

Uso de PyCharm para leer datos de una base de datos MySQL en pandas

Tarde o temprano en su recorrido por la ciencia de datos, llegará a un punto en el que necesitará obtener datos de una base de datos. Sin embargo, dar el salto de la lectura de un archivo CSV almacenado localmente en pandas a la conexión y consulta de bases de datos puede ser una tarea abrumadora. En la primera de una serie de artículos del blog, exploraremos cómo leer datos almacenados en una base de datos MySQL en pandas, y veremos algunas características útiles de PyCharm que facilitan esta tarea.

Visualización del contenido de la base de datos
En este tutorial, vamos a leer algunos datos sobre retrasos y cancelaciones de aerolíneas desde una base de datos MySQL a un DataFrame de pandas. Estos datos son una versión del conjunto de datos “Airline Delays from 2003-2016” de Priank Ravichandar con licencia CC0 1.0.
Una de las primeras cosas que puede resultar frustrante de trabajar con bases de datos es no tener una visión general de los datos disponibles, ya que todas las tablas se almacenan en un servidor remoto. Por lo tanto, la primera función de PyCharm que vamos a utilizar es la ventana de herramientas Database, que le permite conectarse a una base de datos e introspeccionarla completamente antes de realizar cualquier consulta.
Para conectarnos a nuestra base de datos MySQL, primero vamos a navegar por la parte derecha de PyCharm y hacer clic en la ventana de la herramienta Database.
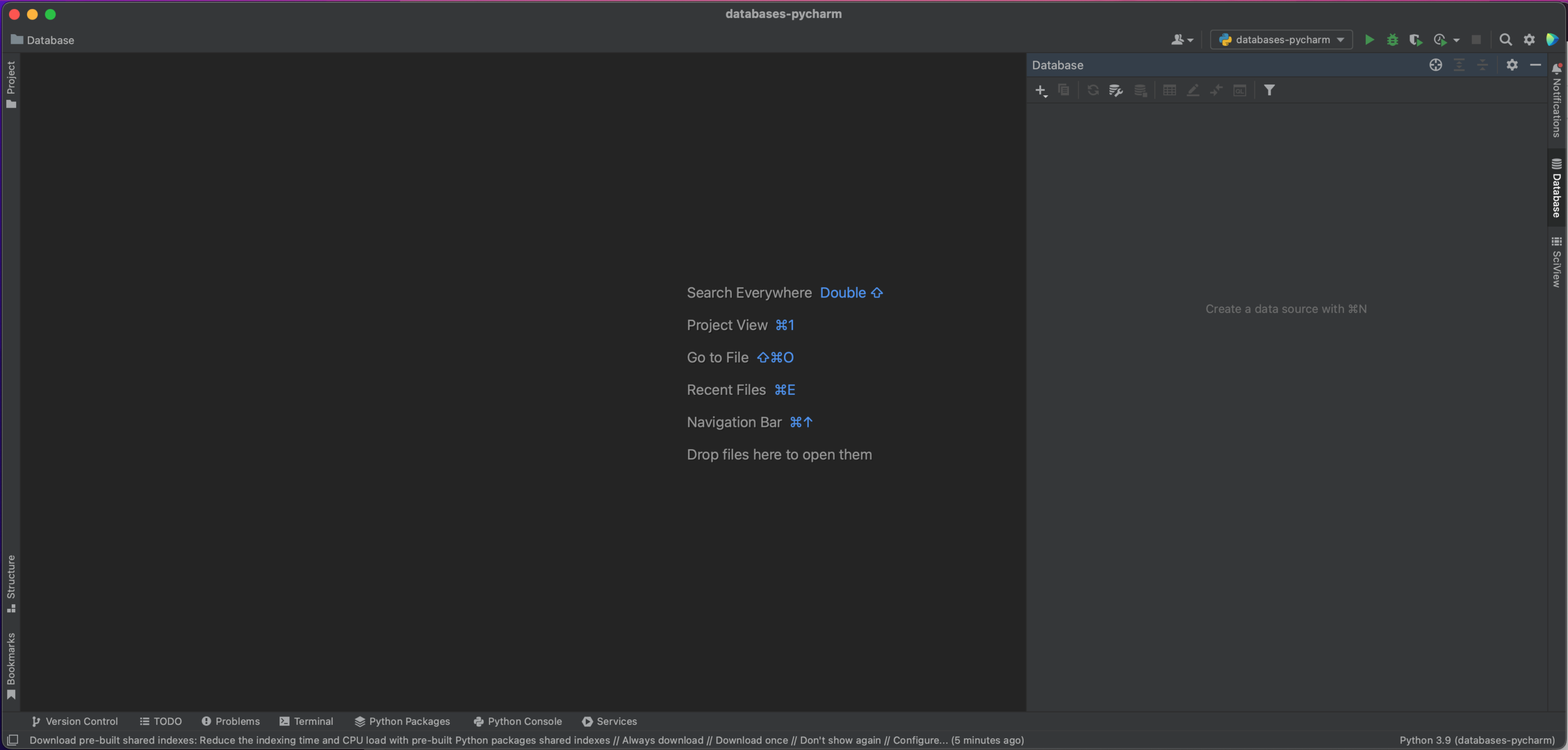
En la parte superior izquierda de esta ventana, verá un botón más. Al hacer clic en él, nos aparece el siguiente cuadro de diálogo desplegable, en el que seleccionaremos Data Source | MySQL.
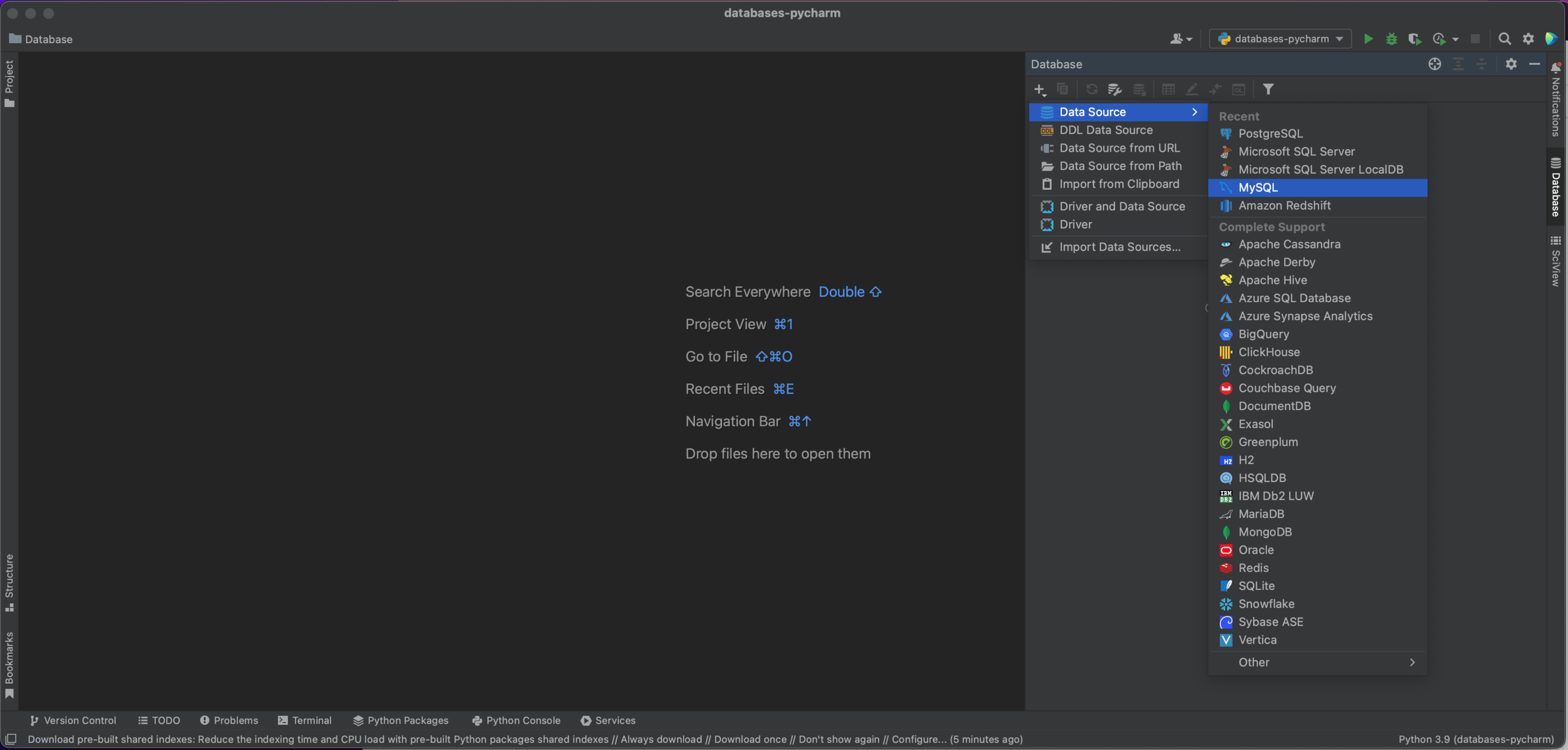
Ahora tenemos una ventana emergente que nos permitirá conectarnos a nuestra base de datos MySQL. En este caso, estamos utilizando una base de datos alojada localmente, por lo que dejamos Host como «localhost» y Port como el puerto MySQL predeterminado de «3306». Utilizaremos la opción Authentication de «User & Password», e introduciremos «pycharm» tanto para en User como en Password. Por último, introducimos el nombre «demo» en Database. Por supuesto, para conectarse a su propia base de datos MySQL necesitará el host específico, el nombre de la base de datos y su nombre de usuario y contraseña. Consulte la documentación para conocer todas las opciones.
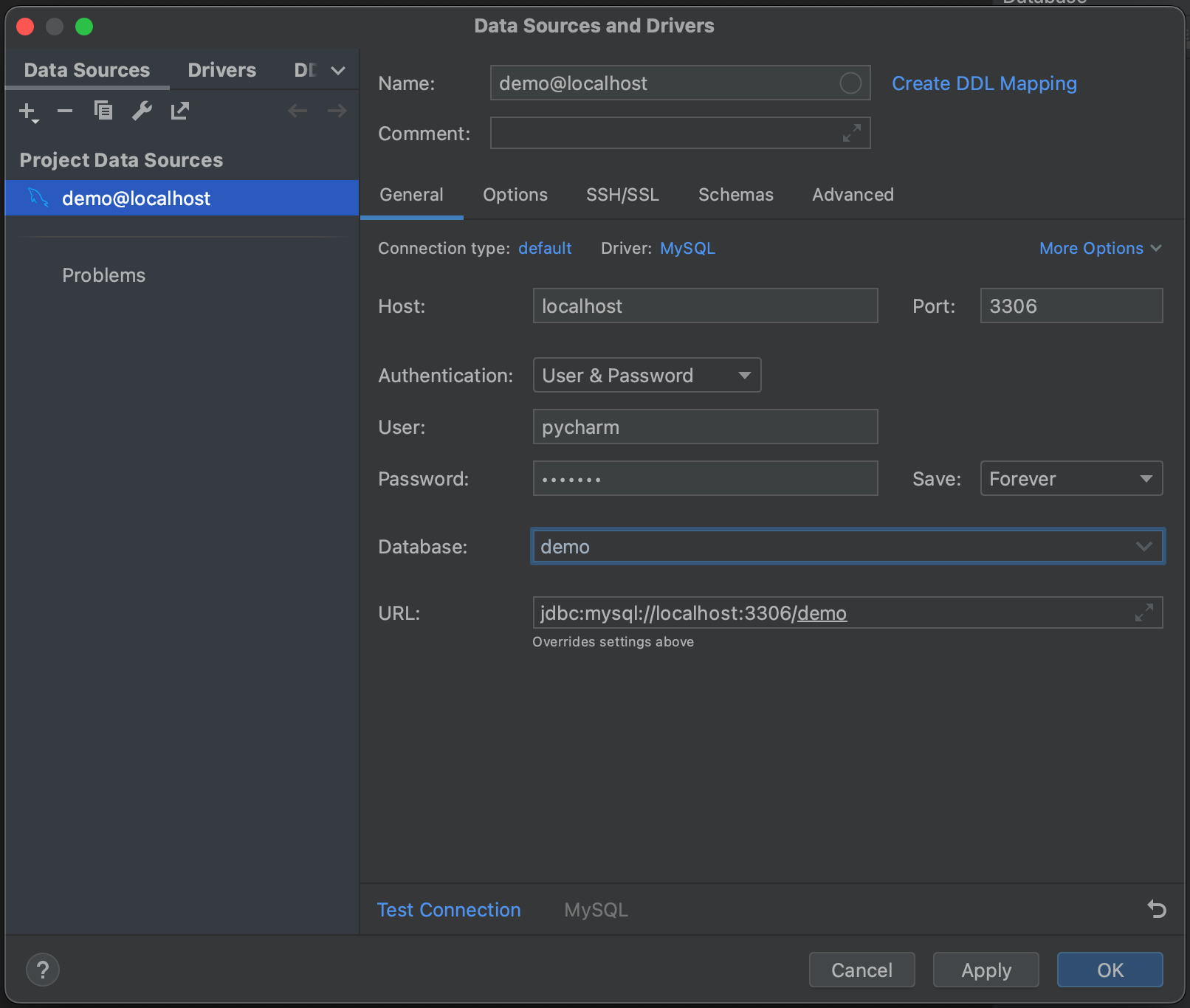
A continuación, haga clic en Test Connection. PyCharm nos avisa de que no tenemos instalados los archivos del controlador. Siga adelante y haga clic en Download Driver Files. Una de las funcionalidades más interesantes de la ventana de herramientas Database es que encuentra e instala automáticamente los controladores correctos.
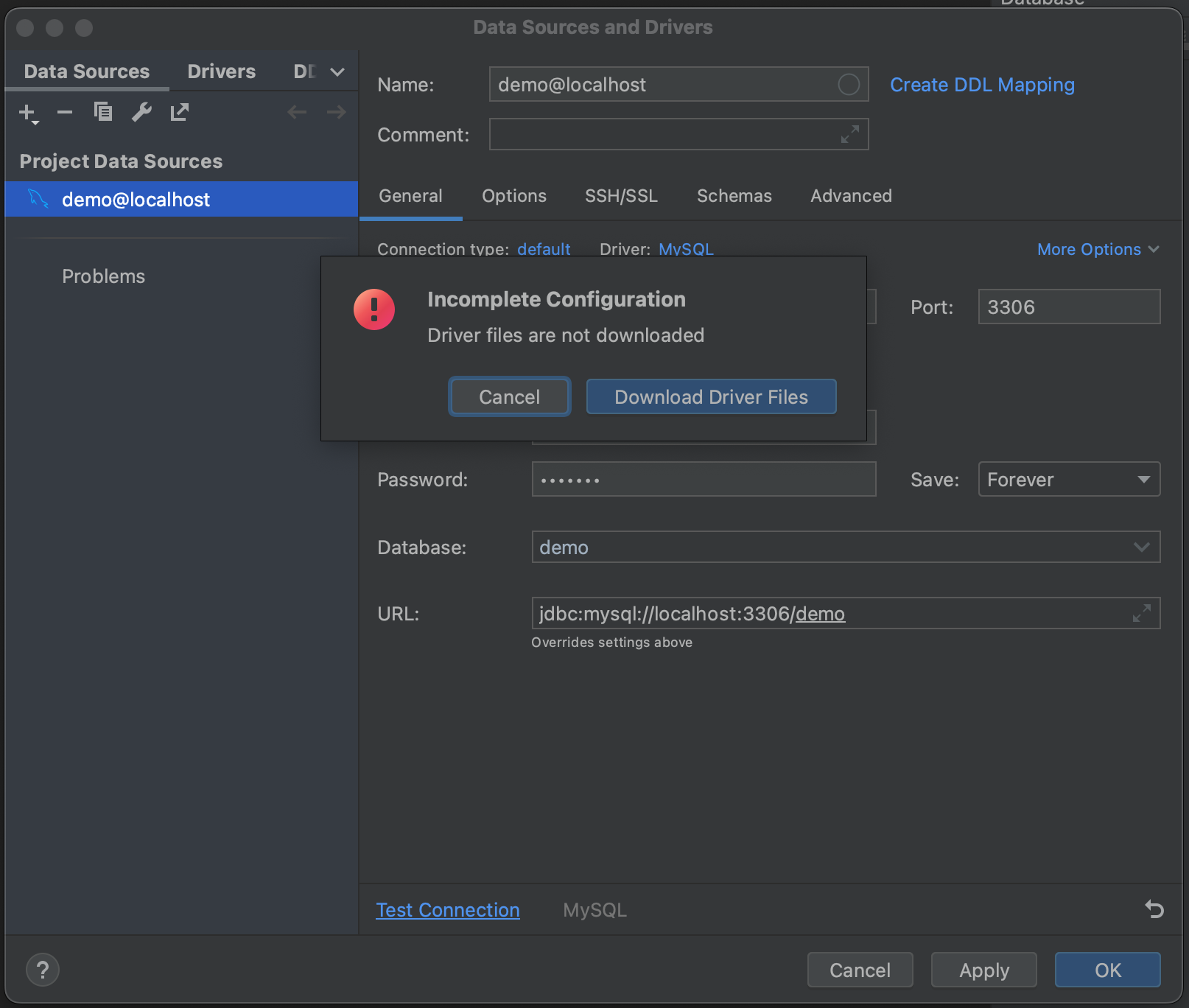
¡Listo! Nos hemos conectado a nuestra base de datos. Ahora podemos navegar hasta la pestaña Schemas y seleccionar qué esquemas queremos introspeccionar. En nuestra base de datos de ejemplo solo tenemos una («demo»), pero en los casos en los que tenga bases de datos muy grandes, puede ahorrarse tiempo introspeccionando solo las relevantes.
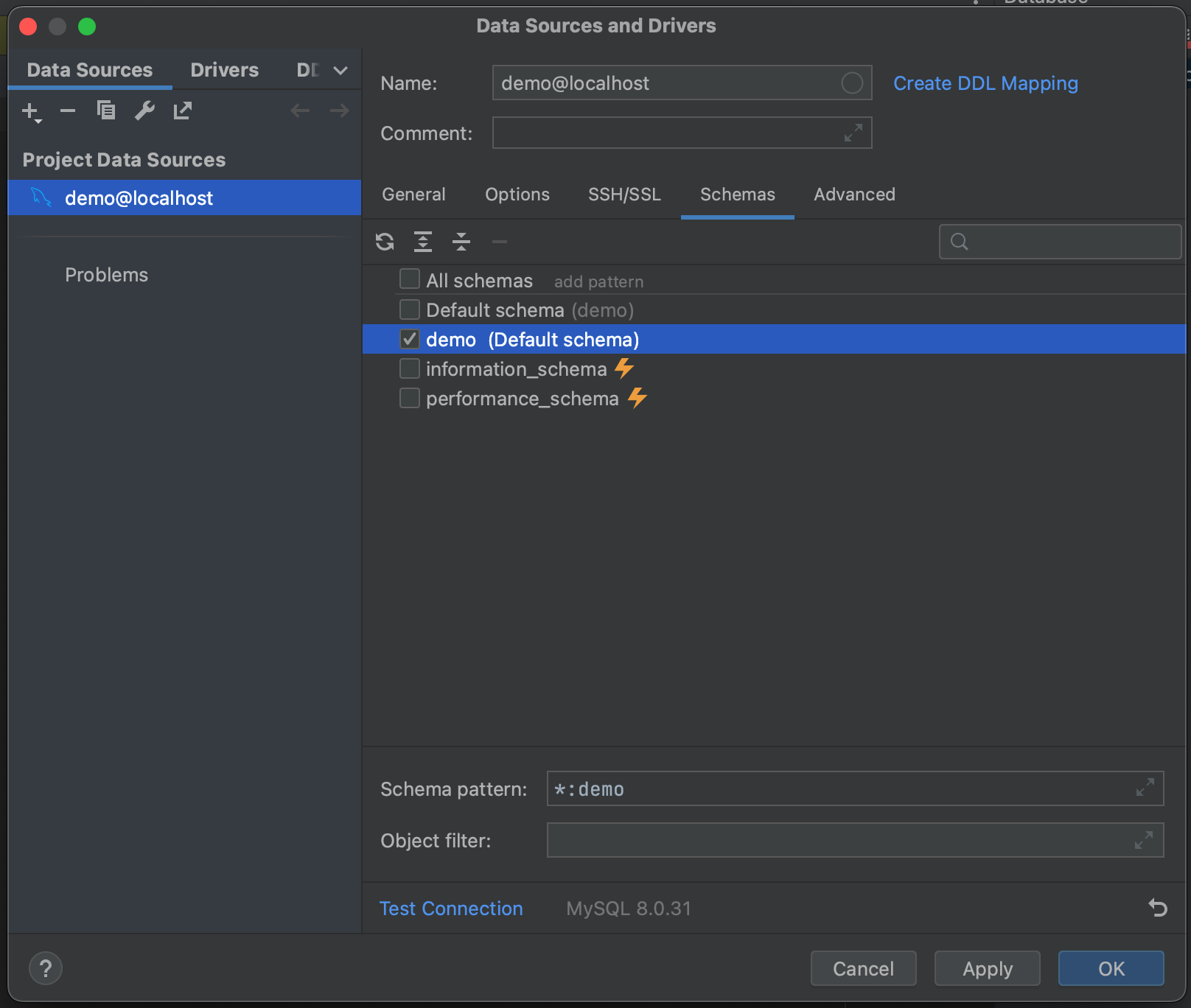
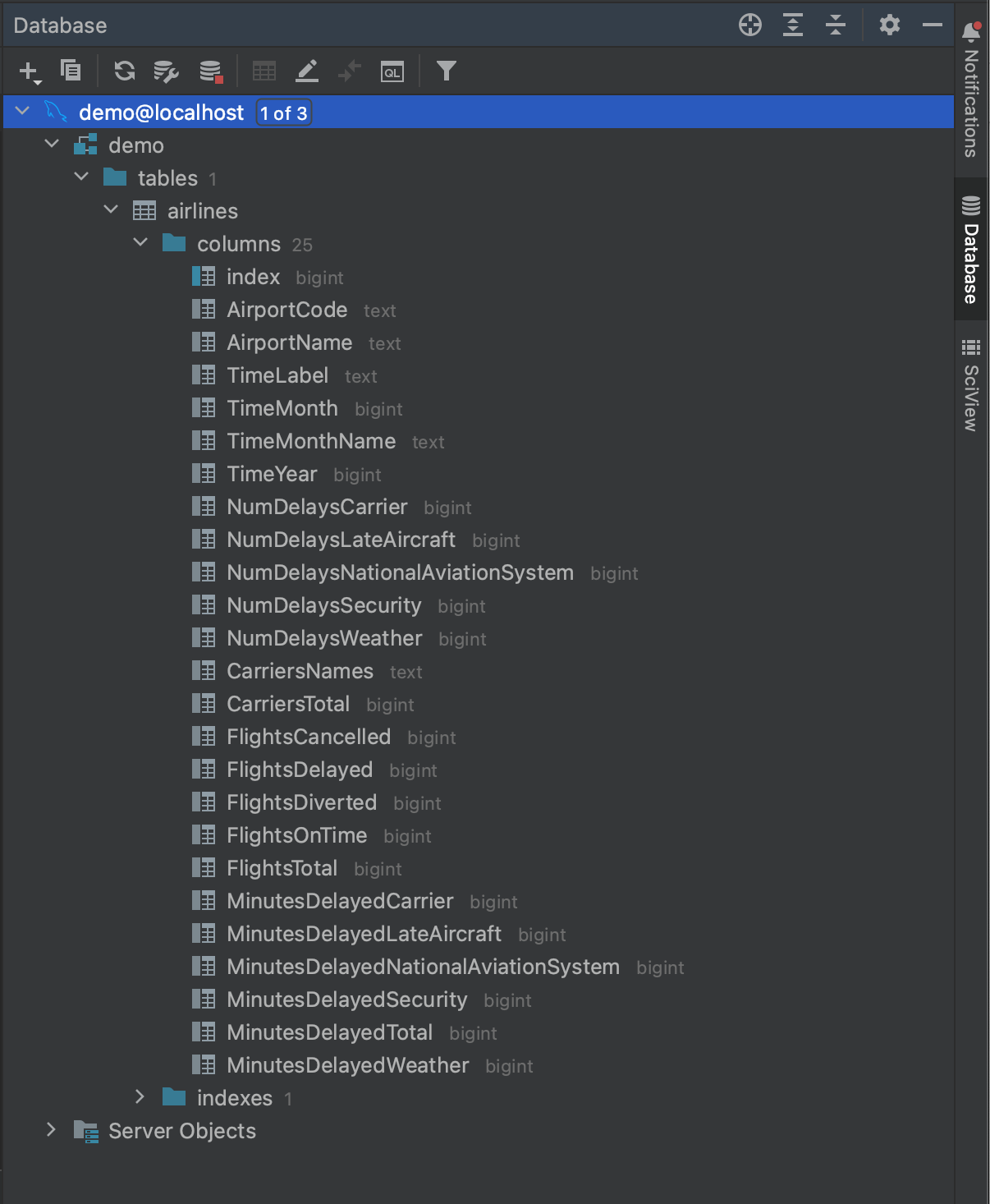
Una vez seguidos estos pasos, ya podemos conectarnos a nuestra base de datos. Pulse OK y espere unos segundos. Ahora puede ver que toda nuestra base de datos ha sido introspeccionada, hasta el nivel de los campos de tabla y sus tipos. Esto nos da una gran visión general de lo que hay en la base de datos antes de ejecutar una consulta.
Lectura de los datos mediante MySQL Connector
Ahora que sabemos lo que hay en nuestra base de datos, estamos listos para elaborar una consulta. Digamos que queremos ver los aeropuertos que sufrieron al menos 500 retrasos en 2016. Observando los campos de la tabla introspeccionada airlines, vemos que podemos obtener esos datos con la siguiente consulta:
SELECT AirportCode,
SUM(FlightsDelayed) AS TotalDelayed
FROM airlines
WHERE TimeYear = 2016
GROUP BY AirportCode
HAVING SUM(FlightsDelayed) > 500;
La primera forma en que podemos ejecutar esta consulta con Python es utilizando un paquete llamado «MySQL Connector», que puede instalarse desde PyPI o Anaconda. Consulte la documentación vinculada si necesita orientación para configurar entornos pip o conda o instalar dependencias. Una vez finalizada la instalación, abriremos un nuevo Jupyter Notebook e importaremos tanto MySQL Connector como pandas.
import mysql.connector import pandas as pd
Para leer los datos de nuestra base de datos, necesitamos crear un conector. Para ello se utiliza el método connect, al que pasamos las credenciales necesarias para acceder a la base de datos: host, database, user y password. Se trata de las mismas credenciales que utilizamos para acceder a la base de datos mediante la ventana de herramientas Database en la sección anterior.
mysql_db_connector = mysql.connector.connect( host="localhost", database="demo", user="pycharm", password="pycharm" )
Ahora necesitamos crear un cursor. Se utilizará para ejecutar nuestras consultas SQL en la base de datos, y usa las credenciales ordenadas en nuestro conector para obtener acceso.
mysql_db_cursor = mysql_db_connector.cursor()
Ahora estamos listos para ejecutar nuestra consulta. Lo hacemos utilizando el método execute de nuestro cursor y pasando la consulta como argumento.
delays_query = """
SELECT AirportCode,
SUM(FlightsDelayed) AS TotalDelayed
FROM airlines
WHERE TimeYear = 2016
GROUP BY AirportCode
HAVING SUM(FlightsDelayed) > 500;
"""
mysql_db_cursor.execute(delays_query)
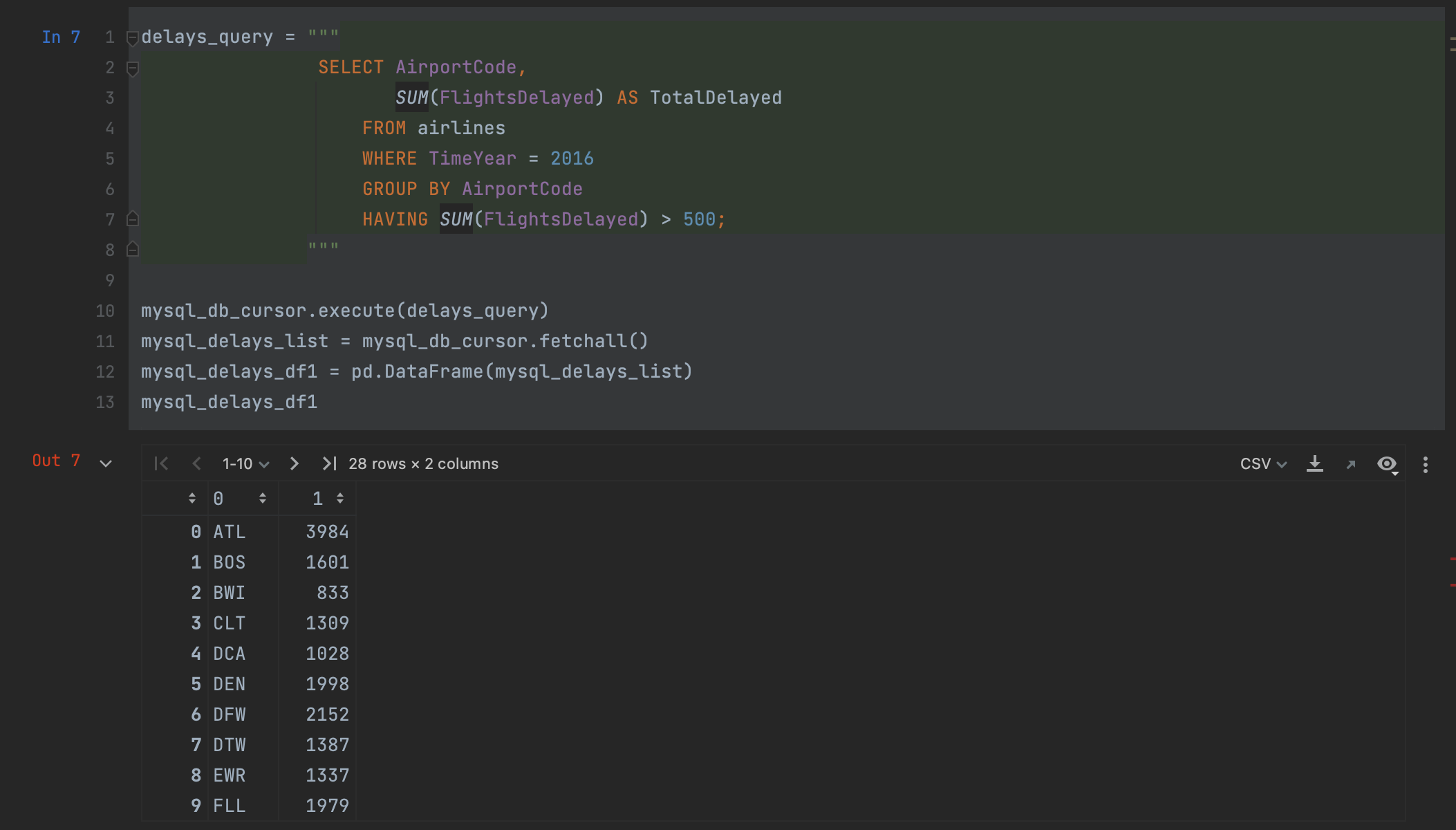
A continuación, obtenemos el resultado utilizando el método fetchall del cursor.
mysql_delays_list = mysql_db_cursor.fetchall()
Sin embargo, en este punto tenemos un problema: fetchall devuelve los datos como una lista. Para introducirlo en pandas, podemos pasarlo a un DataFrame, pero perderemos los nombres de nuestras columnas y tendremos que especificarlos manualmente cuando queramos crear el DataFrame.
Por suerte, pandas ofrece una forma mejor. En lugar de crear un cursor, podemos leer nuestra consulta en un DataFrame en un solo paso, utilizando el método read_sql.
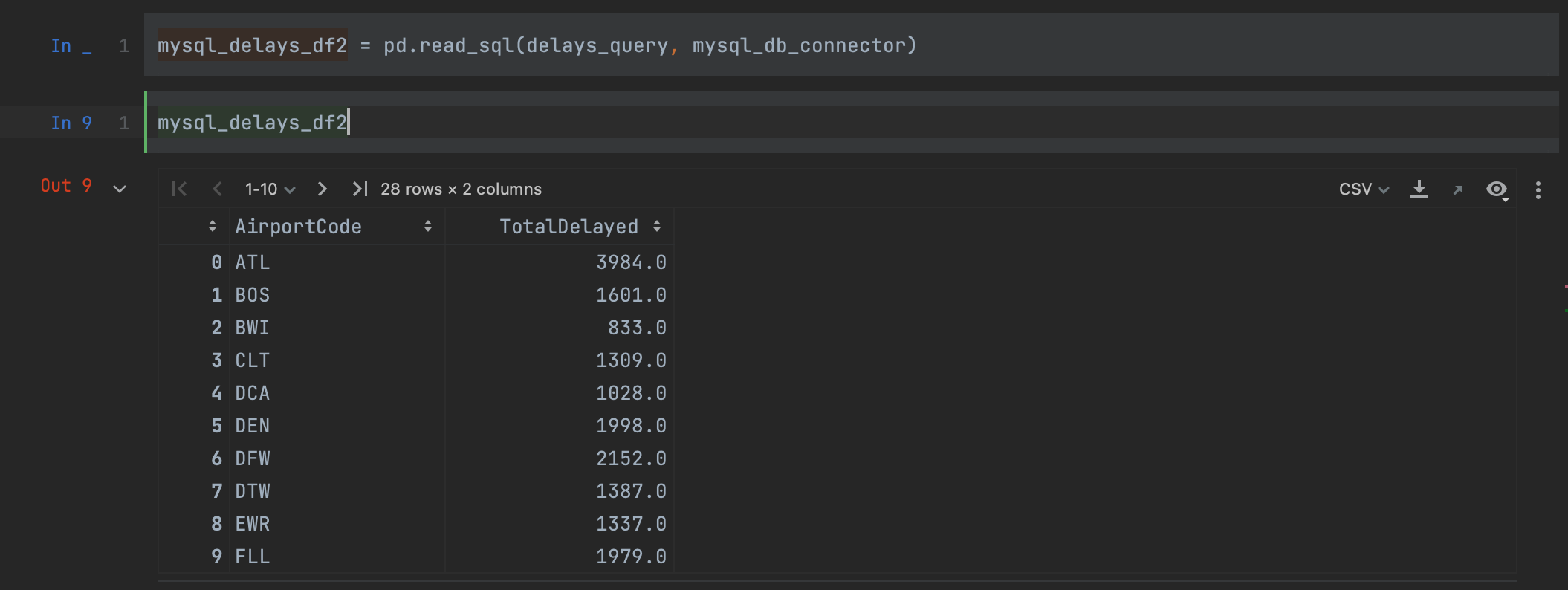
mysql_delays_df2 = pd.read_sql(delays_query, con=mysql_db_connector)
Solo tenemos que pasar nuestra consulta y el conector como argumentos para leer los datos de la base de datos MySQL. Observando nuestro marco de datos, podemos ver que obtenemos exactamente los mismos resultados que antes, pero esta vez se han conservado los nombres de nuestras columnas.
Una funcionalidad estupenda que puede que haya visto es que PyCharm aplica resaltado de sintaxis a la consulta SQL, incluso cuando está contenida dentro de una cadena Python. Describiremos otra forma en la que PyCharm le permite trabajar con SQL más adelante en este artículo del blog.
Lectura de los datos mediante SQLAlchemy
Una alternativa al uso de MySQL Connector es utilizar un paquete llamado SQLAlchemy. Este paquete ofrece un método único para conectarse a una serie de bases de datos diferentes, incluida MySQL. Una de las ventajas de utilizar SQLAlchemy es que la sintaxis para consultar diferentes tipos de bases de datos sigue siendo coherente en todos los tipos de bases de datos, lo que le ahorra tener que recordar un montón de comandos diferentes si trabaja con muchas bases de datos distintas.
Para empezar, necesitamos instalar SQLAlchemy desde PyPI o Anaconda. A continuación, importamos el método create_engine y, por supuesto, pandas.
import pandas as pd from sqlalchemy import create_engine
Ahora tenemos que crear nuestro motor. El motor nos permite decirle a pandas qué dialecto SQL estamos utilizando (en nuestro caso, MySQL) y proporcionarle las credenciales que necesita para acceder a nuestra base de datos. Todo esto se pasa como una sola cadena con la forma siguiente: [dialect]://[user]:[password]@[host]/[database]. Veamos qué aspecto tiene esto en el caso de nuestra base de datos MySQL:
mysql_engine = create_engine("mysql+mysqlconnector://pycharm:pycharm@localhost/demo")
Con esto creado, solo tenemos que utilizar read_sql de nuevo, esta vez pasando el motor al argumento con:
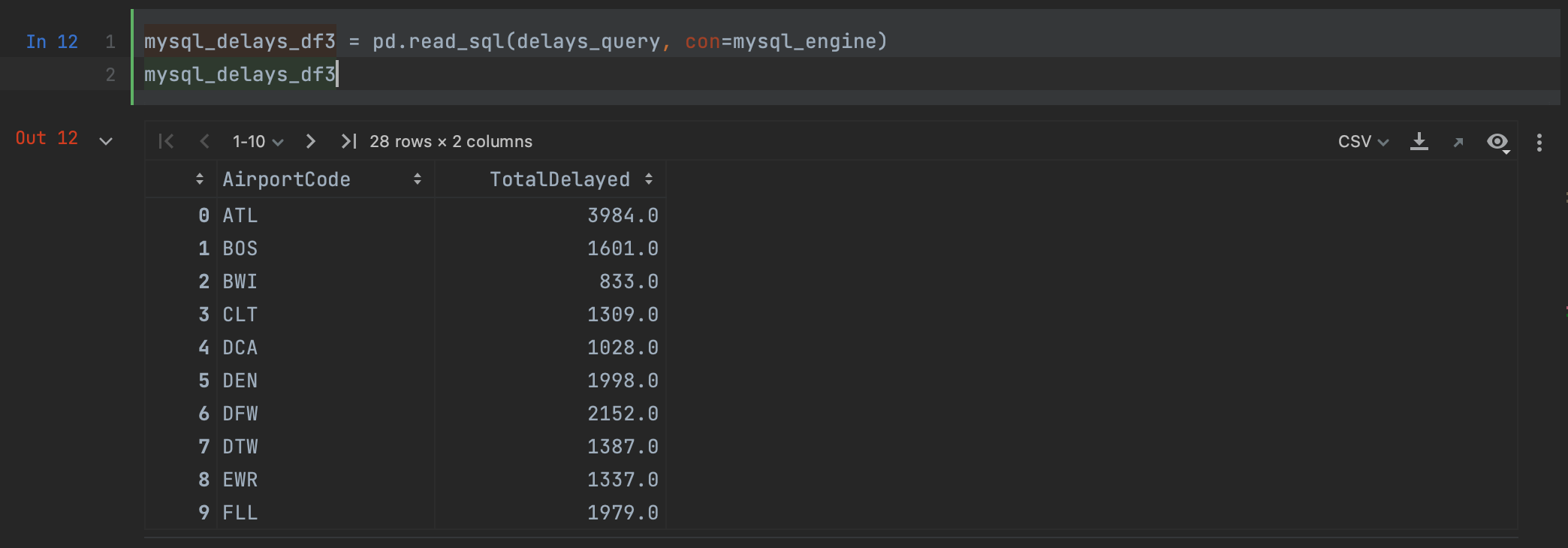
mysql_delays_df3 = pd.read_sql(delays_query, con=mysql_engine)
Como puede ver, obtenemos el mismo resultado que al utilizar read_sql con MySQL Connector.
Opciones avanzadas para trabajar con bases de datos
Ahora bien, estos métodos conectores están muy bien para extraer una consulta que ya sabemos que queremos, pero ¿qué ocurre si queremos obtener una vista previa del aspecto que tendrán nuestros datos antes de ejecutar la consulta completa, o una idea de cuánto tardará toda la consulta? PyCharm está aquí de nuevo con algunas funciones avanzadas para trabajar con bases de datos.
Si volvemos a navegar hasta la ventana de herramientas Database y hacemos clic con el botón derecho del ratón sobre nuestra base de datos, veremos que en New tenemos la opción de crear una Query Console.
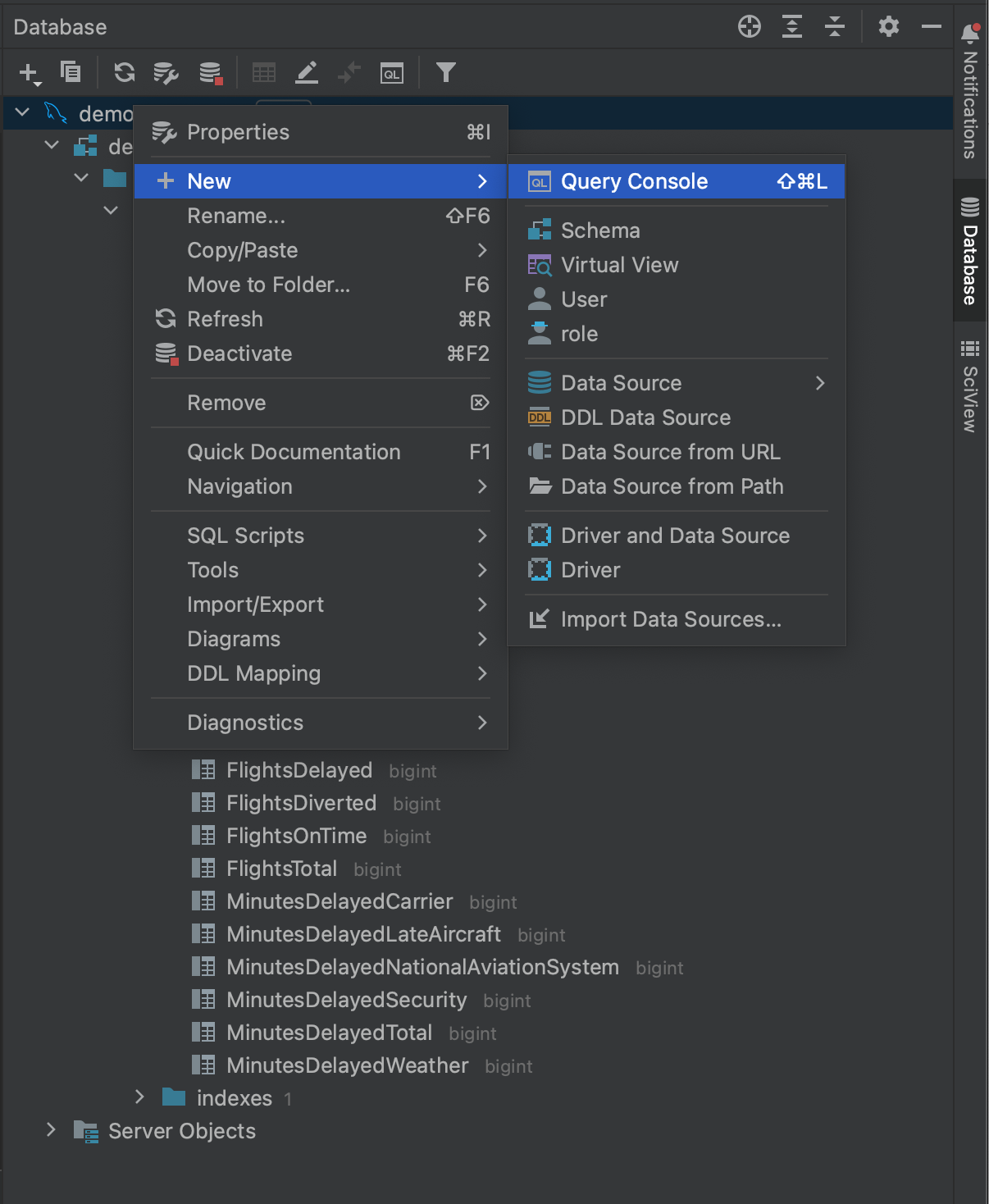
Esto nos permite abrir una consola que podemos utilizar para consultar la base de datos en SQL nativo. La ventana de la consola incluye finalización de código SQL e introspección, lo que le ofrece una forma más sencilla de crear sus consultas antes de pasarlas a los paquetes de conectores en Python.
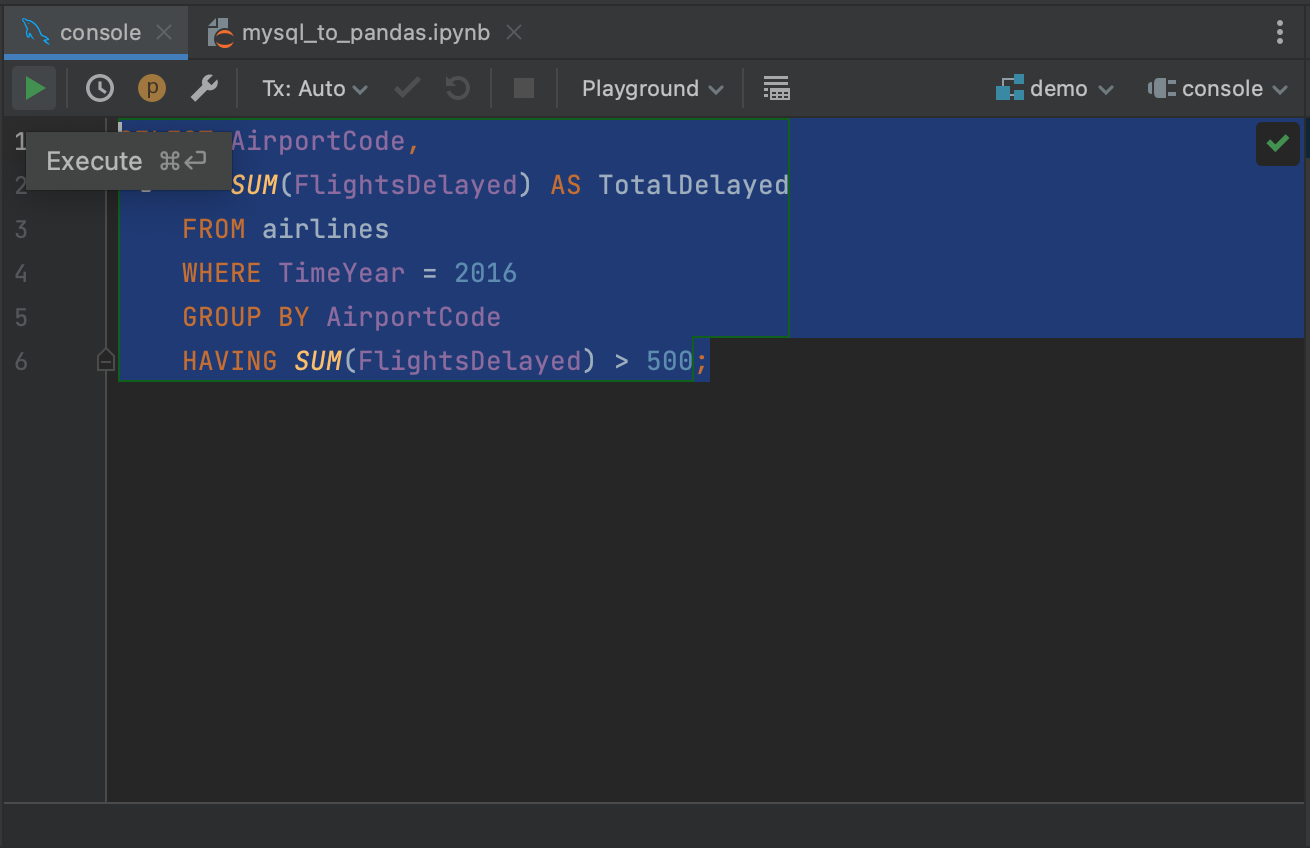
Resalte su consulta y haga clic en el botón Execute en la esquina superior izquierda.
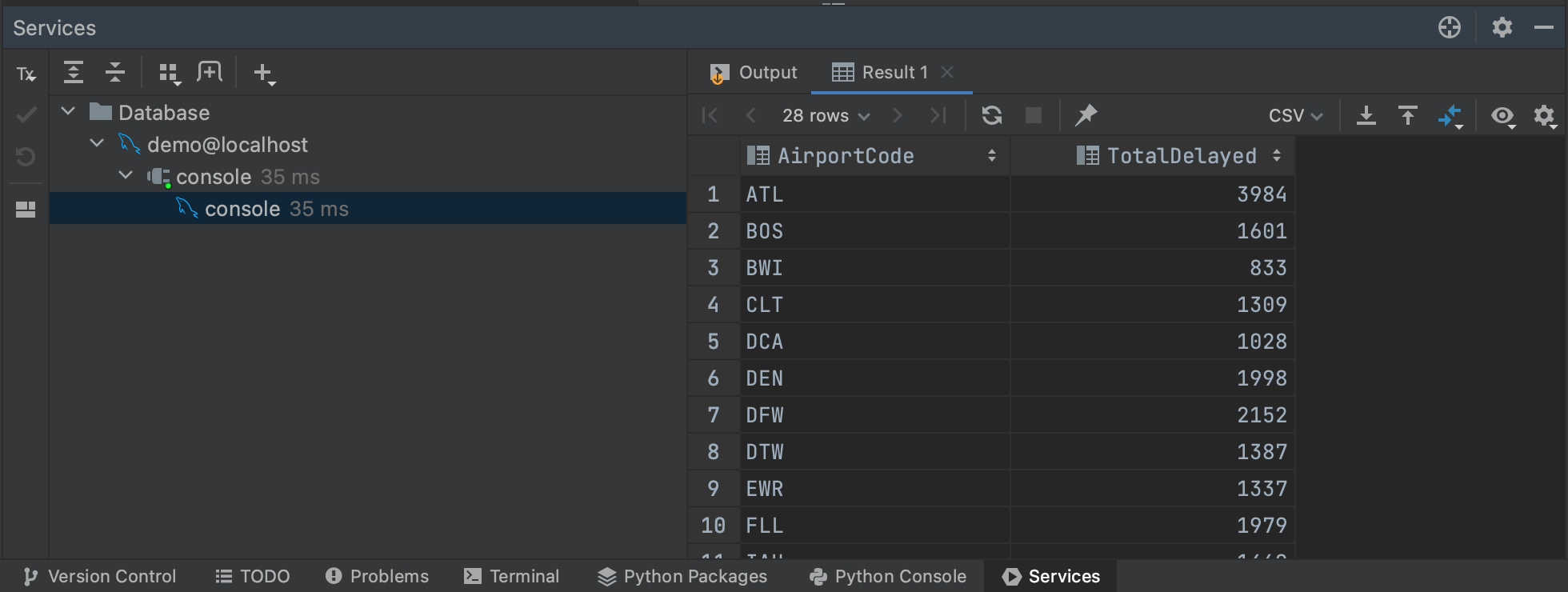
Esto recuperará los resultados de nuestra consulta en la pestaña Services, donde se pueden inspeccionar o exportar. Una cosa buena de ejecutar consultas en la consola es que solo se recuperan inicialmente las primeras 500 filas de la base de datos, lo que significa que puede hacerse una idea de los resultados de consultas más amplias sin que necesite extraer todos los datos. Puede ajustar el número de filas obtenidas yendo a Settings/Preferences | Tools | Database | Data Editor and Viewer y cambiando el valor en Limit page size to:.
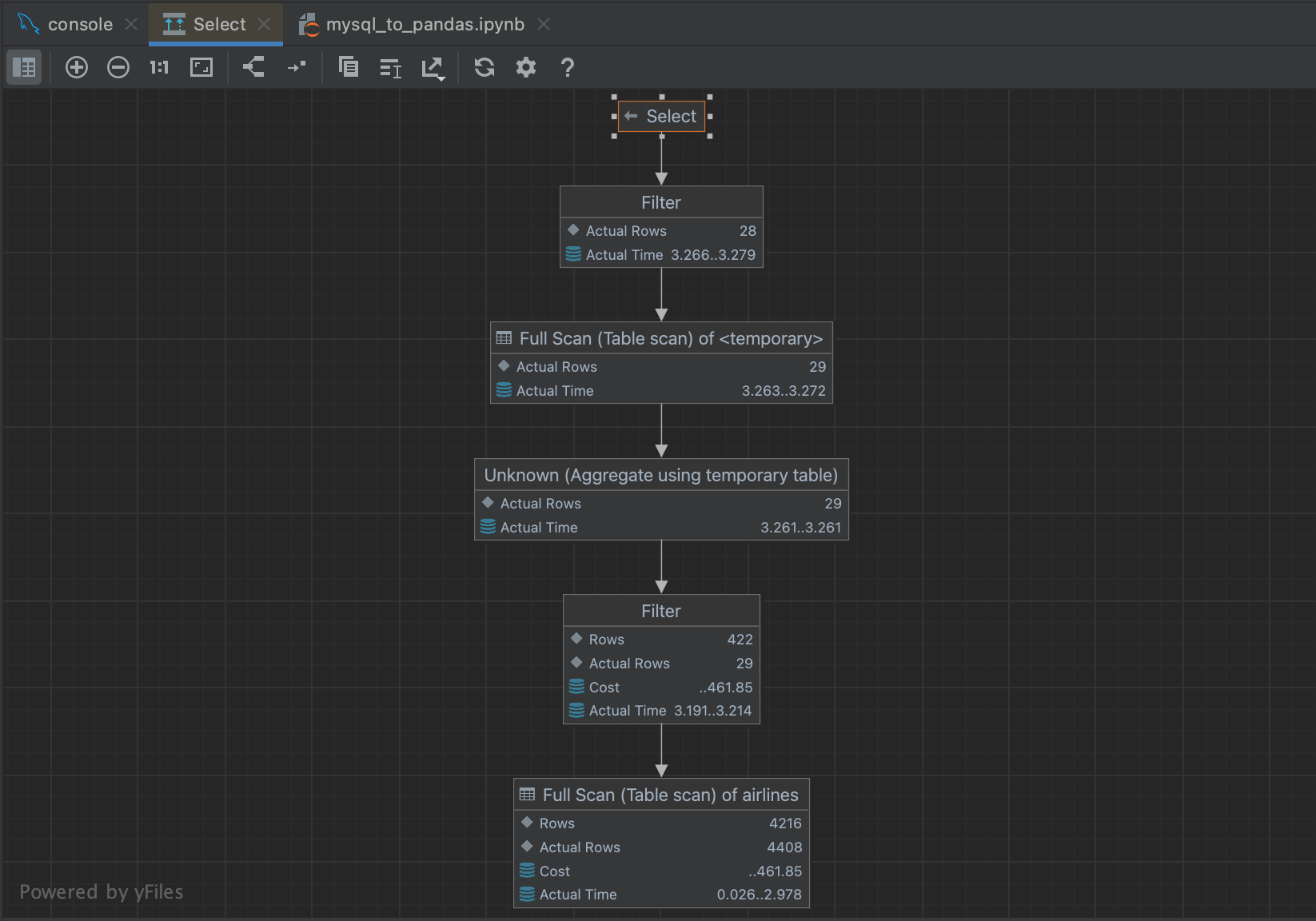
Hablando de consultas grandes, también podemos hacernos una idea de cuánto tardará nuestra consulta generando un plan de ejecución. Si volvemos a resaltar nuestra consulta y hacemos clic con el botón derecho, podemos seleccionar Explain Plan | Explain Analyse en el menú. Esto generará un plan de ejecución para nuestra consulta, mostrando cada paso que el planificador de consultas está dando para obtener nuestros resultados. Los planes de ejecución son su propio tema, y en realidad no necesitamos entender todo lo que nos dice nuestro plan. Lo más relevante para nuestros propósitos es la columna Actual Total Time, donde podemos ver cuánto tiempo tardará en mostrar todas las filas en cada paso. Esto nos da una buena estimación del tiempo total de la consulta, así como si es probable que alguna parte de nuestra consulta consuma especialmente mucho tiempo.
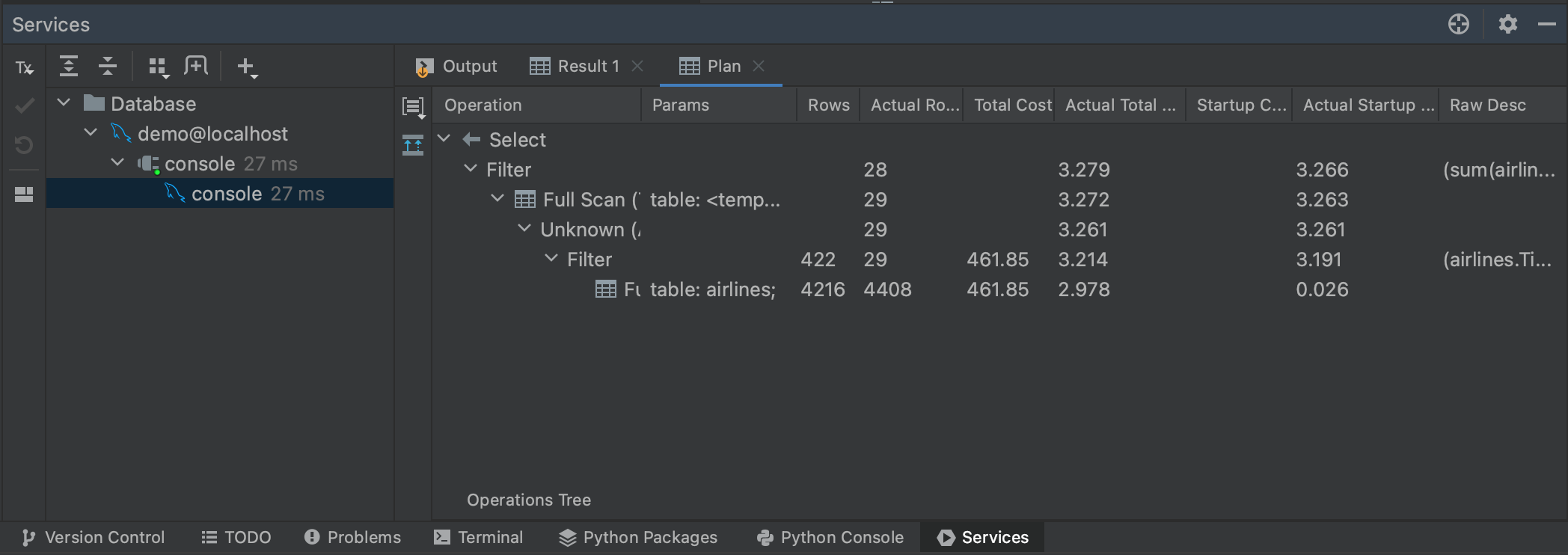
También puede visualizar la ejecución pulsando el botón Show Visualization situado a la izquierda del panel Plan.
Aparecerá un diagrama de flujo que facilita un poco la navegación por los pasos que sigue el planificador de consultas.
Obtener datos de bases de datos MySQL en DataFrames de pandas es sencillo, y PyCharm cuenta con una serie de herramientas potentes para facilitar el trabajo con las bases de datos MySQL. En el próximo artículo del blog, veremos cómo utilizar PyCharm para leer datos en pandas desde otro tipo de base de datos popular, las bases de datos PostgreSQL.
Artículo original en inglés de:

Subscribe to PyCharm Blog updates





