

Datalore
Collaborative data science platform for teams
Revamped Reactive Mode and How It Makes Your Notebooks Reproducible
Greetings from the Datalore team!
Jupyter notebooks can get messy. Perhaps you have tried different things in one notebook, or maybe you have chunks of outdated code and variable declarations all over the place. This isn’t necessarily a sign that something is wrong. Rather, the tool was designed to allow you to work this way.
For the last 3 years, our Datalore team has been experimenting with ways to address the mess. Today we are happy to introduce the new Reactive mode, which helps you make sure your notebooks are always tidy and up-to-date ?
What is the new Reactive mode?
The logic behind the new Reactive mode is quite simple:
It enforces the top-down evaluation order and automatically recalculates the cells below the modified one.
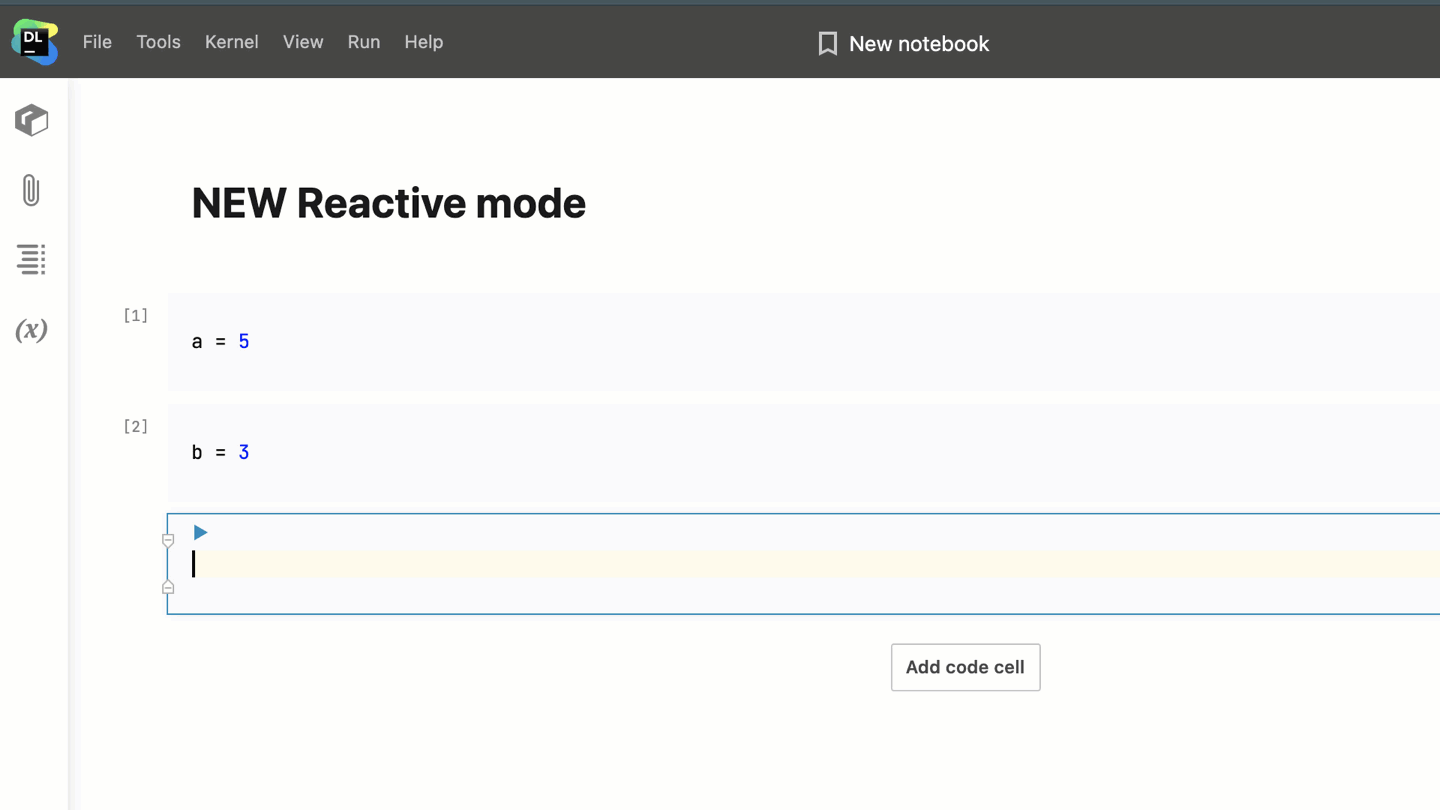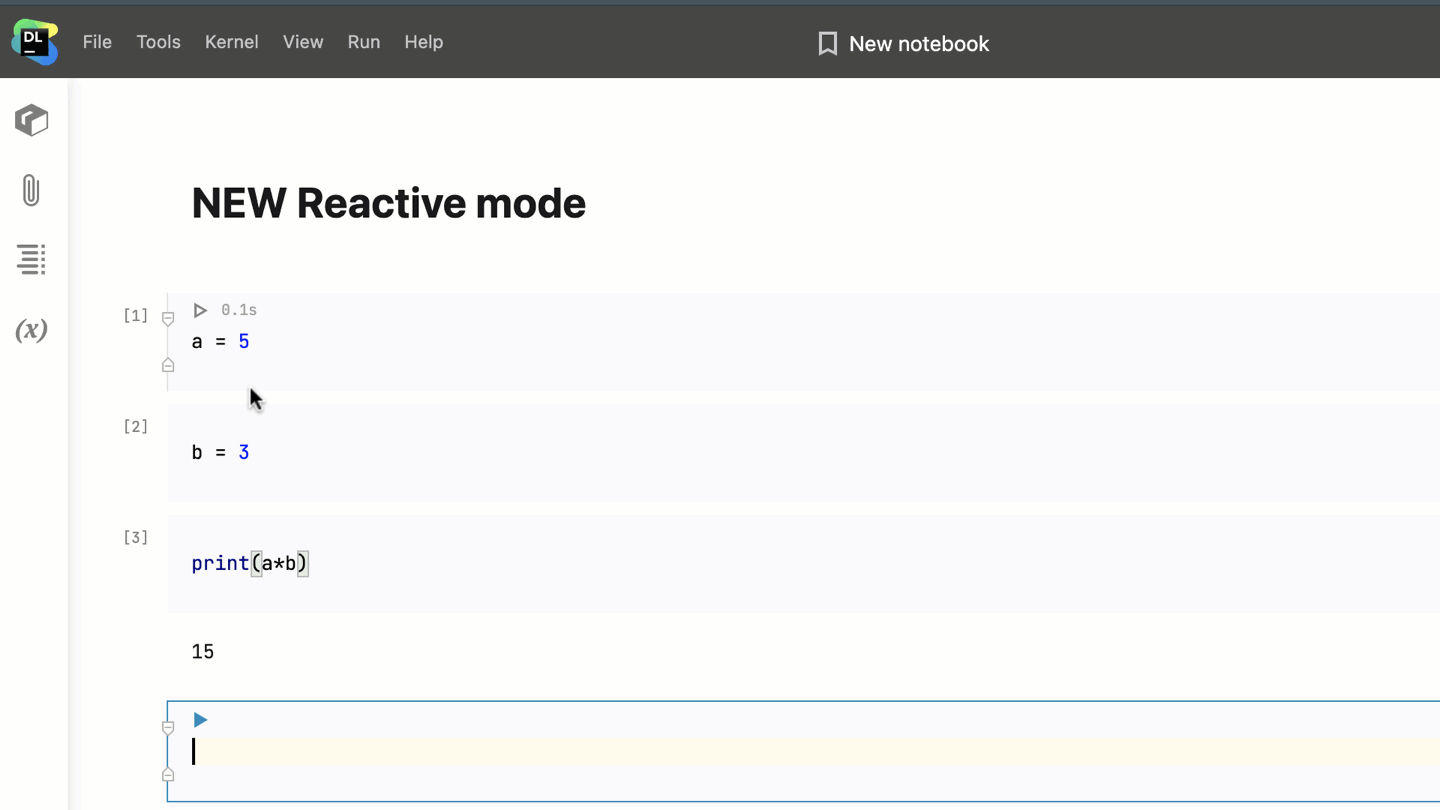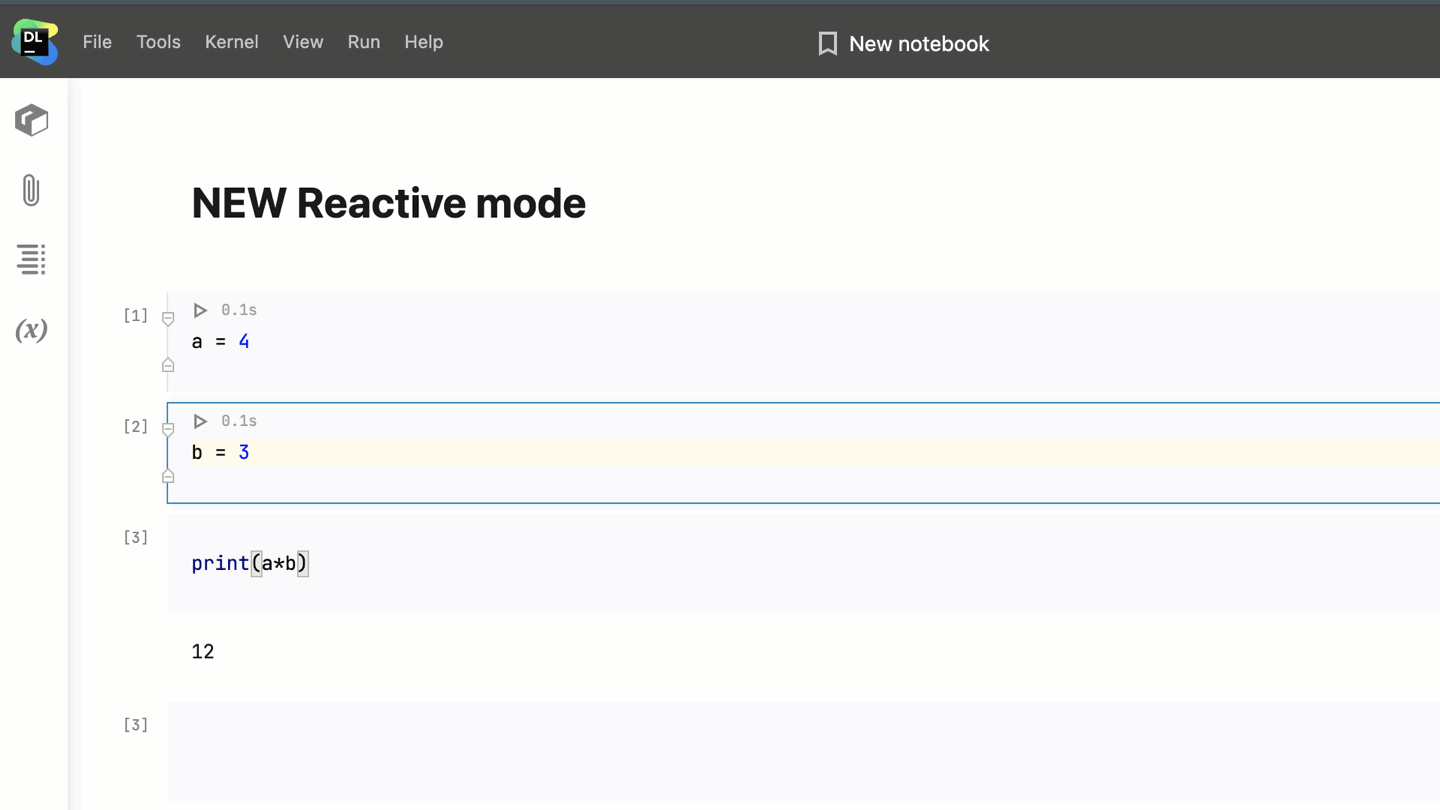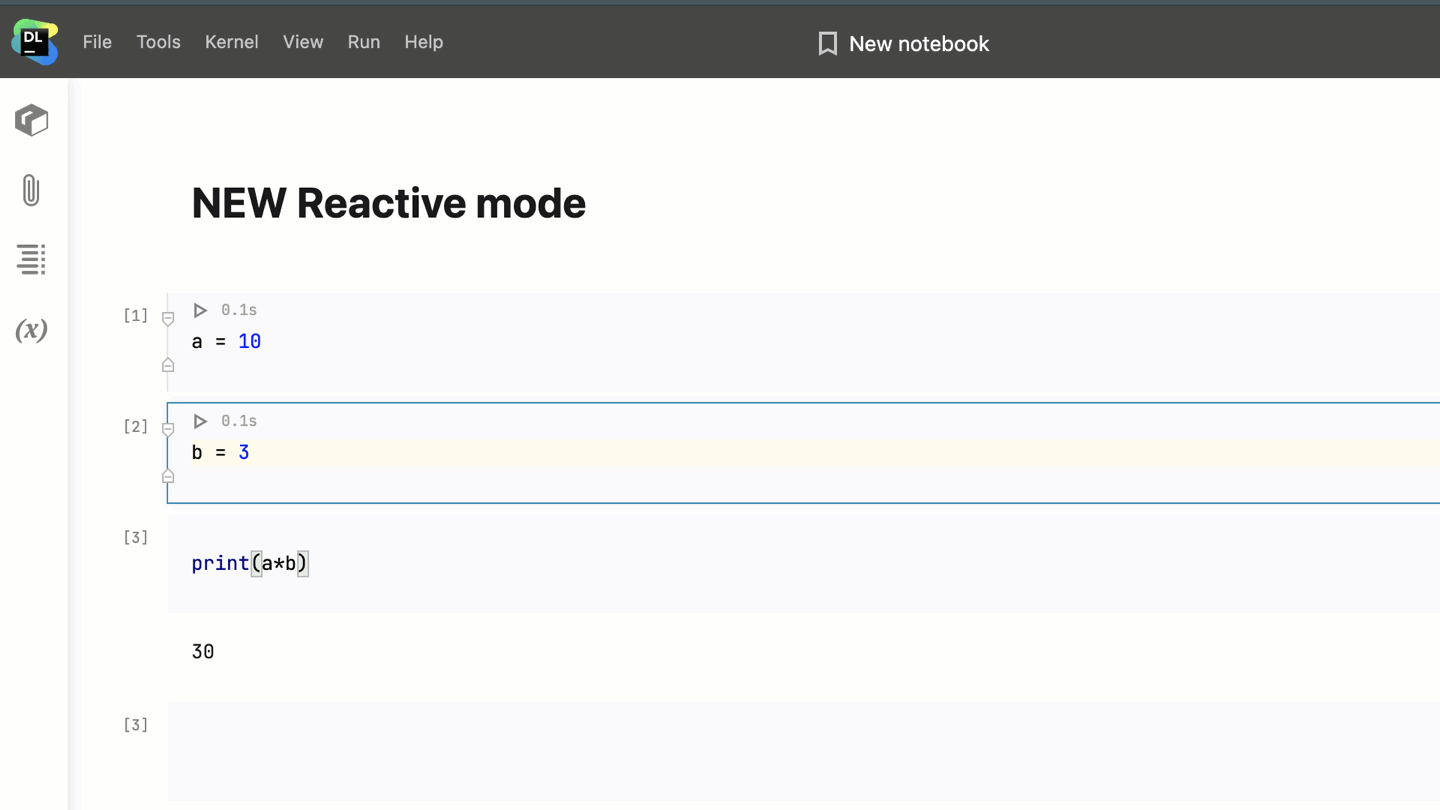
Imagine you have 10 cells in your notebook and you change the contents of the fifth one. When you run the fifth cell with Reactive mode enabled, Datalore will automatically recompute the cells below it, and the contents of your notebook will be updated.
At the same time, the way Reactive mode works in the backend yields an additional advantage:
When you stop working on the notebook and come back to it, say, the next day, you won’t need to recompute the whole notebook and you’ll be able to continue from the point where you left off. In other words, the notebook’s state is saved after each cell evaluation and can be restored at any time.
How is the new mode different from the previous Reactive mode?
The previous Reactive mode from the Datalore kernel had a variety of limitations:
- It relied on the serialization functionality provided by the cloudpickle library. cloudpickle’s serialization works out of the box for most “normal” Python objects, but it requires additional support for many third-party libraries, most notably for modules using native extensions written in C++ or other languages. Unfortunately, in most cases, maintainers of Python packages don’t care about serialization, so many popular libraries don’t work with cloudpickle. This resulted in Reactive mode working inconsistently with some Python packages.
- It started executing the cell upon typing, which could cause undesired side-effects from not-yet-ready code, such as invocations of external APIs, file deletion, and so on.
- As already mentioned, the implementation used Python serialization, which meant it only worked for Python notebooks. A potential extension of this approach to languages other than Python would require starting all over again for each new language.
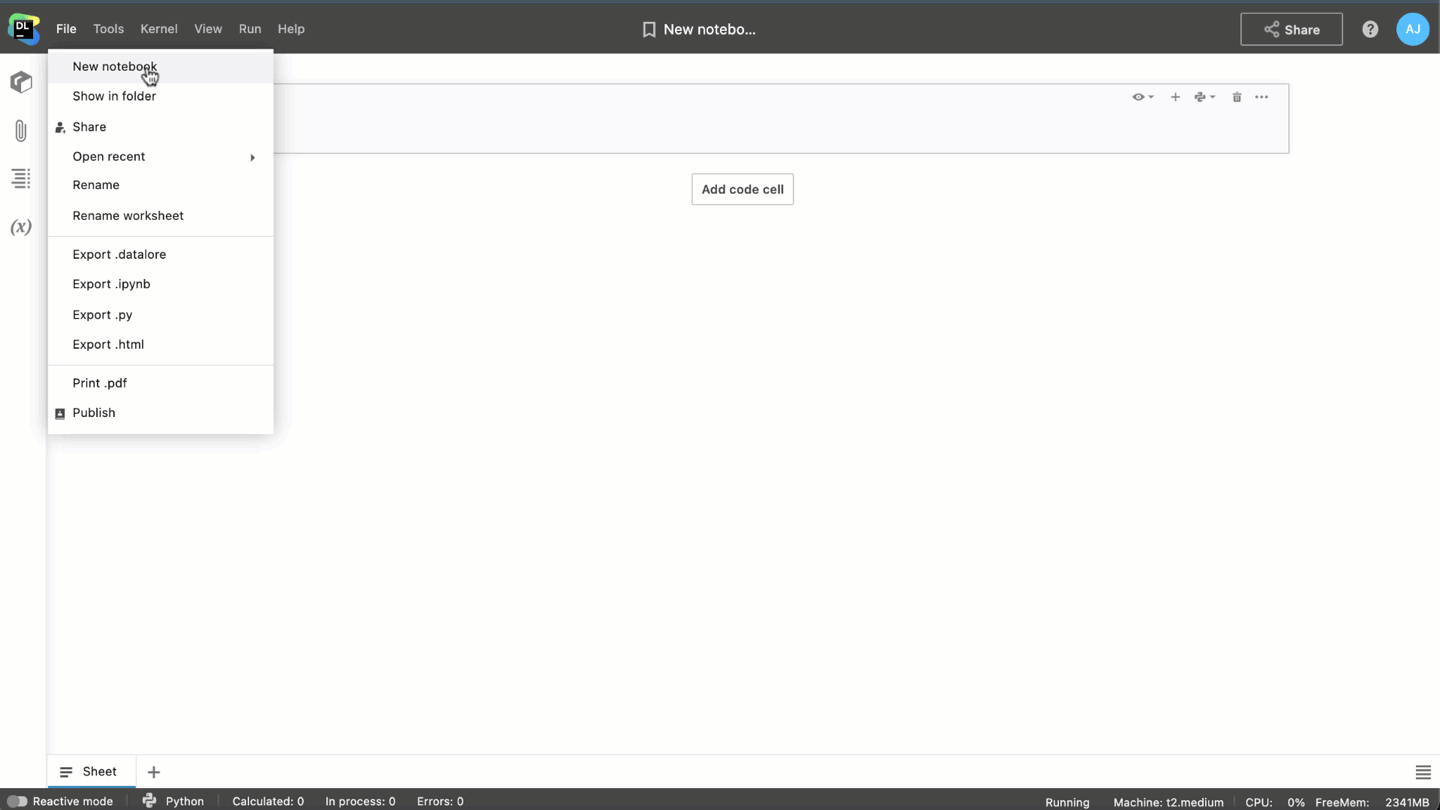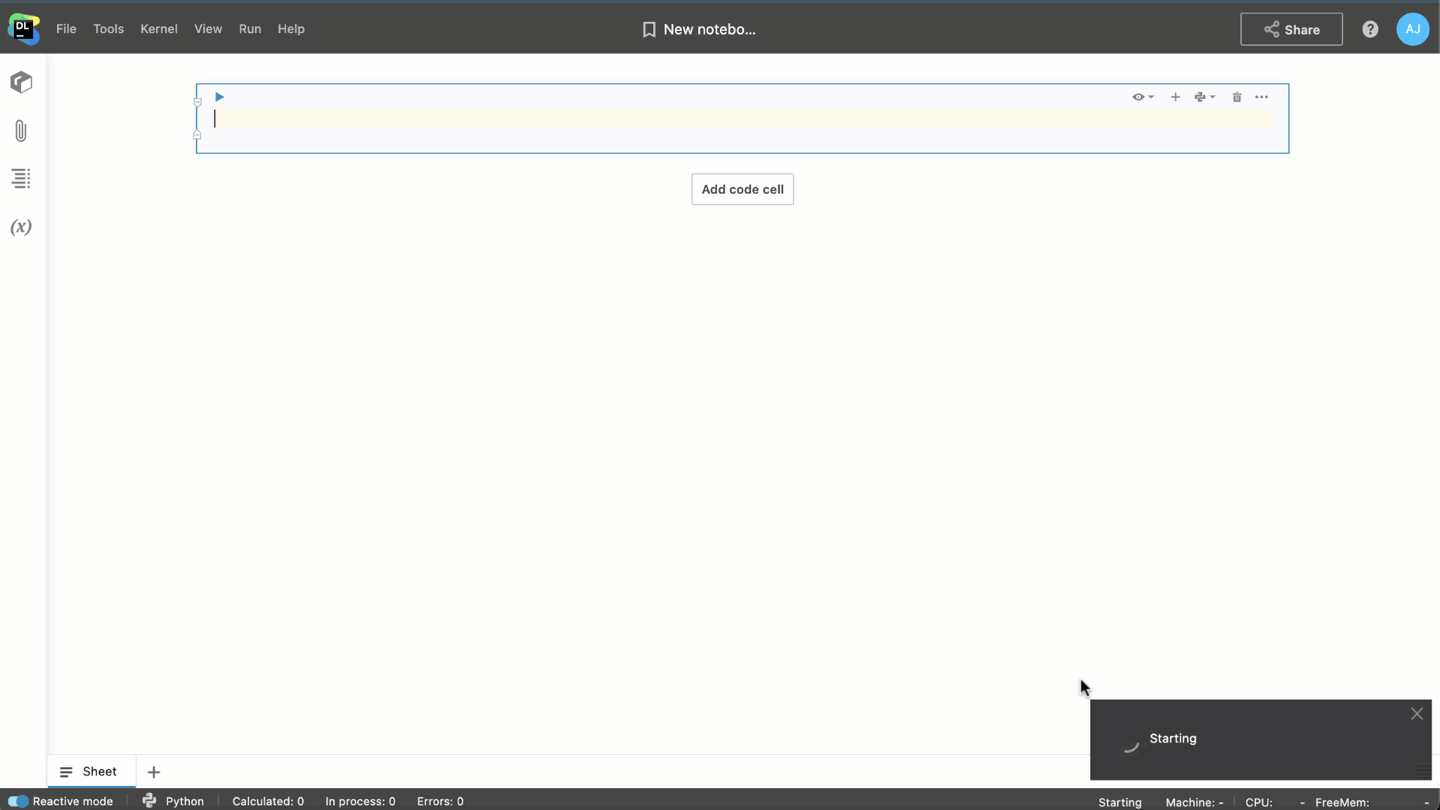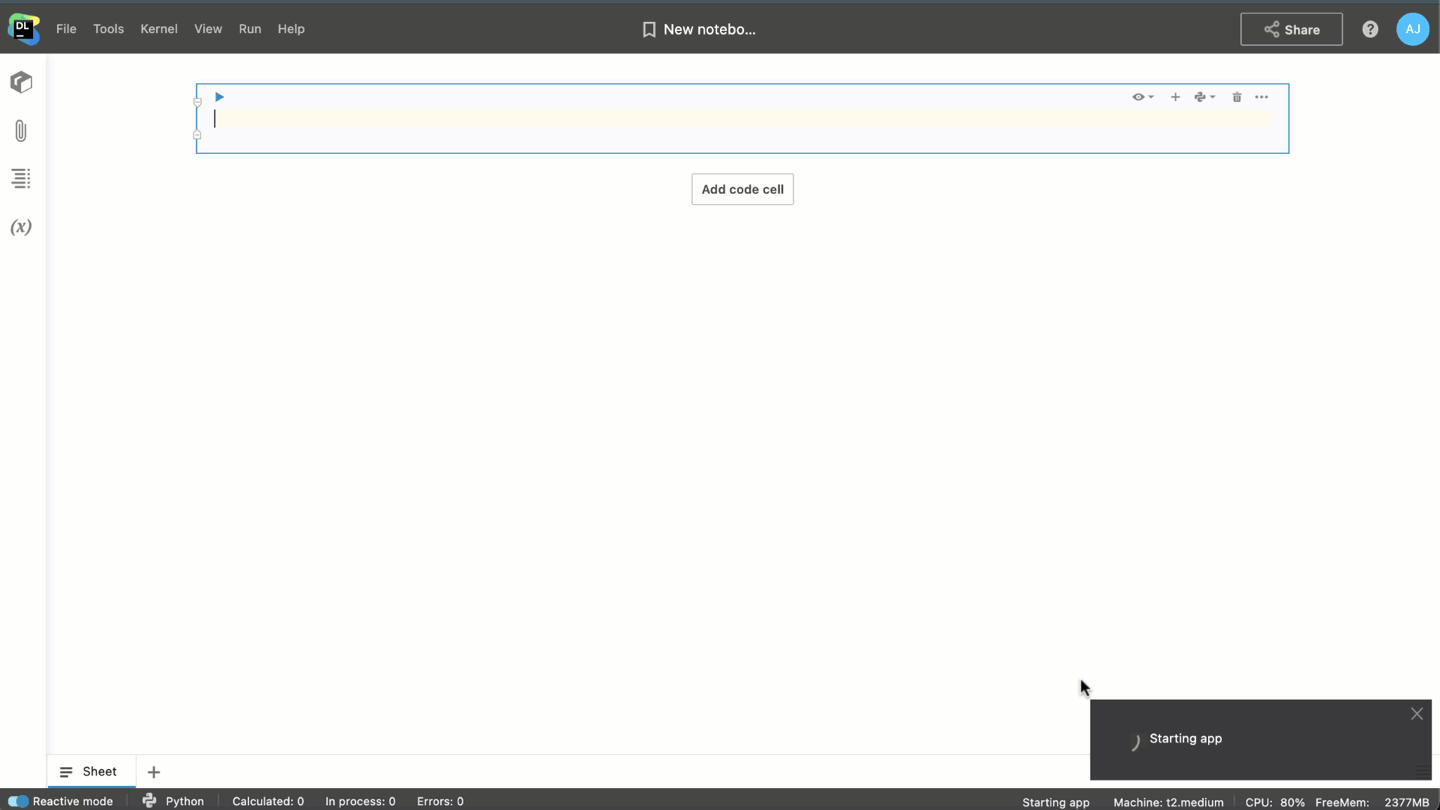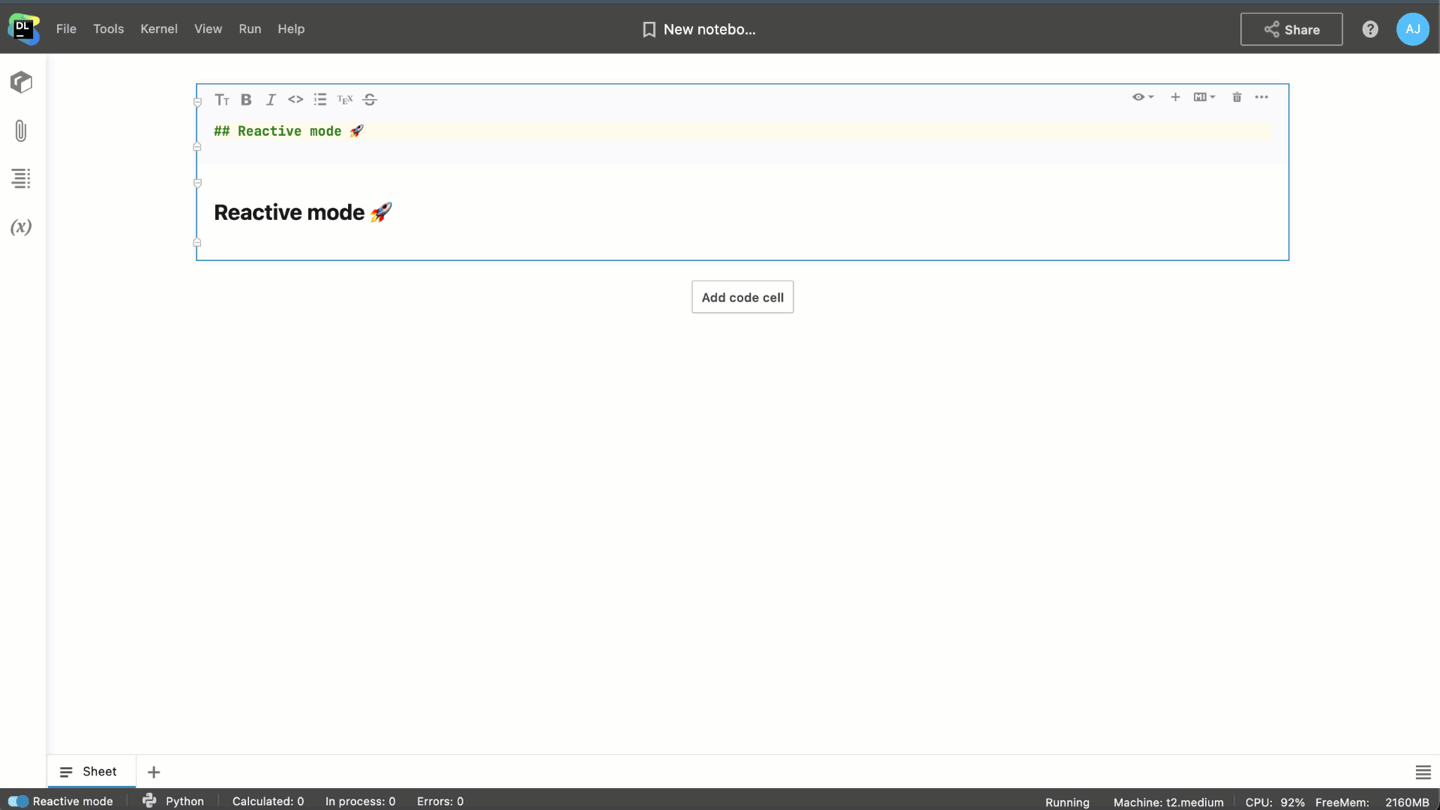
The new Reactive mode addresses all of these challenges:
- It relies on a technology called CRIU (Checkpoint/Restore In Userspace), which provides a generic way to implement backups and restore functionality for arbitrary running Linux applications and which is used by Docker, among others.
- It runs the subsequent cells only after you explicitly press the run button on a modified cell.
- The new approach is completely language-agnostic and works for any Jupyter kernel out of the box.
Reactive mode use cases
- When combined with interactive controls, Reactive mode allows you to turn notebooks into interactive reports.
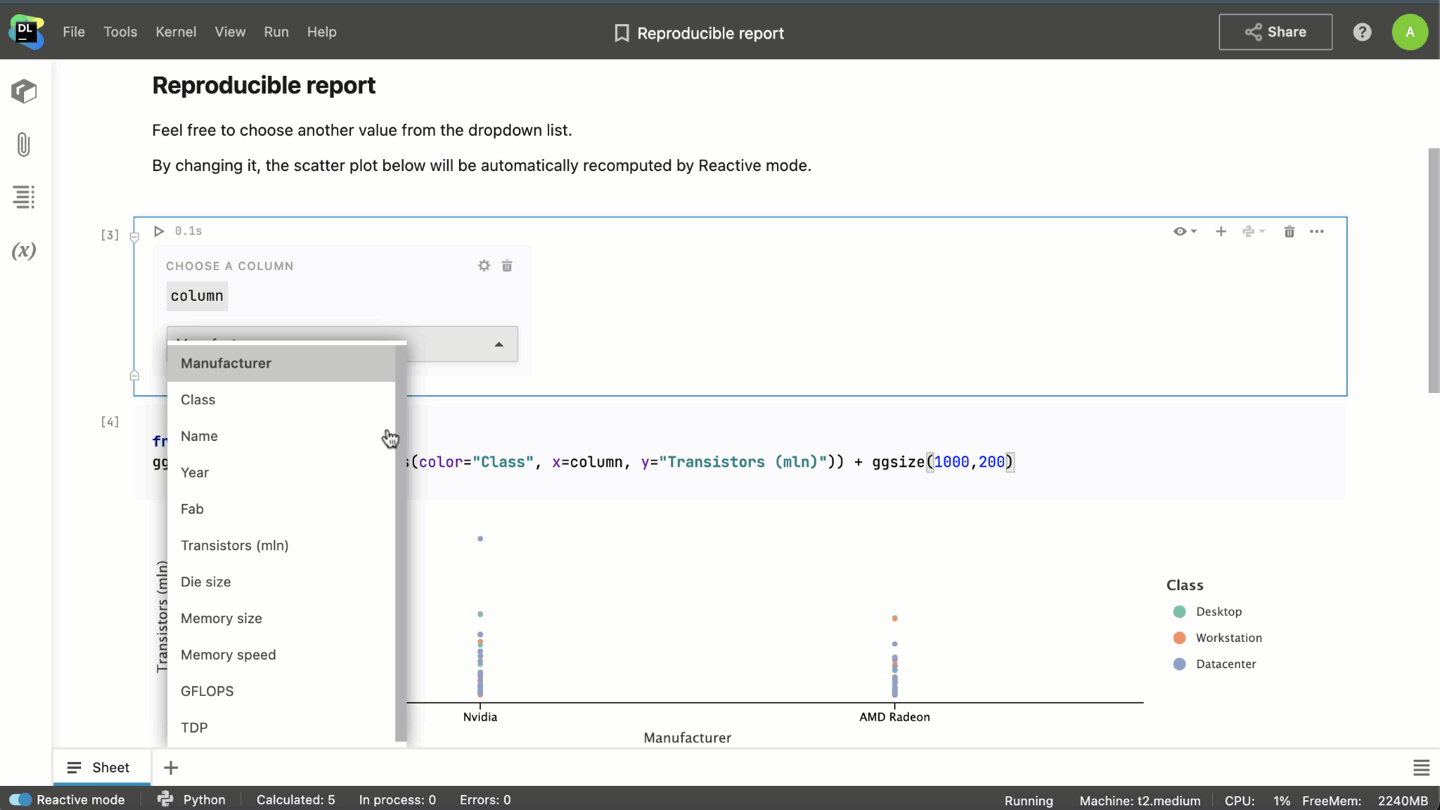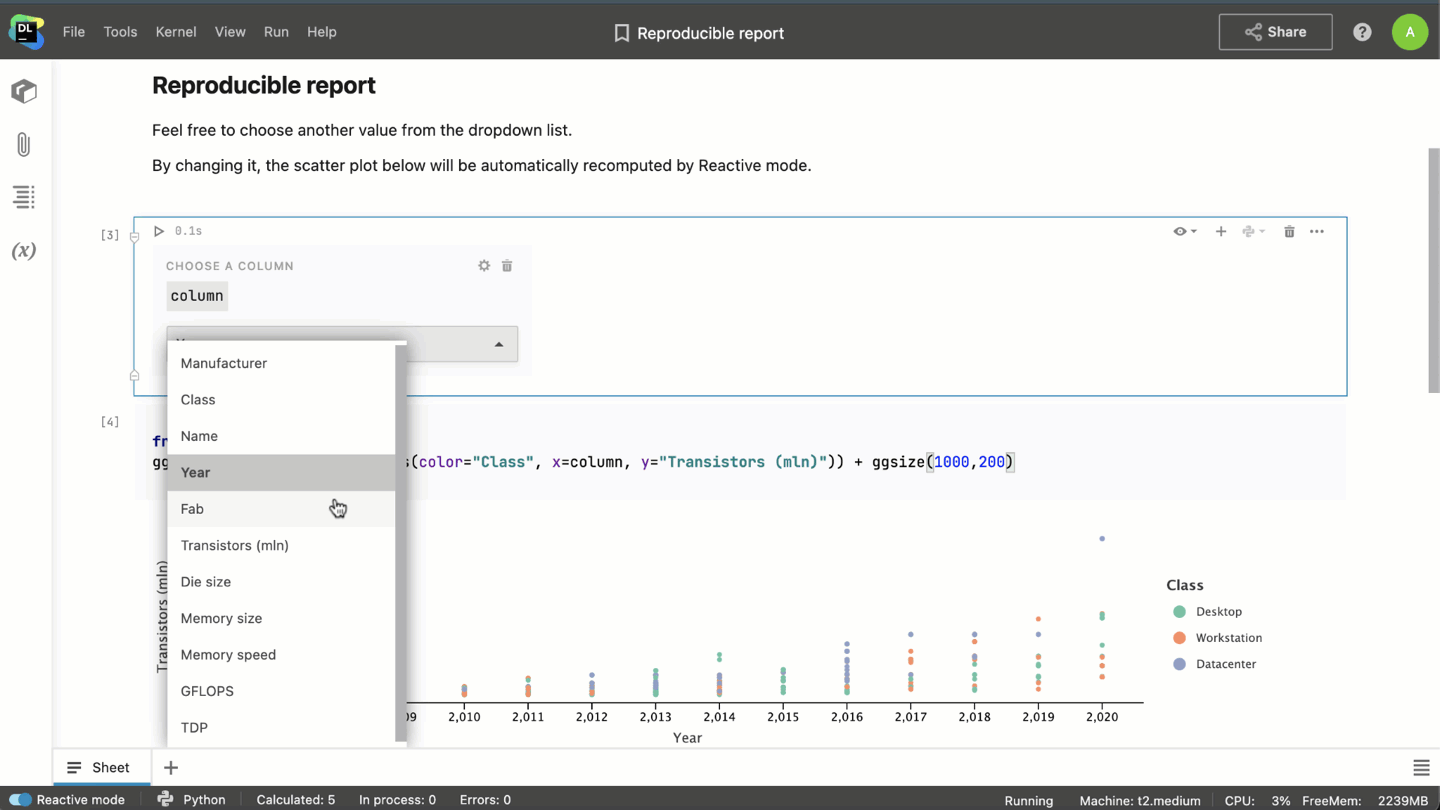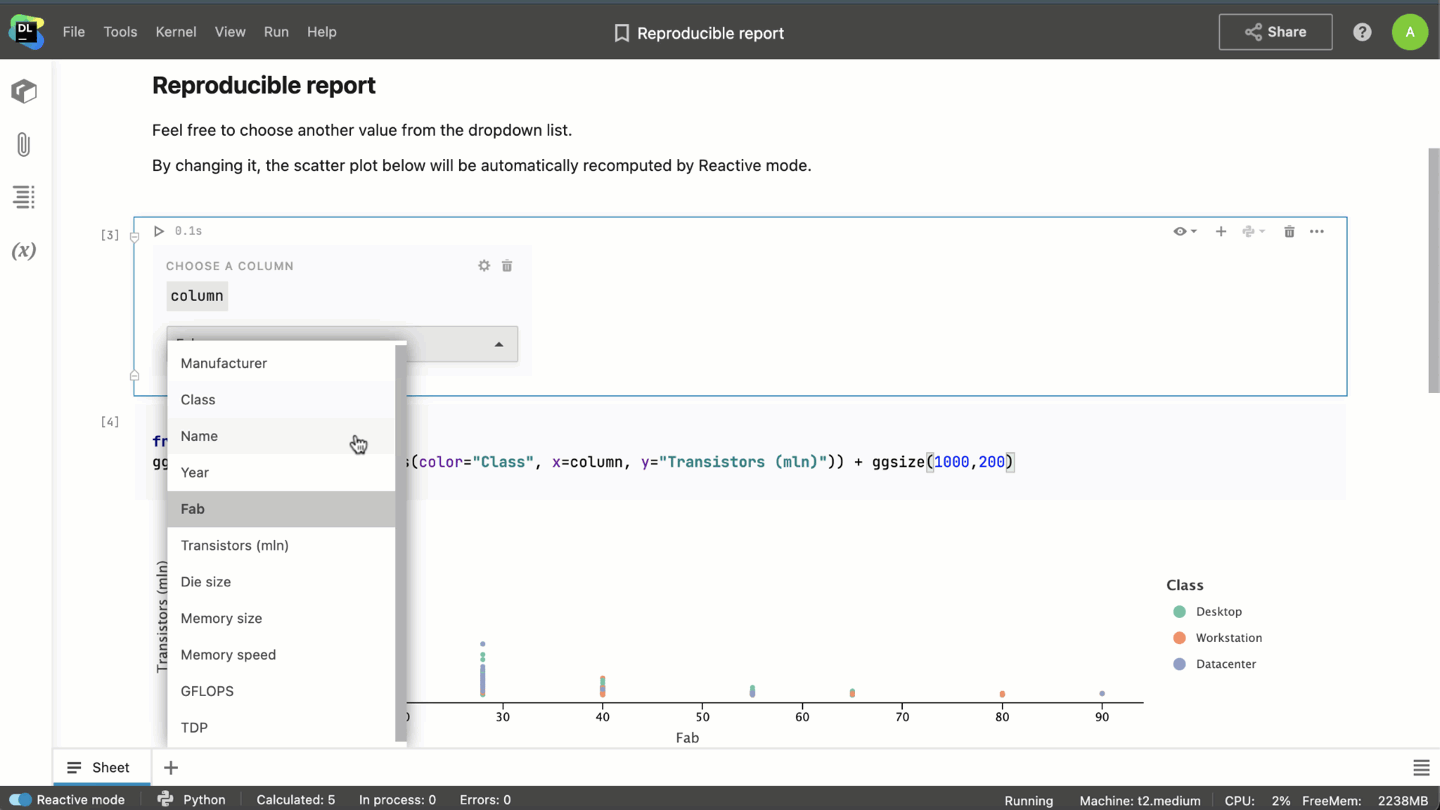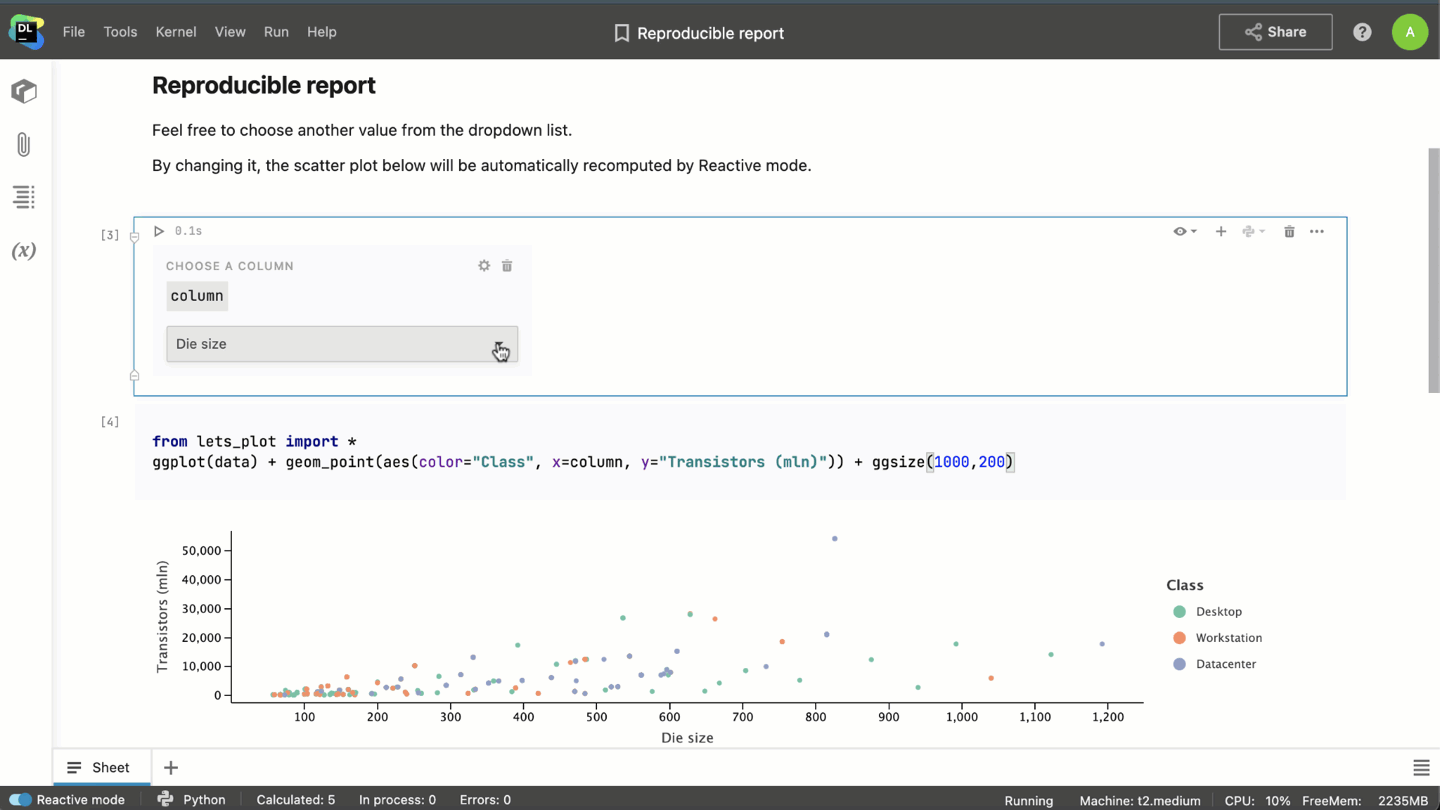
- With Reactive mode enabled, when you’re working on a huge project, you won’t have to rerun it from the very beginning every time you open the notebook. Datalore will save the state of the notebook after each cell calculation, and you’ll be able to restore it the next time you open the notebook.
- It helps when you want to do some tinkering in the notebook and want to keep its state consistent, since Reactive mode will automatically trigger the recalculation of the cells below the modified one.
Before you start
There are a few things you should know about Reactive mode before working with it:
- Notebook states are saved automatically, which may consume storage space. If you find that Reactive mode consumes too much space for you, please let us know by sending an email to support-datalore@jetbrains.com.
- The CRIU framework we rely on doesn’t guarantee support for computations on GPU machines. If you notice any unexpected behavior on a GPU machine, please let us know by sending an email to support-datalore@jetbrains.com.
- Use the Library manager to install packages. It persists the environment when you reopen the notebook.
- Restart the kernel after you switch between Reactive and Jupyter modes. Then rerun all cells.
We hope you enjoy the new Reactive mode! Please share what you think in the comments and tag us on Twitter when sharing your notebooks and ideas.
Happy data sciencing!
The Datalore team



