

Fleet
More Than a Code Editor
Fleet Below Deck, Part II – Breaking down the editor

This is a multipart series on building Fleet, a next generation IDE by JetBrains.
- Part I – Architecture Overview
- Part II – Breaking down the editor
- Part III – State Management
- Part IV – Distributed Transactions
- Part V – The Story of Code Completion
- Part VI – UI with Noria
In the first part of this series we looked at an overview of the Fleet architecture. In this second part we’re going to cover the algorithms and data structures that are used under the covers in the editor.
An aggregate of data structures
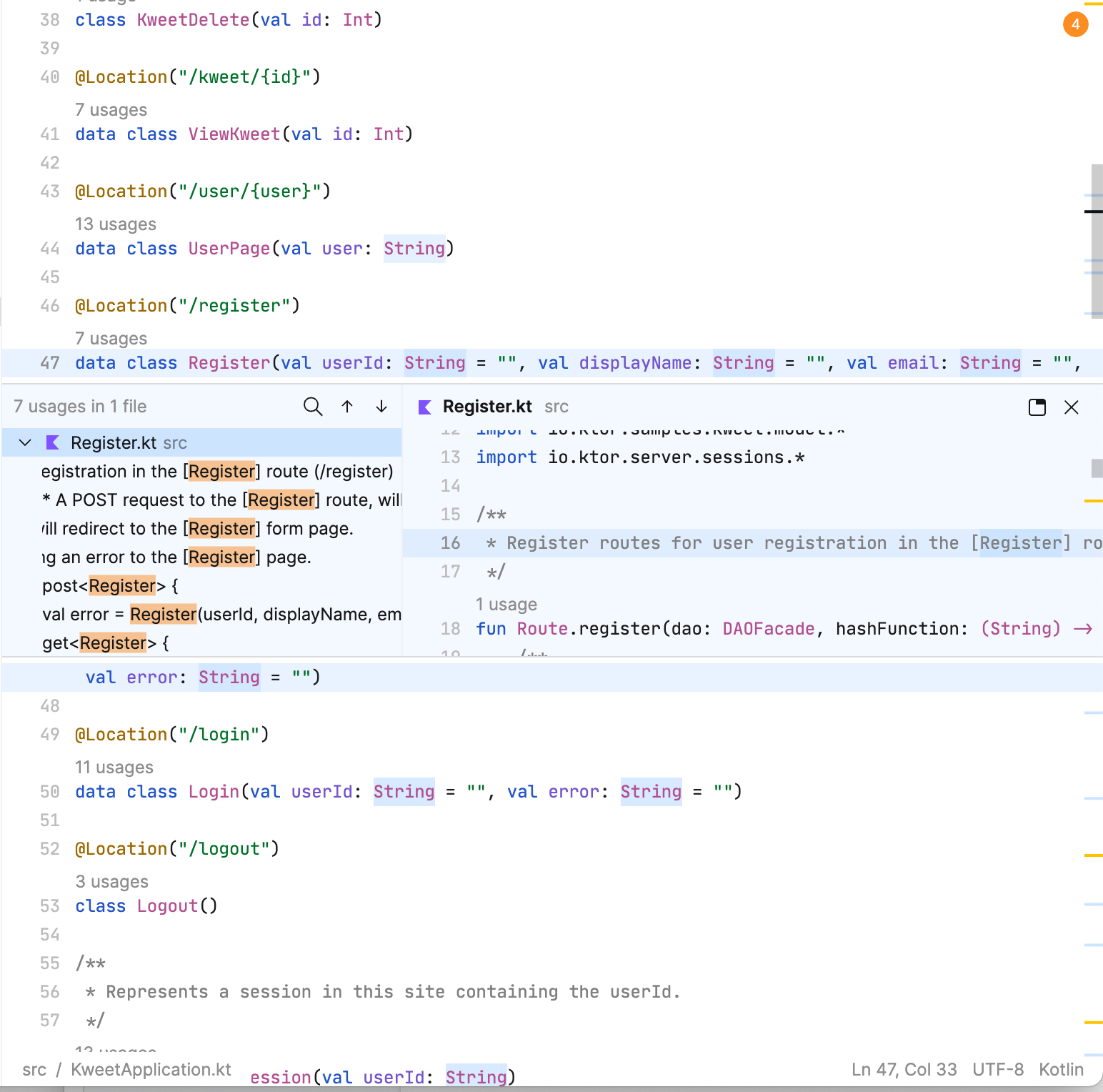
Take a look at the following screenshot of the editor window in Fleet

There’s a line of text with syntax highlighting and a widget providing information about usages of the particular variable. Now one could find multiple ways to display this information, but the issue with editors is that they are not read-only. In addition to visualization of data, they can also be updated. A simple operation such as changing a function name could impact many things such as syntax highlighting, usages, and of course any other feature offered such as static analysis or on-the-fly compilation.
In order to be able to provide a good experience, we need to make sure that editing text and the consequent visualization can be as seamless as possible. In order to accomplish this, we have to store and manipulate data in an efficient manner. However, it’s not just one way of storing data. In fact, the image above stores data in multiple ways, using different data structures that all come together to form what we call the editor. In other words, think of the editor as an aggregator of data structures!
Let’s break these down!
Ropes everywhere
For those familiar with working with large amounts of text, you may already know that using strings (i.e. array of chars) to store them isn’t very efficient. Usually any operation on an array is going to imply having to create a new larger or smaller array, and copy the contents from the old one to the new one. This is hardly efficient.
A better and more standardized approach is to use rope structures. The idea behind this abstract data type is to store strings in leaf nodes on a tree.
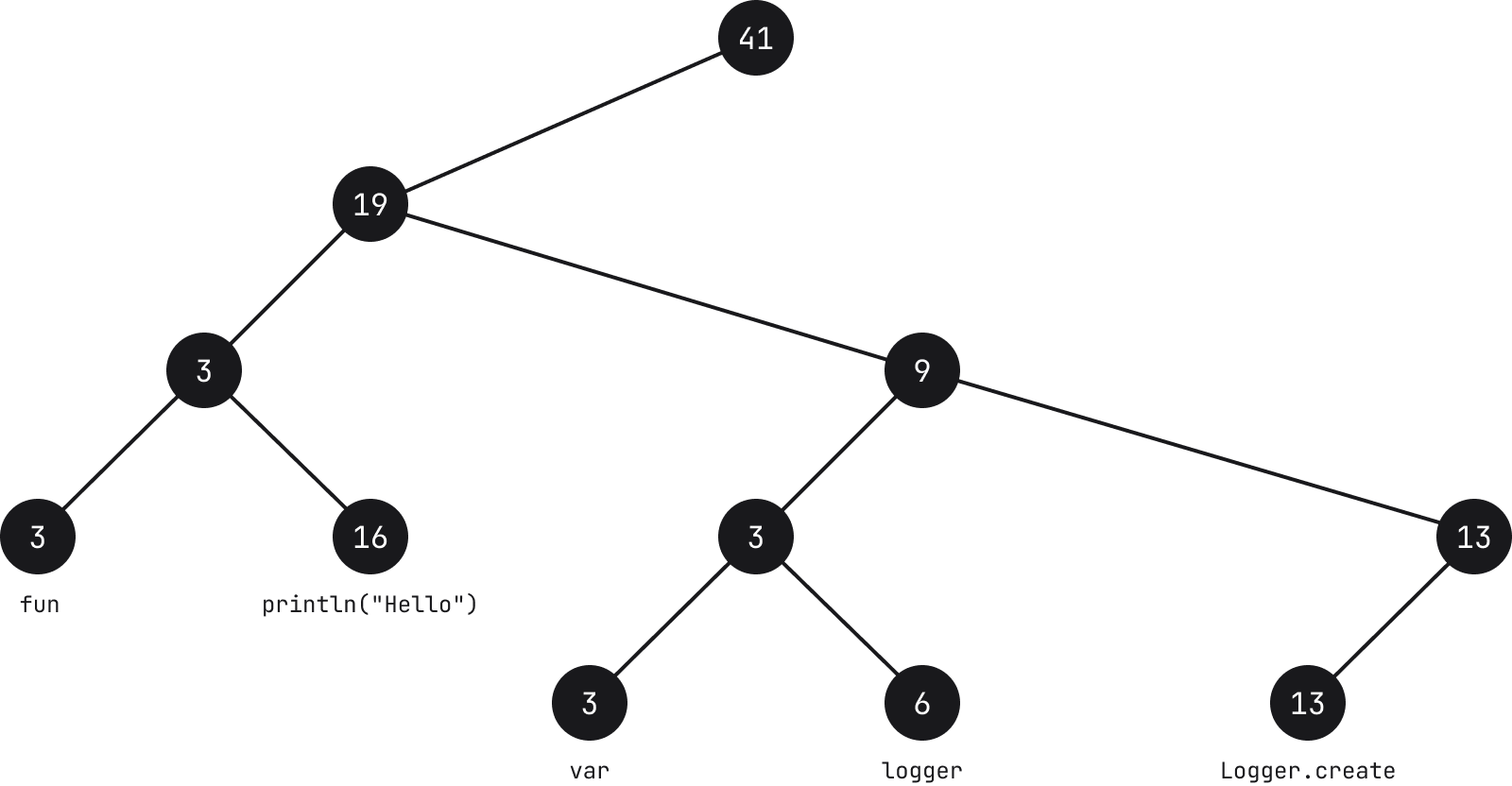
Each leaf node contains a string (see note below) and its length, called weight. Each intermediate node also contains a weight which is the sum of all the leaves in its left subtree.
Note: that the text used on the leaves is a mere example and does not represent how the actual text is broken down in Fleet.
From the example above, if we take for instance the node which holds the characters fun, the count of the node is 3 because the length of the string is 3. Moving up to the parent node, the count is also 3 because the sum of the weight of all nodes to its left is 3. Its parent in turn has a count of 19 because the sum of the leaves to its left is 3 and 16.
Common actions such as searching, appending, removing, splitting strings can be performed with O(log N) time complexity, where N is the length of the string. Operations start by traversing a tree, and given the information of the nodes, this makes it faster. For instance, if we want to find a character in position i = 30, we start with the node, and if 30 is less than the weight of the node (character count), we go to the left, subtracting (see note below) the value of the weight from i. If on the other hand i is higher, we go to the right. As we move down and the value of i decreases, once we reach a leaf node, the character at the i position of the string the leaf node holds is what we’re looking for.
Note: depending on the metric used, subtraction may not be the required operation. What’s important is that as we move down the tree we accumulate the metric up to that point and compare it to the key we are scanning for.
When inserting or deleting nodes in the rope structure in Fleet, we use a self-balancing B-Tree. We start by reading chunks of 64 characters, and once we get to 32 chunks we create a node and start collecting chunks for a second node. Each node has two numbers – in addition to the weight we also store the line count (combination of both is what we call metrics).

By storing the line count, we can navigate faster to specific offsets. Another trait of the tree in Fleet is that we aim to keep them wide as opposed to deep.
Interval trees for widgets et al.
As we saw before a fragment of code may not only contain the actual text, but also additional elements like usages.

We call these widgets, and they can be interline widgets such as the Find Usages or Run widgets, postline (e.g. debug information appearing after the line of code) or inlay (e.g. type hinting on variables and lambdas).
A widget in itself is merely a markup element, and the data structure that holds it is a variation on interval trees, which in some way is also a rope structure. In Interval trees, nodes hold a range and the weight corresponds to the maximum of the ranges from the subtree.
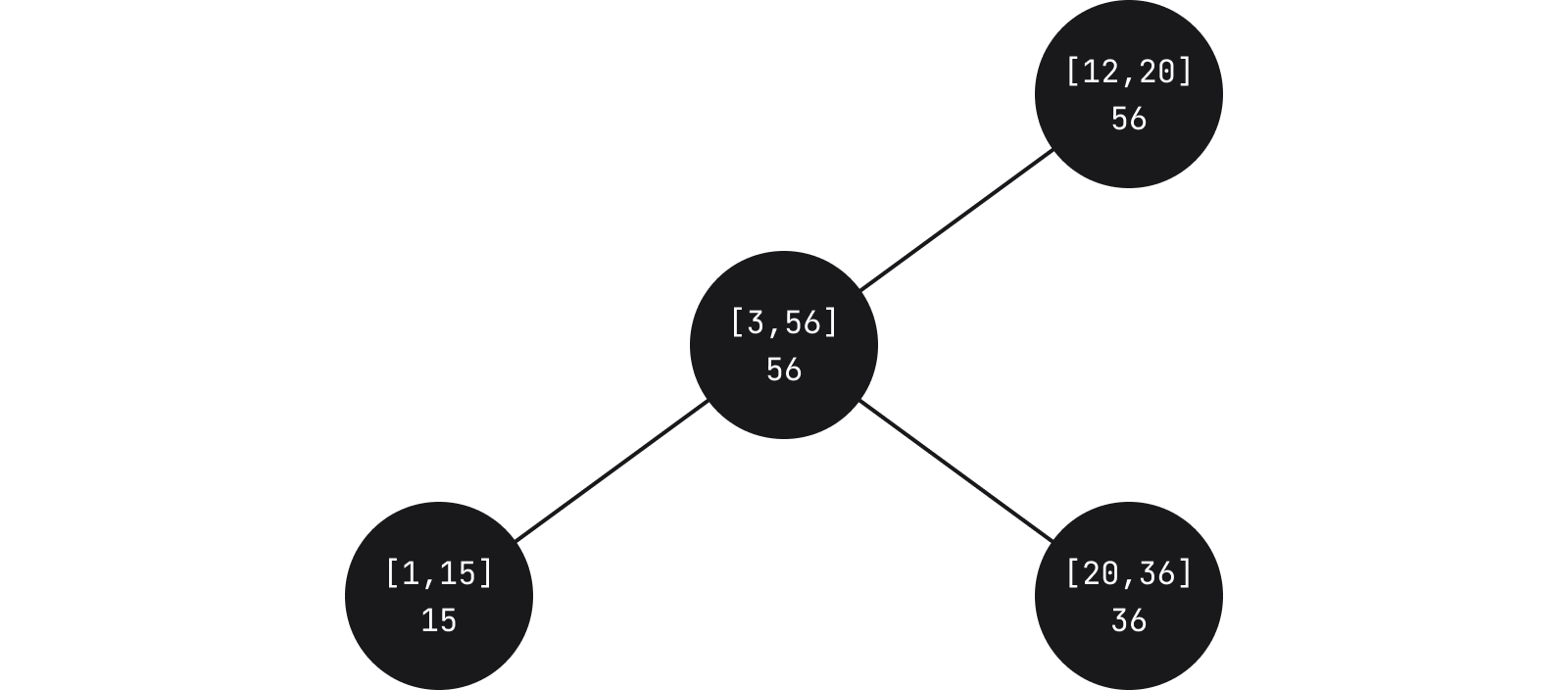
In Fleet, each node contains a relative start and end of children nodes. Leaves in turn contain an actual widget. When running queries to see if a particular widget needs to be displayed based on some specific coordinate, we traverse the tree until we find an intersection of the range with the one we’re querying.
An important aspect is that the leaves also contain the widget ID. This means that in addition to querying what intersects with a specific range, for any widget we can also query to determine where it actually is located.
One variation from a standard interval tree is that in Fleet we allow nodes to overlap. This leads to the possibility of making searches somewhat less efficient, but by allowing this, we can create balanced trees and have them updatable as we type.
In addition to widgets, interval trees in Fleet are also used to keep track of carets, highlighting of text, as well as sticky locations in text which we call anchors.
Ropes for Tokens and the Abstract Syntax Tree
When working with source code, whether it’s a compiler or an editor, you normally would use an Abstract Syntax Tree (AST). The way this works is that a parser analyzes the source code and creates a series of tokens. These tokens are then used to build up the AST.
Take the following code
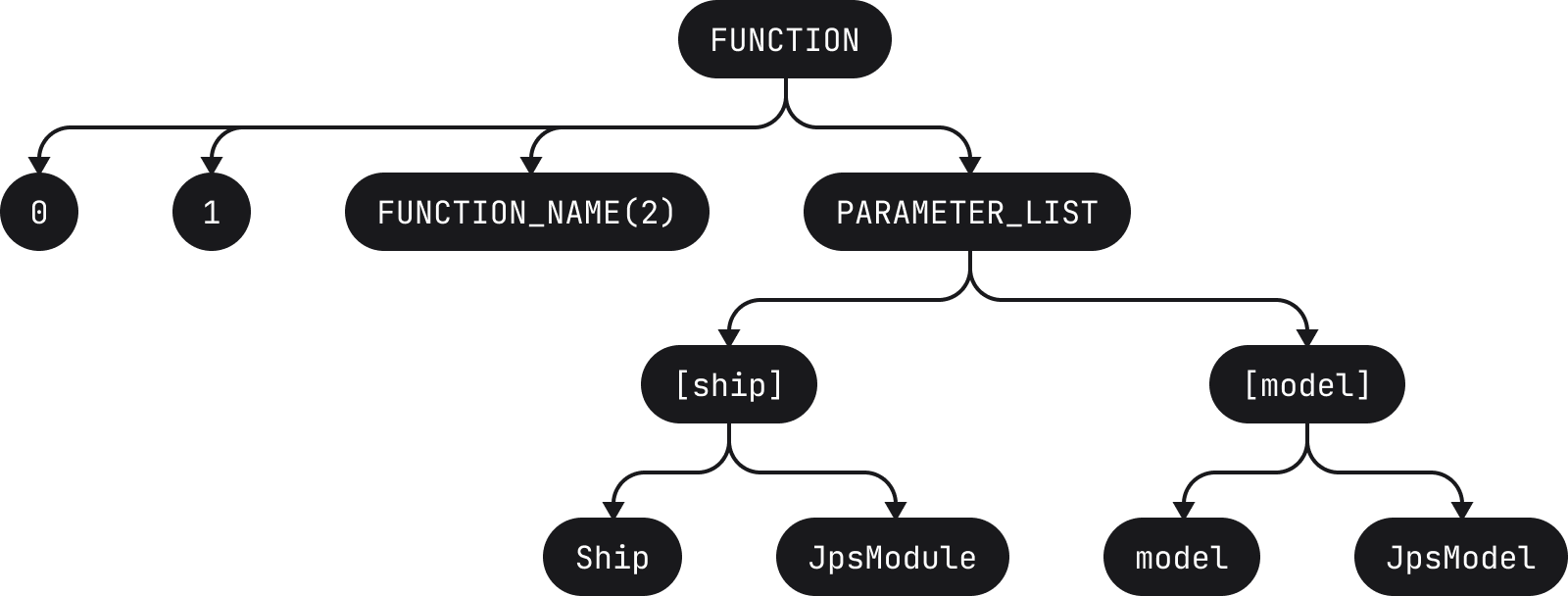
fun compileBundles(ship: JpsModule, model: JpsModel, src: SrcBundles): DstBundles
It would be broken down into the following tokens
[fun][ ][compileBundles][(][ship][:][ ][JpsModule][,][ ][model][:][ ][JpsModel][,][ ][src][:][ ][SrcBundles][)][:][ ][DstBundles]
where each token is represented by square brackets (notice how empty spaces are also tokens). These tokens are then used to build the corresponding AST
The AST is then used for a variety of operations such as syntax highlighting, static analysis, etc. It is an important part of any IDE.
By the way, if you’re interested in seeing how some code is translated into an AST, check-out this cool online AST explorer (which provides support for a variety of languages)
As we type in the editor, the text changes, meaning the tokens change, which in turn requires building a new AST so as to be able to provide the above functionality.
In Fleet, in order to avoid updating the AST directly, we use a rope structure to store the tokens in leaves (actually only the lengths are stored). To give an example, the above list of tokens could be represented with the following tree

When the user types something, for instance a space character, the tree is updated (length of 1 added in the leftmost leaf, causing increase in count along that path)
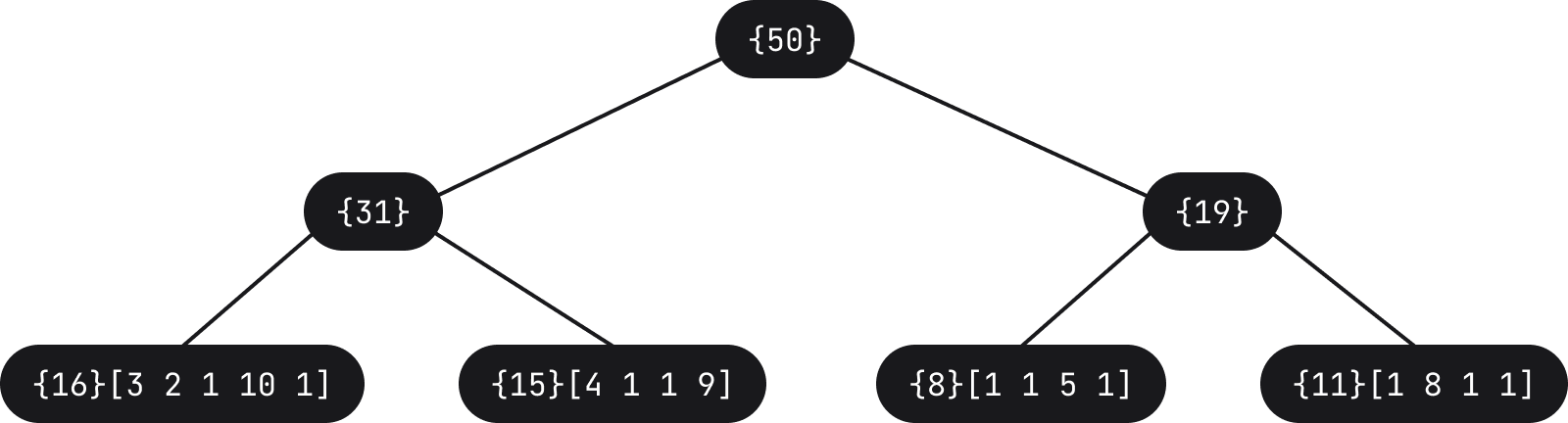
The specific leaf gets the new token length added, which in turn causes updates to certain nodes of the tree in order to adjust the weight. The parser then receives a notification which forces it to update and reparse the AST. As such, for a fraction of second the AST may not be entirely correct, however the user experience is much better when it comes to editing as very little has to be updated.
Ropes for Rendering
The image below is yet another example of the editor, but this time with a few additional elements, namely the actual usages widget expanded to display usages, soft-wrap of lines, and other things such as colored vertical lines in the scrollbar.
To render the above, for a specific Y coordinate, we need to know not only which line is displayed but also take into account all the widgets and soft-wrapped lines.
Fun fact: the editor rendered in the usages widget uses the same underlying data structures we’re exploring in this post. For usages in the same file, the same ropes are used to build and render this overlay editor.
Widget and soft-wrap information is also stored as a rope structure. Whereas before the leaves of the tree would hold the string and its length, in this case, we’re using leaves to hold what we call SoftLine objects. These are chunks of text accompanied by the heights that are considered visual lines. The weight of the nodes in this case (what we call metrics) are the height and length of the SoftLine. The height is stored in order to be able to support viewport queries. This height is affected by the interlines located inside of it. In addition, when soft-wraps are enabled, SoftLines don’t correspond one to one with real lines, but can span multiple lines.
A note on immutability
It’s important to mention that in Fleet we embrace immutability. Working with pure functions and immutable objects provide many benefits. Pure functions allow us to not only reason better about the code but also know that calling a function will not cause some other part of a system to change without our knowledge (i.e. have side-effects). In terms of data, knowing that an object is immutable means that it is thread-safe, and consequently there would not be race conditions when attempting any updates. For multi-threaded environments, this provides huge benefits.
This idea of immutability is also central to operations that use rope structures. Previously we spoke about how we make updates to nodes and leaves of the trees. These are all done in an immutable way – any operation on the tree produces a new copy of the tree which shares the structure with the old one, except from the root to the single node which needs changing. The fact that the trees in general are wide and not deep means that paths are very short. If the operation leads to any unreferenced nodes, these get garbage collected.
This is a significantly different approach from what we do on the IntelliJ platform where we use read-write lock mechanisms to perform changes.
Summary
As we’ve seen in this second part on how we build Fleet, something as simple as an editor where we can type and read code turns out to be a complex underlying aggregation of multiple different data structures, many of them being ropes. If you’re interested in learning more about ropes, make sure you check out the series on Rope Science, which has heavily influenced the work we’ve been doing on Fleet.
Until the next time, happy sailing!




