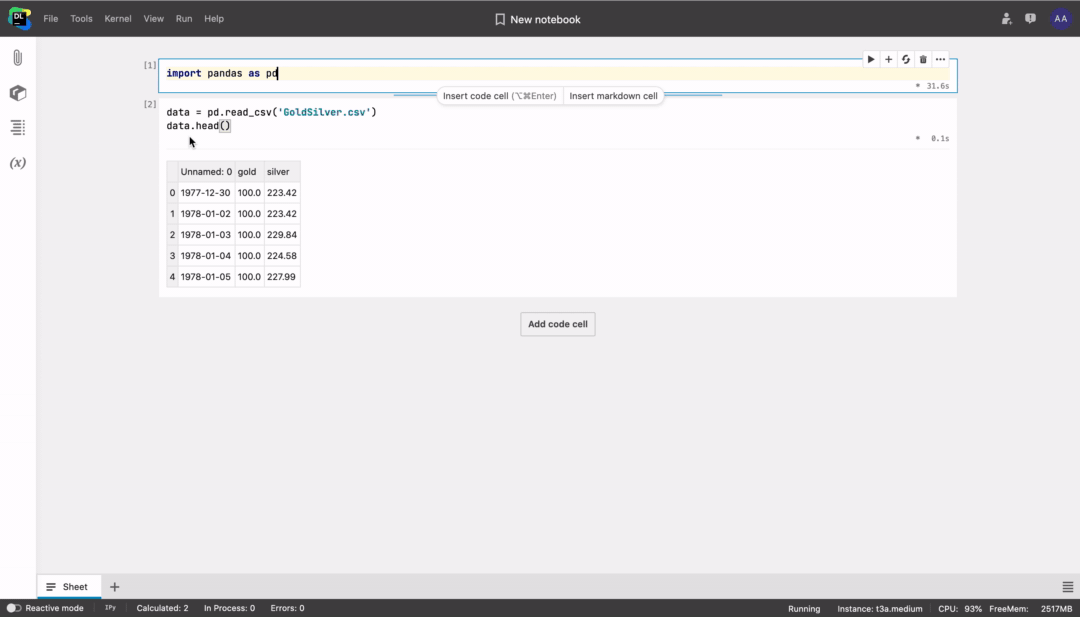
Optimizing imports with quick-fix
Datalore will highlight unused library imports and suggest removing them from the notebook.
Jupyter notebooks research and GPU specification analysis
In December we finalized two major researches of the last months:
- We Downloaded 10,000,000 Jupyter Notebooks From GitHub
- We Analyzed 495 AMD Radeon and Nvidia GPU Specifications
For both studies, we created datasets and shared them publicly. Have a read through the posts and let us know what you think by mentioning us on Twitter.
If you have any feedback or feature suggestions, please email them to us at contact@datalore.jetbrains.com or post them on our forum.
We wish you a happy and safe new year full of inspiring projects!
Kind regards,
The Datalore Team